“如果說中小企業是一片片沿溪而耕的農田,那么我們的愿景就是建一座大壩來管理好上游的水資源,來灌溉下游企業,”
騰訊云資料庫高級工程師楊玨吉說這是他投身資料庫領域的初衷,初創企業、中小企業在資料庫層面的最大需求就是低成本,助力企業降本增效是騰訊云資料庫一直在努力的方向,尤其在疫情沖擊下的經濟社會中,更是一份社會責任,
在技術上深研,突破極致彈性,讓客戶像使用自來水一樣的使用資料庫,用多少、怎么用由客戶決定,計費由使用量決定,這是楊玨吉及其團隊給出的答案,TDSQL-C Serverless 資料庫通過使用計算存盤分離架構,實作自動擴縮容、按使用量計費、無使用無計費功能,從而實作大幅降低成本,下面將詳細介紹功能實作背后的架構原理及應用場景,
點擊此處觀看完整版視頻
一、產品特點
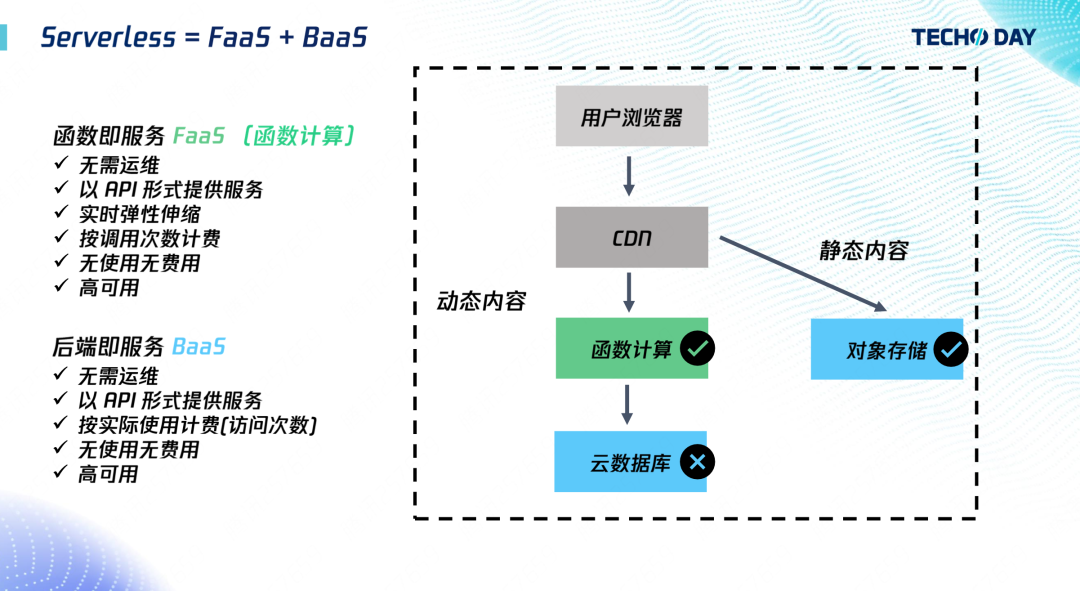
Serverless 分為 FaaS 和 BaaS,其中 FaaS 是函式即服務,也就是我們熟悉的云函式,可以理解成是云主機的一種抽象,免去了復雜的運維,幫助開發者自動擴縮容,實作服務的高可用,并按使用量計費,
BaaS 是后端即服務,比如物件存盤,它也免去了開發者的檔案存盤管理的負擔,能提供足夠的彈性能力,實作按照使用量計費,所以它也滿足 Serverless 的要求,
目前云資料庫的售賣方式還是與云主機類似,開發者需要購買一個固定規格的云資料庫,比如CPU 4 核記憶體 8G,即使開發者沒有 SQL 請求,也將按照 4 核 8G 進行計費,
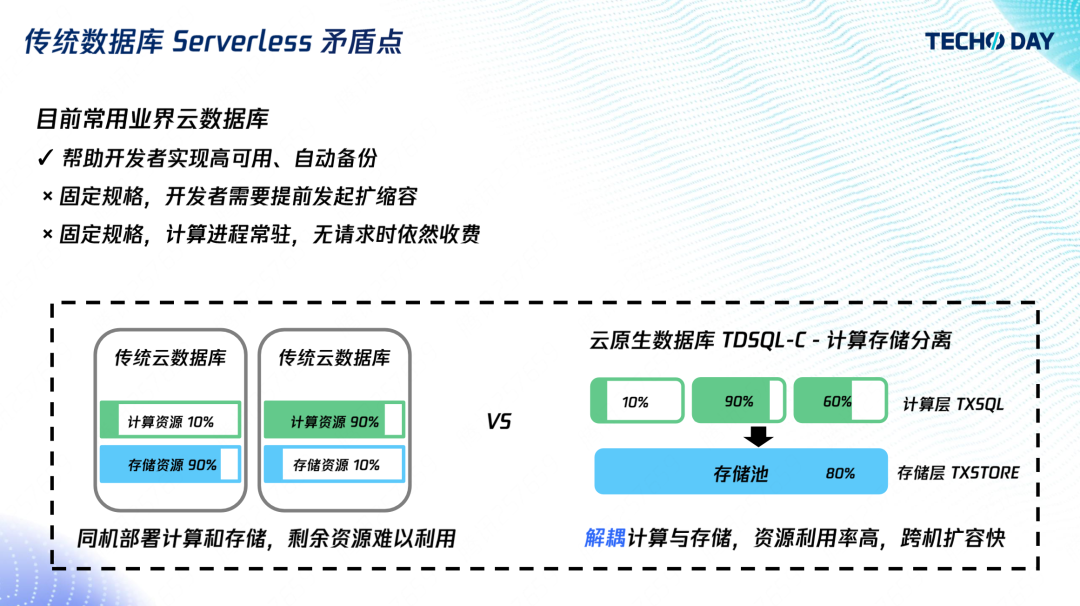
業界場景的云資料庫,確實幫助開發者實作了高可用和自動備份,減少了運維負擔,但開發者需要提前預測業務請求量,并發起擴縮容,也無法在沒有使用的時候不收費,
傳統云資料庫同機部署計算和存盤,內核行程直接寫本地資料檔案,當一臺機器的存盤使用已經接近 90%,即使整機存量實體的計算資源負載再低,也無法再分配新實體了,在這種情況下,該機器上存量實體的用戶,雖然沒有使用計算資源,CPU 記憶體都是 0,也依然要承擔此機器計算資源的費用,反過來也一樣,計算使用 90%,而存盤使用量較少,也將導致剩余存盤無法再售賣,
按實際用量付費的問題本質是按實際用量分配資源,所以云資料庫如果要邁向 Serverless 這個目標,要做的就是計算存盤分離,
計算存盤分離的優勢很多,比如存盤空間和寫帶寬能突破單機上限,更強的容災能力等等,本文重點講解資源分配彈性靈活的特點,
計算存盤分離能使計算和存盤解耦,任意計算節點能訪問任務的存盤節點,計算和存盤維護各自的資源池,分別最大化、最靈活地進行資源分配,存盤層按存放的資料量收費,計算層按真正的負載收費,
另一方面,傳統云資料庫擴縮容需要搬遷資料到另一臺物理設備,所以耗時長,而計算存盤分離架構,計算層擴縮容不需要搬遷存盤層的資料,直接分配計算層資源即可,秒級完成擴縮容,
在計算存盤分離之上,TDSQL-C 完成了 Serverless 產品功能的設計,讓我們來看看具體是怎么做的,
二、架構設計
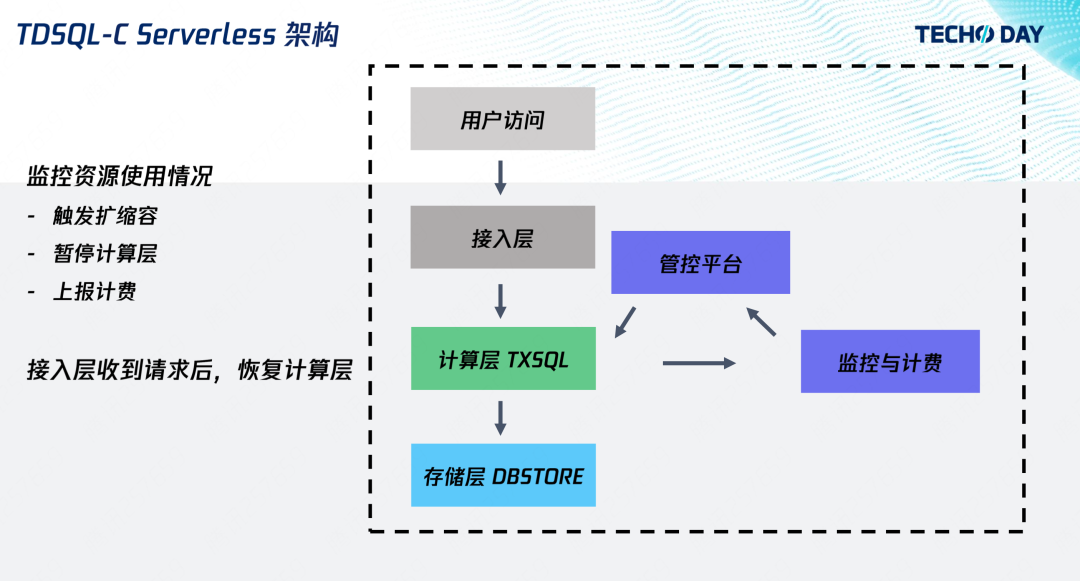
上圖是開發者訪問的全鏈路,應用程式通過接入層訪問計算層,計算層從存盤層回傳資料,
我們的 Serverless 形態是利用監控計算層實作的,通過監控,我們對計算資源進行自動擴縮容,并對該時刻所消耗的資源進行計費,當發現沒有請求時,監控服務就會觸發計算資源的回收,并通知接入層,用戶再次訪問時,接入層則會喚醒實體,再次提供訪問,

從客戶角度總結起來就是三大特點:
自動擴縮容:根據業務負載擴縮容實體,開發者無需預測負載并提前擴容資源;
按使用量計費:以實際使用的負載進行計費,開發者無需為自己沒有使用到的資源付費;
無使用無費用:無資料請求時,不對計算資源計費,
1. 自動擴縮容

自動擴縮容的目標是讓客戶可以像使用自來水那樣使用資料庫,既可以一滴一滴,也可以像瀑布一樣傾瀉地用,
開發者在購買一個 Serverless 實體時,需要指定擴縮容的范圍,也就是最小和最大規格,比如開發者購買了一個最小 1 核 2G 最大 2 核 4G 的實體,我們對 CPU 和記憶體限制到最大規格,也就是說 CPU 和記憶體不存在擴容的時間,而 Buffer Pool 根據 CPU 負載定時調整,
這是一個我們最開始考慮的方案,也是比較業界常見的擴縮容方案,
上圖縱軸表示 CPU,橫軸表示記憶體(Mem),矩形框代表資源限制,實體閑時,就限制實體的規格為 1 核 2G,負載來臨時,CPU 迅速打滿,監控發現后,再觸發擴容,擴成 2 核 4G,其中快取也是 BP 大小也相應增加,可以看到在擴容發生之前,用戶的 CPU 使用是受到限制的,限制的時間取決于觸發擴容的閾值,

我們后來采用的方案則是一開始就限制到最大規格,負載來臨時,可以一下子使用到更多的資源,然后根據 CPU 的使用量來觸發快取大小的更新,在這個方案下用戶使用資料庫可以無感知進行 CPU 擴容,并且也不會因為鏈接突增導致實體 OOM,
2. 按使用量計費
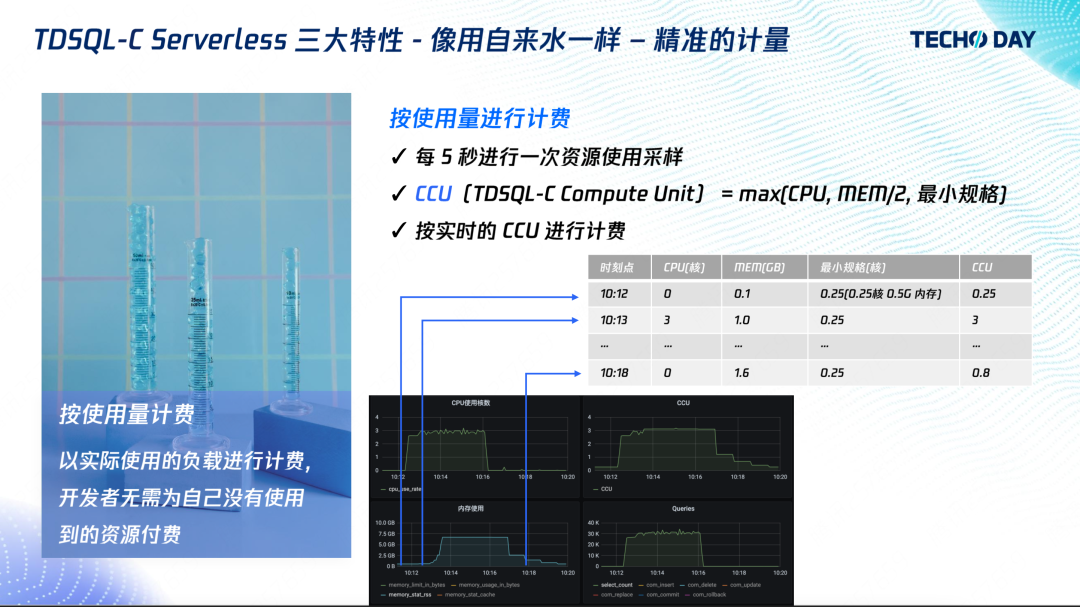
使用量計費的目標是秒級別的計費粒度,以及任意單位的資源規格,比如用到 0.7 核,就按 0.7 核收費,而不是不足 1 核算 1 核,
我們的監控室每 5 秒采集一次,采集結果統一使用 CCU(TDSQL-C Compute Unit)作為統一的算力單位,其計算方法為 CPU、記憶體的1/2以及最小規格三者取最大值,
以上圖為例,閑時以最小規格 0.25 CCU 計費,負載來臨時以 CPU 進行收費,即為 3;當負載結束時,記憶體還在釋放,為記憶體的1/2 ,也就是 0.8,
3. 無使用無計費
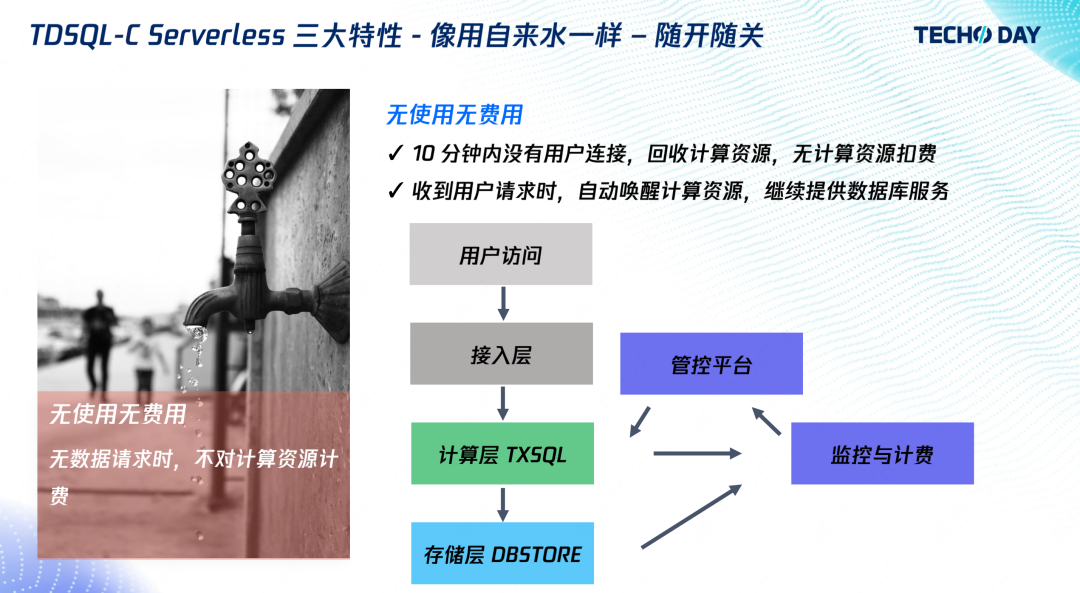
問題來了,大家可能覺得閑時按最小 0.25 CCU 計費也還是多了,于是我們推出無使用無費用的功能,
10 分鐘沒有收到用戶連接,就將回收計算節點,轉為暫停的實體,暫停的實體收到用戶請求后,啟動計算節點,恢復為運行中的實體,
我們通過監控計算的連接數,沒有連接則向管控發起暫停,
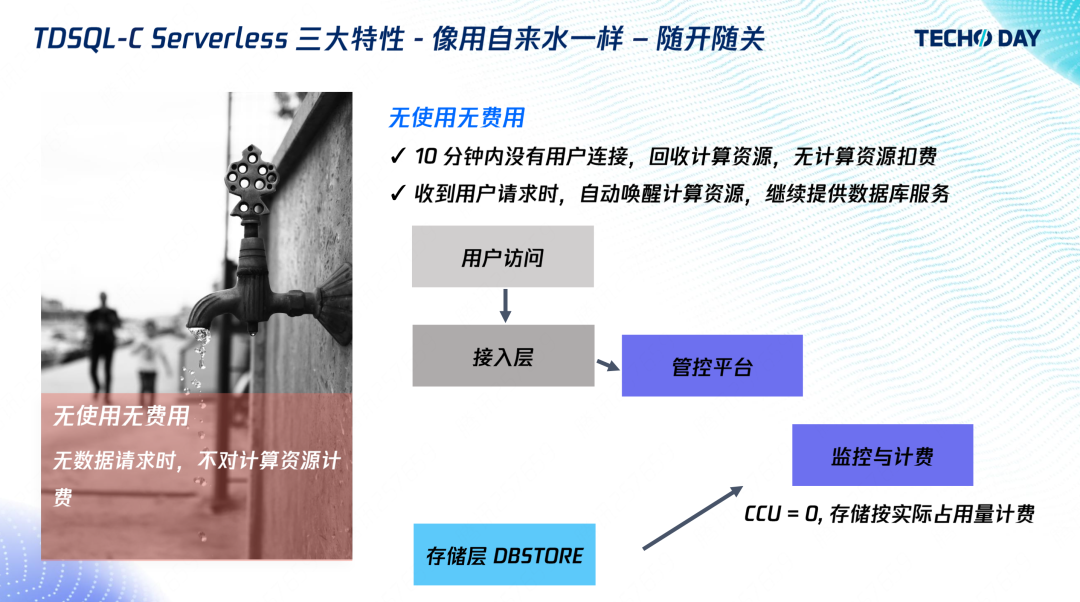
暫停后,我們回收了計算層所有資源,不再對計算資源收費,僅對存盤資源進行收費,接入層收到用戶請求后,管控則會啟動實體,提供給用戶訪問,

這當中比較重要的是恢復時間,也就是冷啟動時間,在恢復時間上,我們做了相當多的優化,包括找持久化的日志位點以及 BP 和事務系統的初始化,目前,恢復時間能做到僅需2秒,
有的讀者可能會感興趣計算存盤分離的架構細節,接下來簡要分享一下架構細節,
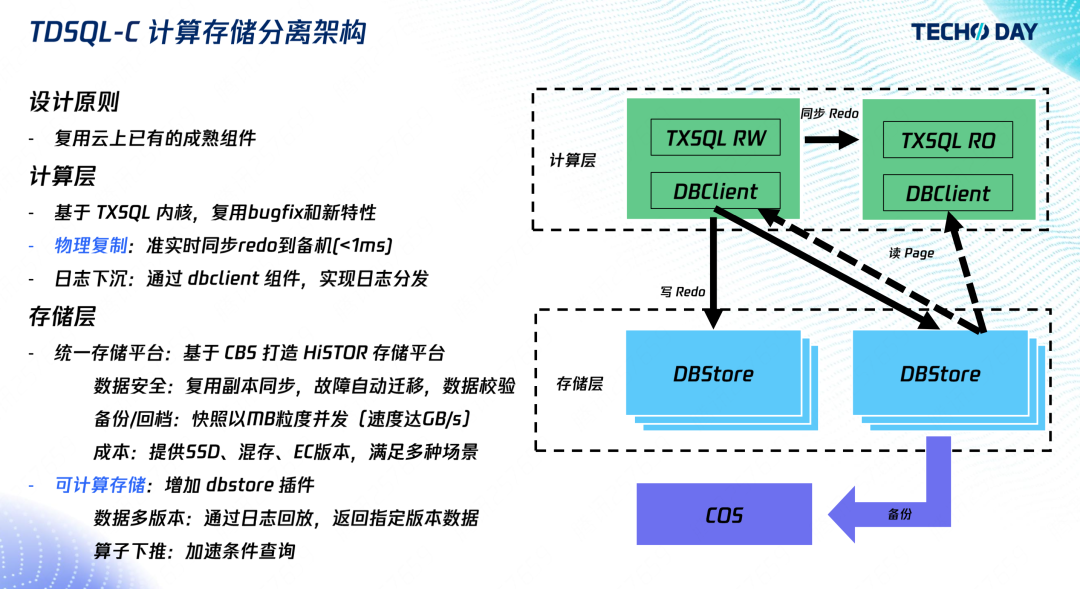
在計算層,我們使用的是的 TXSQL,完全兼容 MySQL 協議,能夠復用社區的 bugfix 和特性,主從復制使用 redo 復制,優點是延遲低,redo 日志不落在本地,而是發送給存盤層,
在存盤層,我們使用的是云硬碟的 HiStore 存盤平臺,保障了資料安全、GB 級別的備份回檔、以及性能與成本的多種存盤選擇方案,我們在 HiStore 中加入資料庫的邏輯,實作日志回放以及算子下推,
大家如果不熟悉資料庫也不要被這個這些名詞嚇到,我們對外其實就是提供的是與 MySQL 一致的資料庫服務,區別是內部我們做了計算存盤分離,分離之后計算層的資源可以更自由、靈活地分配,
三、應用場景
應用場景是廣大開發者比較關心的,接下來給大家分享六類場景的實際應用,
1. 慢查詢
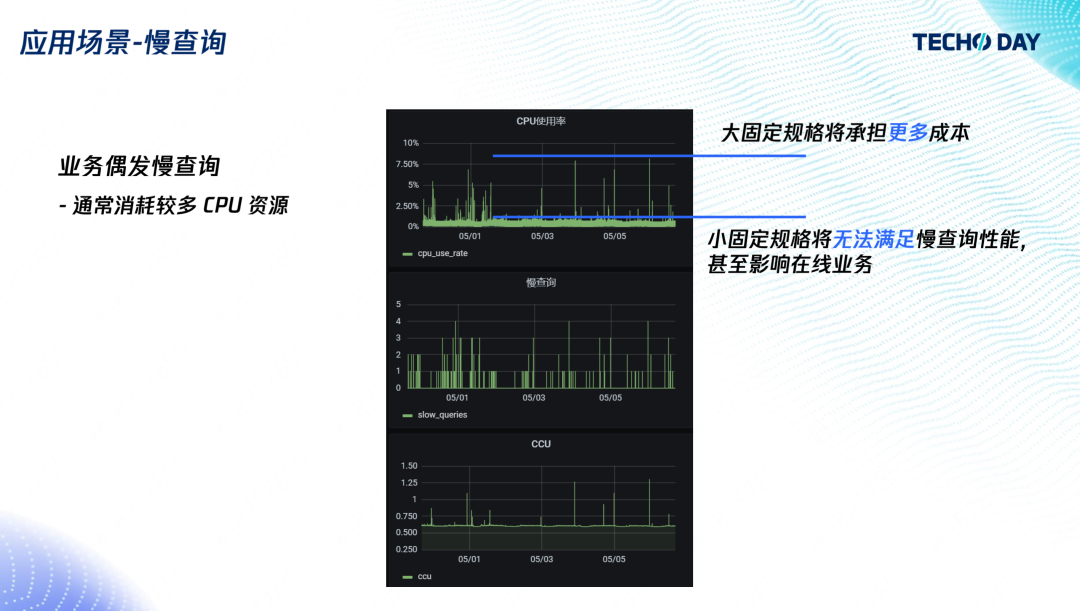
當開發者的 SQL 優化得不夠好,或者偶爾需要全表掃描分析資料時,就會出現慢查詢,與慢查詢相伴的往往是 CPU 使用率高(因為掃描的資料比較多),
這也是用戶能切實感知到的,從上圖的監控中可以看到慢查詢與 CPU 是正相關的,如果用戶購買一個比較大的固定規格的實體,那么將承擔額外的成本;如果購買的是小規格實體,那么在慢查詢到來時用戶的 CPU 會被占滿,進而影響業務,使用Serverless 資料庫就不用擔心這個問題,大部分時間Serverless 資料庫以低 CCU 進行付費,慢查詢來臨的時候可以立刻用到額外的 CPU,所以整體上也只是影響慢查詢時刻的計費,
2. 定時任務
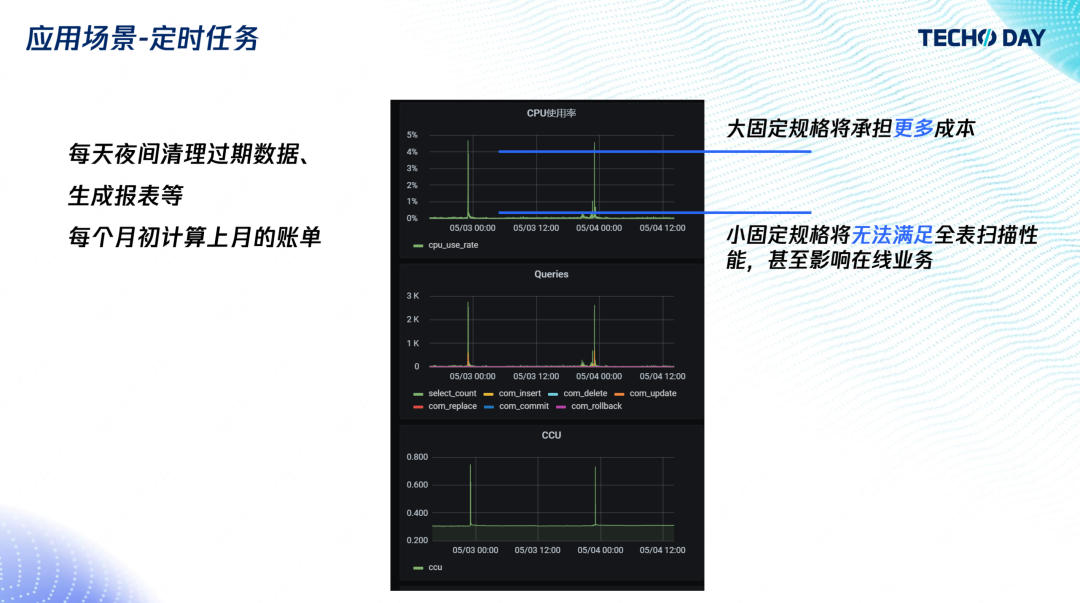
與慢查詢類似,有相當多的業務都有定時處理邏輯,包括定時清理舊資料、定時生成前一天的報表等,上圖可以看到,用戶在每天 0 點會跑非常多的請求,但平時大部分時間是一個低負載,用戶使用了 Serverless 資料庫之后,也不用去對規格和費用做權衡了,和上一個例子一樣,用多少就計費多少,
3. 歸檔資料庫
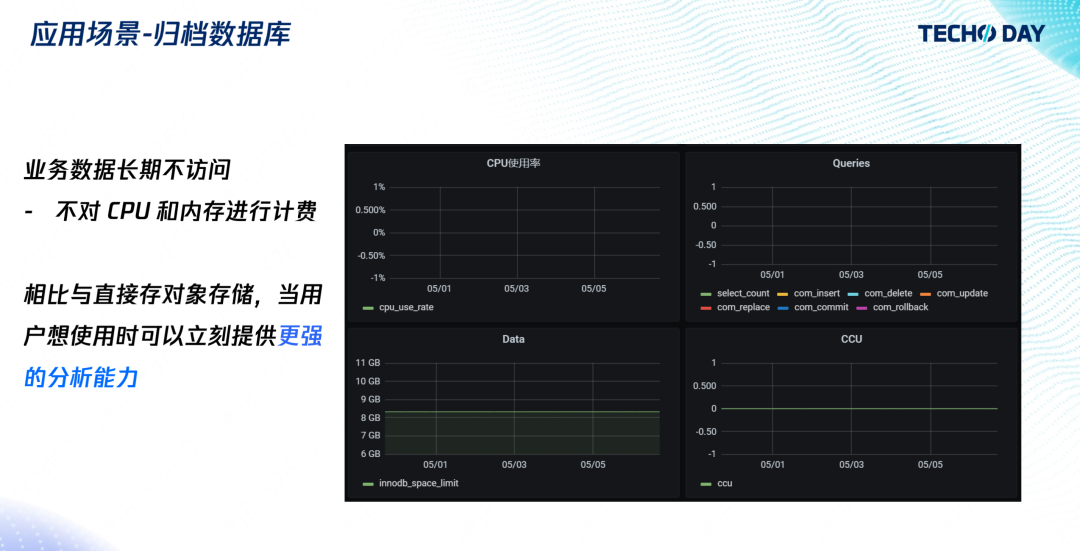
如果長時間不用資料庫,就不用對 CPU 和記憶體進行收費,這類通常見于一些檔案資料庫、機器學習的樣本資料庫、個人家庭的歷史傳感器資料庫等,不會經常使用,而是偶爾訪問的狀態,這類資料的常見的做法是直接存在 COS 里,需要的時候去下載,而Serverless 資料庫有一個很大的優點就是需要的時候立刻能夠提供索引,且擁有強大的分析功能,開發者不需要自己去寫代碼就能搜索到需要的資料,
4. 低頻訪問的業務
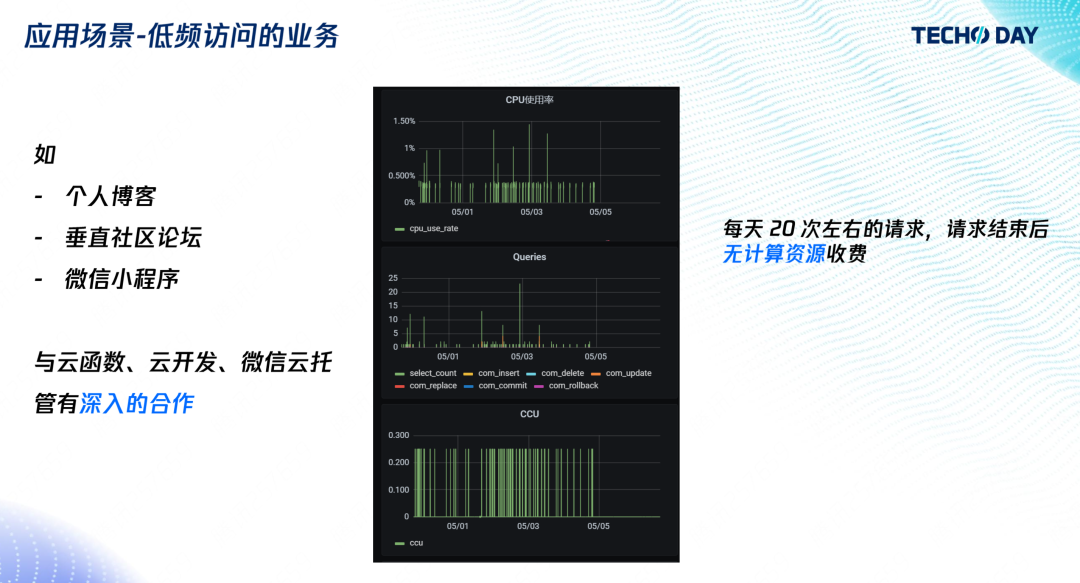
對于平均每天的訪問量小于 10 次的低頻訪問業務,例如個人博客、垂直社區論壇、微信小程式,我們與云函式、云開發、微信云托管有深入合作,能實作訪問結束后就停止計費,
5. 開發測驗環境
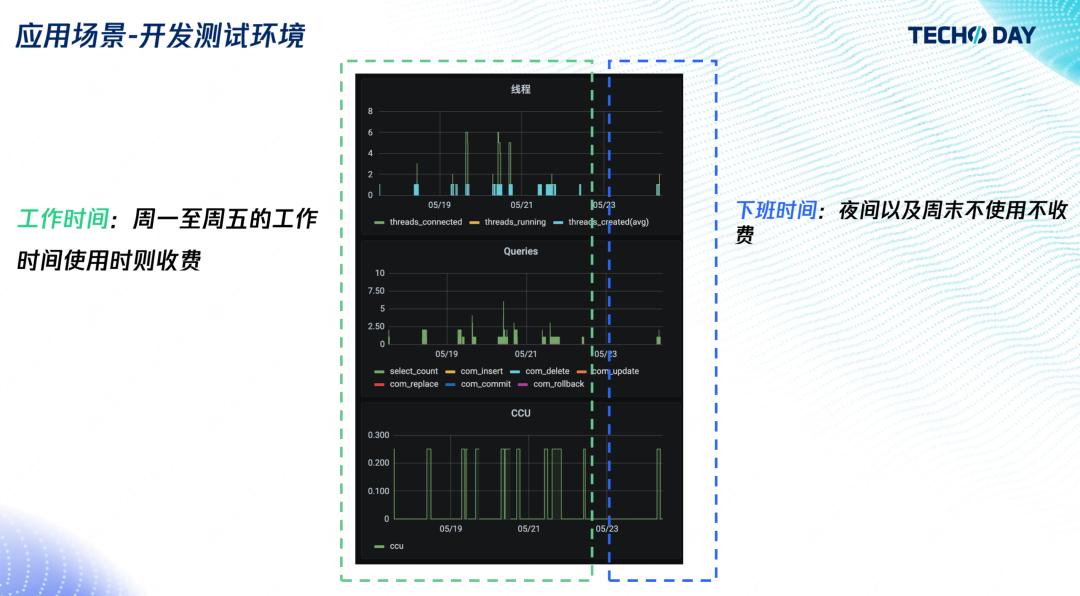
上圖可以看到在一周時間內,用戶在晚上、周末都沒有訪問和使用,用戶通過 TDSQL-C Serverless 資料庫的自動暫停功能,節省了大量研發測驗成本,
6. 微服務場景
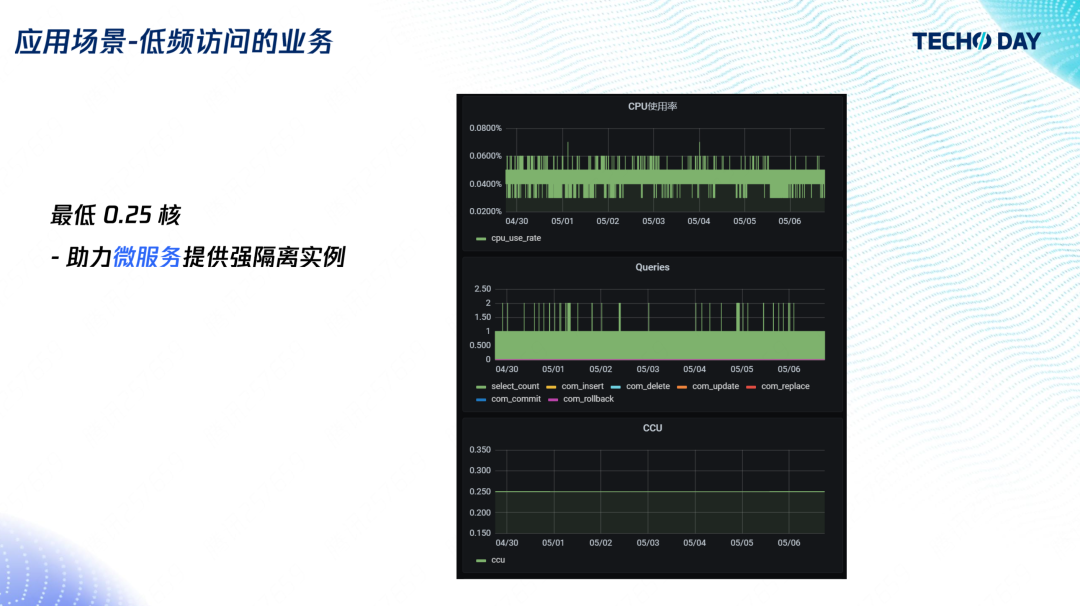
隨著微服務越來越流行,每個單獨的服務負責的功能也越來越小,隨之對應的是微服務后端的資料庫的負載也會變小,一種做法是多個微服務共用一個大的資料庫,但這會帶來相互影響的問題,所以,Serverless 資料庫提供小規格的資料庫實體,來保證微服務之間的隔離性,
四、總結與展望
TDSQL-C Serverless 補充了資料庫領域中 Serverless 的空白,在自動擴縮容上,可以使 CPU 瞬間用到最大規格,按使用量計費上能夠按 CPU 實時的使用量進行計費,不使用不計費上冷啟動時間是 2 秒,目前在 Serverless 資料庫中是絕對領先的,未來我們也會在冷啟動上做進一步的優化,以及幫助客戶進一步降低使用成本,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500879.html
標籤:其他