1. 視窗函式概念和語法
視窗函式對一組查詢行執行類似聚合的操作,然而,聚合操作將查詢行分組到單個結果行,而視窗函式為每個查詢行產生一個結果:
- 函式求值發生的行稱為當前行
- 與發生函式求值的當前行相關的查詢行組成了當前行的視窗
相比之下,視窗操作不會將一組查詢行折疊到單個輸出行,相反,它們為每一行生成一個結果,
SELECT
manufacturer, product, profit,
SUM(profit) OVER() AS total_profit,
SUM(profit) OVER(PARTITION BY manufacturer) AS manufacturer_profit
FROM sales;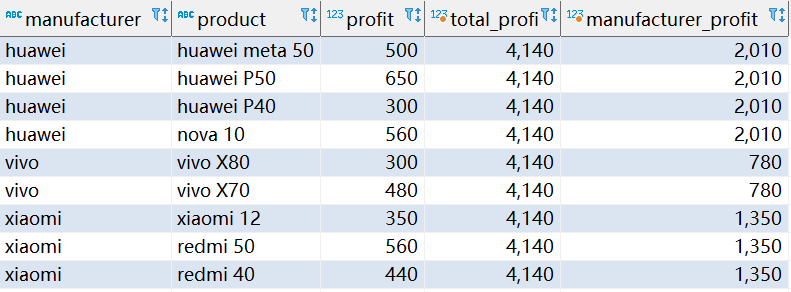
查詢中的每個視窗操作都通過包含一個 OVER 子句來表示,該子句指定如何將查詢行劃分為組以供視窗函式處理:
- 第一個 OVER 子句是空的,它將整個查詢行集視為一個磁區,視窗函式因此產生一個全域和,但對每一行都這樣做,
- 第二個 OVER 子句按 manufacturer 劃分行,產生每個磁區(每個manufacturer)的總和,該函式為每個磁區行生成此總和,
視窗函式只允許在查詢串列和 ORDER BY 子句中使用,
查詢結果行由 FROM 子句確定,在 WHERE、GROUP BY 和 HAVING 處理之后,視窗執行發生在 ORDER BY、LIMIT 和 SELECT DISTINCT 之前,
OVER子句被允許用于許多聚合函式,因此,這些聚合函式可以用作視窗函式或非視窗函式,具體取決于是否存在 OVER 子句:
AVG()
BIT_AND()
BIT_OR()
BIT_XOR()
COUNT()
JSON_ARRAYAGG()
JSON_OBJECTAGG()
MAX()
MIN()
STDDEV_POP(), STDDEV(), STD()
STDDEV_SAMP()
SUM()
VAR_POP(), VARIANCE()
VAR_SAMP()MySQL還支持只能作為視窗函式使用的非聚合函式,對于這些,OVER子句是必須的
CUME_DIST()
DENSE_RANK()
FIRST_VALUE()
LAG()
LAST_VALUE()
LEAD()
NTH_VALUE()
NTILE()
PERCENT_RANK()
RANK()
ROW_NUMBER()ROW_NUMBER() 它生成其磁區內每一行的行號,默認情況下,磁區行是無序的,行編號是不確定的,若要對磁區行進行排序,請在視窗定義中包含一個ORDER BY子句,下面的示例中,查詢使用無序磁區和有序磁區(row_num1和row_num2列)來說明省略和包含ORDER BY之間的區別:
SELECT
manufacturer, product, profit,
ROW_NUMBER() OVER(PARTITION BY manufacturer) AS row_num1,
ROW_NUMBER() OVER(PARTITION BY manufacturer ORDER BY profit) AS row_num2
FROM sales;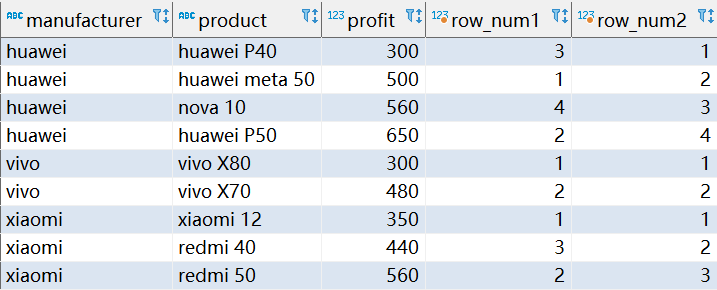
如前所述,要使用視窗函式(或將聚合函式視為視窗函式),需要在函式呼叫后包含OVER子句,OVER子句有兩種形式:
over_clause:
{OVER (window_spec) | OVER window_name}這兩種形式都定義了視窗函式應該如何處理查詢行,它們的區別在于視窗是直接在OVER子句中定義的,還是通過對查詢中其他地方定義的命名視窗的參考提供的:
- 在第一種情況下,視窗規范直接出現在 OVER 子句中的括號之間,
- 在第二種情況下,window_name 是由查詢中其他地方的 WINDOW 子句定義的視窗規范的名稱,
對于 OVER (window_spec) 語法,視窗規范有幾個部分,都是可選的:
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]如果 OVER() 為空,則視窗由所有查詢行組成,視窗函式使用所有行計算結果,否則,括號中的子句決定了使用哪些查詢行來計算函式結果,以及它們是如何磁區和排序的:
- window_name: 由查詢中其他地方的window子句定義的視窗的名稱,如果window_name單獨出現在OVER子句中,則它完全定義了視窗,如果磁區、排序或分幀子句也給出了,它們會修改被命名視窗的解釋,
- partition_clause: PARTITION BY 子句指示如何將查詢行分組,給定行的視窗函式結果基于包含該行的磁區的行,如果省略 PARTITION BY,則有一個由所有查詢行組成的磁區,
partition_clause: PARTITION BY expr [, expr] ... - order_clause: ORDER BY 子句指示如何對每個磁區中的行進行排序,根據 ORDER BY 子句相等的磁區行被視為對等,如果省略 ORDER BY,則磁區行是無序的,沒有隱含的處理順序,并且所有磁區行都是對等的,
order_clause: ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]] ...
每個ORDER BY運算式后面可以有選擇地跟著ASC或DESC來表示排序方向,NULL 值首先進行升序排序,最后進行降序排序,
視窗定義中的 ORDER BY 適用于各個磁區,要將結果集作為一個整體進行排序,請在查詢頂層包含 ORDER BY,
- frame_clause: frame是當前磁區的子集,frame子句指定如何定義該子集,
小結:
視窗,就是資料范圍,也可以理解為記錄集合,視窗函式就是在滿足某種條件的記錄集合上執行的特殊函式,即,應用在視窗內的函式,
- 靜態視窗:視窗大小是固定的,視窗內的每條記錄都要執行此函式
- 動態視窗:也叫滑動視窗,視窗大小是變化的
視窗函式有以下功能:
- 同時具有分組和排序的功能
- 不減少原表的行數
2. 視窗函式frame規范
一個frame是當前磁區的一個子集,frame子句指定如何定義這個子集,
frame是根據當前行確定的,這使得frame可以根據當前行在磁區中的位置在磁區中移動,
- 通過將一個frame定義為從磁區開始到當前行的所有行,我們可以計算每一行的運行總數,
- 通過將一個frame定義為在當前行的每一邊擴展N行,我們可以計算滾動平均,
下面的查詢演示了如何使用移動幀來計算每組按時間順序排列的值的總和,以及從當前行和緊隨其后的行計算的滾動平均值:
SELECT
manufacturer, `month`, profit,
SUM(profit) OVER(
PARTITION BY manufacturer
ORDER BY `month`
ROWS unbounded PRECEDING
) AS running_total,
AVG(profit) OVER(
PARTITION BY manufacturer
ORDER BY `month`
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS running_average
FROM
sales;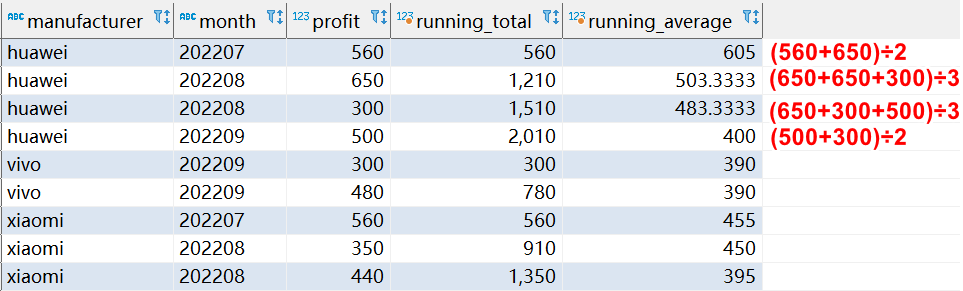
frame 子句語法:
frame_clause:
frame_units frame_extent
frame_units:
{ROWS | RANGE}在沒有frame子句的情況下,默認frame取決于是否存在ORDER BY子句,
frame_units值表示當前行和幀行之間的關系型別:
ROWS: frame由開始行和結束行位置定義,偏移量是行號與當前行號之間的差異,RANGE: frame由值范圍內的行定義,偏移量是行值與當前行值之間的差異,
frame_extend 表示frame的起始點和結束點,可以只指定frame的開始(在這種情況下,當前行隱式地是結束)或使用BETWEEN指定frame的兩個端點:
frame_extent:
{frame_start | frame_between}
frame_between:
BETWEEN frame_start AND frame_end
frame_start, frame_end: {
CURRENT ROW
| UNBOUNDED PRECEDING
| UNBOUNDED FOLLOWING
| expr PRECEDING
| expr FOLLOWING
}使用BETWEEN語法,frame_start不能發生在frame_end之后,
允許的frame_start和frame_end值含義如下:
CURRENT ROW: 對于ROWS,邊界是當前行,對于RANGE,邊界是當前行的對等點,UNBOUNDED PRECEDING: 邊界是第一個磁區行,UNBOUNDED FOLLOWING: 邊界是最后一個磁區行,exprPRECEDINGexprFOLLOWING
下面是一些有效expr PRECEDINGexpr FOLLOWING
10 PRECEDING
INTERVAL 5 DAY PRECEDING
5 FOLLOWING
INTERVAL '2:30' MINUTE_SECOND FOLLOWING在沒有frame子句的情況下,默認的frame取決于是否存在ORDER BY子句:
- 有
ORDER BY:默認frame包括從磁區開始到當前行的行,包括當前行的所有對等點,與之等效的frame如下:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW - 沒有
ORDER BY:默認frame包括所有的磁區行(因為,如果沒有ORDER BY,所有的磁區行都是對等的),與之等效的frame如下:RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
因為默認frame會根據是否存在ORDER BY而有所不同,所以向查詢添加ORDER BY以獲得確定性結果可能會更改結果,要獲得相同的結果,但按ORDER BY排序,無論ORDER BY是否存在,都要提供要使用的顯式frame規范,
3. 視窗函式應用
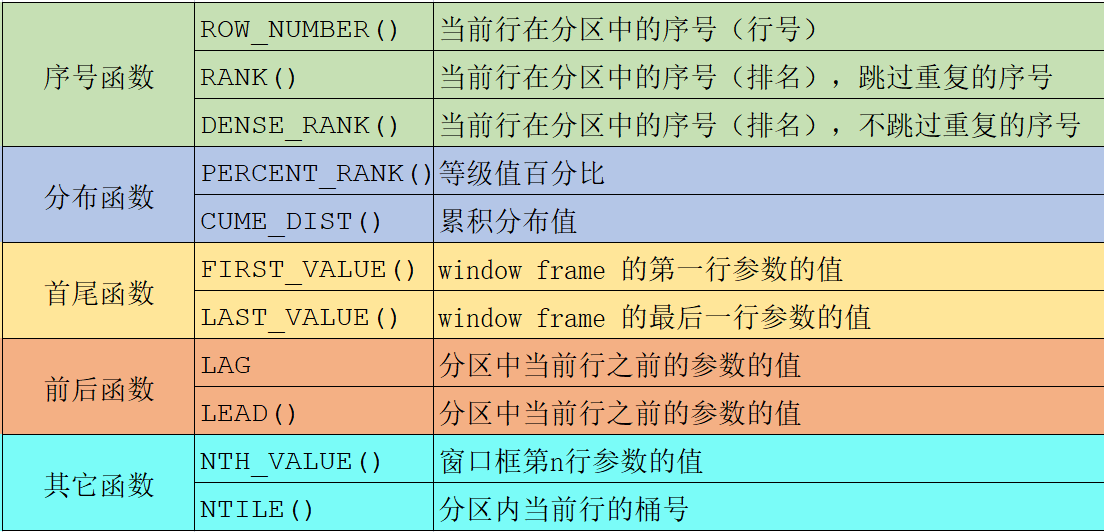
示例資料
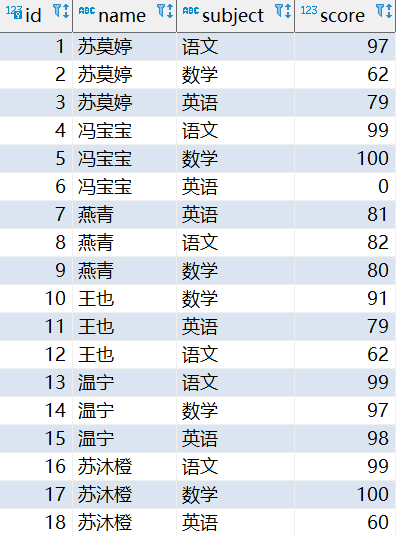
序號函式
select
name, subject, score,
rank() over w as 'rank',
dense_rank() over w as 'dense_rank',
row_number() over w as 'row_number'
from
student
window w as (partition by subject order by score desc);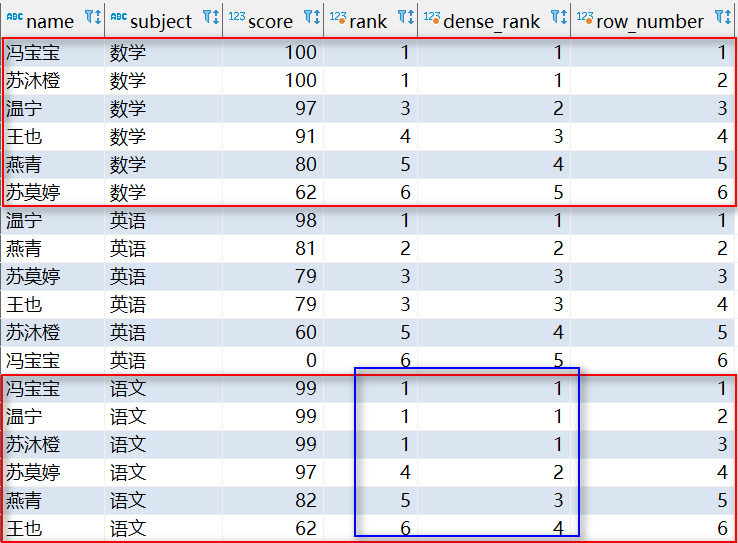
可以看到,row_number就是個序號,rank在處理并列情況的時候會占用后面的序號,而dense_rank不會
同時,這個SQL中使用了命名視窗寫法
Top-N問題:每個類別中取前N條
這類問題可以套用這個模板
SELECT * FROM (SELECT *,row_number() over (PARTITION BY 姓名 ORDER BY 成績 DESC) AS ranking FROM test) AS tmp WHERE tmp.ranking <= N;查詢每科第一名
select * from (
select
name, subject, score,
dense_rank() over(partition by subject order by score desc) as 'rn'
from
student
) tmp where tmp.rn = 1;每科前三名
select * from (
select
name,
subject,
score,
row_number() over(partition by subject order by score desc) as 'rn'
from
student
) tmp where tmp.rn <= 3;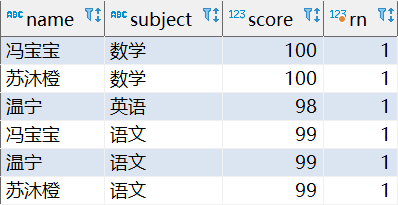
每科高于平均分數(寫法一)
select * from (
select
name, subject, score,
avg(score) over(partition by subject) as 'avg_score'
from
student
) tmp where tmp.score > tmp.avg_score;高于每科平均分數(寫法二)
select
name, subject, score
from
student s
where
s.score > (select avg(score) from student s2 where s2.subject = s.subject)
order by s.subject asc;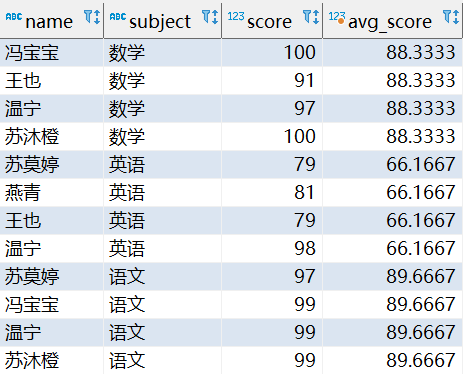
聚集函式作視窗函式
select
name, subject, score,
first_value(score) over(partition by subject order by score desc) as '單科最高分',
max(score) over(partition by subject) as '科目最高分',
min(score) over(partition by subject) as '科目最低分',
avg(score) over(partition by subject) as '科目平均分',
sum(score) over(partition by subject order by score desc rows between unbounded preceding and current row) as '總分',
sum(score) over(partition by name) as '學生總分',
count(subject) over (partition by name) as '參加的學科數'
from
student order by subject;
假設90分算及格,求每個學生的及格率
select
t1.name,
t1.pass_num as '通過的科目數',
t2.total_num as '參加的科目數',
concat(round((t1.pass_num / t2.total_num) * 100, 2), '%') as '及格率'
from
(select name, count(*) pass_num from student where score > 90 group by name) t1
left join (select name, count(*) total_num from student group by name) t2
on t1.name = t2.name;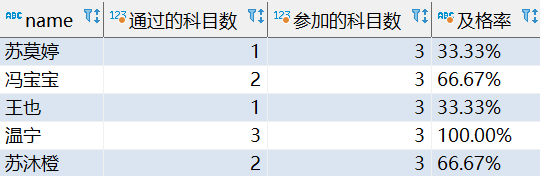
最后,視窗函式只能在查詢或子查詢中使用,不能在UPDATE或DELETE陳述句中使用它們來更新行,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/511104.html
標籤:其他
上一篇:大資料架構-Spark-configuration(官網檔案)(學習隨筆)
下一篇:day08-MySQL事務