- GreatSQL社區原創內容未經授權不得隨意使用,轉載請聯系小編并注明來源,
- GreatSQL是MySQL的國產分支版本,使用上與MySQL一致,
前文回顧
實作一個簡單的Database1(譯文)
實作一個簡單的Database2(譯文)
實作一個簡單的Database3(譯文)
實作一個簡單的Database4(譯文)
譯注:cstsck在github維護了一個簡單的、類似SQLite的資料庫實作,通過這個簡單的專案,可以很好的理解資料庫是如何運行的,本文是第五篇,主要是實作資料持久化
Part 5 持久化到磁盤
“Nothing in the world can take the place of persistence.” – Calvin Coolidge(美國第30任總統)
我們資料庫能讓你插入資料并讀取出來,但是只能在程式一直運行的時候才可以,如果你kill掉程式后再次重啟以后,你所有的資料就丟失了,
我們期望的行為是這樣的,下面是一個spec測驗:
it 'keeps data after closing connection' do
result1 = run_script([
"insert 1 user1 [email protected]",
".exit",
])
expect(result1).to match_array([
"db > Executed.",
"db > ",
])
result2 = run_script([
"select",
".exit",
])
expect(result2).to match_array([
"db > (1, user1, [email protected])",
"Executed.",
"db > ",
])
end
像SQLite一樣,我們會把資料持久化,保存整個資料庫到一個單一的檔案中,
我們已經實作了將行序列化為頁面大小的記憶體塊,為資料庫增加持久化的功能,我們可以簡單的把這些記憶體中的塊(blocks)寫入到檔案,在下次程式啟動時,再把這些資料塊讀取到記憶體,
為了讓實作更簡單點,我們創建了一個叫做pager的抽象,我們向pager請求的資料頁page號為x(page number x),然后pager會返給我們一個記憶體塊,請求會首先查看記憶體中的資料,如果記憶體中沒有(快取未命中,cache miss),pager就會從磁盤上拷貝資料到記憶體中(通過讀取資料庫檔案),
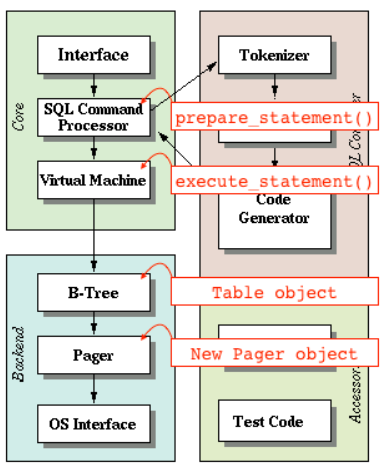
我們的程式是如何與 SQLite 架構匹配的
Pager訪問頁快取(page cache)和檔案,表物件(Table object)通過Pager請求資料頁(pages):
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
uint32_t num_rows;
} Table;
因為new_table()有了打開一個資料庫連接的效果,所以我把new_table()重命名為db_open(),
打開一個連接的含義是:
- 打開資料庫檔案
- 初始化一個Pager資料結構
- 初始化一個table資料結構
-Table* new_table() {
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+ table->pager = pager;
+ table->num_rows = num_rows;
return table;
}
db_open() 接下來呼叫 pager_open(),pager_open() 會打開資料庫檔案并跟蹤檔案的大小,它也會初始化頁快取(page cache)為NULL(NULL 在 C 語言中為一個宏,定義為: #define NULL 0,也就是0),
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ pager->pages[i] = NULL;
+ }
+
+ return pager;
+}
有了上面的Pager的抽象,我們把獲取一個頁面(fetch a page)的邏輯移動到它自己的方法里:
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void* page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void* page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
get_page() 方法有處理快取未命中(cache miss)的邏輯,我們假設資料頁一個接一個地保存在資料庫檔案中:
Page 0 在 offset 0
page 1 在 offset 4096
page 2 在 offset 8192
等等,
如果請求的page在檔案的邊界之外,那我們就知道它應該是空白,所以我們只需要分配一些記憶體并回傳它就可以了,當我們flush這些快取到磁盤時,這些page就會添加到檔案中,
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
現在,我們想一直到用戶關閉資料庫的連接時候再flush這些快取到磁盤,當用戶退出時,我們就呼叫新的方法:db_close(),方法執行下面幾個操作:
- flush頁快取到磁盤
- 關閉資料檔案
- 釋放Pager、table資料結構的記憶體
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows // ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // There may be a partial page to write to the end of the file
+ // This should not be needed after we switch to a B-tree
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+ free(pager);
+ free(table);
+}
+
-MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
_譯注:后面作者會把使用array組織page的方式改為B-tree,有些代碼只是暫時這樣實作,后面還會修改,
在當前的設計中,檔案長度是編碼存盤多少行來決定,所以我們可能會需要在檔案的結尾寫入部分頁面(partial page,頁的一部分,并非全頁),這也是為什么 pager_flush() 同時使用頁碼(page number)和資料頁大小(size)兩個引數的原因,這不是最好的設計,但是在我們開始實作B-tree之后,他們就會很快的消失了,
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written =
+ write(pager->file_descriptor, pager->pages[page_num], size);
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
最后,我們需要接受一個命令列引數:filname,也不要忘了在 do_meta_command() 添加額外引數:
譯注:db_open(filename)回傳一個table結構的指標,將這個指標作為引數傳給do_meta_command(),
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
- switch (do_meta_command(input_buffer)) {
+ switch (do_meta_command(input_buffer, table)) {
有了這些修改,我們能在關閉然后重新打開資料庫時,我們記錄仍然還在資料庫中,
~ ./db mydb.db
db > insert 1 cstack [email protected]
Executed.
db > insert 2 voltorb [email protected]
Executed.
db > .exit
~
~ ./db mydb.db
db > select
(1, cstack, [email protected])
(2, voltorb, [email protected])
Executed.
db > .exit
~
為了多找點樂子,讓我們看看 mydb.db 檔案中資料庫是如何存盤的,我使用的是 vim 來作為 hex 編輯器來查看檔案在記憶體中是如何布局的:
vim mydb.db
:%!xxd
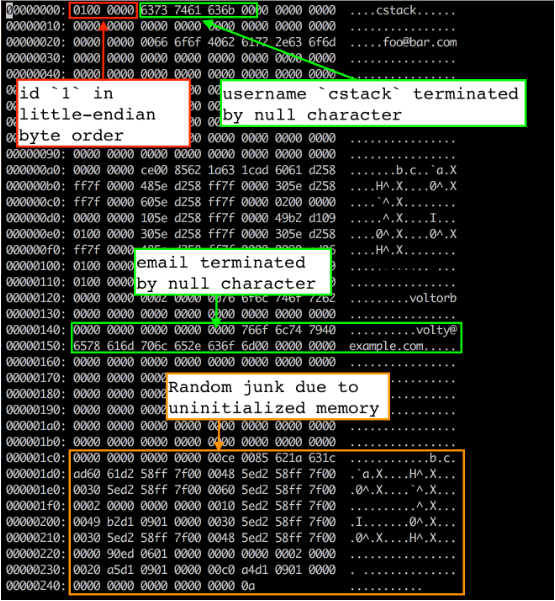
當前的檔案布局
前四個位元組是第一行資料的id(四個位元組是因為我們存盤使用的uint32_t型別),它以小端位元組序存盤,因此低位位元組首先出現 (01),緊跟的是高位位元組( (00 00 00)),我們用 memcpy() 從 Row 資料結構拷貝位元組到頁快取(page cache)中,這也就意味著這些結構在記憶體中的布局是小端位元組序,這是我編譯程式的機器的屬性,如果想在我們的機器上寫資料檔案,然后把它讀取到一個大端位元組序的機器上,就不得不修改 serialize_row() 和 deserialize_row() 方法(序列化和反序列化)始終使用相同的順序存盤和讀取位元組,
譯注:將多個位元組的資料存盤在一片連續的地址上,而將資料的各個位元組從這片空間的高地址位開始存盤還是從低地址位開始存盤就決定了系統的存盤位元組序,大端位元組序:高位位元組資料存放在低地址處,低位資料存放在高地址處;小端位元組序:高位位元組資料存放在高地址處,低位資料存放在低地址處,這一般是服務器特性決定的,并不需要特別關注,作者在此濃墨重彩的介紹了一下,
接下來的33位元組是存盤以null為結尾的 username(占32個位元組,未使用位置填充0,結尾以一個位元組的null結束),顯然“cstack”在 ASCII 十六進制中是 63 73 74 61 63 6b(占用了6個位元組,其余使用0填充),接下來是一個null字符(00),其余33位元組未使用,
接下來的256位元組是使用相同方式存盤的email(占255個位元組,未使用位置填充0,結尾以一個位元組的null結束),在這里能看到在null結束符之后有一些隨機的垃圾字符,這很可能是因為在我們的Row結構沒有初始化記憶體導致的,我們拷貝整個256個位元組長度 email 快取寫入到檔案中,包含了任何在結束符之后的位元組,當我們分配該結構記憶體時,記憶體中的任何原來的內容還在那里,但是因為我們使用了null結束符,所以它對資料庫行為沒有影響,
注意:如果我們需要確認所有的位元組都被初始化,在 serialize_row() 中拷貝 username 和 email 欄位時用 strncpy() 替換 memcpy() 就足夠了,像下面這樣:
void serialize_row(Row* source, void* destination) {
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
- memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
- memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+ strncpy(destination + USERNAME_OFFSET, source->username, USERNAME_SIZE);
+ strncpy(destination + EMAIL_OFFSET, source->email, EMAIL_SIZE);
}
結論
好了!我們實作了持久化,這樣實作不是最好的,例如,如果你kill程式而不是執行“.exit”退出,你就會丟失你的更新,此外,我們寫回所有資料頁到磁盤,盡管資料頁自從我們從磁盤讀取出來就沒有被更新,這些都是我們后面可以解決的問題,
下次我們將要介紹游標(cursors),這會讓我們實作B-tree變得更容易,
在此之前,看一下完整代碼對比(與上一部分對比):
+#include <errno.h>
+#include <fcntl.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
+#include <unistd.h>
struct InputBuffer_t {
char* buffer;
@@ -62,9 +65,16 @@ const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
uint32_t num_rows;
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
} Table;
@@ -84,32 +94,81 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
+
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void *page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
-Table* new_table() {
- Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
- table->pages[i] = NULL;
+ pager->pages[i] = NULL;
}
- return table;
+
+ return pager;
}
-void free_table(Table* table) {
- for (int i = 0; table->pages[i]; i++) {
- free(table->pages[i]);
- }
- free(table);
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
+ Table* table = malloc(sizeof(Table));
+ table->pager = pager;
+ table->num_rows = num_rows;
+
+ return table;
}
InputBuffer* new_input_buffer() {
@@ -142,10 +201,76 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE,
+ SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written = write(
+ pager->file_descriptor, pager->pages[page_num], size
+ );
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
+
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // There may be a partial page to write to the end of the file
+ // This should not be needed after we switch to a B-tree
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+
+ free(pager);
+ free(table);
+}
+
MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
- free_table(table);
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
@@ -182,6 +308,7 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
return PREPARE_SUCCESS;
}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
@@ -227,7 +354,14 @@ ExecuteResult execute_statement(Statement* statement, Table *table) {
}
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
下面是與上一部分的測驗不同的地方:
describe 'database' do
+ before do
+ `rm -rf test.db`
+ end
+
def run_script(commands)
raw_output = nil
- IO.popen("./db", "r+") do |pipe|
+ IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
pipe.puts command
end
@@ -28,6 +32,27 @@ describe 'database' do
])
end
+ it 'keeps data after closing connection' do
+ result1 = run_script([
+ "insert 1 user1 [email protected]",
+ ".exit",
+ ])
+ expect(result1).to match_array([
+ "db > Executed.",
+ "db > ",
+ ])
+
+ result2 = run_script([
+ "select",
+ ".exit",
+ ])
+ expect(result2).to match_array([
+ "db > (1, user1, [email protected])",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
it 'prints error message when table is full' do
script = (1..1401).map do |i|
"insert #{i} user#{i} person#{i}@example.com"
Enjoy GreatSQL ??
關于 GreatSQL
GreatSQL是由萬里資料庫維護的MySQL分支,專注于提升MGR可靠性及性能,支持InnoDB并行查詢特性,是適用于金融級應用的MySQL分支版本,
相關鏈接: GreatSQL社區 Gitee GitHub Bilibili
GreatSQL社區:
歡迎來GreatSQL社區發帖提問
https://greatsql.cn/

技術交流群:
微信:掃碼添加
GreatSQL社區助手微信好友,發送驗證資訊加群,

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/514316.html
標籤:MySQL