3.1 SQL概述:
- SQL:結構化查詢語言,是關系資料庫的標準語言,SQL是一個通用的、功能極強的關系資料庫語言
- 結構化查詢:理解:就是只要告訴資料庫我要干什么,怎么干就可以了
-
3.1.2 SQL的特點:
- 綜合統一:
- 集資料定義語言 DDL,資料操縱語言 DML,資料控制語言 DCL功能于一體, 可以獨立完成資料庫生命周期中的全部活動,如下:
- 定義關系模式,插入資料,建立資料庫,
- 對資料庫中的資料進行查詢和更新
-
資料庫重構和維護
-
資料庫安全性、完整性控制等
- 嵌入式SQL和動態SQL定義
- 用戶資料庫投入運行后,可根據需要隨時逐步修改模式,不影響資料的運行
- 資料運算子統一(如:查詢就用select,洗掉就用:delete)
- 高度非程序化:
- 非關系資料模型的資料操縱語言“面向程序”,必須制定存取路徑
- SQL只要提出“做什么”,無須了解存取路徑
- 存取路徑的選擇以及SQL的操作程序由系統自動完成
- 面向集合的操作方式:
- 非關系資料模型采用面向記錄的操作方式,操作物件是一條記錄
- SQL采用集合操作方式:
- 操作物件、查找結果可以是元組的集合
- 一次插入、洗掉、更新操作的物件可以是元組的集合
- 以同一種語法結構提供多種使用方式:
- SQL是獨立的語言
- 能夠獨立地用于聯機互動的使用方式
- SQL又是嵌入式語言
- SQL能夠嵌入到高級語言(例如C,C++,Java)程式中,供程式員設計程式時使用
- 簡單容學:
- SQL功能極強,完成核心功能只用了9個動詞
-
SQL功能 動詞 資料查詢 SELECT 資料定義 CREATE、DROP、ALTER 資料操縱 INSERT、UPDATE、DELETE 資料控制 GRANT、REVOKE
- 綜合統一:
-
3.1.3SQL基本概念:
-
- SQL支持關系資料庫三級模式結構:
- 基本表:
- 本身獨立存在的表
- SQL中一個關系就對應一個基本表
- 一個(或多個)基本表對應一個存盤檔案
- 一個表可以帶若干索引(索引:目的:快速查找資料,理解:相當于書中的目錄,如給學號做一個目錄,就可以快速查找)
- 存盤檔案
- 邏輯結構組成了關系資料庫的內模式
- 物理結構是任意的,對用戶透明
- 視圖
- 從一個或幾個基本表匯出的表
- 資料庫中只存放視圖的定義而不存放視圖對應的資料
- 視圖是一個虛表
- 用戶可以在視圖上再定義視圖
- 基本表:
- SQL支持關系資料庫三級模式結構:
3.2 學生-課程資料庫:
- 本章節內容以書上學習為主,書上包括示例圖表等
3.3 資料的定義:
- SQL的資料定義功能:模式定義、表定義、視圖和索引的定義
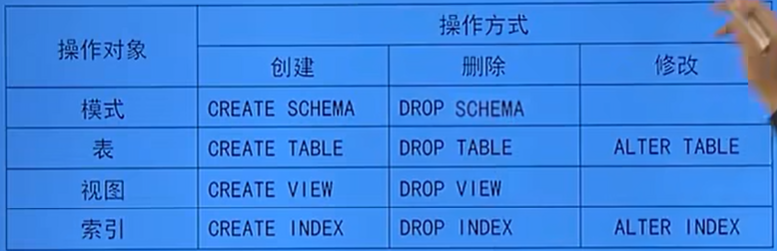
-
3.3.1 模式的定義于洗掉:
- 定義模式:
- 模式在SQL理解:相當于一個倉庫有不同的房間存放不同的工具,不同的房間就是不同的模式,不同的房間也只能放不同的工具,可以給房間授權只允許誰去訪問,資料庫就相當于倉庫
- 陳述句格式如下:
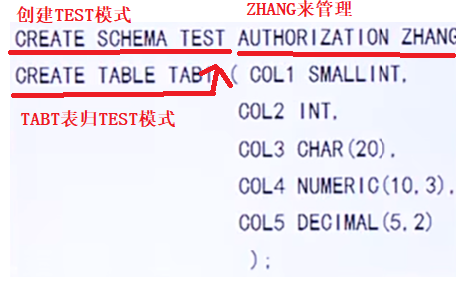
- CREATE SCHEMA <模式名> AUTHORIZATION <用戶名>
- AUTHORIZATION :該關鍵字的意思是把誰設定成該模式的管理員
- CREATE SCHEMA <模式名> AUTHORIZATION <用戶名>
- 例子:為用戶WANG定義一個學生-課程模式S-T
- CREATE SCHEMA "S-T" AUTHORIZATON WANG;
- 細節:
- 若沒有指定模式名,那么就以用戶名來表示
- CREATE SCHEMA <用戶名表示> AUTHORIZATON WANG;
- 在創建模式時同時還可以建立表
- 語法:CREATE SCHEMA <模式名> AUTHORIZATON <用戶名>[<表定義子句>|<視圖定義子句>];

- 執行創建模式陳述句必須擁有DBA權限,或者DBA授權在CREATESCHEMA的權限
- 如:張三管理太多模式了,他就可以在創建模式的時候把權限給到歷史,注意的是資料庫要有李四這個人
- 若沒有指定模式名,那么就以用戶名來表示
- 洗掉模式:
- 語法:DROP SCHEMA <模式名> <CASCADE | RESTRICT>;
- <CASCADE | RESTRICT> 中的兩選項必須二選一:
- CASCADE(級聯)
-
洗掉模式的同時把該模式中所有的資料庫物件全部洗掉
-
-
RESTRICT(限制)
-
如果該模式中定義了下屬的資料庫物件(如表、視圖等),則拒絕該洗掉陳述句的執行
-
- CASCADE(級聯)
-
例子:DROP SCHEMA ZHANG CASCADE;
-
洗掉模式ZHANG,同時該模式中定義的表也被洗掉
-
- 定義模式:
-
3.3.2 基本表的定義、洗掉與修改:
- 定義基本表:
-
陳述句格式:
-
- 定義基本表:
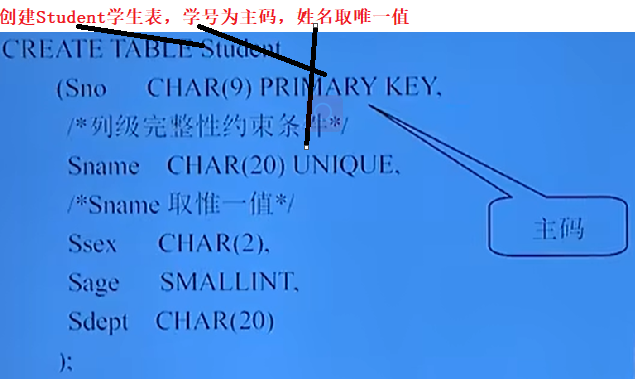
CREATE TABLE <表名>
( <列名> <資料型別> [<列級完整性約束條件>],
<列名> <資料型別> [<列級完整性約束條件>],
[<表級完整性約束條件>]);
-
-
- 細節:
- 如果完整性約束條件涉及到該表的多個屬性列 - [<表級完整性約束條件>],否則定義在列 - [<列級完整性約束條件>]
- 逗號代表一條陳述句的結束
- [ ] 大括號里的內部代表可有可無
- 例子:
- 細節:
-
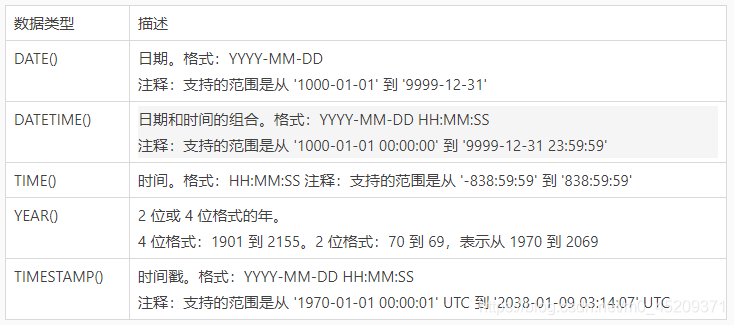
資料型別:
-
-


字串型別:

列舉型別:
列舉型別英文為ENUM,對1~255個成員的列舉需要1個位元組存盤;對于255 ~ 65535個成員,需要2個位元組存盤,最多允許65535個成員,創建方式:enum(“M”,“F”);日期型別:
-
-
-
模式與表:
-
每一個基本表都屬于某一個模式,一個模式包含多個基本表
- 理解:模式代表倉庫房間,基本表代表工具,工具可以是錘子、鐵鍬等等,所以基本表都屬于某一個模式,一個模式包含多個基本表
-
創建基本表(其他資料庫物件也一樣)時,若沒有指定模式,系統根據搜索路徑來確定該物件所屬的模式
- 理解:創建表,沒有指定模式,根據搜索路徑來確定:買了工具,都我沒有說放到能夠房間,那就誰買的誰去管理
-
顯示當前搜索路徑:
- SHOW search path;
-
搜索路徑的當前某默認值:
- $user(用戶名,登錄時的用戶名), PUBLIC;
-
DBA用戶可以設定搜索路徑:
-
SET search_path To "S-T",PUBLIC;
- “S-T”就是修改的搜索路徑,PUBLIC是沒有S-T就創建一個PUBLIC的模式
-
理解:買工具回來放到S-T房間,如果沒有S-T房間就放到PUBLIC房間中去
-
SET search_path To "S-T",PUBLIC;
-
若搜索路徑的模式名都不存在,系統將給出錯誤
-
若搜索路徑中的存在模式,ROMBS還使用模式串列中第一個存在的模式作為資料庫物件的模式名
-
理解:我設定了多個模式名,使用的時候用第一個,如果不存在在找第二個
-
-
每一個基本表都屬于某一個模式,一個模式包含多個基本表
- 創建基本表:
- 在模式的狀態下創建表 - 就是創表的時候指定模式:
- 1.創建表給出模式名:
- CREATE TABLE "ST-T".Studnet(...); // Student所屬的模式是S-T
- CREATE TABLE "ST-T".Course(...); // Course所屬的模式是S-T - 后需還可以往模式中添加表,一個模式可以有若干個基本表(前面有說)
- CREATE TABLE "ST-T".SC(...); // SC所屬的模式是S-T
- 2.在創建模式陳述句中同時創建表:
-
3.設定所屬模式,在創建表中不必給出模式名(就是設定它的搜索路徑)
-
修改基本表:
-
語法:
- CASCADE - 級聯洗掉,使用該操作自動洗掉參考了該列的其它物件
- RESTRICT -限制洗掉,使用該操作如果該列被其它物件參考,就會拒絕洗掉該列
- ALTER COLUMN - 用于修改原有的列定義,包括修改列名和資料型別
-

-
例子:
-

-
-
洗掉基本表:
-
語法:DROP TABLE <表名>[RESTRICT| CASCADE];
- 基本表定義被洗掉,資料被洗掉,表上建立的索引、視圖、觸發器等一般也將被洗掉
-
RESTRICT:洗掉表是有限制的,欲洗掉的基本表不能被其他表的約束所參考
如果存在依賴該表的物件,則此表不能被洗掉 -
CASCADE:洗掉該表沒有限制,
在洗掉基本表的同時,相關的依賴物件一起洗掉 -
例子:
-

-
不同資料庫處理的策略:
-
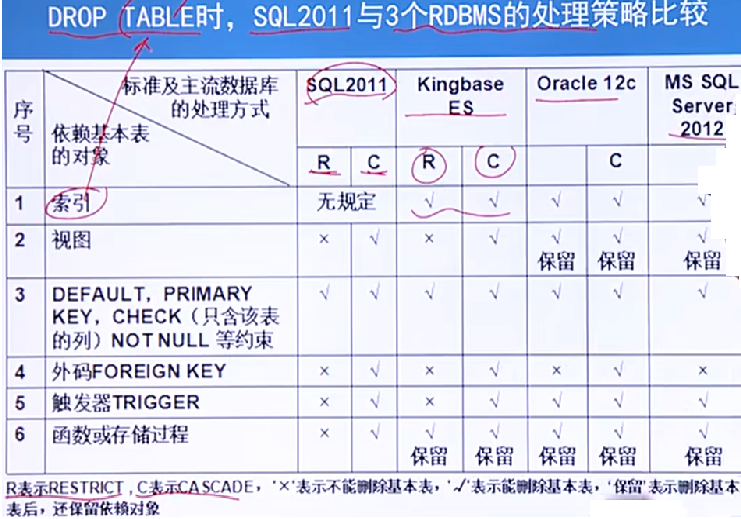
-
-
-
3.3.3 索引的創建和洗掉:
-
建立索引的目的:加速查詢速度
-
誰可以建立索引:DBA或表的屬主(建表人)
-
DMBS一般會自動建立以下列上的索引(相當于有下面關鍵字的自動加到目錄):
-
PRIMARY KEY;
-
UNIQUE;
-
-
誰維護索引:DMBS自動完成
-
使用索引:DMBS自動執行是否使用索引及使用哪些索引
-
R(R表示關系資料庫)DBMS中索引一般采用B+樹、HASH索引來實作
-
B+樹索引具有動態平衡的優點
HASH索引具有查找速度快的特點
采用B+樹,還是HASH索引 則由具體的RDBMS來決定 -
索引是關系資料庫的內部實作技術,屬于內模式的范疇
-
CREATE INDEX 陳述句定義索引時,可以定義索引是唯一索引、非唯一索引(如:年齡,年齡可能就是會重復)或聚簇索引
-
建立索引:
-
陳述句:CREATE [UNIQUE(唯一索引)] [CLUSTER(聚簇索引)] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…); - 不寫大括號里面的索引,就是非唯一索引
-
- 建立唯一索引例子:
-

-
建立聚簇索引例子:
- 什么是聚簇索引:資料搜索到計算機中
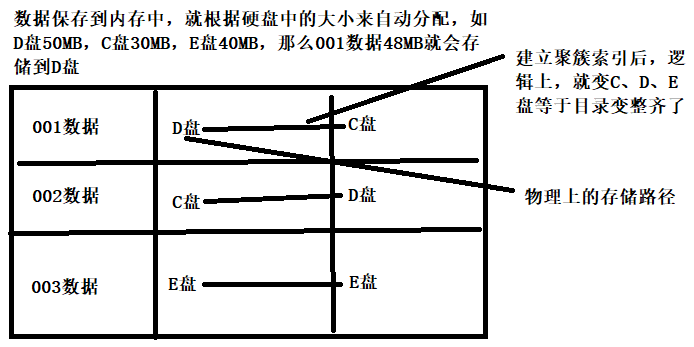
-




-
- 洗掉索引:
- 陳述句:DROP INDEX<索引名>;
- 洗掉索引時,系統會從資料字典中刪去有關該索引的描述
- 例:洗掉Student表的Stusname索引
- DROP INDEX Stusname;
- 資料字典: - 和新華字典一樣記錄了所有資料
- 資料字典是關系資料庫管理系統內部的一組系統表,它記錄了資料庫中所有的定義資訊,包括關系模式定義、視圖定義、索引定義、完整性約束定義、各類用戶對資料庫的操作權限、統計資訊等,
- 關系資料庫管理系統在執行SQL的資料定義陳述句時,實際上就是在更新資料字典表中的相應資訊,
- 在進行查詢優化和查詢處理時,資料字典中的資訊是其重要依據
- 洗掉索引:
3.4 資料查詢:
- 陳述句:
-
/* SELECT - 查詢 all - 顯示所有 distinct - 顯示不同的(去重) from - 去哪個表查 where - 條件 group by - 分組 order by - 排序 */ SELECT [ALL | DISTINCT ]<目標列運算式>[,<目標列運算式>]... FROM<表名或視圖名>[,<表名或視圖名>...] | (<SELECT陳述句>)[AS]<別名> [WHERE<條件運算式>] [GROUP BY<列名1>[HAVING<條件運算式>]] [ORDER BY<列名2>[ASC | DESC]]
-
- 細節:
- 陳述句中的字母不分大小寫
- 陳述句中的符號都為業務狀態下的
- [ ]中的內容,不是陳述句必須內容,需要該功能在添加
-
3.4.1 單表查詢:
- 什么是單表查詢?只對一個表的內容進行查詢
- 查詢表中的若干列:
- 查詢指定列:
-
/* 查詢全體學生的學號和姓名 */ SELECT son,sname FROM Student;
-
查詢表中全部列:
-
/* 查詢全體學生的詳細記錄 */ SELECT * FROM Student;
-
選擇經過計算的值:
-
作用:選出表中指定的屬性列,經過計算后輸出
-
格式:SELECT字陳述句的<目標列運算式>可以為:算數運算式、字串常量、函式、列別名
-
例: 注意表格的名字
-
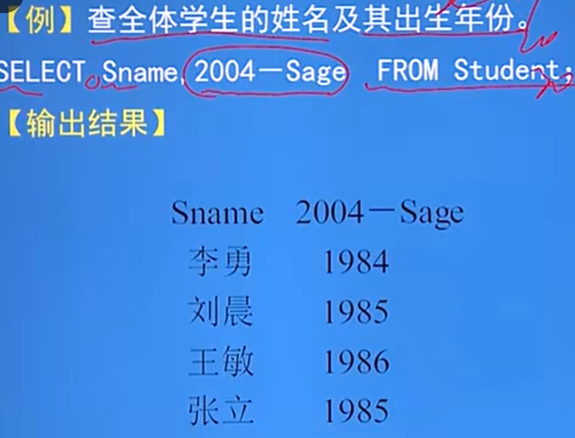
- 例:函式的使用,不存在列,輸出到表格
-

-
例:別名的使用
-
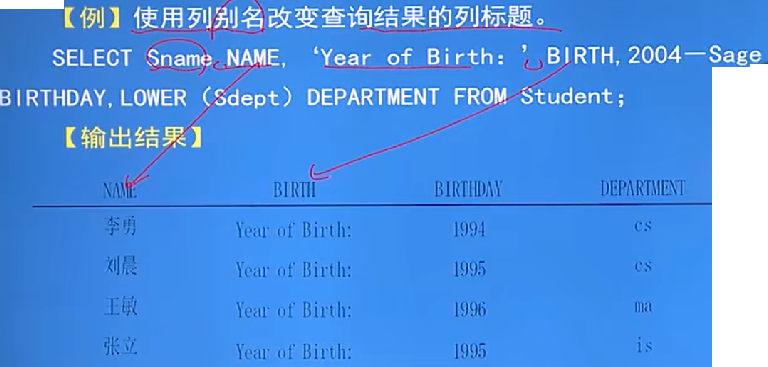
-
-
選擇表中的若干元組:
-
消除取值重復的行(去重):
-
兩個關鍵字:DISTINCT(顯示去重后的)和ALL(顯示所有),不寫關鍵字默認是ALL
-
例:
-

-
-
查詢滿足條件的元組:
-
通過關鍵字where子句實作
-
運算子 說 明 = 等于 <> 不等于 != 不等于 < 小于 <= 小于等于 !< 不小于 > 大于 >= 大于等于 !> 不大于 BETWEEN , NOT BETWEEN 在指定的兩個值之間 ,不在指定訪問的值 IS NULL, IS NOT NILL 為NULL的值, 不為NULL的值
AND,OR,NOT 并且 ,或者,反;不是
-
例子:比較大小
-

-
例子:確定范圍
-
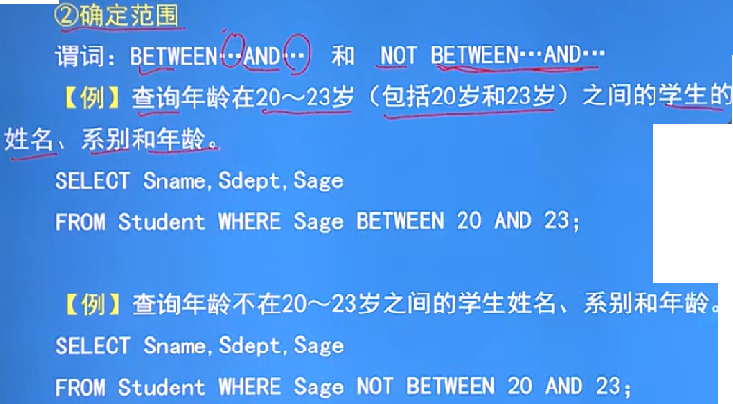
-
例子:確定集合
-

- 例子:字符匹配

-
-
例子:匹配串為含通配符的字串
-
%表示任意長度的字串
-
_ ,下斜線表示任意單個字符
-
-

-
例子:使用換碼字串將通配符轉義為普通字符
-
ESCAPE '<換碼字符>' - 如:查詢的字串中有& _ 這些特殊字符時,可以通過轉碼讓它轉為字符
-
-

-
例子:涉及空值的查詢
-
IS NULL或IS NOT NULL, "IS" 不能用“=”代替
-

-
-
例子:多重條件查詢
-
AND和OR來聯結多個查詢條件,AND的優先級高于OR,可以用括號來改變優先級
-
有時候可以用:[NOT] IN 或 [NOT] BETWEEN ... AND ...
-
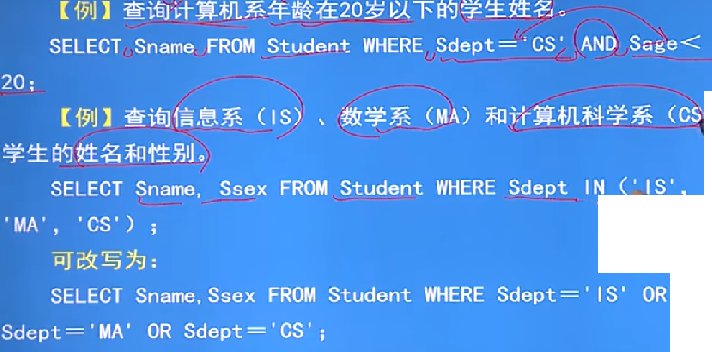
-
-
例子:ORDER BY子句(排序)
-
ORDER BY 子句可以按一個或多個屬性列排序
-
升序:ASC; 降序:DESC; - 默認是升序
-
空值默認是最大值
-
ASC:排序列為空值的元組最后顯示
-
DESC:排序列為空值的元組最先顯示
-

-
-
聚集函式
- COUNT ( * ) 統計元組(行)個數
- COUNT ( [ DISTINCT | ALL ] <列名> ) 統計一列中的值的個數
- SUM( [ DISTINCT | ALL ] <列名> ) 計算一列值的總和(該列必須是陣列型)
- AVG( [ DISTINCT | ALL ] <列名> ) 計算一列值的平均值(該列必須是陣列型)
- MAX( [ DISTINCT | ALL ] <列名> ) 求一列中的最大值
- MIN( [ DISTINCT | ALL ] <列名> ) 求一列中的最效值
- 細節:WHERE子句中不能使用聚集函式作為條件運算式,只能在SELECT和GROUPBY的HAVING子句中

-
GRIOUP BY子句(分組)
-
GRIOUP BY子句作用:按指定的一列或多列值分組,值相等的為一組,來細化聚集函式的作用物件
-
細節:
-
未對查詢結果分組,聚集函式將作用于整個查詢結果
-
對查詢結果分組,聚集函式將分別作用于每個組
-
語
-
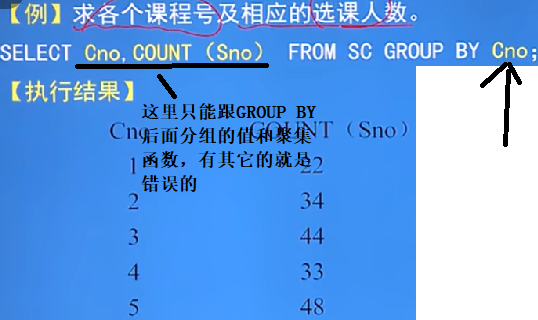
-
-
HAVING陳述句
-
GROUP BY子句分組后,可以使用HAVING陳述句指定篩選條件
-
細節:
-
HAVING是和GROUP BY陳述句連在一起的,作用在分組物件中
-
-

-
-
HAVING短句與WHERE子句的區別
-
HAVING是和GROUP BY陳述句連在一起的,作用在分組物件中
-
WHERE是作用在整個查詢物件中
-
作用物件不同:WHERE子句作用于基表或視圖,從中選擇滿足條件的元組,HAVING短語作用于組,從中選擇滿足條件的元組
-
WHERE子句中是不能用聚集函式作為條件運算式的
-

-
-
-
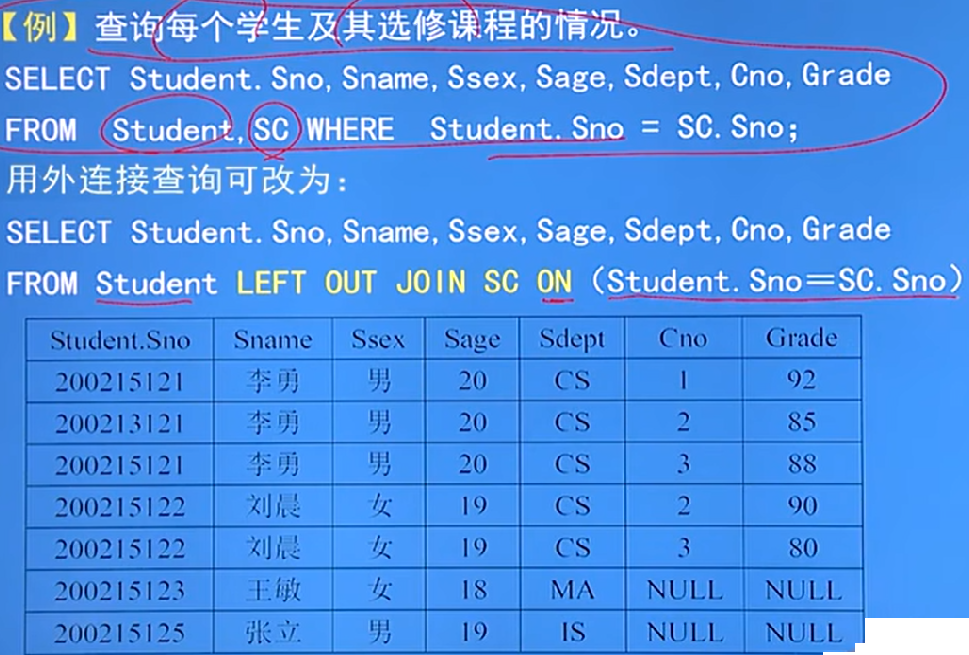
3.4.2 連接查詢:
- 等值連接與非等值連接查詢:
- 連接查詢的WHERE子句中用來連接兩個表的條件稱為連接條件或連接謂詞
-
等值連接:當連接運算子為=時,稱為等值連接
-
非等值連接:所以非=符號時,稱為非等值連接
-
細節:
-
連接謂詞中的列名稱為連接欄位,并且各連接欄位必須是可比的,但名字不必相同
- 運算子有:= > < >= <= != <>等
-
-
例:
-
- 等值連接與非等值連接查詢:
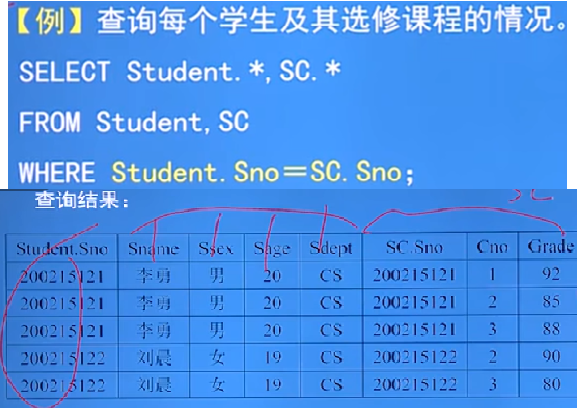
-
- 例的執行程序:首先在Student表中拿出第一個Sno學號和Sc表中的所有Sno學號做比較,只要是和Student的Sno相同的就和成一個新的元組,
以此類推,拼接得到的表不是真實存在的,隨著查詢的結束而結束
-
-
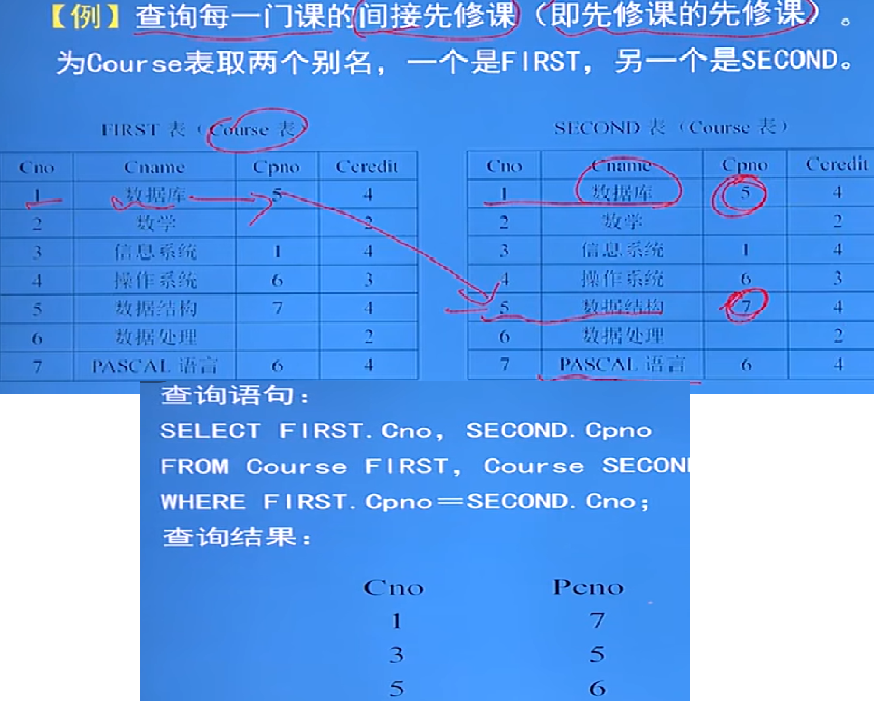
自然連接:
- 若在等中連接中把目標列中重復的屬性列去掉則稱自然連接(就是有重復的屬性或列,就去重)

- 自身連接:
- 一個表與其自己進行連接
- 細節:
- 都是同一個表連接,怎么讓這兩個表區分? 起別名
- 由于屬性名都是同名屬性,因此必須使用別名來區分
-
外連接:
- 就是把不要的懸浮元組也加到表里面
- 普通連接和外連接的區別:
- 普通連接操作只輸出滿足連接條件的元組
- 外連接操 接主體,將主體表中的不符合條件的元組一并輸出
- 外連接分為:
- 左連接為:列出左邊關系中的所有元組
- LEFT OUT JOIN SC ON
- 右連接為:列出右邊關系中的所有元組
- RIGHT OUT JOIN SC ON
- 左連接為:列出左邊關系中的所有元組
- 例:
-
多表連接:
-
連接操作是流量以上的表進行連接
-
-
例: - 下面用到了三個表
-
-
-
3.4.3 嵌套查詢:
-
一個SELECT-FROM-WHERE陳述句陳為一個查詢塊
-
嵌套查詢定義:是指將一個查詢塊嵌套在另一個查詢塊的WHERE子句或HAVING短語的條件中的查詢
-
理解:就是將新的查詢陳述句嵌套在已有的查詢陳述句中的WHERE或HAVLNG中,其它地方不能嵌套
-
-
細節;
-
子查詢中不能使用ORDER BY子句
-
層層嵌套方式反映來哦SQL語言的結構化
-
有些嵌套查詢可以用連接運算代替
-
外層查詢叫:父查詢,內層查詢叫:子查詢
-
父查詢里面嵌套子查詢,子程式里面還可以嵌套子查詢
-
不相關子查詢:子查詢的查詢條件不依賴父查詢(看案例)
-
相關子查詢:子查詢的查詢條件依賴于父查詢,整個陳述句稱為嵌套查詢(看案例)
-
-
例:
-
-
帶有IN謂詞的子程查詢:
-

-

-
例子2:
-

-
-
帶有比較運算子的子查詢:
-
當確切知道內層回傳的是單個值時,可以用 >、<、=、>=、<=、!=或<>等運算子
-
例1:
-

-
例2:
-
例子執行流程:1.x表的第一個Son和y表的每一個Son進行比較,和x的Son一樣的就進行表拼接,依此類推
-
2.得到拼接的表,然后通過函式AVG去求X的Son和y的Son拼接表的平均成績,和X表的成績進行比較,大于就顯示學號
-
-

-
-
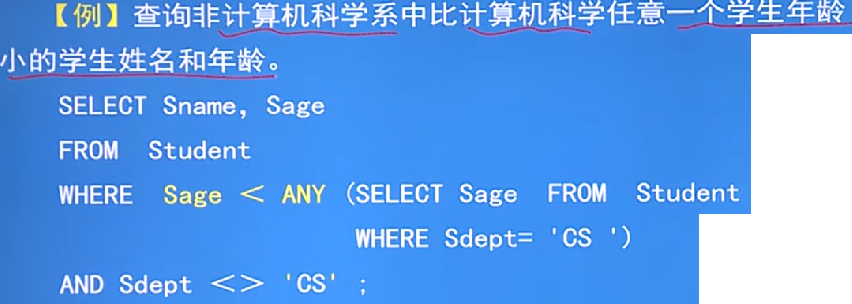
帶有ANY(SOME不同的系統可能使用這個)或ALL謂詞的子查詢:
-
ANY - - 任意一個值
-
ALL - - 所以值
-
ANY和ALL需要配合比較運算子使用
-

-
例子: - 執行程序 :先執行子查詢,找出計算機科學的的所有人年齡得到一個集合(xx,xx),然后執行父查詢不是計算機系的年齡,然后和子程查詢的集合比較
-
-

-

-
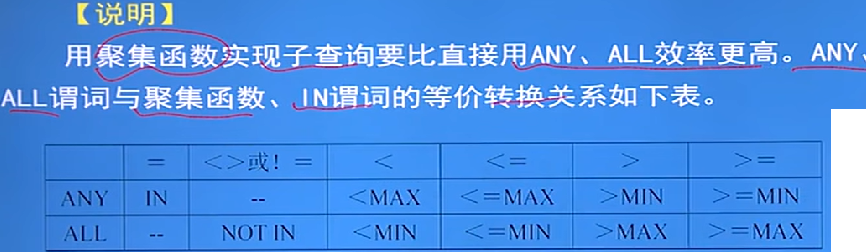
細節: - =ANY等價于IN謂詞,<ANY等價于<MAX,<>ALL等價于NOT IN謂詞,<ALL等價于<MIN,等等
-
-
帶有EXISTS謂詞的子查詢:
-
EXISTS謂詞:代表存在量詞?,帶有EXUISTS謂詞的子查詢,不回傳任何資料,只產生邏輯真值"true",或邏輯假值"false"
-
存在量詞:存在,有些,有一個,至少有一個,存在一個,對某一個,對有些,對某些,有的等
-
-
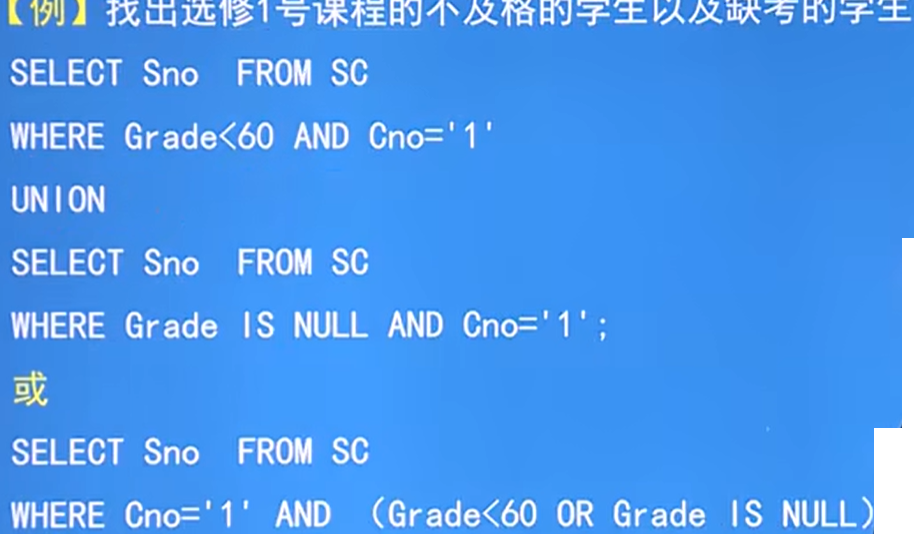
例:查詢所有選修了1號課程的學生姓名
-
思路:需要Student和SC表,通過Student中Son去確定SC中選了課的學生的Sno,并且通過條件AND判斷,課程號為1的
-
-
細節1:所有存在量詞EXISTS后,如若內層查詢結果非空,則外層的WHERE子句回傳真值,否則回傳假值
-
細節2:由EXISTS引出的子查詢,select后通過用*,因為EXISTS回傳的只有真和假,用列名沒有意義
-

-
-
NOT EXISTS謂詞的子查詢:
-
若內查詢結果非空,外層WHERE子句回傳假值
-
若內查詢結果為空,外層WHERE子句回傳真值
-
例子:思路:內層查詢,查詢出所有選擇了1號課程的學生,通過NOT EXISTS回傳沒選擇的學生就是真
-

-
-
不同形式的查詢間的替換:
-
一些帶EXISTS或NOT EXISTS謂詞的子程式不能本其他形式的子程式等價替換
-
所有帶IN謂詞、比較運算子、ANY和ALL謂詞的子查詢都能用帶EXISTS謂詞的子程式等價替換
-
理解:如IN和ALL的目的就是表達查詢結果集里面所有的值,那EXISTS表示真偽,就可以完美代替
-
-
例:思路:內查詢S2表想S1表進行自身連接查詢,當S2中的系和S1中的系對應上,并且S2表中的名字是劉晨,回傳真(不理解畫圖)
-

-
-
用EXISTS/NOT EXISTS實作全稱量詞:
-
全稱量詞:一切、每一個、任意
-
SQL語言中是沒有全稱量詞語的,但可以通過存在量詞轉為全稱量詞
-
例:
-

-
-
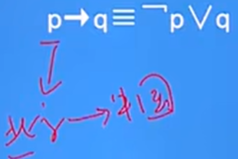
用EXISTS/NOT EXISTS實作邏輯蘊涵:
-
邏輯蘊涵:我來過北京代表我來過中國,我來過中國不代表去過北京
- SQL語言中沒有蘊涵邏輯運算,可以利用謂詞演算將邏輯蘊涵謂詞等價轉換
-
-

-
-
-
-
3.4.4 集合查詢:
- 什么是集合查詢?SELECT陳述句的查詢結果是元組的集合,所以多個的SELECT陳述句的結果可以進行集合查詢
- 集合查詢種類:
- 并操作(操作關鍵字:UNLON):第一個查詢出來的集合是1234,第二個是456,并起來就是123456,是去重的
- UBLON - 是去重的, 如果是:UNLON ALL 是保留重復結果
- 交操作(操作關鍵字:INTERSECT):第一個查詢出來的集合是489,第二個是456,交就是4
- 差操作(操作關鍵字:EXCEPT):第一個查詢出來的集合是1234,第二個是23,差就是在第一個集合里,不在第二個集合里,那么就是14
- 細節:參加集合操作的各查詢結果的列數(一列的的數)必須相同,對應的資料型別也必須相同
- 并操作(操作關鍵字:UNLON):第一個查詢出來的集合是1234,第二個是456,并起來就是123456,是去重的
- 并操作例子:
-
交操作例子:
-
-
差操作例子:
-

-
3.4.5 基于派生表的查詢:
-
在from陳述句中,成為主存在的子查詢叫派生表
- 細節:派生表(子查詢)必須取一個別名,如果沒有使用聚集函式,使用默認的,如果使用了需要指定屬性列
-

-
-
3.4.6 SELECT陳述句的一般格式:
-







3.5資料更新:
- 什么是資料更新?就是如何插入資料、修改資料、洗掉資料
-
3.5.1 插入資料:
- 什么是插入資料?在一個表中插入一個新的,元組、一個查詢結果、多個元組
- 插入明確的資料:
- 格式:INSERT INTO <表名> [ (<屬性1>)[,<屬性2>] ......] VALUES ( <常量1> [常量2] ....);
- 功能:將新元組插入指定表中
- 理解:[ (<屬性1>)[,<屬性2>] ......] - 寫屬性列名可寫可不寫,不寫默認按順序插入,寫了值要和屬性列對應
- 理解:( <常量1> [常量2] ....) - 插入的屬性值
- 細節:
- INTO子句:屬性列的順序可與表中的順序不一致,沒有指定屬性列的默認插入全部
- VALUES子句:提供的值必須與INTO子句匹配,值與屬性列的個數和值的型別要一致
- 插入資料時,主碼是不能為空的
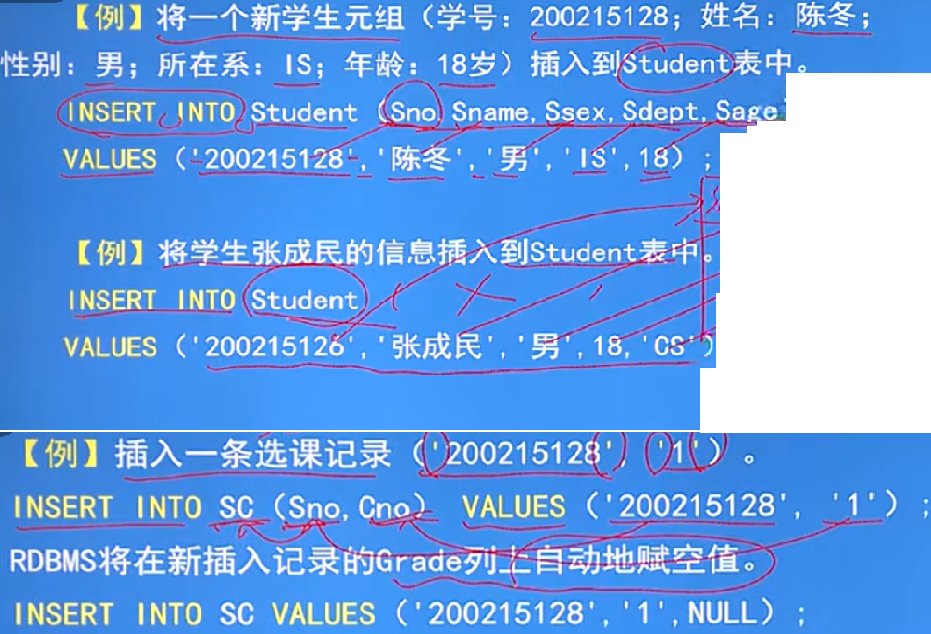
- 插入子查詢結果資料:
- 格式:INSERT INTO <表名> [ (<屬性1>)[,<屬性2>] ......] 子查詢;
- 功能:將子查詢結果插入指定表中

-
3.5.2 修改資料:
-
陳述句:UPDATE <表名> SET <列名>=<運算式>[,<列名>=<運算式> ]...[ WHERE < 條件 > ];
-
功能:修改指定表中滿足WHERE子句條件的元組
-
-
細節:
-
SET子句:指定修改方式,修改的列,修改后取值
-
WHERE子句:指定修改的元組,預設表示修改所有元組
-
在執行修改陳述句時會檢查修改操作是否破壞表上已定的完整性規則(如Student,Sc表的學號)
-
-
將一個元組或多個元組修改:
-
-
帶子查詢的修改陳述句:
-
-
-
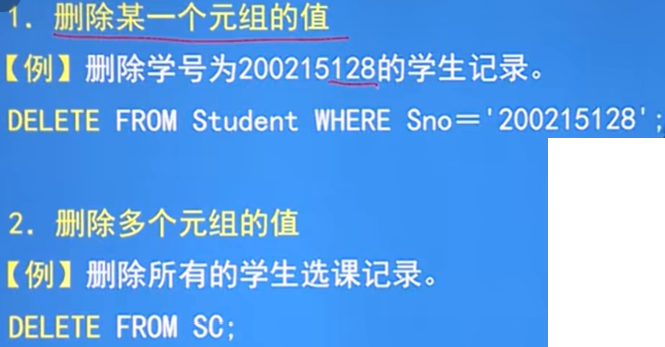
3.5.3 洗掉資料:
-
陳述句:DELETE FROM <表名> [ WHERE <條件> ];
-
功能:洗掉指定表中滿足WHERE子句條件的元組
-
-
細節:
-
WHERE子句:指定洗掉的元組,預設WHERE子句表示洗掉表中全部元組,但定義仍在
- 要保持表的完整性約束,在Student表中洗掉了A學生,Sc中A學生也應該是洗掉的
-
-
洗掉一個或多個元組的值:
-
-
帶子查詢的洗掉陳述句:
-

-


3.6 空值的處理:
- 什么是空值?所謂空值就是 "不指導" 或 “不存在” 或 "無意義" 的值,空值是一個很特殊的值,含有不確定性
- SQL陳述句中取空值一般情況如下:
- 該屬性有值,但當前不知道它的具體值
- 該屬性不應該有值
- 由于某種原因不便于填寫
- 空值的約束條件:
-
- 屬性定義中有 NOT NULL(不能為空)約束條件的不能為空值
- 叫了UNIQUE(唯一)限制的屬性不能取空值
- 碼屬性(主碼,后選碼)不能取空值
-
- 空值的產生:

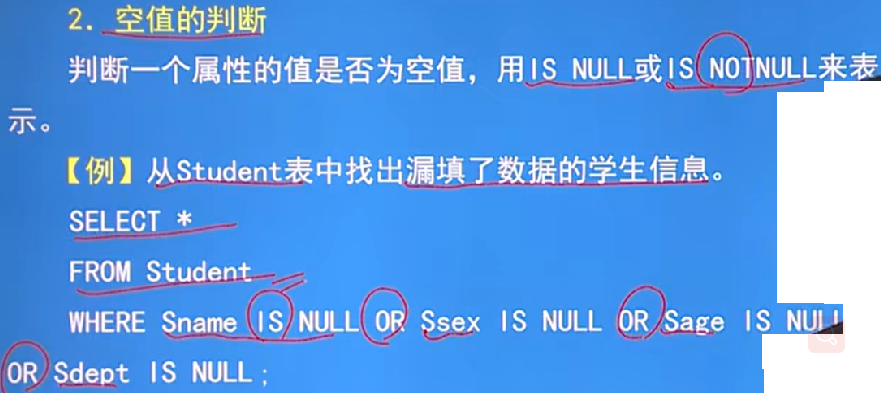
- 空值的判斷:
- IN NULL - 判斷是否是空值 IN NOTNULL - 判斷不是空值的
-
空值的算數運算、比較運算和邏輯運算:
-
算術運算:空值與一個值(包括另一個空值)的算術的結果為空值
-
理解:空值和其他值的算術運算(加減乘除)結果都為空
-
-
比較運算:空值與另一個值(包括另一個空值)的比較運算結果為UNKNOWN(未知數);
- 理解:空值和其他值的比較運算( > < = ...)結果都為UNKNOWN
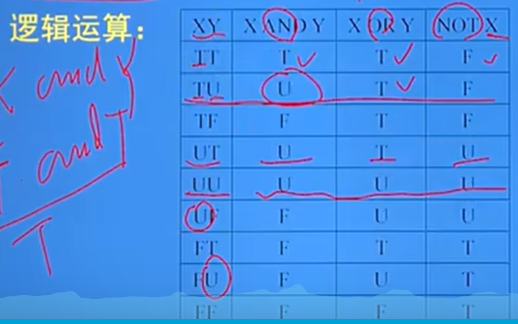
- 邏輯運算:
- T 表示 true
- F 表示 false
- U 表示 UNKNOWN
-
-
例子:
-

3.7 視圖:
- 什么是視圖?視圖是從一個或多個基本表(或視圖)匯出的表,它與基本表不同,它是一個虛表
- 細節:
- 資料庫中只存放視圖的定義,而不存放視圖定義的資料,這些資料仍存放在原本的基本表中
- 基本表中的資料發生變化,視圖中的查詢出的資料也會發生變化
- 視圖的操作:查詢、洗掉、受限更新、定義該視圖的新視圖
-
3.7.1 定義視圖:
- 語法:CREATE VIEW <視圖名> [ (<列名> [,<列名> ]....... ) ] AS <子查詢> [ WITH CHECK OPTION ];
- WITH CHECK OPTION - 關鍵字表示:對視圖進行更新、插入、洗掉操作時,需要滿足視圖定義的謂詞條件
- 如:一個只有資訊系的學生視圖,通過WITH CHECK OPTION關鍵字來保持對視圖操作時,視圖只有資訊系的學生
- 細節:
- 組成視圖的屬性列名:可以全部全部省略或全部指定
- 子查詢不允許含有ORDER BY 子句和DISTINCT(去重)短語
- RDBMS(關系資料庫)執行CREATE VIEW陳述句時只是把視圖定義存入資料字典,并不執行其中的SELECT陳述句
- 在對視圖查詢時,按視圖的定義從基本表中將資料查出
- 小結:視圖是虛表,只是存放視圖的定義,真的向視圖查詢資料時,是向基本表進行資料查詢
- 語法:CREATE VIEW <視圖名> [ (<列名> [,<列名> ]....... ) ] AS <子查詢> [ WITH CHECK OPTION ];
-
創建視圖:
- 例子(基于一個表):
- 下面例子中第二個,加入了WITH CHECK OPTION關鍵字,所有的DMBS對該視圖的更新操作:
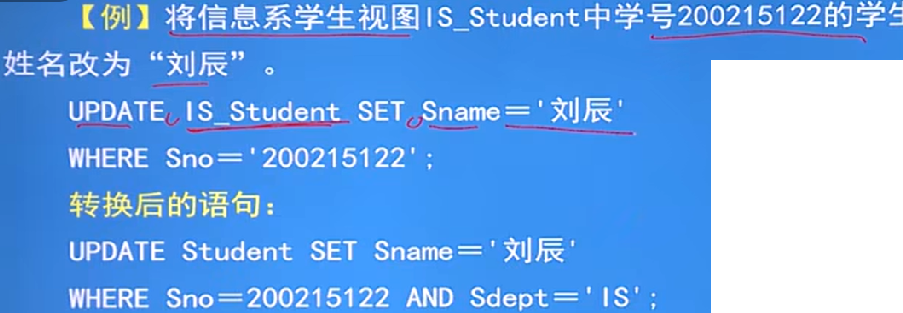
- 修改操作:自動加上Sdpet='IS'的條件
- 洗掉操作:自動加上Sdpet='IS'的條件
- 插入操作:自動檢查Sdpet屬性值是否為'IS',如果不是,則拒絕該插入操作,如果沒有提供Sdpet屬性值自動定義Sdept為'IS'

-
例子(基于多個表):
-

-
例子(基于視圖的視圖):
-

-
例子(帶運算式的視圖):
-

-
例子(分組視圖):
-

-
例子(不指定屬性列):
-
細節:本例中如修改基本表Student的結構后,Student與視圖F_Student視圖的映像關系被破壞,導致該視圖不能正確作業
- 如:我在基本表中sex和age的位置進行了調整,你們中視圖中age的整型存放導sex的字符型中肯定就是錯誤的了
-

-
洗掉視圖:
-
陳述句:DROP VIEW <視圖名> [ CASCADE(級聯) ];
-
細節:
-
該陳述句從資料字典中洗掉指定的視圖定義
-
如果該視圖還匯出了其它視圖(如:由視圖創建出一個新的視圖),使用CASCADE級聯洗掉陳述句,把該陳述句和由他匯出的所有視圖一起洗掉
-
洗掉基本表時,由該基本表匯出的所有視圖定義都必須顯式的使用DEOR VIEW陳述句洗掉(因為洗掉了基本表,但視圖還是在的)
-
-
例子:
-

-
-
視圖的查詢:
- 視圖定義后,用戶可以像基本表意義對視圖進行查詢
- RDBMS實作視圖查詢的方法--視圖消解法:
- 1.進行有效檢查 - 如:查詢S1在Student,但Student陳述句洗掉了,那就是錯誤的
- 2.轉換成等價的對基本表的查詢
- 3.整型修正后的查詢
- 例子:

-
視圖消解法的局限:
-

-
3.7.3 更新視圖:
-
更新視圖是指通過視圖來插入、洗掉和修改資料,由于視圖是不實際存盤資料的虛表,因此對視圖的更新最終要轉換為對基本表的更新
-
細節:為防止在更新視圖時出錯,定義視圖時要加上WITH CHECK OPTION子句
-
例子1(修改資料):
-
-
例子2(插入資料):
-

-
例子3(洗掉資料):
-

-
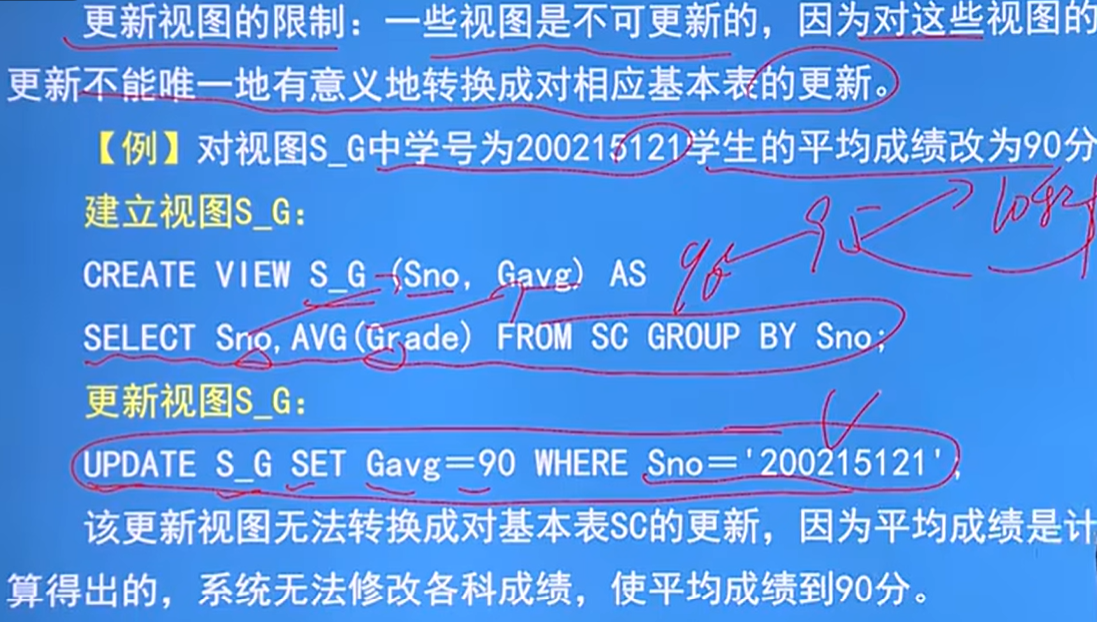
更新視圖的限制:一些視圖是不可以更新的,因為對這些視圖的更新不能唯一的有意義的轉換成對應基本表的更新
-
-
-
3.7.4 視圖的作用:
-
視圖能夠簡化用戶的操作
- 如:我只看資訊系的學生資訊,就可以創建一個視圖,不然每次要去基本表查看
-
視圖使用用戶能以多種角度看待同一資料
- 如:理解:不同的應用可能用到同一個資料
-
視圖對重構資料庫提供了一定程度的邏輯獨立性
-
如:就是基本表和視圖是映射關系,基本表變視圖就會變
-
-
視圖能夠對機密資料提供安全保護
- 如:基本表中的的身份證資訊是不想給別人看的,就可以把其它可以看的放到視圖,然后授權給別人看
-
適當的利用視圖可以更清晰的表達查詢
-
如:可以省略一些查詢條件判斷
-
-

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/519322.html
標籤:SQL Server
上一篇:京東云開發者| Redis資料結構(二)-List、Hash、Set及Sorted Set的結構實作
下一篇:第三章-標準SQL陳述句