HDFS
基于流資料模式訪問和處理超大檔案的需求而開發的,
HDFS不適合的應用型別
低延時的資料訪問
HDFS是為高吞吐資料傳輸設計的,因此可能犧牲延時HBase更適合低延時的資料訪問,
大量小檔案
檔案的元資料保存在NameNode的記憶體中, 整個檔案系統的檔案數量會受限于NameNode的記憶體大小,
多方讀寫,需要任意的檔案修改
HDFS采用追加的方式寫入資料,不支持檔案任意修改,不支持多個寫入器(writer),
相關概念
塊(Block)
HDFS檔案系統的檔案被分成塊進行存盤;HDFS被設計出來就是處理大檔案的;
塊默認大小:64M;小于一個塊大小的檔案不會占據整個塊的空間;
好處:
它將超大檔案分成眾多塊,分別存盤在集群的各個機器上;
簡化存盤系統:塊的大小固定,更利于管理,復制,備份,容錯,并且便于元資料去統計、映射;
塊的大小可以自行設定,但是必須是64M的整數倍(hdfs-site.xml)
<property> <name>dfs.block.size</name> <value>512000</value></property>
為什么塊要設定這么大?
目的是:最小化尋址開銷比如:尋址時間需要10ms1.塊=1M,尋址64M檔案,需要640ms2.塊=64M,需要10ms塊的設定不能太大,因為MapReduce任務是按塊來處理的,塊太大,任務少,作業效率就低了;
從用戶角度看,存盤一個檔案在HDFS上,是通過NameNode看到的
從內部角度看,檔案被切分之后存盤在多個DataNode上,元資料存盤在NameNode;
塊存盤位置:在datanode目錄下
每個塊由兩個檔案組成:檔案資訊和meta校驗資訊
-rw-r--r-- 1 root root 355 9月 10 18:21 blk_1073741839-rw-r--r-- 1 root root 11 9月 10 18:21 blk_1073741839_1015.metaNameNode
NameNode、DataNode分別承擔Master、Worker的角色;
作用:
維護元資料資訊(記憶體);即:管理檔案的命名空間(哪個檔案在哪個DataNode)
維護檔案系統樹及整棵樹內的所有檔案和目錄(磁盤);通過這兩個檔案來管理
命名空間鏡像檔案(NameSpace image)
編輯日志檔案(Edit log):只有4M
(存放目錄:hadoop/data/tmp/dfs/name/current/)
回應客戶端請求(記憶體);
元資料形式:
存放目錄:
# 目錄 副本數 Block數 每個Block及副本位置,h為主機名/test/a.log, 3, {blk_1,blk_2}, [{blk_1:[h1,h1,h2]}, {blk_2:[h0,h2,h4]}]
元資料記錄程序:
首先記錄在記憶體中,因為記憶體回應速度塊;
然后追加到Edit log檔案中;
定期再將Edit log檔案內容,持久化到fsimage磁盤檔案中;
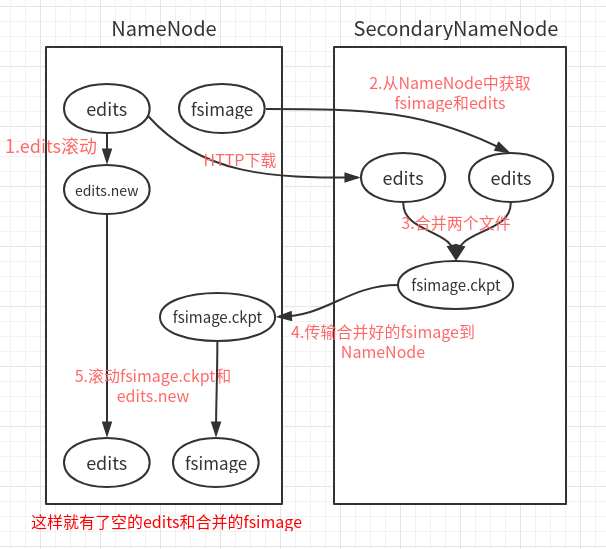
CheckPoint:(安全機制的一種考慮)
即:Edit log檔案持久化到fsimage中的操作;此動作是在Secondary NameNode中進行的;
Secondary NameNode一般運行在一臺單獨的機器上,因為合并需要大量的CPU和記憶體,并且會一直存盤合并過的命名空間鏡像,以免NN宕機;
Edit log檔案快滿了,NN通知SN,進行CheckPoint;
NN停止寫入Edit log,并生成新的New Edit log檔案,來繼續記錄日志;
SN拿到Old Edit log和fsimage副本,并進行合并;
合并完成,再上傳給NN,并洗掉Old Edit log;
DataNode
即:作業節點;
作用:
執行具體的任務:存盤檔案塊,被客戶端和NameNode呼叫;
通過心跳(HeartBeat)定時向NameNode發送所存盤的檔案的塊資訊
作業機制
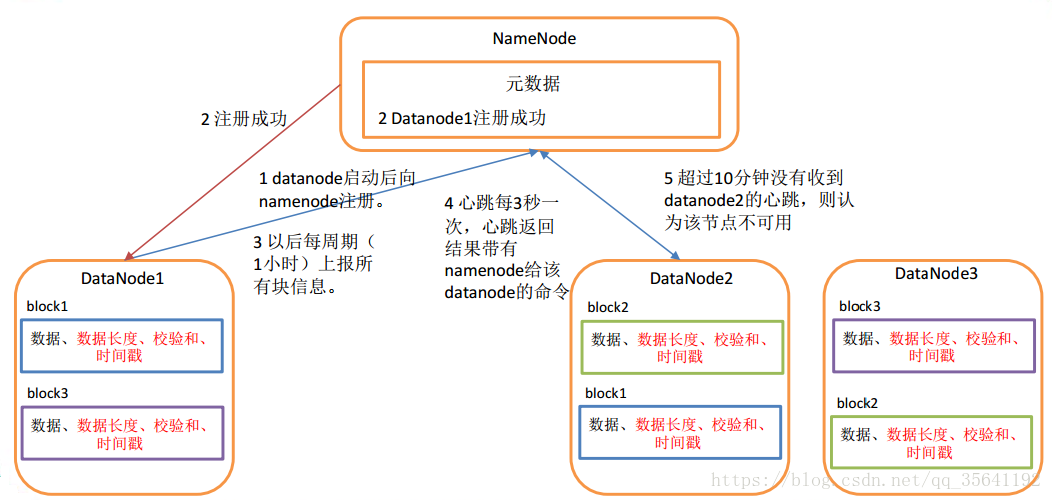
DataNode啟動,對本地磁盤掃描,上報Block資訊給NameNode
通過心跳機制(heartbeat.interval=3s)與NameNode保持聯系,心跳的回傳帶有NameNode命令資訊;
如果NameNode 10分鐘(2* heartbeat.recheck.interval)沒有收到DataNode的心跳,則認為lost,復制其Block到其他DataNode
- 參考圖片,看別人博客那里拿的,后來忘了記下鏈接了,侵刪
-
資料的完整性
創建Block的同時創建checksum,并周期性驗證checksum值;
當DataNode讀取Block的時候,會計算checksum值,與創建時的值對比;
如果值不一樣,認為Block損壞;會繼續讀取副本Block
目錄結構
DataNode檔案不需要格式化;
DataNode版本號:./data/tmp/dfs/data/current
[root@hadoop1 current]# cat VERSION #Tue Sep 10 17:51:35 CST 2019storageID=DS-cc66bc73-0d4d-47a3-8727-69f323c7ae89 # 存盤idclusterID=CID-39e1d84b-8dad-4578-8fdf-f2207368b981 # 集群id,全域唯一cTime=0 # 記錄創建時間datanodeUuid=b5c00298-fbc8-4666-8f35-cc27cb7316b1 # 此node唯一標識碼storageType=DATA_NODE # 存盤型別layoutVersion=-56 # 版本號
資料塊Block版本號:
data/tmp/dfs/data/current/BP-1551134316-192.168.238.129-1568108968205/current
[root@hadoop1 current]# cat VERSION #Tue Sep 10 17:51:35 CST 2019namespaceID=1573478873 # namenode通過此id區分不同的datanodecTime=0 #blockpoolID=BP-1551134316-192.168.238.129-1568108968205 # 唯一標識一個block poollayoutVersion=-56 # 版本號
在集群中添加新的DataNode
參考:
https://blog.csdn.net/qq_35641192/article/details/80303879
HDFS作業流程
讀寫流程
https://www.cnblogs.com/laowangc/p/8949850.html
下面提到的FileSystem是DistributedFileSystem的一個實體物件;
讀
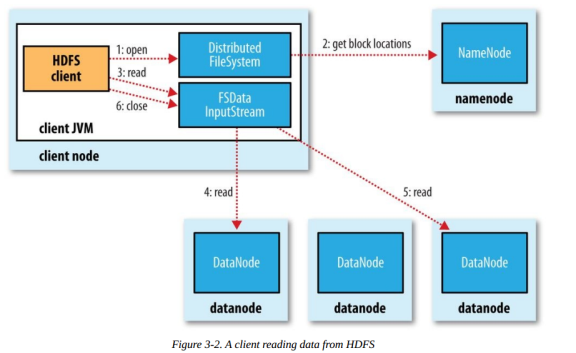
Client呼叫FileSystem.open()方法:
FileSystem通過RPC與NN通信,NN回傳該檔案的部分Block串列(需要的每一個塊在哪個DataNode);
Hadoop會自動算出Client與各個DataNode的距離,選出最短距離的DataNode;
讀取到FSDataInputStream輸入流中,并回傳給客戶端;
Client呼叫FSDataInputStream.read()方法:
開始讀取Block,讀取完一個Block,進行checksum驗證,如果出現錯誤,就從下一個有該拷貝的DataNode中讀取;
每讀取一個Block,就關閉此DataNode的輸入流連接,并找到下一個最近的DataNode繼續讀取;
如果Block串列讀完了,總檔案還沒有結束,就繼續從NN獲取下一批Block串列,重復呼叫read;
Client呼叫FSDataInputStream.close()方法;結束讀取
寫
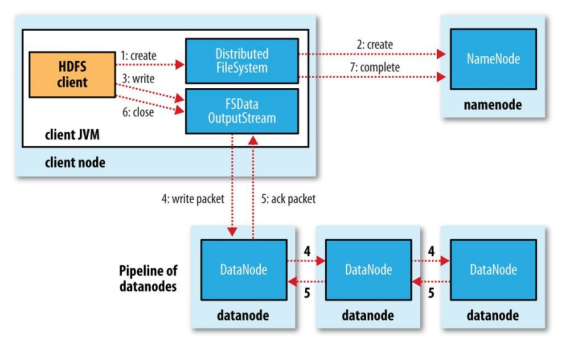
Client呼叫FileSystem的create()方法:
FileSystem向NN發出請求,在NN的namespace里面創建一個新的檔案,但是并不關聯任何DataNode;
NN檢查檔案是否已經存在、操作權限;如果檢查通過,NN記錄新檔案資訊,并在某一個DataNode上創建資料塊;
NN回傳一個FSDataOutputStream物件,用于Client寫入資料;
Client呼叫輸出流的FSDataOutputStream.write()方法:
開始寫入資料,首先FSDataOutputStream會將資料分割成一個個包,放入資料佇列;
根據NN回傳的副本數,以及DataNode串列,先寫入第一個DataNode,此DataNode會推送給下一個DataNode,以此類推,直到副本數創建完畢;(每次都會向佇列回傳確認資訊)
Client呼叫輸出流的FSDataOutputStream.close()方法:
完成寫入之后,呼叫close方法,flush資料佇列的資料包,NN回傳成功資訊;
HDFS基本命令
命令列鍵入:hadoop fs 即可查看命令
1.創建目錄:(/ 為根目錄)
hadoop fs -mkdir /testhadoop fs -mkdir /test/input (前提test目錄必須存在)2.查看檔案串列:(查看根目錄的檔案串列)
hadoop fs -ls /
3.上傳檔案到HDFS:
hadoop fs -put /home/whr/a.dat /test/input/a.dat # 復制:hadoop fs -copyFromLocal -f /home/whr/a.dat /test/input/a.dat
4.下載檔案到本地:
hadoop fs -get /test/input/a.dat /home/whr/a.dat# 復制:hadoop fs -copyToLocal -f /test/input/a.dat /home/whr/a.dat
5.查看HDFS 檔案內容:
hadoop fs -cat /test/input/a.dat
6.洗掉HDFS檔案:
hadoop fs -rm /test/input/a.dat
7.修改hdfs檔案的用戶:用戶組
hadoop fs -chown user_1:group_1 /a.txt
8.查看/test磁盤空間
hadoop fs -df /test
9.洗掉全部
hadoop fs -rm -r hdfs://whr-PC:9000/*
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/50624.html
標籤:大數據
上一篇:怎么將ETL技術落地