一、什么是慢 SQL
什么是慢SQL?顧名思義,運行時間較長的 SQL 陳述句即為慢 SQL!
那問題來了,多久才算慢呢?
這個慢其實是一個相對值,不同的業務場景下,標準要求是不一樣的,
我們都知道,我們每執行一次 SQL,資料庫除了會回傳執行結果以外,還會回傳 SQL 執行耗時,以 MySQL 資料庫為例,當我們開啟了慢 SQL 監控開關后,默認配置下,當 SQL 的執行時長大于 10 秒,會被記錄到慢 SQL 的日志檔案中,
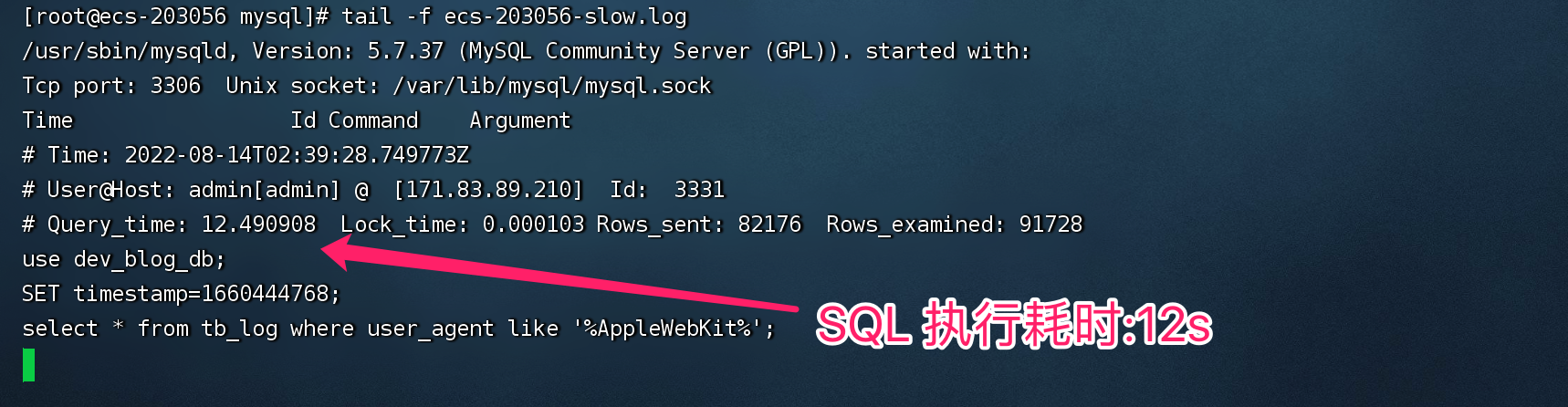
當然,這個值還可以重新設定,生產環境慢 SQL 一般會設定為0.1~0.2s,當我們將其設定為0.2s時,當前資料庫所有 SQL 的執行時長超過0.2s的都會被視為慢 SQL,
可能有的同學會發出疑問,我們為什么要追蹤慢 SQL,有什么意義呢?
二、慢 SQL 危害
這里要從慢 SQL 的危害談起,以 MySQL 資料庫為例,總結起來有以下幾點:
- 當出現慢查詢,DDL 操作都會被阻塞,也就是說創建表、修改表、洗掉表、執行資料備份等操作都需要等待,這對實時備份重要資料的系統來說是不可容忍的
- 慢查可能會占用 mysql 的大量記憶體,嚴重的時候會導致服務器直接掛掉,整個系統直接癱瘓
- 慢 SQL 的執行時間過長,可能會導致應用的行程因超時被 kill,無法回傳結果給到客戶端
- 造成資料庫幻讀、不可重復讀的概率更大,假設該慢 SQL 是一個更新操作但因執行時間過長未提交,而另一條 SQL 也在更新資料并且已提交,用戶再次查詢的時候,看到的資料可能與實際結果不符
- 嚴重影響用戶體驗,SQL 的執行時間越長,頁面加載資料耗時也就越長
以千萬級的訂單表為例,未優化的情況下,單表分頁查詢 10 條資料,耗時:39s
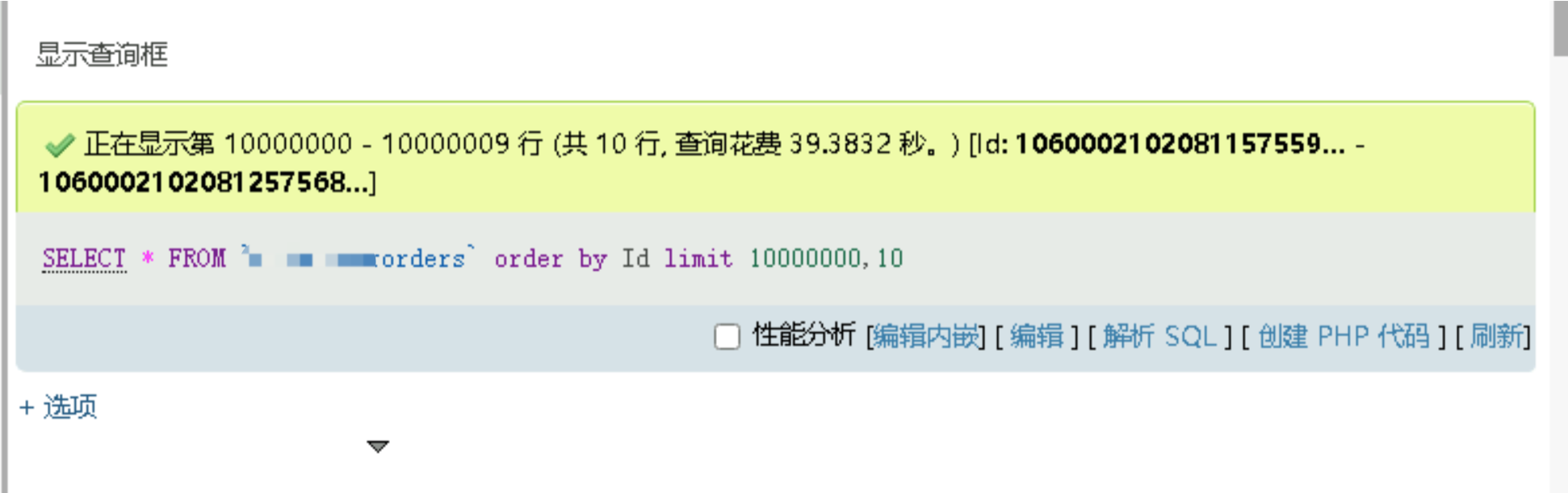
首先不說可能對資料庫服務器造成的潛在壓力,沒有任何一個用戶會在頁面查詢訂單查詢等待 39 秒!
三、如何定位慢 SQL
說了這么多,我們如何去定位慢 SQL 呢?
3.1、開啟慢 SQL 監控
以 MySQL 為例,我們可以通過如下方式,查詢是否開啟慢 SQL 的監控,
show variables like 'slow_query_log%';
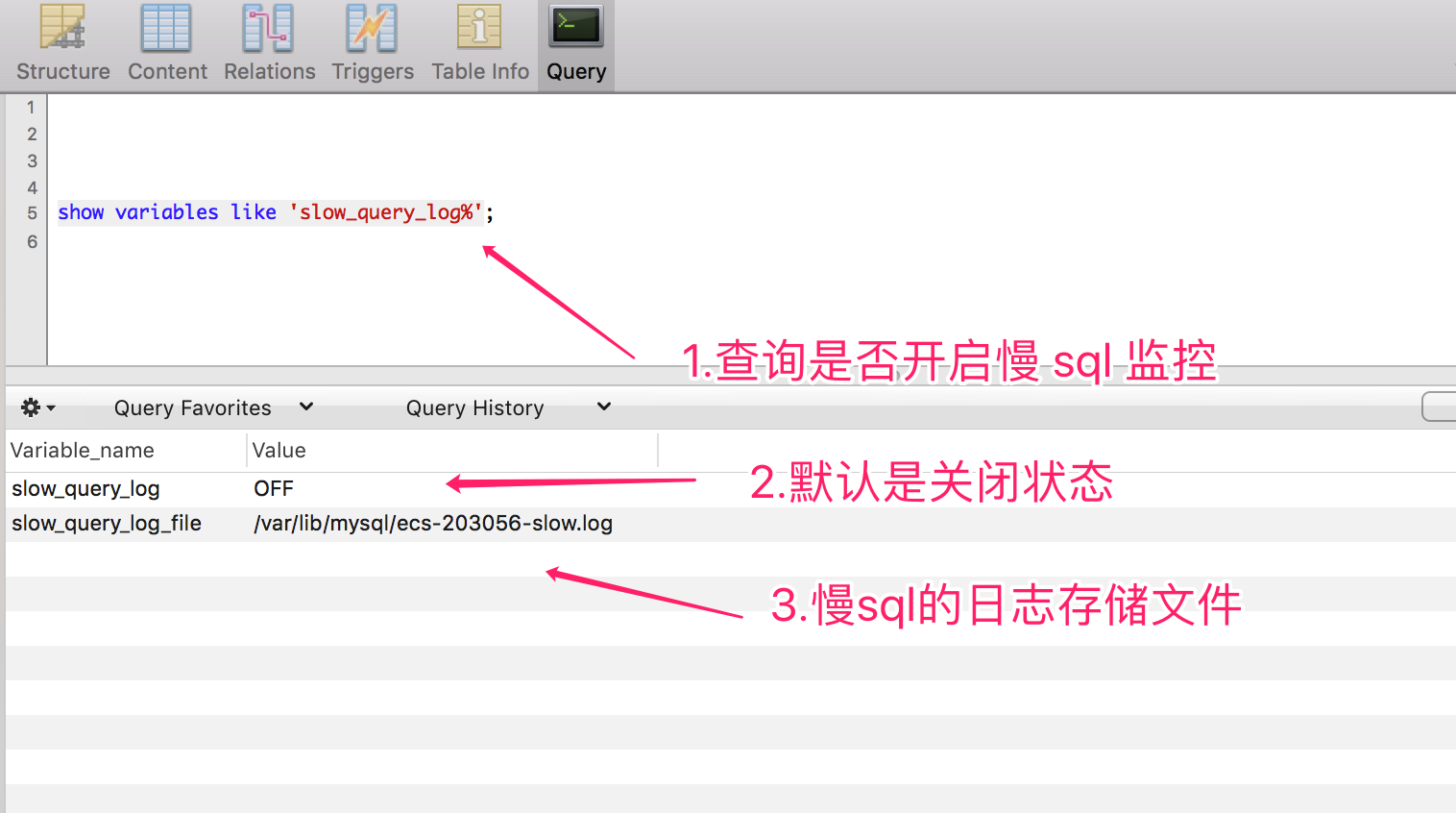
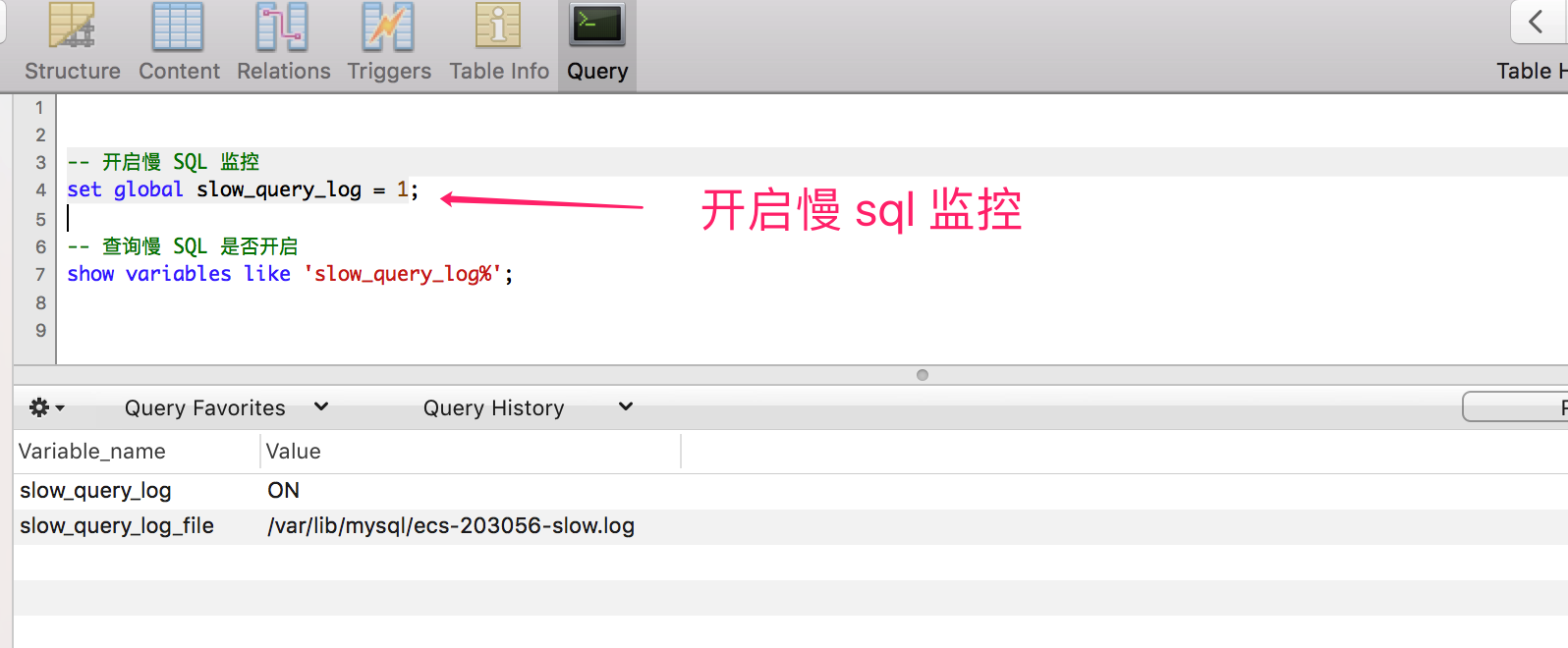
通過如下命令,開啟慢 SQL 監控,執行成功之后,客戶端需要重新連接才能生效,
-- 開啟慢 SQL 監控
set global slow_query_log = 1;
如果想關閉慢 SQL 監控,將其配置為0就可以了,
-- 關閉慢 SQL 監控
set global slow_query_log = 0;
需要特別注意的是,當服務器重啟之后,當前配置會失效!
3.2、配置慢 SQL 閥值
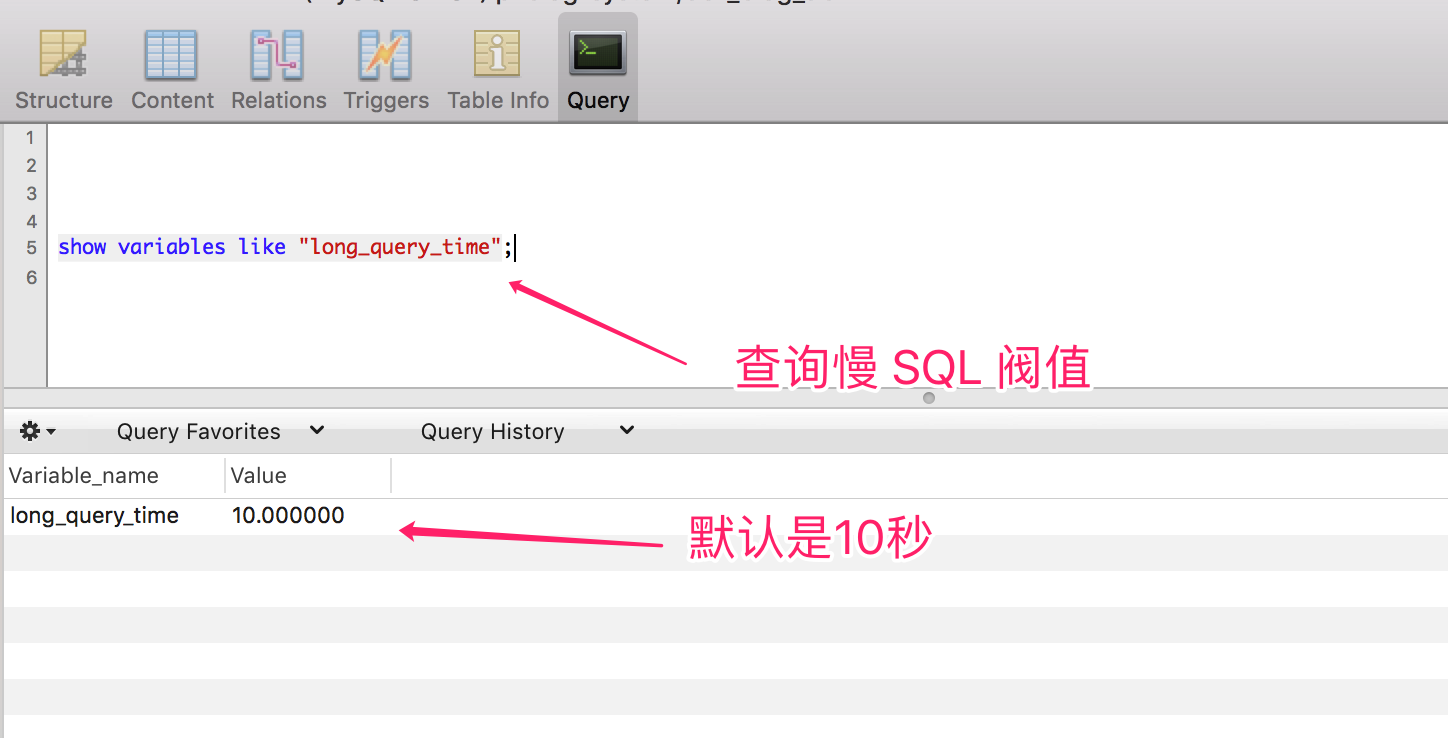
默認的慢 SQL 閥值是10秒,可以通過如下陳述句查詢慢 SQL 的閥值,
-- 查詢慢 SQL 的閥值
show variables like "long_query_time";
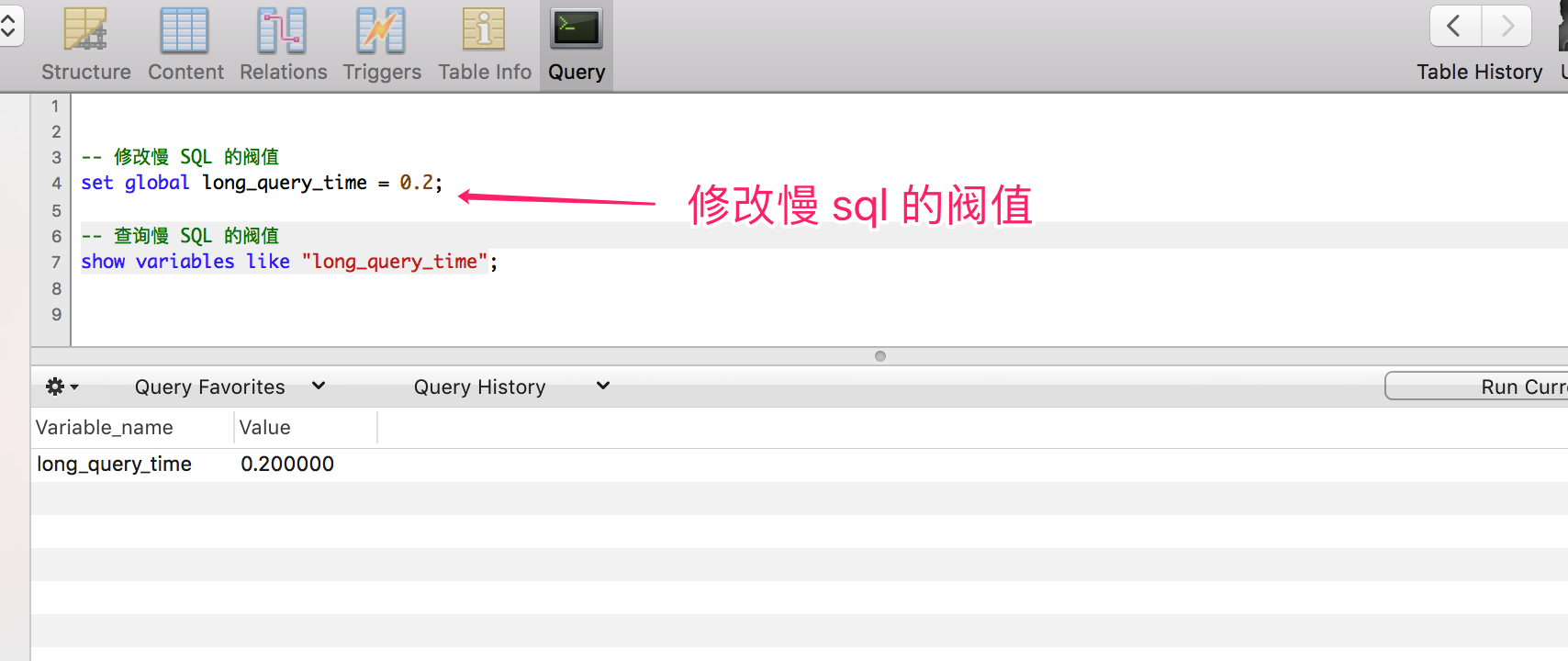
我們可以通過如下方式,將慢 SQL 閥值配置成0.2秒,
-- 修改慢 SQL 的閥值
set global long_query_time = 0.2;
然后,退出客戶端,重新連接服務器,就生效了!
與之類似,當服務器重啟之后,當前配置會失效!
3.3、永久開啟慢 SQL 監控
以上的操作,當服務器不重啟會一直有效,但是當服務器一單重啟之后,配置就會失效,如果想永久生效,可以通過修改全域組態檔my.cnf使之永久生效,
以 CentOS 為例,打開my.cnf組態檔,添加如下配置變數,
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/ecs-203056-slow.log
long_query_time = 1
重啟 mysql 服務器
systemctl restart mysqld
3.4、慢 SQL 監控測驗
初始化一張日志表,資料量在 10 萬左右就夠了,然后我們來執行 SQL,看看是不是被正常抓取到,
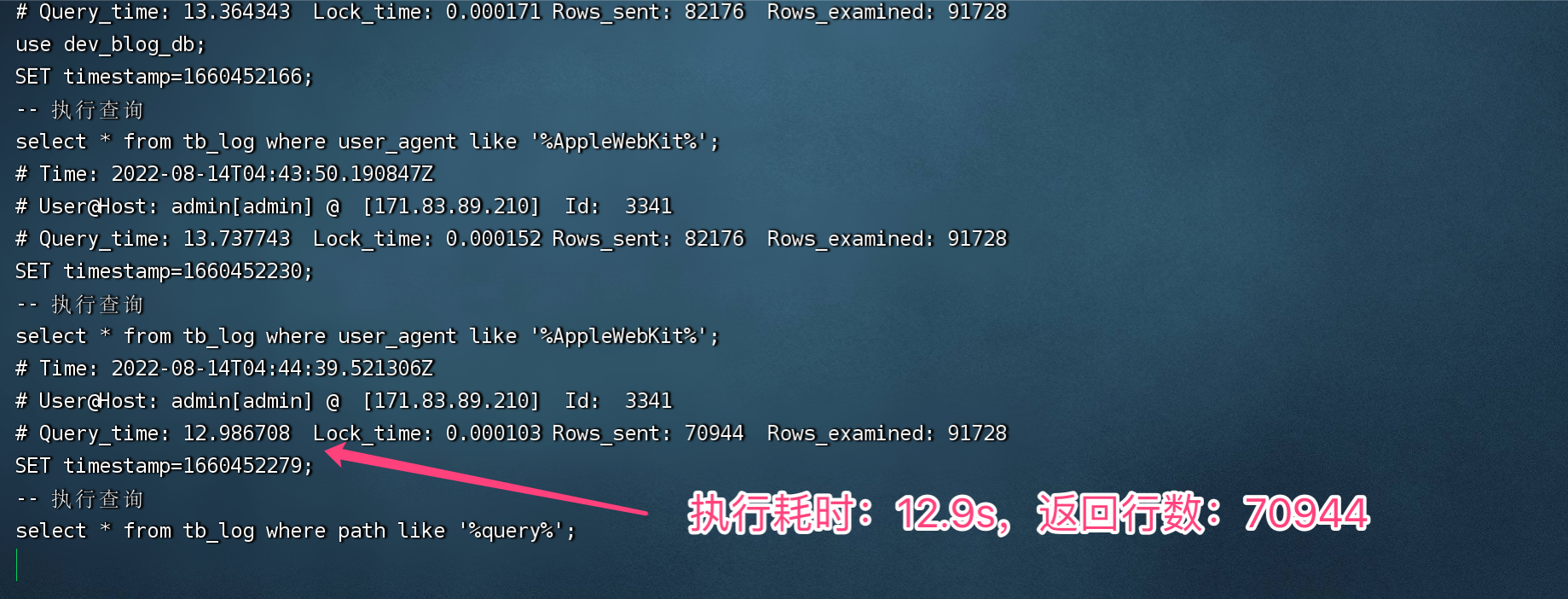
很清晰的看到,慢 SQL 已經被抓取記錄,
日志內容詳解:
- Time:表示客戶端查詢時間
- root[root]:表示客戶端查詢用戶和IP
- Query_time:表示查詢耗時
- Lock_time:表示等待 table lock 的時間,注意InnoDB的行鎖等待是不會反應在這里的
- Rows_sent:表示回傳了多少行記錄(結果集),
- Rows_examined:表示檢查了多少條記錄,
除此之外,我們還可以借助mysqldumpslow命令工具,分析慢 SQL 的資料情況,可以通過如下引數進行組合分析
-s 表示按何種方式排序,支持的引數如下
al: 平均鎖定時間
ar: 平均回傳記錄數
at: 平均查詢時間
c: 訪問次數
l: 鎖定時間
r: 回傳記錄
t: 查詢時間
-t NUM 回傳前面多少條的資料
-g PATTERN 后邊搭配一個正則匹配模式,大小寫不敏感
常見的用法如下:
- 查詢回傳記錄集最多的10個 SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/ecs-203056-slow.log
- 查詢訪問次數最多的10個SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/ecs-203056-slow.log
- 查詢按照時間排序的前10條里面含有左連接的查詢陳述句
mysqldumpslow -s t -t 10 -g "LEFT JOIN" /var/lib/mysql/ecs-203056-slow.log
四、慢 SQL 是怎么發生的
面對這種耗時巨長的 SQL,我們不禁會發出一個疑問,它是怎么發生的呢?
這得從 SQL 的執行程序說起,我們先簡單的看看下面這個圖,
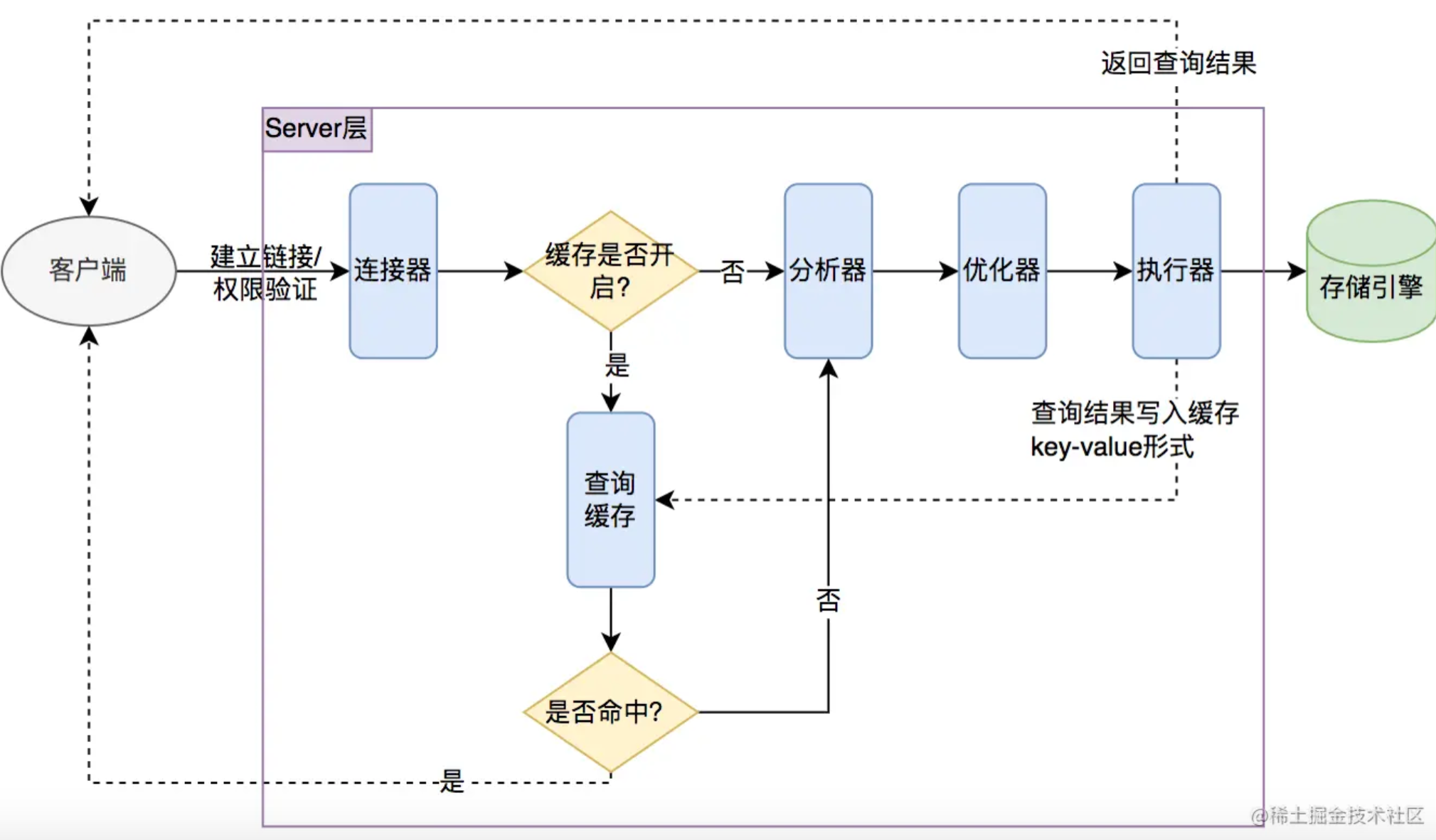
一條 SQL 陳述句執行時,總結起來大概分為以下幾個步驟:
- 1.若查詢快取打開則會優先查詢快取,若命中則直接回傳結果給客戶端,
- 2.若快取未命中,此時 MySQL 需要搞清楚這條陳述句需要做什么,則通過分析器進行詞法分析、語法分析,
- 3.搞清楚要做什么之后,MySQL 會通過優化器對 SQL 進行優化,生成一個最優的執行計劃
- 4.最后通過執行器與存盤引擎提供的介面進行互動,將結果回傳給客戶端
在 MySQL 執行程序中,優化器可能會對我們即將要執行的 SQL 進行改造,改造思路如下:
- 1.根據搜索條件,找出 SQL 中所有可能使用的索引
- 2.然后計算全表掃描的成本開銷
- 3.接著計算使用不同索引執行查詢的成本開銷
- 4.最后會對比各種執行方案的成本開銷,找出開銷值最小的那一個
其中影響成本開銷值的計算,主要是I/O成本和CPU成本這兩個指標,
從I/O成本視角看:
- 當表的資料量越大,需要的 I/O 次數也就越多
- 從磁盤讀取資料比從快取讀取資料,I/O 消耗的時間更多
- 全表掃描比通過索引快速查找,I/O 消耗的時間和次數更多
從CPU成本視角看:
- 當 SQL 中有排序、子查詢等復雜的操作時,CPU 需要先把資料存到臨時表中,再對資料進行加工,需要的 CPU 資源更多
- 全表掃描相比于通過索引快速查找,需要的 CPU 資源也更多
因此我們不難發現,在沒有開啟快取的情況下,當表的資料量越大,如果 SQL 又沒有走索引,很容易發生查詢慢的問題,
五、小結
本文主要圍繞慢 SQL 的定位和可能存在的風險進行了簡單的介紹,整篇介紹的算是一個入門級的知識,文章內容難免有些理解不到位的地方,歡迎網友留言指出!
由于篇幅的原因,我們會在下篇文章中介紹慢 SQL 的優化思路,
六、參考
1、稀土掘金 - 三個豬皮匠 - 慢SQL優化一點小思路
2、博客園 - 雪山上的蒲公英 - 慢 SQL 分析
3、博客園 - 慢查詢的危害
作者:程式員志哥
出處:www.pzblog.cn
資源:微信搜【Java極客技術】關注我,回復 【cccc】有我準備的一執行緒式必備計算機書籍、大廠面試資料和免費電子書, 希望可以幫助大家提升技術和能力,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/502063.html
標籤:其他
上一篇:mysql