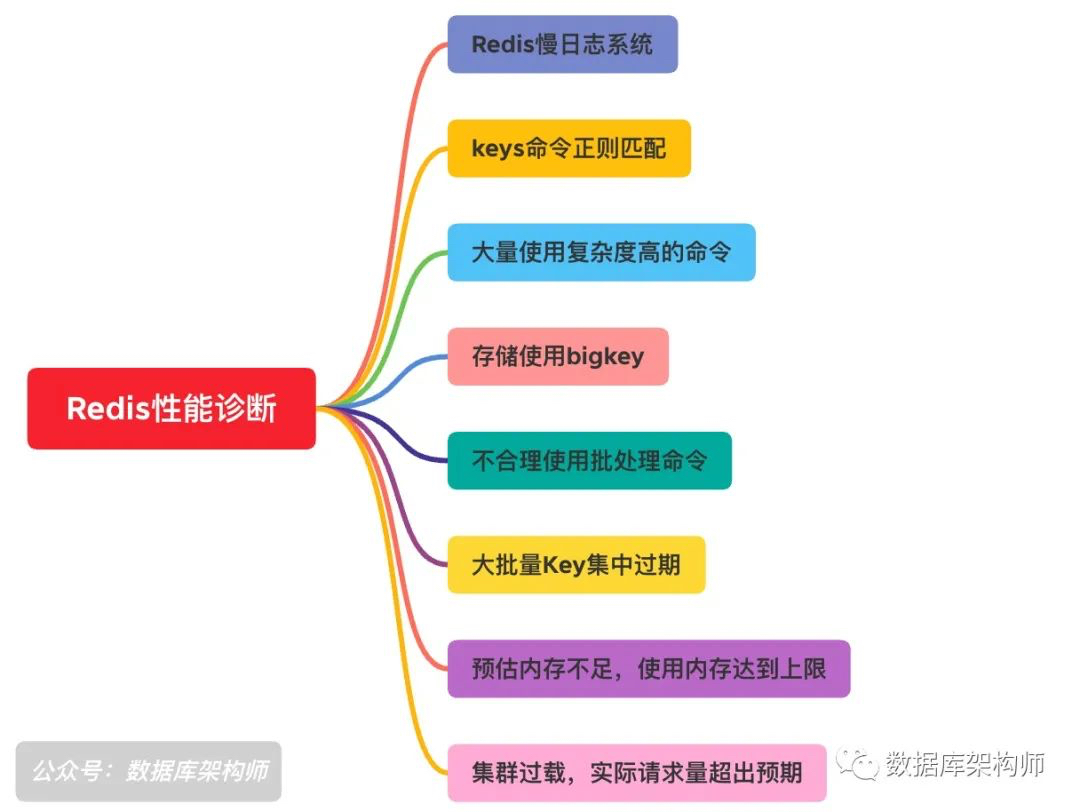
(本文首發于“資料庫架構師”公號,訂閱“資料庫架構師”公號,一起學習資料庫技術) 本篇為Redis性能問題診斷系列的第二篇,本文主要從應用發起的典型命令使用上進行講解,由于Redis為單執行緒服務架構,對于一些命令如果使用不當會極大的影響Redis的性能表現,這里也會對不合理的使用方式給出優化解決方案,
 一、Redis慢日志功能
分析Redis訪問變慢,其中有個最基礎的方法就是先去看Redis是否有慢日志【就像MySQL的慢SQL一樣】,Redis提供了一個簡單的慢命令統計記錄功能,它會記錄有哪些命令在執行時耗時較長,Redis慢日志功能由兩個核心引數控制:
slowlog-log-slower-than 1000
#慢日志命令執行閾值,這里指超過1ms就會被記錄【單位為微秒】
slowlog-max-len 4096
#保留慢日志命令的個數,類似一個先進先出的佇列,超過4096個最早的就會被清理
Redis的這個慢日志功能比較粗糙簡單,有個嚴重的不足:沒有持久化記錄能力,
由于Redis的慢日志記錄都在記憶體中,不像MySQL會持久化到檔案里,那么如果慢日志產生較快,即使設定的slowlog-max-len比較大也會很快被填滿,診斷問題時也就不能統計到那個時間段產生的所有慢命令詳情,
為了避免產生的慢日志被清理,目前一個折中的解決方案是寫一個收集程式周期性的將新增慢命令查出并記錄到MySQL或者本地檔案中,以備事后分析,但是這個頻率一般都是分鐘級,Redis處理的吞吐能力又太大,在慢命令較多的情況下往往也不能全部記錄下來,
配置好慢日志相關閾值后,可以執行以下命令查詢最近的慢日志記錄了:
127.0.0.1:6379> SLOWLOG get 5
1) 1) (integer) 42343
2) (integer) 1653659194 #慢日志產生的時間戳
3) (integer) 73536 #慢日志執行的耗時
4) 1) "KEYS" #慢日志命令詳情
2) "permission::userMenuList:*"
5) "192.168.1.11:20504" #慢日志命令發起來源IP【4.0及以后版本支持】
6) ""2) 1) (integer) 42342
2) (integer) 1653659194
3) (integer) 73650
4) 1) "KEYS"
2) "userPermission:*"
5) "192.168.1.10:20362"
6) ""
3) 1) (integer) 42341
2) (integer) 1653659193
3) (integer) 81505
4) 1) "KEYS"
2) "userRole:*"
5) "192.168.1.13:19926"
6) ""
二、幾種典型導致Redis變慢的不合理使用方式
1.使用keys命令進行正則匹配
Keys的正則匹配是阻塞式的、全量掃描過濾,這對于單執行緒服務的Redis來說是致命的,僅僅幾十萬個Key的匹配查詢在高并發訪問下就有可能將Redis打崩潰!這其實就像MySQL的無索引查詢大表資料,全表掃描狀態下幾個并發查詢就可能會將資料庫堵死,
redis> SLOWLOG get 5
1) 1) (integer) 42343
2) (integer) 1653659194
3) (integer) 73536
4) 1) "KEYS"
2) "Testper::userList:*"
5) "192.168.1.10:20504"
6) ""
2) 1) (integer) 42342
2) (integer) 1653659194
3) (integer) 73650
4) 1) "KEYS"
2) "TestuserPermission:*"
5) "192.168.1.11:20362"
6) ""
3) 1) (integer) 42341
2) (integer) 1653659193
3) (integer) 81505
4) 1) "KEYS"
2) "TestuserRole:*"
5) "192.168.1.12:19926"
6) ""
上述示例中使用Keys來模糊查詢某些Key,每次的執行都在70ms以上,嚴重影響了正常的Redis回應時長和吞吐,
針對這種問題的一個解決方案是使用scan代替keys,這是一個查詢迭代命令,用于迭代當前資料庫中的快取資料,它是一個基于游標的迭代器,每次被呼叫之后, 都會向用戶回傳一個新的游標, 用戶在下次迭代時需要使用這個新游標作為Scan命令的游標引數, 以此來延續之前的迭代程序,具體的命令語法這里不再詳述,
2.大量使用了復雜度較高的命令
(1)應用中高頻使用了 O(N) 及以上復雜度的命令,例如:SUNION、SORT、ZUNIONSTORE、ZINTERSTORE 聚合類命令,SORT命令的時間復雜度:O(N+M*log(M)), N 為要排序的串列或集合內的元素數量, M 為要回傳的元素數量,
這種導致Redis請求變慢的原因是,Redis 在操作資料排序時,時間復雜度過高,要花費更多的 CPU計算資源,
(2)使用 O(N) 復雜度的命令,但 N 的值非常大,比如hgetall、smembers、lrange、zrange等命令,
這種變慢的原因在于,Redis 一次需要回傳給客戶端的資料過多,需要花費更多時間在資料組裝和網路傳輸中,對于hgetall、smembers這種命令,需要警惕專案剛上線之初hash、set或者list存盤的成員個數較少,但是隨著業務發展成員數量極有可能會膨脹的非常大,如果仍然采用上述命令不加控制,會極大拖累整個Redis服務的回應時間,
針對這兩種情況還都可以從資源使用率層面來分析,如果應用程式訪問 Redis 的QPS不是很大,但 Redis 實體的 CPU 使用率卻很高,那么很有可能是使用了復雜度過高的命令導致的,
因為Redis 是單執行緒處理請求的,如果你經常使用以上復雜度較高的命令,那么當 Redis 處理程式請求時,一旦前面某個命令發生耗時較長,就會導致后面的請求發生阻塞排隊,對于應用程式來說,回應延遲也會變長,
3.存盤使用了bigkey
在分析慢日志發現很多請求并不是復雜度高的命令,都是一些del、set、hset等的低復雜度命令,那么就要評估是否寫入了大key,
在往Redis寫入資料時,需要為新資料分配記憶體塊,相對應的,當洗掉資料時,Redis也會釋放對應的記憶體空間,如果一個 key 寫入Redis的值非常大,那么在分配記憶體時就會相對比較耗時,同樣的當洗掉這個 key 時,釋放記憶體也會比較耗時,這種被稱為bigKey,
當然這個描述仍然比較寬泛,因為Redis中的資料庫結構型別比較多,更完善的一些說法可以這么定義:將含有較大資料或含有大量成員、串列數的Key定義為bigkey,
我們一般要求研發使用Redis時,對于String型別Value大小不要超過1KB,
大Key帶來的問題比較多,主要有下面幾種情況:
一、Redis慢日志功能
分析Redis訪問變慢,其中有個最基礎的方法就是先去看Redis是否有慢日志【就像MySQL的慢SQL一樣】,Redis提供了一個簡單的慢命令統計記錄功能,它會記錄有哪些命令在執行時耗時較長,Redis慢日志功能由兩個核心引數控制:
slowlog-log-slower-than 1000
#慢日志命令執行閾值,這里指超過1ms就會被記錄【單位為微秒】
slowlog-max-len 4096
#保留慢日志命令的個數,類似一個先進先出的佇列,超過4096個最早的就會被清理
Redis的這個慢日志功能比較粗糙簡單,有個嚴重的不足:沒有持久化記錄能力,
由于Redis的慢日志記錄都在記憶體中,不像MySQL會持久化到檔案里,那么如果慢日志產生較快,即使設定的slowlog-max-len比較大也會很快被填滿,診斷問題時也就不能統計到那個時間段產生的所有慢命令詳情,
為了避免產生的慢日志被清理,目前一個折中的解決方案是寫一個收集程式周期性的將新增慢命令查出并記錄到MySQL或者本地檔案中,以備事后分析,但是這個頻率一般都是分鐘級,Redis處理的吞吐能力又太大,在慢命令較多的情況下往往也不能全部記錄下來,
配置好慢日志相關閾值后,可以執行以下命令查詢最近的慢日志記錄了:
127.0.0.1:6379> SLOWLOG get 5
1) 1) (integer) 42343
2) (integer) 1653659194 #慢日志產生的時間戳
3) (integer) 73536 #慢日志執行的耗時
4) 1) "KEYS" #慢日志命令詳情
2) "permission::userMenuList:*"
5) "192.168.1.11:20504" #慢日志命令發起來源IP【4.0及以后版本支持】
6) ""2) 1) (integer) 42342
2) (integer) 1653659194
3) (integer) 73650
4) 1) "KEYS"
2) "userPermission:*"
5) "192.168.1.10:20362"
6) ""
3) 1) (integer) 42341
2) (integer) 1653659193
3) (integer) 81505
4) 1) "KEYS"
2) "userRole:*"
5) "192.168.1.13:19926"
6) ""
二、幾種典型導致Redis變慢的不合理使用方式
1.使用keys命令進行正則匹配
Keys的正則匹配是阻塞式的、全量掃描過濾,這對于單執行緒服務的Redis來說是致命的,僅僅幾十萬個Key的匹配查詢在高并發訪問下就有可能將Redis打崩潰!這其實就像MySQL的無索引查詢大表資料,全表掃描狀態下幾個并發查詢就可能會將資料庫堵死,
redis> SLOWLOG get 5
1) 1) (integer) 42343
2) (integer) 1653659194
3) (integer) 73536
4) 1) "KEYS"
2) "Testper::userList:*"
5) "192.168.1.10:20504"
6) ""
2) 1) (integer) 42342
2) (integer) 1653659194
3) (integer) 73650
4) 1) "KEYS"
2) "TestuserPermission:*"
5) "192.168.1.11:20362"
6) ""
3) 1) (integer) 42341
2) (integer) 1653659193
3) (integer) 81505
4) 1) "KEYS"
2) "TestuserRole:*"
5) "192.168.1.12:19926"
6) ""
上述示例中使用Keys來模糊查詢某些Key,每次的執行都在70ms以上,嚴重影響了正常的Redis回應時長和吞吐,
針對這種問題的一個解決方案是使用scan代替keys,這是一個查詢迭代命令,用于迭代當前資料庫中的快取資料,它是一個基于游標的迭代器,每次被呼叫之后, 都會向用戶回傳一個新的游標, 用戶在下次迭代時需要使用這個新游標作為Scan命令的游標引數, 以此來延續之前的迭代程序,具體的命令語法這里不再詳述,
2.大量使用了復雜度較高的命令
(1)應用中高頻使用了 O(N) 及以上復雜度的命令,例如:SUNION、SORT、ZUNIONSTORE、ZINTERSTORE 聚合類命令,SORT命令的時間復雜度:O(N+M*log(M)), N 為要排序的串列或集合內的元素數量, M 為要回傳的元素數量,
這種導致Redis請求變慢的原因是,Redis 在操作資料排序時,時間復雜度過高,要花費更多的 CPU計算資源,
(2)使用 O(N) 復雜度的命令,但 N 的值非常大,比如hgetall、smembers、lrange、zrange等命令,
這種變慢的原因在于,Redis 一次需要回傳給客戶端的資料過多,需要花費更多時間在資料組裝和網路傳輸中,對于hgetall、smembers這種命令,需要警惕專案剛上線之初hash、set或者list存盤的成員個數較少,但是隨著業務發展成員數量極有可能會膨脹的非常大,如果仍然采用上述命令不加控制,會極大拖累整個Redis服務的回應時間,
針對這兩種情況還都可以從資源使用率層面來分析,如果應用程式訪問 Redis 的QPS不是很大,但 Redis 實體的 CPU 使用率卻很高,那么很有可能是使用了復雜度過高的命令導致的,
因為Redis 是單執行緒處理請求的,如果你經常使用以上復雜度較高的命令,那么當 Redis 處理程式請求時,一旦前面某個命令發生耗時較長,就會導致后面的請求發生阻塞排隊,對于應用程式來說,回應延遲也會變長,
3.存盤使用了bigkey
在分析慢日志發現很多請求并不是復雜度高的命令,都是一些del、set、hset等的低復雜度命令,那么就要評估是否寫入了大key,
在往Redis寫入資料時,需要為新資料分配記憶體塊,相對應的,當洗掉資料時,Redis也會釋放對應的記憶體空間,如果一個 key 寫入Redis的值非常大,那么在分配記憶體時就會相對比較耗時,同樣的當洗掉這個 key 時,釋放記憶體也會比較耗時,這種被稱為bigKey,
當然這個描述仍然比較寬泛,因為Redis中的資料庫結構型別比較多,更完善的一些說法可以這么定義:將含有較大資料或含有大量成員、串列數的Key定義為bigkey,
我們一般要求研發使用Redis時,對于String型別Value大小不要超過1KB,
大Key帶來的問題比較多,主要有下面幾種情況:
- 由于大Key的記憶體分配及釋放開銷變大,直接影響就是導致應用訪問Redis的回應變慢;
- 洗掉時會造成較長時間的阻塞并有可能造成集群主備節點切換【4.0之前的版本有這個問題】;
- 記憶體占用過多甚至達到maxmemory配置,會造成新寫入阻塞或一些不應該被提前洗掉的Key被逐出,甚至導致OOM發生;
- 并發讀請求因為Key過大會可能打滿服務器帶寬,如果單機多實體部署則同時會影響到該服務器上的其它服務【假設一個bigkey為1MB,客戶端每秒訪問量為1000,那么每秒產生1000MB的流量】;
- 運維麻煩,比如RedisCluster的資料跨節點均衡,因為均衡遷移原理是通過migrate命令來完成的,這個命令實際是通過dump + restore + del三個命令組合成原子命令完成,如果是bigkey,可能會使遷移失敗,而且較慢的migrate也會阻塞Redis正常請求;
- 分片集群RedisCluster中的出現嚴重的資料傾斜,導致某個節點的記憶體使用過大;
- 對于集合型別的Hash、List、Set、ZSet僅僅統計的是包含的成員個數,個數多并代表占用的記憶體大,僅僅是個參考;
- 對于高并發訪問的集群,使用該命令會造成QPS增加,帶來額外的性能開銷,建議在業務低峰或者從節點進行掃描,
- 降低使用 O(N) 以上復雜度的命令,對于資料的計算聚合操作等可以適當的放在應用程式側處理;
- 使用O(N) 復雜度的命令時,保證 N 盡量的小(推薦 N <= 500),每次處理的更小的資料量,降低阻塞的時長;
- 對于Hgetall、Smembers操作的集合物件,應從應用層面保證單個集合的成員個數不要過大,可以進行適當的拆分等,
- 是否有定時任務的腳本程式,定時或者間隔性的操作Redis
- Redis的Key數量出現集中過期清理
- 被動過期:只有應用發起訪問某個key 時,才判斷這個key是否已過期,如果已過期,則從Redis中洗掉
- 主動過期:在Redis 內部維護了一個定時任務,默認每隔 100 毫秒(1秒10次)從全域的過期哈希表中隨機取出 20 個 key,判斷然后洗掉其中過期的 key,如果過期 key 的比例超過了 25%,則繼續重復此程序,直到過期 key 的比例下降到 25% 以下,或者這次任務的執行耗時超過了 25 毫秒,才會退出回圈
- allkeys-lru:清理最近最少使用(LRU)的Key,不管 key 是否設定了過期時間
- volatile-lru:清理最近最少使用(LRU)的Key,但是只回收有設定過期的Key
- allkeys-random:隨機清理部分Key,不管 key 是否設定了過期時間
- allkeys-lfu:不管 key 是否設定了過期,清理訪問頻次最低的 key(4.0+版本支持)
- volatile-lfu:清理訪問頻次最低且設定了過期時間 key(4.0+版本支持)
- volatile-random:隨機清理部分設定了過期時間的部分Key
- volatile-ttl:清理有設定過期的Key,嘗試先回收離 TTL 最短時間的Key
- noeviction:不清理任何Key,當到達記憶體最大限制時,當客戶端嘗試執行命令時會導致更多記憶體占用時直接回傳錯誤(大多數寫命令,除了 DEL 和一些例外),
- 合理預估記憶體占用,避免達到記憶體的使用上限,這里有兩種方法可以參考:
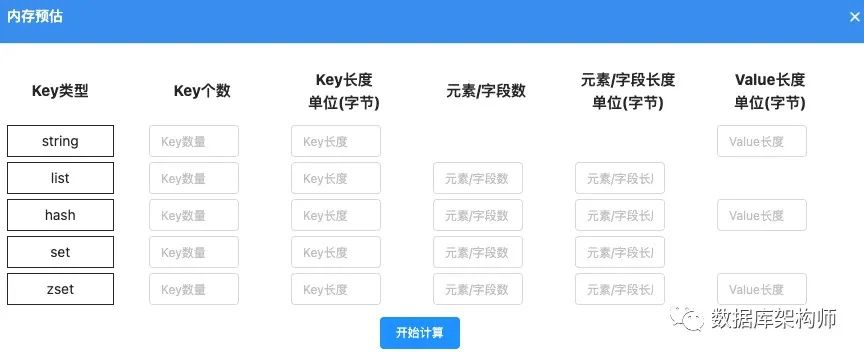 (2)寫入一小部分比例的真實業務資料,然后進行預估,
(2)寫入一小部分比例的真實業務資料,然后進行預估,
- 設定合理的Key過期時間,滿足業務的最小保留時間即可,
- 資料量過大建議拆分成多套Redis或者使用RedisCluster分片集群,建議單集群最大記憶體不超過20G,
- 資料清理策略改為隨機模式,隨機清理比 LRU 要快很多(不過這個要根據業務情況評定,業務優先滿足原則),
- 如果使用的是 Redis 4.0 及以上版本,開啟 layz-free 機制,把淘汰 key 釋放記憶體的操作放到后臺執行緒中執行(配置 lazyfree-lazy-eviction = yes)
- 增加剩余可用記憶體的監控,提前預警并進行最大記憶體上限的擴容或者提前清理釋放記憶體,
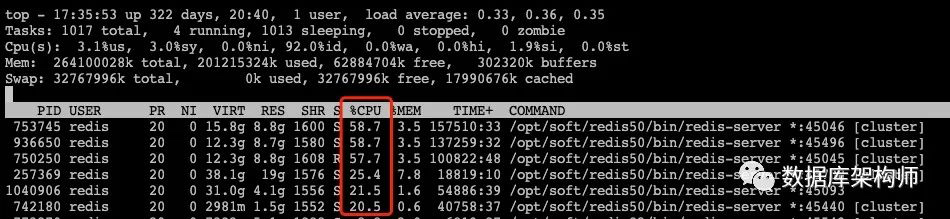 為了解決這種問題,就需要評估當前集群的處理吞吐力,參考官方的測評結果QPS 10W行不行?我們在上一篇文章介紹基本的壓測有過說明,每個Redis所在的服務器配置不一樣,處理能力就不一樣,
更進一步說,每個Redis承載的服務模型不同,比如使用的命令型別、訪問比例等,那么處理的吞吐也會有很大不同,針對這種情況最好的方案就是業務上線前,可以模擬真實的業務進行壓力測評,給出一個大概的吞吐處理能力,如果評估單節點無法承載過多請求,建議進行讀寫分離架構或者拆分為多套集群擴容.
最后就是不要忽略運維監控,可以對使用的CPU使用率、訪問的QPS等進行有效監控,提前發現是否達到集群的處理瓶頸,并決定是否進行擴容或架構調整,
說明:Redis監控指標還是比較多的,不管是性能指標、記憶體使用、持久化、網路連接等,后面會專門發文介紹,大家到時也可以關注下,
為了解決這種問題,就需要評估當前集群的處理吞吐力,參考官方的測評結果QPS 10W行不行?我們在上一篇文章介紹基本的壓測有過說明,每個Redis所在的服務器配置不一樣,處理能力就不一樣,
更進一步說,每個Redis承載的服務模型不同,比如使用的命令型別、訪問比例等,那么處理的吞吐也會有很大不同,針對這種情況最好的方案就是業務上線前,可以模擬真實的業務進行壓力測評,給出一個大概的吞吐處理能力,如果評估單節點無法承載過多請求,建議進行讀寫分離架構或者拆分為多套集群擴容.
最后就是不要忽略運維監控,可以對使用的CPU使用率、訪問的QPS等進行有效監控,提前發現是否達到集群的處理瓶頸,并決定是否進行擴容或架構調整,
說明:Redis監控指標還是比較多的,不管是性能指標、記憶體使用、持久化、網路連接等,后面會專門發文介紹,大家到時也可以關注下,
 如果這篇文章對你有幫助,還請幫忙點贊、在看、轉發 一下,你的支持會激勵我們輸出更多高質量的文章,非常感謝!
如果你還想看更多優質文章,歡迎關注我的公號「資料庫架構師」,提升資料庫技能,
如果這篇文章對你有幫助,還請幫忙點贊、在看、轉發 一下,你的支持會激勵我們輸出更多高質量的文章,非常感謝!
如果你還想看更多優質文章,歡迎關注我的公號「資料庫架構師」,提升資料庫技能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/507272.html
標籤:其他