主從復制 + 分庫分表
要講主從復制,首先來看看MySQL自帶的日志檔案,
日志
錯誤日志
錯誤日志是 MySQL 中最重要的日志之一,它記錄了當 mysqld 啟動和停止時,以及服務器在運行程序中發生任何嚴重錯誤時的相關資訊,當資料庫出現任何故障導致無法正常使用時,建議首先查看此日志檔案,
該日志是默認開啟的,默認存放目錄 /var/log/,默認的日志檔案名為 mysqld.log ,查看日志位置:
show variables like '%log_error%';
通過tail指令查看日志檔案的尾部記錄的日志:
tail -50 /var/log/mysqld.log
實時查看檔案尾部記錄的日志:
tail -f /var/log/mysqld.log
二進制日志
基本概述
二進制日志(BINLOG)記錄了所有的 DDL(資料定義語言)陳述句和 DML(資料操縱語言)陳述句,但不包括資料查詢(SELECT、SHOW)陳述句,在MySQL8版本中,默認二進制日志是開啟著的,
DDL:例如創建資料庫、創建表、修改表等操作;
DML:增刪改操作;
有什么用?
- 資料庫災難時的資料恢復,一旦資料庫崩了,可通過二進制日志進行資料恢復;
- 用于 MySQL 的主從復制;
查看二進制日志相關資訊:
show variables like '%log_bin%';
log_bin_basename:當前資料庫服務器的binlog日志的基礎名稱(前綴),具體的binlog檔案名需要在該basename的基礎上加上編號(編號從000001開始),
log_bin_index:binlog的索引檔案,里面記錄了當前服務器關聯的 binlog 檔案有哪些,
格式
MySQL服務器中提供了多種格式來記錄二進制日志,具體格式及特點如下:
| 日志格式 | 含義 |
|---|---|
| STATEMENT | 基于SQL陳述句的日志記錄,記錄的是SQL陳述句,對資料進行修改的SQL都會記錄在日志檔案中 |
| ROW | 基于行的日志記錄,記錄的是每一行的資料變更之前和之后的樣子,(默認) |
| MIXED | 混合了STATEMENT和ROW兩種格式,默認采用STATEMENT,在某些特殊情況下會自動切換為ROW進行記錄 |
默認的日志記錄格式采用的是“ROW”,可以通過命令
show variables like '%binlog_format%';查看;mysql> show variables like '%binlog_format%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ 1 row in set, 1 warning (0.11 sec)如果我們需要自定義配置二進制日志的格式,只需要在
/etc/my.cnf中配置binlog_format引數即可,
查看二進制日志
由于日志是以二進制方式存盤的,不能直接讀取,需要通過二進制日志查詢工具 mysqlbinlog 來查看,具體語法:
mysqlbinlog [ 引數選項 ] logfilename
引數選項:
-d 指定資料庫名稱,只列出指定的資料庫相關操作,
-o 忽略掉日志中的前n行命令,
-v 將行事件(資料變更)重構為SQL陳述句 (如果是ROW格式的,需要加上該引數)
-vv 將行事件(資料變更)重構為SQL陳述句,并輸出注釋資訊
洗掉二進制日志
對于比較繁忙的業務系統,每天生成的binlog資料巨大,如果長時間不清除,將會占用大量磁盤空間,可以通過以下幾種方式清理日志:
| 指令 | 含義 |
|---|---|
| reset master | 洗掉全部 binlog 日志,洗掉之后,日志編號,將從 binlog.000001 重新開始 |
| purge master logs to 'binlog.*' | 洗掉 * 編號之前的所有日志 |
| purge master logs before 'yyyy-mm-dd hh24:mi:ss' | 洗掉日志為 "yyyy-mm-dd hh24:mi:ss" 之前產生的所有日志 |
也可以在 mysql 的組態檔中配置二進制日志的過期時間,設定了之后,二進制日志過期會自動洗掉,默認二進制日志只存放30天,即2592000s,30天后自動洗掉,
# 查看過期時間
show variables like '%binlog_expire_logs_seconds%';
查詢日志
查詢日志中記錄了客戶端的所有操作陳述句(所有的增刪改查以及DDL陳述句都會記錄),而二進制日志不包含查詢資料的SQL陳述句,默認情況下,查詢日志是未開啟的,
show variables like '%general%';
如果需要開啟查詢日志,可以修改MySQL的組態檔 /etc/my.cnf 檔案,添加如下內容:
# 該選項用來開啟查詢日志 , 可選值 : 0 或者 1 ; 0 代表關閉, 1 代表開啟
general_log=1
# 設定日志的檔案名 , 如果沒有指定, 默認的檔案名為
host_name.log general_log_file=mysql_query.log
開啟了查詢日志之后,在MySQL的資料存放目錄,也就是 /var/lib/mysql/ 目錄下就會出現 mysql_query.log 檔案,之后所有的客戶端的增刪改查操作都會記錄在該日志檔案之中,長時間運行后,該日志檔案將會非常大,
慢查詢日志
顧名思義,記錄的就是執行效率比較低,速度較慢的sql日志,慢查詢日志記錄了所有執行時間超過引數 long_query_time 設定值并且掃描記錄數不小于min_examined_row_limit 的所有的SQL陳述句的日志,默認未開啟,long_query_time 默認為10 秒,最小為 0, 精度可以到微秒,
如果需要開啟慢查詢日志,需要在MySQL的組態檔 /etc/my.cnf 中配置如下引數:
# 開啟慢查詢日志
slow_query_log=1
# 設定慢查詢日志的時間引數為2,代表超過2s,就算慢查詢
long_query_time=2
主從復制
概述
主從復制是指將主資料庫的 DDL 和 DML 操作通過二進制日志傳到從庫服務器中,然后在從庫上對這些日志重新執行(也叫重做),從而使得從庫和主庫的資料保持同步,
MySQL支持一臺主庫同時向多臺從庫進行復制, 從庫同時也可以作為其他從服務器的主庫,實作鏈狀復制,
主從復制的優點:
- 主庫出現問題(宕機或重啟),可以快速切換到從庫提供服務;
- 實作讀寫分離,降低主庫的訪問壓力,主庫執行寫操作(增刪改),從庫執行讀操作(查);
- 可以在從庫中執行備份,以避免備份期間影響主庫服務;
第三點解釋:
進行資料備份時要加上全域鎖,避免資料不一致的情況發生,當前資料庫就處于只讀狀態,其他的客戶端不能執行增刪改操作,有了主從復制后,可以在從庫中加全域鎖進行備份,主庫中依然可以進行增刪改等相關操作,而從庫加了全域鎖,查詢是沒有問題的,
主從復制原理
MySQL主從復制的核心就是 二進制日志,具體的程序如下:
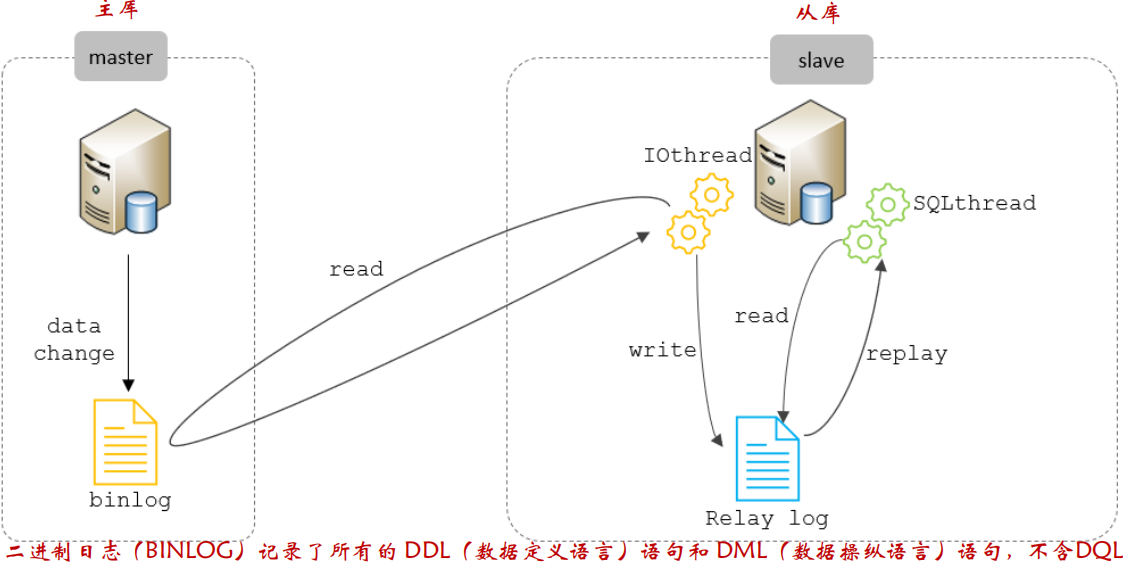
從庫中有兩組執行緒:
- IOthread:發起請求連接 master 資料庫,讀取 master 資料庫中的 binlog 日志檔案,并寫入到 slave 自身的中繼日志 Relay log 中;
- SQLthread:負責讀取中繼日志中的日志,重新執行日志中記錄的操作,保證主從資料的一致性,
主從復制主要分為以下三步操作:
- Master 主庫在事務提交時,會把資料變更記錄在二進制日志檔案 Binlog 中;
- 從庫讀取主庫的二進制日志檔案 Binlog ,寫入到從庫的中繼日志 Relay Log;
- slave 重做(重新執行)中繼日志中的事件,將改變反映它自己的資料;
搭建一主一從
準備
準備兩臺服務器,都關閉防火墻:
systemctl stop firewalld; # 關閉防火墻
systemctl disable firewalld; # 關閉防火墻的開機自啟
在兩臺服務器中分別安裝好 MySQL,并檢查 MySQL 的運行狀態:
systemctl status mysql;
主庫搭建
修改主庫的組態檔 /etc/my.cnf:
vim /etc/my.cnf
# mysql 服務ID,保證整個集群環境中唯一,取值范圍:1 – 2^32-1,默認為1
server-id=1
# 是否只讀,1 代表只讀, 0 代表讀寫(主庫既可讀又可寫,設定為0)
read-only=0
# 忽略的資料, 指不需要同步的資料庫
# binlog-ignore-db=mysql
# 指定同步的資料庫,如果不指定某個具體的資料庫,那表明所有資料庫都需要同步
# binlog-do-db=db01
重啟主庫:
systemctl restart mysqld
登錄mysql,創建遠程連接的賬號,并授予主從復制權限:
mysql -uroot -p123
# 創建 ypf 用戶,并設定密碼123123,該用戶可在任意主機連接該MySQL服務,@'%'表示這個用戶可以在任意主機上來訪問當前服務器
CREATE USER 'ypf'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123123';
# 為 'ypf'@'%' 用戶分配主從復制權限
GRANT REPLICATION SLAVE ON *.* TO 'ypf'@'%';
通過指令,查看二進制日志坐標:
show master status;
輸出欄位解釋:
- file : 寫入到哪個 binlog 日志檔案;
- position : 從哪個位置開始推送日志;
- binlog_ignore_db : 指定不需要同步的資料庫;
從庫配置
修改從庫的組態檔 /etc/my.cnf:
vim /etc/my.cnf
# mysql 服務ID,保證整個集群環境中唯一,取值范圍:1 – 2^32-1,和主庫不一樣即可
server-id=2
# 是否只讀,1 代表只讀, 0 代表讀寫(從庫只讀,設定為1)
read-only=1
重啟主庫:
systemctl restart mysqld
登錄mysql,設定主庫配置:
mysql -uroot -p123
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.200.200', SOURCE_USER='ypf', SOURCE_PASSWORD='Root@123123', SOURCE_LOG_FILE='binlog.000004', SOURCE_LOG_POS=663;
# 如果是 8.0.23 之前的MySQL版本,執行如下SQL:
CHANGE MASTER TO MASTER_HOST='192.168.200.200', MASTER_USER='ypf', MASTER_PASSWORD='Root@123123', MASTER_LOG_FILE='binlog.000004', MASTER_LOG_POS=663;
| 引數名 | 含義 | 8.0.23之前 |
|---|---|---|
| SOURCE_HOST | 主庫IP地址 | MASTER_HOST |
| SOURCE_USER | 連接主庫的用戶名 | MASTER_USER |
| SOURCE_PASSWORD | 連接主庫的密碼 | MASTER_PASSWORD |
| SOURCE_LOG_FILE | binlog日志檔案名 | MASTER_LOG_FILE |
| SOURCE_LOG_POS | binlog日志檔案位置 | MASTER_LOG_POS |
最后兩個引數在主庫中執行
show master status;可查看引數值
開啟主從復制:
start replica; #8.0.22之后
start slave; #8.0.22之前
查看主從同步狀態:
show replica status; #8.0.22之后 如果表比較大,展示資料比較亂,可以在命令后面加上\G
show slave status; #8.0.22之前
測驗主從是否同步
在主庫 192.168.200.200 上創建資料庫、表,并插入資料:
create database db01;
use db01;
create table tb_user(
id int(11) primary key not null auto_increment,
name varchar(50) not null,
sex varchar(1)
)engine=innodb default charset=utf8mb4;
insert into tb_user(id,name,sex) values(null,'Tom', '1'),(null,'Trigger','0'), (null,'Dawn','1');
在從庫 192.168.200.201 中查詢資料,驗證主從是否同步,
上面配置的是從當前二進制日志的指定位置(
SOURCE_LOG_POS引數設定)往后進行主從復制,如果需要把之前主庫的資料同步到從庫,那可以先把主庫的資料匯出到一個sql腳本中,然后在從庫中執行sql腳本,這樣保證了主從的初始資料是一致的,
分庫分表
隨著互聯網及移動互聯網的發展,應用系統的資料量也是成指數式增長,若采用單資料庫進行資料存盤,存在以下性能瓶頸:
- IO瓶頸:熱點資料太多,資料庫快取不足,產生大量磁盤IO,效率較低, 請求資料太多,帶寬不夠,網路IO瓶頸,
- CPU瓶頸:排序、分組、連接查詢、聚合統計等SQL會耗費大量的CPU資源,請求數太多,CPU出現瓶頸,
因此,就需要將存盤在一個資料庫中的資料分散存盤在多臺資料庫中,緩解單臺資料庫的磁盤存盤及訪問的壓力,
什么是分庫分表?
分庫:就是一個資料庫分成多個資料庫,部署到不同機器上,
分表:就是一個資料庫表分成多個表,
分庫分表的中心思想都是將資料分散存盤,使得單一資料庫/表的資料量變小來緩解單一資料庫的性能問題,從而提升資料庫性能,
為什么要分庫?
-
業務量劇增,MySQL單機磁盤容量會撐爆,拆成多個資料庫,磁盤使用率大大降低,
-
我們知道資料庫連接是有限的,在高并發的場景下,大量請求訪問資料庫,MySQL單機是扛不住的!當前非常火的微服務架構出現,就是為了應對高并發,它把訂單、用戶、商品等不同模塊,拆分成多個應用,并且把單個資料庫也拆分成多個不同功能模塊的資料庫(訂單庫、用戶庫、商品庫),以分擔讀寫壓力,
為什么要分表?
- 單表資料量太大的話,SQL的查詢就會變慢,如果一個查詢SQL沒命中索引,千百萬資料量級別的表可能會拖垮整個資料庫,
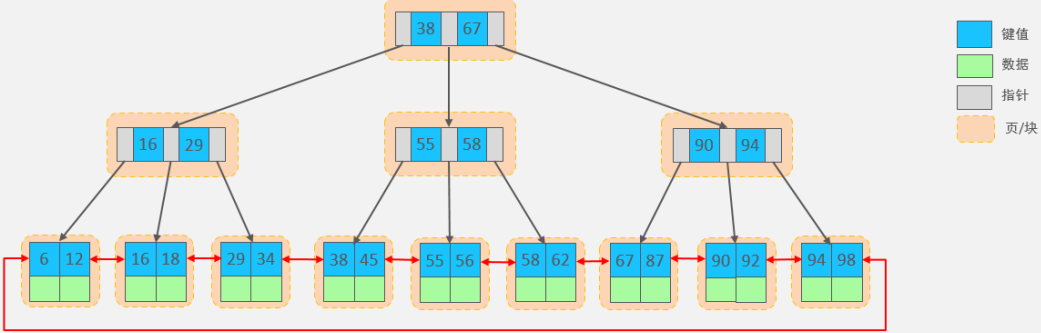
- 即使SQL命中了索引,如果表的資料量超過一千萬的話,查詢也是會明顯變慢的,這是因為索引一般是B+樹結構,資料千萬級別的話,B+樹的高度會增高,查詢就會變慢,
拓展:
MySQL默認的存盤引擎是 InnoDB,使用的索引結構是 B+樹,InnoDB存盤引擎最小儲存單元是頁,一頁大小就是16k,對于葉子節點,假設一行資料的大小為1k,那一頁中可以存盤16行這樣的資料,InnoDB的指標占用6個位元組的空間,主鍵即使為bigint,占用位元組數為8,
所以,對于非葉子節點,設每頁能存的鍵值為n,則
n * 8 + (n + 1) * 6 = 16*1024,可求得n約為1170,那每頁可以存盤的指標數為1171,因此,一棵高度為2的B+樹,能存放1171 * 16 = 18736條這樣的資料行,同理一棵高度為3的B+樹,能存放1171 *1171 *16 =21939856,接近2200W的資料行,B+樹的高度一般為1~3層,如果B+樹到了4層,查詢的時候會多查磁盤的次數(磁盤IO次數),SQL就會變慢,
講一下水平/垂直、分庫/分表?
水平分庫
以欄位為依據,按照一定策略,將一個庫的資料拆分到多個庫中,
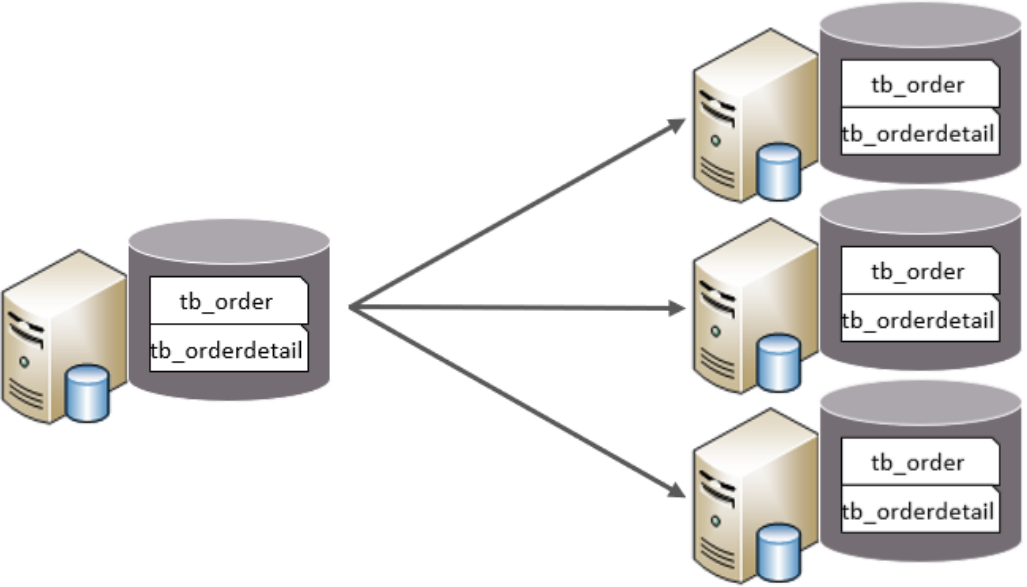
特點:
拆分后,每臺機器中,每個庫的表結構一樣,每個庫的資料都不一樣,所有庫的并集是全量資料,(相當于這個資料庫的每張表橫向分割成多個部分分別保存到不同的機器的資料庫中)
水平分表
以欄位為依據,按照一定策略,將一個表的資料拆分到多個表中,
特點:
拆分后,每臺機器中,每張表的表結構都一樣,每個表的資料都不一樣,所有表的并集是全量資料,
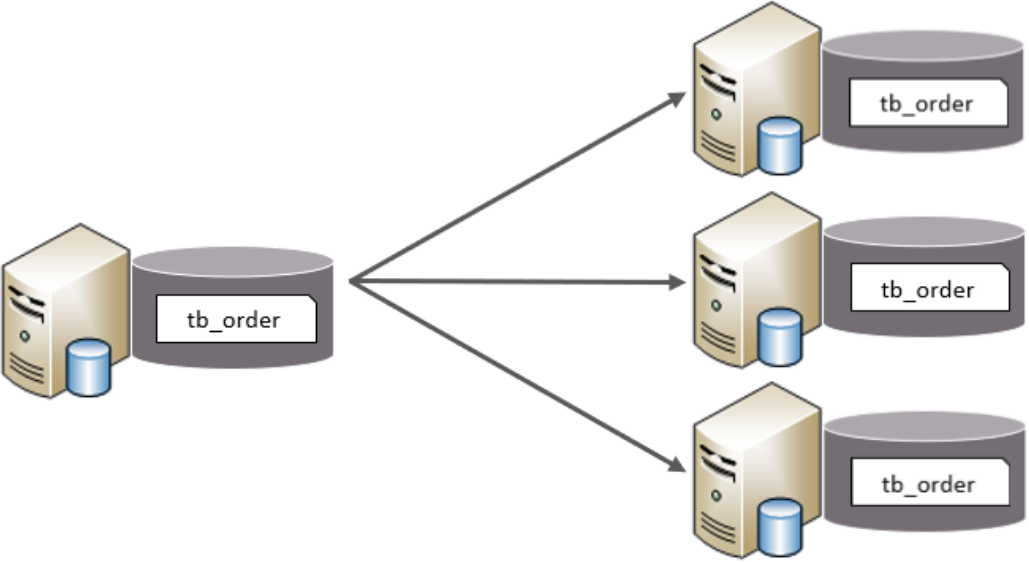
垂直分庫
以表為依據,根據業務將不同表拆分到不同庫中,
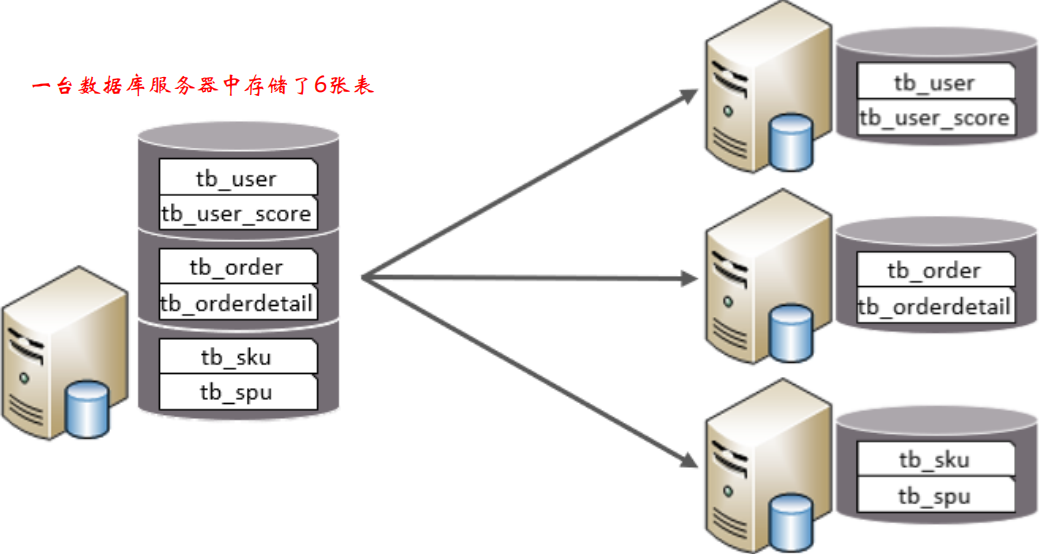
特點:
拆分后,每臺機器中,每張表的表結構都不一樣,每個表的資料也不一樣,所有庫的并集是全量資料,(相當于這個資料庫的每張表縱向分割成多個部分分別保存到不同的機器的資料庫中)
應用場景:
在業務發展初期,業務功能模塊比較少,為了快速上線和迭代,往往采用單個資料庫來保存資料,但是隨著業務蒸蒸日上,系統功能逐漸完善,這時候,可以按照系統中的不同業務進行拆分,比如拆分成用戶庫、訂單庫、積分庫、商品庫,把它們部署在不同的資料庫服務器,
垂直分表
以欄位為依據,根據欄位屬性將不同欄位拆分到不同表中,
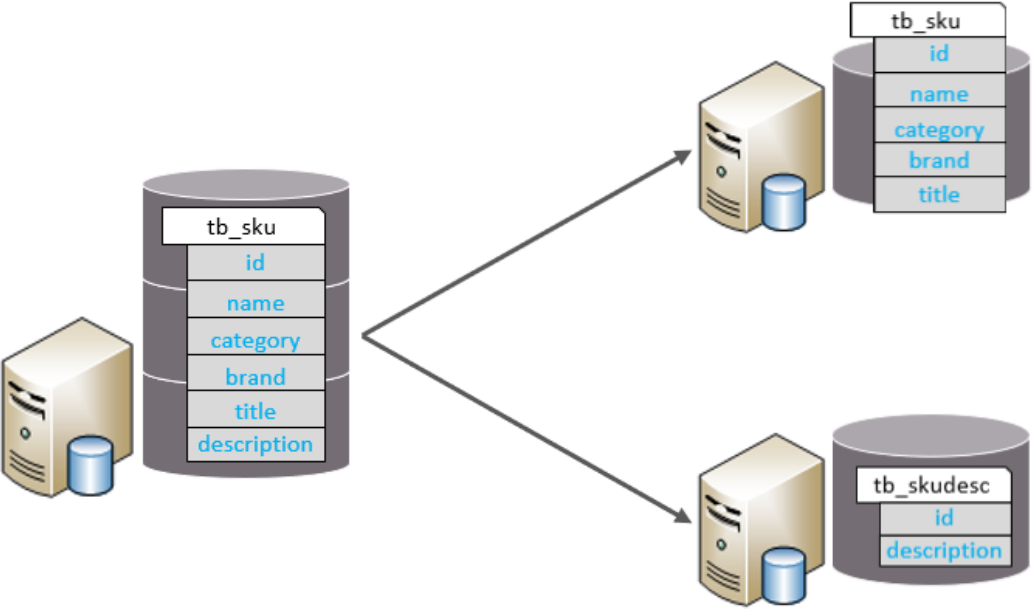
特點:
拆分后,每臺機器中,每張表的表結構都不一樣,每個表的資料也不一樣,一般通過一列(主鍵/外鍵)關聯,所有表的并集是全量資料,
應用場景:
如果一個單表包含了幾十列甚至上百列,管理起來很混亂,每次都select *的話,還占用IO資源,這時候,我們可以將一些不常用的、資料較大或者長度較長的列拆分到另外一張表,
分庫分表有哪些策略?
- 范圍分片
- 取模分片
- 一致性hash分片
范圍分片
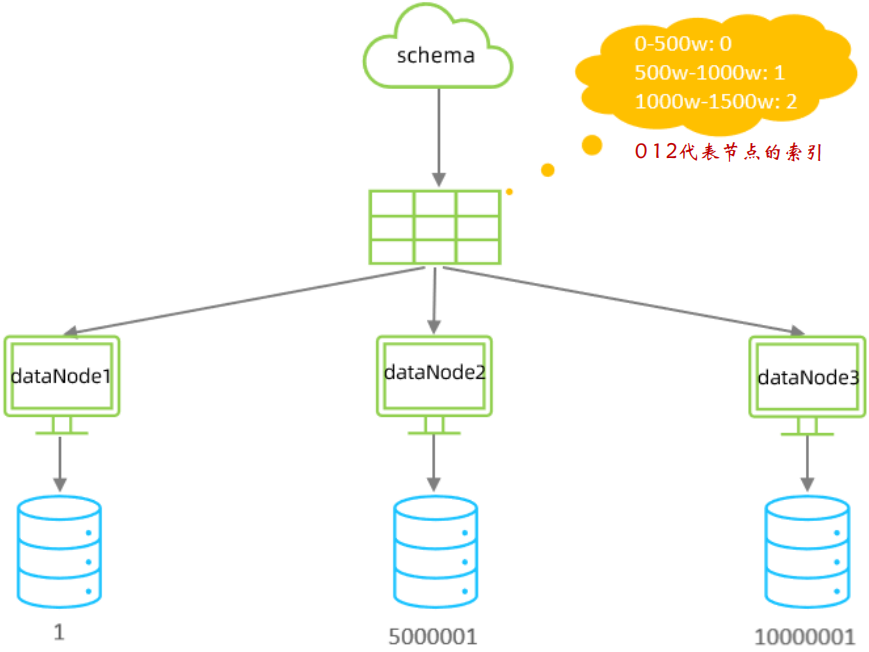
根據指定的欄位及其配置的范圍與資料節點的對應情況, 來決定該資料屬于哪一個分片,比如在訂單表中,我們可以利用表的主鍵,0-500萬之間的值,存盤在0號資料節點(資料節點的索引從0開始) ; 500萬-1000萬之間的資料存盤在1號資料節點 ; 1000萬-1500萬的資料節點存盤在2號節點, 依此類推,
優點:
這種方案有利于擴容,不需要資料遷移,假設資料量增加到2千萬,我們只需要水平增加一張表就好了,之前0~1500萬的資料,不需要遷移,
缺點:
這種方案會有熱點問題,因為訂單id是一直在增大的,也就是說最近一段時間都是匯聚在一張表里面的,比如最近一個月的訂單都在1000萬~2000萬之間,平時用戶一般都查最近一個月的訂單比較多,請求都打到order_1表啦,這就導致資料熱點問題,
該分片規則,主要是針對于數字型別的欄位適用,
取模分片
根據指定的欄位值與節點數量(機器數)進行求模運算,根據運算結果, 來決定該資料屬于哪一個分片,
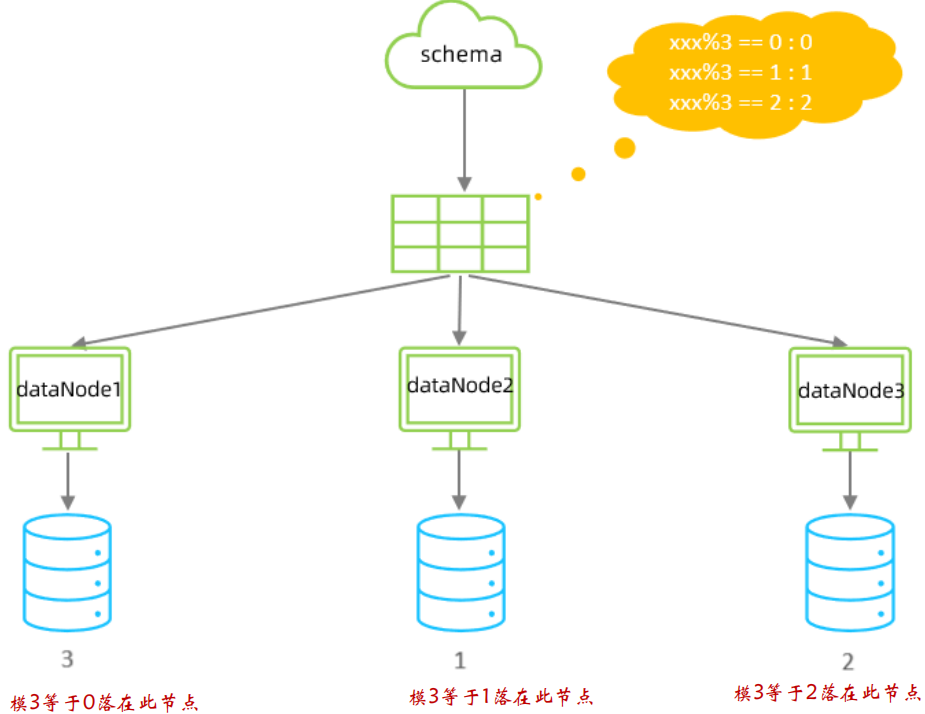
優點:
不會存在明顯的熱點問題,
缺點:
- 如果一開始按照取模分成3個表了,未來某個時候,表資料量又到瓶頸了,需要擴容,這就比較棘手了,比如你從3張表,又擴容成
6張表,那之前id=5的資料是在(5%3=2),現在應該放到(5%6=5),也就是說歷史資料要做遷移了, - 不適用于字串型別,如果主鍵是UUID(字串),那就不適用了,
一致性hash分片
所謂一致性哈希,相同的哈希因子計算值總是被劃分到相同的磁區表中,不會因為磁區節點的增加而改變原來資料的磁區位置,有效的解決了分布式資料的擴容問題,
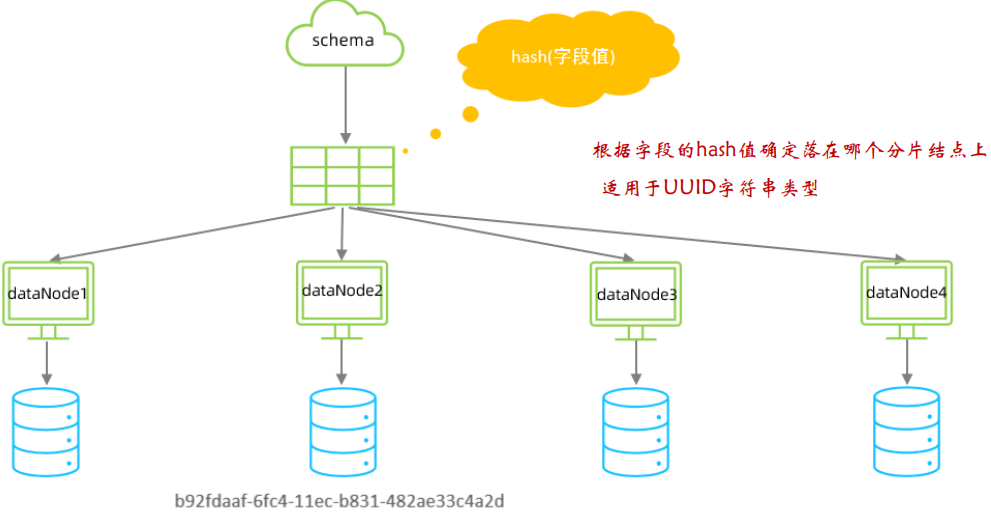
什么時候需要考慮分庫分表?
什么時候分庫?
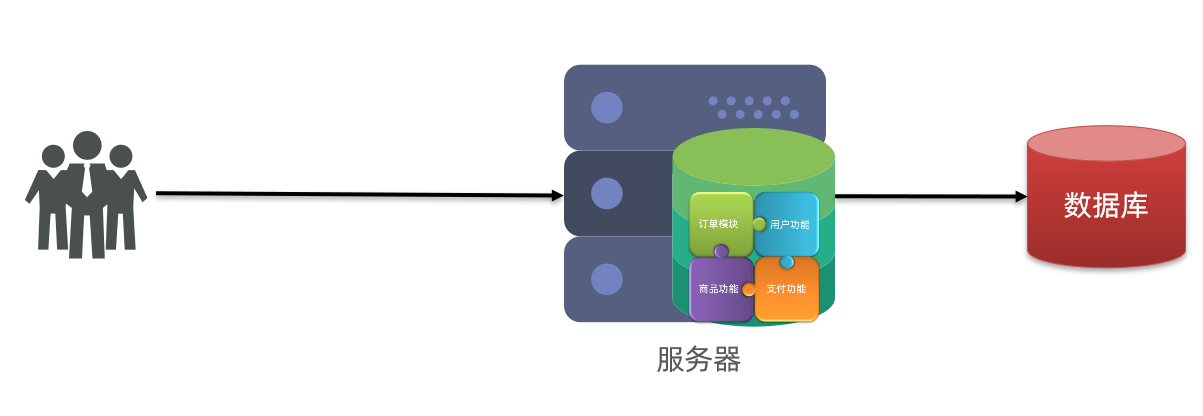
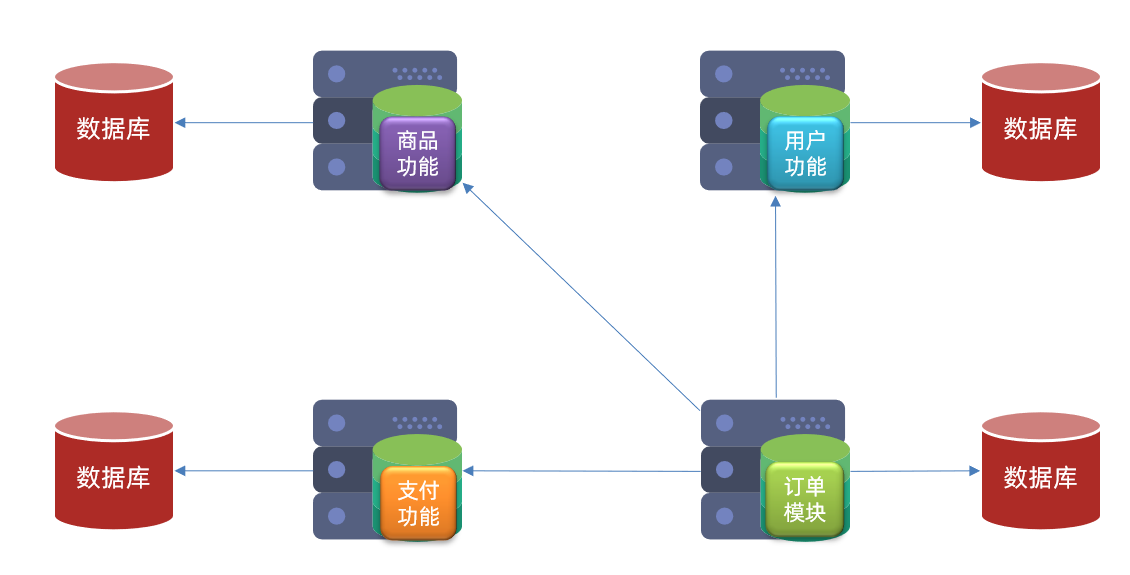
當你的業務發展很快,用戶急劇上漲,并且還是多個服務共享一個單體資料庫,資料庫成為了性能瓶頸,就需要考慮分庫了,比如用戶、商品、支付、訂單等,都可以抽取出來,整成一個獨立的服務(微服務),并且拆分對應的資料庫(用戶庫、商品庫、訂單庫),
什么時候分表?
如果你的系統處于快速發展時期,如果每天的訂單流水都新增幾十萬,并且,訂單表的查詢效率明變慢時,就需要規劃分表了,一般B+樹索引的高度是2~3層最佳(3層的B+樹都可容納超2000W的資料行),如果資料量千萬級別,可能高度就變4層了,資料量就會明顯變慢了,
分庫分表后存在什么問題?
分布式ID
我們往往直接使用資料庫自增特性來生成主鍵ID,這樣確實比較簡單,而在分庫分表的環境中,資料分布在不同的分片上,不能再借助資料庫自增長特性直接生成,否則會造成不同分片上的資料表主鍵會重復,
最簡單可以考慮UUID,或者使用雪花演算法生成分布式ID,
分頁問題
- 將不同分片上查到的結果進行匯總,再分頁;
- 把分頁交給前端,前端傳來pageSize和pageNo,在各個資料庫節點都執行分頁,然后匯聚總數量前端,這種方法,缺點就是會造成空查,
資料遷移,容量規劃,擴容等問題
很少有專案會在初期就開始考慮分片設計的,一般都是在業務高速發展面臨性能和存盤的瓶頸時才會提前準備,使用一致性Hash演算法可以避免后期分片集群擴容起來需要遷移舊的資料這一問題,
參考
黑馬程式員:https://www.bilibili.com/video/BV1Kr4y1i7ru
公眾號:撿田螺的小男孩 -《我們為什么要分庫分表?》
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/509546.html
標籤:MySQL
上一篇:Navicat 連接服務器不成功(Access denied for user 'root'@ '*.*.*.*' (using password: YES))