
在最新一屆國際資料庫頂級會議 ACM SIGMOD 2022 上,來自清華大學的李國良和張超兩位老師發表了一篇論文:《HTAP Database: What is New and What is Next》,并做了 《HTAP Database:A Tutorial 的專項報告,這幾期學術分享會的文章,StoneDB 將系統地梳理一下兩位老師的報告,帶讀者了解 HTAP 的發展現狀和未來趨勢,
在《深度干貨!一篇 Paper 帶您讀懂 HTAP》這期中我們對HTAP產生的背景和現有的HTAP資料庫及其技術堆疊做了比較全面的介紹,
在《爆肝整理 5000 字!HTAP 的關鍵技術有哪些?》這一期,我們對 HTAP 的五大關鍵技術進行了逐個解讀,
本期主要介紹一下主流的幾個的 HTAP 資料庫基準測驗,
編輯:宇亭
頭圖:Yeekin
關于 HTAP 資料庫的基準測驗,我們在學術分享會的第三期也介紹過一個來自慕尼黑工業大學 DB 組的相關作業,感興趣可以了解一下,在這篇報告中,主要介紹兩種:CH-Benchmark 和 HTAPBench,

如圖所示,這兩種基準測驗的核心區別在于,CH-Benchmark 是混合負載測驗,即 OLTP 和 OLAP 一起測;HTAPBench 是先固定統一 OLTP 的標準,然后在這個標準下再去控制測驗 OLAP(當然還多了一個時間視窗的選擇),
這里順便簡單科普一下什么是 TPC-C 和 TPC-H:
先介紹一下 TPC 是啥,TPC(Transaction Processing Performance Council,事務處理性能委員會)是由數十家會員公司創建的非盈利組織,總部設在美國,TPC 的成員主要是計算機軟硬體廠家,而非計算機用戶,其功能是制定商務應用基準程式的標準規范、性能和價格度量,并管理測驗結果的發布,其他更多資訊就可以百度啦,總之這個組織在國際上很有影響力,學術界和工業界也都蠻認可的,
- TPC-C: TPC Benchmark C 于1992年7月批準,是一個在線交易處理(OLTP)基準,TPC-C 比以前的 OLTP 基準測驗(如TPC-A)更復雜,因為它具有多種事務型別、更復雜的資料庫和整體執行結構,TPC-C 涉及五個不同型別和復雜度的并發事務的混合,要么在線執行,要么排隊等待延遲執行,資料庫由九種型別的表組成,這些表存盤的記錄多而廣泛,TPC-C 以每分鐘事務數(tpmC)來衡量,雖然基準描述了批發供應商的活動,但 TPC-C 并不局限于任何特定業務部門的活動,而是代表必須管理、銷售或分銷產品或服務的任何行業,官網:https://www.tpc.org/tpcc/default5.asp
- TPC-H: TPC-H 是 TPC 組織制定的 OLAP 型資料庫管理系統性能測驗的一個標準,用來模擬真實商業的應用環境,以評估商業分析中決策支持系統(DSS)的性能,TPC-H 模擬真實商業交易資料庫的動態查詢,包含了一整套面向商業的 ad-hoc 查詢和并發資料修改,強調測驗的作業系統、資料庫、和 I/O 性能,關注查詢能力,通過TPC-H 測驗,可以全方位評測系統的整體商業計算綜合能力,具有普遍的商業實用意義,官網:https://www.tpc.org/tpch/
簡單說,TPC-C 是專門測驗 OLTP 的;TPC-H 是專門測驗 OLAP 的,當然,其實還有個 TPC-DS 也比較知名(現在一般用來測數倉的),感興趣也可以了解一下,
雖然以上兩種測驗基準已經非常給力,但是對于測驗 HTAP 卻又都顯得片面了一些,因為 HTAP 資料庫上是同時跑著 OLTP 和 OLAP 作業負載的,單獨只考量 OLTP 或者 OLAP 的性能都是不對的,要測就得綜合評估兩者一起作業時的性能(比如 TP 和 AP 的隔離性),因此,后續有人提出了專門針對 HTAP 資料庫的基準測驗,其中比較知名的就是 CH-Benchmark 和 HTAPBench,
這兩個測驗基準單獨拿出來都能寫一篇文章,但在報告中其實只有兩段話,我這一篇解讀文章先做一個簡單的介紹,后面會出擴充的講解,歡迎大家關注 StoneDB 公眾號,

一、CH-Benchmark
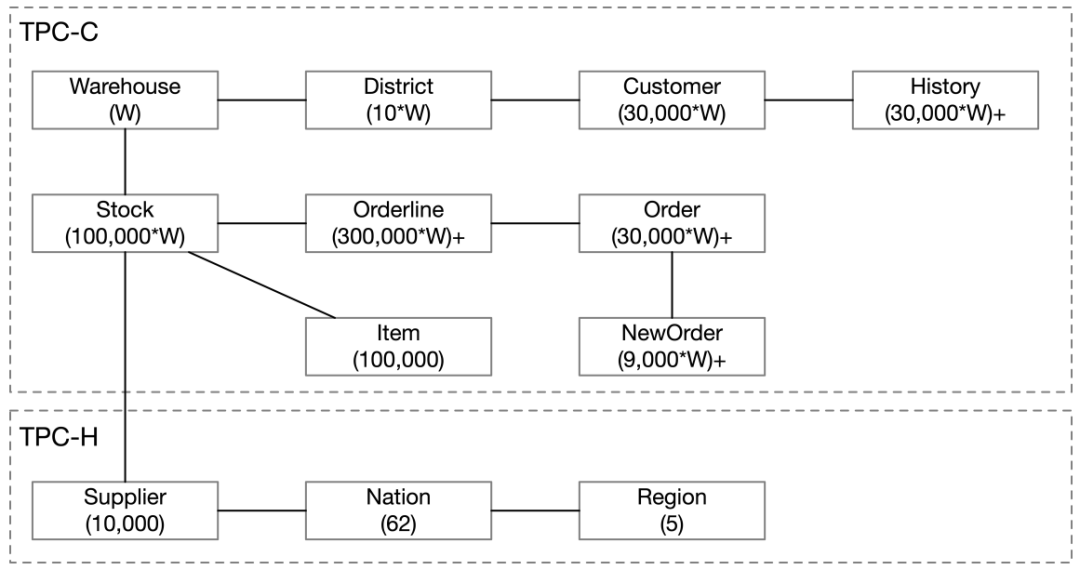
在 CH-Benchmark 中結合了 TPC-C 和 TPC-H 兩種基準,它把原來 TPC-C 中的 9 個表和 TPC-H 中的 8 個表修改合并成了 12 個表,并將兩者的伸縮模型也統一起來(Scaling TPC-H by the same factors of TPC-C),
這里小編來解釋一下,TPC-C 和 TPC-H 遵循不同的伸縮模型,TPC-C 遵循連續伸縮模型,倉庫表中的資料隨著系統性能的增加而增加,相反,TPC-H 遵循固定比例因子模型,其中資料庫大小由比例因子設定,而與系統性能無關,在 CH-Benchmark 中要求令 TPC-H 的伸縮模型去與TPC-C的伸縮模型相適應(以TPC-C的伸縮模型為基礎),也就是要求根據TPC-C規則,去設定各表(Warehouse, Stock, Item, History, Neworder, Orderline, District, Customer, and Order)的規模,
關于查詢陳述句,有三點大的修改:
- 保留了 TPC-C 中的五個事務:新訂單(New Order) :客戶輸入一筆新的訂貨交易;支付操作(Payment) :更新客戶帳戶余額以反映其支付狀況;發貨(Delivery) :發貨(模擬批處理交易);訂單狀態查詢(Order Status) :查詢客戶最近交易的狀態;庫存狀態查詢(Stock Level) :查詢倉庫庫存狀況,以便能夠及時補貨,
- 修改了 TPC-H 的 22 條查詢,修改了 table name 和 join key,并減少了算術運算,
- 刪掉了重繪函式(refresh functions)

1 CH-Benchmark 的執行規則
- 先僅測驗 OLTP 或 OLAP,然后混合執行(OLTP+OLAP)
- 控制 OLTP 和 OLAP 并行流的個數(The number of parallel OLTP and OLAP streams)
這里就是需要用到基準引數控制 OLTP 和 OLAP 作業負載的并發執行,
2 CH-Benchmark 評測度量的性能指標
這里提出了一種基于參照系的評測指標,主要是結合每分鐘事務(tpmC,transactions per minute)和每小時已完成查詢(QphH,queries per hour)的指標,
- 面向 OLAP 的指標(OLAP 占據主導):
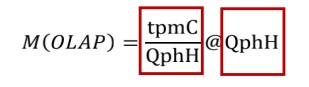
- 面向 OLTP 的指標(OLTP 占據主導):
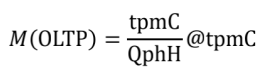
為了進行這一比較,我們首先從 n 個 OLTP 和 m 個 OLAP 流隔離運行的運行中計算 tpmC 和 QphH 測量值之間的比率,然后,我們將此比率與并行執行 n 個 OLTP 和 m 個 OLAP 流的混合作業負載所產生的比率進行比較,與獨立運行作業負載部分相比,并行執行的比例更高,這意味著資料庫系統在并行執行中為 OLTP 事務提供更好的服務,
舉個栗子:隔離執行為 5.7@5084 tpmC,混合執行為 6.5@5188 tpmC,這表示混合執行增加了 OLTP 吞吐量,
參考論文:Cole R, Funke F, Giakoumakis L, et al. The mixed workload CH-benCHmark[C]//Proceedings of the Fourth International Workshop on Testing Database Systems. 2011: 1-6.

二、HTAPBench
1 HTAPBench 的模式和作業負載
這一塊是和 CH-Benchmark(TPC-C + TPC-H)一樣的,不贅述了,
2 HTAPBench 的執行規則
- Fixed target tpmC with controllable OLAP workers
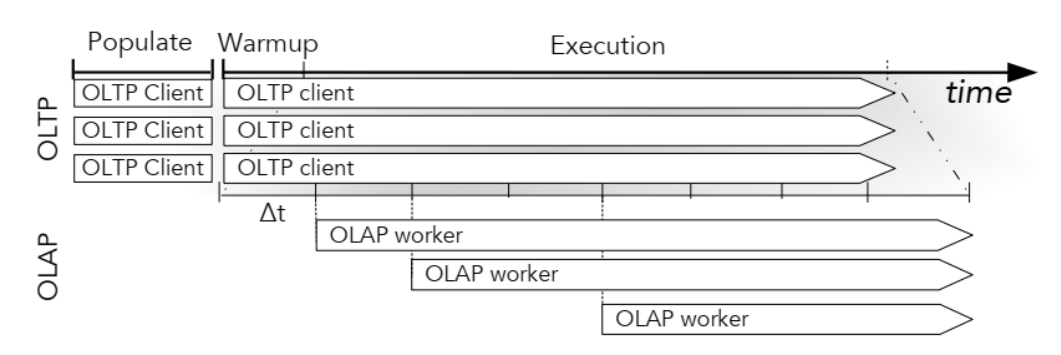
固定 OLTP (tpmC)為首要目標,然后動態地控制 OLAP 的 Worker 執行緒,這種方式在執行程序中會根據 OLTP 的實時吞吐量來調整添加 OLAP 作業流,由此測驗出在固定 OLTP 性能下能獲得的最大 OLAP 性能,
- Time window for querying newly-inserted data(查詢新插入資料的時間視窗)
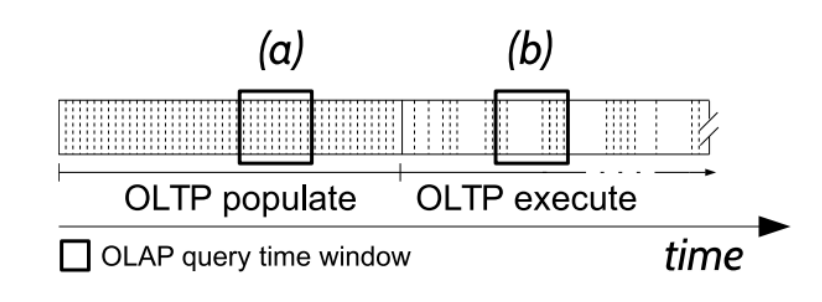
優勢是增加了時間視窗的選擇,Time window 這個不知道大家熟不熟悉,所謂時間視窗,就是根據時間劃分視窗,是將指定時間范圍內的所有資料組成一個 window,一次對一個 window 里面的所有資料進行計算,詳細的不展開講了,后續我把這篇論文拿出來解讀一下子,
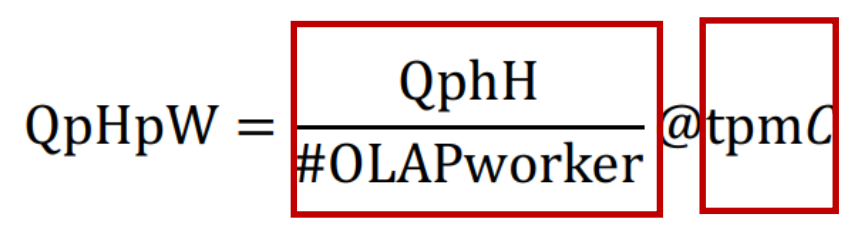
3 HTAPBench 評測度量的性能指標:
Under a certain TP throughput, the AP throughput per hour per worker(在一定 TP 吞吐量下,每個 Worker 每小時的 AP 吞吐量)
參考論文:Coelho F, Paulo J, Vila?a R, et al. Htapbench: Hybrid transactional and analytical processing benchmark[C]//Proceedings of the 8th ACM/SPEC on International Conference on Performance Engineering. 2017: 293-304.

三、對比
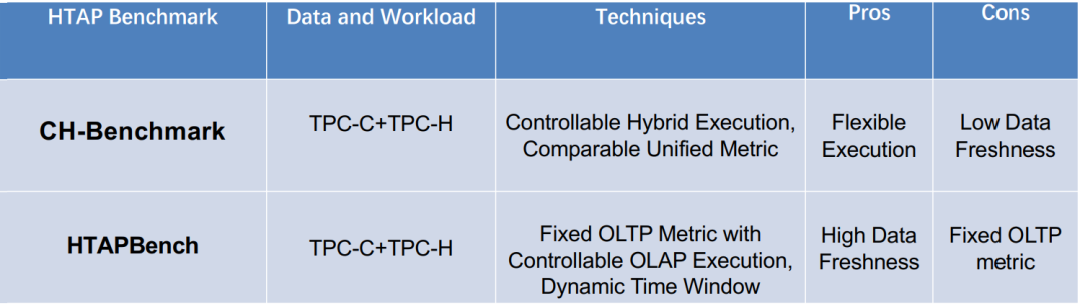
Comparison of HTAP End-to-End Benchmarks
- CH-Benchmark:
- 優勢:易用、執行靈活
- 劣勢:資料新鮮度較低
- HTAPBench:
- 優勢:資料新鮮度高
- 劣勢:固定了 OLTP 的指標

四、其他 HTAP 測驗標準
首先介紹一下端到端(End-to-End)的 HTAP 評測基準,比如:
Swarm64 HTAP benchmark
稍早的有 Swarm64 HTAP benchmark:
- 結合了 CH-benchmark 和 HTAPBench
- 采用了 CH-benchmark 中的混合執行規則
- 采用了 HTAPBench 中的動態時間視窗,
Github地址:https://github.com/swarm64/s64da-benchmark-toolkit
OLxPBench
最近在 ICDE 2022 上 Kang 提出了 OLxPBench,這種基準測驗有三個方法:Su-benchmark(TPC-C)、Fi-Benchmark(small-bank,面向小型銀行)、Tabenchamark(TATP,面向電信行業),
參考論文:Kang G, Wang L, Gao W, et al. OLxPBench: Real-time, Semantically Consistent, and Domain-specific are Essential in Benchmarking, Designing, and Implementing HTAP Systems[J]. arXiv preprint arXiv:2203.16095, 2022.
HATrick
來自威斯康辛大學 Miklai 在 SIGMOD 2022 新提出了一個叫 HATrick Benchmark 的混合基準,這個 HATrcik 融合了兩個新的性能指標:吞吐邊界(Throught frontier)和面向查詢的新鮮度(Query-Driven Freshness),
目前流行的HTAP基準包括 CH-Benchmark、HTAPBench 和 Swarm64,但在測驗中有著以下的限制:無法測量性能隔離;無法測量新鮮度;無法識別設計類別,HATtrick benchmark 作為一個開源專案,補充了吞吐量前沿,整合了新鮮度測量方法,可以有效評測 HTAP 系統,
吞吐量:該概念的引入是為了捕捉事務處理和分析處理的性能,通過在2D圖表中可視化吞吐量邊界,我們可以理解 HTAP 系統的整體性能行為,并識別出問題所在,
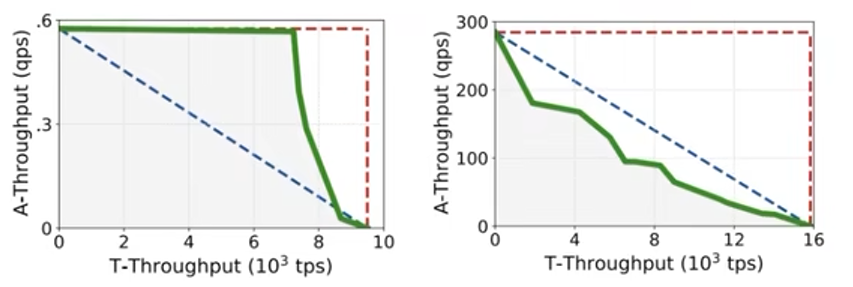
Throught frontier
如上圖,X 軸就是事務的吞吐,Y 軸就是分析的吞吐,這兩張圖怎么看的呢?簡單來說,就是第一幅圖中綠色曲線靠近紅色對角線,表示系統相對穩定;第二張圖中綠色曲線遠離紅色對角線,表示 AP 和 TP 兩者作業負載受干擾較大,
新鮮度:該指標的設計,是為了捕捉HTAP系統對實時分析的支持程度,松散地說,HTAP系統的新鮮度是對OLAP查詢可見的資料庫更新的延遲度量,
參考論文:Milkai E, Chronis Y, Gaffney K P, et al. How Good is My HTAP System?[C]//Proceedings of the 2022 International Conference on Management of Data. 2022: 1810-1824.
Micro-benchmarks
除了端到端(End-to-End)的HTAP基準,還有一些特別針對資料組織(data organization,為啥特別要針對這個?因為資料組織是 HTAP 的五大關鍵技術之一的微型基準測驗(Micro-benchmarks),比如:
- ADAPT Benchmark [Arulraj et al, SIGMOD 2016]

插入資料后簡單的對一些列資料進行 select 操作,
- HAP Benchmark [Athanassoulis et al, VLDB 2019]

這個就是在 select 基礎上增加了一些 insert、delete 和 update 操作,
好了,以上就是本期的分享內容,歡迎點贊收藏轉發,咱們下一期再見~
StoneDB 代碼已完全在 Github 開源,歡迎關注:
https://github.com/stoneatom/stonedb
StoneDB 官網:
_https://stonedb.io/
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/518998.html
標籤:其他