摘要: HetuEngine作為MRS服務中互動式分析&多源統一SQL引擎,親自全程體驗其如何實作多資料源的跨源跨域分析能力,
本文分享自華為云社區《MRS HetuEngine體驗跨源跨域分析【玩轉華為云】》,作者:龍哥手記,
HetuEngine作為MRS服務中互動式分析&多源統一SQL引擎,親自全程體驗其如何實作多資料源的跨源跨域分析能力,
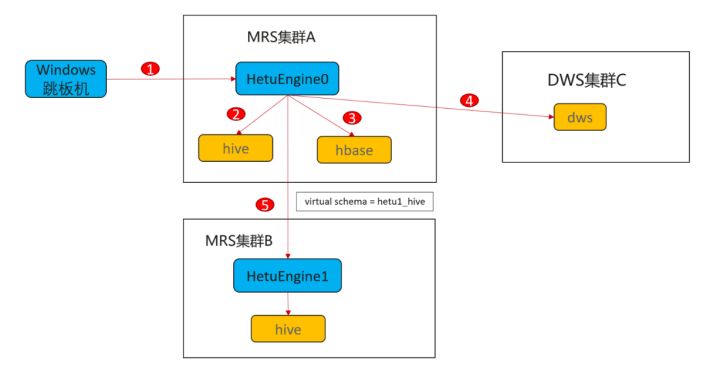
一場景完整描述
1.1 首先說明下
1)用戶通過登錄Windows跳板機,使用SQL開發工具DBeaver連接MRS集群A的HetuEngine進行分析體驗
2)跨源分析體驗,通過HetuEngine0連接集群內部資料源hive
3)跨源分析體驗,通過HetuEngine0連接集群內部資料源hbase
4)跨倉分析體驗,通過HetuEngine0連接關系型資料庫DWS
5)跨湖分析體驗,通過HetuEngine0連接到MRS集群B的HetuEngine1再連接到集群B的資料源hive
二 登錄環境并完成準備作業
2.1. 登錄跳板機
登錄:http://121.13.226.78:18080/ssh/#/
① 用戶名:hdc01,
② 密碼:請聯系現場引導員獲取
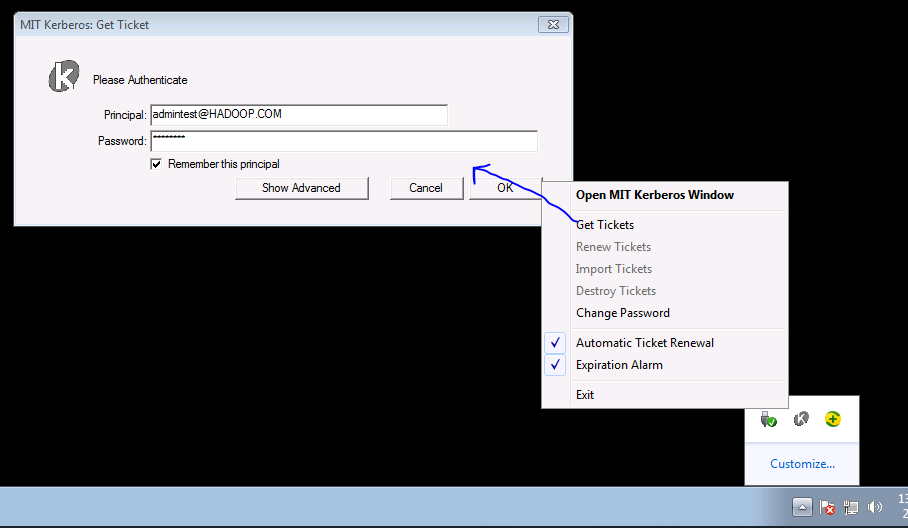
2.2 登錄認證軟體MIT Kerberos進行認證
點擊右下角的MIT Kerberos,選擇Get Tickets輸入用戶名密碼獲取Kerberos認證票據
① Principal:[email protected],
② Password: Admin12!
2.3 打開SQL編輯器軟體DBeaver
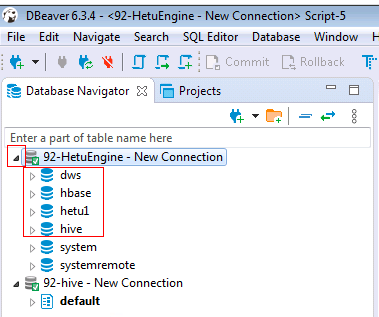
2.4 查看已配置好的MRS集群A的HetuEngine連接
點擊三角符號打開已配置好的HetuEngine連接
說明:
① dws: 外部dws資料庫
② hbase: MRS集群A中的hbase資料源
③ hetu1: 遠端MRS集群B的HetuEngine
④ hive: MRS集群A中的hive資料源
三 體驗HetuEngine hive查詢性能提升
3.1 通過普通JDBC查詢MRS集群A中的hive表
選擇配置好的hive資料源92-hive - New Connection,右鍵選擇SQL Editor
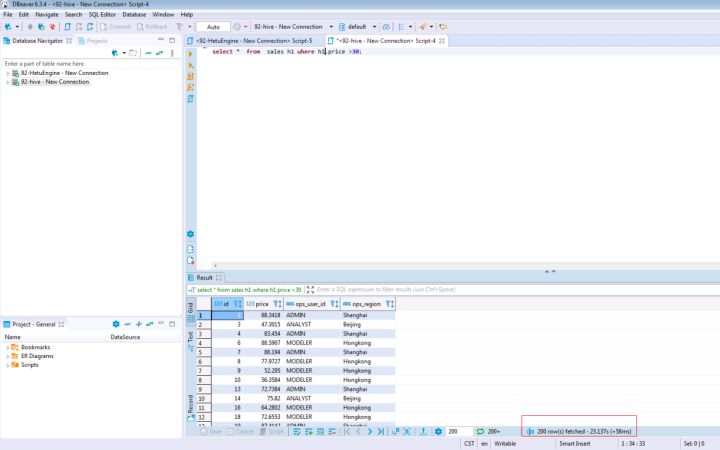
輸入以下SQL陳述句并查看結果與時間
SELECT * FROM sales h1 WHERE h1.price >30;
3.2. 通過HetuEngine查詢MRS集群A中的hive表
選擇配置好的hive資料源92-HetuEngine - New Connection,右鍵選擇SQL Editor
輸入以下的SQL陳述句并查看結果和時間
SELECT * FROM hive.default.sales h1 WHERE h1.price >30;
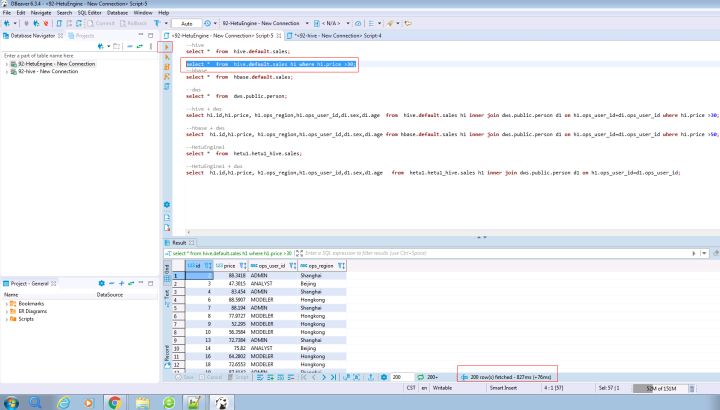
3.3. 結論
通過比較兩次查詢時間,可以看到HetuEngine會加速查詢性能,比普通的hive查詢更加快速;
四 體驗HetuEngine跨源、跨倉分析能力
4.1 通過HetuEngine對MRS集群A中的HBase進行跨源資料查詢
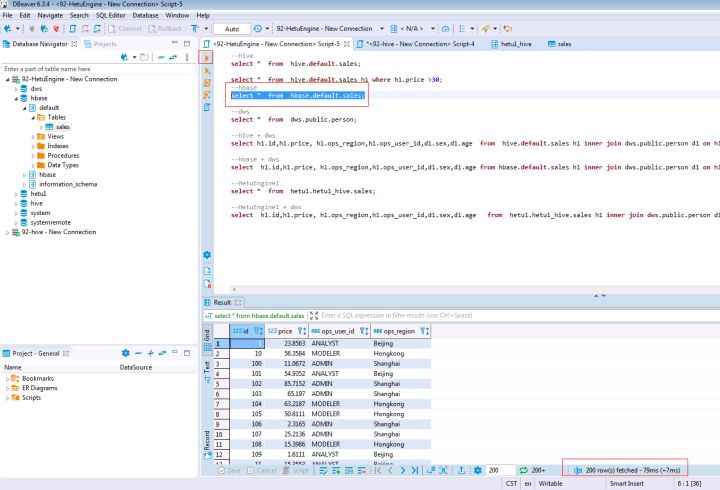
在打開的SQL Editor中輸入如下SQL陳述句查詢MRS集群A的HBase資料
SELECT * FROM hbase.default.sales;
4.2 通過HetuEngine對DWS集群C進行跨倉資料查詢
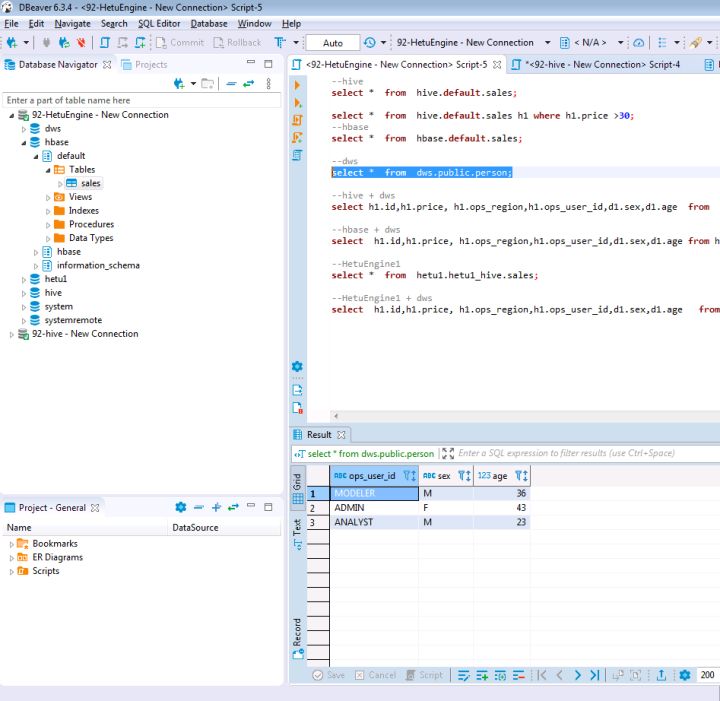
在打開的SQL Editor中輸入如下SQL陳述句查詢DWS集群C中的維表資料
SELECT * FROM dws.public.person;
4.3. 體驗MRS集群A的hive同DWS集群C跨倉分析查詢
在打開的SQL Editor中輸入如下SQL陳述句可做MRS集群A的hive與DWS集群C的跨倉資料分析
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hive.default.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id WHERE h1.price >30;
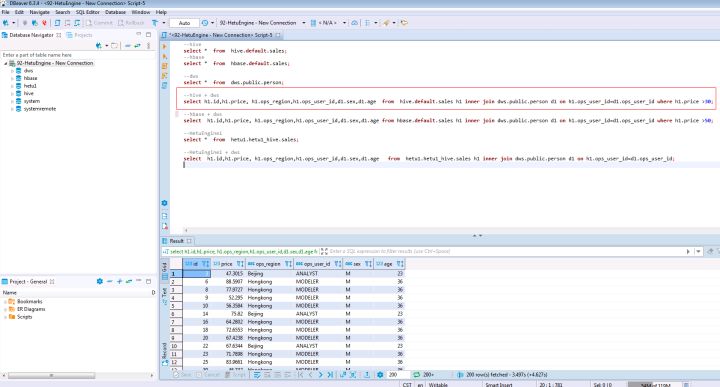
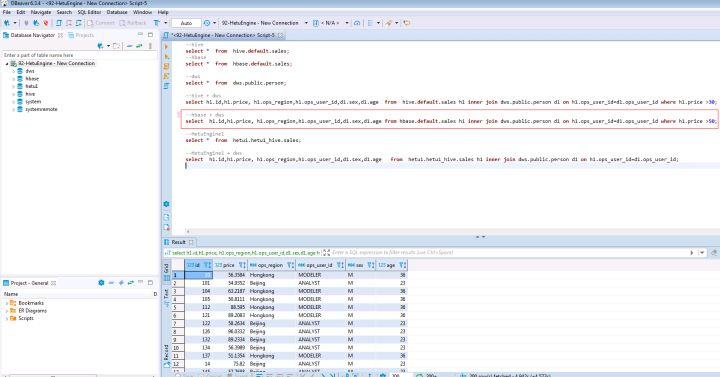
4.4 體驗MRS集群A的hbase同DWS集群C跨倉分析查詢
在打開的SQL Editor中輸入如下SQL陳述句可做MRS集群A的hbase與DWS集群C的跨倉資料分析
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hbase.default.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id WHERE h1.price >50;
4.5 下結論
出于管理和資訊收集的需要,企業內部會存盤海量資料,包括數目眾多的各種資料庫、資料倉庫等,此時會面臨資料源種類繁多、資料集結構化混合、相關資料存放分散等困境,導致跨源查詢開發成本高,跨源復雜查詢耗時長,HetuEngine提供了統一標準SQL實作跨源協同分析,簡化跨源分析操作;
五 體驗HetuEngine跨湖分析能力
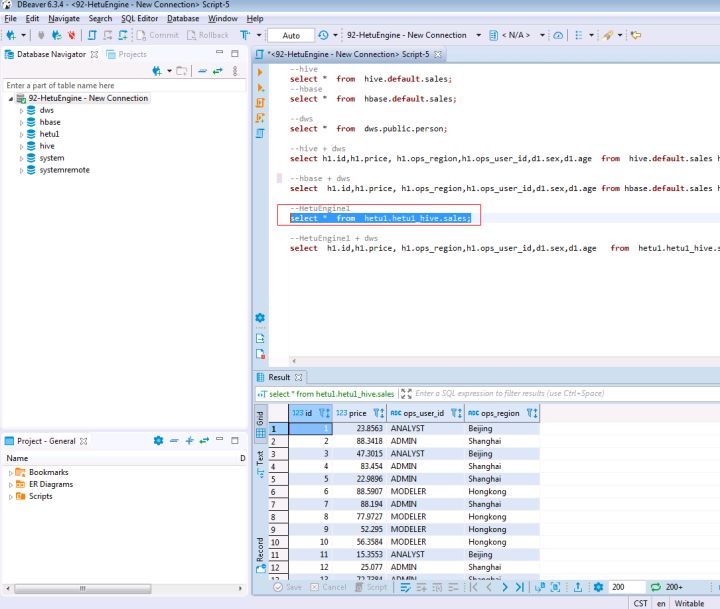
5.1 將MRS集群A的HetuEngine連接到MRS集群B的HetuEngine進行跨湖查詢
在打開的SQL Editor中輸入如下SQL陳述句可做MRS集群B中HetuEngine的hive跨湖查詢
SELECT * FROM hetu1.hetu1_hive.sales;
5.2 體驗MRS集群B的HetuEngine同DWS集群C跨湖分析查詢
打開SQL Editor輸入如下SQL陳述句可做MRS集群B中HetuEngine的hive同DWS集群C的跨湖查詢
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hetu1.hetu1_hive.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id;
5.3 結論
HetuEngine提供統一標準SQL對分布于多個地域(或資料中心)的多種資料源實作高效訪問,屏蔽資料在結構、存盤及地域上的差異,實作資料與應用的解耦,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/508853.html
標籤:大數據
上一篇:Nginx服務器不會將大于2MB的視頻處理到后端和AWSS3存盤桶
下一篇:如何設計企業級資料埋點采集方案?