摘要:華為云資料庫創新Lab在論文《MARINA: An MLP-Attention Model for Multivariate Time-Series Analysis》中提出了華為自研的自回歸時序神經網路模型,可用于時序資料的預測以及例外檢測,
本文分享自華為云社區《CIKM'22 MARINA論文解讀》,作者: 云資料庫創新Lab ,
華為云資料庫創新Lab在論文《MARINA: An MLP-Attention Model for Multivariate Time-Series Analysis》中提出了華為自研的自回歸時序神經網路模型,可用于時序資料的預測以及例外檢測,本文發表在CIKM'22上,CIKM會議是由美國計算機協會(ACM)組織的、資料挖掘領域的頂級國際學識訓議,該會議與2022年10月17日到21日在美國佐治亞州亞特蘭大召開,
論文鏈接:https://dl.acm.org/doi/pdf/10.1145/3511808.3557386
背景
近年來,隨著物聯網(IoT)以及智能運維(AIOps)等新興業務的興起,時序資料在資料分析領域逐漸成為了一種主要的資料型別,在IoT場景,一個系統的各個組件中會實時產生監控時序資料,例如工廠鍋爐的壓力,溫度傳感器都會實時上傳對應的壓力溫度資料,飛機的高度,速度傳感器也會記錄相應的時序資料,同時在AIOps場景,一個云服務集群也會實時上傳虛擬機的CPU, MEM, disk usage等關鍵指標作為系統健康度,系統負載的評價標準,
一般來說時序資料具有以下兩個特點:體量巨大,資訊密度低,以云系統監控為例,一臺虛擬機的指標檢測數量一般在幾十的數量級,一個region的云監控時間線上報量可以達到上億的級別,一星期的時序資料存盤量就可以超過10TB,另一方面,絕大部分云監控資料都是穩定不變或者是小范圍變化的,只有極少資料是大范圍波動,甚至有例外的,因此從海量的時序資料中發掘有意義的資訊是非常巨大的挑戰,
鑒于時序資料的特點,人工從大量時序資料中發掘有效資訊是不可行的,近年來,工業界和高校都投入了很多人力去研究自動化的時序分析演算法,時序分析包含時序預測,例外檢測,分類,聚類,特征提取等多個方向,本文主要關注的是預測和例外檢測兩個方面,
問題描述
本文主要關注的是時序預測和例外檢測,下面是對這兩個問題簡單的數學化描述,
多維時序預測:

多維例外檢測:

采用基于預測的例外檢測的好處是可以統一利用預測神經網路同時解決預測和例外檢測的問題,
問題思考
基于以上的問題定義后,本文專注于設計預測演算法,預測演算法需要考慮到以下三個要點才能做到預測準確:
時間相關性
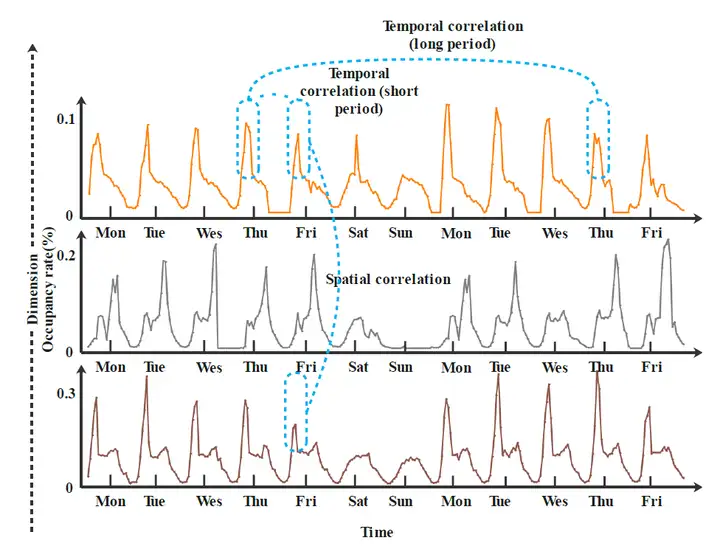
時間相關性指多維時間序列中,同一維度的資料點前后時間的相關性,從宏觀上體現在該維度的周期性和趨勢性,以下圖為例,下圖是加州灣區的三條道路擁堵程度的時序資料,可以清楚的看到,每一個維度都存在明顯的周期性,這種周期性即被歸為時間相關性,
空間相關性
空間相關性指的是多維時間序列中,不同維度之間的相關性,從上圖可以看到,維度1和維度3的擁堵程度尖峰的發生時間存在很強的相似性,這種相似性在本文中被歸為空間相關性,
平穩性
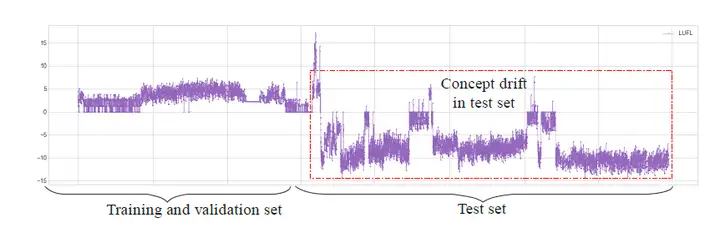
在工程實作中,平穩性一般指寬平穩或回圈平穩,即分布的均值以及自相關函式不隨時間變化或隨時間周期變化,平穩性是自回歸預測的潛在假設,當資料非平穩時,預測值可能發生巨大偏差,在時序資料中,非平穩資料是很常見的,例如下圖ETT資料集中,資料前后,均值發生較大變化,是典型非平穩資料,常見的預測演算法,例如ARIMA采取差分的方式迫使資料平穩,
演算法設計
歸一化方法設計
在設計演算法網路之前,首先需要保證網路輸入資料的平穩性,即需要限制資料輸入的波動范圍,ARIMA等演算法采取差分的方式做平穩性保證,然而,差分的方式會使噪聲疊加,增大噪聲干擾,本文提出利用動態歸一化(dynamic normalization)的方式對資料進行平穩性保證,
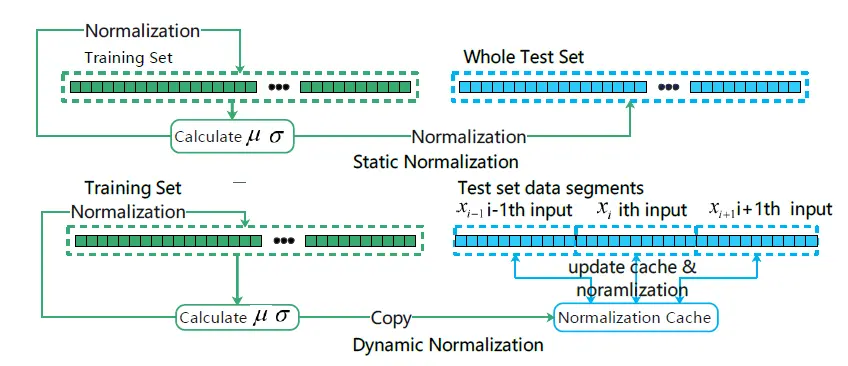
如上圖所示,一般的時序歸一化方法如上圖的上半部分所示,資料分為訓練集合測驗集兩部分,在歸一化的程序中,首先計算訓練集的均值方差,并用該均值方差歸一化訓練集自身,在測驗集上,則利用訓練集的均值方差歸一化測驗集,這種做法存在的問題是,當資料非平穩時,測驗集的值域可能合訓練集差距較大,導致測驗集上的預測結果非常差,并且此種歸一化并未考慮到時序資料的特性,在測驗集上,資料實際上是按斬訓動視窗順序輸入神經網路進行預測的,滑動視窗之前的所有資料應該被視為已知并可用于幫助后續預測,
基于以上分析,我們提出動態歸一化策略,首先,在訓練集上,動態歸一化與傳統歸一化采用相同的策略,即訓練集計算整體均值方差并用它來歸一化自己,在測驗集上,歸一化程序以網路輸入的滑動視窗為單位,如上圖下半部分所示,演算法維持一個動態的均值,方差,其初始值為訓練集的均值方差,每當一個滑動視窗的資料進入歸一化演算法,首先該演算法利用滑動視窗的資料更新當前的均值方差,并用該均值方差歸一化滑動視窗的預測輸入,該方法的好處是可以動態保證神經網路輸入資料的范圍,確保輸入資料的平穩性,同時不會引入多余噪聲,
時間相關性學習模塊
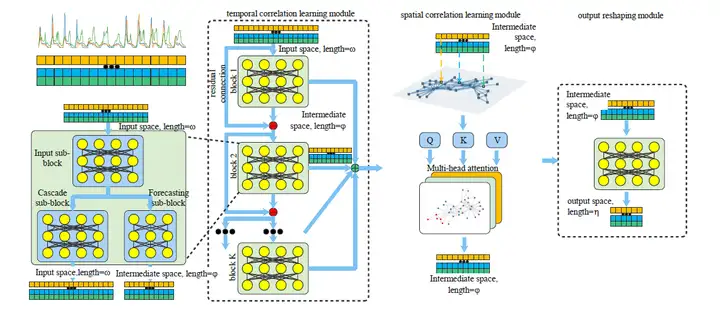
本文的預測網路結構MARINA如上圖所示,整個網路結構分為三個模塊,時間相關性模塊,空間相關性模塊,輸出整形模塊,
在時間相關性學習中,一般的備選網路結構包含MLP,RNN (GRU, LSTM),TCN,attention等結構,經過在多個資料集上的多次實驗對比,我們選擇了最高效,預測準確率最高的MLP,即全連接神經網路,為了增加網路的深度以學習到更復雜的時序波形,我們采取了殘差連接的方式,把多個MLP模塊連接到了一起,具體每個模塊之間的傳播方式可參見文中的公式3,4,5,
空間相關性模塊
需要注意的是,時間相關性模塊中,資料點資訊的傳播僅僅集中在了時間維度上,不同維度之間的資訊并沒有進行互動,在多維時間序列中,不同維度的資料常常具有相關性,利用好這些相關性可以增加預測準確度,因此,在時間相關性模塊后,我們設計了空間相關性模塊,我們把時間相關性模塊的輸出中的每一維度視為視為圖中的一個節點,并送入self-attention網路中進行空間相關性學習,在圖學習中,資訊在圖的每個節點中相互傳播,以達到學習不同維度相似性的目的,空間相關性模塊的傳播公式可以參考文中的公式6,7,8,
輸出整形模塊
預測輸出需要調整到用戶需要的長度,因此,在網路的尾部我們加入了一個輸出整形模塊,這個整形模塊由一個MLP模塊構成,對時間維度進行操作,把時間維度的長度整形到需要的長度,
實驗部分
在設計完了預處理演算法以及網路結構后,我們做了大量了的實驗來驗證我們演算法的效果,我們的實驗分為預測實驗,例外檢測實驗,消融性實驗,演算法效率實驗四部分,
預測實驗
預測實驗中,我們采用了ETT等三個資料集加上electricity資料集,
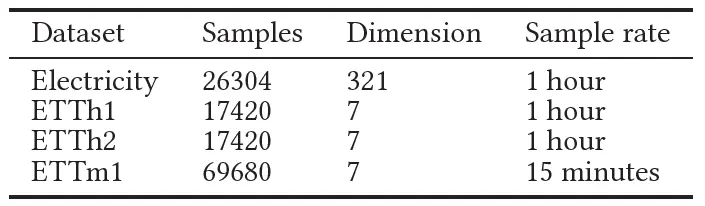
baseline我們采用了近5年中一些著名的預測演算法,例如LSTMa,Reformer, LogTrans, LSTNet, Informer, 以及HI (historical inertia),其中需要注意的是,HI是發表在CIKM2021的一個對baseline的研究,它對時間序列不做任何操作,僅僅把輸入作為輸出(當輸出長度小于輸入時則需要截斷),這樣的baseline的好處是不受任何引數影響,可以作為任意預測演算法有效性的基本驗證,
在實驗結果中,我們利用MSE, MAE兩個指標來評估演算法預測的準確度,預測長度我們測驗了端序列預測24步到長序列預測960步,粗體代表最佳結果,下劃線資料代表第二好的結果,
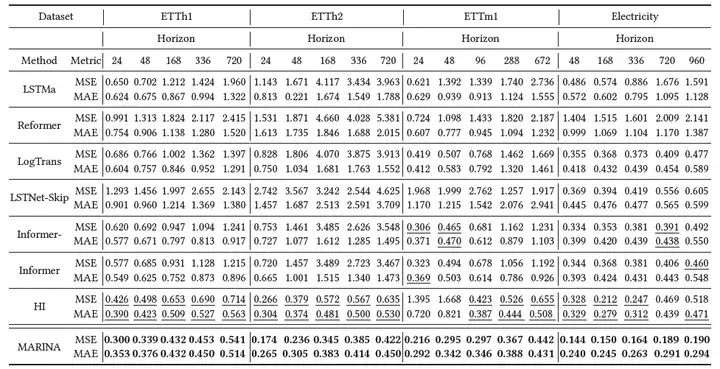
從實驗結果可以看出,在所有指標上,MARINA的性能都超過了對比演算法,值得一提的是HI演算法的性能也超過了絕大部分對比演算法,對于這一現象,我們認為是由資料導致,ETT資料集普遍都由很輕的非平穩性,以上其他的對比演算法都沒有對非平穩資料做處理,導致無法獲得合理的預測值,
例外檢測實驗
例外檢測實驗中,我們采用了SMD, SMAP, MSL以及SMAP四個經典資料集,
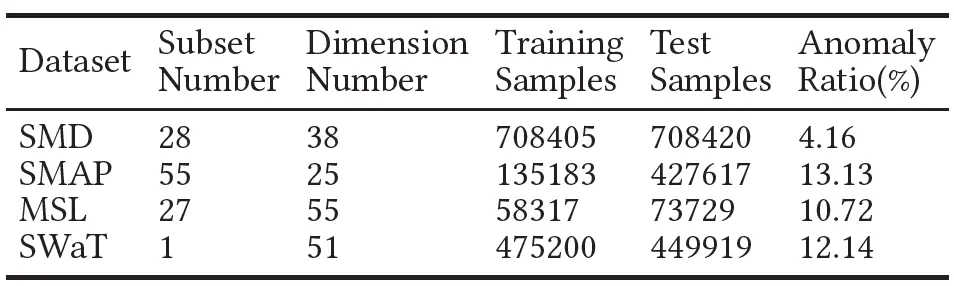
對比演算法中同樣包含了近幾年提出的著名檢測演算法,包含AE, EncDec-AD, GANomaly, LSTM-NDT, DAGMM, LSTM-VAE, BeatGan, OmniAnomaly, DAEMON演算法,
在實驗結果中,我們利用F1-score, Precision, Recall三個例外檢測的準確度,
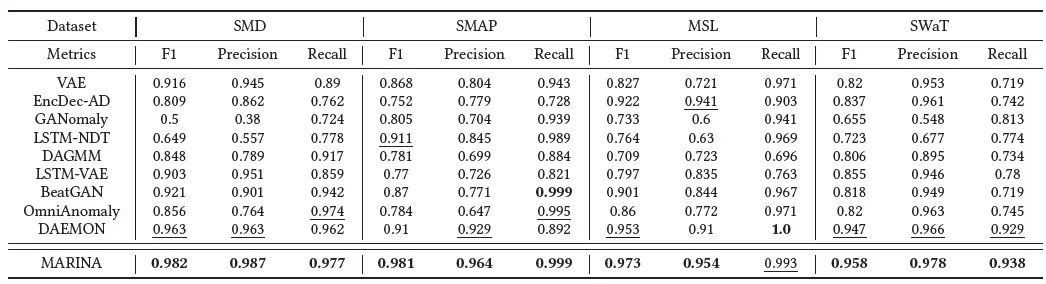
從實驗結果來看,MARINA在F1-score指標上可以擊敗所有的對比演算法,
消融性實驗
在消融性實驗中,我們考慮了歸一化策略,時間相關性模塊,空間相關性模塊對演算法預測效果的影響,
歸一化策略
在歸一化策略的消融性實驗中我們對比了演算法在ETTh1, ETTh2資料集上的預測結果,
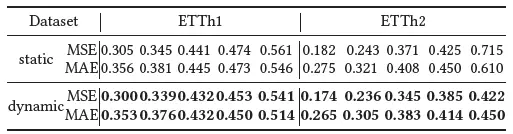
從結果中可以看出,利用動態歸一化策略的預測結果均好于用普通靜態歸一化的預測結果,這種性能提升在ETTh2資料集上尤為明顯,原因是ETTh2資料集的非平穩性更加明顯,
時間相關性模塊
為了證實MLP模塊在時間相關性學習中的有效性,我們把MLP模塊替換成了LSTM, GRU, attention, TCN四種模塊,并與MLP做對比,
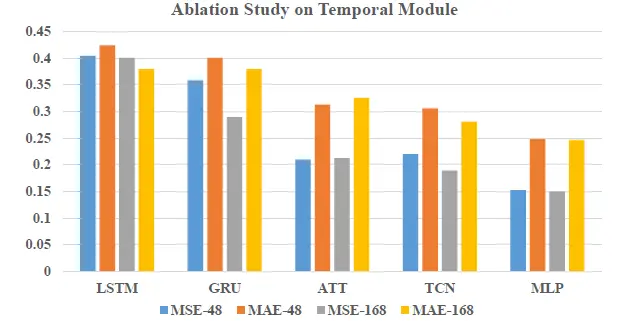
對比效果如上圖所示,其中LSTM和GRU的預測效果最差,attention, TCN效果相當,但都低于MLP的預測效果,
空間相關性模塊
空間相關性模塊的原理是讓資訊在不同維度之間傳遞以學習不同維度之間的相關性,在對比實驗中,我們對比了其余三種空間相關性模塊的實作方案:MLP網路,Mix-Hop網路,無空間相關性模塊,
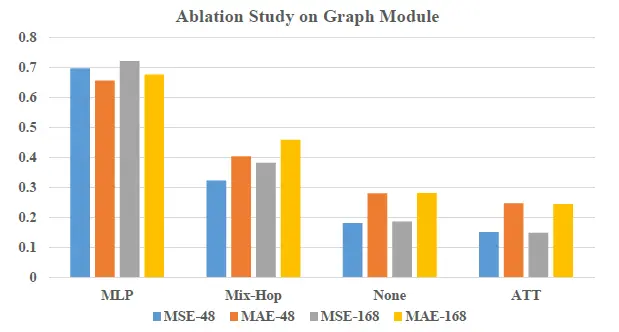
從上圖的對比效果可以看出,MLP, Mix-Hop在空間相關性學習中甚至起到了反向效果,性能比沒有空間相關性模塊還差,self-attention網路相對于無空間相關性學習性能有一定提升,
演算法效率對比
在效率對比中,我們對比了MTGNN, LSTNet, Informer, Informer-, MARINA-, MARINA的訓練+預測時間,其中MARINA-是指去掉了圖學習模塊的MARINA,一般,在有空間相關性的多維時序資料中,圖學習才能起到顯著效果,在沒有明顯相關性的多維時序資料中,可以把圖學習去掉來減少演算法訓練,檢測時間,
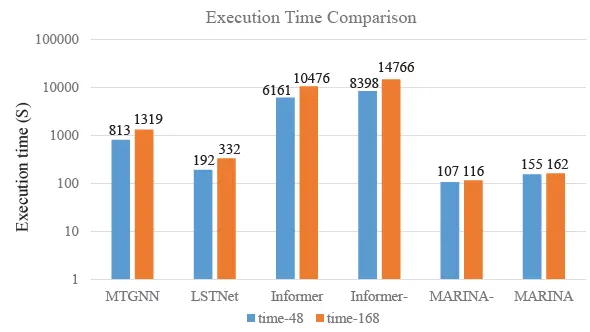
從訓練+檢測時間對比中可以看出,MARINA相比于主流演算法消耗時間最少,在所有演算法中,Informer由于其超高的復雜度,訓練檢測時間最高可以達到MARINA的100倍,
總結
在本論文中,我們提出了MARINA神經網路結構,該結構可以用于預測以及例外檢測任務,通過充分的實驗,我們可以看出,在預測和例外檢測任務上,MARINA都能達到最優的效果,且在訓練檢測效率上,MARINA也相比對比演算法能達到最高效率,由于MARINA的高效,高準確率的特點,其十分適合于云服務中海量監控時間線的場景,目前MARINA已經集成在了云資料庫創新lab的時序分析演算法庫中,
展現領先科研實力,華為云資料庫創新LAB三篇論文入選國際資料庫頂級會議VLDB’2022
華為云資料庫創新lab官網:https://www.huaweicloud.com/lab/clouddb/home.html
We Are Hiring:https://www.huaweicloud.com/lab/clouddb/career.html ,簡歷發送郵箱:[email protected]
華為云資料庫創新Lab 時序資料庫openGemini正式開源,開源地址:https://github.com/openGemini,誠邀開源領域專家加入!
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/521911.html
標籤:其他
上一篇:安裝openruler詳細步驟