前言
該文章中將會整理一些大資料中常見的檔案格式及壓縮演算法的理論知識,作為后期實踐的理論指導,理論+實踐才會更方便用這些檔案格式和壓縮演算法,
目前hadoop中常見的檔案格式有textfile、sequencefile、avro、rcfile、orcfile、parquet等,上述六種檔案格式又可以劃分為行式存盤(textfile、sequencefile、avro)和列式存盤(rcfile、orcfile、parquet),那么什么是行式存盤?什么又是列式存盤呢?
一、行式存盤及列式存盤
1.行式存盤
行式存盤就是每一行的所有資料存在一個block中,各個block之間連續存盤,
優點:
- 因為每一行的所有欄位都存在一起,因此對資料進行插入(INSERT)和修改(UPDATE)操作很方便,
- 整表查詢比較方便,可以很快將整張表組裝出來,
缺點:
- 查詢(SELECT)時如果涉及到某條資料,需要把該行資料所有內容都讀取到記憶體中,即使只SELECT一兩個欄位也要把整行資料都讀進來,讀取資料的時候硬碟尋址范圍很大,
- 要加速查詢的話需要建立索引,建立索引需要花費很多時間,
- 空值也要占固定的空間,
應用場景:
行式存盤用于存盤關系型資料,用于使用資料的時候需要經常用到資料之間的依賴關系的場景,即讀取的時候需要整行資料或者整行中大部分列的資料,需要經常用到插入、修改操作,比如存盤用戶的注冊資訊等,
2.列式存盤
列式存盤就是每一列的所有資料存在一起,不同列之間可以分開存盤,
優點:
- 每一列單獨存盤,因此僅SELECT個別列的時候,可以僅讀取需要的那幾個列,相當于為每一列都建立了索引,因此硬碟尋道范圍小,
- 資料壓縮,列式存盤的時候可以為每一列創建一個字典,存盤的時候就僅存盤數字編碼即可,降低了存盤空間需求
缺點:
- SELECT完成時,被選中的資料需要重新組裝,
- 插入(INSERT)和修改(UPDATE)操作比較麻煩,
應用場景:
列式存盤適合分布式資料庫和資料倉庫,適合于對大量資料進行統計分析,列與列之間關聯性不強,僅進行插入和讀取操作的場景,如網站流量統計、用戶行為分析等,
二、具體的檔案格式
看完具體的大類劃分,我們再看看具體的檔案格式,
1. TextFile
默認格式,存盤方式為行存盤,資料不做壓縮,磁盤開銷大,資料決議開銷大,可結合 Gzip、Bzip2 使用(系統自動檢查,執行查詢時自動解壓),但使用 這種方式,壓縮后的檔案不支持 split,Hive 不會對資料進行切分,從而無法對資料進行并行操作,并且在反序列化程序中,必須逐個字符判斷是不是分隔符和行結束符,因此反序列化開銷會比 SequenceFile 高幾十倍 ,
2. SequenceFile
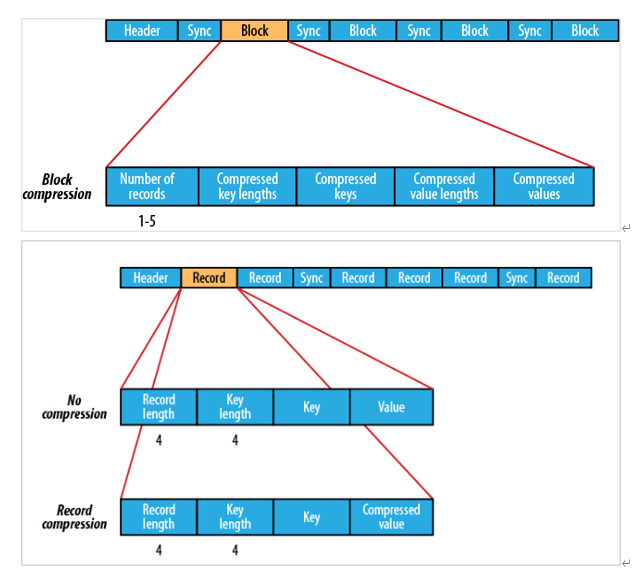
SequenceFile 是 Hadoop API 提供的一種二進制檔案支持,存盤方式為行存盤,其具有使用方便、可分割、可壓縮的特點,SequenceFile 支持三種壓縮選擇:NONE,RECORD,BLOCK,Record 壓縮率低,一般建議使用 BLOCK 壓縮,優勢是檔案和 hadoop api 中的 MapFile 是相互兼容的 ,
3. Avro
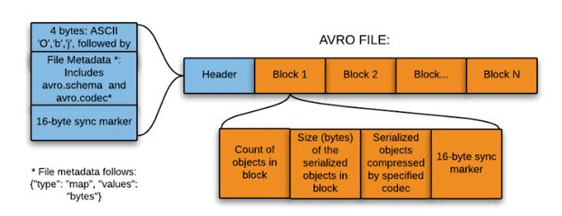
Avro格式是Hadoop的一種基于行的存盤格式,被廣泛用作序列化平臺,Avro格式以JSON格式存盤模式,使其易于被任何程式讀取和解釋,資料本身以二進制格式存盤,使其在Avro檔案中緊湊且高效,Avro格式是語言中立的資料序列化系統,它可以被多種語言處理(目前是C、C++、C#、Java、Python和Ruby),Avro格式的一個關鍵特性是對隨時間變化的資料模式的強大支持,即模式演變,Avro處理模式更改,例如缺少欄位、添加的欄位和更改的欄位,Avro格式提供了豐富的資料結構,例如,您可以創建包含陣列、列舉型別和子記錄的記錄,
4. RCFile
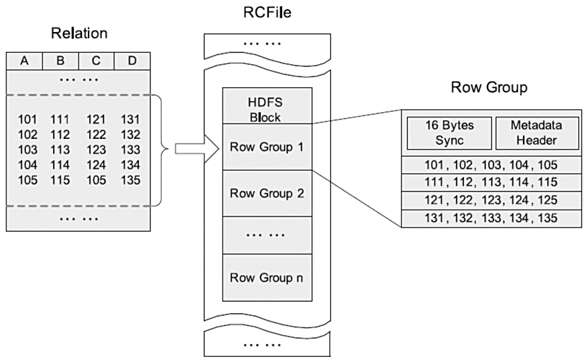
RCFile是為基于MapReduce的資料倉庫系統設計的資料存盤結構,它結合了行存盤和列存盤的優點,可以滿足快速資料加載和查詢,有效利用存盤空間以及適應高負載的需求,RCFile是由二進制鍵/值對組成的flat檔案,它與sequence file有很多相似之處,在數倉中執行分析時,這種面向列的存盤非常有用,當我們使用面向列的存盤型別時,執行分析很容易,缺點是RC不支持schema擴展,如果要添加新的列,則必須重寫檔案,這會降低操作效率,
5. OrcFile
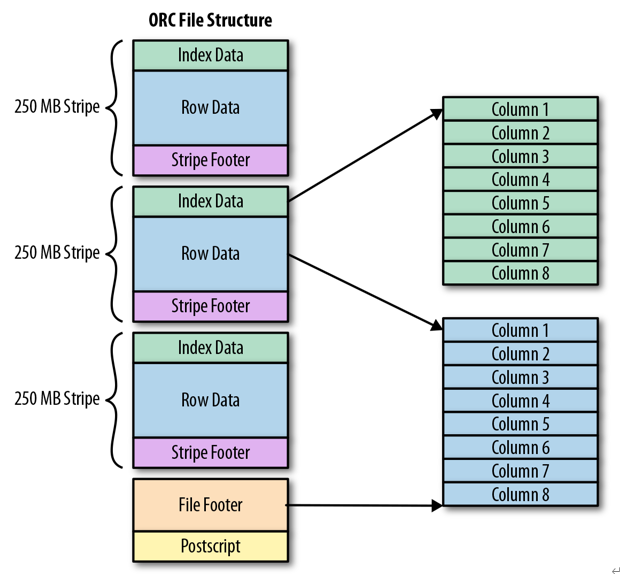
Apache ORC是Apache Hadoop生態系統面向列的開源資料存盤格式,它與Hadoop環境中的大多數計算框架兼容,ORC代表“優化行列”,它以比RC更為優化的方式存盤資料,提供了一種非常有效的方式來存盤關系資料,然后存盤RC檔案,ORC將原始資料的大小最多減少75%,資料處理的速度也提高了,
6. Parquet
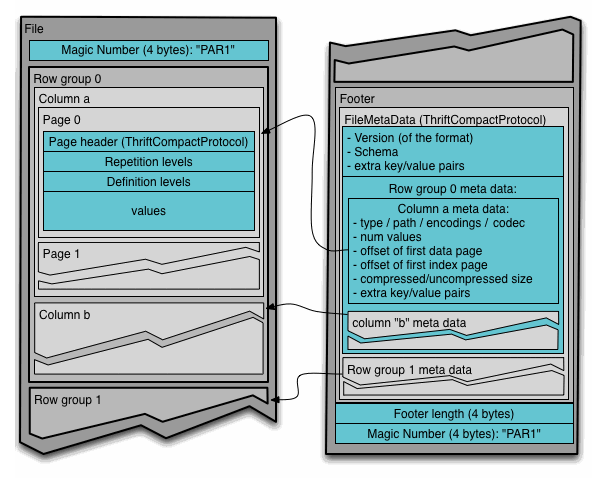
與以行方式存盤資料的傳統方法相比,Parquet檔案格式在存盤和性能方面更高效,這對于從“寬”(具有許多列)表中讀取特定列的查詢特別有用,因為只讀取需要的列,并且最小化 IO,Parquet的獨特功能之一是它也可以以柱狀方式存盤具有嵌套結構的資料,這意味著在 Parquet 檔案格式中,即使是嵌套欄位也可以單獨讀取,而無需讀取嵌套結構中的所有欄位,Parquet 格式使用記錄分解和組裝演算法以柱狀方式存盤嵌套結構,
三、壓縮演算法
|
壓縮格式 |
工具 |
演算法 |
檔案擴展名 |
是否可切分 |
|
default/deflate |
無 |
deflate |
.deflate |
否 |
|
gzip |
gzip |
deflate |
.gz |
否 |
|
bzip2 |
bzip2 |
bzip2 |
.bz2 |
是 |
|
lzo |
lzop |
lzo |
.lzo |
否 |
|
lz4 |
無 |
lz4 |
.lz4 |
否 |
|
snappy |
無 |
snappy |
.snappy |
否 |
四、總結
Hadoop支持的檔案格式和壓縮演算法非常多,每種檔案格式和壓縮演算法都有自己獨特的特點和一定的應用場景,下一期我們講講這些內容,并選擇合適的檔案格式和壓縮演算法組合,作為默認的檔案格式和壓縮演算法,
如有錯誤,不吝指正,
參考文章
- https://zhuanlan.zhihu.com/p/459444652
- https://www.51cto.com/article/615292.html
- https://segmentfault.com/a/1190000040823167
- https://blog.csdn.net/longyanchen/article/details/97160466
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/502417.html
標籤:其他
上一篇:Redis 主從復制