MySQL學習筆記

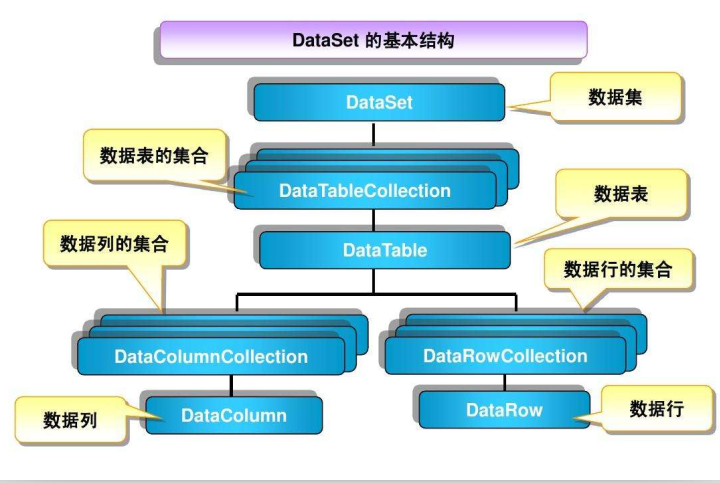
資料結構圖
|
更改字符集 |
alter database dbName character set 'charsetName'; alter database dwg2pdf character set 'utf8'; alter table tableName convert to character set ‘'charsetName'’; alter table tasks convert to character set 'utf8';
|
|
創建表之后 添加約束 |
1.主鍵約束 添加:alter table table_name add primary key (欄位) 洗掉:alter table table_name drop primary key 2.非空約束 添加:alter table table_name modify 列名 資料型別 not null 洗掉:alter table table_name modify 列名 資料型別 null 3.唯一約束 添加:alter table table_name add unique 約束名(欄位) 洗掉:alter table table_name drop key 約束名 4.自動增長 添加:alter table table_name modify 列名 int auto_increment 洗掉:alter table table_name modify 列名 int 5.外鍵約束 添加:alter table table_name add constraint 約束名 foreign key(外鍵列) references 主鍵表(主鍵列) 洗掉: 第一步:洗掉外鍵 alter table table_name drop foreign key 約束名 第二步:洗掉索引 alter table table_name drop index 索引名 [^1]: 約束名和索引名一樣 6.默認值 添加:alter table table_name alter 列名 set default '值' 例子: alter table tasks modify sDwgPath varchar(255) not null; alter table tasks modify id int(20) not null; alter table tasks add unique(id); alter table tasks modify id int(64) not null; alter table tasks modify id int auto_increment; |
性能優化
|
概述 |
MySQL性能優化:通過合理安排資源,調整系統引數,使MySQL運行更快,更節約資源; 包括:查詢速度優化、更新速度優化、資料庫結構優化、服務器優化; 查看服務器性能引數show status like 'value'; connections連接服務器次數uptime上線時間 slow_queries慢查詢次數com_select查詢操作次數 com_insert插入操作次數com_update更新操作次數 com_delete洗掉操作次數 |
|
查詢 |
用explain和describe,分析查詢陳述句; explain [extended]selectOptions; extended將產生附加資訊;selectOptions包括from where等子句; describe select selectOptions;describe 可以簡寫為desc; describe和explain的語法相同,結果也相同; 索引可以提高查詢速度; 并非所有查詢都會用到索引; l like關鍵字查詢,匹配字串第一個字符是%,索引就不會起作用; l 多列索引,只有查詢使用了第一個欄位時,索引才會起作用; 子查詢效率低,因為要建立一個臨時表,查詢結束后又要銷毀臨時表; 可以用join連接查詢代替子查詢,因為join查詢不會創建臨時表;
|
|
結構 |
分解表:將欄位多的表分解成多個表,將使用頻率低的欄位分離到單獨表; 建立中間表:將聯合查詢的資料放入中間表,用中間表查詢代替聯合查詢; 增加冗余欄位,可以提高查詢速度; |
|
插入 |
插入記錄時,影響插入速度的因素有:索引、唯一性校驗、一次插入條數等; ①禁用索引:禁用→插入→啟用; 插入資料時,系統會為新插入資料建立索引,拖慢了插入速度; 在插入大量資料前禁用索引,可以提高插入速度; 禁用索引 alter table tableName disable keys; 啟用索引alter table tableName enable keys; ②禁用唯一性檢查:禁用→插入→啟用; set unique_check=0; set unique_check=1; ③使用批量插入:使用一條陳述句插入多條資料,比一條陳述句插入一條資料要快; ④使用load data infile批量匯入 load data infile比insert快; 對于InnoDB引擎,優化方法: 禁用唯一性檢查set unique_checks=0;set unique_checks=1; 禁用外鍵檢查set foreign_key_checks=0;set foreign_key_checks=1; 禁用自動提交set autocommit=0;set autocommit=1; |
|
表 |
■分析表:分析關鍵字分布 analyze [local|no_write_to_binlog] table tableName[,...]; local是no_write_to_binlog的別名,二者等價,表示不寫入二進制日志記錄; analyze table message; ■檢查表:是否存在錯誤 check table tableName [,...] [option]... option={quick|fast|medium|extended|changed} ① quick不檢查行,不檢查錯誤連接| ② fast只檢查沒有正確關閉的表| ③ medium掃描行,以驗證被洗掉的連接有效;計算各行關鍵字校驗和,并用校驗和驗證;| ④ extended對每行的所有關鍵字查找,可以確保100%一致,但是很慢| ⑤ changed只檢查上次檢查后更改的和沒有正常關閉的表; ■優化表:消除洗掉或更新造成的空間浪費 optimize [local|no_write_to_binlog] table tableName [,...]; optimize 只能優化varchar、blog或text型別欄位; optimize 可以清理由洗掉更新操作造成的資料碎片; |
|
服務器 |
服務器優化:硬體優化、引數優化; ■硬體優化:大記憶體、高速磁盤、分散磁盤IO、多處理器多執行緒; ■MySQL引數優化:配置引數在my.cnf或者my.ini檔案的[mysqld]組中; (1) key_buffer_size索引緩沖區大小; (2) table_cache同時打開表個數;不是越大越好; (3) query_cache_size查詢緩沖區;0-1-2 (4) sort_buffer_size排序緩沖區,越大,排序越快; (5) read_buffer_sizs 掃描表緩沖區; (6) read_rnd_buffer_size每個執行緒的緩沖區;頻繁進行多次連續 掃描,可增加該值; (7) innodb_buffer_pool_size表示InnoDB表和索引快取;越大查詢越快,太大影響系統性能; (8) max_connections最大連接數,過大浪費記憶體或者服務器卡死; (9) innodb_flush_log_at_trx_commit寫入日志的時機;0-1-2 (10) back_log偵聽佇列大小,存入堆疊的最大請求數;高并發才需要調高; (11) interactive_timeout服務器關閉連接前等待的秒數; (12) sort_buffer_size排序執行緒的緩沖區;增大排序快;默認2M; (13) wait_timeout關閉連接時等待的秒數,默認28800; |

資料備份
|
備份 |
mysqldump -u user -h host -ppassword dbName [tableName[,...]]>fileName.sql; user 用戶名;host 主機名;dbName 資料庫;tableName表名;fileName.sql另存的檔案名及后綴; ■備份一個資料庫 mysqldump -u root -p myDatabase>C:\backup\myBackUp_20220901.sql enter password 666; ■備份資料表 mysqldump -u user -h host -p dbName [tableName[,...]]>fileName.sql; mydqldump -u ‘root’-h ‘localhost’-p ‘myDB’student>C:\Users\Administrator\Desktop\backup.sql; ■備份多個資料庫 mysqldump -u root -h host -p --databases dbName[,...]>fileName.sql; databases后面至少指定一個資料庫名稱,多個用逗號隔開; mysqldump -u root -h ‘localhost’ -p --databases db1,db2,db3>threeBackUp.sql; ■備份所有資料庫 mysqldump -u root -h host -p --all-databases >fileName.sql; mysqldump -u root -h ‘localhost’-p --all-databases >allBackUp.sql; ■MyISAM引擎備份插件(Unix系統) mysqlhotcopy dbName[,...] /path/to/new.directory; mysqlhotcopy -u root -p test /usr/backup
|
|
還原 |
■用<還原 mysql -u user -p [dbName]<fileName.sql; mysql -u root -p myDB<C:\backup\myBackUp.sql; ■用source命令還原 use myDB; source C:\backup\myBackUp.sql; 先選擇資料庫,然后選擇資料檔案,資料將還原到當前資料庫; ■mysqlhotcopy還原 chown -r mysql.mysql /var/lib/mysql/dbName; cp -r /usr/backup/test usr/local/mysql/data; ■拷貝檔案還原:服務器版本相同,MyISAM引擎可用,InooDB引擎不可用; |
|
遷移 |
資料遷移的原因:安裝新的服務器;MySQL版本更新;從SqlServer到MySQL; ?不同主機間的遷移 將www.abc.com主機上的資料庫遷移到www.xyz.com主機上; mysqldump -h www.abc.com -u root -p password dbName| mysql -h www.xzy.com -uroot -ppassword; mysqldump 匯出的資料直接通過管道符|,傳給mysql命令匯入到www.xzy.com資料庫中; dbName為需要遷移的資料庫名稱,如果要遷移所有資料庫,用--all-databases; ?不同MySQL版本間的遷移 備份老資料庫→卸載舊版本→安裝新版本→用新版本恢復資料; ?不同資料庫間的遷移(oracle、sqlserver、MySQL等等) 了解不同資料庫的架構,比較差異; 關鍵字不同,非標準的SQL陳述句,需要進行映射處理; |
|
匯出 |
MySQL資料庫支持sql、xml、html檔案的匯出和匯入; select volunmList from tableName where condition into outfile ‘fileName’[options] --options fields termianted by ‘value’欄位間分隔字符,可以一個或多個,默認制表符\t; fields [optionally]enclosed by ‘value’包圍字符,只能單個字符; fields escaped by‘value’設定轉義字符,默認\; lines starting by ‘value’每行開頭字符,可以一個或多個,默認無; lines terninated by‘value’每行結束字符,可以一個或多個,默認\n; into oufile 前面是一個查詢陳述句,后面是匯出的檔案名和選項; select*from test.student into outfile “C:\student.txt”; select * from test.student into outfile “C:\student.txt” fields terminated by ‘,’enclosed by ‘\”’escaped by ‘\’’ lines terninated by ‘\r\n’;
mysqldump -t path -u root -p dbName [tables] [options] --options --fields-termianted-by=value分隔字符,默認\t; --fields-enclose-by=value包圍字符; --fields-optionally-enclosed-by=value包圍字符,只適用char、varchar等字符資料; --fields-escaped-by=value轉義字符,默認\; --lines-terminated-by=value行結束符,默認\n; 指定引數-t才可以匯出TXT格式檔案;若不指定tables則匯出所有表; mysqldump -t c:\ test person -u root -p; mysqldump -t C:\backup test person -u root -p --fields-terminated-by=,--fields-optionally-enclosed-by=\” --fields-escaped-by=? --lines-terminated-by=\r\n; mysql -u root -p --execute =”select陳述句;” dbName>fileName.txt; mysql -u root -p --execute=”select*from person;” test>C:\personOut.txt; mysql -u root -p --vertical --execute=”select*from person;” test>C:\personOut.txt; mysql -u root -p --html --execute=”select*from person;” test>C:\personOut.html; mysql -u root -p --xml --execute=”select*from person;” test>C:\personOut.xml;
|
|
匯入 |
load data infile ‘fileName.txt’int table tableName [options] [ignore number lines] --optoins 同上 load data infile ‘C:\person.txt’ into table test.person; 還原之前,應先洗掉原有資料;use test; delete from person;
load data infile ‘C:\person.txt’ into table test.person fields terminated by ‘,’ enclosed by ‘\”’ escaped by’\’’ lines terminated by ‘\r\n’; mysqlimport -u root-p dbName fileName.txt [options]; C:\>mysqlinport -u root -p test C:\backup\person.txt --fields-terminated-by=,--fields-optionally-enclosed-by=\” --fields-escaped-by=? --lines-terminated-by=\r\n; |
用戶管理

|
概述 |
MySQL是一個多用戶資料庫,可以為不同的用戶指定不同的權限; root用戶=超級管理員:擁有所有權限; 權限:創建用戶、洗掉用戶、修改用戶密碼; 普通用戶:擁有被授予的權限; |
|
|
資訊表 |
資訊表:user,db,host,tables_priv,columns_priv,procs_priv; ■user表的權限是全域級的,user表有洗掉權限,則可以洗掉所有資料庫的所有資料;
■db表:對某個資料庫的操作權限; ■host表:對主機的操作權限; ■tables_priv表:對表的操作權限; ■columns_priv表:對列的操作權限; select*from mysql.tables_priv; select user,password,host,select_priv,update_priv from mysql.user; select*from mysql.db; |
|
|
|
■procs_priv表:對存盤程序和存盤函式的權限; |
|
|
登錄 |
-h主機名(host),指定主機名或IP,不指定默認localhost; -u用戶名(user); -p密碼(password),密碼和-p之間不能有空格; -P埠號(Port)默認3306; 資料庫名,可以再命令最后指定資料庫名稱; -e要執行的sql陳述句,登錄→執行→退出;
mysql --user=tom --password=guess db_name; mysql -u tom -pguess db_anme;-p和密碼之間不能有空格; mysql -uroot -p -hlocalhost test; mysql-uroot-p-hlocalhost test -e”desc person;” |
|
|
用戶 |
■■■創建用戶create user create user userSpecification [,...] userSpecification:user@host [identified by [password]’password’|identified with authPlugin[as ‘authString’] ] l user 表示用戶名,host表示允許登錄的主機名稱; l identified by用來設定登錄密碼; l [password]表示使用哈希值密碼; l ’password’表示使用普通明文密碼; l identified with為用戶指定身份驗證插件; l authPlugin身份驗證插件名稱,可以是單引號字串或雙引號字串; l authString’該引數傳遞給身份驗證插件,由該插件解釋引數的意義; 使用create user必須要有全域的create user權限,或者資料庫的insert權限; 創建后,會在user表中添加一條記錄,但是該賬戶沒有任何權限; 如果待添加賬戶已經存在,則會回傳錯誤; create user ‘jeffrey’@’localhost’ indentified by ‘mypass’;賬號+密碼 create user ‘jeffrey’@’localhost’;不指定密碼,則登錄不需要密碼 create user ‘jeffrey’;不指定主機,則可訪問所有主機; 如果只指定用戶名,主機名則默認‘%’,表示對所有主機開放; select password(‘mypass’);顯示密碼的哈希值 顯示結果:password('mypass') *6C8989366EAF75BB670AD8EA7A7FC1176A95CEF4 create user ‘jeffrey’@’localhost’ identified by password ‘*6C8989366EAF75BB670AD8EA7A7FC1176A95CEF4’; 使用哈希值設定密碼; create user ‘jeffrey’@’localhost’ idendified with my_auth_plugin; 使用插件進行身份驗證; identified by和identified with是互斥的,只能二選一;
■■■創建用戶grant(推薦) grant privileges on db.table to user@host [idendified by ‘password’][,...] [with grant option] ; privileges 賦予用戶的權限型別; db.table 表示用戶權限作用的表; idendified by設定密碼;‘password’表示用戶密碼; [with grant option]賦予用戶grant權限,該用戶可以對其他用戶賦予權限; select host,user,select_priv,update_priv from mysql.user where user=’testUser’; ■■■創建用戶 編輯user表 insert into mysql.user(host,user,password,[privlegeList]) values(‘host’,’userName’,password(‘password’),[privilegeValueList]); password()函式為密碼的加密函式; privilegeValueList的值只能是‘Y’或‘N’; insert into user(host,user,password) values(‘localhost’,’testUser’,password(‘123456’)); mysql> insert into mysql. user(host,user,password) values('localhost','testUser',password('666')); ERROR 1364 (HY000): Field 'ssl_cipher' doesn't have a default value flush privileges;重新加載授權表; insert into需要使用加密函式password(),而grant會自動加密,不需要加密函式; ■■■洗掉用戶 drop user[,...]; drop user ‘user’@’localhost’;洗掉user在本地登錄權限; drop user;洗掉來自所有授權表的賬戶權限記錄; 被洗掉用戶打開時,drop不會立即生效,等到用戶關閉對話后才會生效; 當用戶再次嘗試登錄時,則登錄失敗; delete from mysql.user where host=’hostName’ and user=’userName’; delete from mysql.user where host=’localhost’ and user=’test’; |
|
|
密碼 |
■■■root用戶改密碼 ①用mysqladmin 改密碼 mysqladmin -u username -h localhost -p password ‘newPassword’; mysqladmin -u root -p password “654321”;新密碼需要用雙引號; ②通過user表改密碼 update mysql.user set password=password(“newPassword”) where user=’root’and host=’localhost’ update mysql.user set password=password(“645321”); ③用set改密碼 set password=password(“666888”);
■■■root修改普通用戶密碼 set password for ‘user’@’host’=password(“newPassword”); set password for’test’@’localhost’=password(“666”); update mysql.user set password=password(“newPassword”) where user=’userName’and host=’hostName’; update mysql.user set password=password(“999”)where user=’test’and host=’localhost’; grant usage on *.* to ‘userName’@’%’idendified by ‘newPassword’; grant usage on *.* to ‘test’@’localhost’idendified by ‘666’; ■■■普通用戶自己改密碼 set password=password(‘newPassword’); ■■■忘記密碼的解決方案 以skip-grant-tables選項啟動時,不加載權限判斷,任何用戶都能訪問資料庫; mysqld --skip-grant-tables;(Windows系統) mysqld-nt --skip-grant-tables;(Windows系統) mysqld_safe --skip-grant-tables user=mysql;(Linux系統) /etc/init.d/mysql start-mysql --skip-grant-tables;(Linux系統) 使用root登錄,重新設定密碼(XP系統) ① C:\>net stop mysql 停止服務(命令列視窗輸入) ② C:\mysqld --skip-grant-tables 啟動服務(命令列視窗輸入) ③ C:\mysql -u root 無密碼登錄(打開另外一個命令列視窗) ④ update mysql,user set password=password(‘newPassword’)where user=’root’and host=’localhost’; 重新設定密碼; ⑤ flush privileges;重新加載權限表,新的密碼才會生效; 關閉輸入 mysqld --skip-grant-tables視窗,用新密碼登錄; |
|
|
權限 |
■■■授權grant 全域層級:grant all on *.*;revoke all on *.*;存盤在mysql.user表中 資料庫層級:grant all on dbName;revoke all on dbName;存盤在mysql.db和mysql.host表中; 表層級:grant all on dbName.tableName; revoke all on dbName.tableName;存盤在mysql.tables_priv中; 列層級:存盤在mysql.columns_priv表中;當使用revoke時,必須指定與被授權列相同的列; 子程式層級:create routine,alter routine,execute,grant適用于已存盤的子程式;這些權限可以授予全域層級和資料庫層級;除了create routine外,可以授予子程式層級,存盤在mysql.procs_priv表中; grant privType [(columns)] [,...] on [objectType] table1,table2... to user [identified by [password]’password’][,...] [with grant option] grant option: max_queries_per_hour count每小時查詢次數 max_updates_per_hour count每小時更新次數 max_connections_per_hour count每小時連接次數 max_user_connections count同時最大連接數 privType 權限型別;columns權限作用的列,不指定表示作用于整個表; objectType授權作用的物件型別,有table,function,procedure; table1,table2...權限作用的表; user用戶賬戶,用戶名+主機名,例如’userName’@’hostName’; identified by密碼; grant select,insert on *.* to ‘student’@’localhost’ idendified by ‘123456’; ■■■取消權限revoke revoke取消權限后,用戶的賬戶記錄將從db,host,tables_priv,columns_priv表中洗掉; 但是用戶賬號不會洗掉,仍在user表中,想要洗掉賬號,用drop user; 從user表中洗掉賬號前,應該回收所有權限; revoke all privileges,grant option from ‘userName’@’hostName’[,...] revoke privType [(columns)] [,...] on table1 [,...] from ‘userName’@’hostName’[,...]; revoke update on *.* from ‘student’@’localhost’; |
|
|
查看 |
show grants for ‘userName’@’hostName’; show grants for ‘student’@’localhost’; select privilegesList from user where user=’userName’,host=’hostName’; select tables_priv,update_priv from user where user=’tom’,host=’localhost’; |
|
|
訪問 |
①連接核實階段 MySQL用3個欄位檢查身份,host,user,password; ②請求核實階段 對用戶將要進行的操作,檢查是否有足夠的權限來執行; 檢查順序:user表→db表→tables_priv表→columns_priv表; |
觸發器:由事件觸發的程式段
|
定義 |
1. 觸發器也是一段程式,相當于事件處理程式EventHandler; 2. 觸發器和存盤程序一樣,都是嵌入到MySQL中的一段程式; 3. 觸發器由事件來觸發,觸發事件包括insert,update,delete; 4. 觸發器基于某個表,當該表進行特定操作時,就會激活該觸發器; 5. 觸發器不需要call來呼叫,而是由系統自動呼叫;
|
||
|
創建 |
create trigger triggerName triggerTime triggerEvent on tableName for each row triggerBody; triggerName 觸發器名稱,用戶指定; triggerTime 觸發時機,可以指定為before或after; triggerEvent 觸發事件,包括insert、update、delete; tableName 建立觸發器的表名,即在哪張表上建立觸發器; triggerBody觸發程式體; 觸發器可以包含多條陳述句,用begin和end標識; create talbe account(num int,amount decimal(10,2)); create trigger myTrigger before insert on account for each row set@sum=@sum+new.amount; create trigger triggerName triggerTime triggerEvent on tableName for each row triggerBody;
1 |
||
|
查看 |
show triggers; select*from information_schema.triggers where condition; select*from infromation_schema.triggers where trigger_name=’myTrigger’\g;
|
||
|
使用 |
當滿足觸發條件時,系統自動激活觸發器,執行相關代碼; |
||
|
洗掉 |
drop trigger [dbName.]triggerName; 如果不指定資料庫名稱,則在當前資料庫執行洗掉操作; drop trigger test.myTrigger; |
視圖:一個虛擬表;
|
概述 |
1. 視圖中的資料是對現有表資料的參考; 2. 視圖是從一個表或者多個表中匯出的; 3. 視圖中可以使用:select,insert,update,delete,, 4. 視圖可以從現有視圖中創建,視圖一經定義便存盤于資料庫中; 5. 通過視圖看到的資料只是基本表中的資料; 6. 視圖中資料修改,基本表中資料也同時修改; 7. 基本表中的資料修改,視圖中的資料也同時修改; |
|
創建 |
視圖創建基于select陳述句和基本表資料; create [or replace] [algorithm={undefined|merge|templateble}] view viewName[{columnList}] as select statement [with [cascaded|local] check option] create 創建新視圖,replace替換已有視圖; algorithm選擇的演算法; viewName視圖名稱 ;columnList屬性列;select statement選擇陳述句; [with [cascaded|local] check option]視圖更新時保證在視圖的權限范圍內; l undefined自動選擇演算法| l merge將使用的視圖陳述句和視圖定義結合起來,使得視圖定義的某一部分取代陳述句對應的部分| l templateble將視圖結果存入臨時表,然后用臨時表來執行陳述句; ? cascaded更新視圖時需要滿足所有相關視圖和表的條件;(滿足所有條件) ? local表示可更新視圖時滿足該視圖本身定義的條件即可;(滿足自身條件) 要求具有create view權限和select權限,如果replace要求drop視圖權限; 視圖屬于資料庫,默認在當前資料庫創建; 要在指定資料庫創建視圖,需要使用完全限定名daName.viewName; create view myView as select quantity,price,quantity*price from t; create view myView(quantity,price,total) as select quantity,price,quantity*price from t; create view class(id,name,class) as select student.id,student.name,stuInfo.class from student,stuInfo where student.id=stuInfo.id;
|
|
查看 |
describe viewName; show table status like’viewName’;show table status like ‘viewT’\g; show create view viewName;show create view myView; select*from information_schema.views;
|
|
修改 |
create or replace view myView as select*from t; 可以用create or replace修改,語法同創建; alter view myView as select quantity from t;
|
|
更新 |
update view myView set quantity=5; insert into t values(3,5);更新表,視圖會跟隨更新; delete from myView where price=5; 視圖中的洗掉是通過洗掉基本表中的資料實作的; |
|
洗掉 |
drop view [if exists]viewName[,...] [restrict|cascade] 可以同時洗掉多個視圖,逗號隔開;必須要有drop權限; drop view if exists myView; |
存盤程式=存盤程序+存盤函式
|
創建 |
create procedure create function ■■■存盤程序 create procedure pName([pParameter])[characteristics...]routineBody; create procedure 程序名([引數])[特性...]程序體; 引數:[in|out|inout]pParameter輸入、輸出、可入可出 特性:characteristics
示例
delimiter//將MySQL結束符設定為//,保證procedure的完整性,完事后,再用delimiter;將結束符設定為默認值分號;delimiter也可以指定其他符號作為結束符; delimiter應該避免使用反斜杠\,因為\是SQL的轉義字符;
■■■存盤函式 create function funcName([parameter]) returns type [characteristic...]routineBody create function funcName([引數]) returns type [特性]函式體 如果定義的回傳值型別與實際回傳值型別不同,系統會自動轉型; 只能對procedure指定引數型別in/out/inout; 不能對function指定引數型別in/out/inout,function引數默認in; |
||||||||||||
|
變數 |
■■■變數 宣告陳述句:declare varName[,varName2]...dataType[default value]; declare 變數名 dataType[default 默認值]; declear count int default 0; 默認值可以指定為一個常量,也可以指定為一個運算式; 如果不指定默認值,初始值就是null; 賦值陳述句:set varName=expr[,varName2=expr2]...; declare a,b,c int;set a=1,b=2;set c=a+b; select colName[,...]into varName[,...] tableExpr;
|
||||||||||||
|
例外 |
■■■例外條件:將一個名字和一個錯誤條件相關聯 意義:保證程序/函式在遇到警告或錯誤時能夠繼續運行,避免程式例外停止; declare conditionName condition for [conditionType] l [conditionType]:sqlstate[value]sqlstateValue|mysqlErrorCode l conditionName 條件名稱conditionType條件型別 l sqlstateValue錯誤代碼-長度為5的字串 l mysqlErrorCode錯誤代碼-數值型別 declare command_not_allowed condition for sqlstate’42000’; declare command_not_allowed condition for 1148; ■■■定義例外處理程式: declare handlerType handler for conditionValue[,...] spStatement handlerType:continue|exit|undo conditionValue:sqlstate[value]sqlstateValue |conditionName|sqlWarning|notFound|sqlException|mySqlErrorCode handlerType錯誤處理方式,引數可取3個值continue|exit|undo l continue表示不處理錯誤,繼續執行| l exit表示遇到錯誤馬上推出| l undo表示遇到錯誤后,撤回之前的操作,MySQL中斷暫時不支持這樣的操作; conditionValue表示錯誤型別,可以取值如下: l sqlstate[value]sqlstateValue包含5個字符的錯誤字串; l conditionName表示declare condition定義的錯誤條件名稱; l sqlWarning匹配所有以01開頭的sqlstate錯誤代碼; l notFound匹配所有以02開頭的sqlstate錯誤代碼; l sqlException匹配所有未被sqlWarning和notFound匹配的錯誤代碼; l mySqlErrorCode匹配數值型錯誤代碼; ① 捕獲字串錯誤碼sqlStateValue declare continue handler for sqlstate’42s02’set@info=’no_such_table’; ② 捕獲數字錯誤碼mysqlErrorCode declare continue handler for 1146 set@info’no_such_table’; ③ 捕獲自定義錯誤碼 declare no_such_table conditon for 1146; delare continu handler for no_such_table set@info=’no_such_table’; ④ 捕獲警告錯誤碼sqlWarning declare exit handler for sqlwarning set@info=’error’; ⑤ 捕獲未找到錯誤碼notFound declare exit handler for not found set@info=’no_such_table’; ⑥ 捕獲資料庫例外錯誤碼sqlException declare exit handler for sqlexception set @info=’error’; |
||||||||||||
|
游標 |
游標:用來逐條讀取大量資料 順序:宣告條件和變數→宣告游標→宣告處理程式 順序:宣告declare→打開open→使用fetch→關閉close declare cursorName cursor for selectStatement declare cursorFruit sursor for select name,price from fruits; open cursorName;open cursorFruit; fetch cursorName into varName[,varName2...] fetch cursorFruit into name ,price; close cursorName;close cursorFruit;
|
||||||||||||
|
流程 |
流程控制:條件轉移陳述句 if,case,loop,while,leave,iterate,repeat,,, 每個流程控制,可以包含單個陳述句,可以包含復合陳述句(begin end),可以嵌套;
leave用來退出任何流程控制構造;leave label; iterate用來跳轉到開頭處;可以放在loop,while,repeate內,表示再次回圈;iterate label;
until后面是回圈結束的條件,如果條件為真,則結束回圈,條件為假,繼續回圈;
while后面是進行回圈的條件,條件為真,繼續回圈,條件為假,結束回圈; |
||||||||||||
|
呼叫 |
呼叫存盤程序 call pName([parameter[,...]]); call CountProc(101,@num); select CountFunc(101); |
||||||||||||
|
查看 |
查看存盤程序和函式狀態 show {procedure|function}statuss [like’pattern’] show procedure status like ‘c%’\g; show create {procedure|function}name; show create function test.CountFunc \g; select*from information_schema.routines where routine_name=’sp_name’; select*from information_schema.routines where routine_name=’countFunc’ and routine_type=’function’\g’; |
||||||||||||
|
修改 |
修改存盤程序和函式 alter {procedure|function} name [characteristic...] alter procedure CountProc modifies sql data sql security invoker; alter function countFunc reads sql data comment ‘find name’; |
||||||||||||
|
洗掉 |
洗掉存盤程序和函式 drop {procedure|function} [if exists] name; drop prodedure countProc; drop function countFunc; |
索引index、key
|
創建索引 |
一、創建表的同時創建索引 create table name [colName dataType] [unique|fulltext|spatial] [index|key] [indexName](colName[length]) [asc|desc] create table teacher (id int(11),name varchar(25),salary int(11),index(id));普通索引 create table t1(id int(11),name varchar(25),unique index myindex(id));唯一索引 create table t2(id int(11) not null,name varchar(30) not null, index singleIndex(name(20)));單列索引,只能在string型別上創建,并且索引長度不得大于欄位長度; create table t3(id int(11) not null,name varchar(30)not null,index(id,name(30))); 多列索引;索引長度不能超過string資料長度; 全文索引,只支持MyISAM引擎,創建表時,必須顯示指明引擎型別,否則報錯; create table t4(id int not null,name char(30) not null,fulltext index(name));× ERROR 1214 (HY000): The used table type doesn't support FULLTEXT indexes create table t4(id int not null,name char(30) not null,fulltext index(name))engine=myisam;√ create table t5(g geometry not null ,spatial index myindex (g))engine=myisam ; |
|
二、在已經存在的表上創建索引 ■■使用alter table創建 alter table name add [unique|fulltext|spatial] [index|key] [indexName](colName[length],...)[asc|desc] alter table student add index myIndex(name(10)); 索引的查看方式: l show index from tableName;查看表中索引的詳細資訊;(這里不能用show key) l show create table tableName;查看創建表資訊,包含創建索引資訊; l explain select *from student where name='cat';可以查看該篩選所用的索引; alter table student add unique key(age); 創建唯一索引,要保證該列的資料唯一性,否則報錯; ERROR 1062 (23000): Duplicate entry '22' for key 'age' 關鍵字key和index是等價的; alter table student add key multiKey(name,age); alter table t1 engine=myisam;先修改引擎為MyISAM,然后再添加fulltext索引; alter table t1 add fulltext key(name); ■■用create index創建 create [unique|fulltext|spatial] index indexName on tableName(colName[lenght],...) [asc|desc] create index idIndex on t2(id);普通索引 create unique index nameIndex on t2(name);唯一索引 create index multiIndex on t2(id,name);多列索引 alter table t3 engine=myisam;修改引擎后,再創建全文索引; create index fullIndex on t3(name); |
|
|
洗掉索引 |
■用alter table洗掉索引 alter table tableName drop index indexName;編輯表 洗掉索引; show create table tableName;首先查看包含的索引名稱,然后再針對性洗掉; alter table t3 drop index fullIndex; ■用drop index洗掉索引 drop index indexName on tableName;洗掉某個表上的某個索引; drop index name on t3; 在洗掉表中的列時,該列也會從索引中洗掉; 如果索引中的列全部被洗掉,那么該索引也會被自動洗掉; |
查詢指令
|
查詢 |
查詢是資料庫最重要的功能;可以查詢資料、篩選資料、指定顯示格式; 幾何函式查詢、連接查詢、子查詢、合并查詢、取別名、正則運算式;
select name from stu; select name,age from stu order by age; 單表查詢:所有欄位、指定欄位、指定記錄、空值、多條件查詢、結果排序; 指定欄位:列舉所需查詢的欄位即可,*表示所有欄位; select*from stu where age>10; where:>、<、>=、<=、=、<>、!=、between and、in、like、is null、and、or、distinct select*from student where age between 18 and 28; between a and b等價于x>=a&&x<=b,雙閉區間,如果a>b,則回傳空; select*from student where age in(55,66,77,88); in(a,b,c)表示是()中的任意一個資料,等價于x=a||x=b||x=c; like通配符%表示任意個任意字符,字符個數0-n個,字符任意; ’b%’’%b’’%b%’’a%b’分別表示b開頭,b結尾,包含b,a開頭且b結尾; 下劃線通配符_,表示任意一個字符,字符個數為1,字符任意; 多個邏輯條件查詢:邏輯與and邏輯或or; select*from student where name like 'a%'; select*from student where name like '%o%'; select*from student where name like '%o%y'; select*from student where name like '___'; select*from student where name like '____y'; select*from student where name is null; select*from student where name like 'm%' and age>10; select*from student where name like'%y' or age<10; select distinct field from tableName; select distinct age from student; 排序: order by field;按照某個欄位進行排序,默認升序;降序排序用desc關鍵字; select*from student where name like '%o%' order by age; order by filed1,field2;多列排序,首先第一列必須有相同的值,否則不會按照第二例進行排序; select*from student order by name ,age ; select *from student order by age desc; select*from student order by name desc,age desc; 分組:■■■ group by通常和集合函式一起使用,min,max,avg,count,sum,, select field count(*) as total from table group by field; select name count(*) as total from student group by name; select field1 group_concat(field2) as newField from table group by field1; select name ,group_concat(age) as ages from student group by name; select fiedl1, group_concat(field2) as newField from table group by field1 having count(field2)>1;分組→統計→篩選 select name,group_concat(age) as ages from student group by name having count(age)>1;
where→group by→having with rollup表示統計資料; select name,count(*) as total from student group by name with rollup; select*from table gruop by field1,field2,field3; 多欄位分組,先按照第一個欄位分組(相同項合并),然后在第一個欄位相同的記錄中,按照第二個欄位分組,以此類推; select field from table limit count; 限制查詢結果數量:limit[,位置偏移量]行數 select*from student order by name limit 4; select*from student limit 3,4; 從偏移量3開始共顯示4行;偏移量3表示第四行,第一行的偏移量為0; 集合函式/聚合函式查詢count,sum,avg,max,min,,, count(*)計算表中的總行數,不管是否為空; count(欄位名)計算某欄位的行數,為空不計入; select count(*) as rowCount from student; select count(name) as nameCount from student; select age,count(name) as nameCount from student group by age; select sum(age) as sumAge from student where age<10; select avg(age) as avgAge from student; select min(age)from student; select max(name)from student;字串按照字碼順序進行排序; 連接查詢■ 連接是關系型資料庫的主要特點; 連接查詢包括:內連接、外連接、復核連接; 通過連接運算子實作多個表的查詢; 內連接查詢inner join select suplliers.id supplyer.name fruits.name fruits.price from suppliers,fruits where suplliers.id=fruits.id; select suplliers.id supplyer.name fruits.name fruits.price from suppliers inner join fruits on suplliers.id=fruits.id; 對于兩個表中都有的欄位,需要使用完全限定名,用.連接符號,即表名.欄位名; 從供應商表選擇兩個列,id和name,從水果表選擇兩個列,name和price,共同組成一個新的表;條件是二者的id相同; 自連接查詢(自己連接自己) select s1.name,s2.age from student as s1, student as s2 where s1.age=s2.age and s1.age<10; 如果在一個連接查詢中,涉及到的兩個表是同一個表,這種查詢稱為自連接查詢; 自連接是一種特殊的內連接,兩個相互連接的表在物理上為同一張表,但可以在邏輯上分為兩張表; 為了避免同一個表名稱相同導致的二義性,這里對兩個表分別重命名,也叫別名; 外連接分為 左外連接,右外連接; left join 左連接:回傳包括左表中所有記錄和右表中連接欄位相等的記錄; right join 右連接:回傳包括右表中的所有記錄和左表中連接欄位相等的記錄; select customer.id,orders.num from customers left outer join orders on customers.id=orders.id; select customer.id,orders.num from customer right outer join orders on customer.id=orders.id; select customers.id,orders.num from customers inner join orders on customers.id=orders.id and customers.id=10001; 子查詢也叫嵌套查詢,是一個查詢嵌套在另一個查詢內; 先執行子查詢,將子查詢的結果作為外層查詢的入參,進行第二層查詢過濾; 子查詢常用運算子:any,some,all,in,exists,<,<=,>,>=,=,!=,in,,,, 子查詢可以添加到select,upodate,delete陳述句中,并且可以多層嵌套; select num from tb1 where num>any(select num from tb2); select num from tb1 where num>some(select num from tb2); any等價于some,表示大于集合中的任意一個,就算是滿足條件;相當于邏輯或;也就是大于集合中的最小值即可; select num from tb1 where num >all(select num from tb2); all表示大于集合中的所有,相當于邏輯與;也就是大于集合中的最大值; select num from tb1 where exists(select num from tb2 where num<0); 子查詢是否存在,也就是子查詢是否為空,如果為空,則不再進行外層查詢,如果不為空,也就是子查詢結果存在,就進行外層查詢; select num from tb1 where num in(select num from tb2); in表示是否屬于集合的元素,也就是集合中是否有一個元素與該值相等;相當于交集; select num from tb1 where num not in(select*from tb2); non in表示不在集合中,相當于差集; 合并查詢結果 union[all]可以將兩個查詢結果合并為一個結果集,前提是兩個查詢的列數和資料型別必須相同; select num from tb1 where num>5 union all select num from tb2 where num>5; select num from tb1 union select age from stu; select num from tb1 union all select num from tb2; select num from tb1 union select num from tb2; union all包含重復行;union會自動洗掉重復行;union all效率更高; 表和欄位的別名 表名 [as] 表別名;欄位名 [as] 欄位別名;其中as可以省略; select*from student as s where s.age>10;使用as select*from student s where s.age>10;省略as 在為表取別名時,不能與已存在的表名沖突; select s.name n,s.age a from student s where s.age<10; 欄位別名主要是為了顯示的需要; 正則運算式查詢regexp
select*from student where name regexp('^c');匹配cat Charles Clark select*from student where name regexp('y$');匹配mokey donkey Marry Lily select*from student where name regexp('o.*[stuvwxyz]');mokey donkey Colorful select*from student where name regexp('ap'); apple select*from student where name regexp('co|ca');cat Colorful |
基本指令
|
MySQL指令 |
舉例 |
||||||||||||||||
|
資料庫 |
創建:create database name;create database mydatabase; 洗掉:drop database name;drop database mydatabase; 查看定義:show create database name;show create database mydatabase; 顯示:show databases;顯示資料庫清單(所有資料庫)
|
||||||||||||||||
|
引擎 |
顯示所有存盤引擎:show engines; 顯示默認引擎:show variables like 'storage_engine'; MySQL存盤引擎:InnoDB,MyISAM,Memory,Merge,Archive,Fdedrated,CSV,BLACKHOLE; |
||||||||||||||||
|
資料表 |
選擇資料庫→在該資料庫內創建資料表; use database mydatabase;create table mytable;
顯示所有表:show tables; 查看資料表結構:describe tablename;describe student;desc student; 可以查看:欄位名稱、資料型別、約束資訊; 查看創建表資訊:show create table tablename;show create table mytable; 可以查看:創建表的陳述句、存盤引擎、字符編碼;
修改表名:alter table 舊名稱rename [to] 新名稱; alter table student rename to stu;alter table stu rename student; 修改資料型別:alter table student modify name varchar(50); 修改欄位名稱:必須指定資料型別,不可省略; alter table 表名change 原欄位名 新欄位名 資料型別; alter table tablename change name fullname varchar(50); change可以同時修改欄位名稱和資料型別,若只想修改名稱,則把資料型別寫成原先的型別;若只想修改資料型別,則把名稱寫成原名稱,此時change等效于modify;
添加欄位:alter table 表名 add 欄位名 資料型別 [約束條件][first|after 已有欄位名]; alter table student add sex varchar(10) default ‘male’ after name; alter table student add id int(11) not null first; alter table dogs add sex varchar(11) default 'male' after name; 添加位置有2中選擇:開頭或者某個欄位后面; 洗掉欄位:alter table student drop age; 修改位置:alter table student modify age int(11) after name; 修改存盤引擎:alter table student engine=myISAM;(引擎名稱不區分大小寫) MySQL存盤引擎:InnoDB,MyISAM,Memory,Merge,Archive,Fdedrated,CSV,BLACKHOLE; 洗掉無關聯資料表:洗掉沒有關聯的一個或者多個資料表; drop table [if exists] name1 [,name2,name3...]; drop table if exists stu; 洗掉關聯父表:先洗掉子表再刪父表;先取消子表的外鍵約束,再洗掉父表;
|
||||||||||||||||
|
主鍵和外鍵 |
主鍵:列資料必須唯一且非空;主鍵與記錄一一對應,主鍵是記錄的唯一標識; 主鍵分為單欄位主鍵和多欄位聯合主鍵; [constraint 約束名] primary key(欄位名); primary key (id);id int(11)primary key;primary key(id,name); 外鍵: 用來在兩個表的資料之間建立鏈接; l 外鍵可以使一列或者多列,一個表可以有一個或多個外鍵; l 外鍵可空,若不為空時,必須是另一個表中主鍵的某個值; l 外鍵是一個欄位,可以不是本表的主鍵,但一定是另外一個表的主鍵; l 外鍵主要用來保證資料參考的完整性,定義外鍵后,關聯表中的行不得洗掉; 主表(父表):關聯欄位中主鍵所在的表稱為主表; 從表(子表):關聯欄位中外鍵所在的表稱為從表; [constraint 外鍵名]foreign key 欄位名 references主表名 主鍵列; [constraint 外鍵名]foreign key 欄位名[,欄位名2,...] references主表名 主鍵列[,主鍵列2,...]; constraint fk_name foreign key(students)reference class(id) 關聯:指的是關系型資料庫中,相關表之間的聯系, 子表的外鍵必須關聯父表的主鍵,并且關聯欄位的資料型別必須匹配; 建表以后添加外鍵: 創建表的同時添加外鍵 -> errorType varchar(25), -> constraint fk_errorType foreign key(errorType) references errorType(name) 表創建好之后再添加外鍵: alter table res2 add foreign key(errorType) references errorType(name); 洗掉外鍵約束:alter talbe name drop foreign key fkname; alter table res3 drop foreign key fk_errorType; |
||||||||||||||||
|
約束 |
定義列的同時指定約束,列定義完后為欄位指定約束; 主鍵約束:id int(11)primary key;constraint pk primary key(id); 非空約束:name varchar(25)not null;constraint nnull not null(name); 唯一約束:name varchar(25)unique;constraint uni unique(name); 默認值約束:departId int(11) default(1111); 自增約束:id int(11) primary key auto_increment; 默認初始值1,每增加一條記錄,欄位值加1; 一個表只能有一個欄位使用自增約束; 自增約束的欄位必須是主鍵或主鍵的一部分; |
||||||||||||||||
|
資料 |
■插入資料: insert into tablename (field1,field2,field3)values(v1,v2,v3); insert into student (name,age) value('Tome',33); insert into student value('Joe',88); insert into student values('Trump',77); 關鍵詞,用value或者value均可; 兩種插入方式:指定欄位和不指定欄位; 如果不指定欄位名稱,則插入資料的個數和順序,必須和所有的欄位一一對應; insert into tablename (columnList)values(valueList1),(valueList2)...; insert into student(name,age)values('dog',3),('cat',4); insert into student values('mokey',11),('donkey',22); 將查詢結果插入到表中 insert into tableName1(columnList)select (columnList)from tableName2 where condition; insert into stu(name,age)select name,age from student where age<20; ■修改資料: update 表名 set 欄位名1=值1,欄位名2=值2,欄位名3=值3 where 條件; update stu set name='monkey' where name='mokey'; update stu set name='dongkey',age=22 where name='monkey'; 如果忽略where子句,則更新表中的所有資料; ■洗掉資料: delete from tableName [where condition]; 如果不指定where條件,則洗掉表中的所有資料; delete from student where age=33; delete from student where age between 10 and 90; 修改和洗掉,如果不指定where條件,則會對所有的行進行操作; 一般應先用select陳述句進行查看,再進行修改和洗掉操作; |
|
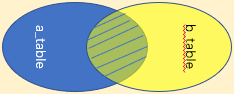
內連接 |
關鍵字:left join on / left outer join on 陳述句:select * from a_table a left join b_table b on a.a_id = b.b_id; 組合兩個表中的記錄,回傳關聯欄位相符的記錄,也就是回傳兩個表的交集(陰影)部分 |
|
|
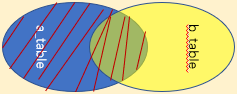
左連接
左外連接
|
關鍵字:left join on / left outer join on 陳述句:select * from a_table a left join b_table b on a.a_id = b.b_id; left join 是left outer join的簡寫,它的全稱是左外連接,是外連接中的一種, 左(外)連接,左表(a_table)的記錄將會全部表示出來,而右表(b_table)只會顯示符合搜索條件的記錄,右表記錄不足的地方均為NULL, |
|
|
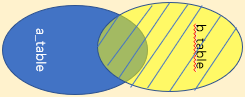
右連接
右外連接
|
關鍵字:right join on / right outer join on 陳述句:select * from a_table a right outer join b_table b on a.a_id = b.b_id; right join是right outer join的簡寫,它的全稱是右外連接,是外連接中的一種, 與左(外)連接相反,右(外)連接,左表(a_table)只會顯示符合搜索條件的記錄,而右表(b_table)的記錄將會全部表示出來,左表記錄不足的地方均為NULL,
|
|
|
|
|
- MySQL陳述句中,字串應當用單引號表示,而不是雙引號,例如’Tom’;
- 表中欄位區分大小寫,name和Name是不同的欄位;
- 命令不區分大小寫,DROP和drop是相同的命令;
- 表名稱不區分大訊息,Student和student被認為是同名的;
- 命令列后面必須跟分號;
通過MySQL命令列修改:(編碼可選)
mysql> set character_set_client=utf8;
mysql> set character_set_connection=utf8;
mysql> set character_set_database=utf8;
mysql> set character_set_results=utf8;
mysql> set character_set_server=utf8;
mysql> set character_set_system=utf8;
mysql> set collation_connection=utf8;
mysql> set collation_database=utf8;
mysql> set collation_server=utf8;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/506169.html
標籤:其他
上一篇:MySQL用戶和權限管理