簡述
實時資料處理領域中,使用 Flink 方式,除了從日志服務訂閱埋點資料外,總離不開從關系型資料庫訂閱并處理相關業務資料,這時就需要監測并捕獲資料庫增量資料,將變更按發生的順序寫入到訊息中間件以供計算(或消費),
本文主要介紹如何通過 CloudCanal 快速構建一條高效穩定運行的 MySQL -> Kafka -> Flink 資料同步鏈路,
技術點
兼容多種常見訊息結構
CloudCanal 目前支持 Debezium Envelope (新增)、Canal、Aliyun DTS Avro 等多種流行訊息結構,對資料下游消費比較友好,
本次對 Debezium Envelope 訊息格式的支持,我們采用了一種輕量的方式做到完全兼容,充分利用 CloudCanal 增量組件,擴展資料序列化器 (EnvelopDeserialize),得到 Envelop 訊息并發送到 Kafka 中,
其中 Envelop 的訊息結構分為 Payload 和 Schema 兩部分
- Payload:存盤具體資料
- Schema:定義 Payload 的決議格式 (默認關閉)
{
"payload":{
"after":{
"column_1":"3",
...
},
"before":null,
"op":"c",
"source":{
"db":"kafka_test",
"table":"new_table"
"pos":110341861,
"ts_ms":1659614884026,
...
},
"ts_ms":1659614884026
},
"schema":{
"fields":[
{
"field":"after",
"fields":[
{
"field":"column_1",
"isPK":true,
"jdbType":4,
"type":"int(11)"
},
...
],
"type":"struct"
},
...
],
"type":"struct"
}
}
高度可視化的CDC
CDC 工具如 FlinkCDC、Maxwell、Debezium ... 各有特色,CloudCanal 相對這些產品,最大的特點是高度可視化,自動化,下表針對目標端為Kafka 的 CDC 簡要做了一些對比,
| CloudCanal | FlinkCDC | Maxwell | |
|---|---|---|---|
| 產品化 | 完備 | 基礎 | 無 |
| 同步物件配置 | 可視化 | 代碼 | 組態檔 |
| 封裝格式 | 多種常用格式 | 自定義 | JSON |
| 高可用 | 有 | 有 | 無 |
| 資料初始化(snapshot) | 實體級 | 實體級 | 單表 |
| 源端支持 | ORACLE,MySQL,SQLServer,MongoDB,PostgreSQL... | ORACLE,MySQL,SQLServer,MongoDB,PostgreSQL... | MySQL |
CloudCanal 在平衡性能的基礎上,提供多種關系型資料源的同步,以及反向同步;提供便捷的可視化操作、輕巧的資料源添加、輕便的引數配置;
提供多種常見的訊息格式,僅僅通過滑鼠點擊,就可以使用其他 CDC 的訊息格式的傳輸,讓資料處理變的例外的快捷、方便,
其中經過我們在相同環境的測驗下, CloudCanal 在高寫入的 MySQL 場景中,處理資料的效率表現的很出色,后續我們會繼續對 CloudCanal 進行優化,提升整體的性能,
綜上,相比與類似的 CDC 產品來說,CloudCanal 簡單輕巧并集成一體化的操作占據了很大的優勢,
無縫對接 Flink 流式計算
Flink 流式計算中不僅要訂閱日志服務器的日志埋點資訊,同樣需要業務資料庫中的資訊,通過 CDC 工具訂閱資料,能減少查詢對業務資料庫產生的壓力還能以流的形式傳輸,方便與日志服務器中的資料進行關聯處理,
實際開發中,可以將業務資料庫中的資訊提取過濾之后動態的放入 Hbase 中作為維度資料,方便相關聯的寬表進行關聯查詢;
也可以對資料進行開窗、分組、聚合,同樣也可以下沉到其他的 Kafka 消費者組中,實作資料的分層,
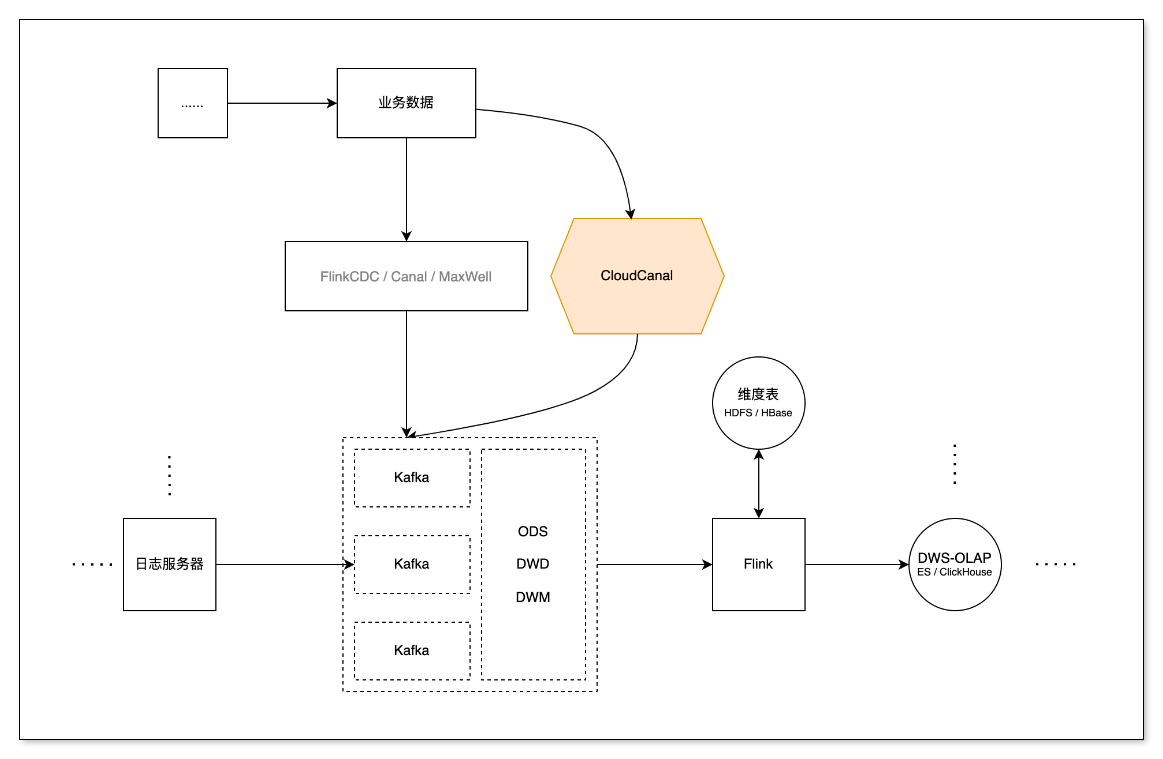
操作示例
前置條件
- 本例使用 Envelop 訊息格式,關系型資料庫 MySQL 為示例,展示 MySQL 對接 Flink 的 Demo
- 登陸 CloudCanal SaaS版,使用參見快速上手檔案
- 準備好 1 個 MySQL 實體,1 個 Kafka 實體(本例使用自己搭建的 MySQL 5.6,阿里云 Kafka 2.2)
- 準備好 Flink 消費端程式,配置好相關資訊:flink-demo 下載
- 登錄 CloudCanal 平臺,添加 Kafka,MySQL
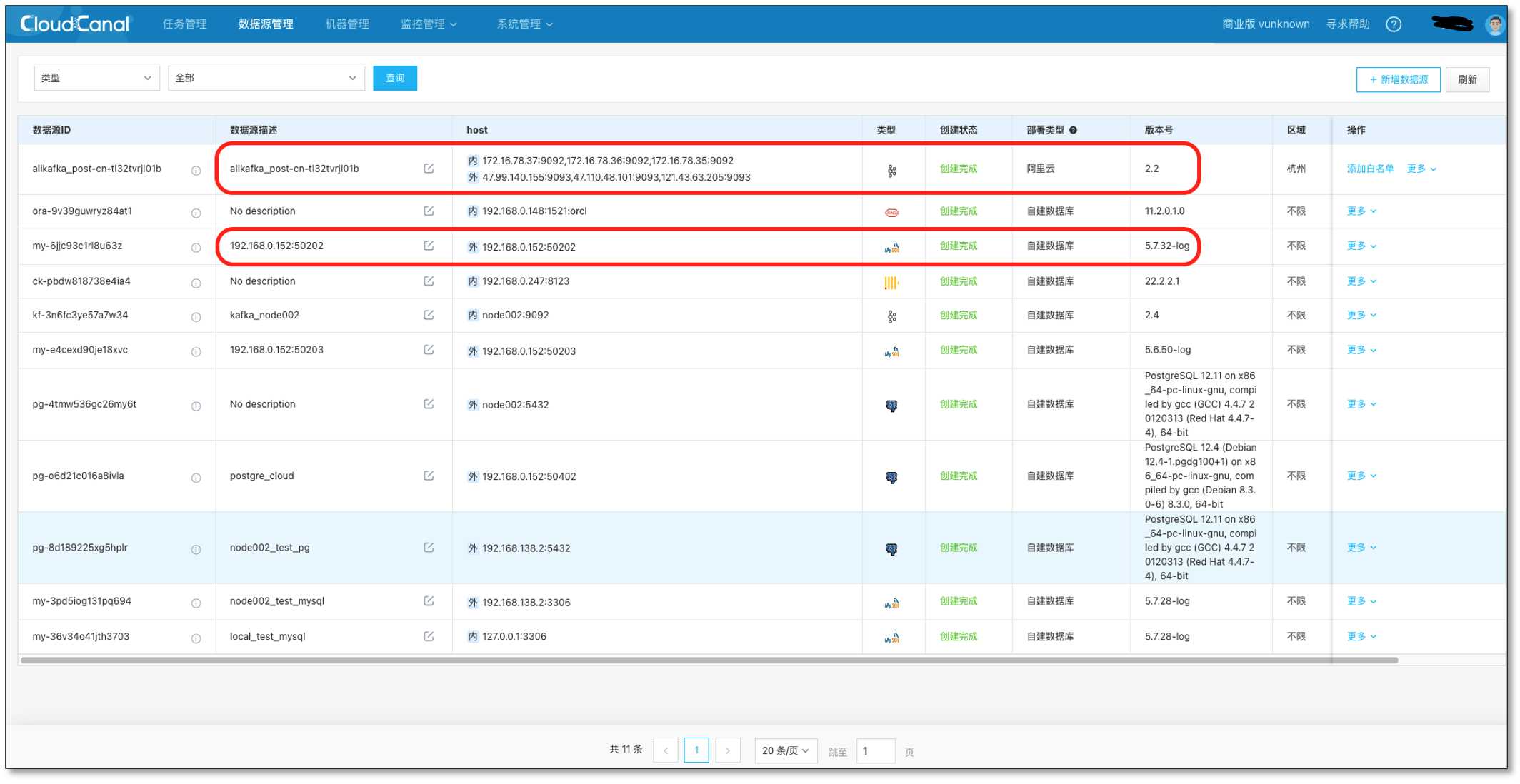
- Kafka 自定義一個主題 topic_1,并創建一條 MySQL -> Kafka 鏈路作為增量資料來源
任務創建
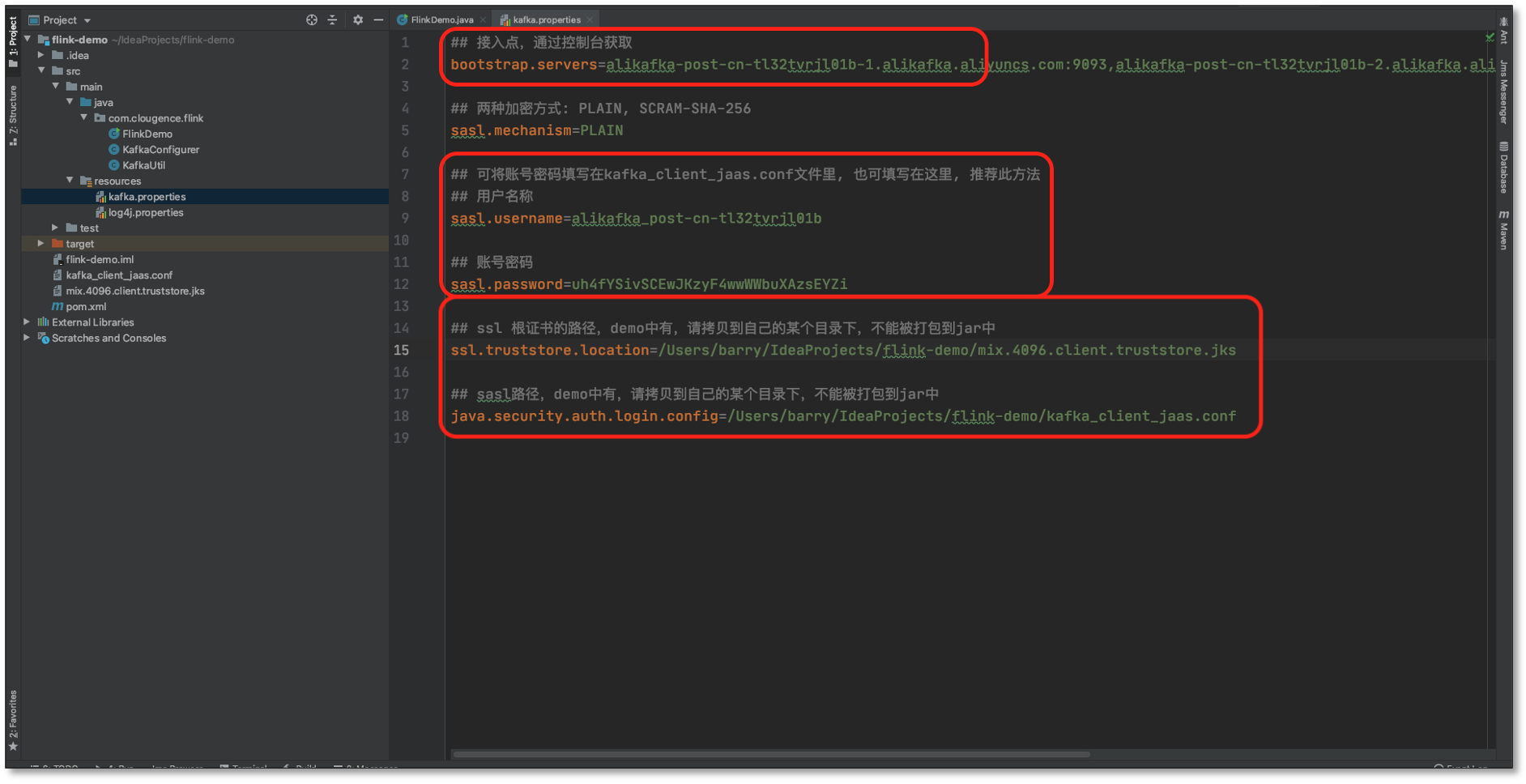
- 首先配置 **FlinkDemo 程式的 **阿里云 Kafka 相關資訊
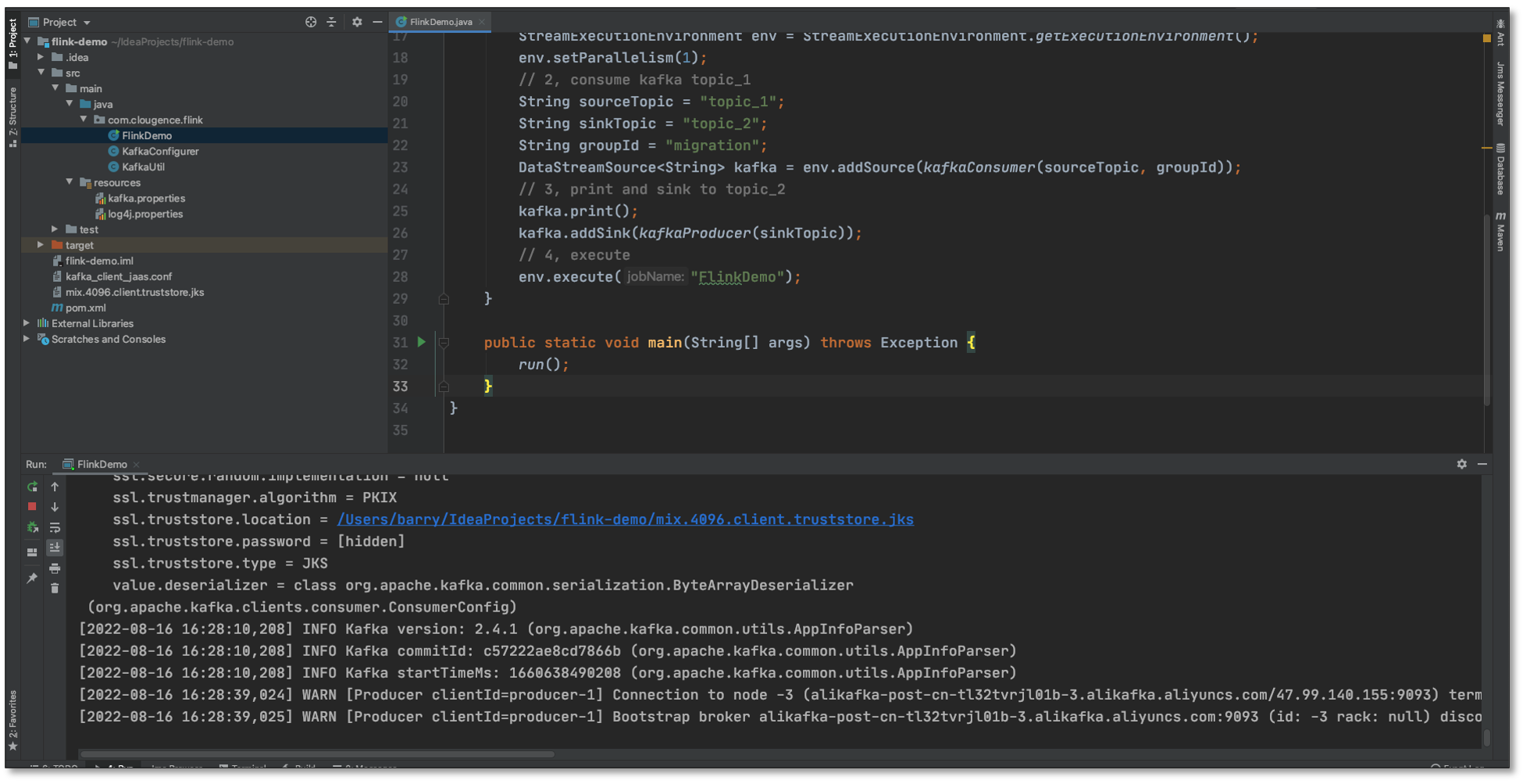
- 運行 FlinkDemo 程式,等待消費 MySQL 同步 Kafka 的資料(程式不要關閉)
- **任務管理 **-> **任務創建 **
- 測驗鏈接并選擇 源 和 目標 資料庫,**并選擇 DebeziumEnvelope 訊息格式,和 topic_1 主題 **(在阿里云里提前創建)
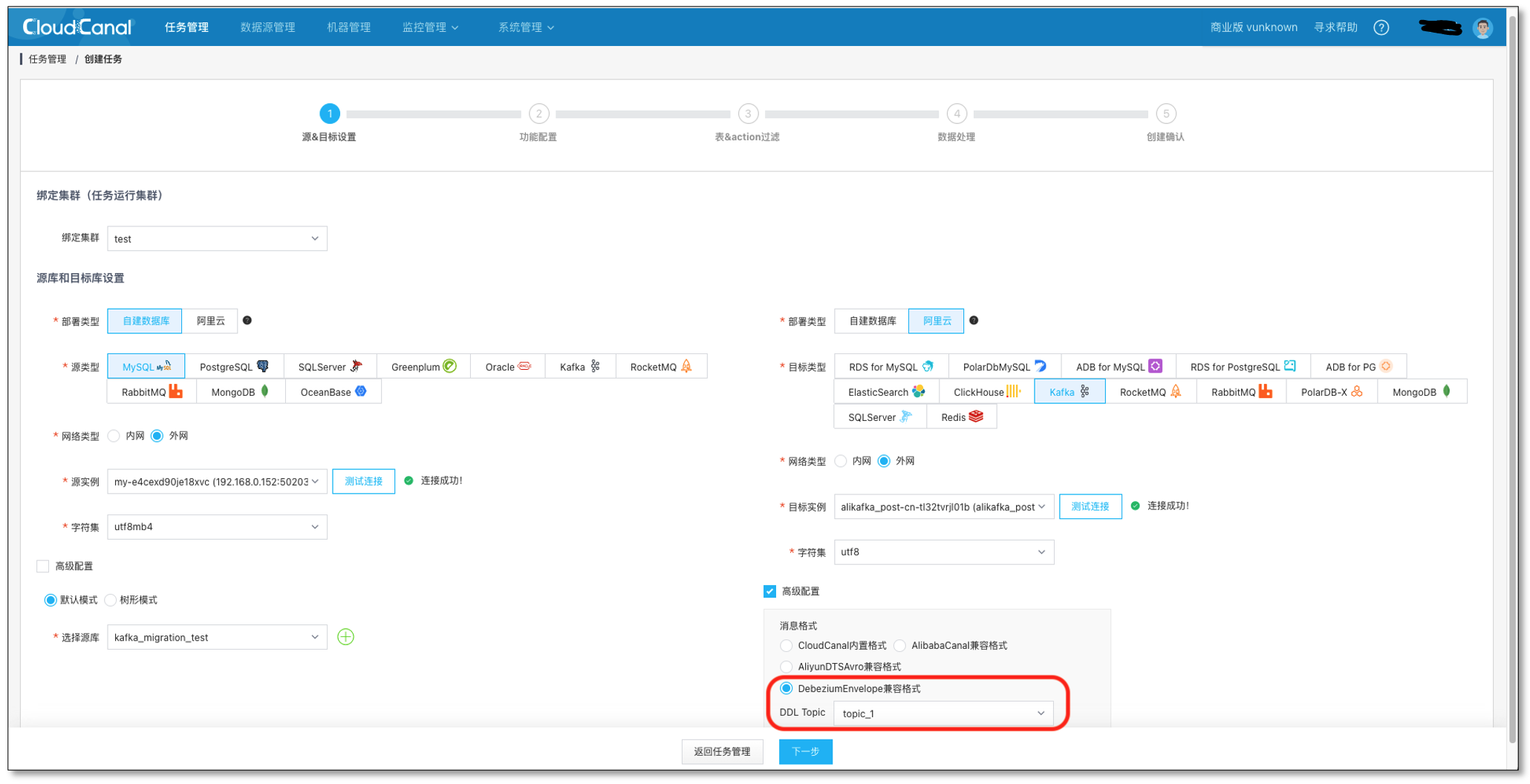
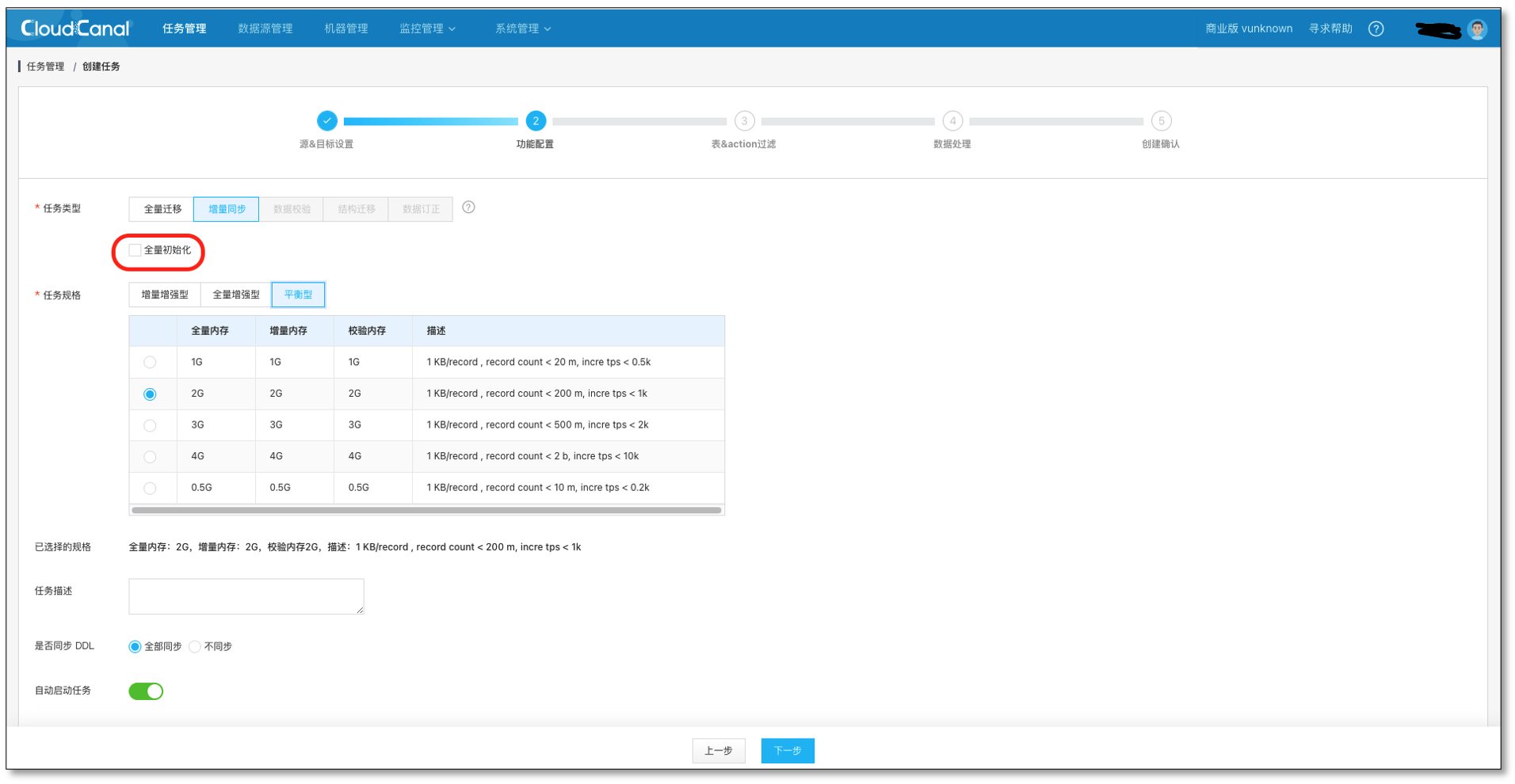
- 選擇 資料同步,不勾選 全量資料初始化,其他選項默認
- 選擇需要遷移同步的表 **table1 **和對應的 Kafka 主題 topic_1
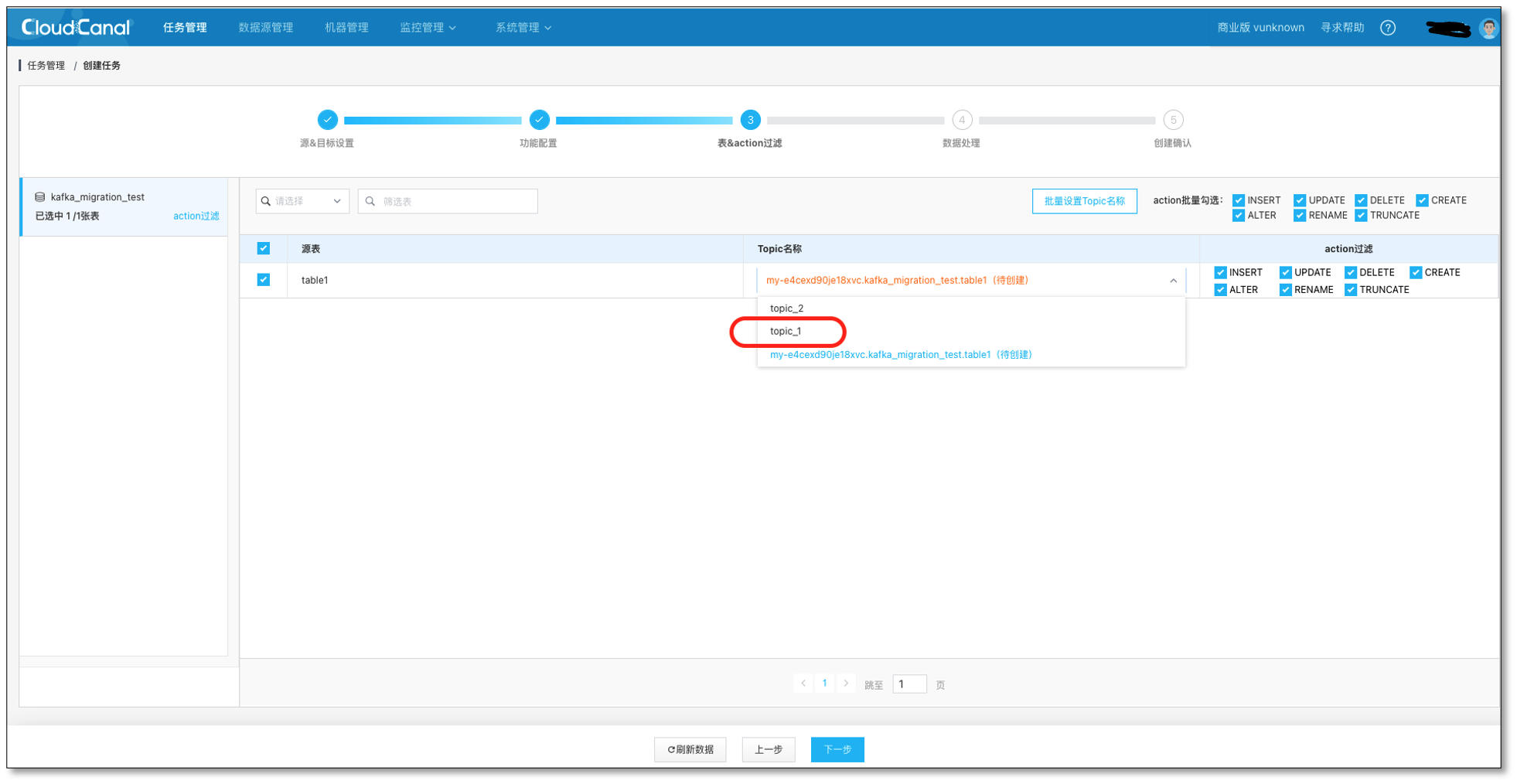
持續點擊下一步,并創建出資料同步任務,
Flink 消費資料
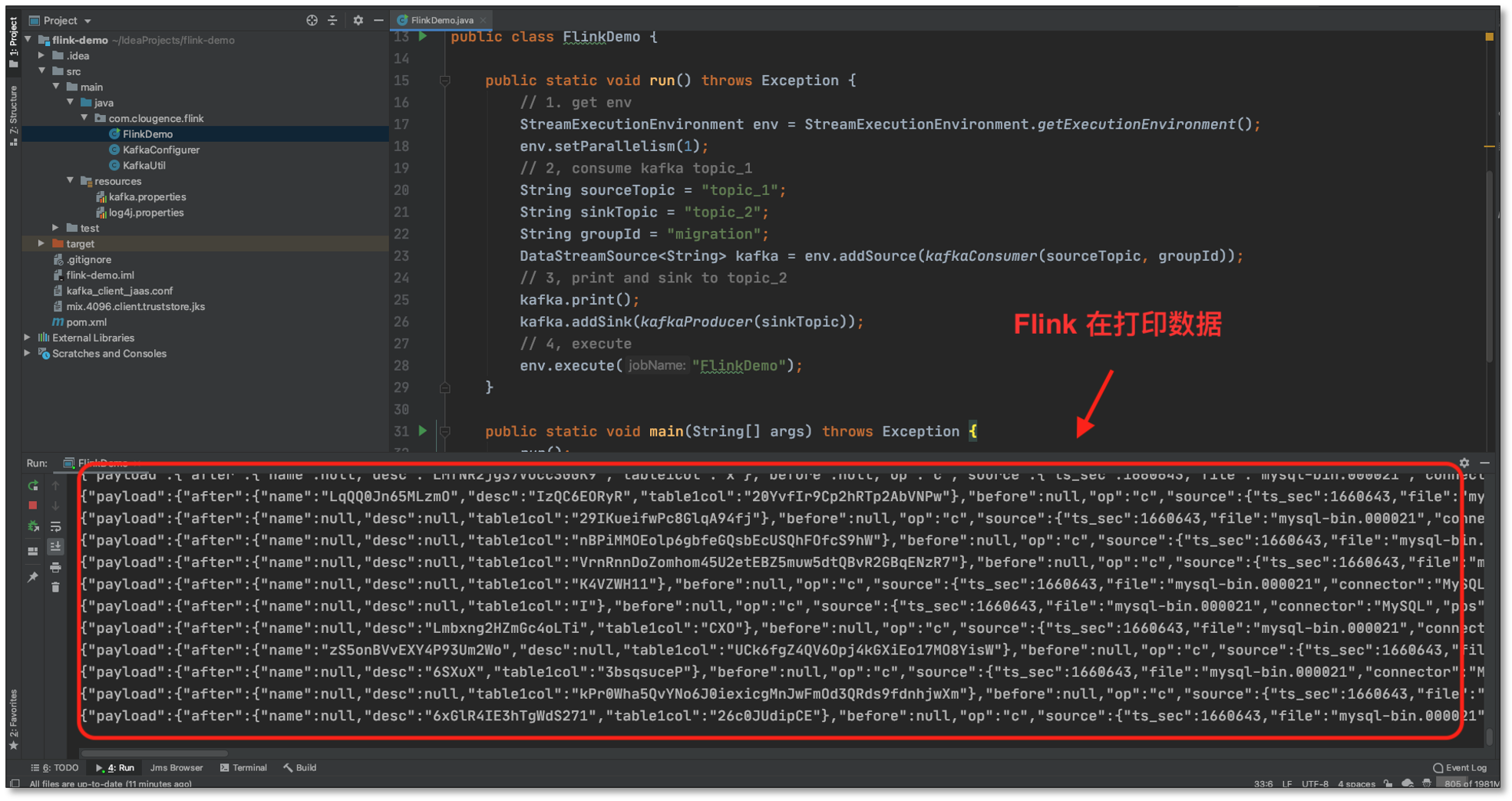
- 向 **MySQL 生成資料,MySQL **-> Kafka(topic_1) -> Flink
- FlinkDemo 接收到 Kafka(topic_1) 資料,下沉到 topic_2 主題,列印并輸出;這里 Flink 程式可以做更多的流式計算的操作,FlinkDemo 只是演示了最基本的資料傳輸案例,
常見問題
還支持哪些源端資料源呢?
目前開放 MySQL、Oracle,SQLServer,Postgres,MongoDB 到 Kafka,如果各位有需求,可以在社區反饋給我們,
支持 DDL 訊息同步嗎?
目前 關系型資料到 kafka 是支持 DDL 訊息的同步的,可以將 關系型資料庫 DDL 的變化同步到 Kafka 當中,
總結
本文簡單介紹了如何使用 CloudCanal 進行 MySQL -> Kafka -> Flink 資料遷移同步,各位讀者朋友,如果你覺得還不錯,請點贊、評論加轉發吧,
加入CloudCanal粉絲群掌握一手訊息和獲取更多福利,請添加我們小助手微信:suhuayue001
CloudCanal-免費好用的企業級資料同步工具,歡迎品鑒,
了解更多產品可以查看官方網站: http://www.clougence.com
CloudCanal社區:https://www.askcug.com/
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/503236.html
標籤:其他