目錄
- 當前服務器上創建表(單節點)
- 語法形式
- 使用顯式架構
- 從相同結構的表復制創建
- 從表函式創建
- 從選擇查詢創建
- 語法形式
- 分布式集群創建表
- 臨時表
- 磁區表
- 創建表陳述句關鍵字決議
- 空值或非空修飾符
- 默認值運算式
- 一般運算式
- 物化運算式
- 臨時運算式
- 別名運算式
- 主鍵
- 約束
- 資料TTL
- 列級別TTL
- 表級別TTL
- clickhouse壓縮與編碼
- 列壓縮
- 目前clickhouse支持的壓縮演算法
- ClickHouse相關資料分享
- 參考文章
當前服務器上創建表(單節點)
創建新表具有幾種種語法形式,具體取決于用例,默認情況下,僅在當前服務器上創建表,分布式DDL查詢作為子句實作,該子句另外描述,
語法形式
使用顯式架構
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr2] [compression_codec] [TTL expr2],
...
) ENGINE = engine
使用[db_name.]引數可以為資料表指定資料庫,如果不指定此引數,則默認會使用default資料庫,
末尾的ENGINE引數,它被用于指定資料表的引擎,表引擎決定了資料表的特性,也決定了資料將會被如何存盤及加載,例如示例中使用的Memory表引擎,是ClickHouse最簡單的表引擎,資料只會被保存在記憶體中,在服務重啟時資料會丟失,
從相同結構的表復制創建
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
創建與另一個表具有相同結構的表,您可以為表指定其他引擎,如果未指定引擎,則將使用與表相同的引擎,
從表函式創建
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS table_function()
創建與指定表函式的結果相同的表,創建的表也將以與指定的相應表函式相同的方式作業,
什么是表函式?簡單來說就是一個可以回傳一張表的函式,下面是一個表函式的例子,from后面跟著的就是一個表函式,
CREATE TABLE Orders
ENGINE = MergeTree
ORDER BY OrderID AS
SELECT *
FROM mysql('10.42.134.136:4000', 'databas', 'Orders', 'root', '1234')
目前的表函式有下面幾個,這里暫時不展開講,
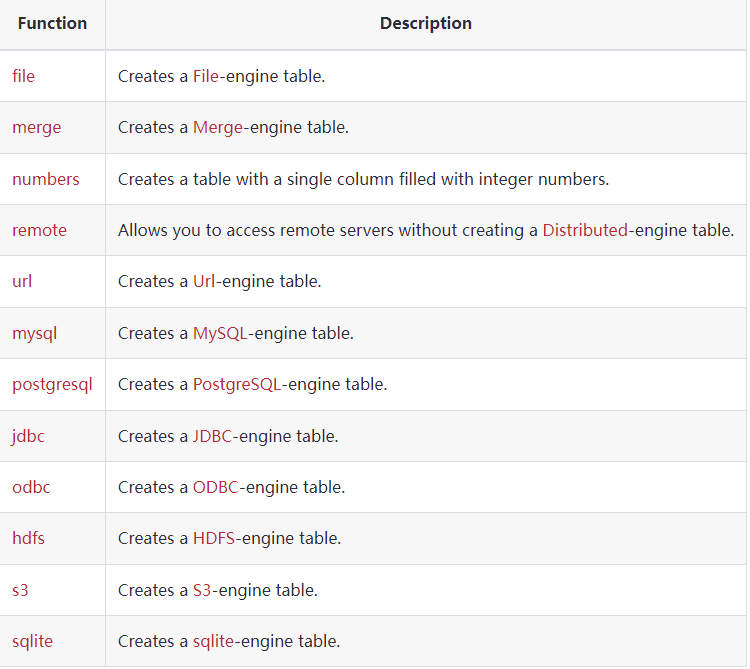
從選擇查詢創建
CREATE TABLE [IF NOT EXISTS] [db.]table_name[(name1 [type1], name2 [type2], ...)] ENGINE = engine AS SELECT ...
使用引擎創建具有類似于查詢結果的結構的表,并使用來自的資料填充該表,創建的時候,還可以顯式指定列說明,
使用IF NOT EXISTS,如果表已存在且已指定,則查詢不會執行任何操作,
查詢中的子句之后可以有其他子句,
分布式集群創建表
ClickHouse支持集群模式,一個集群擁有1到多個節點,CREATE、ALTER、DROP、RENMAE及TRUNCATE這些DDL陳述句,都支持分布式執行,這意味著,如果在集群中任意一個節點上執行DDL陳述句,那么集群中的每個節點都會以相同的順序執行相同的陳述句,這項特性意義非凡,它就如同批處理命令一樣,省去了需要依次去單個節點執行DDL的煩惱,
將一條普通的DDL陳述句轉換成分布式執行十分簡單,只需加上ON CLUSTER cluster_name宣告即可,
例如,執行下面的陳述句后將會對ch_cluster集群內的所有節點廣播這條DDL陳述句:
CREATE TABLE partition_v3 ON CLUSTER ch_cluster(
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
ch_cluster是集群的名稱,
臨時表
ClickHouse也有臨時表的概念,創建臨時表的方法是在普通表的基礎之上添加TEMPORARY關鍵字,它的完整語法如下所示:
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
)
相比普通表而言,臨時表有如下兩點特殊之處:
- 它的生命周期是會話系結的,所以它只支持Memory表引擎,如果會話結束,資料表就會被銷毀;
- 臨時表不屬于任何資料庫,所以在它的建表陳述句中,既沒有資料庫引數也沒有表引擎引數,
臨時表的優先級是大于普通表的,當兩張資料表名稱相同的時候,會優先讀取臨時表的資料,
磁區表
資料磁區(partition)和資料分片(shard)是完全不同的兩個概念,資料磁區是針對本地資料而言的,是資料的一種縱向切分,而資料分片是資料的一種橫向切分,借助資料磁區,在后續的查詢程序中能夠跳過不必要的資料目錄,從而提升查詢的性能,
不是所有的表引擎都可以使用磁區,目前只有合并樹(MergeTree)家族系列的表引擎才支持資料磁區,由PARTITION BY指定磁區鍵,下面的資料表partition_00使用了日期欄位作為磁區鍵,并將其格式化為年月的形式:
CREATE TABLE partition_00 (
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
創建表陳述句關鍵字決議
空值或非空修飾符
列定義中資料型別后面的修飾符可以指定允許或不允許其值為Null,
CREATE TABLE Orders
(
`order_id` String,
`created_at` Nullable(DateTime),
`updated_at` Nullable(DateTime)
)
ENGINE = MergeTree
ORDER BY (order_id)
SETTINGS index_granularity = 8192
上面的例子中created_at和updated_at可以插入一個NULL值,反之不可以,
默認值運算式
[DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1]
表欄位支持四種默認值運算式的定義方法,分別是DEFAULT、MATERIALIZED、EPHEMERAL和ALIAS,無論使用哪種形式,表欄位一旦被定義了默認值,它便不再強制要求定義資料型別,因為ClickHouse會根據默認值進行型別推斷,
例:URLDomain String DEFAULT domain(URL)
默認值運算式的定義方法之間也存在著不同之處,可以從如下三個方面進行比較,
- 資料寫入:在資料寫入時,只有DEFAULT型別的欄位可以出現在INSERT陳述句中,而MATERIALIZED、EPHEMERAL和ALIAS都不能被顯式賦值,它們只能依靠計算取值,例如試圖為MATERIALIZED型別的欄位寫入資料,將會得到如下的錯誤,
DB::Exception: Cannot insert column URL, because it is MATERIALIZED column.. - 資料查詢:在資料查詢時,只有DEFAULT型別的欄位可以通過SELECT *回傳,而MATERIALIZED、EPHEMERAL和ALIAS型別的欄位不會出現在SELECT *查詢的回傳結果集中,
- 資料存盤:在資料存盤時,只有DEFAULT和MATERIALIZED型別的欄位才支持持久化,如果使用的表引擎支持物理存盤(例如TinyLog表引擎),那么這些列欄位將會擁有物理存盤,而ALIAS、EPHEMERAL型別的欄位不支持持久化,它的取值總是需要依靠計算產生,資料不會落到磁盤,
- EPHEMERAL只能在CREATE陳述句的默認值中參考,
怎么理解這四種運算式呢?它其實就是列值的四種生成方式,DEFAULT是在插入的時候計算填充,MATERIALIZED和ALIAS是在查詢的時候,或者說用到的時候填充,而EPHEMERAL,有點類似于我們在建表的時候,創建一個變數,一個代碼塊,
一般運算式
DEFAULT expr
正常默認值,如果INSERT查詢未指定相應的列,則將通過計算相應的運算式來填充它,
物化運算式
MATERIALIZED expr
物化欄位列,這樣的欄位不能在INSERT陳述句中指定值插入,因為這樣的欄位總是通過使用其他欄位計算出來的,
臨時運算式
EPHEMERAL expr
臨時欄位列,這樣的列不存盤在表中,不能被SELECT 查詢,但可以在CREATE陳述句的默認值中參考,
別名運算式
ALIAS expr
欄位別名,這樣的列根本不存盤在表中,其值不能插入到表中,并且在通過SELECT * 查詢,不會出現在結果集,如果在查詢分析期間擴展了別名,則可以在SELECT中使用它,
主鍵
您可以在創建表時定義主鍵,可以通過兩種方式指定主鍵:
-- 內部定義
CREATE TABLE db.table_name
(
name1 type1, name2 type2, ...,
PRIMARY KEY(expr1[, expr2,...])]
)
ENGINE = engine;
-- 外部定義
CREATE TABLE db.table_name
(
name1 type1, name2 type2, ...
)
ENGINE = engine
PRIMARY KEY(expr1[, expr2,...]);
警告:不能在一個查詢中以兩種方式組合,
約束
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [compression_codec] [TTL expr1],
...
CONSTRAINT constraint_name_1 CHECK boolean_expr_1,
...
) ENGINE = engine
boolean_expr_1可以通過任何布爾運算式,如果為表定義了約束,則將針對查詢中的每一行檢查每個約束,如果不滿足任何約束,服務器將引發包含約束名稱和檢查運算式的例外,INSERT添加大量約束可能會對大型查詢的性能產生負面影響,
資料TTL
TTL即Time To Live,運算式正常為:TTL expr1,只能為合并樹族表指定,
它表示資料的存活時間,在MergeTree中,可以為某個列欄位或整張表設定TTL,當時間到達時,如果是列欄位級別的TTL,則會洗掉這一列的資料;如果是表級別的TTL,則會洗掉整張表的資料;如果同時設定了列級別和表級別的TTL,則會以先到期的那個為主,
無論是列級別還是表級別的TTL,都需要依托某個DateTime或Date型別的欄位,通過對這個時間欄位的INTERVAL操作,來表述TTL的過期時間,
如下面的例子,
-- 表示資料的存活時間是time_col時間的3天之后,
TTL time_col + INTERVAL 3 DAY 上述
-- 表示資料的存活時間是time_col時間的1月之后
TTL time_col + INTERVAL 1 MONTH,
-- INTERVAL完整的操作包括SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER和YEAR,
列級別TTL
CREATE TABLE ttl_table_v1(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 10 SECOND,
type UInt8 TTL create_time + INTERVAL 10 SECOND
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id
表級別TTL
CREATE TABLE ttl_table_v2(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 1 MINUTE,
type UInt8
)ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
TTL create_time + INTERVAL 1 DAY
clickhouse壓縮與編碼
列壓縮
我們可以每個單獨列定義壓縮方法,這樣可以減少資料存盤的空間,可以指定編解碼器以參考默認壓縮,這可能取決于運行時中的不同設定(和資料屬性)
CREATE TABLE codec_example
(
dt Date CODEC(ZSTD),
ts DateTime CODEC(LZ4HC),
float_value Float32 CODEC(NONE),
double_value Float64 CODEC(LZ4HC(9)),
value Float32 CODEC(Delta, ZSTD)
)
ENGINE = <Engine>
...
下表引擎支持壓縮:
- MergeTree family:支持列壓縮編解碼器,并通過壓縮設定選擇默認壓縮方法,
- Log family:默認情況下使用壓縮方法,并支持列壓縮編解碼器lz4,
- Set:僅支持默認壓縮,
- Join:僅支持默認壓縮,
目前clickhouse支持的壓縮演算法
- 通用編碼
- None:無壓縮
- LZ4:默認的壓縮演算法,預設值也是使用默認的壓縮演算法
- LZ4HC[(level)]:z4高壓縮率壓縮演算法版本, level默認值為9,支持[112],推薦選用[49]
- ZSTD[(level)]:zstd壓縮演算法,level默認值為1,支持[1~22]
- 特殊編碼
- LowCardinality:列舉值小于1w的字串
- Delta:時間序列型別的資料,不會對資料進行壓縮
- T64:比較適合Int型別資料
- DoubleDelta:適用緩慢變化的序列:比如時間序列,對于遞增序列效果很好
- Gorilla:使用緩慢變化的數值型別
特殊編碼與通用的壓縮演算法相比,區別在于,通用的LZ4和ZSTD壓縮演算法是普適行的,不關心資料的分布特點,而特殊編碼型別對于特定場景下的資料會有更好的壓縮效果,
ClickHouse相關資料分享
ClickHouse經典中文檔案分享
參考文章
ClickHouse(06)ClickHouse的資料表創建陳述句詳細決議
本文來自博客園,作者:張飛的豬,轉載請注明原文鏈接:https://www.cnblogs.com/the-pig-of-zf/p/16708795.html
作者公眾號:張飛的豬大資料分享,不定期分享大資料學習的總結和相關資料,歡迎關注,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/509157.html
標籤:大數據