Hadoop的第一個產品是HDFS,可以說分布式檔案存盤是分布式計算的基礎,也可見分布式檔案存盤的重要性,如果我們將大資料計算比作烹飪,那么資料就是食材,而Hadoop分布式檔案系統HDFS就是燒菜的那口大鍋,這些年來,各種計算框架、各種演算法、各種應用場景不斷推陳出新,讓人眼花繚亂,但是大資料存盤的王者依然是HDFS,
為什么HDFS的地位如此穩固呢?在整個大資料體系里面,最寶貴、最難以代替的資產就是資料,大資料所有的一切都要圍繞資料展開,HDFS作為最早的大資料存盤系統,存盤著寶貴的資料資產,各種新的演算法、框架要想得到人們的廣泛使用,必須支持HDFS才能獲取已經存盤在里面的資料,所以大資料技術越發展,新技術越多,HDFS得到的支持越多,我們越離不開HDFS,HDFS也許不是最好的大資料存盤技術,但依然最重要的大資料存盤技術,
那我們就從HDFS的原理說起,今天我們來聊聊HDFS是如何實作大資料高速、可靠的存盤和訪問的,
Hadoop分布式檔案系統HDFS的設計目標是管理數以千計的服務器、數以萬計的磁盤,將這么大規模的服務器計算資源當作一個單一的存盤系統進行管理,對應用程式提供數以PB計的存盤容量,讓應用程式像使用普通檔案系統一樣存盤大規模的檔案資料,
如何設計這樣一個分布式檔案系統?其實思路很簡單,
我們想想RAID磁盤陣列存盤,RAID將資料分片后在多塊磁盤上并發進行讀寫訪問,從而提高了存盤容量、加快了訪問速度,并通過資料的冗余校驗提高了資料的可靠性,即使某塊磁盤損壞也不會丟失資料,將RAID的設計理念擴大到整個分布式服務器集群,就產生了分布式檔案系統,Hadoop分布式檔案系統的核心原理就是如此,
和RAID在多個磁盤上進行檔案存盤及并行讀寫的思路一樣,HDFS是在一個大規模分布式服務器集群上,對資料分片后進行并行讀寫及冗余存盤,因為HDFS可以部署在一個比較大的服務器集群上,集群中所有服務器的磁盤都可供HDFS使用,所以整個HDFS的存盤空間可以達到PB級容量,
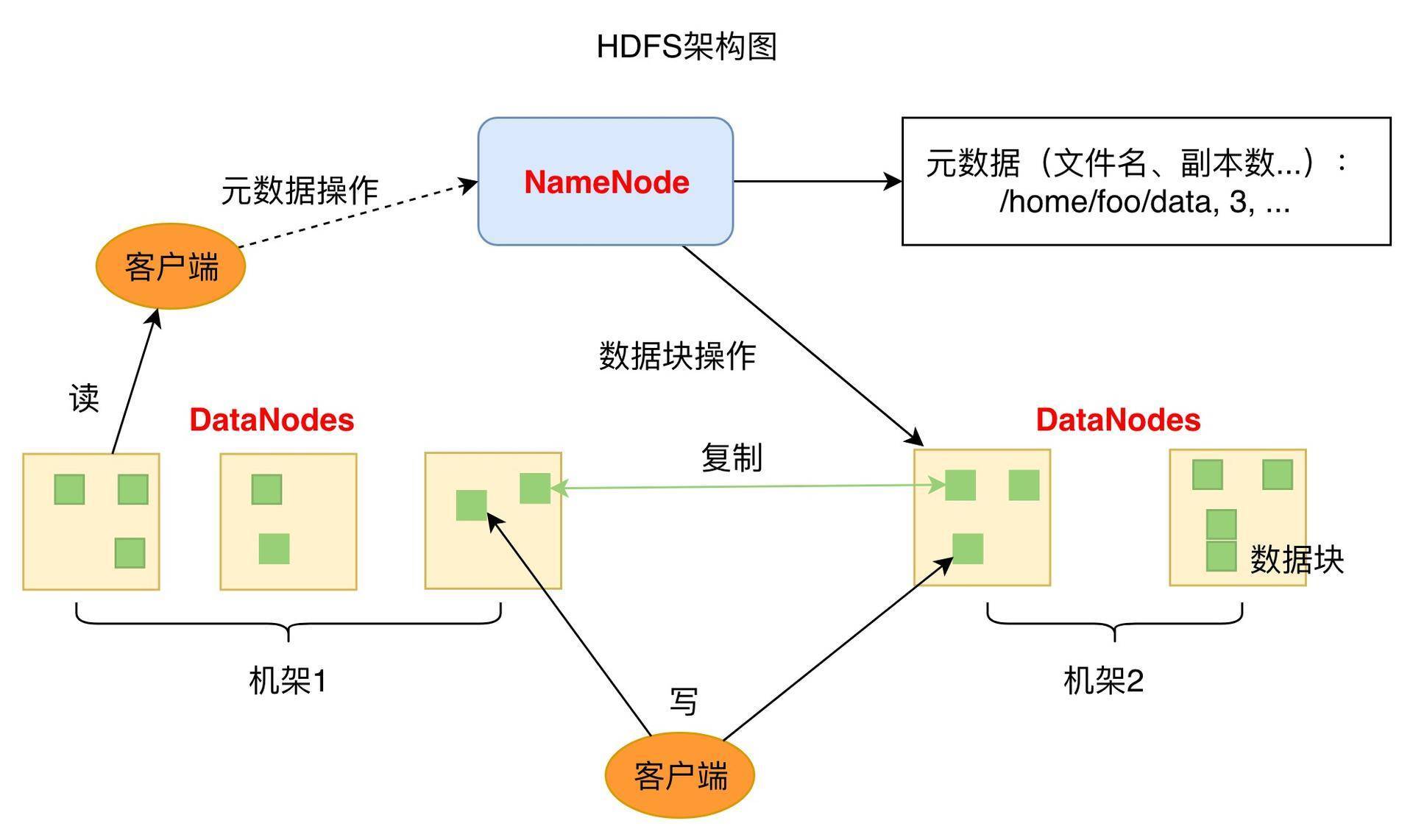
上圖是HDFS的架構圖,從圖中你可以看到HDFS的關鍵組件有兩個,一個是DataNode,一個是NameNode,
DataNode負責檔案資料的存盤和讀寫操作,HDFS將檔案資料分割成若干資料塊(Block),每個DataNode存盤一部分資料塊,這樣檔案就分布存盤在整個HDFS服務器集群中,應用程式客戶端(Client)可以并行對這些資料塊進行訪問,從而使得HDFS可以在服務器集群規模上實作資料并行訪問,極大地提高了訪問速度,
在實踐中,HDFS集群的DataNode服務器會有很多臺,一般在幾百臺到幾千臺這樣的規模,每臺服務器配有數塊磁盤,整個集群的存盤容量大概在幾PB到數百PB,
NameNode負責整個分布式檔案系統的元資料(MetaData)管理,也就是檔案路徑名、資料塊的ID以及存盤位置等資訊,HDFS為了保證資料的高可用,會將一個資料塊復制為多份(預設情況為3份),并將多份相同的資料塊存盤在不同的服務器上,甚至不同的機架上,這樣當有磁盤損壞,或者某個DataNode服務器宕機,甚至某個交換機宕機,導致其存盤的資料塊不能訪問的時候,客戶端會查找其備份的資料塊進行訪問,
下面這張圖是資料塊多份復制存盤的示意,圖中對于檔案/users/sameerp/data/part-0,其復制備份數設定為2,存盤的BlockID分別為1、3,Block1的兩個備份存盤在DataNode0和DataNode2兩個服務器上,Block3的兩個備份存盤DataNode4和DataNode6兩個服務器上,上述任何一臺服務器宕機后,每個資料塊都至少還有一個備份存在,不會影響對檔案/users/sameerp/data/part-0的訪問,
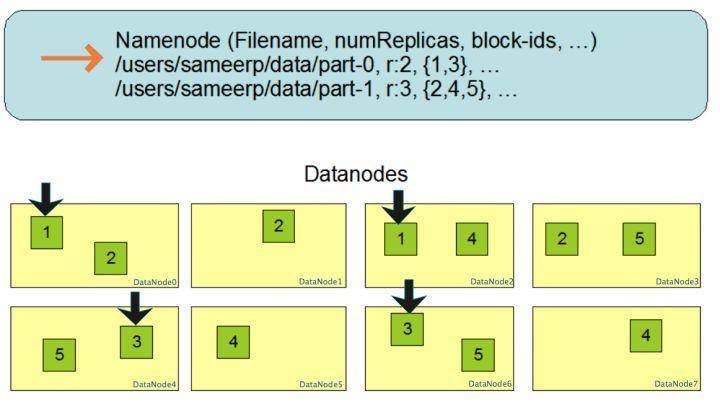
和RAID一樣,資料分成若干資料塊后存盤到不同服務器上,可以實作資料大容量存盤,并且不同分片的資料可以并行進行讀/寫操作,進而實作資料的高速訪問,你可以看到,HDFS的大容量存盤和高速訪問相對比較容易實作,但是HDFS是如何保證存盤的高可用性呢?
我們嘗試從不同層面來討論一下HDFS的高可用設計,
1.資料存盤故障容錯
磁盤介質在存盤程序中受環境或者老化影響,其存盤的資料可能會出現錯亂,HDFS的應對措施是,對于存盤在DataNode上的資料塊,計算并存盤校驗和(CheckSum),在讀取資料的時候,重新計算讀取出來的資料的校驗和,如果校驗不正確就拋出例外,應用程式捕獲例外后就到其他DataNode上讀取備份資料,
2.磁盤故障容錯
如果DataNode監測到本機的某塊磁盤損壞,就將該塊磁盤上存盤的所有BlockID報告給NameNode,NameNode檢查這些資料塊還在哪些DataNode上有備份,通知相應的DataNode服務器將對應的資料塊復制到其他服務器上,以保證資料塊的備份數滿足要求,
3.DataNode故障容錯
DataNode會通過心跳和NameNode保持通信,如果DataNode超時未發送心跳,NameNode就會認為這個DataNode已經宕機失效,立即查找這個DataNode上存盤的資料塊有哪些,以及這些資料塊還存盤在哪些服務器上,隨后通知這些服務器再復制一份資料塊到其他服務器上,保證HDFS存盤的資料塊備份數符合用戶設定的數目,即使再出現服務器宕機,也不會丟失資料,
4.NameNode故障容錯
NameNode是整個HDFS的核心,記錄著HDFS檔案分配表資訊,所有的檔案路徑和資料塊存盤資訊都保存在NameNode,如果NameNode故障,整個HDFS系統集群都無法使用;如果NameNode上記錄的資料丟失,整個集群所有DataNode存盤的資料也就沒用了,
所以,NameNode高可用容錯能力非常重要,NameNode采用主從熱備的方式提供高可用服務,請看下圖,
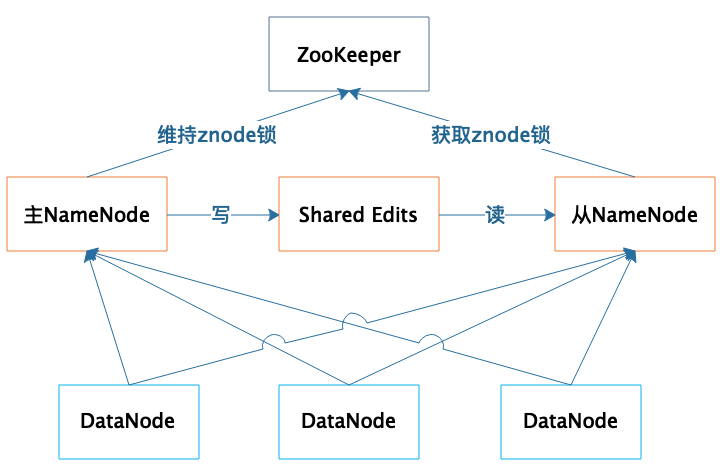
集群部署兩臺NameNode服務器,一臺作為主服務器提供服務,一臺作為從服務器進行熱備,兩臺服務器通過ZooKeeper選舉,主要是通過爭奪znode鎖資源,決定誰是主服務器,而DataNode則會向兩個NameNode同時發送心跳資料,但是只有主NameNode才能向DataNode回傳控制資訊,
正常運行期間,主從NameNode之間通過一個共享存盤系統shared edits來同步檔案系統的元資料資訊,當主NameNode服務器宕機,從NameNode會通過ZooKeeper升級成為主服務器,并保證HDFS集群的元資料資訊,也就是檔案分配表資訊完整一致,
對于一個軟體系統而言,性能差一點,用戶也許可以接受;使用體驗差,也許也能忍受,但是如果可用性差,經常出故障導致不可用,那就比較麻煩了;如果出現重要資料丟失,那開發工程師絕對是攤上大事了,
而分布式系統可能出故障地方又非常多,記憶體、CPU、主板、磁盤會損壞,服務器會宕機,網路會中斷,機房會停電,所有這些都可能會引起軟體系統的不可用,甚至資料永久丟失,
所以在設計分布式系統的時候,軟體工程師一定要繃緊可用性這根弦,思考在各種可能的故障情況下,如何保證整個軟體系統依然是可用的,
根據我的經驗,一般說來,常用的保證系統可用性的策略有冗余備份、失效轉移和降級限流,雖然這3種策略你可能早已耳熟能詳,但還是有一些容易被忽略的地方,
比如冗余備份,任何程式、任何資料,都至少要有一個備份,也就是說程式至少要部署到兩臺服務器,資料至少要備份到另一臺服務器上,此外,稍有規模的互聯網企業都會建設多個資料中心,資料中心之間互相進行備份,用戶請求可能會被分發到任何一個資料中心,即所謂的異地多活,在遭遇地域性的重大故障和自然災害的時候,依然保證應用的高可用,
當要訪問的程式或者資料無法訪問時,需要將訪問請求轉移到備份的程式或者資料所在的服務器上,這也就是失效轉移,失效轉移你應該注意的是失效的鑒定,像NameNode這樣主從服務器管理同一份資料的場景,如果從服務器錯誤地以為主服務器宕機而接管集群管理,會出現主從服務器一起對DataNode發送指令,進而導致集群混亂,也就是所謂的“腦裂”,這也是這類場景選舉主服務器時,引入ZooKeeper的原因,ZooKeeper的作業原理,我將會在后面專門分析,
當大量的用戶請求或者資料處理請求到達的時候,由于計算資源有限,可能無法處理如此大量的請求,進而導致資源耗盡,系統崩潰,這種情況下,可以拒絕部分請求,即進行限流;也可以關閉部分功能,降低資源消耗,即進行降級,限流是互聯網應用的常備功能,因為超出負載能力的訪問流量在何時會突然到來,你根本無法預料,所以必須提前做好準備,當遇到突發高峰流量時,就可以立即啟動限流,而降級通常是為可預知的場景準備的,比如電商的“雙十一”促銷,為了保障促銷活動期間應用的核心功能能夠正常運行,比如下單功能,可以對系統進行降級處理,關閉部分非重要功能,比如商品評價功能,
我們小結一下,看看HDFS是如何通過大規模分布式服務器集群實作資料的大容量、高速、可靠存盤、訪問的,
1.檔案資料以資料塊的方式進行切分,資料塊可以存盤在集群任意DataNode服務器上,所以HDFS存盤的檔案可以非常大,一個檔案理論上可以占據整個HDFS服務器集群上的所有磁盤,實作了大容量存盤,
2.HDFS一般的訪問模式是通過MapReduce程式在計算時讀取,MapReduce對輸入資料進行分片讀取,通常一個分片就是一個資料塊,每個資料塊分配一個計算行程,這樣就可以同時啟動很多行程對一個HDFS檔案的多個資料塊進行并發訪問,從而實作資料的高速訪問,關于MapReduce的具體處理程序,我們會在專欄后面詳細討論,
3.DataNode存盤的資料塊會進行復制,使每個資料塊在集群里有多個備份,保證了資料的可靠性,并通過一系列的故障容錯手段實作HDFS系統中主要組件的高可用,進而保證資料和整個系統的高可用,
?轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/509376.html
標籤:其他