5.MySQL常用函式
5.1合計/統計函式
5.1.1合計函式-count
count 回傳行的總數
Select count(*)|count (列名) from table_name
[WHERE where_definition]
練習
-- 統計一個班級共有幾個學生
SELECT COUNT(*) FROM student
-- 統計數學成績大于90的學生有多少個
SELECT COUNT(*) FROM student
WHERE math > 90
-- 統計總分大于250的人數有多少個
SELECT COUNT(*) FROM student
WHERE chinese+english+math> 250
count(*) 和 count(列)的區別:
count(*)回傳滿足條件的記錄的行數
count(列)統計滿足條件的某列有多少個,但是會排除為null的情況
5.1.2合計函式-sum
sum函式回傳滿足where條件的行的和,一般使用在數值列
Select sum(列名) {,sum(列名)...} from tablename
[WHERE where_definition]
練習
-- sum函式
-- 統計一個班的數學總成績
SELECT SUM(math) FROM student
-- 統計一個班語文、英語、數學各科的總成績
SELECT SUM(math),SUM(english),SUM(chinese) FROM student
-- 統計一個班語文、英語、數學的成績總和
SELECT SUM(math+english+chinese) FROM student
-- 統計一個班級語文成績平均分
SELECT SUM(chinese)/COUNT(*) FROM student
注意:
sum僅對數值起作用,否則沒有意義
對多列求和,“ , ” 不能少
5.1.3合計函式-avg
avg函式回傳滿足where條件的一列的平均值
Select avg (列名) {,avg(列名)...} from tablename
[WHERE where_definition]
練習
-- avg 函式
-- 求一個班級數學平均分
SELECT AVG(math) FROM student
-- 求一個班級總分平均分
SELECT AVG(chinese+english+math) FROM student
5.1.4 合計函式-Max/min
Max/min函式回傳滿足where條件的一列的最大/最小值
Select max (列名) {,avg(列名)...} from tablename
[WHERE where_definition]
練習
-- max和min 函式
-- 求班級最高分和最低分
SELECT MAX(chinese+english+math),MIN(chinese+english+math)FROM student
-- 求班級數學最高分和最低分
SELECT MAX(math),MIN(math)FROM student
5.1.5分組統計-group by
- 使用group by子句對列進行分組
SELECT column1,column2,column3... FROM table
group by column
- 使用having子句對分組后的結果進行過濾
SELECT column1,column2,column3...
FROM table
group by column having ...
練習:
-- 先創建測驗表
CREATE TABLE dept( /*部門表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
);
INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON');
SELECT * FROM dept;
-- 員工表
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*編號*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*作業*/
mgr MEDIUMINT UNSIGNED ,/*上級編號*/
hiredate DATE NOT NULL,/*入職時間*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) ,/*紅利 獎金*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部門編號*/
);
-- 添加測驗資料
INSERT INTO emp VALUES(7369, 'SMITH', 'CLERK', 7902, '1990-12-17', 800.00,NULL , 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1991-2-20', 1600.00, 300.00, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1991-2-22', 1250.00, 500.00, 30),
(7566, 'JONES', 'MANAGER', 7839, '1991-4-2', 2975.00,NULL,20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1991-9-28',1250.00,1400.00,30),
(7698, 'BLAKE','MANAGER', 7839,'1991-5-1', 2850.00,NULL,30),
(7782, 'CLARK','MANAGER', 7839, '1991-6-9',2450.00,NULL,10),
(7788, 'SCOTT','ANALYST',7566, '1997-4-19',3000.00,NULL,20),
(7839, 'KING','PRESIDENT',NULL,'1991-11-17',5000.00,NULL,10),
(7844, 'TURNER', 'SALESMAN',7698, '1991-9-8', 1500.00, NULL,30),
(7900, 'JAMES','CLERK',7698, '1991-12-3',950.00,NULL,30),
(7902, 'FORD', 'ANALYST',7566,'1991-12-3',3000.00, NULL,20),
(7934,'MILLER','CLERK',7782,'1992-1-23', 1300.00, NULL,10);
SELECT * FROM emp;
-- 工資級別
#工資級別表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*工資級別*/
losal DECIMAL(17,2) NOT NULL, /* 該級別的最低工資 */
hisal DECIMAL(17,2) NOT NULL /* 該級別的最高工資*/
);
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
SELECT * FROM salgrade;
SELECT * FROM dept;
SELECT * FROM emp;
# 演示group by + having
# GROUP by用于對查詢的結果分組統計, having子句用于限制分組顯示結果.
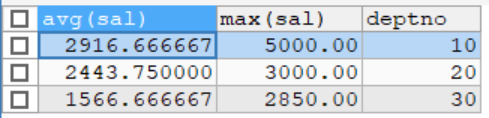
-- 如何顯示每個部門的平均工資和最高工資
-- 按照部門來分組查詢
SELECT AVG(sal),MAX(sal) ,deptno
FROM emp
GROUP BY deptno;
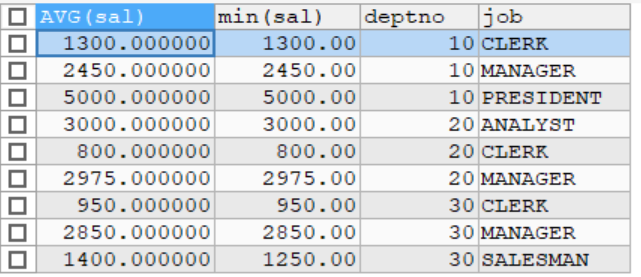
-- 顯示每個部門的每種崗位的平均工資和最低工資
# 1.先顯示每個部門的平均工資和最低工資
# 2.再顯示每個部門的每種崗位的平均工資和最低工資
SELECT AVG(sal),MIN(sal) ,deptno,job
FROM emp
GROUP BY deptno,job; -- 先按照部門分組,再按照崗位分組
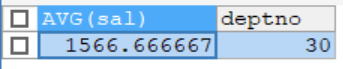
-- 顯示平均工資低于2000的部門號和它的平均工資
# 1.先顯示各個部門的平均工資和部門號
# 2.再顯示平均工資低于2000的(having過濾)
SELECT AVG(sal),deptno
FROM emp
GROUP BY deptno
HAVING AVG(sal)<2000
-- 也可以使用別名進行過濾,如下:
SELECT AVG(sal) AS avg_sal,deptno
FROM emp
GROUP BY deptno
HAVING avg_sal<2000
5.2字串函式
字串相關函式
| 函式 | 解釋 |
|---|---|
| charset(str) | 回傳字串字符集 |
| concat(string2[,...]) | 連接字串 |
| instr(string,substring) | 回傳substring在string中出現的位置,沒有就回傳0 |
| ucase(string2) | 轉換成大寫 |
| lcase(string2) | 轉換成小寫 |
| left(string2,length) | 從string2的左邊起,取length個字符 |
| right(string2,length) | 從string2的右邊起,取length個字符 |
| length(string) | string的長度[按照位元組長度回傳] |
| replace(str,search_str,repace_str) | 在str中用replace_str替換seacher_str |
| strcmp(string1,string 2) | 逐字符比較兩字串的大小 |
| substring(str,position[,length]) | 從str的position開始[從1開始計算],取length個字符 |
| ltrim(string2) | 去除前端空格 |
| rtrim(string2) | 去除后端空格 |
| trim(stirng2) | 去除前后的空格 |
練習
-- -- 演示字串相關的操作
-- -- 使用前面創建的emp表來演示
-- charset(str) 回傳字串字符集
SELECT CHARSET(ename) FROM emp;
-- concat(string2[,...]) 連接字串,將多個列拼接成一列
SELECT CONCAT(ename,'作業是',job) FROM emp;
-- instr(string,substring)回傳substring在string中出現的位置,沒有就回傳0
SELECT INSTR('hanshunping','ping') FROM DUAL; -- 8
-- dual 亞元表,是系統表,可以作為測驗表使用
-- ucase(string2) 轉換成大寫
SELECT UCASE(ename) FROM emp; -- 將指定列的所有資訊變為大寫
-- lcase(string2) 轉換成小寫
SELECT LCASE(ename) FROM emp;-- -- 將指定列的所有資訊變為小寫
-- left(string2,length) 從string2的左邊起,取length個字符
SELECT LEFT(ename,2) FROM emp;
-- right(string2,length) 從string2的右邊起,取length個字符
SELECT RIGHT(ename,2) FROM emp;
-- length(string) string的長度[按照位元組]
SELECT LENGTH(ename) FROM emp;
-- replace(str,search_str,repace_str) 在str中用replace_str替換seacher_str
-- 將表中的job職位的MANEGER替換成‘經理’
SELECT REPLACE(job,'MANAGER','經理') FROM emp;
-- strcmp(string1,string 2) 逐字符比較兩字串的大小
SELECT STRCMP('hsp','asp') FROM DUAL;
-- substring(str,position[,length]) 從str的position開始[從1開始計算],取length個字符
-- 從ename列的第一個位置開始取出兩個字符
SELECT SUBSTRING(ename,1,2) FROM emp;
-- ltrim(string2)rtrim(string2) 去除前端或者后端空格
SELECT LTRIM(' 123nihao') FROM DUAL;
SELECT RTRIM('123nihao ') FROM DUAL;
-- trim(stirng2) 去除前后的空格
SELECT TRIM(' 123nihao ') FROM DUAL;
-- 以首字母小寫的方式顯示所有員工emp表的姓名
-- 截取第一個字符將其小寫,然后拼接剩下的字串輸出即可
SELECT CONCAT( LCASE(LEFT(ename,1)) , SUBSTRING(ename,2)) FROM emp; -- 拼接完成
5.3數學函式
5.4時間函式
5.5流程控制
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/510942.html
標籤:MySQL
上一篇:我操作MySQL的驚險一幕