
Hbase最核心但也是最難理解的就是資料模型,由于與傳統的關系型資料庫不同,雖然Hbase也有表(Table),也有行(Row)和列(Column),但是與關系型資料庫不同的是Hbase有一個列族(Column Family)的概念,它將一列或者多列組織在一起,HBase必須屬于某一個列族,
行和列交叉點稱為單元格(Cell),單元格時版本化的,單元格的內容,也就是列的值是不可分割的位元組陣列,
HBase沒有資料型別,任何列值都被轉換成位元組陣列進行存盤,
HBase表中的行是通過行鍵(Rowkey)進行區分的,行鍵也是用來唯一確定一行的標識,
HBase中的行按Rowkey排序,排序方式采用字典順序,
這些都是HBase的邏輯結果,他的物理結構也和傳統關系型資料庫有很大不同,

邏輯模型
HBase的邏輯模型源自Google的BigTable模型,可以理解為一個稀疏的,長期存盤的,多維度的和排序的映射表,
以下示例是 BigTable 論文第 2 頁上的一個略微修改的形式,有一個名為webtable的表包含兩行(com.cnn.www和com.example.www)和三個列族,名為contents,anchor和people,
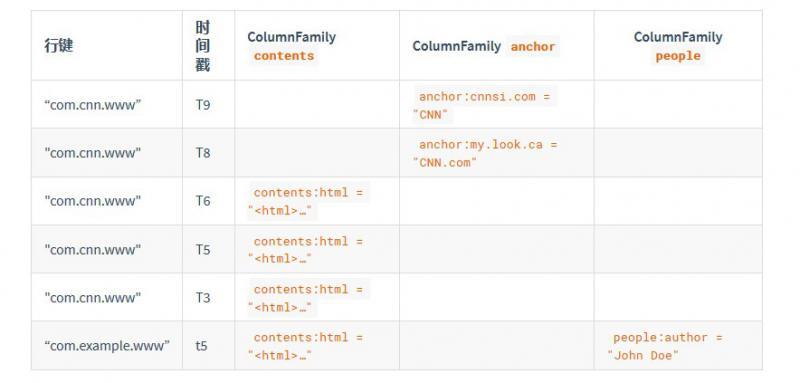
在此示例中,對于第一行(com.cnn.www),anchor包含兩列(anchor:cssnsi.com,anchor:my.look.ca),contents包含一列(contents:html),此示例包含具有行鍵com.cnn.www的行的 5 個版本,以及具有行鍵com.example.www的行的一個版本, contents:html列限定符包含給定網站的整個HTML, anchor列族的限定符每個都包含指向該行所代表的站點的外部站點的鏈接,以及它在其鏈接的anchor中使用的文本, people列系串列示與該站點關聯的人員,
此表中看起來為空的單元格在 HBase 中不占用空間,或實際上不存在,這就是HBase“稀疏”的原因,表格視圖不是查看 HBase 中資料的唯一方法,甚至也不是最準確的方法,以下表示與多維映射相同的資訊,這只是一個出于演示目的的模型,可能并不完全準確,
{
"com.cnn.www": {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
}
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
people: {}
}
"com.example.www": {
contents: {
t5: contents:html: "<html>..."
}
anchor: {}
people: {
t5: people:author: "John Doe"
}
}
}
物理模型
雖然Hbase表可以看作一組稀疏的行,但在物理意義上它們是按照列族存盤的,所以列是可以隨時添加的,
Hbase是面向列的,存放行的不同列的物理檔案,一個列族存放在多個HFile中,最重要的是一個列族的資料會被同一個Region管理,
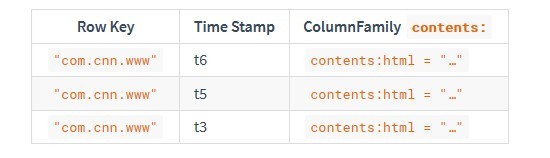
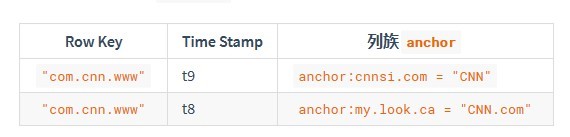
空單元格不占據物理存盤空間,因此,在時間戳t8處對contents:html列的值的請求將不回傳任何值,類似地,在時間戳t9處對anchor:my.look.ca值的請求將不回傳任何值,但是,如果未提供時間戳,則將回傳特定列的最新值,給定多個版本,最新版本也是第一個版本,因為時間戳按降序存盤,因此,如果沒有指定時間戳,則對行com.cnn.www中所有列的值的請求將是:來自時間戳t6的contents:html的值,來自時間戳t9的anchor:cnnsi.com的值,來自時間戳t8的anchor:my.look.ca,
資料模型操作
四個主要的資料模型操作是 Get,Put,Scan 和 Delete,通過實體化Table進行操作,
版本問題: Rowkey、Column(列族和列)、Version組合在一起稱為Hbase中的一個單元格,
Rowkey和Column的值是用位元組陣串列示的,Version則是用一個長整型表示的,
Get
操作回傳指定行的屬性,Get是在Scan基礎上實作的,在默認情況下,如果沒有指定版本,一旦使用Get操作,會回傳最近版本的Cell,
要回傳多個版本,需要設定Get.setMaxVersions()
要回傳最新版本以外的其他版本,請參見 Get.setTimeRange()
默認版本Get示例
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Get get = new Get(Bytes.toBytes("row1"));
Result r = table.get(get);
byte[] b = r.getValue(CF, ATTR); // returns current version of value
給定版本的Get示例
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Get get = new Get(Bytes.toBytes("row1"));
get.setMaxVersions(3); // will return last 3 versions of row
Result r = table.get(get);
byte[] b = r.getValue(CF, ATTR); // returns current version of value
List<KeyValue> kv = r.getColumn(CF, ATTR); // returns all versions of this column
PUT
執行 put 總是在某個時間戳創建cell的新版本,默認情況下,系統使用服務器的currentTimeMillis,但您可以在針對每一列指定版本(=長整數),這意味著您可以在過去或將來指定時間,或者將long值用于非時間目的,
隱式版本示例
HBase 將使用當前時間隱式地對以下 Put 進行版本控制,
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Put put = new Put(Bytes.toBytes(row));
put.add(CF, ATTR, Bytes.toBytes( data));
table.put(put);
顯式版本示例
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Put put = new Put( Bytes.toBytes(row));
long explicitTimeInMs = 555; // just an example
put.add(CF, ATTR, explicitTimeInMs, Bytes.toBytes(data));
table.put(put);
DELETE
洗掉通過 Table.delete]執行,
有三種不同型別的內部洗掉標記,
- 洗掉:對于特定版本的列,
- 洗掉列:適用于列的所有版本,
- 洗掉系列:適用于特定 ColumnFamily 的所有列
SCAN
掃描表
下面是對表進行掃描的示例,假設一個表填充了具有鍵“row1”,“row2”,“row3”的行,然后另一組是具有鍵“abc1”,“abc2”和“abc3”的行,以下示例將展示如何設定 Scan 實體以回傳以“row”開頭的行,
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Table table = ... // instantiate a Table instance
Scan scan = new Scan();
scan.addColumn(CF, ATTR);
scan.setRowPrefixFilter(Bytes.toBytes("row"));
ResultScanner rs = table.getScanner(scan);
try {
for (Result r = rs.next(); r != null; r = rs.next()) {
// process result...
}
} finally {
rs.close(); // always close the ResultScanner!
}
更多實時計算,Hbase,Flink,Kafka等相關技術博文,歡迎關注實時流式計算

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/50643.html
標籤:大數據
上一篇:MapReduce之Job提交流程原始碼和切片原始碼分析
下一篇:zookeeper特性與節點說明