產生背景及定義
HDFS:分布式檔案系統,用于存盤檔案,主要特點在于其分布式,即有很多服務器聯合起來實作其功能,集群中的服務器各有各的角色
- 隨著資料量越來越大,一個作業系統存不下所有的資料,那么就分配到更多的作業系統管理的磁盤中,但是管理和維護極不方便,于是迫切需要一種系統來管理多臺機器上的檔案,這就是分布式管理系統,HDFS是其中一種,
- HDFS的使用適合一次寫入,多次讀出的場景,且不支持對檔案的直接修改,僅支持在檔案末尾追加
- HDFS采用流式的資料訪問方式:特點就是像流水一樣,資料不是一次過來,而是一點一點“流”過來,處理資料也是一點一點處理,如果是資料全部過來之后才處理,那么延遲就會很大,而且會消耗很大的記憶體,
優缺點
- 高容錯性
- 資料自動保存多個副本,通過增加副本的方式,提高容錯性
- 若某一個副本丟失后,它可以自動分配到其它節點作為新的副本
- 處理大資料
- 資料規模:能夠處理的資料規模可以達到GB,TB,甚至PB級別的資料
- 檔案規模:能夠處理百萬規模以上的檔案數量,數量相當之大
- 可構建在廉價的機器上,通過多副本機制,提高可靠性
組成架構
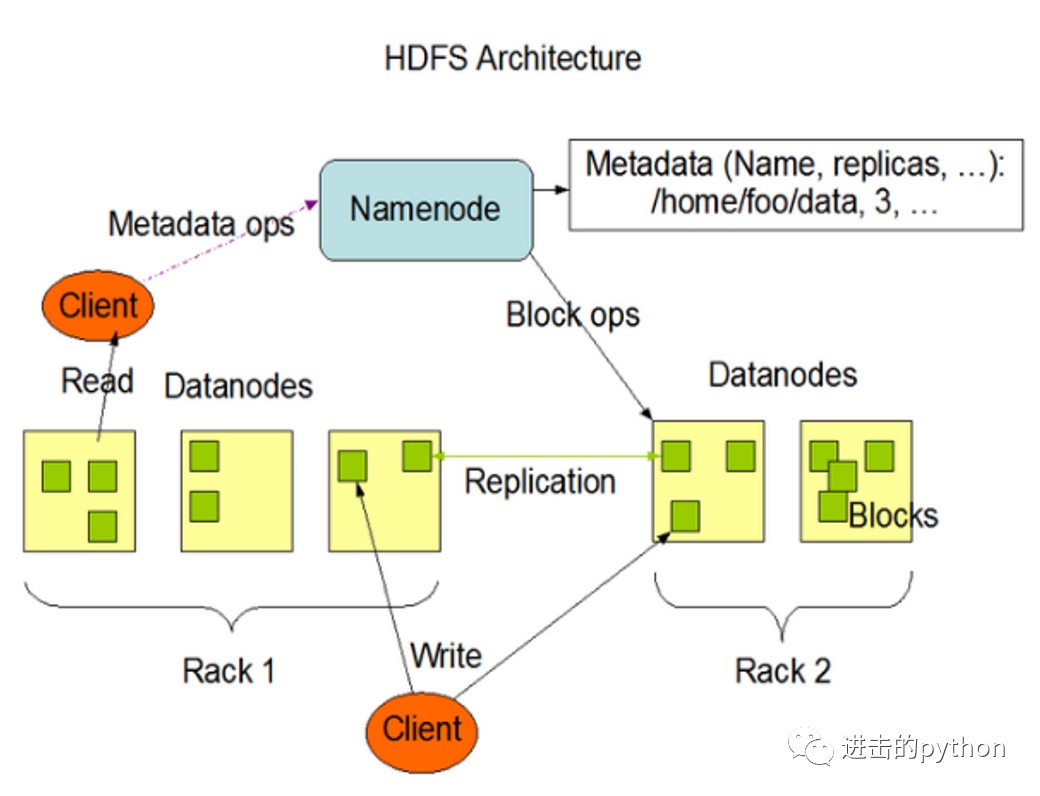
namenode(nn):就是Master,是一個管理者,存放元資料- 管理HDFS的名稱空間
- 配置副本策略
- 管理資料塊的映射資訊
- 處理客戶端的讀寫請求
datanode(dn):就是slave,真正存盤檔案的地方- 存盤實際的資料塊
- 執行資料塊的讀寫操作
secondarynamenode(2nn):并非namenode的熱備,當namenode掛掉的時候,并不能馬上替換namenode并提供服務- 作為namenode的輔助,分擔其作業量,比如定期合并Fsimage和Edits(文章后邊會講到這兩個東西),并推送給namenode
- 在緊急情況下,可輔助恢復namenode,但是只能恢復部分,而不能全部恢復
client:客戶端- 檔案的切分,在上傳HDFS之前,client將檔案切分為一個一個的Block,然后一個一個進行上傳
- 與namenode互動,獲取檔案的datanode資訊
- 與datanode互動,讀取或寫入資料
- client提供一些命令來管理HDFS,比如namenode的格式化
- client通過一些命令來訪問HDFS,比如對HDFS的增刪查改等
檔案塊大小
為什么要把檔案抽象為Block塊存盤?
- block的拆分使得單個檔案大小可以大于整個磁盤的容量,構成檔案的Block可以分布在整個集群, 理論上,單個檔案可以占據集群中所有機器的磁盤,
- Block的抽象也簡化了存盤系統,對于Block,無需關注其權限,所有者等內容(這些內容都在檔案級別上進行控制),
- Block作為容錯和高可用機制中的副本單元,即以Block為單位進行復制,
HDFS中的檔案在物理記憶體中分塊存盤(Block),塊的大小在Hadoop2.x版本中默認為128M,在老版本中為64M,那么為什么為128M呢?
其實,HDFS的塊的大小的設定主要取決于磁盤傳輸速率,如下:
- 如果在HDFS中,尋址時間為10ms,即查找到目標Block的時間為10ms
- 專家說操作的最佳狀態為:尋址時間為傳輸時間的1%,因此傳輸時間為1s
- 而目前磁盤的傳輸速率普遍為100M/s
為什么塊大小不能設定太小,也不能設定太大?
- HDFS的塊設定太小,會增加尋址時間,使得程式可能一直在尋找塊的開始位置
- 如果設定的太大,從磁盤傳輸資料的時間會明顯大于定位這個塊所需的尋址時間,導致程式處理這塊資料時會非常慢
HDFS的資料流
HDFS寫資料流程
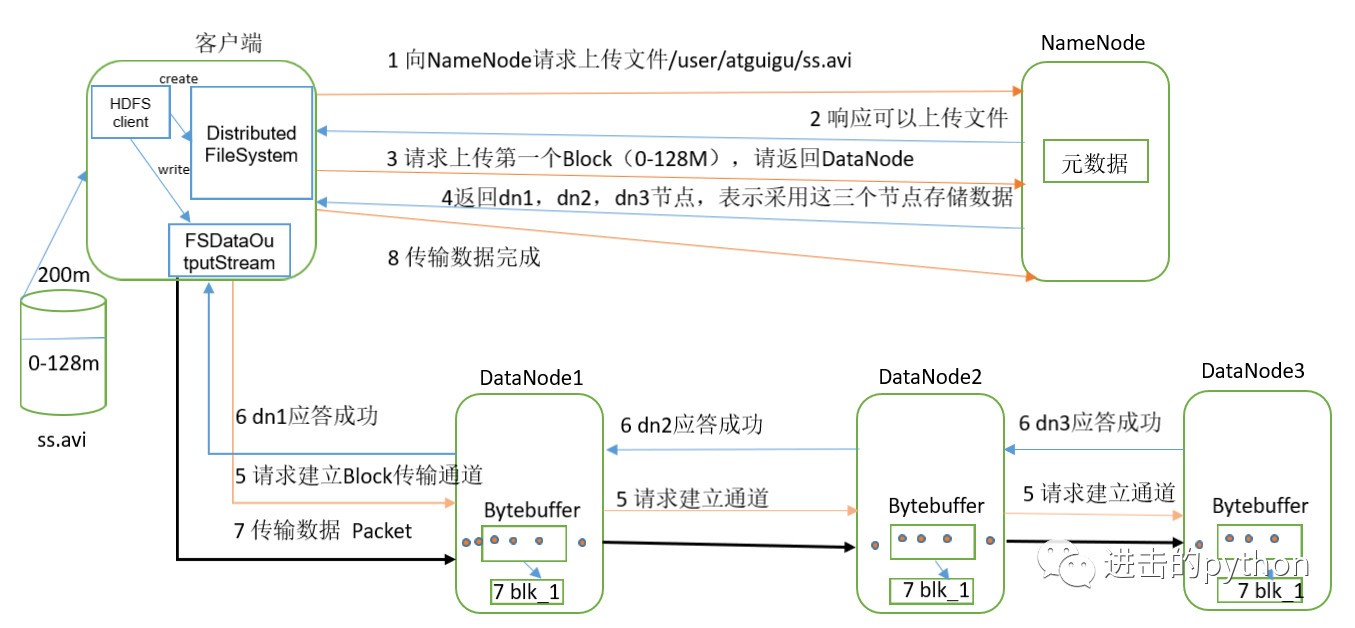
- 客戶端通過Distributed FileSystem模塊向NameNode請求上傳檔案,NameNode檢查目標檔案是否已存在,父目錄是否存在,
- NameNode回傳是否可以上傳,
- 客戶端請求第一個 Block上傳到哪幾個DataNode服務器上,
- NameNode回傳3個DataNode節點,分別為dn1、dn2、dn3, 如果有多個節點,回傳實際的副本數量,并根據距離及負載情況計算
- 客戶端通過FSDataOutputStream模塊請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然后dn2呼叫dn3,將這個通信管道建立完成,
- dn1、dn2、dn3逐級應答客戶端,
- 客戶端開始往dn1上傳第一個Block(先從磁盤讀取資料放到一個本地記憶體快取),以Packet為單位,dn1收到一個Packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答,
- 當一個Block傳輸完成之后,客戶端再次請求NameNode上傳第二個Block的服務器,(重復執行3-7步),
網路拓撲---節點距離計算
在HDFS寫資料的程序中,NameNode會選擇距離待上傳資料最近距離的DataNode接收資料,那么這個最近距離是怎么計算的呢?
結論:兩個節點到達最近的共同祖先的距離總和,即為節點距離,
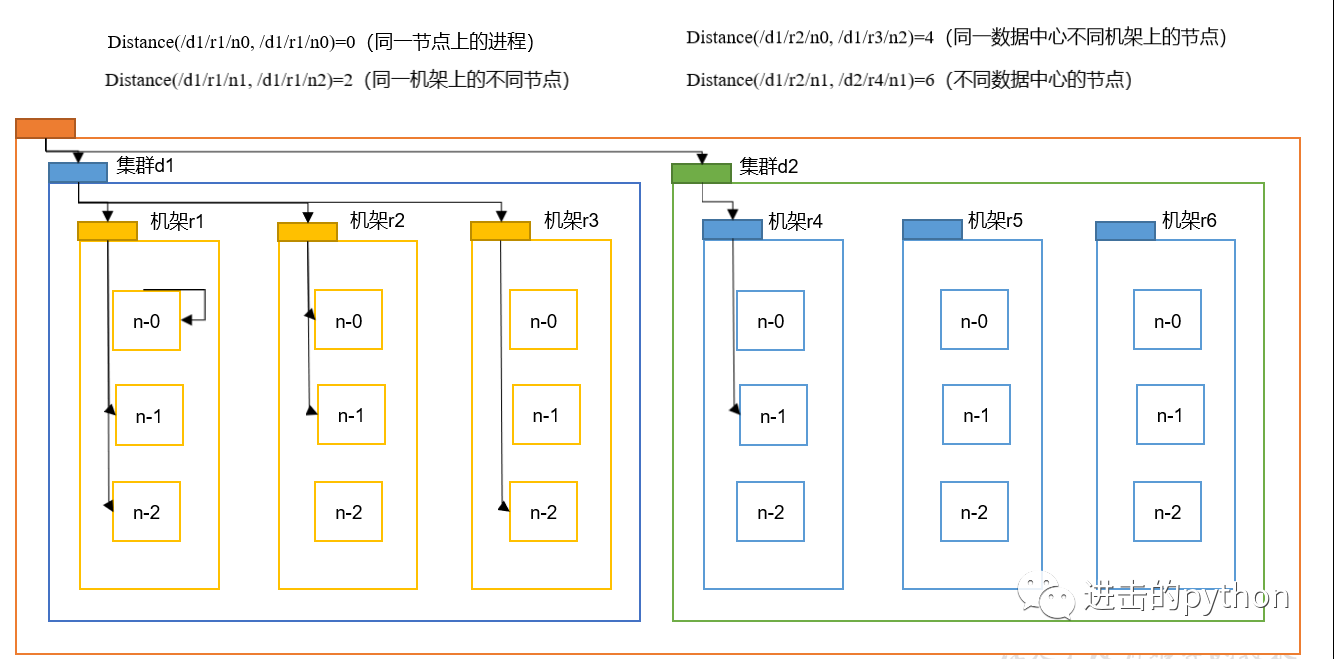
如上圖所示:
- 同一節點上的行程節點距離為0
- 同一機架上不同節點的距離為兩個節點到共同機架r1的距離總和,為2
- 同一資料中心不同機架的節點距離為兩個節點到共同祖先集群d1的距離之和,為4
- 不同資料中心的節點距離為兩個節點到達共同祖先資料中心的距離之和,為6
機架感知(副本存盤的節點選擇)
副本的數量我們可以從組態檔中設定,那么HDFS是怎么選擇副本存盤的節點的呢?
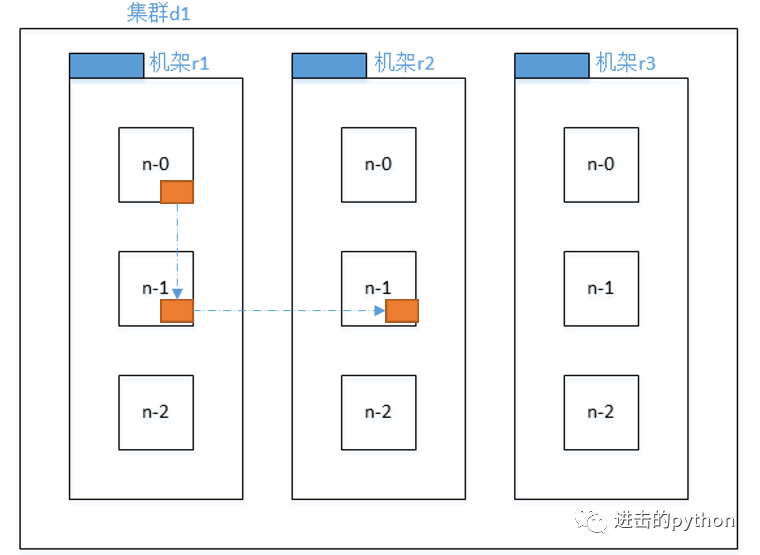
如上圖所示,為了提高容錯性,有如下設定,加入現在有3個副本:
- 第一個副本在Client所在的節點上,如果客戶端在集群外,則隨機選一個
- 第二個副本和第一個副本位于相同機架,隨機節點
- 第三個副本位于不同機架,隨機節點
這樣做的目的就是為了提高容錯性,
HDFS讀資料流程
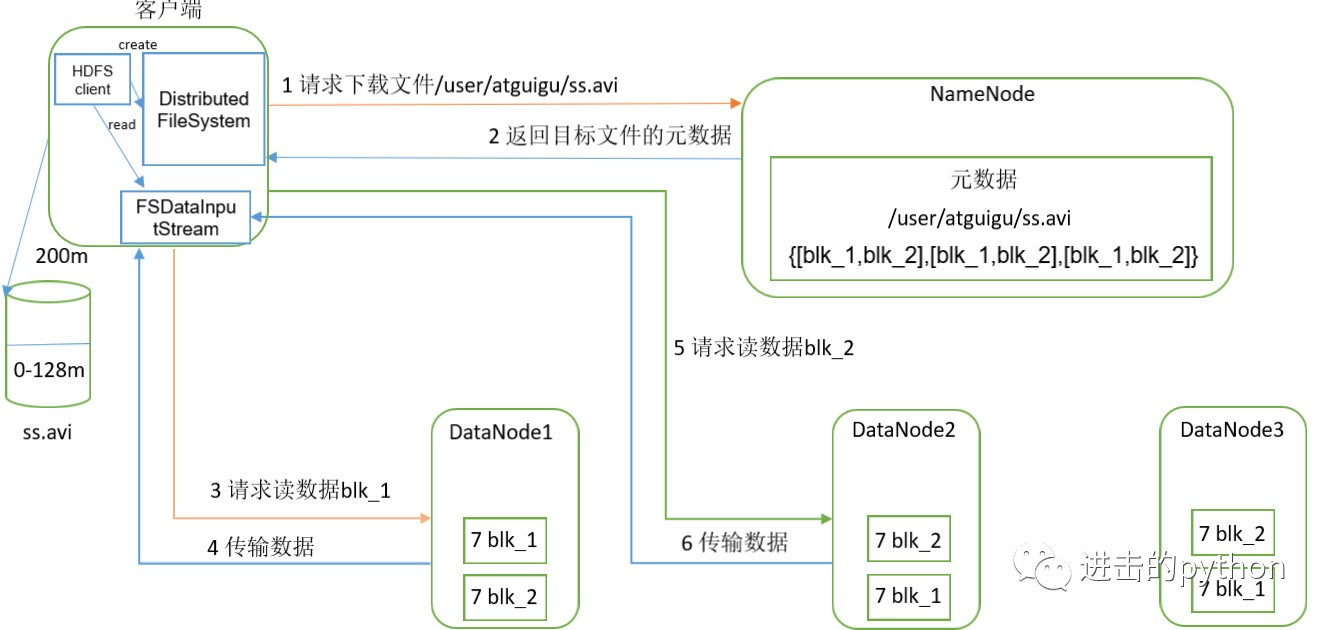
- 客戶端通過Distributed FileSystem向NameNode請求下載檔案,NameNode通過查詢元資料,找到檔案塊所在的DataNode地址,
- 挑選一臺DataNode(就近原則,然后隨機)服務器,請求讀取資料,
- DataNode開始傳輸資料給客戶端(從磁盤里面讀取資料輸入流,以Packet為單位來做校驗),
- 客戶端以Packet為單位接收,先在本地快取,然后寫入目標檔案,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/50614.html
標籤:大數據