作為國民經濟的命脈和樞紐,金融行業對底層資料庫的能力要求正在不斷提高,在眾多要求中,資料一致性無疑是重中之重,即資料不能出錯,最好還能提高并發效率,
TDSQL采用MC(輕量級GTM)+全域MVCC的全域讀一致性方案,如果只使用全域事務管理器GTM,除需維護全域序列外,還需要維護全域的事務沖突,這個程序的通信量及與GTM之間的通信頻率都會成為瓶頸,TDSQL引入全域MVCC,將每個分片上MVCC版本和全域GTS做映射,通過全域GTS和全域的MVCC映射來管理每個分片上的鏡像,進而實作全域的MVCC,從而極大減少和GTM 之間的通信量及避免全域的沖突事務檢測,
上述方案確保了TDSQL無任何資料例外,且具備高性能的可擴展性,解決了分布式資料庫在金融級場景應用的最核心技術挑戰,使得國產分布式資料庫實作在金融核心系統場景的可用、好用,進而推動國產基礎軟體產業化,基于此,TDSQL是當前國內率先進入國有大型銀行核心系統正式投產的國產分布式資料庫,
在WOT全球技術創新大會2022的騰訊云資料庫專場中,騰訊云資料庫專家架構師汪泗龍分享了金融級分布式資料庫TDSQL的一致性技術及應用實踐,以下為詳情內容:
一、TDSQL產品介紹
1.1 發展歷程
騰訊云資料庫TDSQL誕生自騰訊內部百億級賬戶規模的金融級場景,從內部自研蛻變成規模化商業產品,TDSQL的發展歷程可分為四個階段:
第一階段是2007-2009年,當時開源的MySQL已經越來越難以應對騰訊爆發式增長的業務,研制服務于計費、定位于金融場景的分布式資料庫TDSQL逐漸提上日程,
第二階段是2009-2012年,騰訊進入開放時代,海量業務群雄并起,以開心農場等為代表的眾多億級應用比比皆是,TDSQL逐漸在性能瓶頸、資料可靠性保障、高可用等“不可能三角”的技術難題上取得突破,
第三階段是2012-2014年,云計算興起,資料庫上云、多租戶、標準化成為標配,騰訊云資料庫的能力逐漸外溢,TDSQL因其優異的性能已經擁有眾多外部客戶,在經過公有云的海量數字化、大規模高并發業務場景打磨以及內核級的深度自研優化后,TDSQL逐漸形成標準化的國產分布式資料庫產品,包括金融級分布式TDSQL、計算與存盤分離的云原生資料庫TDSQL-C 等產品,獲得了云原生技術、多租戶隔離能力,
第四階段是2014-2020年,數字化升級成為行業趨勢,TDSQL深入金融核心,走向大規模應用階段,比如作為微眾銀行分布式資料庫底座承擔核心作用,幫助張家港農商銀行上線新一代核心業務系統,助力平安銀行打造信用卡“A+”新核心系統等等,
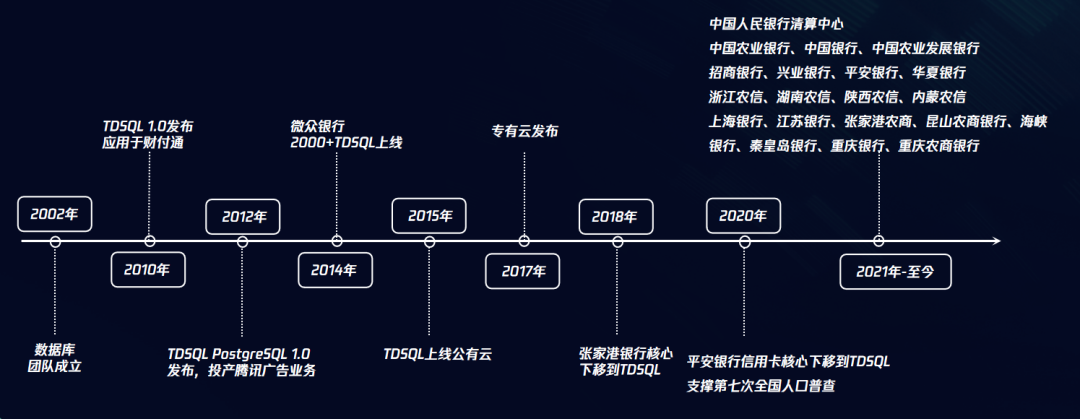
目前,TDSQL已服務金融、政務、工業制造等行業超過50萬家客戶,幫助20余家金融機構完成核心替換,國內TOP 10銀行機構服務占比超過60%,同時TDSQL也支持了第七次全國人口普查,以及騰訊會議、健康碼等關系國計民生的數字化應用,有力推進國產資料庫的技術創新和發展,
1.2 核心特性
隨著云計算和數字化業務的發展,針對新型企業級資訊化以及實作國產化的轉型升級需求,TDSQL逐漸形成6大核心特性:
- 資料強一致性:確保多副本架構下資料強一致,避免故障后導致集群資料錯亂和丟失,
- 金融級高可用:確保99.999%以上高可用;跨區容災;同城雙活;故障自動恢復,
- 高性能低成本:軟硬結合;支持讀寫分離、秒殺、紅包、全球同服等超高性能場景,
- 企業級安全性:資料庫防火墻;透明加密;自動脫敏;減少用戶誤操作/黑客入侵帶來的安全風險,
- 線性水平擴展:無論是資源還是功能,均提供良好的擴展性,
- 便捷的運維:完善的配套設施,包括智能DBA、自助化運營管理臺,
1.3 產品架構
TDSQL的架構主要分為三層,最上層是管理層,包含赤兔管理平臺、MC以及Keeper,中間層是SQL引擎,可以選擇使用TDSQL附帶的接入層,也可使用傳統意義上的F5等接入層來進行接入,最下層是存盤引擎層,即TDSQL內核,
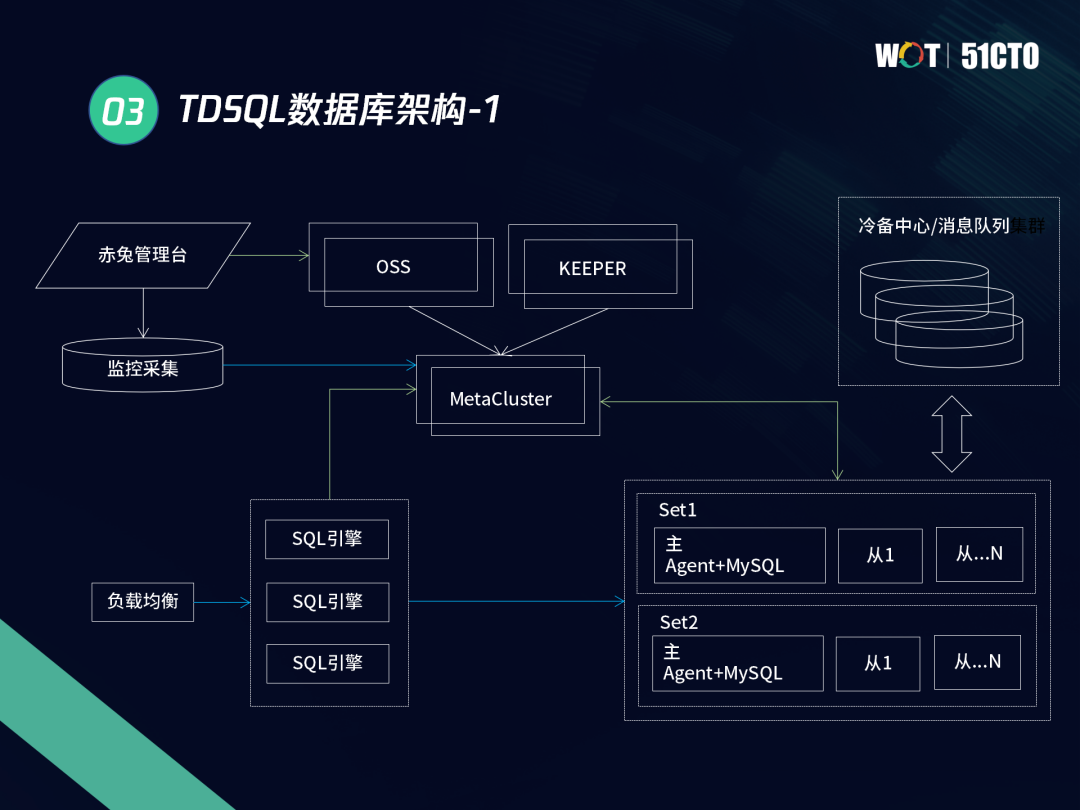
下圖是實作 GTM 全域唯一序列的圖簽,這里是TDSQL在實作分布式事務后在全域一致性讀方面的優化點,該插件實作了輕量級的GTM,
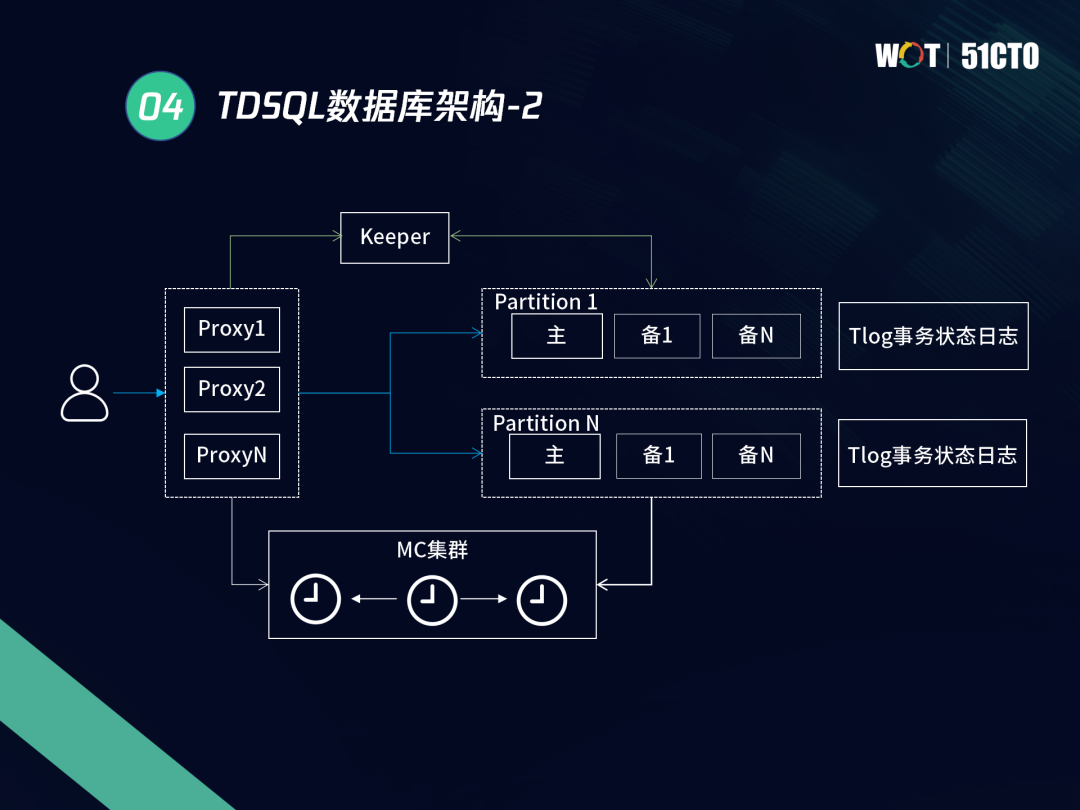
二、分布式事務處理
事務處理面臨的挑戰有兩點:保障資料正確性及提高并發效率,這兩點都是事務處理的關鍵點,如果為了提高并發效率而犧牲資料正確性,就背離了初衷,反之也是如此,為了解決這兩個問題,我們需要用到很多技術,比如讀寫分離、物理時鐘、時間戳機制、GTM等,

2.1 分布式事務模型
不管是分布式資料庫還是應用,都是在分布式事務模型下,進行分布式事務的實踐和開發,對資料庫而言,常用的分布式事務模型是XA模型;對應用而言,主要是TCC、SAGA、AT等模型,
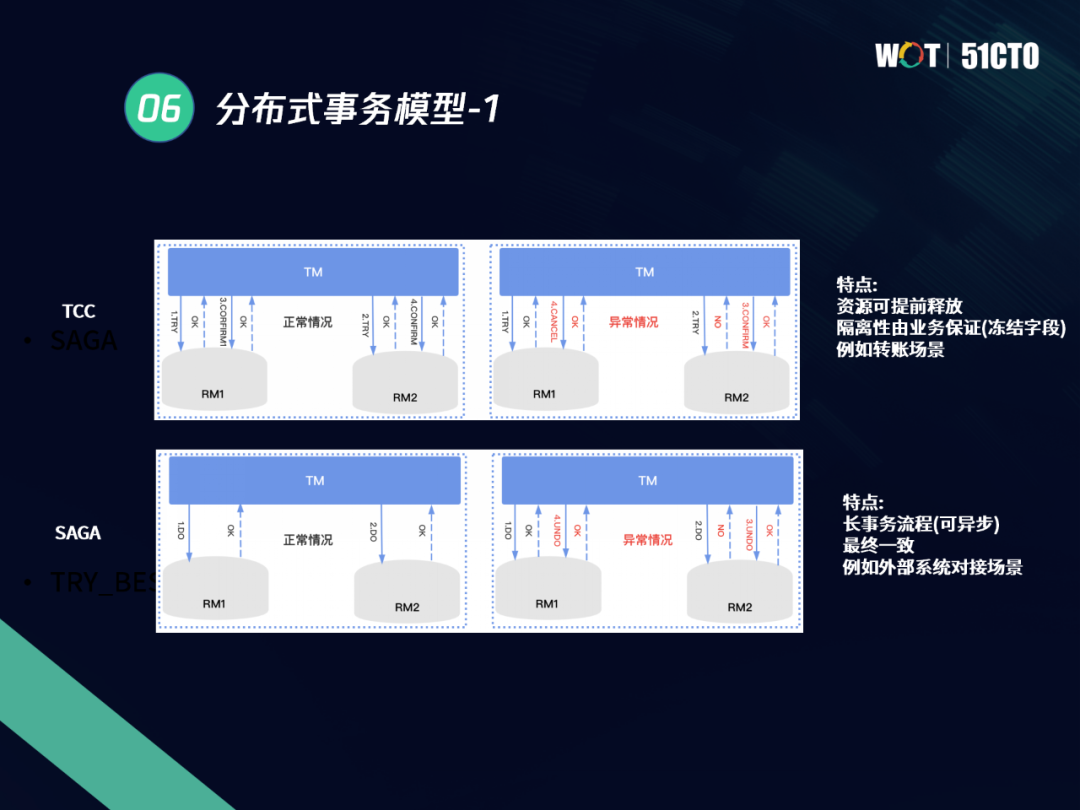
Oracle、MySQL、TDSQL等資料庫,通常使用XA模型來進行分布式事務處理,在XA模型里,事務主要采用兩階段提交方式,先進行PREPARE,再進行COMMIT,也稱之為兩階段事務,
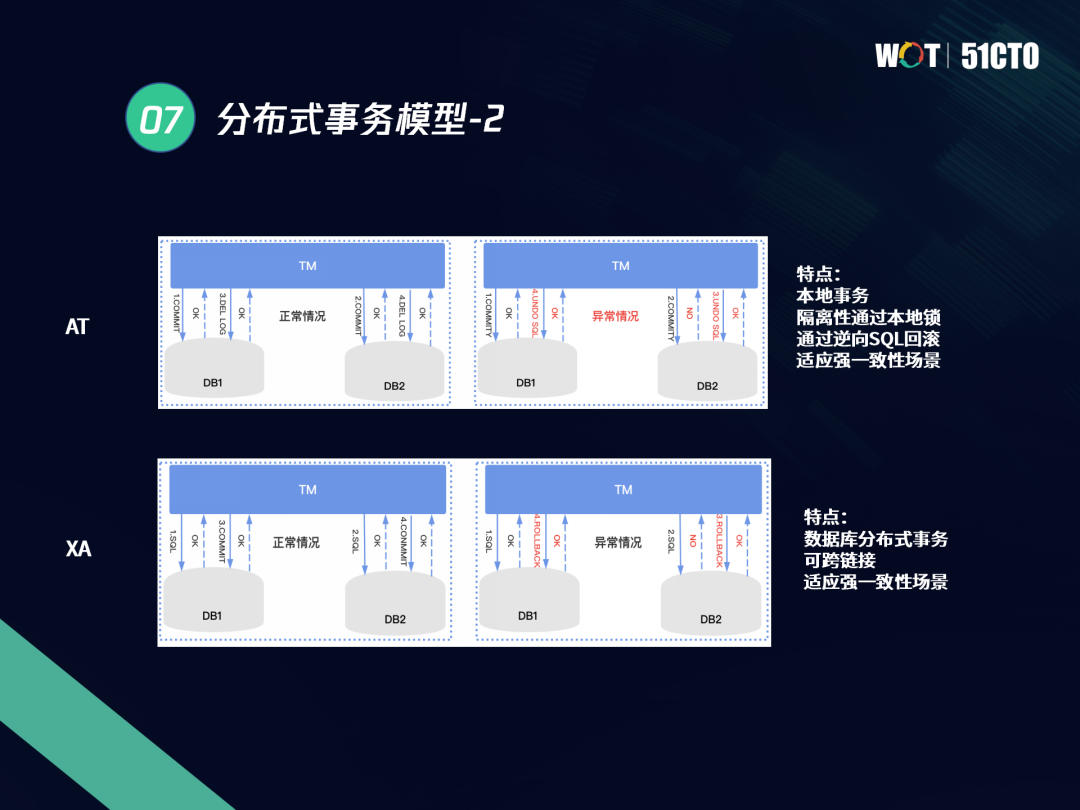
2.2 資料例外問題
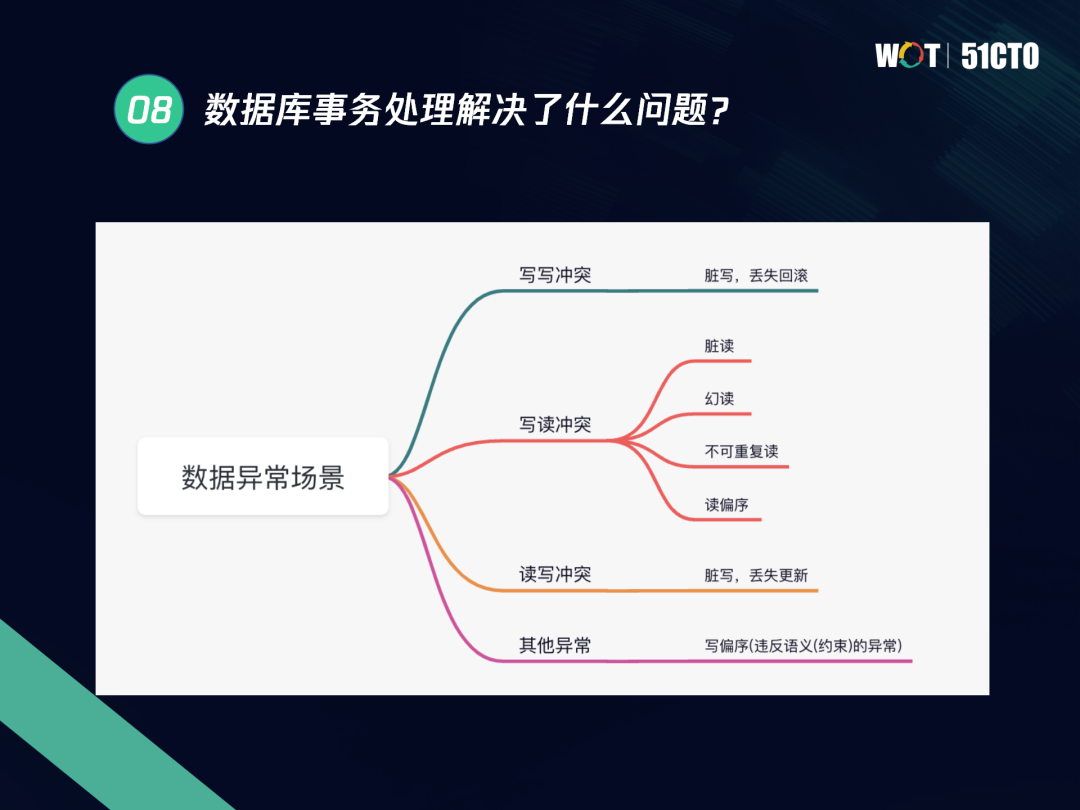
事務模型簡化后劃分為讀寫兩類操作,組合下來有四種場景,即讀寫、寫讀、讀讀、寫寫,存在沖突(資料例外)的場景主要是寫寫、寫讀、讀寫,具體的沖突如下:
- 寫寫沖突:會出現臟寫、丟失回滾,
- 寫讀沖突:會出現臟讀、幻讀、不可重復讀、讀偏序等,
- 讀寫沖突:會出現臟寫、丟失更新等,
- 其他例外:主要是寫偏序,即違背語意(約束)的例外,兩筆事務同時發生,每筆事務都滿足約束,但在分別進行的程序中,因為沒有提前加鎖,沒有滿足語意,導致最終事務完成后違背了語意約束,
針對上述問題,我們可以通過資料庫的并發控制演算法來解決:
- 基于鎖(兩階段鎖)進行控制:兩階段鎖除我們常用的2PL外還有S2PL、SS2PL,主要是鎖定階段的不同,在種類上主要有S鎖、X鎖、U鎖、間隙鎖,
- 基于MVCC的方案:將讀寫進行分離,支持多版本和快照,
- 基于時間戳進行控制:主要有三個時間戳,即事務啟動時的時間戳、資料讀的時間戳以及資料寫的時間戳,
- 基于有效性確認來進行控制,
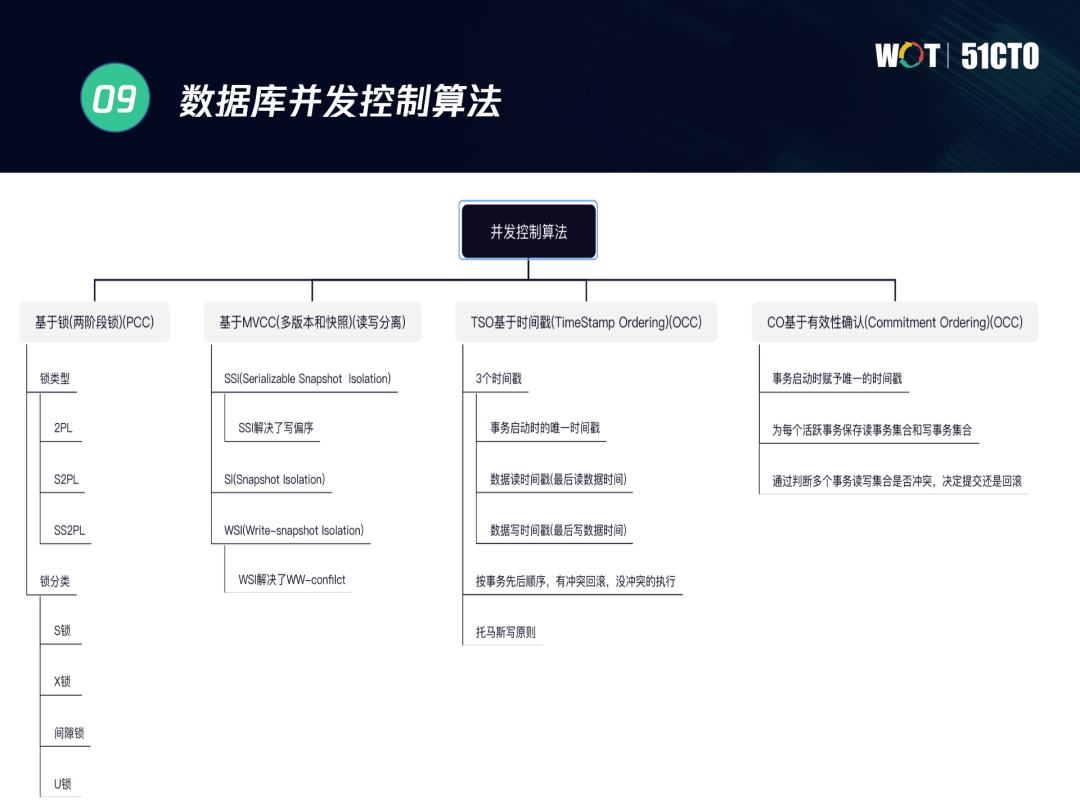
我們需要根據不同的場景來使用不同的演算法,在分布式事務處理方面,TDSQL使用的是2PL加上MVCC特性,
2.3 全域讀不一致問題
我們以下圖為例說明全域讀不一致問題,有A、B兩個賬戶,賬戶余額均為100元,有兩個事務,事務X和事務Y,事務X是A給B轉100元,事務Y是讀取A和B的余額,當事務Y發起查詢時,事務X中(NA分片屬于COMMITting狀態,NB分片屬于COMMITed狀態),這時讀到兩人余額總和為300元,這就是分布式事務進行程序中的全域讀不一致問題,
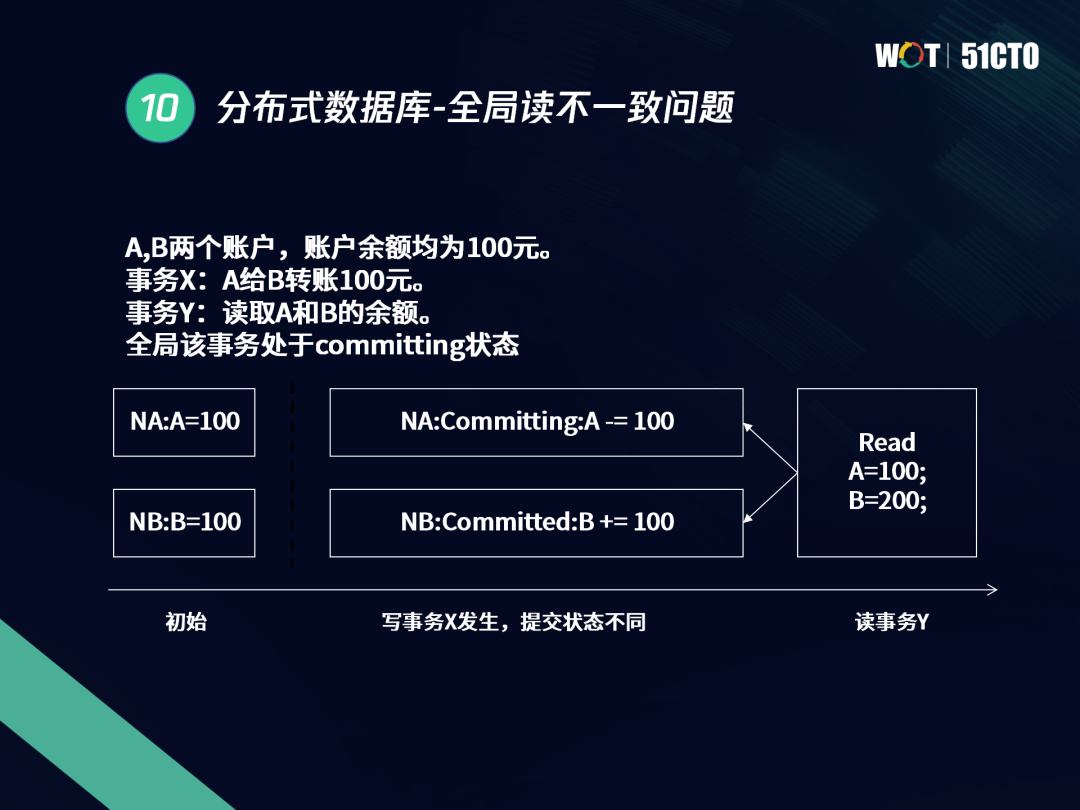
出現這種全域讀不一致的情況,主要原因在于這里沒有全域一致的MVCC版本,而是依賴每個分片各自的MVCC特征進行實作,我們讀到的NA片還沒提交,因此讀到的資料是不一致的資料,針對上述例外情況,主要有以下幾種解決方案:
- 利用全域事務管理器GTM,GTM會提供一個全域序列來滿足使用,還會維護全域的事務沖突串列,
- 以封鎖機制實作全域可串行化,將所有的讀寫都變成相關的邏輯上的DML操作,實作全域封鎖,這個程序可以解決所有的讀寫沖突,從而實作全域讀一致性,但這種模式會帶來性能上的問題,導致效率降低,
- 采用物理時鐘排序,其缺點在于成本高,且效率比全域封鎖的效率低,
- 采用混合時間戳機制實作區域偏序排序,但這個方案只限于特定場景,
- 兩次讀機制,第一次讀發現資料不一致就會發起第二次讀,直到可以給到客戶一致性的版本,
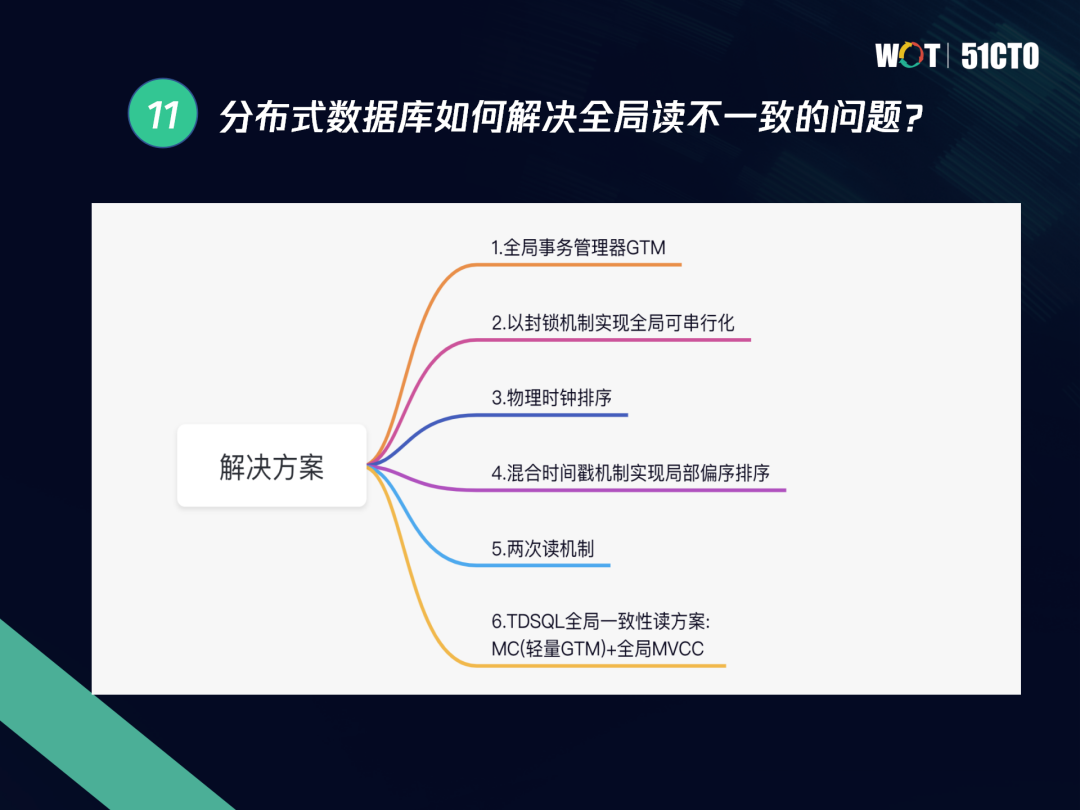
TDSQL的全域讀一致性方案是MC(輕量級GTM)+全域MVCC,只使用全域事務管理器GTM的方案,除需維護全域序列外,還需要維護全域的事務沖突,這個程序的通信量及與GTM之間的通信頻率都會成為瓶頸,因此需要引入另一個特性——全域MVCC,這時的讀寫沖突可通過undo的前鏡像完成一個全域的MVCC來實作,解決各副本間的讀寫沖突,
完全重新開發一套全域MVCC的成本較高,且和InnoDB的兼容性是個問題,因此我們采用了折中方式,我們將每個分片上MVCC版本和全域GTS做映射,通過全域GTS和全域的MVCC映射來管理每個分片上的鏡像,進而實作全域的MVCC,這樣就可極大減少和GTM 之間的通信量及避免全域的沖突事務檢測,
三、TDSQL分布式事務實踐
3.1 TDSQL分布式事務模型
下圖為TDSQL分布式事務的實作模型,主要有三個角色:
- TM:SQLEngine充當事務管理器角色,負責發起分布式事務,
- RM:DB節點相當于分布式事務的資源節點(RM),作為分布式事務的重要參與者,
- TC:XID_LOG作為分布式事務協調者的角色,確認PREPARE狀態的完成,
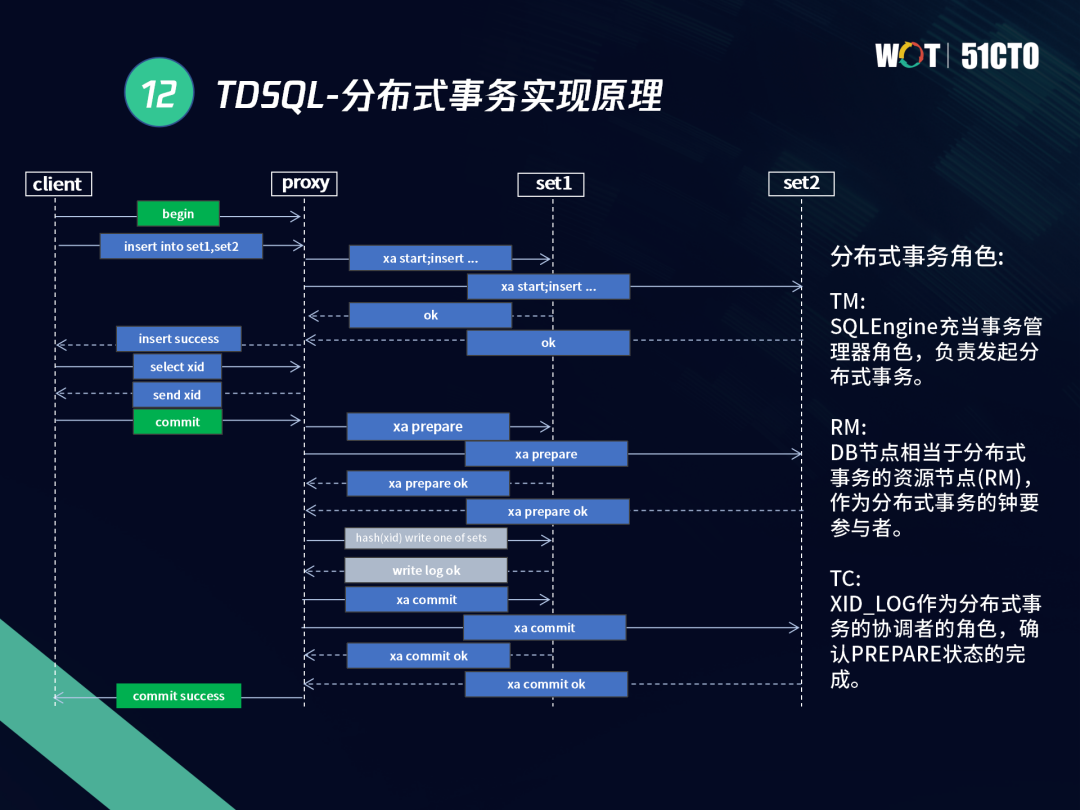
通過Client發起一個事務BEGIN后,會往后端發起一個插入陳述句到Proxy,此時Proxy發起XA Start,到后端的兩個SET上,兩個SET回傳正常后則插入成功,獲取到XID后,開始正式進入COMMIT階段,Client發起COMMIT后,Proxy往后端發時就會帶著全域的XID往后提交,這時進入PREPARE和COMMIT階段,
當所有參與者PREPARE成功后,會插入全域的XID_LOG,XID_LOG是PREPARE階段的一個平衡點,解決懸掛等待的高成本及超時回滾等問題,一旦事務進入到這個階段,寫入全域的XID_LOG成功后,即使后面的操作失敗,我們依然會認為事務是成功的,針對沒有提交成功的事務,Agent參與進來,掃描XID_LOG表進行后續處理;如果執行超時,Agent會參與進來,終止掉超時的事務,之后Agent會更新XID_LOG的狀態,
Proxy和Agent是協作模式,XID同一時間點只能有一種狀態,我們可以通過這種狀態來協調Proxy和Agent,如果Proxy Crash掉,Agent進行任務接管,根據XID_LOG的資訊決定對事務進行補提交或回滾,在此程序中,Proxy本身是無狀態的,這就使得TDSQL具備良好的業務體驗,
如果在主備程序中,一個SET發生主備切換,另外一個SET正常,這時Agent會根據全域XID_LOG的狀態進行相關補償或者回滾,如果XID_LOG寫成功,我們會進入到最終的COMMIT階段,兩個分片分別COMMIT成功后,會正常反饋給Client端,以上就是TDSQL基于XA兩階段提交的分布式事務模型和原理,
3.2 TDSQL全域一致性讀實作方案
分布式資料庫,不僅要解決分布式事務的問題,還要解決全域寫讀沖突,從而實作全域的一致性讀,TDSQL具體的實作方案如圖所示:
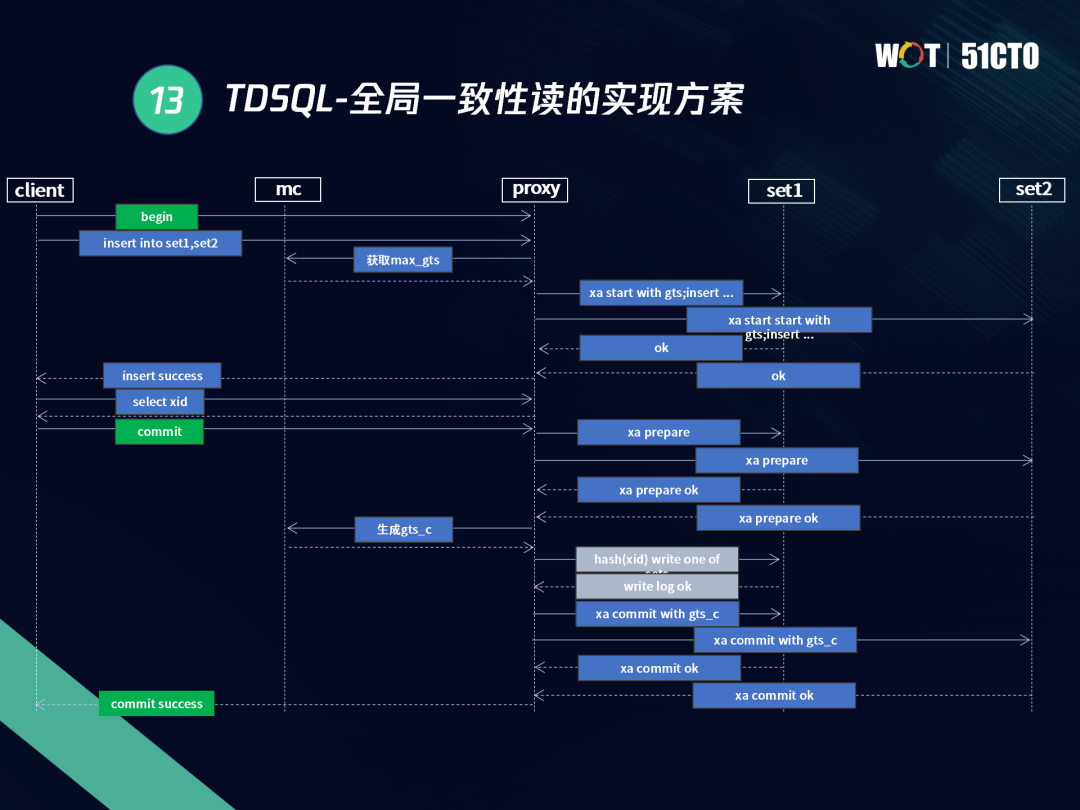
與前面提到的TDSQL分布式事務模型相比,整體架構較為相似,區別在于多了一個MC組件,
MC是全域的輕量級GTM,負責生成全域的唯一序列,以上述兩個SET的插入的事務模型為例,整個程序中只是多了兩次和GTM之間的獲取步驟,其他流程是一致的,
當我們發起一個分布式事務,在CLIENT啟動及提交時,我們會在這里再加入一個階段,獲取全域最大的GTS,GTS是標識的全域唯一序列,XID是唯一標識全域事務的標簽,兩者相互獨立分別保證分布式場景下讀取一致性和事務一致性,在COMMIT發起后進入兩階段提交,這里需要對PREPARE階段進行判定,通過XID_LOG日志來作為全域提交成功的標識,在PREPARE成功后,PROXY和MC會進行第二次互動,重新獲取COMMIT_GTS,并伴隨事務的COMMIT寫入到TDSQL REDO日志和快取中,相對于XA的START和COMMIT,TDSQL為了實作全域的MVCC特性,改寫了XA的語法,增加部分關鍵詞,同時對內核做微量調整,以上就是TDSQL實作全域一致性讀的方案,
在該方案中,我們和MC的通信量非常少,整個程序中基本只有2次非常輕量的通信,某些場景下當我們進行一個不涉及多分片的事務時,即如果只涉及一個分片,我們會對第二次獲取COMMIT_GTS進行優化,進一步減少和MC通信,實際上,TDSQL實作分布式事務和分布式全域一致性的方案,是把InnoDB自身的MVCC和全域GTS進行全域映射,從而實作全域輕量級的GTM+全域的MVCC,
下圖是InnoDB的MVCC模型,共有六個事務,當前事務ID是trx6,為活躍狀態,眾所周知,InnoDB會將trxid直接排序,通過全域事務鏈表管理維護,我們以下圖為例來說明可見性演算法是如何對外可見的,
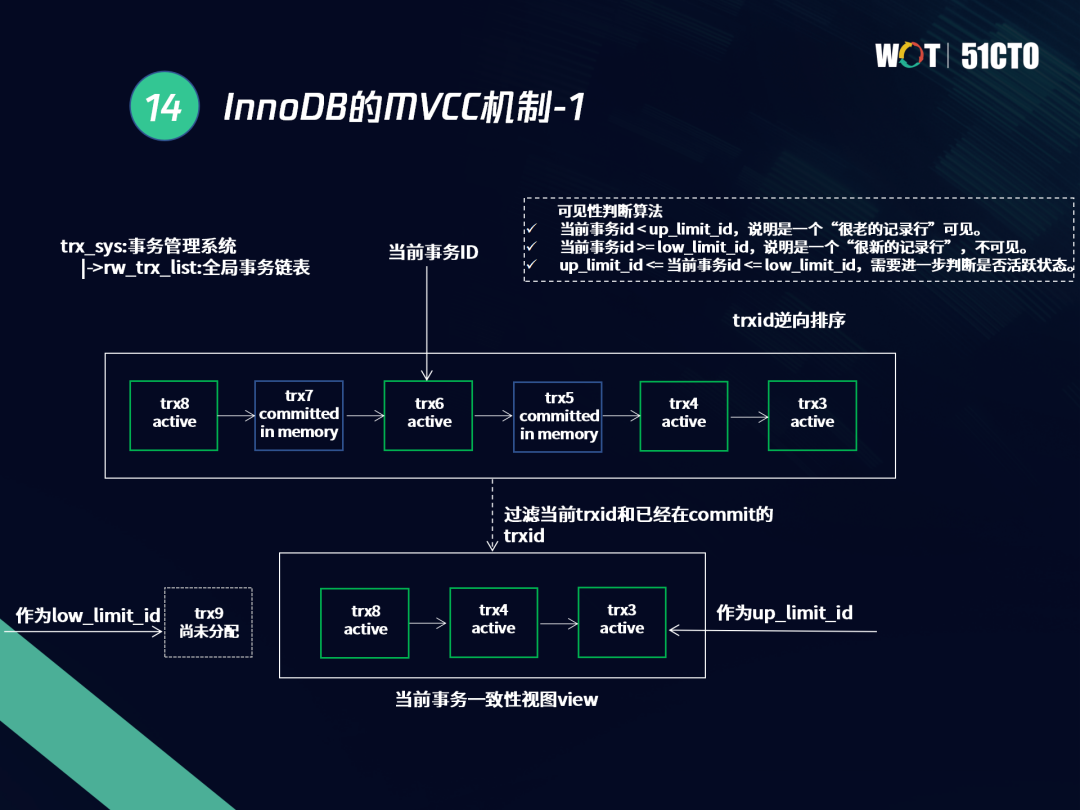
我們過濾時需要過濾事務本身的可見性情況,要看哪些事務對外已經能看到屬于活躍事務,我們可以過濾掉trx7和trx5,活躍事務為trx8、trx4、trx3,根據活躍的trxid,我們可以獲取到兩個id,一個是比較舊的快照即up_limit_id;另一個是比較新的快照地址即low_limit_id,如果當前事務的id小于up_limit_id,說明這屬于比較老的快照地址,對當前查詢來說事務可見;如果當前事務的id大于等于low_limit_id,說明是非常新的快照地址,事務不可見,當處于兩者之間時,就需要判斷是否為活躍狀態,
我們以下圖為例,來說明如何把全域可見性視圖串起來,有四行記錄,分別是ROW0到ROW3,需要查詢一個比較老的快照(up_limit_id:76),我們可以看下每一條記錄的查詢情況,ROW0行有兩個版本,trxid:100和trxid:62,ROW1行有trxid:80、trxid:75、id32三個版本,ROW2只有trxid:20一個版本,對于ROW0,滿足條件的是trxid:62,對于ROW1,滿足條件的是trxid:75和trxid:32,因為我們找快照時是根據串列找到滿足條件的第一個快照,而非找到最老的trx:32,要找的是trx75,另外對于ROW2,當前只有一個版本,且只有20,這時已經滿足條件,
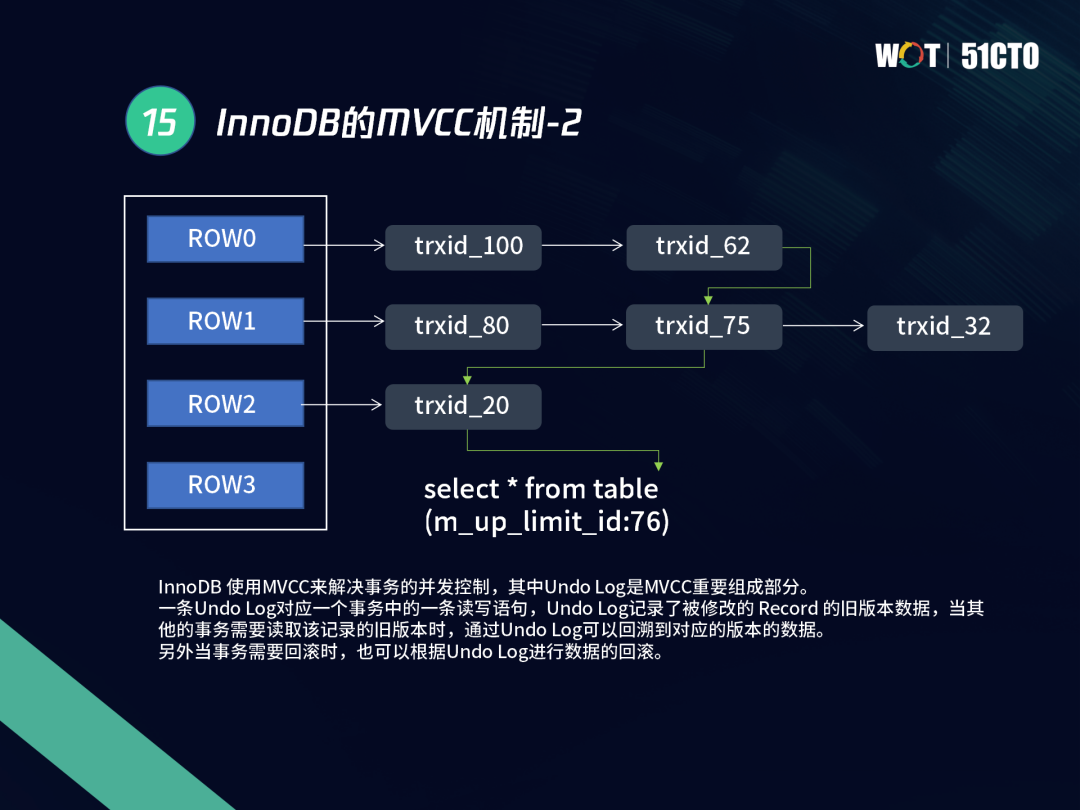
InnoDB本身是使用MVCC機制來解決讀寫并發問題,通過Undo log來對應事務中的讀寫陳述句,Undo log記錄的是每個舊的鏡像版本,當事務需要讀取舊版本時,可以通過鏈表去回溯舊的版本,當需要回滾時,也可以基于Undo來進行相關的資料回滾,
TDSQL實作全域MVCC的原理與InnoDB相似,將全域的trxid和全域事務序列對應,將trxid和全域GTS進行關聯,從而實作全域的MVCC,如下圖所示,全域場景下會存在全域序列GTS,對于trx6,其GTS值為150,對它可見的GTS必須小于等于150,如果比它大則不可見,因此trx7和trx8對其不可見;trx5的GTS是100,小于150,因此可見;trx4是大于100,在100-150之間因此可見;trx3的GTS值是300,也不可見,
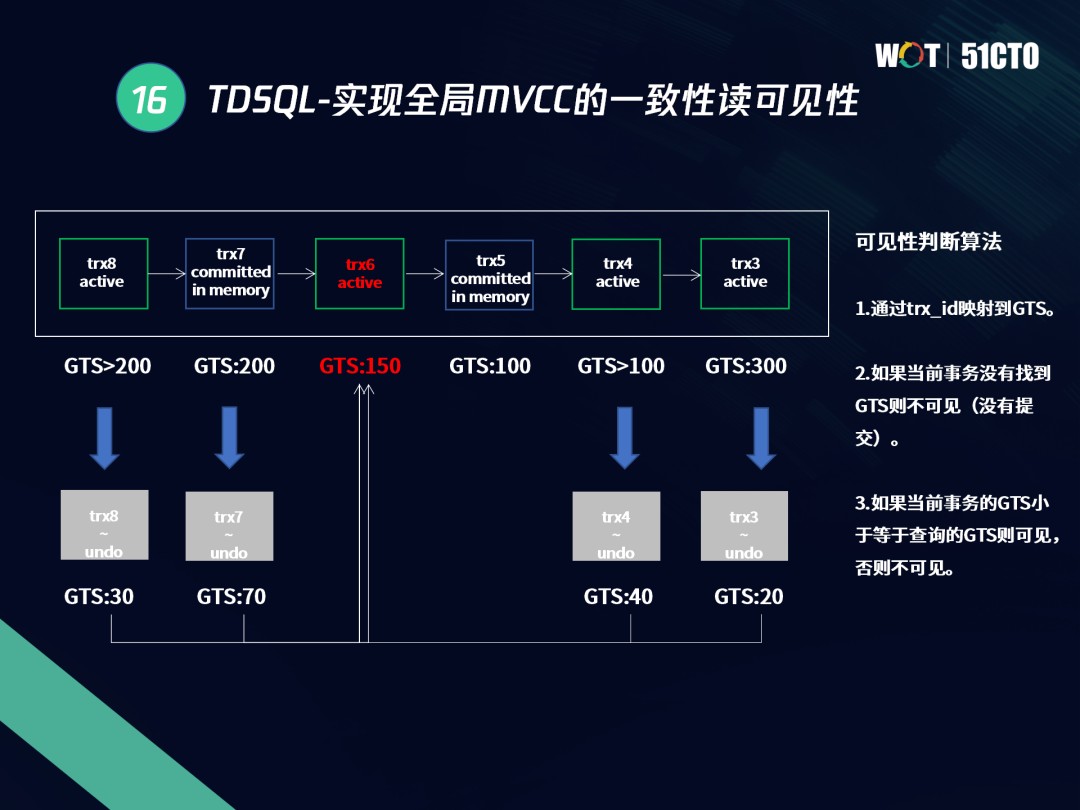
對于trx8、trx7、trx4和trx3,我們要分別找到對應記錄行的Undo歷史版本,如果找到的Undo項的GTS值依然大,就繼續往前找,對于trx8關聯的記錄行通過undo鏈的回溯,最終找到的記錄所系結的GTS是30,以此類推對于trx7“最終記錄行”是70,trx4是40,trx3是20,這樣trx6,trx8、trx7、trx5、trx4、trx3對應“可見的記錄行”的GTS值分別是30、70、100、40和20,
回到前文流程,這時全域事務還在COMMTTING程序中,一個事務已經提交,另一個事務沒有提交,在另外一個讀事務掃描記錄行的程序中,讀取到前兩個寫事務時,我們可能都要通過undo獲取他們的歷史版本,TDSQL的全域可見性演算法是把節點區域的trxid和全域GTS進行映射關聯,實作全域MVCC,從而消除讀寫沖突和一致性問題,
我們以一個寫事務和讀事務的場景為例,開啟MC后,TDSQL對PREPARE狀態進行了相關處理,當寫事務進行UPDATE操作后,這個事務可能為ACTIVE、PREPARE或COMMIT狀態,此時需要判斷這些狀態是可見還是不可見,
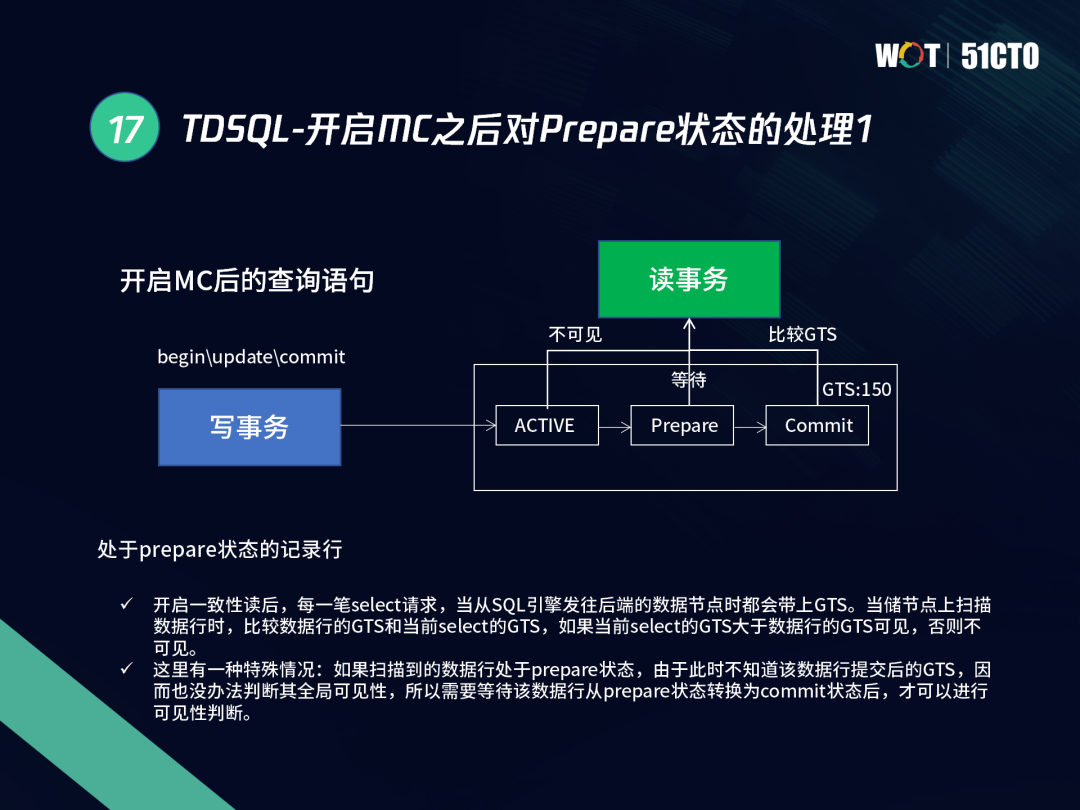
對于處于ACTIVE狀態的事務,InnoDB下對非當前事務不可見,轉換為COMMIT狀態后,通過比較GTS,再根據全域層面的可見性來進行判定,同樣地,一個PREPARE中的事務,對于InnoDB或TDSQL都處于等待狀態,如果等的時間久了,則全域的分布式事務效率會降低,需要進行優化,所以每筆請求時,SELECT都會帶上GTS,當掃描到這一行時,會比較資料行的GTS和當前SELECT的GTS,如果SELECT的GTS大于資料行的GTS則可見,否則不可見,當資料行處于PREPARE狀態時,我們還不知道它提交的GTS,此時可見性無法判斷,需要等到進入到提交狀態,才能進行可見性判斷,
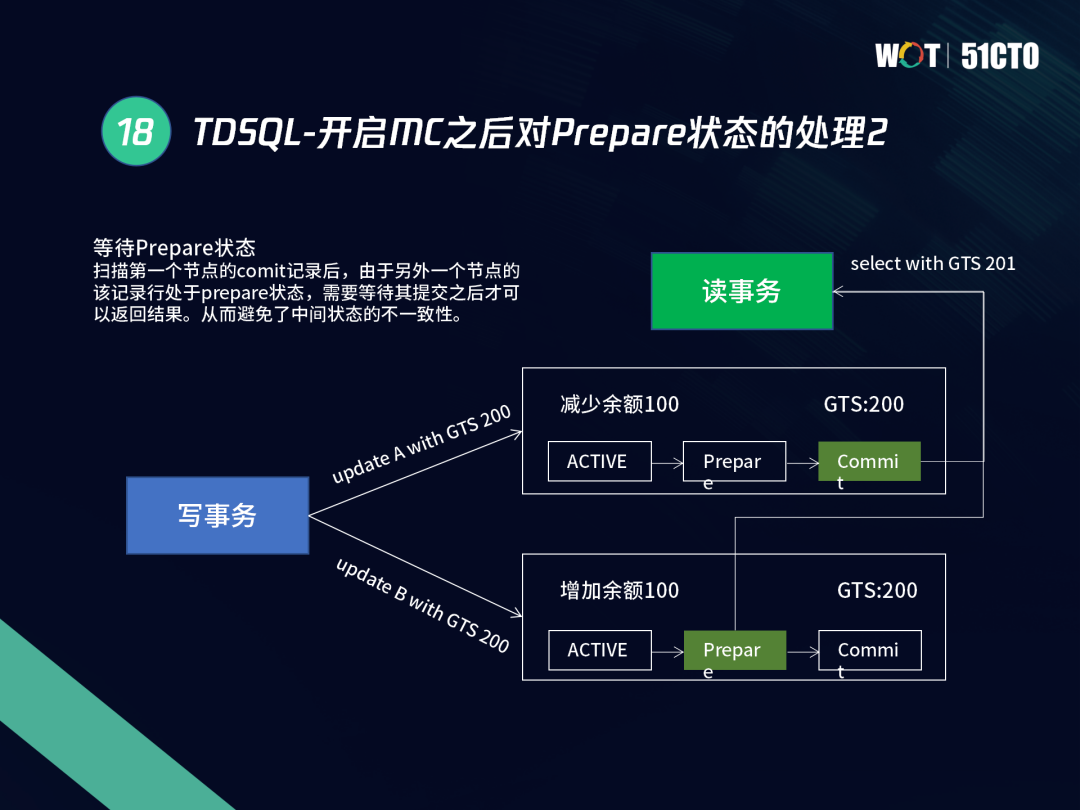
下圖所示的場景中,存在兩個UPDATE事務,當第一個節點COMMIT之后,另一個節點仍處于PREPARE狀態,這時我們需要等它提交及回傳結果,這個程序中它的狀態不可知,因此無法比較GTS值,則需要等待,不會讀取到中間狀態,
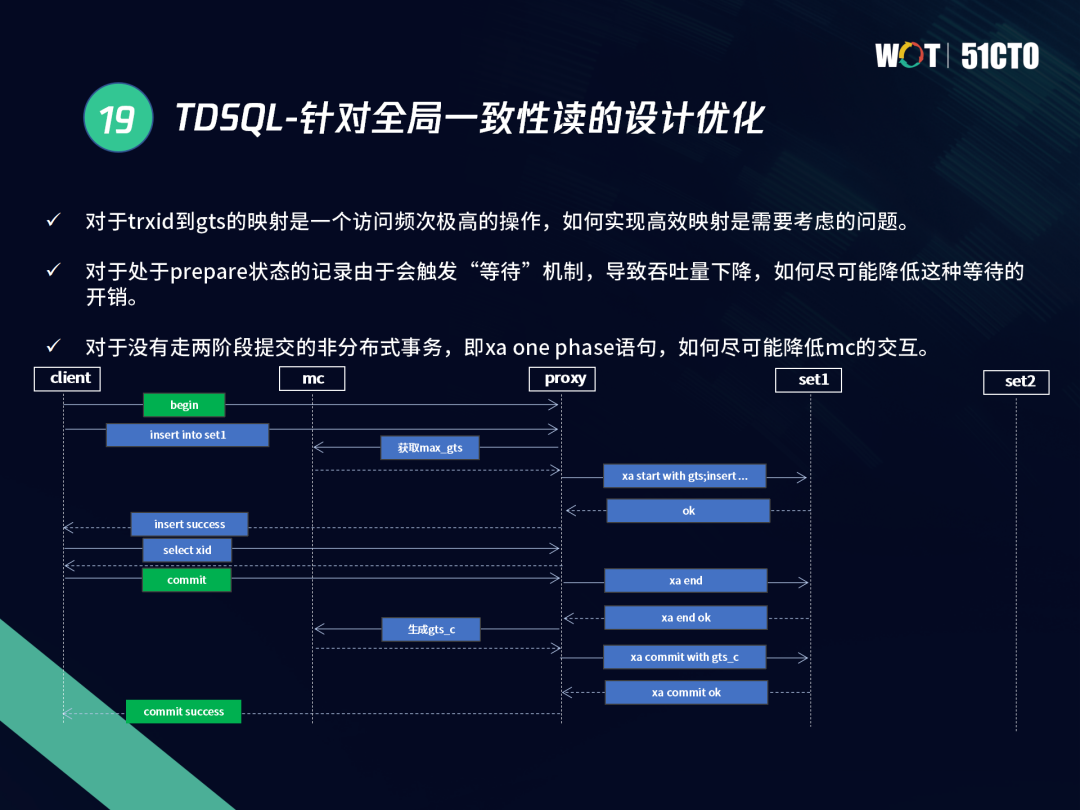
3.3 TDSQL全域一致性讀的設計優化
TDSQL主要從三個方面針對全域一致性讀進行設計優化:
- 在全域的trxid到GTS進行映射后,每次訪問都需要獲取一個MAXGTS和COMMIT GTS,對事務來說需要增加兩次訪問,訪問頻次提高后,如何實作高效映射這是首先需要考慮的事情,
- 處于PREPARE狀態的記錄,會觸發等待機制導致吞吐量下降,需要想辦法降低等待開銷,
- 對于沒有走兩階段提交的非分布式事務,需要盡可能減少和MC的互動,在提交階段可以將操作進行合并,合并后只獲取一次COMMITGTS,
下圖主要介紹TDSQL在開啟MC之后的優化,首先是tlog,tlog實作了本地MVCC和全域MVCC之間的映射關系,主要存盤的是GTS和trxid,tlog的整體設計非常簡潔,一個tlog里包括4K的資料頁,每一頁包含4K個位元組,一個GTS是64位的無符號整型,占8位元組,整個頁面是128個位元組,128位元組中最后的111位元組是checksum值,因此每個頁面能存盤約496個GTS,
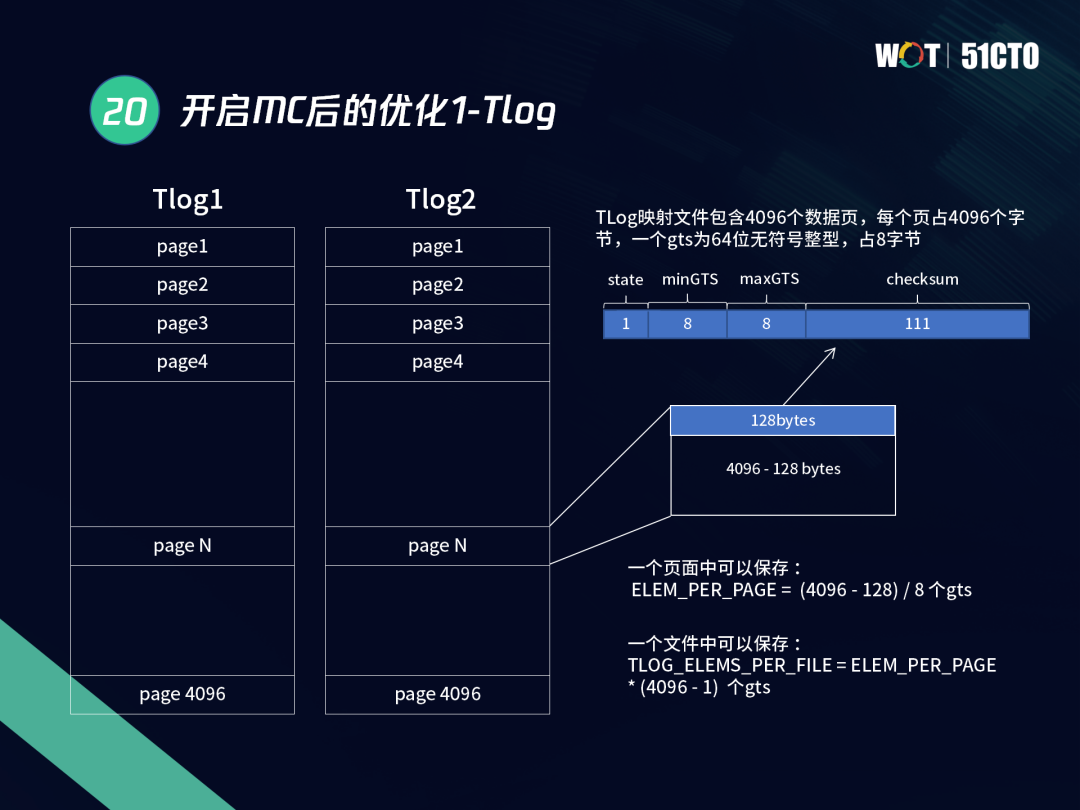
第二是trxid和GTS映射,要實作高效的映射,就需要有快速定位的方法,實際上,每個trxid對應到tlog時都有偏移,檔案起始的trxid稱為startid,當前的trxid減去stardid乘以8,就是偏移值,基于這個演算法,我們可以快速定位到檔案的地址和偏移值,實作快讀定位,

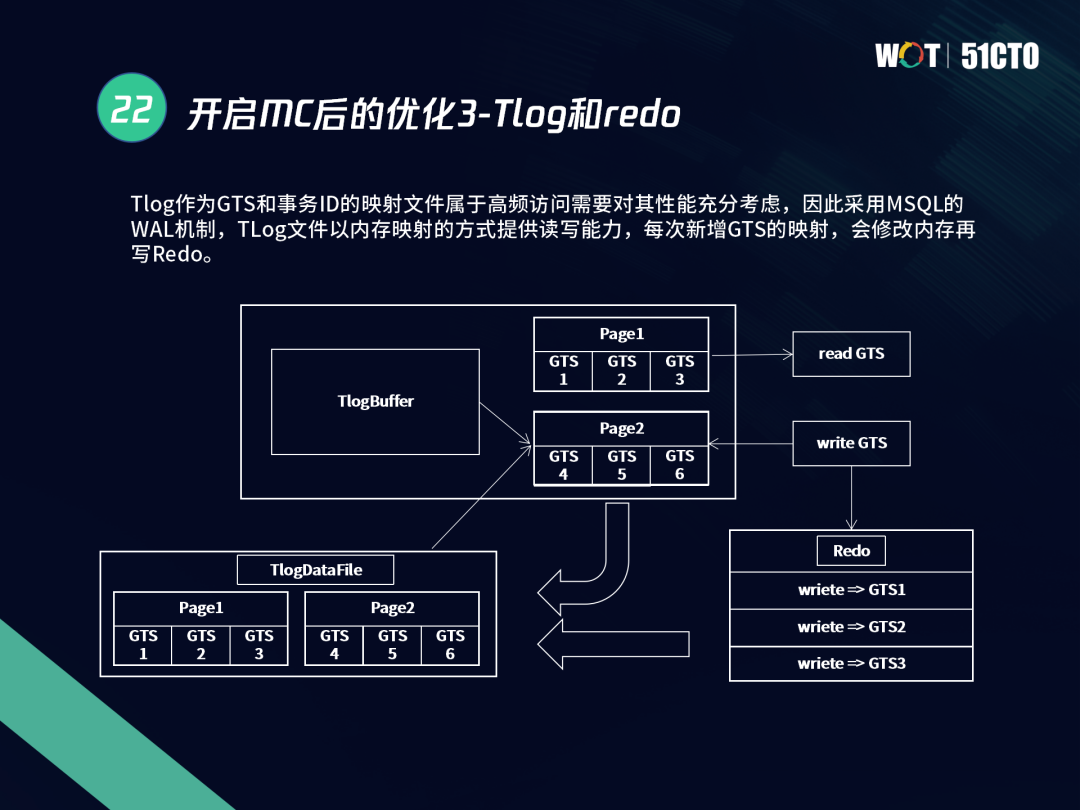
第三是tlog和redo,tlog可實作了全域MVCC和GTS映射,這個程序中也需要對XA陳述句進行調整,我們對這塊進行了微調兼容XA語法,每次XA Start和XA COMMIT時,都會攜帶GTS值,把GTS寫到redo的同時也寫到tlog中,為了避免tlog重繪帶來頻繁的隨機讀寫問題,TDSQL采用WAL機制,tlog檔案以記憶體映射方式提供讀寫能力,
如圖所示,左側是tlog的buffer,其中tlog buffer和tlogdatafile對應,每次讀GTS時,其實是從tlog buffer頁面去讀,寫GTS時也是寫tlog buffer同時寫入Redo,這樣可以保證tlog的持久化,同樣當實體crash后,可以在啟動階段構讀取到tlog buffer,整個tlog也能構造出一致性,
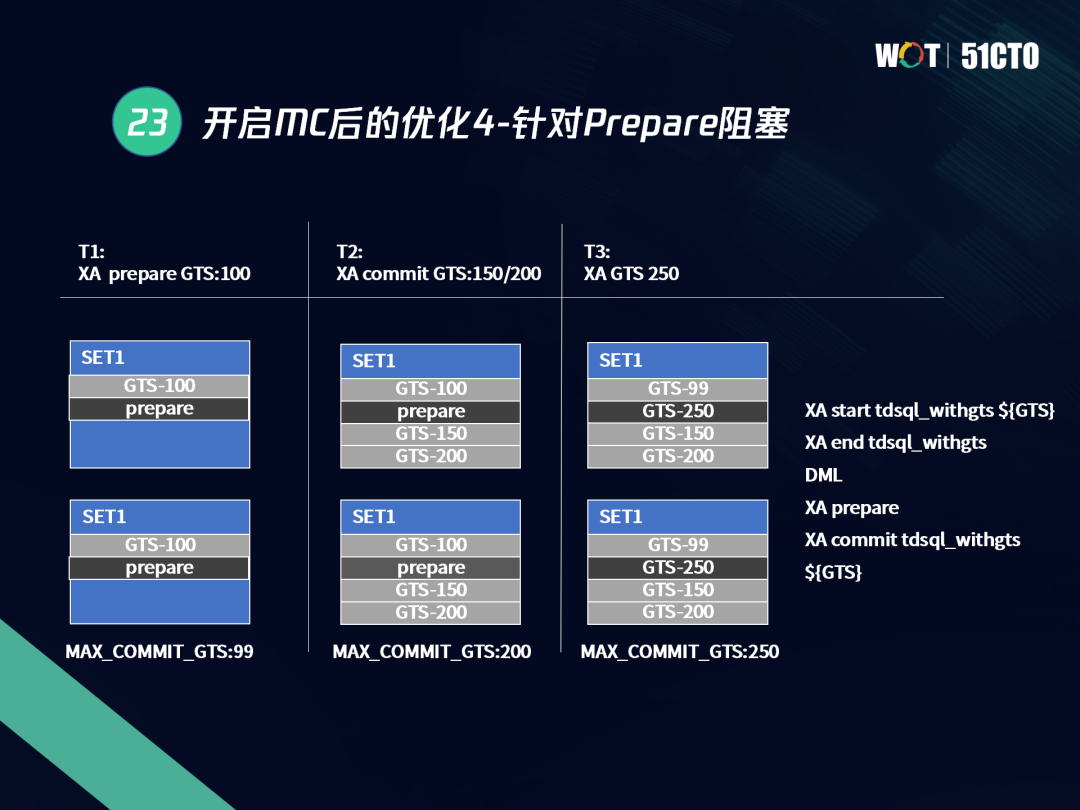
第四是針對PREPARE的優化,以下圖中的場景為例,在T1啟動后,當前MySQL節點已經提交的最大GTS為99,所以PREPARE的GTS一定大于99,至少為100,所以此時為PREPARE的記錄行系結了100的GTS,
同時又有活躍事務T2進行了COMMIT操作,其COMMIT的GTS為150和200,所以T2提交后把SET1、SET2兩個節點區域快取的MAX_COMMIT_GTS推進到了150和200,
同時存在的活躍事務T3為一個只讀事務,其GTS為250,那么它讀取到T1的PREPARE的記錄行時事務將會被阻塞,但是如果T3啟動時系結的GTS為99,那么它將直接跳過PREPARE記錄,因為通過PREPARE系結的100 GTS就可以確定,即使將來該記錄提交也一定對T3事務不可見,
綜上所述,TDSQL針對該流程進行了優化,在進行查詢時,如果當前讀事務系結的GTS值比PREPARE的GTS值要小,這時我們不用等PREPARE完成,可以直接去找其undo前鏡像,因為該記錄“將來的”COMMIT_GTS一定比當前PREPARE的GTS要大,
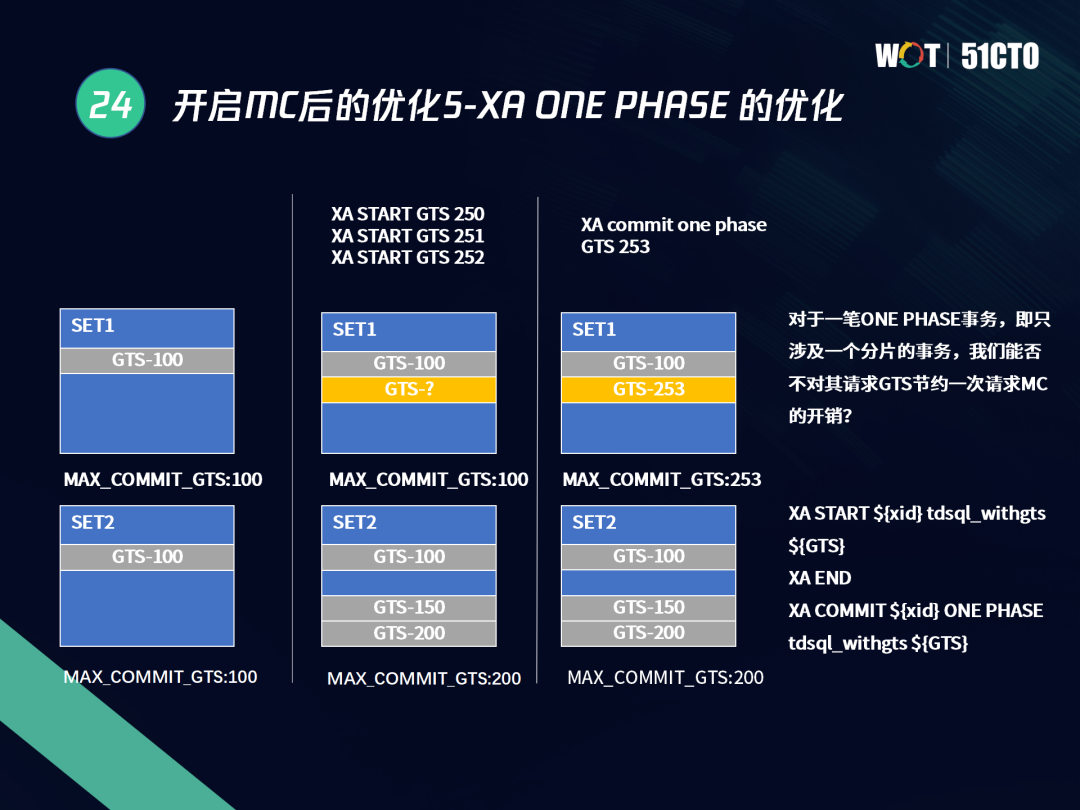
第五是針對XA的優化,以下圖為例,有SET1和SET2,SET1進行單機事務插入,SET2也在進行單機事務插入,即SET1和SET2插入的事務并沒有任何因果關系,如果在同一SET上同時發起三筆單機事務,需要為這三次COMMIT請求三次MC獲取全域GTS嗎?
TDSQL采用了一個優化措施,此時沒有請求三次MC獲取COMMIT_GTS,而是復用當前MySQL節點上最大的“快照GTS”,如下圖第三階段所示,三個先后開啟的非分布式事務,“同時”提交,此時不再請求MC而是本地獲取全域最大的快照GTS 253,SET1的GTS與SET2本身沒有依賴關系,對SET1而言,發生的是自身的一階段的分布式事務,所以這里無需通過MC獲取全域最新GTS只需要保證事務的區域時序性,這樣可以減少和MC之間的通信的開銷,
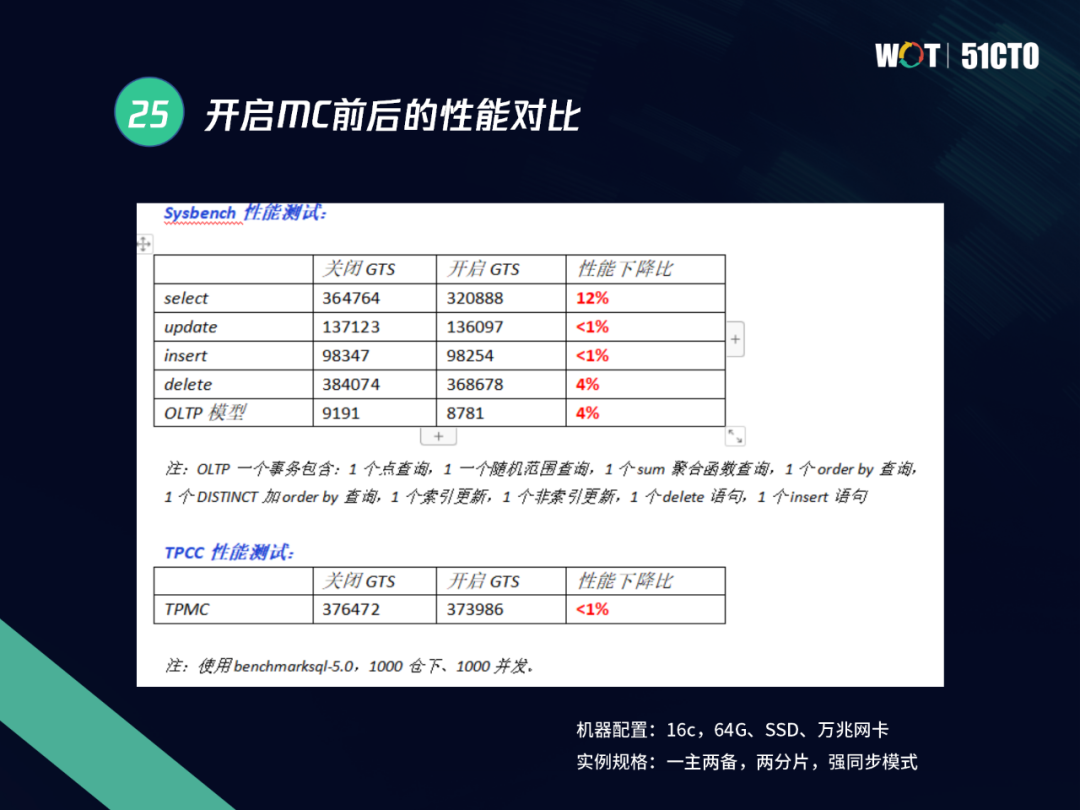
TDSQL在MC開啟之后進行多種優化來提升性能,我們在內外部進行多次測驗、驗證,得出的結論是MC開啟之后有一定損耗,但可以有效的控制在10%左右,對業務來說影響比較小,在一些INSERT和UPDATE場景下我們對相關模型也進行了優化調整,所以帶來的性能提升非常高,
圖中可以看到,我們在一些混合的TPMC場景測驗下,在一臺16C 64G的機器下測驗模型,開啟和關閉GTS對性能影響較小,TDSQL使用全域MVCC,再加上輕量的MC特性,可以將GTS的通信次數降低,從而帶來較大的收益,
四、TDSQL應用實踐
分布式事務或分布式一致性,不僅僅是資料庫要去解決的問題,很多場景下應用下也會面臨相同的挑戰,對于熱點賬戶的入賬或者面對面收賬等高并發的場景,資料庫仍然存在自身極限,我們認為需要結合應用資料庫一起做優化,
常規方案是將賬戶系統進行切割,包括做單元化、大小賬戶分離等,但是在這些場景中,一個比較極端的場景是:熱點賬戶,只有一行記錄,怎么進行拆分?這種場景下,我們就要結合應用優化配合TDSQL來實作,
以下圖為例,有兩個賬戶,賬戶C和賬戶B之間進行轉賬,這個程序中一個減少、一個增加,如果我們通過資料庫的分布式事務來進行實作,就會有上限值,如果要謀求更低的處理時效,就需采用異步訊息的方式,
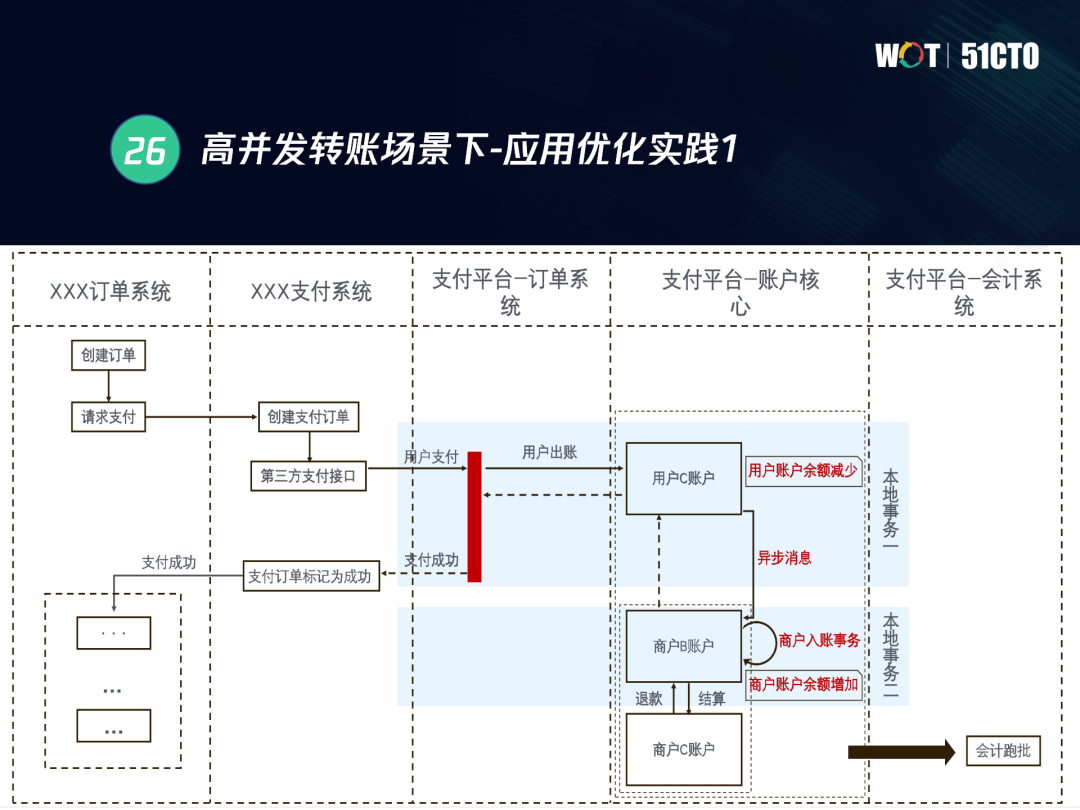
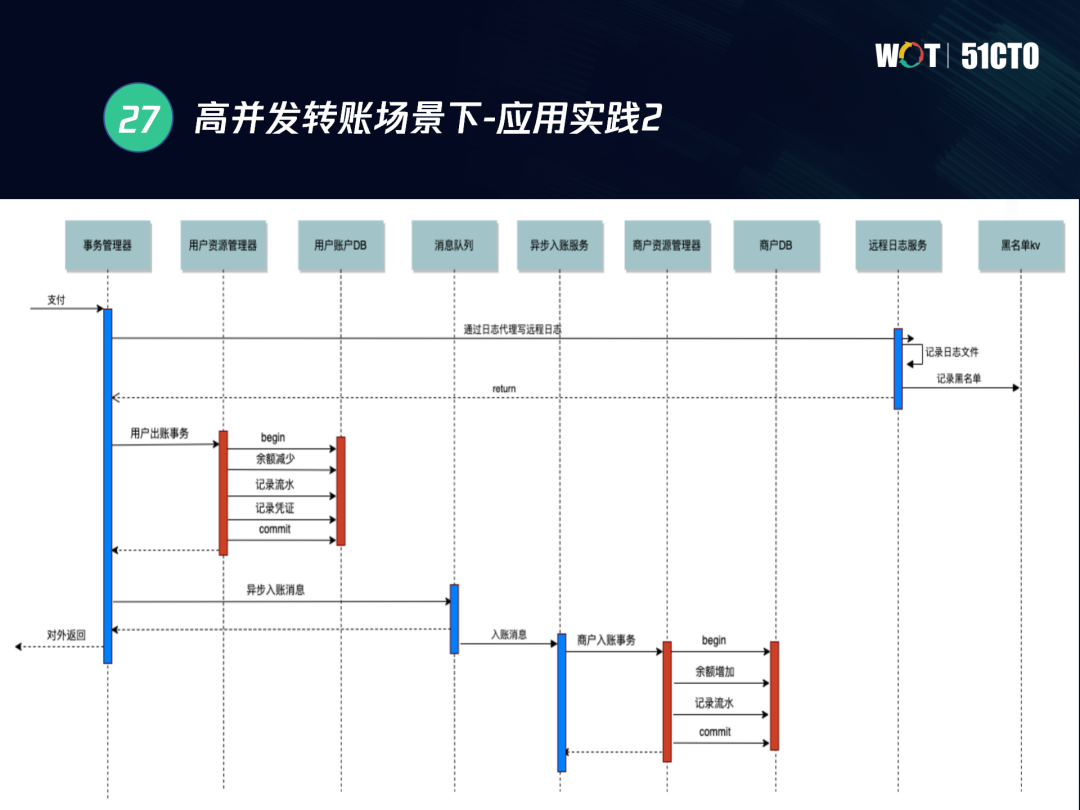
比如熱點商戶賬戶收單等場景下,僅靠資料庫層分布式事務已經不能滿足海量的并發場景,采用異步訊息優化的同時我們也會采用多級對賬機制,應用層會有一個交易訂單,交易訂單標記著這筆分布式事務成功與否,當交易訂單形成后,即使該事務在程序中出錯,也可以通過應用層的補償機制對這個事務進行處理,從而實作實時出賬+異步批量入賬,減少行鎖競爭,
在下圖的紅包轉賬場景下,還需要分布式快取+全域快取來進一步深入優化,這種場景下,除了采用異步賬戶外,我們還需要將一個熱點賬戶拆成多個平行子賬戶,使用訊息佇列和分布式快取,通過多級快取機制,分別實作多級對賬、多級快取、平行熱點賬戶、單元化等實作實時出賬、批量異步入賬,這樣可以將轉賬邏輯從頻繁的網路之間的互動變成一次批量請求,也極大提高了系統的并發能力和事務處理的回應速度,
總的來說,在上述這些極限的高并發場景下,我們需要在應用側和資料庫側做優化和結合,包括采用異步訊息、多級快取機制等,
作為領先的國產分布式資料庫,TDSQL針對新型企業級資訊化以及快速實作國產化的轉型升級需求,具備資料強一致、金融級高可用、高性能低成本、線性水平擴展、企業級安全、便捷智能運維等核心特性,
目前,TDSQL已服務金融、政務、工業制造等多個行業領域,未來五年,TDSQL將幫助1000家金融機構實作核心系統國產化轉型,持續助力國產資料庫未來發展,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/509794.html
標籤:其它