1 導讀
資料的一致性是資料準確的重要指標,那如何實作資料的一致性呢?本文從事務特性和事務級別的角度和大家一起學習如何實作資料的讀寫一致性,
2 一致性
1.資料的一致性:通常指關聯資料之間的邏輯關系是否正確和完整,
舉個例子:某系統實作讀寫分離,讀資料庫是寫資料庫的備份庫,小李在系統中之前錄入的學歷資訊是高中,經過小李努力學習,成功獲得了本科學位,小李及時把資訊變成成了本科,可是由于今天系統備份時間較長,小李變更資訊時,資料已經開始備份,公司的HR通過系統查詢小李資訊時,發現還是本科,小李的申請被駁回,這就是資料不一致問題,
2.資料庫的一致性:是指資料庫從一個一致性狀態變到另一個一致性狀態,這是事務的一致性的定義,
舉個例子:倉庫中商品A有100件,門店中商品A有10件,上午10點,倉庫發送商品A50件到門店,最后倉庫中有商品A50件,門店有商品A60件,這樣商品的總是是不變的,不能門店收到貨后,倉庫的商品A還是100件,這樣就出現資料庫不一致問題,倉庫和門店商品A的總數是110才是正確的,這就是資料庫的一致性,
3 資料庫事務
資料庫事務( transaction)是訪問并可能操作各種資料項的一個資料庫操作序列,這些操作要么全部執行,要么全部不執行,是一個不可分割的作業單位,事務由事務開始與事務結束之間執行的全部資料庫操作組成,
事務的性質:
- 原子性(Atomicity):事務中的全部操作在資料庫中是不可分割的,要么全部完成,要么全部不執行,
- 一致性(Consistency):幾個并行執行的事務,其執行結果必須與按某一順序 串行執行的結果相一致,
- 隔離性(Isolation):事務的執行不受其他事務的干擾,事務執行的中間結果對其他事務必須是透明的,
- 持久性(Durability):對于任意已提交事務,系統必須保證該事務對資料庫的改變不被丟失,即使資料庫出現故障
4 并發問題
資料庫在并發環境下會出現臟讀、重復讀和幻讀問題,
1.臟讀
事務A讀取了事務B未提交的資料,如果事務B回滾了,事務A讀取的資料就是臟的,
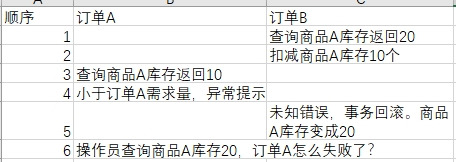
舉例:訂單A需要商品A20件,訂單B需要商品A10件,倉庫中有商品A庫存是20件,訂單B先查詢,發現庫存夠,進行扣減,在扣減的程序中,訂單A進行查詢,發現庫存只有10個不夠訂單數量,拋出例外,這時候訂單B提交失敗了,庫存數量又變成20了,這時候,倉庫人員去查庫存,發現數量是20,可是訂單A卻說庫存不足,這就讓人很奇怪,
2.不可重復讀
復讀指的是在一個事務內,最開始讀到的資料和事務結束前的任意時刻讀到的同一批資料出現不一致的情況,
舉例:庫房管理員查詢商品A的數量,讀取結果是20件,這是訂單A出庫,扣減了商品10件,這時管理員再去查商品A時,發現商品A的數量時10件和第一此查詢的結果不同了,

3.幻讀
事務A在執行讀取操作,需要兩次統計資料的總量,前一次查詢資料總量后,此時事務B執行了新增資料的操作并提交后,這個時候事務A讀取的資料總量和之前統計的不一樣,就像產生了幻覺一樣,平白無故的多了幾條資料,成為幻讀,
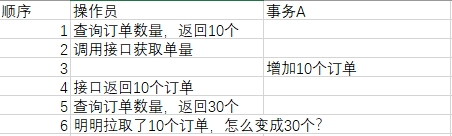
舉例:操作員查詢可生產單量10個,呼叫介面下發10個訂單,事務A增加10個訂單,操作員獲取10個訂單落庫,查詢 發現變成30個訂單,
5 事務隔離級別
Read Uncommitted(未提交讀)
一個事務可以讀取到其他事務未提交的資料,會出現臟讀,所以叫做 RU,它沒有解決任何的問題,
Read Committed(已提交讀)
一個事務只能讀取到其他事務已提交的資料,不能讀取到其他事務未提交的資料,它解決了臟讀的問題,但是會出現不可重復讀的問題,
Repeatable Read(可重復讀)
它解決了不可重復讀的問題,也就是在同一個事務里面多次讀取同樣的資料結果是一樣的,但是在這個級別下,沒有定義解決幻讀的問題,
Serializable(串行化)
在這個隔離級別里面,所有的事務都是串行執行的,也就是對資料的操作需要排隊,已經不存在事務的并發操作了,所以它解決了所有的問題,
6 解決資料讀一致性
有兩個方案可以解決讀一致性問題:基于鎖的并發操作(LBCC)和基于多版本的并發操作(MVCC)
6.1 LBCC
既然要保證前后兩次讀取資料一致,那么讀取資料的時候,鎖定我要操作的資料,不允許其他的事務修改就行了,這種方案叫做基于鎖的并發控制 Lock Based Concurrency Control(LBCC),
LBCC是通過悲觀鎖來實作并發控制的,
如果事務A對資料進行加鎖,在鎖釋放前,其他事務就不能對資料進行讀寫操作,這樣并發呼叫,改成了順序呼叫,對目前的大多數系統來說,性能完全不能滿足要求,
6.2 MVCC
要讓一個事務前后兩次讀取的資料保持一致,那么我們可以在修改資料的時候給它建立一個備份或者叫快照,后面再來讀取這個快照就行了,不管事務執行多長時間,事務內部看到的資料是不受其它事務影響的,根據事務開始的時間不同,每個事務對同一張表,同一時刻看到的資料可能是不一樣的,這種方案我們叫做多版本的并發控制 Multi Version Concurrency Control(MVCC),
MVCC是基于樂觀鎖的,
在 InnoDB 中,MVCC 是通過Undo log中的版本鏈和Read-View一致性視圖來實作的,
6.2.1 Undo log
undo log是innodb引擎的一種日志,在事務的修改記錄之前,會把該記錄的原值先保存起來再做修改,以便修改程序中出錯能夠恢復原值或者其他的事務讀取,undo log是一種用于撤銷回退的日志,在事務沒提交之前,MySQL會先記錄更新前的資料到 undo log日志檔案里面,當事務回滾時或者資料庫崩潰時,可以利用 undo log來進行回退,
對資料變更的操作不同,undo log記錄的內容也不同:
- 新增一條記錄的時候,在創建對應undo日志時,只需要把這條記錄的主鍵值記錄下來,如果要回滾插入操作,只需要根據對應的主鍵值對記錄進行洗掉操作,
- 洗掉一條記錄的時候,在創建對應undo日志時,需要把這條資料的所有內容都記錄下來,如果要回滾洗掉陳述句,需要把記錄的資料內容生產相應的insert陳述句,并插入到資料庫中,
- 更新一條記錄的時候,如果沒有更新主鍵,在創建對應undo日志時,如果要回滾更新陳述句,需要把變更前的內容記錄下來,如果要回滾更新陳述句,需要根據主鍵,把記錄的資料更新回去,
- 更新一條記錄的時候,如果有更新主鍵,在創建對應undo日志時,需要把資料的所有內容都記錄下來,如果要回滾更新陳述句,先把變更后的資料刪掉,再執行插入陳述句,把備份的資料插入到資料庫中,
undo log版本鏈
每條資料有兩個隱藏欄位,trx_id 和 roll_pointer,trx_id表示最近一次事務的id,roll_pointer表示指向你更新這個事務之前生成的undo log,
事務ID:MySQL維護一個全域變數,當需要為某個事務分配事務ID時,將該變數的值作為事務id分配給事務,然后將變數自增1,
舉例:
- 事務A id是1 插入一條資料X,這條資料的trx_id =1 ,roll_pointer 是空(第一次插入),
- 事務B id 是2 對這條資料進行了更新,這條資料的 trx_id =2 ,roll_pointer 指向 事務A的undo log.
- 事務C id 是3 又對資料進行了更新操作,這條資料的trx_id =3,roll_pointer 指向 事務B的undo log.
所以當多個事務串行執行的時候,每個事務修改了一行資料,都會更新隱藏欄位trx_id 和 roll_pointer,同時多個事務的undo log會通過roll_pointer指標串聯起來,形成undo log版本鏈,
6.2.2 Read-View一致性視圖
InnoDB為每個事務維護了一個陣列,這個陣列用來保存這個事務啟動的瞬間,當前活躍的事務ID,這個陣列里有兩個水位值: 低水位(事務ID 最小值)和 高水位(事務ID 最大值 + 1);這兩個水位值就構成了當前事務的一致性視圖(Read-View)
ReadView中主要包含4個比較重要的內容:
- m_ids:表示在生成ReadView時當前系統中活躍的讀寫事務的事務id串列,
- min_trx_id:表示在生成ReadView時當前系統中活躍的讀寫事務中最小的事務id,也就是m_ids中的最小值,
- max_trx_id:表示生成ReadView時系統中應該分配給下一個事務的id值,
- creator_trx_id:表示生成該ReadView的事務的事務id,
有了這些資訊,這樣在訪問某條記錄時,只需要按照下邊的步驟判斷記錄的某個版本是否可見:
- 如果被訪問版本的trx_id屬性值與ReadView中的creator_trx_id值相同,意味著當前事務在訪問它自己修改過的記錄,所以該版本可以被當前事務訪問,
- 如果被訪問版本的trx_id屬性值小于ReadView中的min_trx_id值,表明生成該版本的事務在當前事務生成ReadView前已經提交,所以該版本可以被當前事務訪問,
- 如果被訪問版本的trx_id屬性值大于ReadView中的max_trx_id值,表明生成該版本的事務在當前事務生成ReadView后才開啟,所以該版本不可以被當前事務訪問,
- 如果被訪問版本的trx_id屬性值在ReadView的min_trx_id和max_trx_id之間,那就需要判斷一下trx_id屬性值是不是在m_ids串列中,如果在,說明創建ReadView時生成該版本的事務還是活躍的,該版本不可以被訪問;如不在,說明創建ReadView時生成該版本的事務已經被提交,該版本可以被訪問,
- 如果某個版本的資料對當前事務不可見的話,那就順著版本鏈找到下一個版本的資料,繼續按照上邊的步驟判斷可見性,依此類推,直到版本鏈中的最后一個版本,如果最后一個版本也不可見的話,那么就意味著該條記錄對該事務完全不可見,查詢結果就不包含該記錄,
6.2.3 資料的查找方式
1.快照讀
快照讀又叫一致性讀,讀取的是歷史版本的資料,不加鎖的簡單的SELECT都屬于快照讀,即不加鎖的非阻塞讀,只能查找創建時間小于等于當前事務ID的資料或者洗掉時間大于當前事務ID的行(或未洗掉),
2.當前讀
當前讀查找的是記錄的最新資料,加鎖的SELECT、對資料進行增刪改都會進行當前讀,
6.2.4 資料舉例
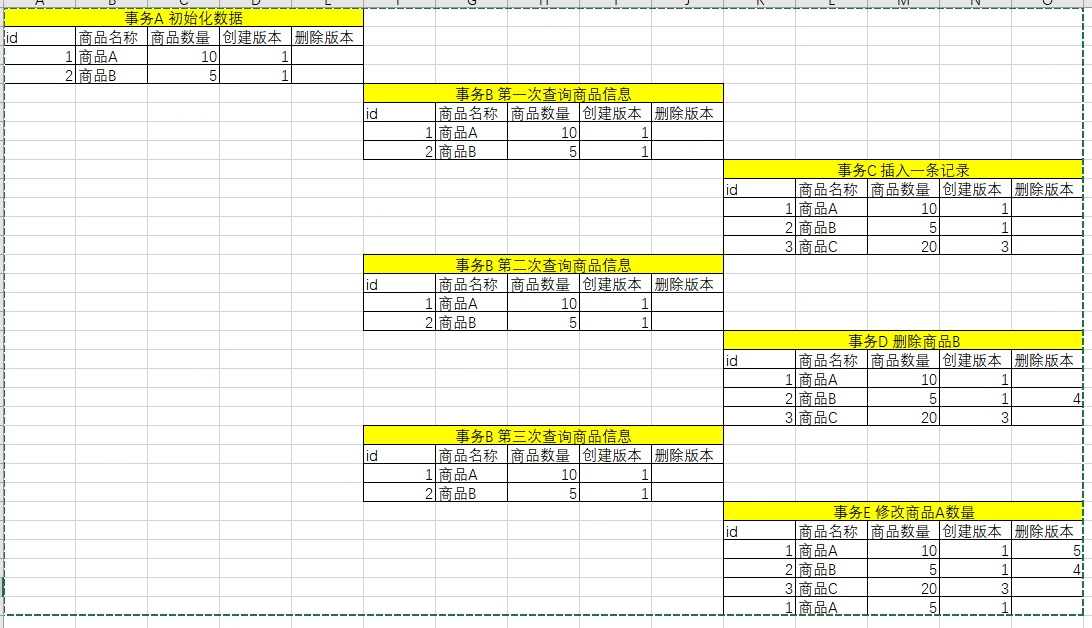
如圖所示:
事務A id =1 初始化了資料
事務B id=2 進行了查詢操作(MVCC只讀取創建時間小于當前事務ID的資料或者洗掉時間大于當前事務ID的行)
事務B的結果是 (商品A:10,商品B:5)
事務C id =3 插入了商品C
事務B id=2 進行了查詢操作(MVCC只讀取創建時間小于當前事務ID的資料或者洗掉時間大于當前事務ID的行)
事務B的結果是 (商品A:10,商品B:5)
事務D id =4 洗掉商品B
事務B id=2 進行了查詢操作(MVCC只讀取創建時間小于當前事務ID的資料或者洗掉時間大于當前事務ID的行)
事務B的結果是 (商品A:10,商品B:5)
事務E id =4 修改商品A的數量
事務B id=2 進行了查詢操作(MVCC只讀取創建時間小于當前事務ID的資料或者洗掉時間大于當前事務ID的行)
事務B的結果是 (商品A:10,商品B:5)
所以當事務E提交后,當前讀獲取的資料和事務B讀取的快照資料明顯不同,
6.2.5 可解決問題
MVCC可以很好的解決讀一致問題,只能看到這個時間點之前事務提交更新的結果,而不能看到這個時間點之后事務提交的更新結果,而且降低了死鎖的概率和解決讀寫之間堵塞問題,
7 小結
LBCC和MVCC都可以解決讀一致問題,具體使用哪種方式,要結合業務場景選擇最合適的方式,MVCC和鎖也可以結合使用,沒有最好只有更好,
作者:陳昌浩
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/509726.html
標籤:其他
上一篇:記一次批量更新整型型別的列 → 探究 UPDATE 的使用細節
下一篇:?小長假要到了,來偶遇嗎?