編者按: Benchmarking 作為一個衡量標尺,可從不同的維度來客觀公正公平的評價相關產品,例如:對應資料測評而言,有 TPC-C、TPC-H,TP-DS 等等,現有的這些測評 TPC-X 標準(Benchmarking)真的適合現有的 OLTP&OLAP 混合型資料庫嗎?現在對于很多 HTAP 資料庫廠商來說,對外所發布的性能對比資料都是以 TPC-H 為基準,但是單方面或者說只看一個 TPC-H 真的能真實地反映出這些 HTAP 資料庫的指標嗎?這篇來自德國慕尼黑工業大學資料庫研究組的 Paper 就給大家介紹了一種專門針對 HTAP 資料庫測評的標準,真正的從 HTAP 的基礎出發,引出如何正確地評測一款 HTAP 資料庫產品,希望本文能夠給諸多的 HTAP 廠商起到拋磚引玉的作用,
當然,除了 TPC-H 之外,StoneDB 也會持續基于此類專門針對 HTAP 的 Benchmarking 上做出優化,我們后續會及時給社區的小伙伴們同步我們的最新進展,論文翻譯:王學姣,編輯:李明康
背景介紹
在正式開始介紹這篇論文前,我想先介紹一下這篇論文作者的背景,首先是,三位作者的單位慕尼黑工業大學(TMU),想必在DB組待過的同學應該不會陌生,著名的 HyPer 資料庫就是出自他們的手里,
HyPer 是一款高速主記憶體資料庫系統,可在不影響性能的前提下,同時進行聯機事務處理(OLTP)和聯機分析處理(OLAP),此外,它還能在同一個系統中對交易和分析進行統一處理,
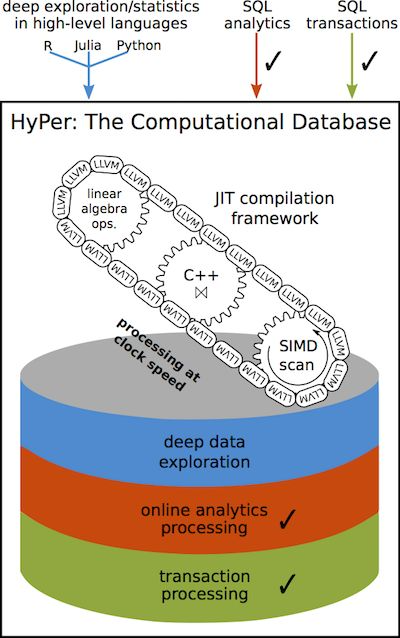
怎么樣?是不是聽著很耳熟?沒錯,在我們上一期的學術分享會也提到:StoneDB:深度干貨!一篇Paper帶您讀懂HTAP | StoneDB學術分享會第①期
清華大學李國良教授他們就把 HyPer 定義為第一代的 HTAP 資料庫,可以說,任何一家研究 HTAP 資料庫的企業,理解學習 Hyper 的架構還是有很有大幫助的,
讓我們回到 2010 年,那一年,谷歌大資料“三駕馬車“的論文最后一篇已經發表了四年,Hadoop 系列分化專案勢頭正猛;Oracle 收購了 Sun 公司間接獲得了 MySQL,引起軒然大波;放眼整個資料庫行業,關系型資料庫也迎來了 NoSQL 運動的又一波挑戰;OLTP 和 OLAP 在飛快發展,商業資料智能化分析的價值不斷被放大,適用于 HTAP 的市場業務場景需求也不斷增加,很多人提出了要做“Real-Time Business Intelligence(實時商業智能)”,在慕尼黑工業大學的資料庫研究組組長 Thomas Neumann 教授和同組的 Alfons Kemper 教授較早地意識到了這一點,他們認為使用傳統復雜的 ETL 鏈路處理方式會有天然的缺陷,包括不限于陳舊過時的資料(即資料新鮮度低)、系統的冗余和高昂的軟硬體維護費用等等,為了嘗試解決這些缺陷,他們正式發表了 HTAP 領域最經典的奠基論文之一《HyPer: Hybrid OLTP&OLAP High-Performance Database System》,這篇論文在資料庫學術界上影響深遠,除了 HTAP 概念的雛形,也提及了 In-memory、MVCC等關鍵技術,同時也標志著 HyPer 資料庫的正式誕生,
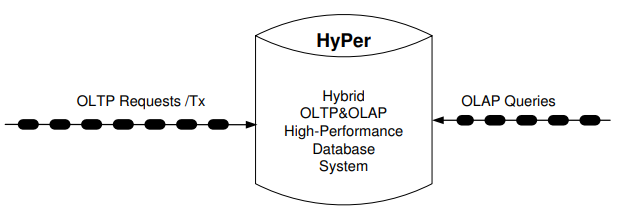
Hybrid OLTP&OLAP Database Architecture
而今天介紹的這篇《Benchmarking Hybrid OLTP&OLAP Database Systems》,正是由這兩位教授和他們的博士研究生 Florian Funke 共同發表的,當然,那個時候 HTAP 的概念還沒有提出來,他們在文中用的都是 “OLTP&OLAP 資料庫系統”,此文發表于2011年,同年6月他們還發表了一篇《The mixed workload CH-benCHmark》,也是講的 HTAP 資料庫基準測驗,同樣非常經典,值得一讀,不得不說,人家這么搞資料庫還是厲害,頭一年整出個資料庫類別,第二年這個類別的資料庫怎么評測都給你整的明明白白,出招快準狠就是這樣,
摘要
最近有這么一個操作型或實時商業智能(business intelligence,BI)的案例,在操作型 BI 場景下, OLTP 資料庫和 OLAP 資料倉庫分離的傳統架構存在嚴重的延時,為解決這一問題,OLTP&OLAP 資料庫系統正在緊鑼密鼓地開發中,第一代 OLTP&OLAP 混合型資料庫系統的出現要求有能夠衡量其性能的工具,
當前市場中已經存在一些分別針對 OLTP 和 OLAP 作業負載廣泛使用的標準化基準,但是卻沒有針對 OLTP 和 OLAP 混合負載的基準,因此,我們基于針對 OLTP 負載的 TPC-C 基準和針對 OLAP 負載的 TPC-H 基準,定義了一個可以測驗 OLTP 和 OLAP 混合負載的基準:TPC-CH,TPC-CH 基準執行了如下混合作業負載:基于 TPC-C 的訂單輸入處理的事務性作業負載,以及基于該銷售資料庫的對應的 TPC-H 等效 OLAP 查詢套件,派生于最廣泛使用的 TPC 基準,TPC-CH 基準產生的結果與混合型系統和傳統的單作業負載系統具有很高的可比性,因此,我們能夠將我們的(或其他的)OLTP&OLAP 混合型資料庫系統同 OLTP 系統(如 VoltDB)的 OLTP 性能和OLAP 系統的 OLAP 性能進行比較,
1. 簡介
在線事務處理(online transaction processing,OLTP)和在線分析處理(online analytical processing,OLAP)這兩個領域對資料庫架構提出了不同的挑戰,事務通常是短期運行的,大多涉及選擇性很強的資料訪問;而分析查詢通常是長期運行的,大多需要掃描絕大部分資料,因此,具有高關鍵任務事務率的客戶目前只能操作兩個獨立的系統:一個操作型資料庫用于處理事務,一個資料倉庫用于分析查詢,資料倉庫定期從 OLTP 系統中同步更新資料,并將最新資料轉換為易于分析的模型,人們也嘗試過在操作型系統中直接執行分析處理,但是這樣做帶來了難以接受的事務處理性能損耗【DHKK97】,
雖然這種資料分級(data staging)方法允許針對各自的作業負載對每個系統進行調優,但存在以下幾個固有的缺點: 必須購買和維護兩套軟體和硬體系統,根據資料分級實施情況,可能需要增加額外的系統,所有系統都必須存盤相同資料的冗余副本,但最重要的是,用于分析的資料并非最新資料,而是資料倉庫中的陳舊快照,
近期有如下一個實時 BI 的案例,SAP 的聯合創始人 Hasso Plattner【Pla09】發表了自己對當前 OLTP 和 OLAP 分離的現狀的看法,并表示對市場更重視 OLTP 而感到遺憾,他強調了 OLAP 在戰略管理中的必要性,并將實時分析對管理的預期影響與互聯網搜索引擎對世界的影響進行了對比, 實時 BI 推動了新的資料庫架構的誕生,這些新的資料庫架構通常以記憶體(in-memory)技術為基礎,如用于運營報告的行列混合存盤 OLTP 資料庫架構【SBKZ08,BHF09,KGT+10】和 HyPer【KN11】,它們使用一個系統來處理兩種作業負載,從而消除了資料分級的缺點,
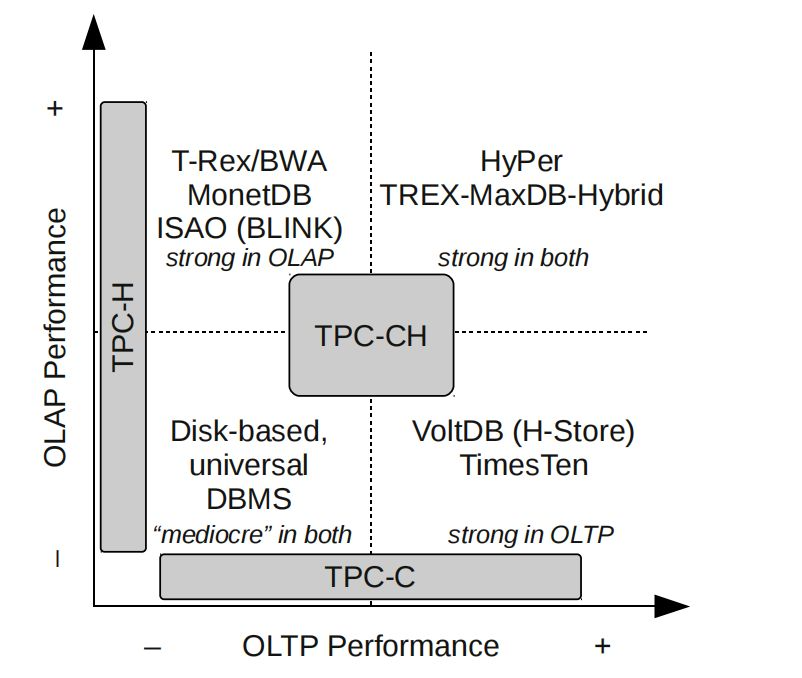
圖1:DBMS 分類以及各分類的測驗基準
不同的策略看起來可以在頻繁的插入和更新與長時間運行的 BI 查詢尋求平衡點:由交易觸發的修改可以作為增量資料收集起來,并定期合并到作為查詢基礎的主資料集中【KGT+10】,或者,可以在 DBMS 上開發支持版本控制功能,從而實作基于最新資料的事務處理與基于版本化資料快照執行的查詢之間的隔離,
這種新型 DBMS 的產生要求能分析其性能的方法,混合系統之間需要進行對比,以便對不同的實作策略進行比較,它們還必須與傳統的通用 DBMS 和單作業負載 DBMS 進行比較,以證明其在性能和資源消耗方面的競爭力,
我們提出了 TPC-CH,這是一個旨在為所有型別的系統生成高度可比結果的測驗基準(參見圖1),下一章評價了各相關基準,第3章描述了 TPC-CH 的設計,第4章描述了我們用于測驗的系統,第5章提供了各型別 DBMS 代表的設定以及測驗結果,第6章對本論文內容進行了總結,
2. 相關作業
TPC(Transaction Processing Performance Council,事務處理性能委員會)指定了在工業界和學術界廣泛使用的基準來測量資料庫系統的性能特征,TPC-C 及其后繼產品 TPC-E 模擬了 OLTP 作業負載,TPC-C 中使用的模型由圍繞產品或服務的管理、銷售和分銷的九個表(relation)和五個事務組成,資料庫的初始資料隨機產生,隨著新訂單的處理而更新,TPC-E 模擬了一家經紀公司的作業負載,它有一個更復雜的模型和偽真實的內容,用來更好地匹配實際的客戶資料,但是,與 TPC-E 相比,TPC-C 的使用更為普遍【Tra10c,Tra10d】,因此具有更好的可比性,
TPC-H 是 TPC 目前唯一活躍于市場上的決策支持基準,它模擬了類似于 TPC-C 的業務場景中的分析作業負載,該基準包含8個表以及能夠通過這8個表得到預期結果的22個查詢,它的后繼產品 TPC-DS 將采用星形模型、包含大約100個決策支持查詢和填充資料庫的 ETL 程序描述,但是,TPC-DS 目前尚未正式完成,
注意,通過簡單地使用兩個 TPC 模型(一個用于 OLTP,一個用于 OLAP)為混合型 DBMS 構建一個基準并不能產生有意義的結果,這樣的基準無法洞察系統如何處理其最具挑戰性的任務: 即如何并發處理對同一資料集事務和分析查詢,
在線事務處理(CBTR)綜合基準【BKS08】旨在衡量由 OLTP 和運營報告組成的作業負載的影響,CBTR 沒有結合現有的標準化基準,而是使用了一個企業的真實資料,作者提到了資料生成器的概念,從而能夠產生系統間可比較的結果,然而,CBTR 的重點似乎是為了某個企業的特定用例來對不同的資料庫系統進行比較,
3. 基準設計
我們設計 TPC-CH 的首要目標是可比性,因此,我們將 TPC-C 和 TPC-H 進行了結合,這兩個基準已經得到了廣泛的使用并得到了市場的認可,且能夠快速實施,并且二者在設計上擁有足夠高的相似度,從而保證了可比性,
TPC-CH 由未經修改的 TPC-C 模型和事務、以及 TPC-H 查詢的改編版本構成,由于這兩個基準的模型(參見圖2)都模擬了“必須管理、銷售或分發產品或服務”的業務【Tra10a,Tra10b】,它們之間有一些相似之處,兩個模型都包含ORDER(S) 和 CUSTOMER 表,此外,ORDER-LINE(TPC-C)和 LINEITEM(TPC-H)模型物體是 ORDER(S) 的子物體,因此彼此相似,
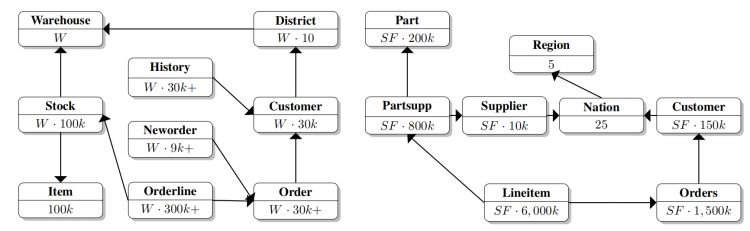
圖2:TPC-C 和 TPC-H 的模型
TPC-CH 保持所有 TPC-C 物體和關系完全不變,并集成了 TPC-H 模型中的 SUPPLIER、REGION 和 NATION 表,這些表在 TPC-H 查詢中頻繁使用,并允許以非侵入的方式集成到 TPC-C 模型中,SUPPLIER 包含固定數量(10,000條)的條目,因此,STOCK 中的一條記錄可以通過 STOCK.S I ID × STOCK.S W ID mod 10, 000 = SUPPLIER.SU SUPPKEY 與其唯一的供應商(SUPPLIER 表中對應記錄)關聯起來,
TPC-C 中的原始 CUSTOMER 表不包含參考自 NATION 表的外鍵,我們并沒有改變原始模型,從而保持了與現有 TPC-C 的兼容性,所以外鍵是從欄位 C STATE 的第一個字符開始計算的,TPC-C 規定第一個字符可以有62個不同的值(即大寫字母、小寫字母、數字),因此我們選擇了62個國家來填充 NATION,根據 TPC-H 規范,主鍵 N NATIONKEY 是一個識別符號,它的值被規定,從而使得與這些值相關聯的 ASCII 值是一個字母或數字,即 N NATIONKEY ∈ [48, 57]∪[65, 90]∪[97. 122],因此,不需要額外的計算來跳過 ASCII 碼中數字、大寫字母和小寫字母之間的間隔,不支持從字符轉換到 ASCII 碼的資料庫系統可能會偏離 TPC-H 模式,使用單個字符作為 NATION 的主鍵,REGION 包含國家的五個地區,新表之間的關系使用簡單的外鍵欄位來建模:NATION.N REGIONKEY 和 SUPPLIER.SU NATIONKEY,
3.1 交易和查詢
如圖4中的概述所示,該作業負載由五個原始 TPC-C 事務和22個來自 TPC-H 的查詢組成,由于 TPC-C 模型是 TPC-CH 模型的子集,因此這5個原始事務可以直接執行,無需修改:
New-Order 該事務將一個帶有多行資料的訂單輸入至資料庫中,
對于每行資料,99%的情況下,供應倉庫是主倉庫,主倉庫是固定的,其 ID 與一個終端相連,為了模擬用戶資料輸入錯誤,1%的事務失敗并觸發回滾:
- Payment:該事務更新客戶的賬號余額,15%的情況下,客戶是從一個隨機的遠程倉庫中選擇的,在另外85%的情況下,客戶與主倉庫相關聯,在60%的情況下,客戶是按姓氏選擇的,其他情況下則是按三要素鍵(three-component key)進行選擇的,
- Order-Status:該只讀事務報告客戶最后一個訂單的狀態,60%的情況下,客戶是按姓氏選擇的,在其他情況下,客戶按照客戶 ID 選擇,所選客戶始終與主倉庫相關聯,
- Delivery:該事務一次交付10個訂單,所有訂單都與主倉庫相關聯,
- Stock-Level:該只讀事務只對主倉庫進行操作,并回傳那些最近有售賣記錄且庫存水平低于閾值的庫存商品的數量,
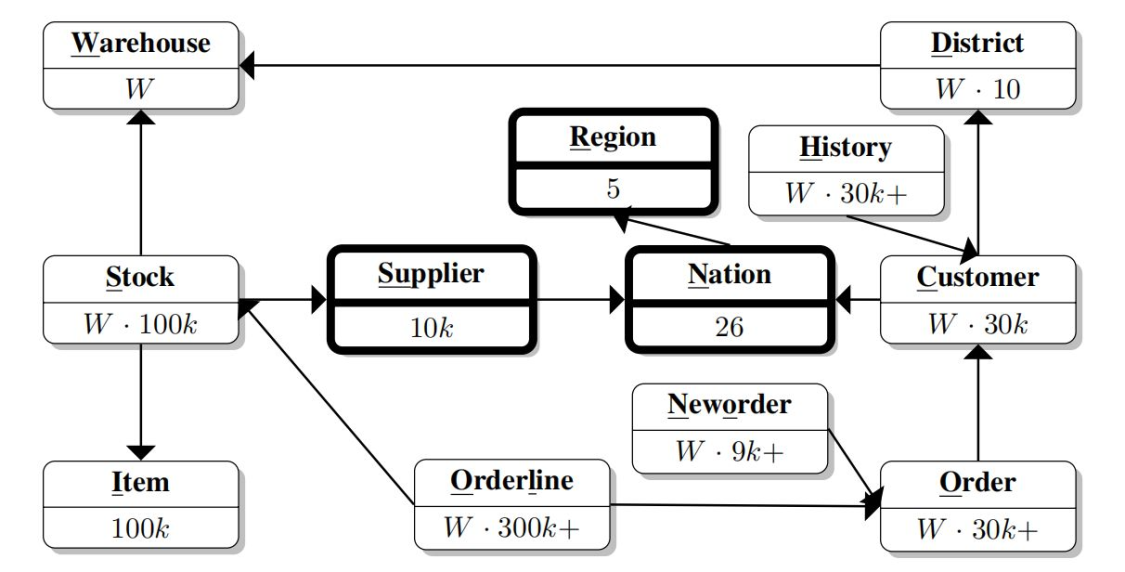
圖3:TPC-CH 模型加粗顯示部分為源自 TPC-H 的物體
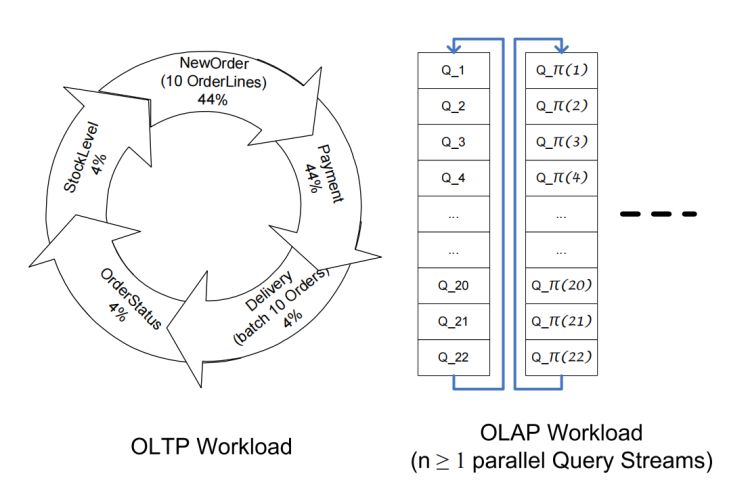
圖4:基準概述: 針對相同資料進行 OLTP 和 OLAP
TPC-CH 與其底層的 TPC-C 基準不同,因為它不模擬終端,并且在沒有任何思考時間的情況下生成客戶端請求,正如【Vola】所提議的,從而可以在相對較小的資料庫配置上實作非常高的事務率,TPC-CH 中的事務與 TPC-C 中的事務是相同的,因此 TPC-CH 的結果可直接與做了同樣修改的 TPC-C 的結果進行比較,例如 VoltDB【Vola】,此外,這些修改可以很容易地應用于現有的 TPC-C 工具,從而產生的結果與 TPC-CH 兼容,
對于作業負載中的 OLAP 部分,我們將 TPC-H 中的22個查詢應用到了 TPC-CH 模式中,在修改這些查詢以使之符合 TPC-CH 模型的程序的同時,我們也確保修改后的查詢保留了它們的業務語意和語法結構,例如,查詢5列出了通過本地供應商獲得的收入(請見Listing 1 和 Listing 2),這兩個查詢將相似的表連接起來,具有相似的選擇標準,并執行求和、分組和排序操作,
Listing 1: TPC-CH 查詢5
SELECT n_name, SUM(ol_amount) AS revenue
FROM customer, "order", orderline, stock, supplier, nation, region
WHERE c_id=o_c_id AND c_w_id=o_w_id AND c_d_id=o_d_id
AND ol_o_id=o_id AND ol_w_id=o_w_id AND ol_d_id=o_d_id
AND ol_w_id=s_w_id AND ol_i_id=s_i_id
ANDmod((s_w_id * s_i_id),10000)=su_suppkey
ANDascii(SUBSTRING(c_state, 1, 1))=su_nationkey
AND su_nationkey=n_nationkey AND n_regionkey=r_regionkey
AND r_name=’[REGION]’ AND o_entry_d>=’[DATE]’
GROUPBY n_name ORDERBY revenue DESC
Listing 2: TPC-H 查詢5
SELECT n_name, SUM(l_extendedprice * (1 - l_discount)) AS revenue
FROM customer, orders, lineitem, supplier, nation, region
WHERE c_custkey = o_custkey AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey AND n_regionkey = r_regionkey
AND r_name = ’[REGION]’ AND o_orderdate >= DATE ’[DATE]’
AND o_orderdate < DATE ’[DATE]’ + INTERVAL ’1’ YEAR
GROUPBY n_name ORDERBY revenue DESC
TPC-CH 不需要 TPC-H 規定的重繪函式,因為 TPC-C 事務會不斷地更新資料庫,查詢何時必須包含這些更新將在下一章進行詳細說明,
3.2 基準引數
TPC-CH 有四個引數:第一個引數用于指定資料庫大小,在 TPC-C 中,資料庫的大小由倉庫的數量來決定,大多數表隨著倉庫數量的增加而增加,只有 ITEM、SUPPLIER、NATION 和 REGION 的大小不變,
第二個引數用于指定作業負載的構成,它可以純 OLAP、純 OLTP、也可以是兩種作業負載的任意組合,該引數通過指定連接到資料庫系統的并行 OLTP 和 OLAP 會話(流)的數量來設定,OLTP 會話按照官方規范【Tra10a】中描述的分布順序調度隨機 TPC-C 事務,OLAP 會話針對由這22個查詢組成的查詢集進行持續迭代,每個會話以不同的查詢開始,以避免會話之間的快取效應,如圖4所示,
第三個輸入引數用于指定隔離級別,較低的隔離級別(如讀已提交)意味著較高的處理效率,而較高的隔離級別則保證了事務和查詢的結果質量, 最后一個引數用來指定用做分析基礎的資料的新鮮度,它僅適用于作業負載組合同時包含 OLTP 和 OLAP 兩種負載的情況,資料新鮮度通過事務的時間或數量來指定,在該時間或數量之后,新發出的查詢集必須包含最新的資料,從而該基準可以同時支持兩種資料架構:一種可以支持在單一資料集上同時進行 OLTP 和 OLAP,另一種則是通過資料增量的應用來實作對 OLTP 和 OLAP 的支持,
3.3 報告要求
除了對用到的硬體和軟體的描述之外,報告還需要包含以下系統特征資訊:OLTP 引擎的性能由 New-Order 事務和所有事務的吞吐量來衡量,在 OLAP 端,針對每一次迭代和每一個會話統計查詢回應時間,中值和查詢吞吐量也是統計指標,除了新鮮度引數之外,需要報告資料集已存在的時長最大值,對于記憶體型(in-memory)系統,總記憶體消耗會按一定時間間隔報告,其中包括已分配但尚未使用的記憶體塊,圖5提供了一個報告樣例,
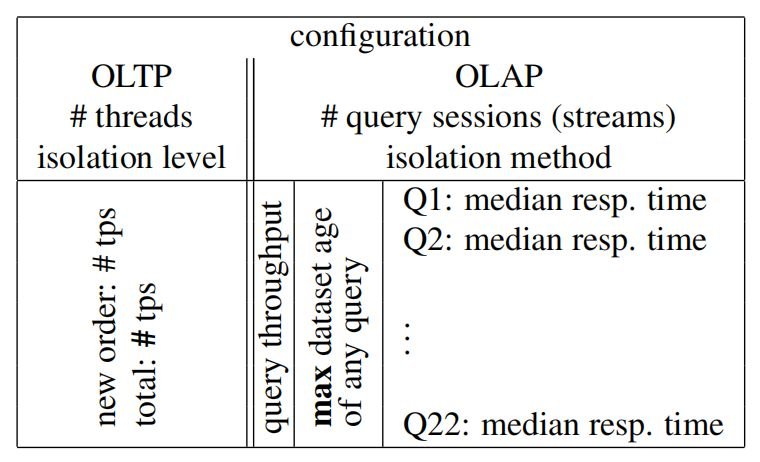
圖5:TPC-CH 基準的測驗報告要求
4. 被測系統
在圖1中,我們將 DBMS 分為四類,我們從四類 DBMS 中各選了一個代表進行了 TPC-CH 基準測驗,
4.1 分析型資料庫
MonetDB 是針對記憶體型 OLAP 資料庫的最有名的列存存盤方案,關于該系統的概述可以在總結性檔案【bmk09】中找到,因此,我們使用 MonetDB 作為“OLAP型”類別的代表,此類別還包括 SAP 的 TREX (BWA)、IBM Smart Analytics Optimizer 和 Vertica 分析資料庫,
4.2 事務型資料庫
最近一家名為 VoltDB 的初創公司將 Michael Stonebraker 牽頭創造的 H-Store 原型【KKN+08】進行了商業化,VoltDB 是一個高性能的記憶體型 OLTP 系統,它采用無鎖方法【HAMS08】進行事務處理,其中事務在私有磁區上操作,并以串行方式執行【Volb】,因此,我們使用 VoltDB 作為事務型資料庫的代表,該類別還包括以下系統: P*Time【CS04】、IBM solidDB、Oracle 的 TimesTen 以及新啟動的開發專案 Electron DB、Clustrix、Akiban、dbShards、NimbusDB、ScaleDB 和 Lightwolf,
4.3 通用資料庫
此類別包含基于磁盤存盤的通用資料庫,我們選擇了一個流行的、商業上可用的系統 System X 作為此類別的代表,
4.4 混合型資料庫
這一類別包括 Hasso Plattner【Pla09】概述的 SAP 新資料庫開發和我們的 HyPer【KN11】系統,Crescando【GUMG10】是一個特殊的 OLTP&OLAP 混合型系統,但是它的查詢能力比較有限,
4.4.1 HyPer:虛擬記憶體快照
我們開發了一個新型 OLTP&OLAP 混合型資料庫系統,該系統通過作業系統的虛擬記憶體管理【KN11】對事務資料進行快照,在該架構下,OLTP 行程“擁有”資料庫,并定期(秒級或分鐘級)派生出 OLAP 行程,此 OLAP 行程創建了資料庫的新事務一致性快照,因此,我們利用作業系統提供的功能為新的、重復的行程創建虛擬記憶體快照,例如,在 Unix 中,這是通過呼叫 fork() 來為 OLTP 行程創建子行程來實作的,為了保證事務的一致性,fork() 應該只在兩個連續的事務之間執行,而不應該在一個事務執行程序中執行,在4.4.1節中,我們將使用 undo 日志將動作一致的快照(在某個事務執行程序中創建的)轉換成事務一致的快照來放寬此約束,
通過派生產生的子行程會獲得父行程地址空間的精確副本,如圖6中的重疊的頁框面板所示,使用 fork() 創建的這個虛擬記憶體快照將用于執行一個 OLAP 查詢會話,如圖6中的右側部分所示,
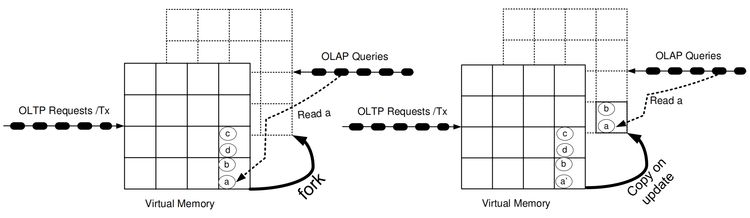
圖6:派生新快照(左側)和更新/寫入時復制(右側)
快照精確地停留在 fork() 發生時的狀態,值得慶幸的是,最先進的作業系統不會立即復制這些記憶體段,相反,這些作業系統采用了一種延遲更新時復制(lazy copy-on-write)策略,如圖6所示,最初,父行程(OLTP)和子行程(OLAP)通過將任一虛擬地址(例如,到物件 a)轉換到相同的物理主存位置來共享相同的物理記憶體段,共享記憶體段在圖中用虛線框標識,一個虛線方格表示一個尚未復制的虛擬記憶體頁面,只有當物件被更新時,比如資料項 a,作業系統和硬體支持的更新時復制機制才啟動對 a 所在的虛擬記憶體頁面的復制,從而產生了可由執行事務的 OLTP 行程訪問的新狀態 a’,以及可由 OLAP 查詢會話訪問的舊狀態 a,與圖中所示不同,額外的頁面實際上是為啟動頁面更改的 OLTP 行程創建的,而 OLAP 快照參考的是舊頁面,如果創建了多個這樣的快照,這一細節對于估算空間消耗非常重要(參見圖7),
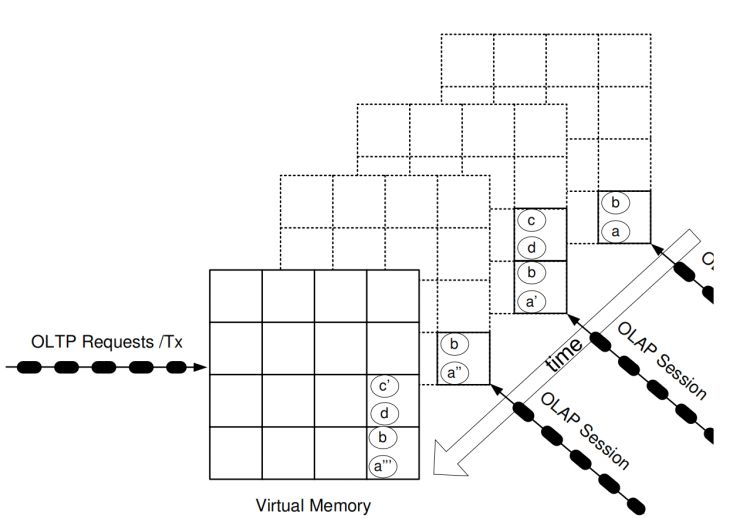
圖7:不同時間點的多個 OLAP 會話
至此,我們已經描繪了一個使用兩個行程的資料庫架構,一個行程用于 OLTP,而另一個用于 OLAP,由于 OLAP 查詢是只讀的,它們可以很容易地在共享相同地址空間的多個執行緒中并行執行,盡管如此,我們可以避免任何同步(鎖定和鎖存)開銷,因為 OLAP 查詢不共享任何可變的資料結構,現代多核計算機通常具有十個以上的內核,通過這種查詢間的并行化,肯定可以大幅提高速度,
充分利用多核服務器的另一種可能性是創建多個快照,HyPer 架構允許任意快照,這可以簡單地通過周期性(或按需)派生新的快照并由此啟動新的 OLAP 查詢會話行程來實作,圖7提供了一個示例,圖7中描繪了一個 OLTP 行程的當前資料庫狀態(最上層)和三個活躍的查詢會話行程的快照,按時間順序排列,時間越近,越靠上層,連續的狀態變化由資料項 a(最老的狀態)、a′、a′′和a′′′(最新的事務一致狀態)的四種不同狀態來突出顯示,顯然,大多數資料項在不同的快照之間不會改變,因為我們預期的快照間隔為幾秒鐘,而不是像當前使用 ETL 資料暫存方式的獨立資料倉庫解決方案那樣以幾分鐘或幾小時為間隔,原則上,活躍快照的數量不受限制,因為每個快照都“活在”自己的行程中,通過調整優先級,我們可以確保任務關鍵型 OLTP 行程始終分配有一個內核,即使 OLAP 行程數量眾多和/或利用多執行緒,從而超過了內核數量,
會話的最后一個查詢完成后,快照將被洗掉,這可以通過簡單地終止正在執行查詢會話的行程來完成,另外,快照洗掉不需要按照創建時間順序進行,一些快照可能會因為某些特殊原因,比如用于詳細盤點,需要保留更長時間,但是,快照的記憶體開銷與從創建該快照到下一個快照(如果存在)或當前時間之間執行的事務數量成比例,該圖使用資料項 c 說明了這一點,資料項 c 被物理復制用于“中年”快照,因此被最老的快照共享和訪問,與我們的直覺有些不太一樣的是,“中年”快照有可能會在早于最老的快照被終止,因為 c 駐留的頁面將被作業系統/處理器自動檢測為通過與物理頁面相關聯的參考計數器與最老的快照共享,因此,最老快照在“中年”快照終止后仍然存在——不像 a’所在的頁面那樣,最老快照在“中年”快照行程終止時被釋放,最新的快照訪問了包含在當前 OLTP 行程的地址空間中的狀態 c’,
5. 結果
在本節中,我們給出了 TPC-CH 的粗略結果,我們使用的測驗機使用的是 RHEL 5.4 作業系統,配有兩個四核2.93 GHz Intel R Xeon R 處理器和 64GB 記憶體,所有資料庫都擴展到了12個倉庫,對查詢集共執行了5次迭代,
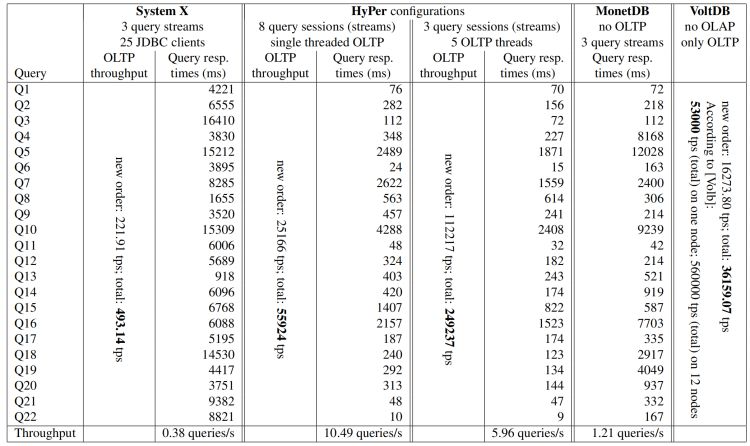
圖8:各系統的測驗結果對比
對于 MonetDB,我們評估了一個執行純 OLAP 作業負載的基準實體,我們排除了 OLTP,因為 MonetDB 中缺少索引會影響事務處理效率,我們在圖9中展示了處理三個并行 OLAP 會話的結果,由于在這種情況下不涉及對資料庫的更新,所以新鮮度和隔離級別引數無效,將查詢流的數量增加到5幾乎不會改變吞吐量,但是查詢執行時間幾乎增加了一倍,單個查詢會話執行將執行速度提高了10%到45%,但是吞吐量下降到每秒0.55個查詢,
對于 VoltDB,作業負載僅包括事務,每個倉庫/磁區一個“站點”(即12個站點)在我們的服務器上產生最佳結果,與 TPC-CH 規范不同,我們允許 VoltDB 只執行單磁區事務,如【Vola】中所建議的,并跳過那些涉及多個倉庫的 New-Order 和 Payment 實體,VoltDB 中的隔離級別是可序列化(serializable),
對于 System X,我們使用了25個 OLTP 會話和3個 OLAP 會話,對于 OLTP 和 OLAP,配置的隔離級別是讀已提交,我們對五個事務的組使用組提交,由于系統針對單個資料集進行操作,所以每個查詢都是對最新的資料進行操作,圖9顯示了此設定下的測驗結果,將 OLAP 會話從3個增加到12個之后,查詢吞吐量從0.38個查詢/秒提高到1.20個查詢/秒,但是這種調整導致查詢執行時間增加了20%到30%,且 OLTP 吞吐量下降14%,添加更多的 OLTP 會話也會大大增加查詢執行時間,
對于 HyPer,我們混合使用5個 OLTP 會話和3個并行 OLAP 會話來執行查詢,我們并沒有像 VoltDB 那樣簡化單磁區事務的運行,而是用3.1節中指定的跨倉庫事務來挑戰 HyPer,在一種設定下,OLAP 會話對最初加載的資料進行操作(參見圖9),在第二種設定下,為每個新的查詢流創建一個新的快照(參見圖9),查詢與事務通過快照隔離,在 OLTP 端,隔離級別為可序列化,
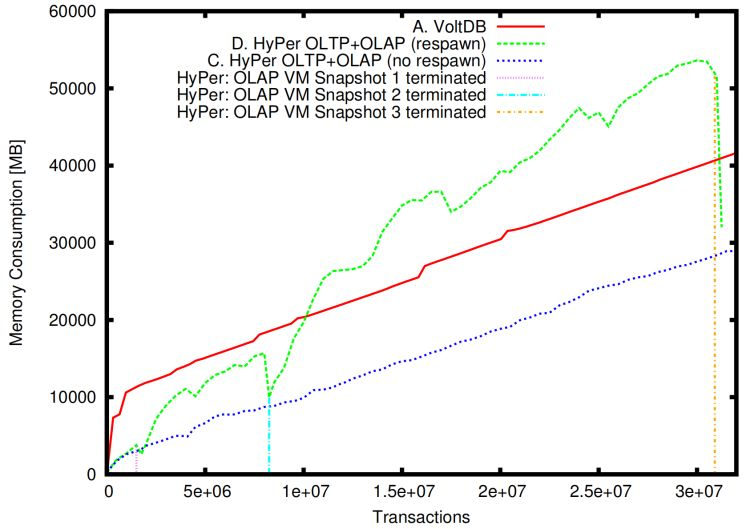
圖9:VoltDB 和 HyPer 的記憶體消耗(加載后)
因為 HyPer 還沒有獨立的客戶端和服務器行程,所以結果是由包含兩個組件的單個驅動程式產生的,因此,HyPer 排除了由行程間通信引起的潛在性能損失,但其他被測系統卻沒有,HyPer 強大的 OLTP 性能源于其能將事務編譯成機器碼,VoltDB 使用 Java 撰寫的存盤程序,
圖9顯示了 HyPer 和 VoltDB 的記憶體消耗,我們在這里沒有提供 MonetDB 結果,因為 MonetDB 資料庫大小不會隨著時間的推移而變化,HyPer 對5個 OLTP 會話并發運行3個查詢會話,并在每次迭代后生成一個新的虛擬機快照,VoltDB 執行純 OLTP 作業負載,該圖顯示了初始加載完成后的記憶體消耗,
6. 小結
本文中,我們展示了一個適用于混合 OLTP 和 OLAP 資料庫系統的基準——TPC-CH,這個基準是基于標準化的 TPC-C 和 TPC-H 基準開發的,它不僅適用于混合 DBMS,還可以用于將混合 DBMS 與 OLTP、OLAP、傳統資料庫以及通用資料庫進行比較,我們用 TPC-CH 對各類資料庫的主流產品進行了測驗并證實了上述觀點,
鳴謝
我們非常感謝 Dagstuhl 研討會(Dagstuhl Workshop)在2010年9月進行的關于“穩健查詢處理(Robust Query Processing)”研討中,關于該基準卓有成效的探討,另外,感謝 Stefan Krompa? 幫助實作了 System X 基準測驗,
考慮篇幅,我們會把論文的附錄部分放到官網上,歡迎大家關注~
StoneDB 已經正式開源,歡迎關注我們
官網:https://stonedb.io/
Github: https://github.com/stoneatom/stonedb
Slack: https://stonedb.slack.com/ssb/redirect#/shared-invite/email
參考文獻

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/506068.html
標籤:MySQL
下一篇:生產資料庫主鍵超出限制解決方案