1 引言
之前介紹了Redis的資料存盤及String型別的實作,接下來再來看下List、Hash、Set及Sorted Set的資料結構的實作,
2 List
List型別通常被用作異步訊息佇列、文章串列查詢等;存盤有序可重復資料或做為簡單的訊息推送機制時,可以使用Redis的List型別,對于這些資料的存盤通常會使用鏈表或者陣列作為存盤結構,
- 使用陣列存盤,隨機訪問節點通過索引定位時間復雜度為O(1),但在初始化時需要分配連續的記憶體空間;在增加資料時,如果超過當前分配空間,需要將資料整體搬遷移到新陣列中,
- 使用鏈表存盤,在進行前序遍歷或后續遍歷,當前節點中要存盤前指標和后指標,這兩個指標在分別需要8byte共16byte空間存盤,存在大量節點會因指標占用過多空間,鏈表雖然不需要連續空間存盤可以提高記憶體利用率,但頻繁的增加和洗掉操作會使記憶體碎片化,影響資料讀寫速率,
如果我們能夠將鏈表和陣列的特點結合起來就能夠很好處理List型別的資料存盤,
2.1 ZipList
3.2之前Redis使用的是ZipList,具體結構如下:
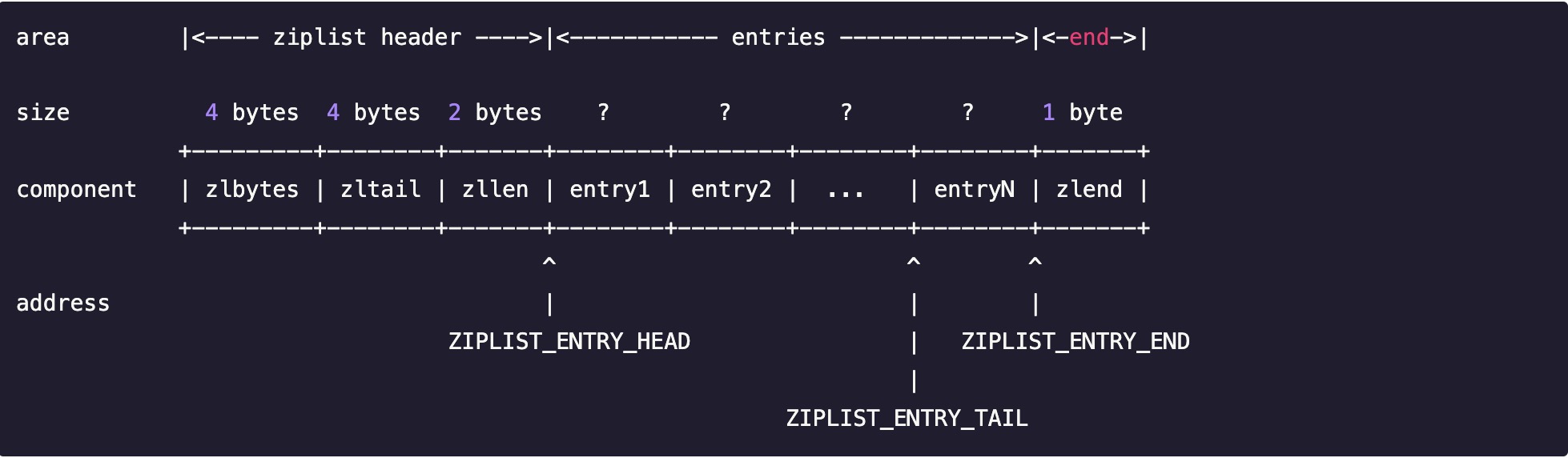
- zlbytes: 4byte 記錄整個壓縮串列占用的記憶體位元組數:在對壓縮串列進行記憶體重分配, 或者計算 zlend 的位置時使用,
- zltail:4byte 記錄壓縮串列表尾節點距離壓縮串列的起始地址有多少位元組: 通過這個偏移量,程式無須遍歷整個壓縮串列就可以確定表尾節點的地址,
- zllen:2byte 記錄了壓縮串列包含的節點數量: 當這個屬性的值小于 UINT16_MAX(65535)時, 這個屬性的值就是壓縮串列包含節點的數量; 當這個值等于UINT16_MAX 時,節點的真實數量需要遍歷整個壓縮串列才能計算得出,
- entry X:壓縮串列包含的各個節點,節點的長度由節點保存的內容決定,包含屬性如下:
- prerawlen:記錄前一個節點所占記憶體的位元組數,方便查找上一個元素地址
- len:data根據len的首個byte選用不同的資料型別來存盤data
- data:本元素的資訊
- zlend: 尾節點 恒等于255
ziplist是一個連續的記憶體塊,由表頭、若干個entry節點和壓縮串列尾部識別符號zlend組成,通過一系列編碼規則,提高記憶體的利用率,使用于存盤整數和短字串,每次增加和洗掉資料時,所有資料都在同一個ziplist中都會進行搬移操作,如果將一個組資料按閾值進行拆分出多個資料,就能保證每次只操作某一個ziplist,3.2之后使用的quicklist與ziplist,
2.2 QuickList
quicklist就是維護了一種宏觀上的雙端鏈表(類似于B樹),鏈表的節點為對ziplist包裝的quicklistNode,每個quciklistNode都會通過前后指標相互指向,quicklist包含頭、尾quicklistNode的指標,
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
...
} quicklist;
- *head:表頭節點
- *tail:表尾節點
- count:節點包含entries數量
- len:quicklistNode節點計數器
- fill:保存ziplist的大小,組態檔設定
- compress:保存壓縮程度值,組態檔設定
quicklistNode:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
,,,
} quicklistNode;
- *prev:前置節點
- *next:后置節點
- *zl:不進行壓縮時指向一個ziplist結構,壓縮時指向quicklistLZF結構(具體內容請參考下方鏈接)
- sz:ziplist個數
- count:ziplist中包含的節點數
在redis.conf通過設定每個ziplist的最大容量,quicklist的資料壓縮范圍,提升資料存取效率,單個ziplist節點最大能存盤量,超過則進行分裂,將資料存盤在新的ziplist節點中
-5: max size: 64 Kb <— not recommended for normal workloads
-4: max size: 32 Kb <— not recommended
-3: max size: 16 Kb <— probably not recommended
-2: max size: 8 Kb <— good
-1: max size: 4 Kb <— good
List-max-ziplist-size -2
0代表所有節點,都不進行壓縮,1.代表從頭節點往后一個,尾結點往前一個不用壓縮,其它值以此類推
List-compress-depth 1
Redis 的鏈表實作的特性可以總結如下:
- 雙端:鏈表節點帶有prev和next指標, 獲取某個節點的前置節點和后置節點的復雜度都是O(1) ,
- 無環:表頭節點的prev指標和表尾節點的next指標都指向NULL,對鏈表的訪問以NULL為終點,
- 帶表頭指標和表尾指標:通過list結構的head指標和tail指標,程式獲取鏈表的表頭節點和表尾節點的復雜度為O(1) ,
- 帶鏈表長度計數器:程式使用list結構的len屬性來對list持有的鏈表節點進行計數,程式獲取鏈表中節點數量的復雜度為O(1),
3 Hash
存盤一個物件,可以直接將該物件進行序列化后使用String型別存盤,再通過反序列化獲取物件,對于只需要獲取物件的某個屬性的場景,可以將將每個屬性分別存盤;但這樣在Redis的dict中就會存在大量的key,對于鍵時效后的回收效率存在很大影響,使用Map結構就可以再dict的存盤中只存在一個key并將屬性與值再做關聯,
Redis的Hash資料結構也是使用的dict(具體實作可以查看上一篇,淺談Redis資料結構(上)-Redis資料存盤及String型別的實作)實作,當資料量比較小,或者單個元素比較小時,底層使用ziplist存盤,資料量大小和元素數量有如下配置:

ziplist元素個數超過512,將改為hashtable編碼
hash-max-ziplist-entries 512
單個元素大小超過64byte時,將改為hashtable編碼
hash-max-ziplist-value 64

4 Set
Set型別可以在對不重復集合操作時使用,可以判斷元素是否存在于集合中,Set資料結構底層實作為value為null的dict,當資料可以使用整形表示時,Set集合將被編碼為intset結構,
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
整數集合是一個有序的,存盤整型資料的結構,整型集合在Redis中可以保存xxxx的整型資料,并且可以保證集合中不會出現重復資料,

使用intset可以節省空間,會根據最大元素范圍確定所有元素型別;元素有序存盤在判斷某個元素是否存在時可以基于二分查找,但在以下任意條件不滿足時將會使用hashtable存盤資料,
- 元素個數大于配置的set-max-inset-entries值
- 元素無法用整型表示

5 Sorted Set
連續空間存盤資料,每次增加資料都會對全量資料進行搬運,對于有序鏈表查找指定元素,只能通過頭、尾節點遍歷方式進行查找,如果將每個資料增加不定層數的索引,索引之間相互關聯,尋找指定或范圍的元素時就可以通過遍歷層級的索引來確定元素所處范圍,減少空間復雜度,跳躍表是一種可以對有序鏈表進行近似二分查找的資料結構,redis 在兩個地方用到了跳躍表,一個是實作有序集合,另一個是在集群節點中用作內部資料結構,
跳躍表 ( skiplist ) 是一種有序資料結構,自動去重的集合資料型別,ZSet資料結構底層實作為字典(dict) + 跳表(skiplist),它通過在每個節點中維持多個指向其他節點的指標,從而達到快速訪問節點的目的,支持平均O ( logN ) 、最壞 O(N) 復雜度的節點查找,還可以通過順序性操作來批量處理節點,
資料比較少時,用ziplist編碼結構存盤,包含的元素數量比較多,又或者有序集合中元素的成員(member) 是比較長的字串時,Redis 就會使用跳躍表來作為有序集合鍵的底層實作,
元素個數超過128,將用skiplist編碼
zset-max-ziplist-entries 128
單個元素大小超過64 byte,將用skiplist編碼
zset-max-ziplist-value 64
5.1 跳躍表
zset結構如下:
typedef struct zset {
// 字典,存盤資料元素
dict *dict;
// 跳躍表,實作范圍查找
zskiplist *zsl;
} zset;
robj *createZsetObject(void) {
// 分配空間
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// dict用來查詢資料到分數的對應關系,zscore可以直接根據元素拿到分值
zs->dict = dictCreate(&zsetDictType,NULL);
// 創建skiplist
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
zskiplist
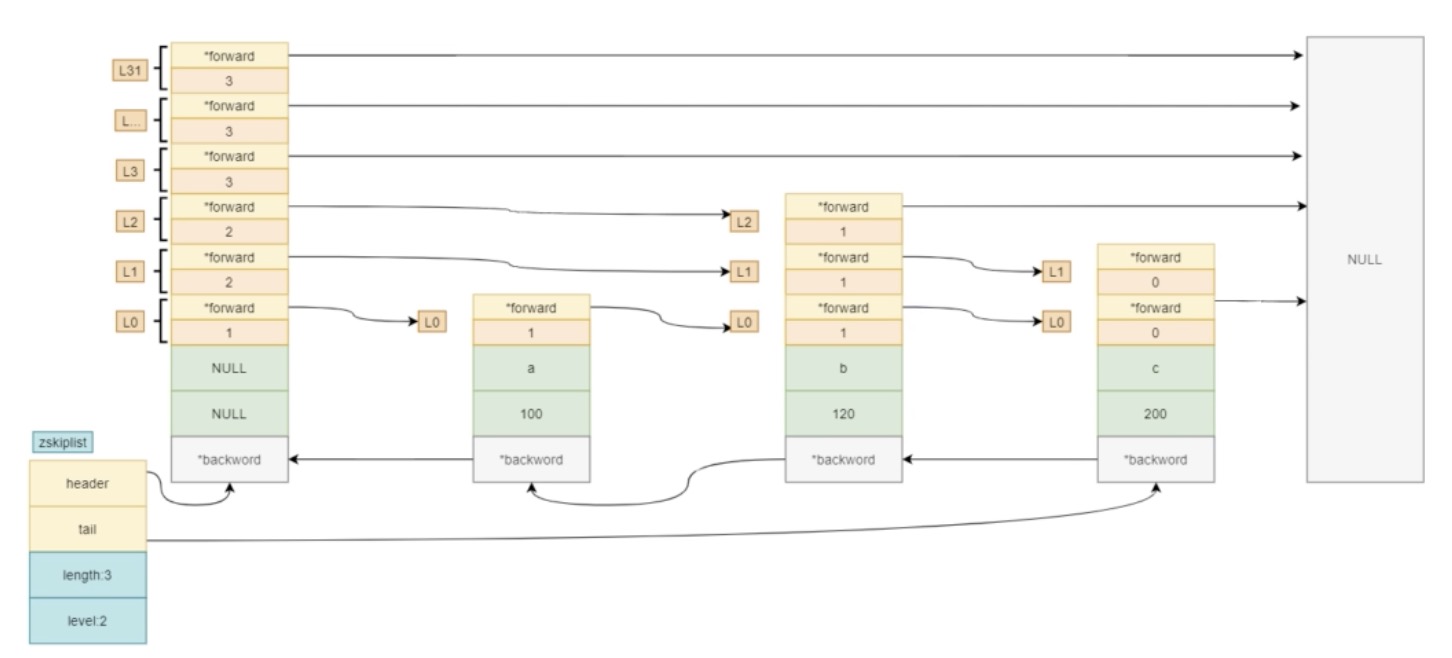
typedef struct zskiplist {
// 頭、尾節點;頭節點不存盤元素,擁有最高層高
struct zskiplistNode *header, *tail;
unsigned long length;
// 層級,所有節點中的最高層高
int level;
} zskiplist;
typedef struct zskiplistNode {
// 元素member值
sds ele;
// 分值
double score;
// 后退指標
struct zskiplistNode *backward;
// 節點中用 L1、L2、L3 等字樣標記節點的各個層, L1代表第一層, L2代表第二層,以此類推,
struct zskiplistLevel {
// 指向本層下一個節點,尾節點指向null
struct zskiplistNode *forward;
// *forward指向的節點與本節點之間的元素個數,span值越大,跳過的節點個數越多
unsigned long span;
} level[];
} zskiplistNode;
結構圖如下:
5.2 創建節點及插入流程
SkipList初始化,創建一個有最高層級的空節點:
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 分配空間
zsl = zmalloc(sizeof(*zsl));
// 設定起始層次
zsl->level = 1;
// 元素個數
zsl->length = 0;
// 初始化表頭,表頭不存盤元素,擁有最高的層級
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 初始化層高
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
// 設定表頭后退指標為NULL
zsl->header->backward = NULL;
// 初始表尾為NULL
zsl->tail = NULL;
return zsl;
}
新增元素:
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
// 遍歷所有層高,尋找插入點:高位 -> 低位
for (i = zsl->level-1; i >= 0; i--) {
// 存盤排位,便于更新
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
// 找到第一個比新分值大的節點,前面一個位置即是插入點
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
// 相同分值則按字典順序排序
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
// 累加跨度
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
// 每一層的拐點
update[i] = x;
}
// 隨機生成層高,以25%的概率決定是否出現下一層,越高的層出現概率越低
level = zslRandomLevel();
// 隨機層高大于當前的最大層高,則初始化新的層高
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
// 創建新的節點
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
// 插入新節點,將新節點的當前層前指標更新為被修改節點的前指標
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
// 新節點跨度為后一節點的跨度 - 兩個節點之間的跨度
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
// 新節點加入,更新頂層 span
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 更新后退指標和尾指標
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x
}
5.3 SkipList與平衡樹的比較
skiplist是為了實作sorted set相關功能,紅黑樹也能實作,并且sorted set會存盤更多的冗余資料,Redis作者antirez曾回答過這個問題,原文見https://news.ycombinator.com/item?id=1171423

大致內容如下:
skiplist只需要調整下節點到更高level的概率,就可以做到比B樹更少的記憶體消耗,
sorted set面對大量的zrange和zreverange操作,作為單鏈表遍歷的實作性能不亞于其它的平衡樹,
實作比較簡單,
6 參考學習
- 《Redis 設計與實作》:https://www.w3cschool.cn/hdclil/cnv2lozt.html
- 雙端串列:https://blog.csdn.net/qq_20853741/article/details/111946054
作者:盛旭
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/519328.html
標籤:其他