本期我們帶大家回顧一下無倦同學的直播分享《ChunJun類加載器隔離》,ChunJun類加載器隔離的方案是我們近期探索的一個新方案,這個方案目前還不是非常成熟,希望能借由此次分享與大家一起探討下這方案,如果大家有一些新的想法歡迎大家在github上給我提issue或者pr,
一、Java 類加載器解決類沖突基本思想
在學習方案之前,首先為大家介紹一下Java類加載器解決類沖突的基本思想,
01 什么是 Classpath?
Classpath是JVM用到的一個環境變數,它用來指示JVM如何搜索Class,
因為Java是編譯型語言,原始碼檔案是.java,而編譯后的.class檔案才是真正可以被JVM執行的位元組碼,因此,JVM需要知道,如果要加載一個com.dtstack.HelloWorld的類,應該去哪搜索對應的HelloWorld.class檔案,
所以,Classpath就是一組目錄的集合,它設定的搜索路徑與作業系統相關,例如:
在Windows系統上,用;分隔,帶空格的目錄用""括起來,可能長這樣:
C:\work\project1\bin;C:\shared;"D:\My Documents\project1\bin"
在MacOS & Linux系統上,用:分隔,可能長這樣:
/usr/shared:/usr/local/bin:/home/wujuan/bin
啟動JVM時設定Classpath變數, 實際上就是給java命令傳入-Classpath或-cp引數.
java -Classpath .;/Users/lzq/Java/a;/Users/lzq/Java/b com.dtstack.HelloWorld
沒有設定系統環境變數,也沒有傳入-cp引數,那么JVM默認的Classpath為,即當前目錄:
java com.dtstack.HelloWorld
02 Jar 包中的類什么時候被加載?
● Jar包
Jar 包就是 zip 包,只不過后綴名字不同,用于管理分散的 .class 類,
生成 jar 包可以用 zip 命令 zip -r ChunJun.zip ChunJun
java -cp ./ChunJun.zip com.dtstack.HelloWorld
● 加載
“加載”(Loading) 階段是整個“類加載”(Class Loading) 程序中的一個階段,希望讀者沒有混淆這兩個看起來很相似的名詞,在加載階段,Java虛 擬機需要完成以下三件事情:
1.通過一個類的全限定名來獲取定義此類的二進制位元組流;
2.將這個位元組流所代表的靜態存盤結構轉化為方法區的運行時資料結構;
3.在記憶體中生成一個代表這個類的java.lang.Class物件,作為方法區這個類的各種資料的訪問入口,
● 決議
類或介面的決議
假設當前代碼所處的類為D,如果要把一個從未決議過的符號參考N決議為一個類或介面C的直接參考,那虛擬機完成整個決議的程序需要包括以下3個步驟:
1.如果C不是一個陣列型別,那虛擬機將會把代表N的全限定名傳遞給D的類加載器去加載這個類C,
在加載程序中,由于元資料驗證、位元組碼驗證的需要,又可能觸發其他相關類的加載動作,例如加載這個類的父類或實作的介面,一旦這個加載程序出現了任何例外,決議程序就將宣告失敗,
2.如果C是一個陣列型別,并且陣列的元素型別為物件,也就是N的描述符會是類
似“[Ljava/lang/Integer的形式,那將會按照第一點的規則加載陣列元素型別,
如果N的描述符如前面所假設的形式,需要加載的元素型別就是“java.lang.Integer",接著由虛擬機生成一個代表該陣列維度和元素的陣列物件,
3.如果上面兩步沒有出現任何例外,那么C在虛擬機中實際上已經成為一個有效的類或介面了,但在決議完成前還要進行符號參考驗證,確認D是否具備對C的訪問權限,如果發現不具備訪問權限,將拋出java.lang,llegalAccessEror例外,
03 哪些行為會觸發類的加載?
關于在什么情況下需要開始類加載程序的第一個階段“加載”,《Java虛擬機規范》中并沒有進行 強制約束,這點可以交給虛擬機的具體實作來自由把握,但是對于初始化階段,《Java虛擬機規范》 則是嚴格規定了有且只有六種情況必須立即對類進行“初始化”(而加載、驗證、準備自然需要在此之 前開始):

● 場景一
遇到new、getstatic、putstatic或invokestatic這四條位元組碼指令時,如果型別沒有進行過初始 化,則需要先觸發其初始化階段,能夠生成這四條指令的典型Java代碼場景有:
1.使用new關鍵字實體化物件的時候,
2.讀取或設定一個型別的靜態欄位(被final修飾、已在編譯期把結果放入常量池的靜態欄位除外) 的時候,
3.呼叫一個型別的靜態方法的時候,
● 場景二
使用java.lang.reflect包的方法對型別進行反射呼叫的時候,如果型別沒有進行過初始化,則需 要先觸發其初始化,
● 場景三
當初始化類的時候,如果發現其父類還沒有進行過初始化,則需要先觸發其父類的初始化,
● 場景四
當虛擬機啟動時,用戶需要指定一個要執行的主類(包含main()方法的那個類),虛擬機會先 初始化這個主類,
● 場景五
當使用JDK 7新加入的動態語言支持時,如果一個java.lang.invoke.MethodHandle實體最后的決議結果為REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四種型別的方法句柄,并且這個方法句柄對應的類沒有進行過初始化,則需要先觸發其初始化,
●場景六
當一個介面中定義了JDK 8新加入的默認方法(被default關鍵字修飾的介面方法)時,如果有這個介面的實作類發生了初始化,那該介面要在其之前被初始化,
對于以上這六種會觸發型別進行初始化的場景,《Java虛擬機規范》中使用了一個非常強烈的限定語 ——“有且只有”,這六種場景中的行為稱為對一個型別進行主動參考,除此之外,所有參考型別的方 式都不會觸發初始化,稱為被動參考,
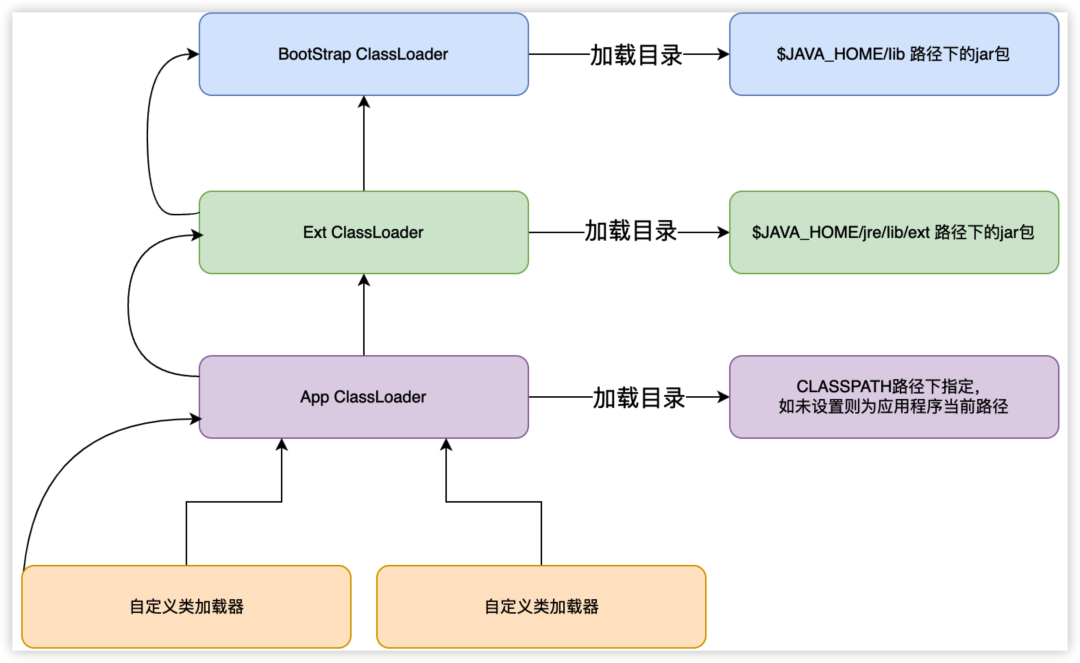
04 什么是雙親委派機制?
雙親委派機制,是按照加載器的層級關系,逐層進行委派,例如下圖中的自定義類加載器想要加載類,它首先不會想要自己去加載,它會通過層級關系逐層進行委派,從自定義類加載器 -> App ClassLoader -> Ext ClassLoader -> BootStrap ClassLoader,如果在BootStrap ClassLoader中沒有找到想要加載的類,又會逆回圈加載,
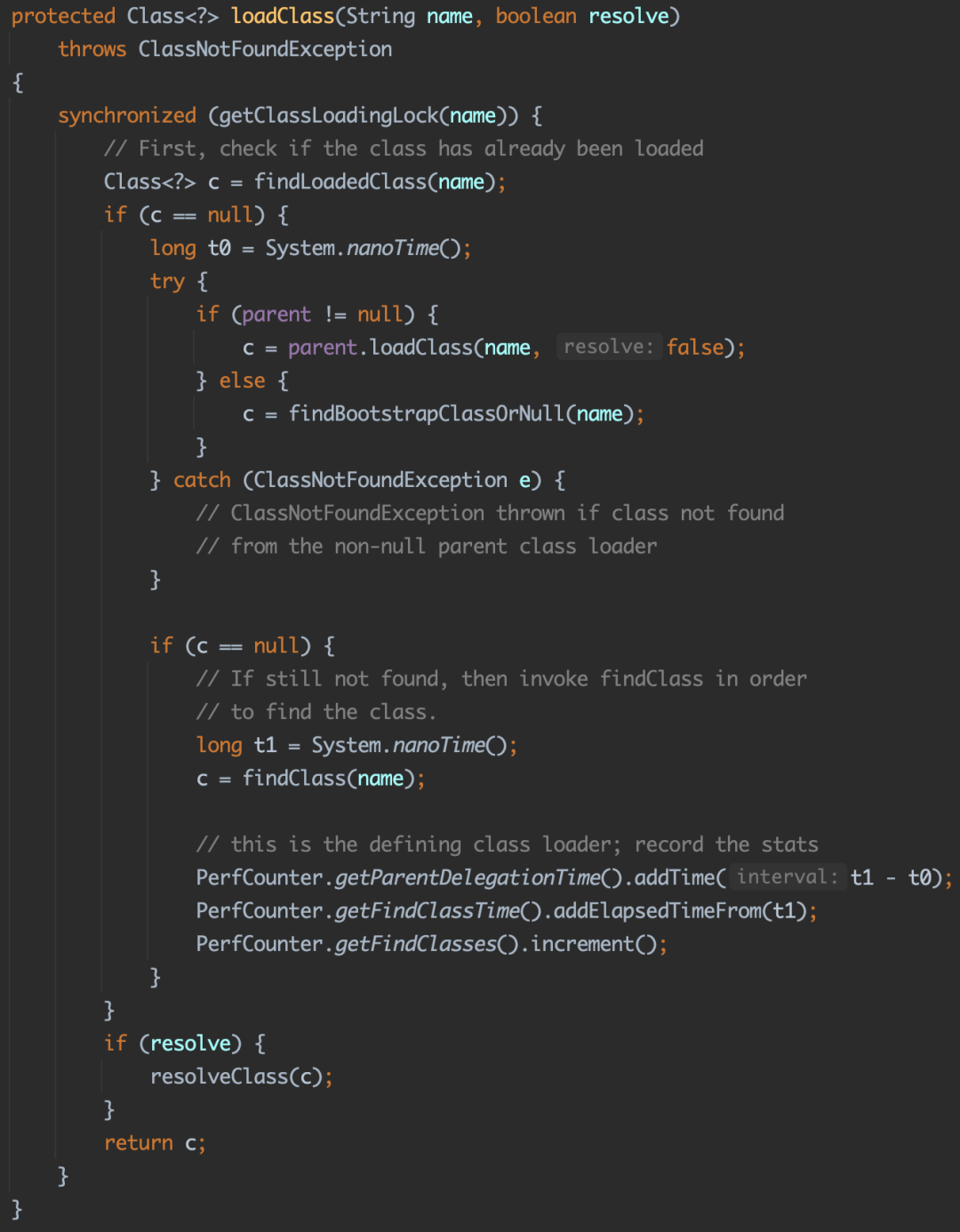
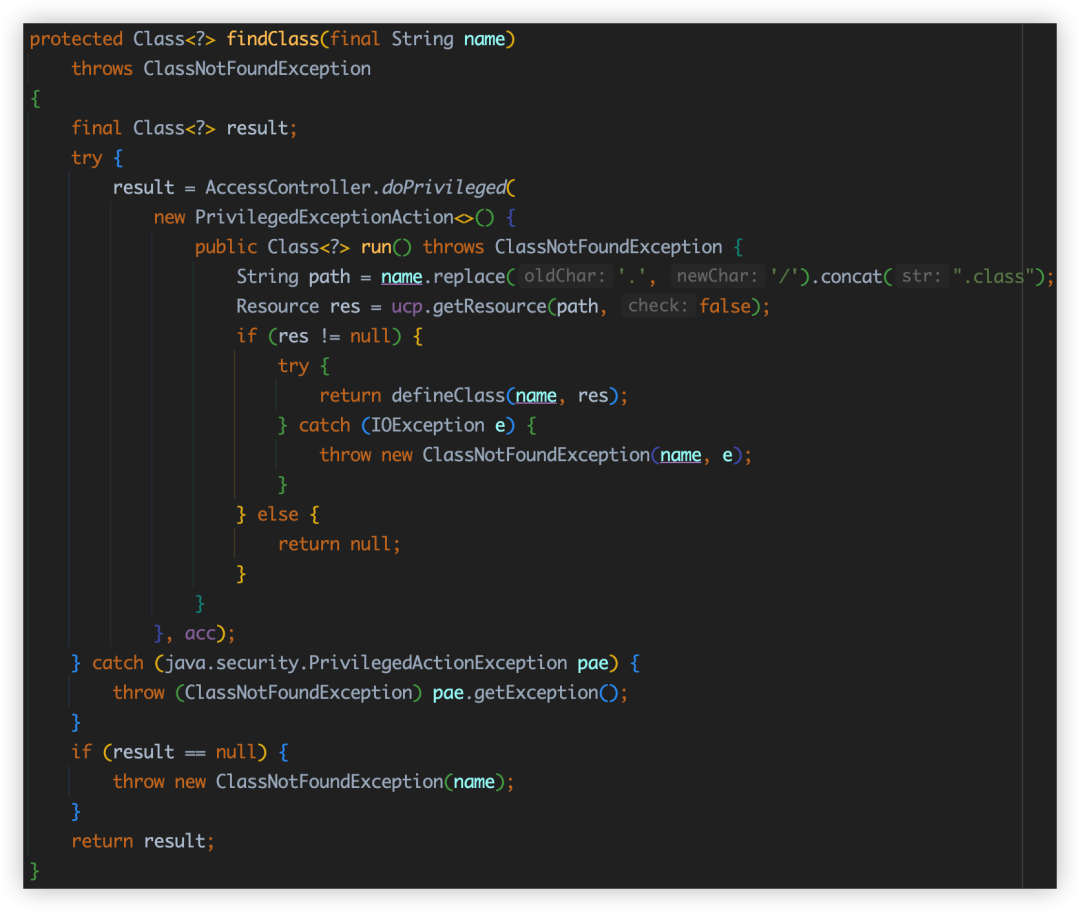
05 如何打破雙親委派機制?
那么如何打破雙親委派機制呢?其實可以通過重寫 loadclass 方法來實作,具體程序大家可通過視頻了解,這里就不過多贅述,
二、Flink 類加載隔離的方案
接下來我們來介紹下Flink 類加載隔離的方案,Flink有兩種類加載器Parent-First和Child-First,他們的區別是:
1.Parent-First
類似 Java 中的雙親委派的類加載機制,Parent First ClassLoader 實際的邏輯就是一個 URL ClassLoader,
2.Child-First
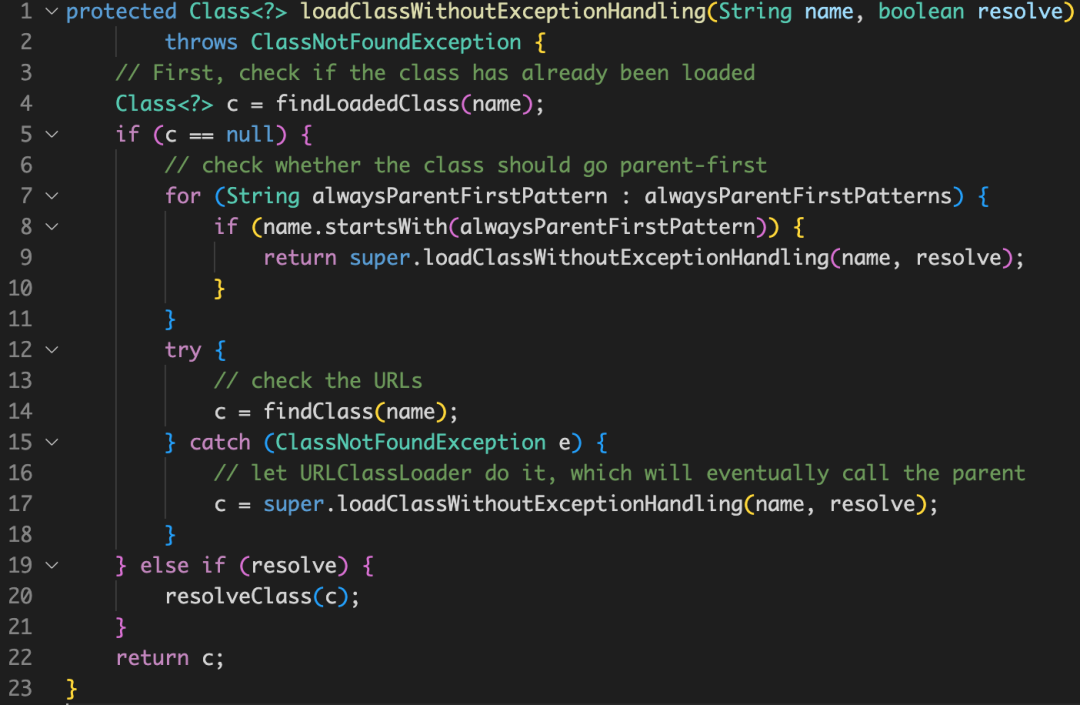
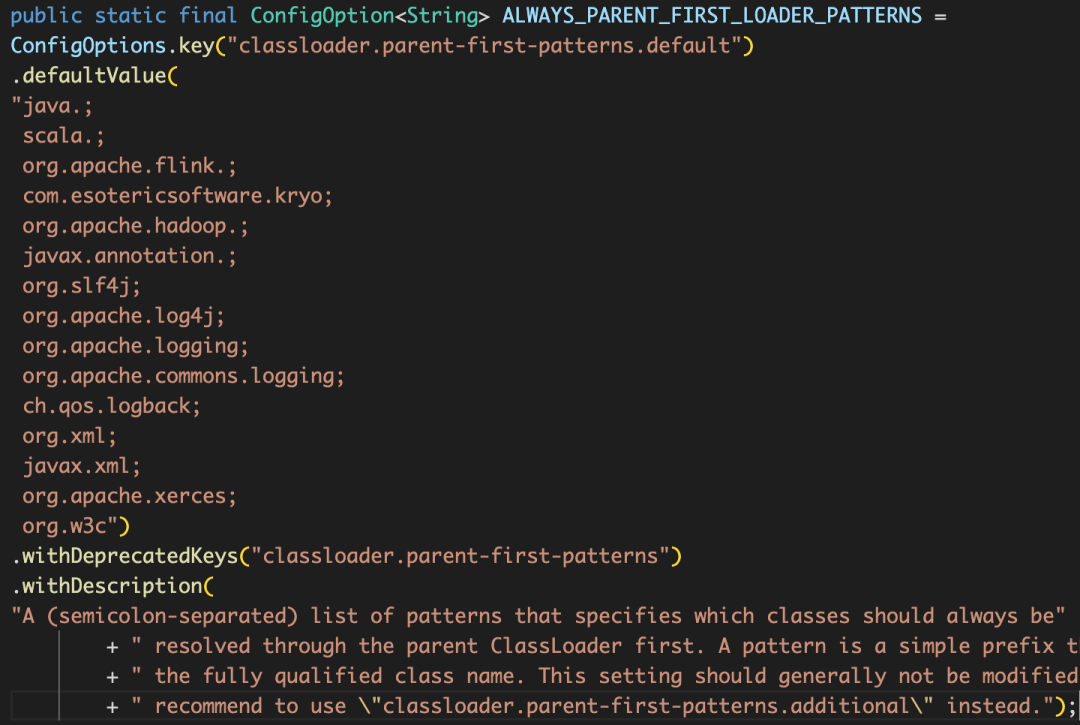
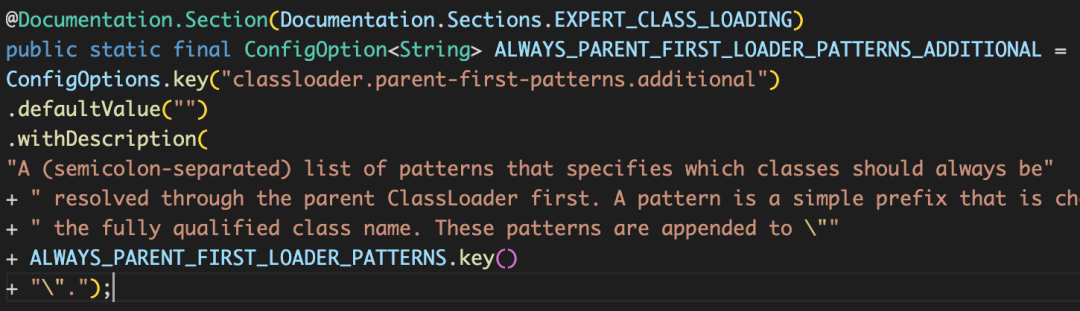
先用 classloader.parent-first-patterns.default 和 classloader.parent-first-patterns.additional 拼接的list做匹配,如果類名前綴匹配了,先走雙親委派,否則就用 ChildFirstClassLoader 先加載,
Child-First 存在的問題
每次新 new 一個 ChildFirstClassLoader,如果運行時間久的話,類似 Session 這種 TaskManager 一直不關閉的情況,任務運行多次以后,會出現元資料空間爆掉,導致任務失敗,
Child-First 加載原理

01 Flink是如何避免類泄露的?
大家可以參考Flink中的jira,這里面包含一些bug和處理方法:
https://issues.apache.org/jira/browse/FLINK-16245
https://issues.apache.org/jira/browse/FLINK-11205
Flink如何避免類泄露,主要是通過以下兩種方法:
-
增加一層委派類加載器,將真正的 UserClassloader 包裹起來,
-
增加一個回呼鉤子,當任務結束的時候可以提供給用戶一個介面,去釋放未釋放的資源,
KinesisProducer 使用了這個鉤子
final RuntimeContext ctx = getRuntimeContext();
ctx.registerUserCodeClassLoaderReleaseHookIfAbsent(
KINESIS_PRODUCER_RELEASE_HOOK_NAME,
()-> this.runClassLoaderReleaseHook
(ctx.getUserCodeClassLoader()));
02 Flink 卸載用戶代碼中動態加載的類
卸載用戶代碼中動態加載的類,所有涉及動態用戶代碼類加載(會話)的場景都依賴于再次卸載的類,
類卸載指垃圾回收器發現一個類的物件不再被參考,這時會對該類(相關代碼、靜態變數、元資料等)進行移除,
當TaskManager啟動或重啟任務時會加載指定任務的代碼,除非這些類可以卸載,否則就有可能引起記憶體泄露,因為更新新版本的類可能會隨著時間不斷的被加載積累,這種現象經常會引起OutOfMemoryError: Metaspace這種典型例外,
類泄漏的常見原因和建議的修復方式:
● Lingering Threads
確保應用代碼的函式/sources/sink關閉了所有執行緒,延遲關閉的執行緒不僅自身消耗資源,同時會因為占據物件參考,從而阻止垃圾回收和類的卸載,
● Interners
避免快取超出function/sources/sinks生命周期的特殊結構中的物件,比如Guava的Interner,或是Avro的序列化器中的類或物件,
● JDBC
JDBC驅動會在用戶類加載器之外泄漏參考,為了確保這些類只被加載一次,可以將驅動JAR包放在Flink的 lib/ 目錄下,或者將驅動類通過 classloader-parent-first-patterns-additional 加到父級優先加載類的串列中,
釋放用戶代碼類加載器的鉤子(hook)可以幫助卸載動態加載的類,這種鉤子在類加載器卸載前執行,通常情況下最好把關閉和卸載資源作為正常函式生命周期操作的一部分(比如典型的close()方法),有些情況下(比如靜態欄位)最好確定類加載器不再需要后就立即卸載,
釋放類加載器的鉤子可以通過
RuntimeContext.registerUserCodeClassLoaderReleaseHookIfAbsent()方法進行注冊,
03 Flink 卸載 Classloader 原始碼
BlobLibraryCacheManager$ResolvedClassLoader
private void runReleaseHooks() {
Set<map.entry> hooks = releaseHooks.entrySet();
if (!hooks.isEmpty()) {
for (Map.EntryhookEntry : hooks) {
try {
LOG.debug("Running class loader shutdown hook: {}.", hookEntry.getKey());
hookEntry.getValue().run();
} catch (Throwable t) {
LOG.warn(
"Failed to run release hook '{}' for user code class loader.",
hookEntry.getValue(),
t);
}
}
releaseHooks.clear();
}
}
三、ChunJun 如何實作類加載隔離
接下來為大家介紹下ChunJun 如何實作類加載隔離,
01 Flink jar 的上傳時機
首先我們需要上傳Jar包,整體流程如下圖所示:
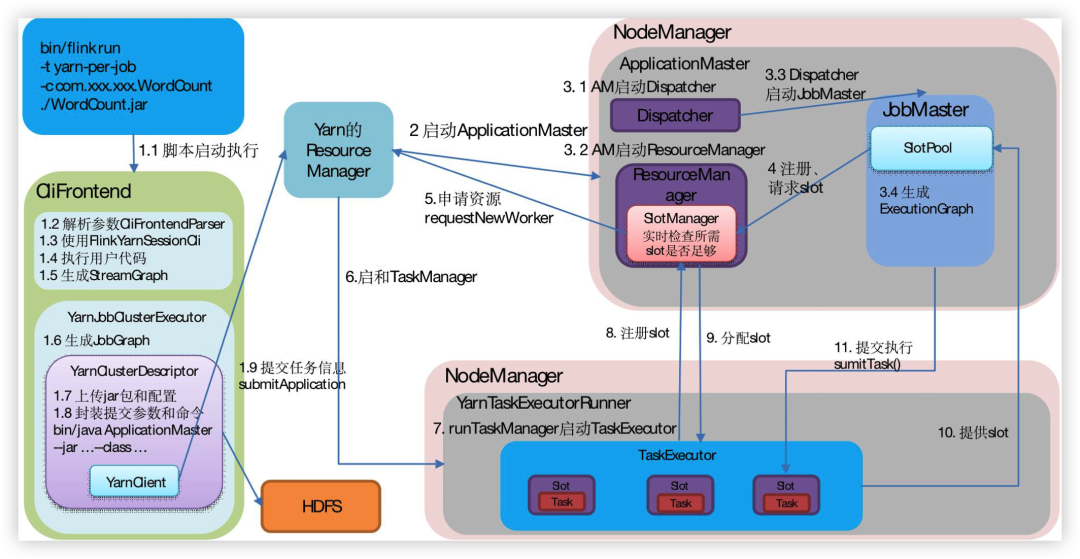
● Yarn Perjob
提交任務的時候上傳 jar 包,會放到
hdfs://flink03:9000/user/root/.flink/application_1654762357754_0140,
● Yarn Session
啟動 Session 的時候,Yarn 的 App 上傳 Jar 包機制,往 Session 提交任務的時候,Flink 的 Blob Server 負責收,
02 Yarn 的分布式快取
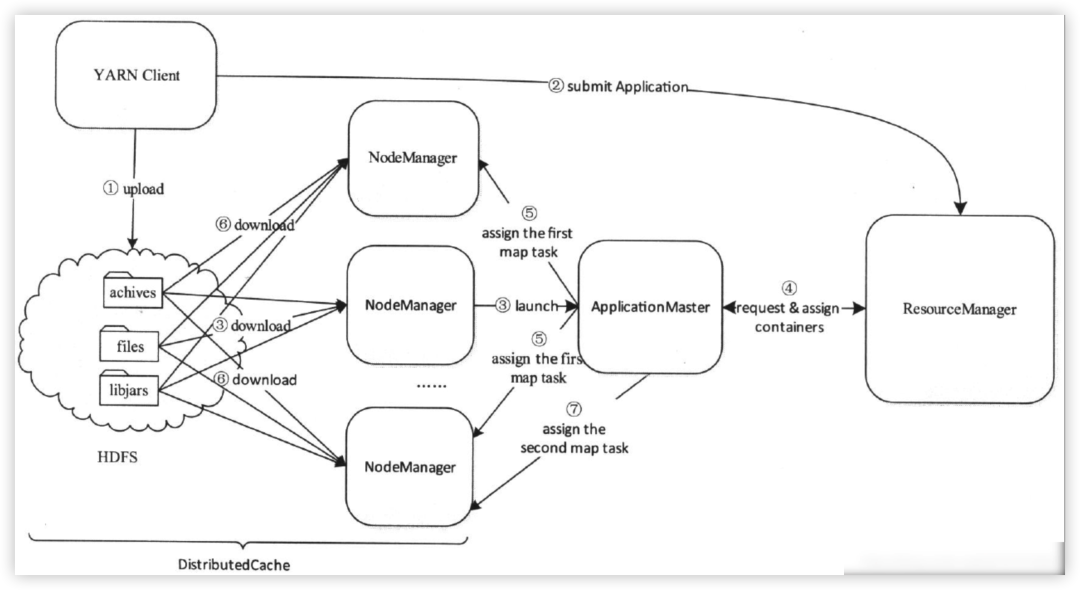
03 Yarn 的分布式快取
分布式快取機制是由各個NM實作的,主要功能是將應用程式所需的檔案資源快取到本地,以便后續任務的使用,資源快取是用時觸發的,也就是第一個用到該資源的任務觸發,后續任務無需再進行快取,直接使用即可,
根據資源型別和資源可見性,NM可將資源分成不同型別:
資源可見性分類
● Public
節點上所有的用戶都可以共享該資源,只要有一個用戶的應用程式將著這些資源快取到本地,其他所有用戶的所有應用程式都可以使用,
● Private
節點上同一用戶的所有應用程式共享該資源,只要該用戶其中一個應用程式將資源快取到本地,該用戶的所有應用程式都可以使用,
● Application
節點上同一應用程式的所有Container共享該資源
資源型別分類
● Archive
歸檔檔案,支持.jar、.zip、.tar.gz、.tgz、.tar的5種歸檔檔案,
● File
普通檔案,NM只是將這類檔案下載到本地目錄,不做任何處理
● Pattern
以上兩種檔案的混合體
YARN是通過比較resource、type、timestamp和pattern四個欄位是否相同來判斷兩個資源請求是否相同的,如果一個已經被快取到各個節點上的檔案被用戶修改了,則下次使用時會自動觸發一次快取更新,以重新從HDFS上下載檔案,
分布式快取完成的主要功能是檔案下載,涉及大量的磁盤讀寫,因此整個程序采用了異步并發模型加快檔案下載速度,以避免同步模型帶來的性能開銷,
04 Yarn 的分布式快取
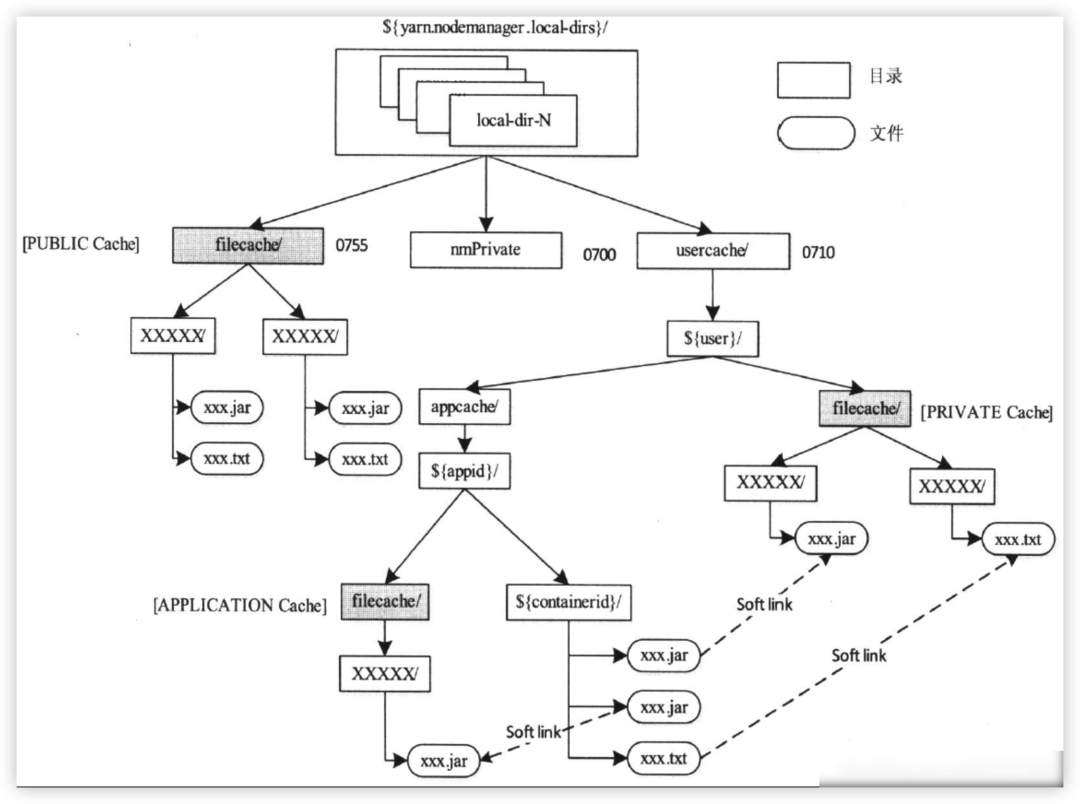
NodeManager采用輪詢的分配策略將這三類資源存放在yarn.nodemanager.local-dirs指定的目錄串列中,在每個目錄中,資源按照以下方式存放:
● Public資源
存放在${yarn.nodemanager.local-dirs}/filecache/目錄下,每個資源將單獨存放在以一個隨機整數命名的目錄中,且目錄的訪問權限均為0755,
● Private資源
存放在${yarn.nodemanager.local-dirs}/usercache/${user}/filecache/目錄下,(其中${user}是應用程式提交者,默認情況下均為NodeManager啟動者),每個資源將單獨存放在以一個隨機整數命名的目錄中,且目錄的訪問權限均為0710,
● Application資源
存放在${yarn.nodemanager.local-dirs}/usercache/${user}/${appcache}/${appid}/filecache/目錄下(其中${appid}是應用程式ID),每個資源將單獨存放在以一個隨機整數命名的目錄中,且目錄的訪問權限均為0710;
其中Container的作業目錄位于${yarn.nodemanager.local-dirs}/usercache/${user}/${appcache}/${appid}/${containerid}目錄下,其主要保存jar包檔案、字典檔案對應的軟鏈接,
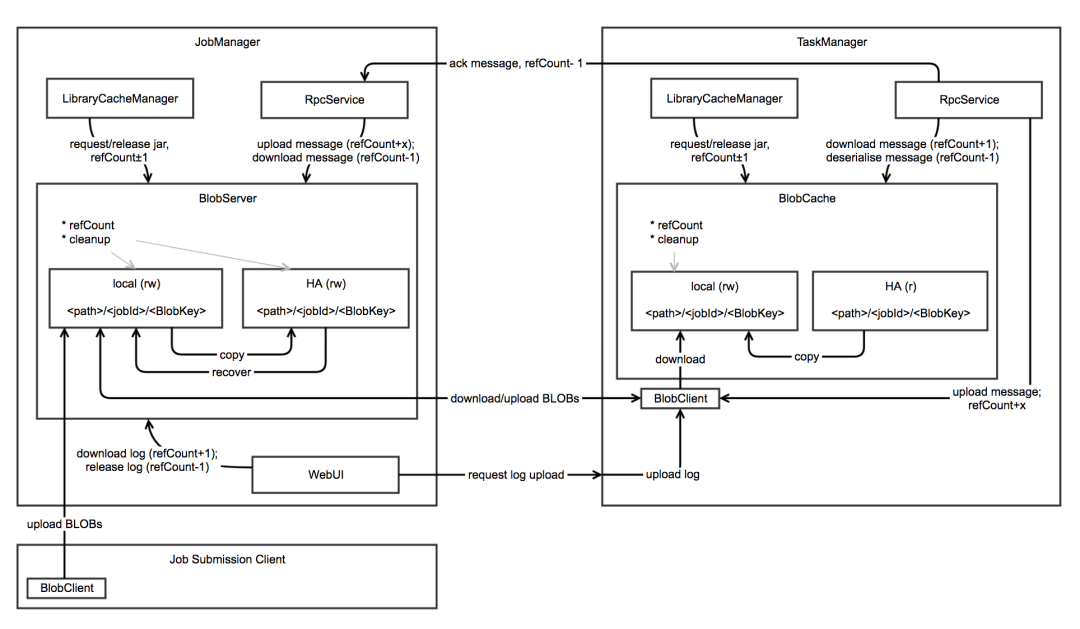
05 Flink BlobServer
06 如何快速提交,減少上傳 jar 包
Flink libs 下面 jar包、Flink Plugins 下面的 jar 包、Flink 任務的 jar 包(對于 ChunJun 來說就是所有 connector 和 core), Flink jar 用戶自定義 jar 包,
● Perjob
如果可以提前上傳到 HDFS:
-
提前把 Flink lib 、Flink plugins、ChunJun jar 上傳到 HDFS 上面,
-
提交任務的時候通過 yarn.provided.lib.dirs 指定 HDFS 上面的路徑即可,
如果不可以提前上傳到 HDFS:
-
任務提交上傳到 HDFS 固定位置,提交的時候檢查 HDFS 上如果有對應的 jar(有快取策略),就把本地路徑替換成遠程路徑,
-
利用回呼鉤子,清楚例外任務結束的垃圾檔案,
● Seeion
如果可以提前上傳到 HDFS:
-
提前把 Flink lib 、Flink plugins、ChunJun jar 上傳到 HDFS 上面,
-
啟動 session 的時候通過 yarn.provided.lib.dirs 指定 HDFS 上面的路徑即可,
-
提交任務的時候不需要上傳 core 包,
如果不可以提前上傳到 HDFS:
-
Session 啟動的時候就上傳所有 jar 到 HDFS 上面,通過 yarnship 指定,
-
Flink 任務提交到 Session 的時候,不需要提交任何 jar 包,

07 類加載隔離遇到的問題分析
● 思路分析
-
首先要把不同插件(connector) 放到不同的 Classloader 里面,
-
然后使用 child-first 的加載策略,
-
確保不會發生 x not cast x 錯誤,
-
元資料空間不會記憶體泄露,導致任務報錯,
-
要快取 connector jar 包,
● 遇到的問題
-
Flink 一個 job 可能有多個算子,一個 connector 就是一個算子,Flink 原生是為 job 級別新生成的 Classloader,無法把每個 connector 放在一個獨立的 Classloader 里面,
-
child-first 加載策略在 Session 模式下每次都新 new 一個 Classloader,導致元資料空間記憶體泄露,
-
connecotor 之間用到公有的類會報錯,
-
和問題2類似,主要是因為有些執行緒池,守護執行緒會拿著一些類物件,或者類 class 物件的參考,
-
如果用原生 -yarnship 去上傳,會放到 App Classloader 里面,那么就會導致某些不期望用 App Classloader 加載的類被加載,
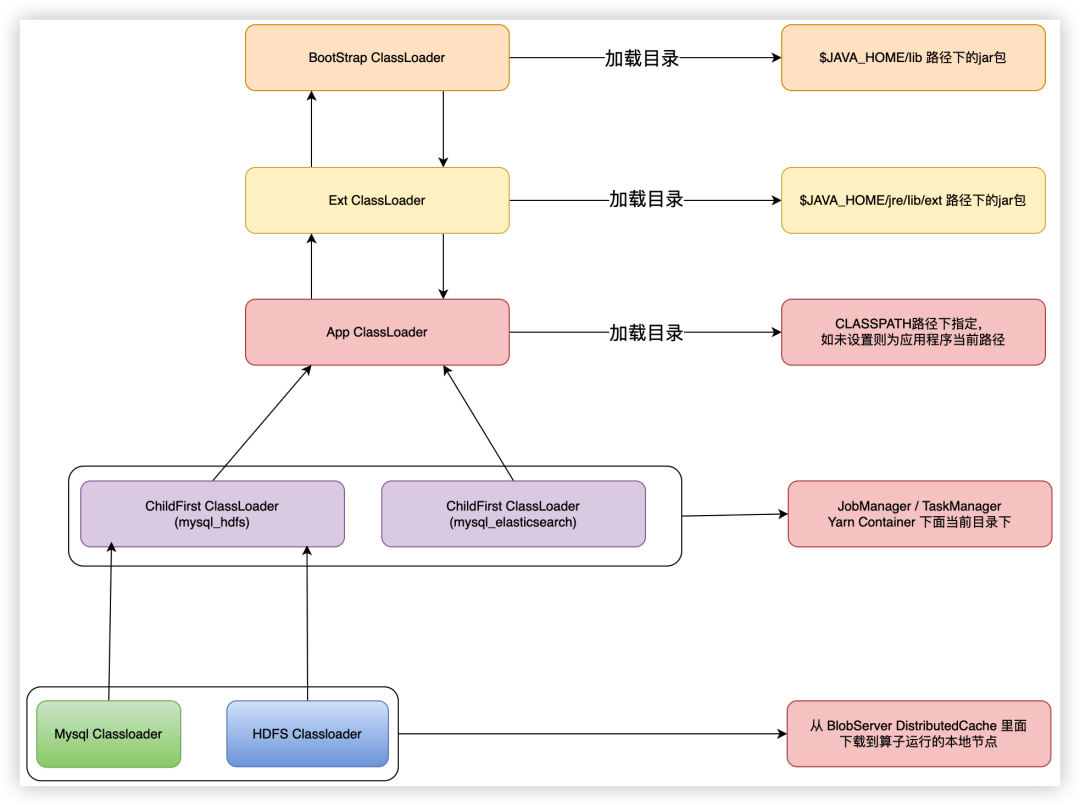
08 Flink JobGraph Classpath 的使用
/** Set of JAR files required to run this job. */
private final ListuserJars = new ArrayList();
/** Set of custom files required to run this job. */
private final MapuserArtifacts = new HashMap<>();
/** List of Classpaths required to run this job. */
private ListClasspaths = Collections.emptyList();
-
客戶端處理,JobGraph 處理 userJars、userArtifacts、Classpaths 這三個屬性,
-
Classpath 只留下 connector 的層級目錄,
-
啟動 Session 的時候上傳 jar,jar 快取在 Yarn 的所有的 NodeManager 節點,
-
jobmanager 和 taskmanager 構建 Classloader 的時候去修改 Classpath 的路徑,替換成當前節點 NodeManager 的快取路徑,
-
根據不同 connecotr 去構建Flink Job 的 Classloader,
-
把構建出來的 classlaoder 進行快取,下次任務還有相同的 Classloader,避免記憶體泄露,
-
重寫新的 ChildFirstCacheClassloader 里面的 loadclass 方法,根據不同的 connector url 去生成 單獨的 Classloader,
四、遇到的問題和排查方案?
jar包沖突常見的例外為找不到類(java.lang.ClassNotFoundException)、找不到具體方法(java.lang.NoSuchMethodError)、欄位錯誤( java.lang.NoSuchFieldError)或者類錯誤(java.lang.LinkageError),
● 常見的解決方法如下
1、首先做法是打出工程檔案的依賴樹,將根據jar包依賴情況判定是不是同一個jar包依賴了多個版本,如果確認問題所在,直接exclusion其中錯誤的jar包即可,
2、如果通過看依賴樹不能確定具體沖突的jar包,可以使用添加jvm引數的方式啟動程式,將類加載的具體jar資訊列印出來;-verbose:class ,
3、經過上述步驟基本就可以解決jar包沖突問題,具體的問題要具體分析,
● 常用工具推薦
1.Maven-helper
主要排查類沖突的 IDEA 插件,
2.Jstack
死鎖的一些問題可以通過這個工具查看 jstack 呼叫堆疊,
3.Arthas
排查一些性能問題和 Classloader 泄露問題,
4.VisualVM
排查一些物件記憶體泄露、dump 檔案分析等,
袋鼠云開源框架釘釘技術交流qun(30537511),歡迎對大資料開源專案有興趣的同學加入交流最新技術資訊,開源專案庫地址:https://github.com/DTStack/Taier
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/512008.html
標籤:其他
上一篇:為什么在單獨的go例程中需要wg.Wait()和close()?
下一篇:day09-1存盤引擎