
Hbase的表結構設計與關系型資料庫有很多不同,主要是Hbase有Rowkey和列族、timestamp這幾個全新的概念,如何設計表結構就非常的重要,

創建
Hbase就是通過 表 Rowkey 列族 timestamp確定一行資料,
這與關系型資料庫完全不同:
| 屬性 | HBase | RDBMS |
|---|---|---|
| 資料型別 | 只有字串 | 豐富的資料型別 |
| 資料操作 | 簡單的增刪改查 不支持join | 各種函式和表連接 |
| 存盤模式 | 基于列式存盤 | 基于表格結構和行式存盤 |
| 資料保護 | 更新后仍然保留舊版本 | 替換 |
| 可伸縮性 | 輕易的增加節點,兼容性高 | 需要中間層,犧牲功能 |
所以Hbase需要考慮的因素有:
1、這個表應該有多少列族
2、列族使用什么資料
3、每個列族有多少列
4、列名是什么
5、單元應該存放什么資料
6、每個單元存盤多少時間版本
7、Rowkey結構是什么,應該包含什么資訊
需要注意的點:
1、Join
Hbase中沒有join 所以需要大表結構 行記錄加關鍵字 解決這個問題
2、Rowkey
Rowkey設計非常重要 由于Hbase是有序的 需要考慮前綴后綴問題
可以通過Hbase Shell和 Java Api創建:
Configuration config = HBaseConfiguration.create();
Admin admin = new Admin(conf);
TableName table = TableName.valueOf("myTable");
admin.disableTable(table);
HColumnDescriptor cf1 = ...;
admin.addColumn(table, cf1); // adding new ColumnFamily
HColumnDescriptor cf2 = ...;
admin.modifyColumn(table, cf2); // modifying existing ColumnFamily
admin.enableTable(table);
Rowkey設計
Rowkey是不可分割的位元組陣列,按字典序存盤在表中,
由于:Region基于Rowkey為一個區間的行提供服務 HFile在硬碟上存盤有序的行 所以Rowkey就極大的影響了Hbase的性能,
Rowkey就是索引,如果不清楚Rowkey就只能掃描全表,那么性能將會大幅度下降,
這里用影片熱度排行榜舉例:
1、Rowkey是以字典序從大到小
原生Hbase只支持從小到大排序,要想實作從大到小,可以采用 Rowkey=Integer.MAX_VALUE-Rowkey的方式,在應用層再轉回來完成需求,
2、Rowkey盡量散列
Rowkey要盡量散列,這樣可以保證資料不在一個Region上,從而避免了讀寫的集中,
比如我們可以設計 userid_videoid 拼接字串 這樣的話user就會不均勻,
有三種辦法解決: 反轉userid 散列userid 將userid取模后進行MD5加密 取前6位加入userid中
3、Rowkey長度要盡量短
Rowkey過長,存盤開銷會大,
Rowkey過長,會導致記憶體的利用率降低,進而降低索引命中率,
列族
列族是一些列的集合,一個列族所有成員都有同樣的前綴,比如courses:history 和 courses:math都是courses列族的成員,冒號是分隔符,列族前綴必須是可輸出字符,列可由任意位元組陣列組成,
列族必須在表建立的時候宣告,列則不需要特別宣告,用戶隨時可以創建新列,
經驗法則:
- 目標是把 region 的大小限制在 10 到 50 GB 之間,
- 目標是限制 cell 的大小在 10 MB 之內,如果使用的是 mob型別,限制在 50 MB 之內,否則,考慮把 cell 的資料存盤在 HDFS 中,并在 HBase 中存盤指向該資料的指標,
- 典型的 scheme 每張表包含 1 到 3 個列族,HBase 表設計不應當和 RDBMS 表設計類似,
- 對于擁有 1 或 2 個列族的表來說,50-100 個 region 是比較合適的,請記住, region 是列族的連續段,
- 保持列族名稱盡可能短,每個值都會存盤列族的名稱(忽略前綴編碼),它們不應該像典型 RDBMS 那樣,是自檔案化,描述性的名稱,
- 如果你正在存盤基于時間的機器資料或者日志資訊,并且 row key 是基于設備 ID 或者服務 ID + 時間,最侄訓出現這樣一種情況,即更舊的資料 region 永遠不會有額外寫入,在這種情況下,最侄訓存在少量的活動 region 和大量不會再有新寫入的 region,對于這種情況,可以接受更多的 region 數量,因為資源的消耗只取決于活動 region,
- 如果只有一個列族會頻繁寫,那么只讓這個列族占用記憶體,當分配資源的時候注意寫入模式,
實體
店鋪與商品
店鋪shop 商品 item 是多對多的關系
RDBMS表結構設計:
商鋪表:
| 列名 | 列含義 |
|---|---|
| id | 主鍵 |
| name | 店鋪名稱 |
| address | 所在地 |
| regdate | 注冊日期 |
商品表:
| 列名 | 列含義 |
|---|---|
| id | 主鍵 |
| name | 商品名稱 |
| price | 價格 |
| details | 商品詳情 |
| title | 展示名稱 |
關系表:
| 列名 | 列含義 |
|---|---|
| shop_id | 店鋪主鍵 |
| item_id | 商品主鍵 |
| type | 關聯型別 |
Hbase表結構設計:
店鋪表:

商品表:

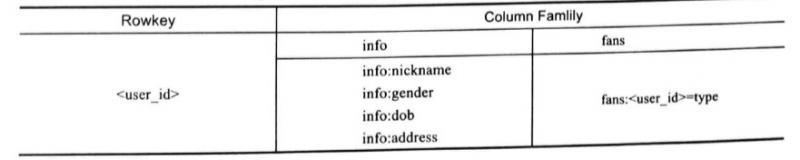
微博用戶與粉絲
用戶與粉絲是一對多
RDBMS表結構設計:
用戶表:
| 列名 | 列含義 |
|---|---|
| id | 主鍵 |
| nickname | 用戶名 |
粉絲對應表:
| 列名 | 列含義 |
|---|---|
| user_id | 用戶id |
| fans_id | 粉絲id |
Hbase表結構設計:
更多實時計算,Hbase,Flink,Kafka等相關技術博文,歡迎關注實時流式計算

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/50662.html
標籤:大數據
上一篇:ES 32 - Elasticsearch 資料建模的探索與實踐
下一篇:B+樹索引