時代在召喚: HTAP Is On The Way
近些年,HTAP 正在受到人們越來越多的關注,Gartner 在 2014 年提出了 HTAP 這個術語和它的定義:
Hybrid transaction/analytical processing (HTAP) is an emerging application architecture that ”breaks the wall“ between transaction processing and analytics. It enables more informed and ”in business real time“ decision making.
在此之前,市面上基本是 OLTP 和 OLAP 資料庫的天下,
OLTP
第一個有效的面向事務的資料庫在 1970 / 1980 年代開始廣泛使用,它們后來被稱為在線事務處理 (OLTP:Online Transaction Processing) 系統, 事務處理對單記錄操作可靠性、準確性和速度要求非常高,
OLAP
隨著資料量的增大,特別是互聯網的發展,OLTP 資料庫的作業負載越來越大,同時分析能力嚴重受限,我們需要一個能非常快速地在一個或多個資料庫表中查找單個記錄、多條記錄或一種記錄總數的資料庫,OLAP 資料庫同 OLTP 資料庫在技術上也分道揚鑣,
然而,針對不同資料場景選擇對應的 TP / AP 系統也帶來了相應的難題,因為 TP 和 AP 不是一套系統,在搭配使用時就會有資料傳輸的程序,在 一體化實時 HTAP 資料庫 StoneDB,如何替換 MySQL 并實作近百倍性能提升的文章中,我們總結了業界通過 TP / ETL或資料遷移 / AP 結構來構建 HTAP 系統存在的一些問題:
- 實時性低(TP + AP 系統導致了資料孤島,意味著 OLAP 資料庫中的資料總是過時的,根據資料量的不同,資料延遲通常從幾小時到一周),
- 企業維護兩套資料庫系統,管理和維護成本很高,
Gartner 的最新報告表明,傳統的 TP + AP 架構將事務和分析系統分開,業務實時回應的高需求意味著使用“過時”的資料已經不合時宜,商業時刻轉瞬即逝,我們需要創建一套更簡單的體系結構,讓 TP + AP 及 ETL 程序被單個資料庫所取代,消除資料副本,將資料存盤在 OLTP 引擎中進行事務處理,然后將資料復制到 OLAP 引擎(可能多次)以進行分析,隨著軟硬體基礎設施和資料庫技術的不斷進步,屬于 HTAP 資料庫系統的時代已經到來,
HTAP 資料庫 StoneDB 為什么選擇擁抱 MySQL 生態?
StoneDB 并不希望打造一個新的 StoneDB HTAP 生態,對于大部分資料庫用戶來說,最好的產品體驗就是開箱即用,在一個黑盒系統中完成業務的平滑遷移,最大程度的降低用戶學習成本和運維成本,而 MySQL 是世界上最流行的資料庫,擁有龐大和成熟的生態,
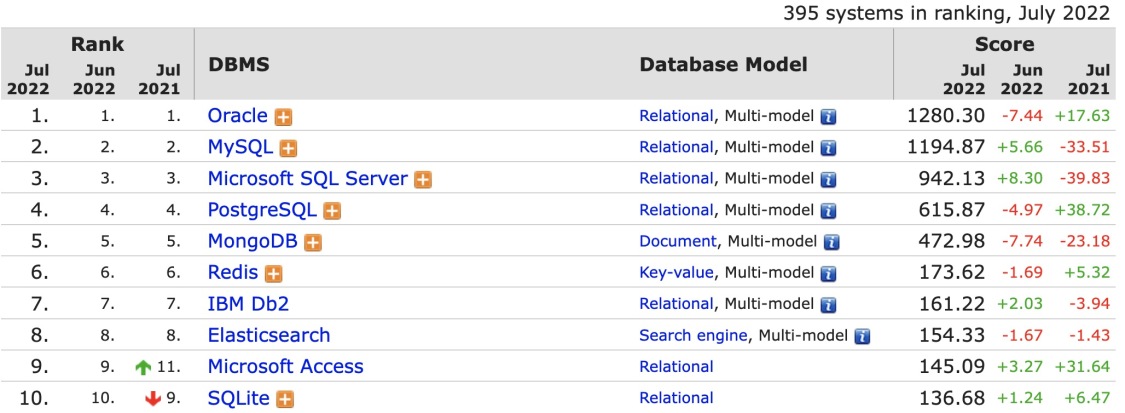
從 DB-Engines 排名上看到,MySQL 穩居第二,僅次于 Oracle,(下圖來自 DB-Engines)
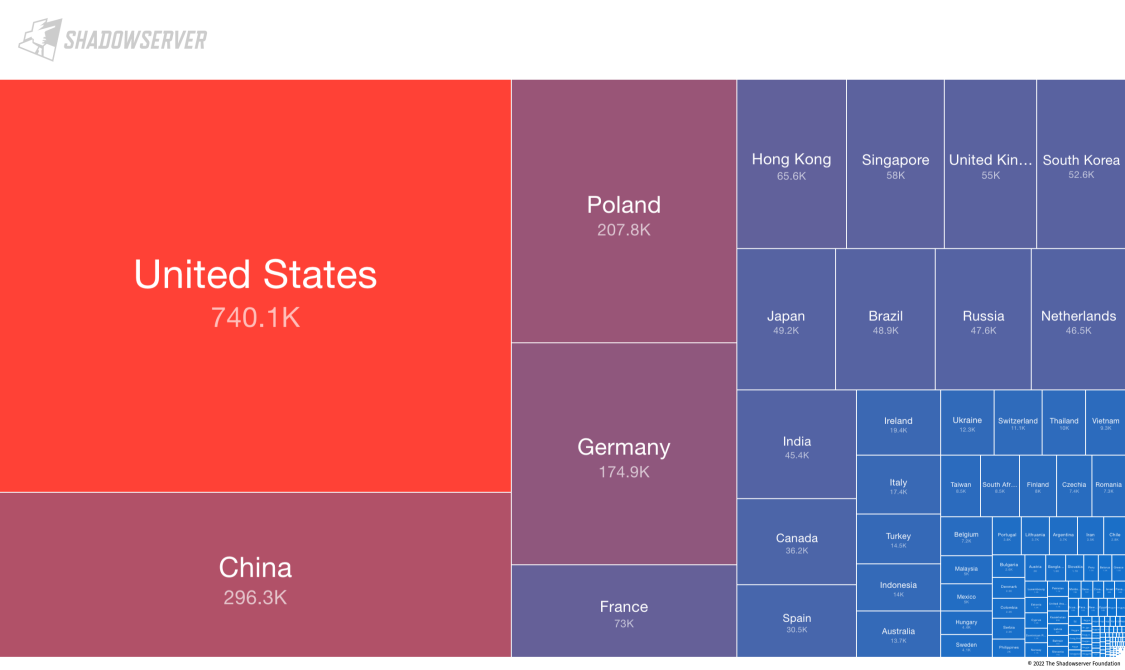
Shadowserver Foundation 在 5 月 31 日發布了一份全網的 MySQL掃描報告,超過 360 萬個 MySQL 實體暴露在公網,這只是暴露出來的,我們可以推斷,實際的裝機量要遠遠大于這個數字,
IPv4 掃描
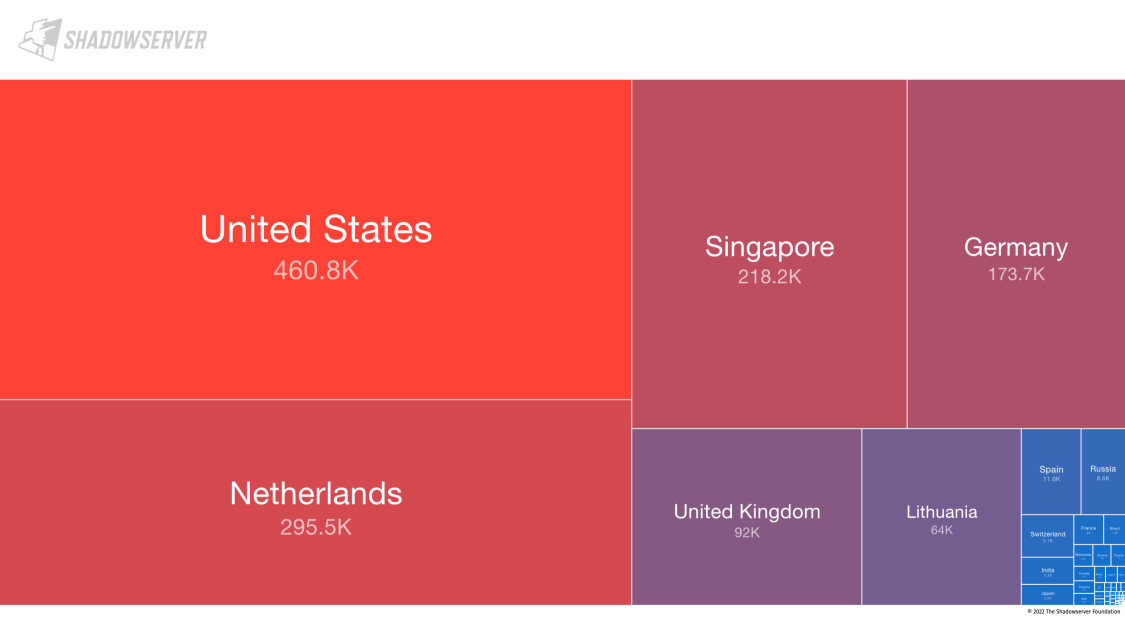
IPv6 掃描
業界唯一開源的 HTAP
我們以存盤架構為特征對業界最新的 HTAP 資料庫做一個概覽:
- 基于磁盤的行存盤 + 分布式列存盤:MySQL HeatWave
- 以行存盤為主 + IMCS (記憶體列):Oracle Database In-Memory(A dual format in-memory database)、 SQL Server、DB2 BLU
- 分布式行存盤 + 列存副本:SingleStore
- 以列存為主 + Delta Row Store:SAP HANA
從上述中可以看到,哪怕是最流行的開源資料庫 MySQL,它的 HeatWave 也不開源,
StoneDB 就是希望打破這種局面,在開源這條道路上做一個探索,做一款由我們中國人主導的開源 HTAP 資料庫,
MySQL 原生
StoneDB 沿用并適配 MySQL sql 層,原生 100% 兼容 MySQL 協議和語法,我們先看下 StoneDB 官網提供的 2.0 架構圖:
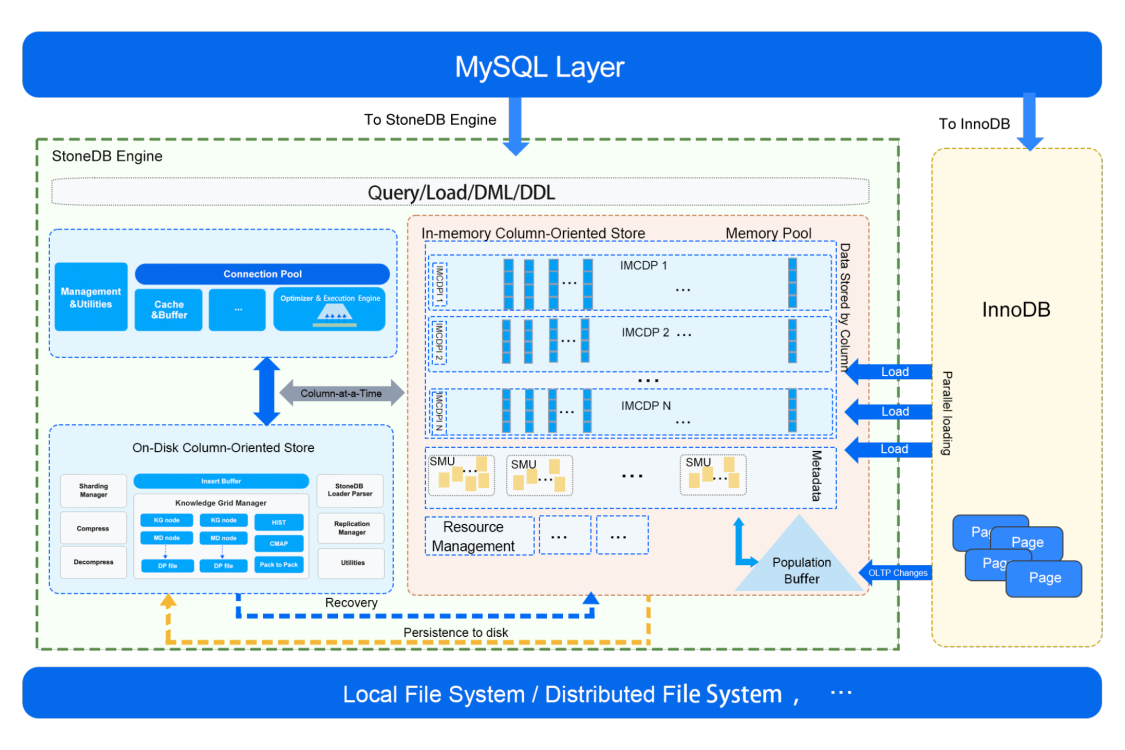
架構圖中相關術語介紹:
IMCDP:In Memory Column Data Pack 的縮寫,存盤在記憶體中的列資料包,
IMCDPI:In Memory Column Data Pack Index 的縮寫,用于保存 IMCDP 的元資料,包括:
- 物件數量
- 列數量
- 映射行的資訊
- 事務相關的資料
SMU:snapshot meta unit 的縮寫,
在 StoneDB 2.0 的設計中,會推出類似 MySQL HeatWave 的 In-Memory Column Store 引擎:基于磁盤的 RDBMS (MySQL 8.0)和分布式記憶體列存盤(IMCS)來實作 HTAP,
StoneDB 在不改變 MySQL 原生的 OLTP 作業負載的前提下,深度集成 IMCS 集群以加速查詢處理,事務在原生 MySQL 作業負載中執行,另外 StoneDB 會自行判斷復雜查詢并將其下推到 IMCS 引擎進行加速處理,經常訪問的列將被加載到 IMCS 中,列資料從行存盤中提取(由 InnoDB 并行加載到 IMCS),熱資料駐留在 IMCS,冷資料落盤,
基于 IMCS 引擎我們將實作 AP 負載的全記憶體計算:
- 記憶體中資料組織方式:IMCDP + IMCDPI ,
- 資料加載方式:由 InnoDB 并行加載至 IMCS 中,
- 資料的更新:當 TP 中的資料發生變化的時候,實時更新到 AP 引擎中,
- 記憶體中資料持久化及系統恢復:為了加速恢復的速度,我們將記憶體中的資料持久化到我們的 on-disk column store 中,
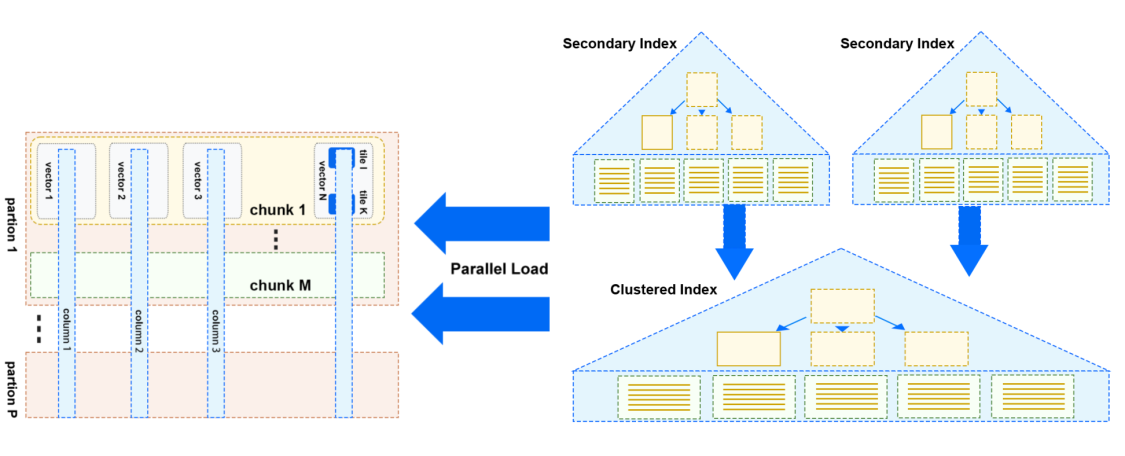
高效加載 TP 資料(From InnoDB)
上圖是剛剛介紹了 StoneDB 2.0 架構中提到的從 InnoDB 并行加載資料的示意圖,
與 HeatWave 采用的方案類似,通過并行掃描 TP 中的資料(主要是 InnoDB 表),將需要加載的資料按 partition ,chunk, vector, tile 的資料組織方式并行的加載至 IMCS 中,每個partion 中包括若干個 chunk,每個 chunk 中又包含若干個 vector,每個 vector 中包括了某列中的部分資料,同時,提供匯入行為的監控能力,實時感知加載進度,在加載程序中通過非阻塞,無鎖機制來實作高性能資料加載能力,
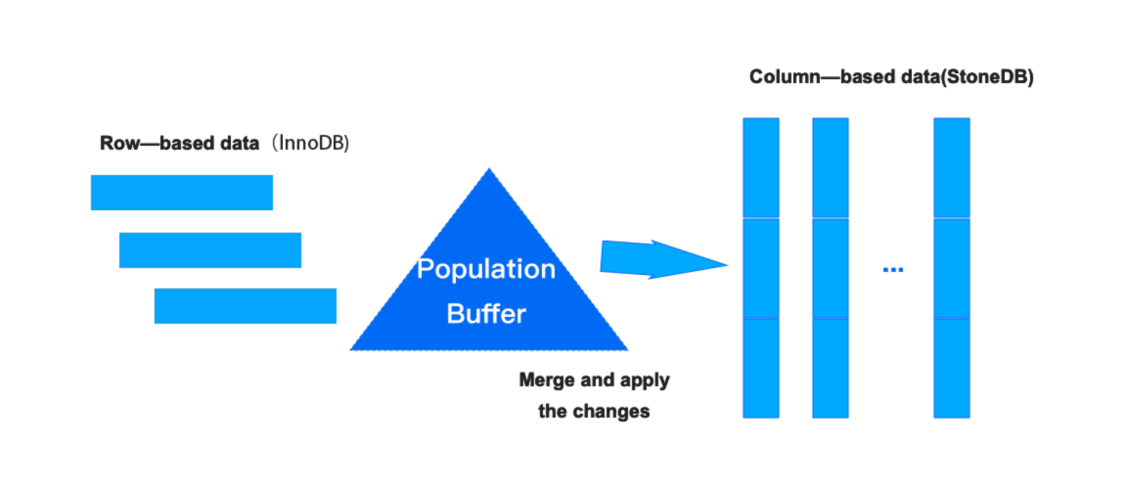
資料的更新
當 TP 中的資料發生變化后,將該項資料插入到 Population Buffer 中,并維護該資料的版本資訊,當滿足如下任一條件的時候,會將 Population Buffer 中的資料,依據版本資訊依次與記憶體中的資料合并為最新的版本資料:
- 當我們的 Population Buffer 已經寫滿后,會執行一次 flush 動作,將 Population Buffer 中的資料更新到其對應的資料中,
- 指定 merge 的時間,例如:200ms,
- 當 AP 中的負載發現其參考到了 TP 中的資料,其會主動的檢查 Population Buffer 是否有最新的版本,如果有則合并形成最新資料,
未來 2.0 其它的重點作業:
- 基于代價的新查詢引擎:一個負載透明,具有更加高效,準確的代價模型將是我們系統性能的保證;并行查詢和向量化等技術也將會得到持續的迭代,
- 分布式 Column Store AP 集群將在單機能力構建后,重點演進,
最后
除了 Gartner 的原始定義,我們對 HTAP 更多視為一個集硬體、TP、AP、記憶體、云原生資料庫技術、可擴展事務管理等多種功能的新興架構,使事務處理和分析(HTAP)能夠在同一套資料庫上運行,
一個現代的 HTAP 資料庫應該具備以下特性:
一致性:包含全面的 ACID 事務支持,資料密集型應用程式可以依靠它來保證資料一致性,從而提高開發人員的速度和用戶體驗,
高可用性:無論后端發生什么,用戶都能進行 7x24 小時的訪問,有一套內部機制來處理機器故障和網路問題等瞬時和永久性故障(比如宕機/腦裂),并且提供資料復制和細粒度資料放置功能,以確保資料高可用,并且提供滾動升級機制,避免集群擴展和架構升級等引發的停機對業務造成影響,
可擴展性:應用云原生技術,其計算和存盤資源可以輕松擴展以應對業務的增長,按需且實時地添加新節點,以存盤更多資料、處理更多讀取和寫入以及處理更復雜的查詢,
實時性:資料庫應支持任何實時更新,從而實作細粒度索引和并行查詢執行,為了確保及時性,資料庫架構必須同時利用行存盤和列存盤,并基于查詢優化器選擇最佳的資料訪問路徑,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/501761.html
標籤:MySQL