通過簡單的KV資料庫理解Redis
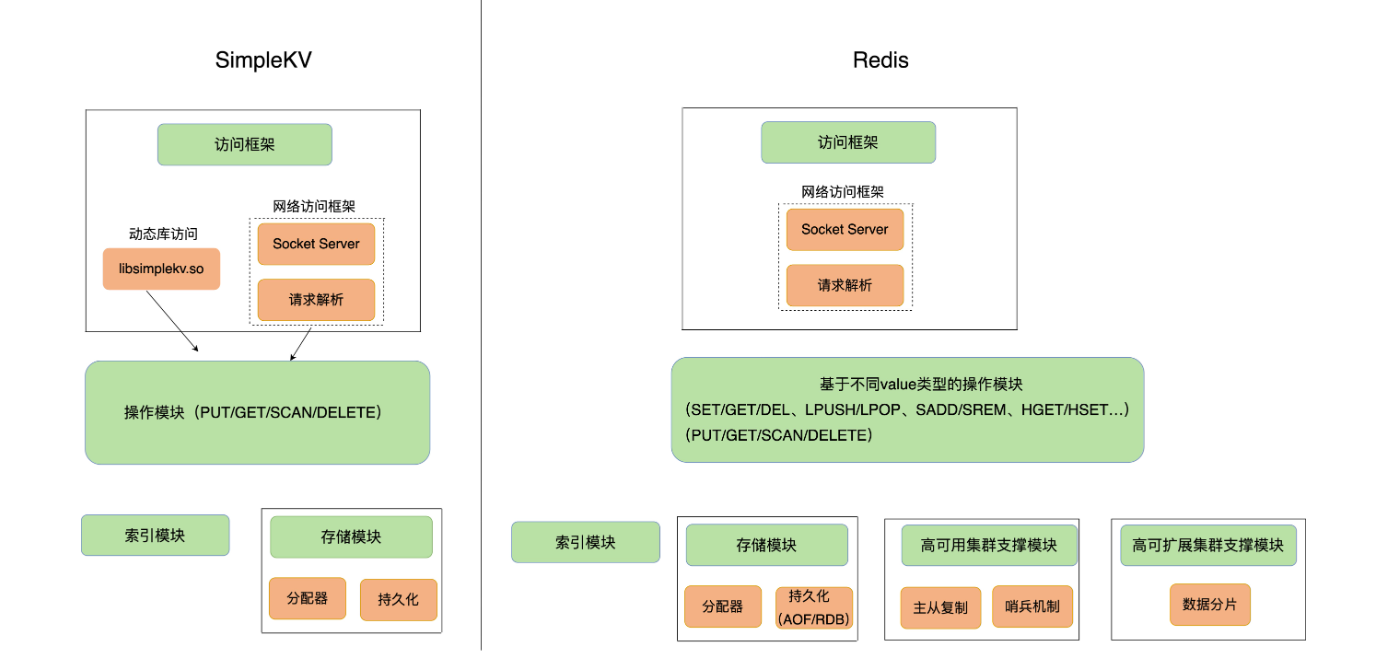
分為訪問模塊,操作模塊,索引模塊,存盤模塊
底層資料結構
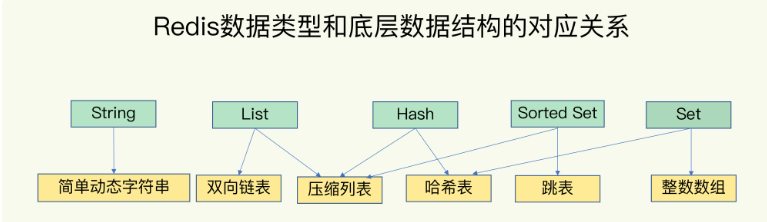
除了String型別,其他型別都是一個鍵對應一個集合,鍵值對的存盤結構采用哈希表
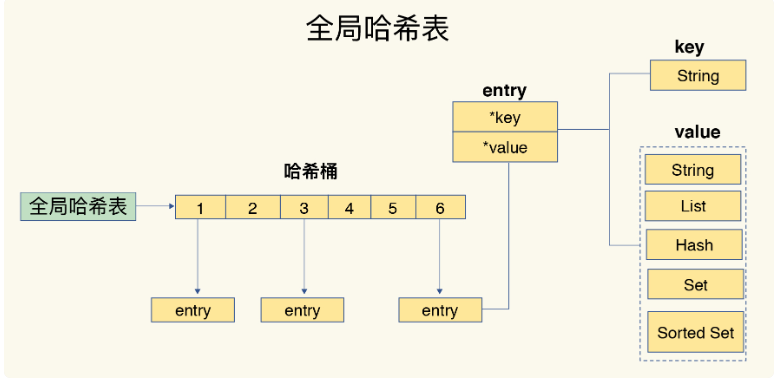
哈希表由多個哈希桶組成,桶中存盤entry元素,存盤key和value的地址
但是當hash沖突元素過多會導致查詢效率變慢,所以引入rehash操作
采用兩個全域hash表,但是從一個哈希表復制到另一個哈希表肯定會造成執行緒阻塞,所以使用漸進式哈希 :分攤到多次拷貝
接受第一次請求就拷貝第一個索引的entry元素,下一次再拷貝第二個,以此類推
對于集合型別的底層資料結構:雙向鏈表,壓縮串列,哈希表,跳表,整數陣列
壓縮串列:

跳表:
增加多級索引,通過索引位置的跳轉,快速找到元素 (時間復雜度為logn)
不同操作所對應的時間復雜度也不同
對于單個元素的操作一般為O(1)
范圍操作一般為O(n),一般使用scan來代替
統計操作,因為底層的資料結構中有元素個數的統計,所以時間復雜度為O(1)
為什么快
單執行緒(多路復用)不會阻塞在一個客戶端的請求連接上,因為在請求程序中有可能會因為監聽到有連接請求但是遲遲沒有建立起連接或者建立起連接資料一直沒有到達都會發生阻塞,所以采用多路復用非阻塞結構,允許在內核中存在多個監聽套接字和已連接套接字,采用**事件回呼機制**,當有事件到來,進入一個佇列,redis處理佇列中的請求,針對每個事件都有相應的回呼函式
在記憶體中操作資料
高效的底層資料結構
持久手段
AOF(記錄操作命令,所以恢復時還要執行,速度慢)
mysql資料庫是寫前日志,redis是寫后日志,所以不會阻塞當前的寫操作
但是有兩個風險:1.redis宕機,有丟失一段時間內資料的可能 2.因為在主執行緒中進行aof操作,有可能會阻塞下一個操作
但是隨著時間的推移,aof檔案越來越大怎么辦,資料恢復效率肯定會降低?
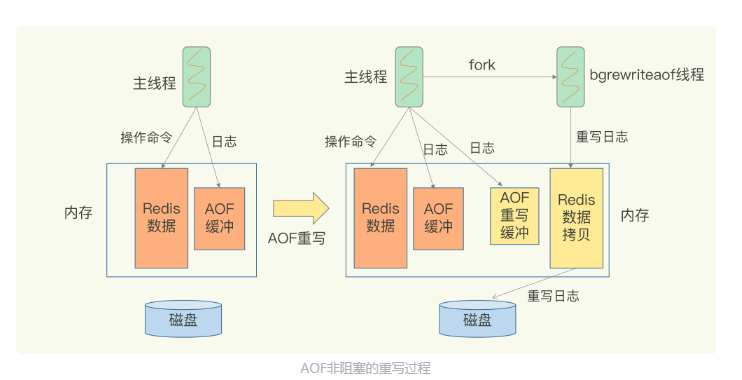
引入aof重寫
多變一,把多條對同一個鍵的舊操作合并成最新的一條操作
但是aof重寫會阻塞主執行緒嗎?
不會的,和aof追加寫入不一樣,采用的不是主執行緒,是由主執行緒fork出的子執行緒bgrewriteaof執行緒重寫,子執行緒里也有父執行緒的記憶體的最新資料(共享頁表)
在重寫程序中,客戶端的操作也會由主執行緒寫入當前aof的緩沖區和重寫aof的緩沖區,保證宕機也是資料齊全的,重寫之后資料也是最新的
RDB(記憶體快照)
把某一時刻的狀態記錄到磁盤上
兩個命令生成RDB:1. save,使用主執行緒,會阻塞主執行緒 2. bgsave,使用子執行緒,避免了阻塞問題(但是主執行緒只可讀,不可寫)
那么在記錄到磁盤的時間段內,怎么保證資料不被修改?
使用bgsave+寫時復制:主執行緒修改處于RDB中的資料時,需要生成一個副本,子行程把副本資料寫進RDB檔案
雖然RDB恢復速度快,但是進行持久化的時間間隔卻不好把控,所以Redis4.0推出AOF和RDB結合的方法:在兩次RDB持久化期間,期間發生的改動由AOF記錄,這樣恢復資料即快,又避免了頻繁fork子執行緒對主執行緒的阻塞,
?
高可用
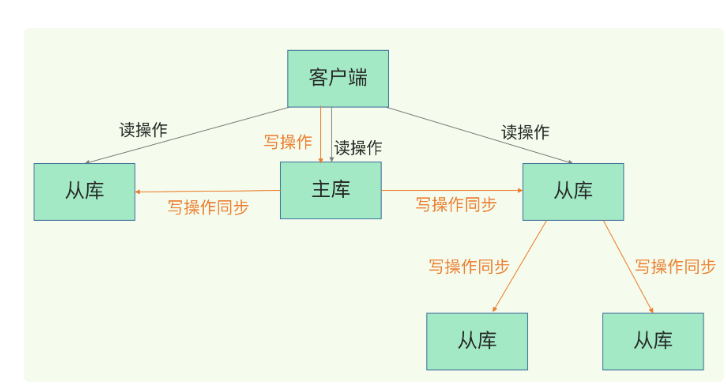
主從
主從同步程序
第一步:從庫發送同步命令,包括主庫ID和復制進度offset
第二步:主庫生成RDB檔案,發送RDB檔案,全量復制,發送包含兩個引數:主庫ID和復制進度offset
第三步:主庫把第二步程序中收到的命令發送到從庫
那么當從庫增多,主庫fork子執行緒生產RDB的壓力必然會增大,所以采用主-從-從架構,進行從庫之間的級聯,取一些從庫幫主庫分擔壓力
那么網路斷了怎么辦?
redis2.8之前是再進行一次全量復制
之后是進行增量復制
在redis中存在一個環形緩沖區,記錄主庫寫的進度和從庫復制的進度,由兩個引數確定,master-repl-offset和slave-repl-offset
網路斷開再重連之后,從庫根據offset位置進行增量復制就好
但是如果從庫復制進度趕不上主庫寫的進度,緩沖區就會被覆寫,就會觸發從庫的全量復制,所以一般增大緩沖區為2倍
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/501222.html
標籤:其他