DataNode作業機制
- 一個資料塊在DataNode上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗和,以及時間戳,
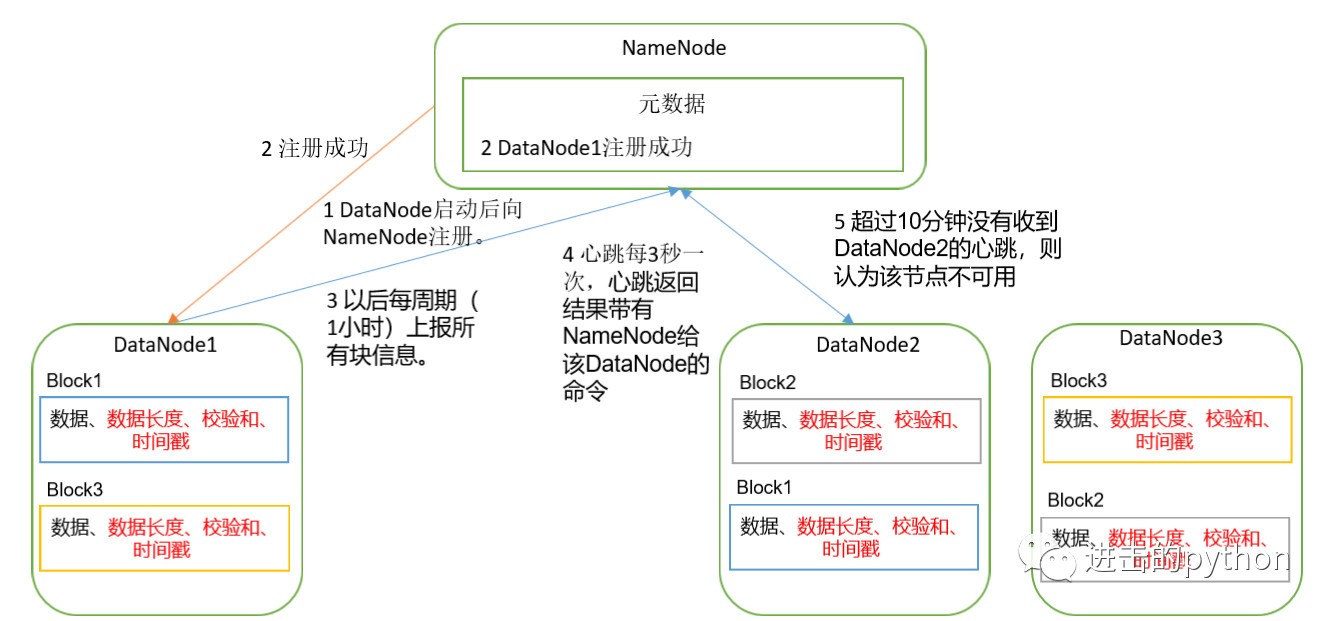
- DataNode啟動后向NameNode注冊,通過后,周期性(1小時)的向NameNode上報所有的塊資訊,
- DataNode與NameNode之間有一個心跳事件,心跳是每3秒一次,心跳回傳結果帶有NameNode給該DataNode的命令,如果超過10分鐘沒有收到某個DataNode的心跳,則認為該節點不可用,
- 集群運行中可以安全加入和退出一些機器
資料完整性
思考:如果電腦磁盤里面存盤的資料是控制高鐵信號燈的紅燈信號(1)和綠燈信號(0),但是存盤該資料的磁盤壞了,一直顯示是綠燈,是否很危險?
同理,DataNode節點上的資料損壞了,卻沒有發現,是否也很危險,那么如何解決呢?
- 保證資料完整性的方法
- 當DataNode讀取Block的時候,它會計算CheckSum(校驗和)
- 如果計算后的CheckSum,與Block創建時值不一樣,說明Block已經損壞
- Client讀取其他DataNode上的Block
- DataNode在其檔案創建后周期驗證CheckSum,如下圖:

掉線時引數設定
DataNode行程死亡或者網路故障造成DataNode無法與NameNode通信時的TimeOut引數設定
- NameNode不會立即把該節點判斷為死亡,要經過一段時間,這段時間稱作超時時長
- HDFS默認的超時時長為10分鐘+30秒
- 超時時長的計算公式為:
# dfs.namenode.heartbeat.recheck-interval默認為300000ms,dfs.heartbeat.interval默認為5s
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
- 實際開發的時候,可以根據自己服務器的情況進行調整,比如服務器性能比較低,那么可以適當的把時間調長;如果服務器性能很好,那么可以適當縮短,
服役新資料節點
需求:隨著公司業務的增長或者重大活動(例如雙11),資料量越來越大,原有的資料節點的容量已經不能滿足存盤資料的需求,需要在原有集群基礎上動態添加新的資料節點,
- 步驟:
- 克隆一臺虛擬機
- 修改IP地址和主機名稱
- 洗掉原來HDFS檔案系統中留存的data和logs檔案
- 直接單點啟動節點即可
退役舊資料節點
退役舊資料節點有兩種方式:添加白名單和黑名單退役
添加白名單
- 步驟:
- 在NameNode的
hadoop安裝目錄/etc/hadoop目錄下創建dfs.hosts檔案 - 添加白名單主機名稱
- 在NameNode的hdfs-site.xml組態檔中增加dfs.hosts屬性
<property>
<name>dfs.hosts</name>
# dfs.hosts檔案所在路徑
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
- 組態檔同步到集群其它節點
- 重繪NameNode
[kocdaniel@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
- 更新ResourceManager節點
[kocdaniel@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
- 如果資料不均衡,可以用命令實作集群的再平衡
[kocdaniel@hadoop102 sbin]$ ./start-balancer.sh
黑名單退役
- 步驟:
- 在NameNode的
hadoop安裝目錄/etc/hadoop目錄下創建dfs.hosts.exclude檔案 - 添加要退役的主機名稱
- 在NameNode的hdfs-site.xml組態檔中增加dfs.hosts.exclude屬性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
- 組態檔同步到集群其它節點
- 重繪NameNode、重繪ResourceManager
[kocdaniel@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[kocdaniel@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
- 檢查Web瀏覽器,退役節點的狀態為decommission in progress(退役中),說明資料節點正在復制塊到其他節點
- 等待退役節點狀態為decommissioned(所有塊已經復制完成),停止該節點及節點資源管理器,
- 注意:如果副本數是3,服役的節點小于等于3,是不能退役成功的,需要修改副本數后才能退役
- 注意:不允許白名單和黑名單中同時出現同一個主機名稱,
兩者的不同
- 添加白名單比較暴躁,會直接把要退役的節點服務關掉,不復制資料
- 黑名單退役,會將要退役的節點服務器的資料復制到其它節點上,不會直接關閉節點服務,比較慢
DataNode多目錄配置
- DataNode也可以配置成多個目錄,每個目錄存盤的資料不一樣,即:資料不是副本,與NameNode多目錄不同
- 作用:保證所有磁盤都被利用均衡,類似于windows中的磁盤磁區
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/50629.html
標籤:大數據