打破資料邊界,是數字化時代常掛在嘴邊的一句話,資料的價值是在流動中體現的,資料應用也是如此,以往為了滿足開發、測驗、資料保護容災和資料分析的需要,我們不斷對資料進行復制、備份、遷移,因此資料遷移非常重要,
混合多云時代,用戶資料遷移需求與場景激增
今天我們來重點聊聊混合云時代中資料遷移,先來看看常見的幾種企業資料遷移的需求與場景:
-
傳統云化型:設備老舊,需要升級,硬體成本升級性價比不高,云上更經濟;
-
價格敏感型:綜合對比多家廠商價格,靈活選型采用成本最優方案;
-
災備驅動型:需要多云、異構云來架構自己的災備體系,保證資料的安全
-
游戲客戶:異地開服,服務不同地域的用戶,因各地網路質量不一致需要多云模式用于構建服務本地用戶的游戲服務器,
-
泛金融客戶:要符合金融安全政策的要求,需要資料的遷移
這些客戶都因系統和技術升級、業務的發展、以及安全合規等因素采用混合多云的方案,同時對其資料的遷移有著很高的訴求,在不同的業務模式和需求下也會面臨多種問題,
混合多云時代下,資料遷移的困境
資料庫的發展多樣性提升遷移門檻
混合多云時代,遷移是面臨的一大難題,其中資料安全遷移往往又是企業最關注的,提到資料遷移的困難,究其原因先粗略回顧下關系型資料庫到非關系型資料庫的發展,
關系型資料庫,是指采用了關系模型來組織資料的資料庫,關系模型是在1970年由IBM的研究員E.F.Codd博士首先提出的,在之后的幾十年中,關系模型的概念得到了充分的發展并逐漸成為主流,關系型資料庫具備事務一致性、讀寫實時性、結構化與規范化等特性,因而容易理解、使用方便、易于維護,在虛機時代,互聯網還未普及時它是最主流的資料庫,典型的代表有Oracle、Microsoft SQL Server、DB2、MySQL等,
但隨著互聯網的飛速發展,網站用戶并發高,海量資料的產生,傳統關系型資料庫已經不能滿足企業的資料存盤需求了,非關系型資料庫應勢而生,它高并發,讀寫能力強、榷訓資料結構一致性,使用更加靈活有良好的可擴展性等優勢逐漸成為了企業的首選,
NoSQL一詞首先是Carlo Strozzi在1998年提出來的,典型代表Redis, Amazon DynamoDB, Memcached,Microsoft Azure Cosmos DB等
在面對這兩種資料庫之間的遷移,關系型資料庫SQL RDBMS發展久,遷移生態工具齊全,且大部分資料庫產品都自帶遷移工具;而非關系NoSQL,資料定義更寬松,產品體積輕量,放棄了一致性校驗,導致某些資料結構濫用,提升了遷移難度,而遷移工具大部分開放給生態來做,由于發展時間較短,工具完善度不如RDBMS高,
廠商試圖“資料綁架”,使遷移雪上加霜
分析完關系型資料庫到非關系資料庫的發展,可以看到資料存盤結構本身已發生了巨大的變化,這從根因上已大幅提升了遷移的難度,而一些云廠商對資料庫的再次改造,且對關系型資料庫底層改造不透明,導致資料庫的復雜性大大加大,試圖用資料遷移成本高來長期系結客戶,更是令資料的遷移雪上加霜,
“個體差異”導致通用型解決方案缺失
不同的企業由于自身需求不同與使用場景的多樣性,每一個客戶,對我們來說都是一個新的案例,我們必須“量身定制”化服務,但在程序中我們也總結出幾類常見難點:
-
難點一:多節點資料庫遷移,節點數量不一致
-
難點二:原生產品跨版本問題,版本不一致且上下版本兼容性不夠好
-
難點三:快取類資料易失性更高
面臨挑戰,京東云破局遷移困境
下面通過實際案例和大家分享我們是如何破局遷移困境,幫助用戶解脫資料枷鎖的,
重大挑戰,臨危不亂/從容不迫
2019年京東物流為了實作其輕資產化、降低成本、升級架構的三大目的,將其ES開始由本地機房遷移到云上,依托京東云云搜索ES高可用、易擴展、近實時等特性,京東物流成功地將分揀中心自動化系統、冷鏈流程監控系統、開放訂單跟蹤系統等上百個系統遷移上云,
在遷移程序中京東云不僅提供了常規的停機遷移方案,還提供了特殊的不停機遷移方案,保證了物流業務不停服,不停機遷移方案如下:在云端創建新集群,將云上集群和用戶集群合并成一個大集群,利用Elasticsearch資料分布API(cluster.routing.allocation.exclude)將用戶集群中的索引資料遷移到云上集群的資料節點,最后將用戶集群和云上集群構成的大集群拆分,關閉用戶集群即可完成遷移,(采用這種方式須注意同時滿足以下兩個條件:用戶集群版本和云上集群版本相同;用戶集群所有節點和云上集群所有節點網路能夠互通,)
通過上述方法,很快就就完成了京東物流近百個系統的數百個集群、數千個節點資料上云作業,在此之上京東云還配套提供了一鍵報警等核心功能,對上云作業進行全天候、全方位的保障,
截止目前,京東物流已有超過90%的應用在公有云上部署了實體,去年11.11期間業務量超過日常三倍以上的情況下,整體運營平穩,
遷移利器,上云必備
關系型資料庫依然是各行業的主流應用之一,怎樣更快的將傳統關系型資料中的資料遷移上云也是很多行業用戶關心的,為此京東云特意打造了一款針對關系型資料庫的遷移工具——資料傳輸DTS,
資料傳輸DTS 提供實時資料流服務,支持資料遷移、資料訂閱和資料同步服務,可簡單方便的滿足資料上云、業務異步解耦、資料異地災備、業務系統資料流轉等業務場景,目前資料傳輸DTS支持MySQL、MariaDB、Percona、SQL Server、PostgreSQL等多種資料庫遷移,可以簡單快速地將本地自建資料庫遷移至京東云,源資料庫在遷移程序中可繼續正常運行,從而最大程度地減少應用程式的停機時間,
不斷突破,技術創新
某家在線廣告公司需要將Redis從自有機房遷移到云上,由于客戶系統承載著大量結算快取和業務快取所以要求在遷移程序中不能有業務中斷,當時有一些開源工具,但是不滿足要求,主要是由于版本問題,客戶用的Redis版本是4.0而當時開源的工具只支持3.28及以下版本,本著京東客戶業務為先的原則,和鼓勵創新的技術精神,我們思考,能不能為客戶自研一套工具,能夠Cover住Redis資料流轉大部分場景的通用工具,于是2019年7月redissyncer 1.0版本誕生,完成了資料源及目標校驗、原生集群同步、 大KV的拆解等基本功能,
1.0完后很快迎來了幾個客戶:
-
其一是互聯網行業用戶,Redis單實體,資料體量不大20Gb左右,我們通過啟動引數修復、調整每批次Value值等細節優化順利完成了遷移任務;
-
第二個用戶是游戲行業的用戶,用戶需要將自有IDC中的Redis遷移到京東云,在使用我們的產品之前,用戶自己找過若干開源產品但都不符合要求,由于用戶的實體數量較多,在了解過Redissyncer產品特性后,用戶決定使用我們的工具自行遷移,
貼近一線,無微不至
經過一個下午的培訓遠程培訓,用戶很快上手第一個實體遷移很順利,在接下來的幾天用戶通過我們的工具陸續完成遷移作業,并反饋中給予產品很高評價,并特意發來感謝信,

來自客戶的認可,是我們不斷向前的最大動力!
不斷打磨,精益求精
在剖析過更多客戶痛點與需求后, 2019年11月底,我們完成了2.0版本的升級,補充了同步模式拆分、斷點續傳、離線檔案加載、跨版本遷移、流式加載等功能,
很快2019年12月我們又迎來了一個金融用戶,用戶需要將原生Redis集群遷移到自研的Redis集群,目標集群節點數多大16*2即16對主從構成的集群,遷移程序很順利,經過準備15分鐘完成應用割接,
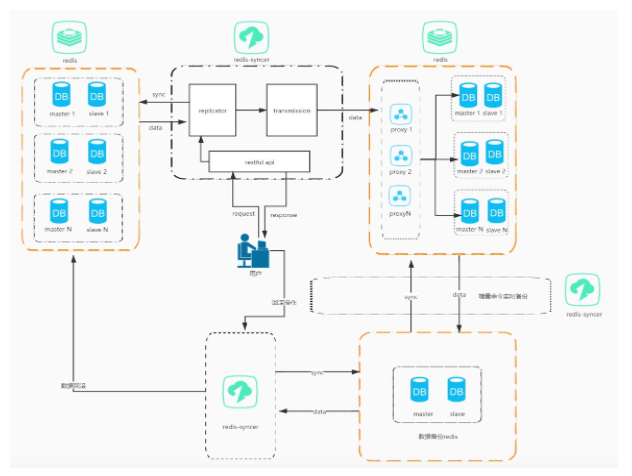
(遷移部署圖)
經過實際場景的打磨,我們陸續修復了一些測驗中很難遇到的bug,添加了一些新特性,使得產品不僅支持升級遷移同時支持降級遷移;為了提高用戶體驗,我們參考Redis、MySQL等優秀開源產品的方式做了一個命令列客戶端命名為redissyncer-cli,至此,完成了RedisSyncer3.X的升級,這個專案的體系建設基本上可以滿足Redis遷移同步場景中的大部分需求了,
不止于此,突破創新
起初,我們把RedisSyncer定位為一個Redis的同步工具,隨著開發和用戶側的實踐,我們下一步想把RedisSyncer打造成為具備企業級災備能力的Redis資料同步中間件,從工具到具備企業級災備能力還是有一定門檻的,所以下一步我們的作業重點是對軟體進行分布式改造,最終目標是在任意節點發生故障時任務可自動化持續,實作企業級災備能力的Redis資料同步中間件,
擁抱開源,包容開放
目前京東云已經積累了覆寫互聯網、游戲、金融、物流、零售等多場景領域的遷移經驗,隨著混合多云趨勢到來,我們深知用戶遷移之苦,也愿意以兼容開放的心態為客戶提供技術服務,真正做到把選擇權交給用戶,同時為了讓更多人享受技術帶來的便利,我們在今年決定將自研RedisSyncer完全開源(開源地址:https://github.com/TraceNature/redissyncer-server),將技識訓歸社區,給更多用戶和開發者帶來便利!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/503495.html
標籤:其它
上一篇:SQL中的排座位問題