通過寫SQL查詢,我們可以發現很多簡單查詢陳述句主要就是由一些算術操作、欄位操作、函式還有各種子句構成的,今天我們從這個角度對MySQL單表查詢的基礎知識進行一個匯總,
- 計算:
- 計算欄位
- 算術運算子
- 算術計算
- 欄位拼接
- 格式化顯示
- 函式:
- 統計函式
- 其他常用函式
- 子句:
- 排序
- 過濾
- 分組
- 分組過濾
- 去重
以這份模擬薪酬統計表為例
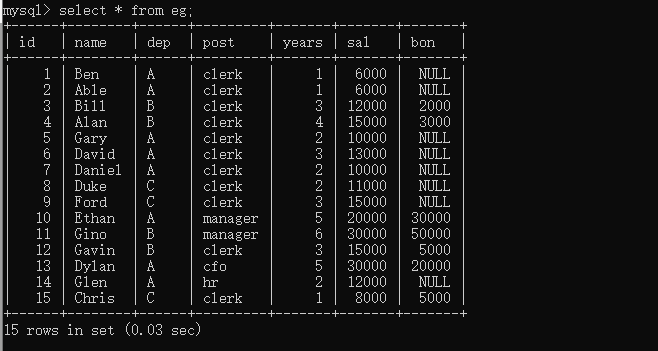
欄位解讀:
id(工號),name(員工姓名),dep(部門),post(職位),years(作業年限),sal(薪酬),bon(獎金)
計算部分
-
1.計算欄位說明
很多時候,存在資料庫表中的資料不是我們直接需要的,要進行一些計算、清洗或者格式化等操作,所以就有了計算欄位的存在,它們不實際存在于資料庫表中,是運行時在select陳述句中創建的,
-
2.算術運算子
算術運算子:+ 加法,- 減法,* 乘法,/(DIV) 除法,%(MOD) 求余
-
3.算術計算
# 統計一下CFO的年薪 select name, sal*12+bon from eg where post = 'cfo';
-
4.欄位拼接及列別名
列別名: 別名是一個欄位或者值的替換名,可以用關鍵字AS賦予(也可以省略掉AS),
在上面的例子中,如果要對計算后的年薪賦予一個名稱,修改第一行代碼即可
select name, sal*12+bon as '年薪'
下面我們看下使用concat() 函式來進行欄位拼接
# 將員工職位標注在員工名后面
select concat(name, post)
from eg;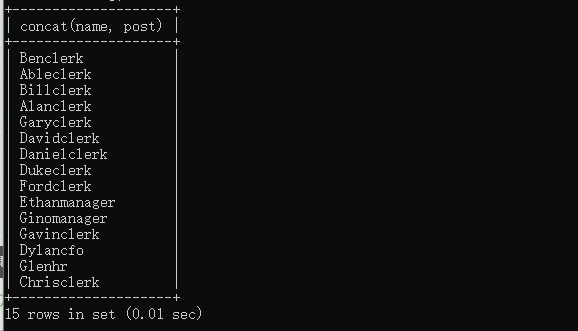
-
5.格式化顯示
上面例子是欄位的拼接,但是顯然看起來不方便,所以我們進一步看看如何進行格式化顯示,假如我們現在需要讓每個員工的崗位、年薪顯示在一起,構成一個“員工資訊”欄位
select concat('姓名:', name, '\t', '(', '崗位:', post, '\t', '年薪:', sal*12, ')') as '員工資訊'
from eg;
#這里因為有些員工獎金為null,無法有效參與計算,所以年薪的演算法一律去掉獎金部分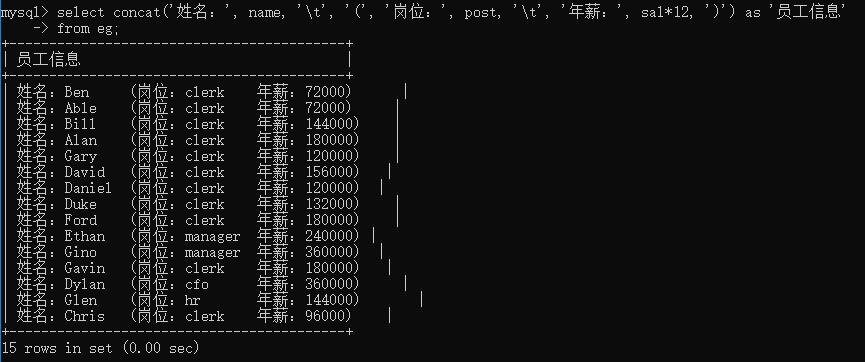
函式部分
-
1.常用統計函式
count():回傳某列的行數
avg():回傳某列的平均值
sum():回傳某列值的和
max():回傳某列最大值
min():回傳某列最小值
我們先看下這些函式的簡單應用,后面子句中還會提到
select count(id) from eg;
select avg(sal) from eg;
select sum(sal) from eg;
select max(sal) from eg;
select min(sal) from eg;
通過上面的統計資料,我們就可以對這個15人團隊的整體人力成本有一個大致了解
-
2.文本處理函式
left():回傳串左邊的字符
length():回傳串的長度
locate():找出串的一個子串
lower():將串轉換為小寫
ltrim():去掉串左邊的空格
right():回傳串右邊的字符
rtrim():去掉串右邊的字符
soundex():回傳串的soundex值
substring():回傳子串的字符
upper():將串轉換為大寫
-
3.時間日期函式
adddate():增加一個日期(天、周等)
addtime():增加一個時間(時、分等)
curdate():回傳當前日期
curtime():回傳當前時間
date():回傳日期時間的日期部分
datediff():計算兩個日期之差
date_add():高度靈活的日期運算函式
date_format():回傳一個格式化的日期或時間串
day():回傳一個日期的天數部分
dayofweek():對于一個日期,回傳對應的星期幾
hour():回傳一個時間的小時部分
minute():回傳一個時間的分鐘部分
month():回傳一個日期的月份部分
now():回傳當前日期和時間
second():回傳一個時間的秒部分
time():回傳一個日期時間的時間部分
year():回傳一個日期的年份部分
-
4.數值處理函式
abs():回傳一個數的絕對值
cos():回傳一個角度的余弦
exp():回傳一個數的指數值
mod():回傳除操作的余數
pi():回傳圓周率
rand():回傳一個亂數
sin():回傳一個角度的正弦
sqrt():回傳一個數的平方根
tan():回傳一個角度的正切
--《MySQL必知必會》上面是從《MySQL必知必會》里直接摘錄的一些常用函式,我們在這里進行一下匯總,需要的時候可以方便地參考,就不一一舉例說明了,
子句部分
-
1.MySQL語法順序
select-->from-->where-->group by-->having-->order by-->limit.
-
2.MySQL執行順序
from --> where --> group by --> having --> select --> distinct --> order by --> limit.
-
3.排序
- 基本排序
查詢到的資料一般是以在底層表中出現的順序顯示的,如果我們有排序需求,則不能以此為依賴,而是要嚴謹地使用order by子句來明確控制,
# 按照員工工齡進行排序
select name, years
from eg
order by years;- 指定排序方向
上面的操作查詢了員工姓名與工齡,并按照工齡進行排序,如果需要讓工齡越久的越靠前,我們就可以指定一下排序方向
select name, years
from eg
order by years desc;
# asc(升序)/ desc(降序),默認是升序

- 多列排序
下面我們看下如何對多個列進行排序
select name, years, sal, bon from eg order by years asc, sal desc;
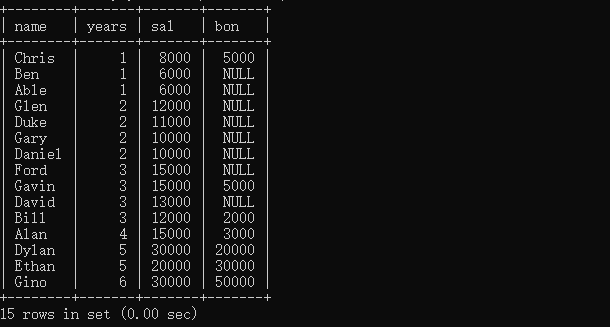
這里要注意,多列排序時,當前一列中有相同行時,才對相同行按照下一列的規則繼續啟動排序,
-
4.過濾
作業用的資料庫表中一般包含大量資料,很少會一次全部查詢,所以會使用where子句加過濾條件來查詢我們需要的資料,
-
認識運算子
- 比較運算子
=(等于),<>、!=(不等于),<(小于),<=(小于等于),>=(大于等于),>(大于),between(在指定兩個值之間)
- 邏輯運算子
and(邏輯與),or(邏輯或),in(指定條件范圍),not(邏輯非)
- 匹配運算子
like,regexp
-
單條件匹配
select name from eg where years > 3;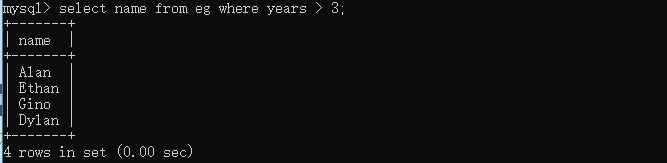
select name, years from eg where years != 1; # 不匹配查詢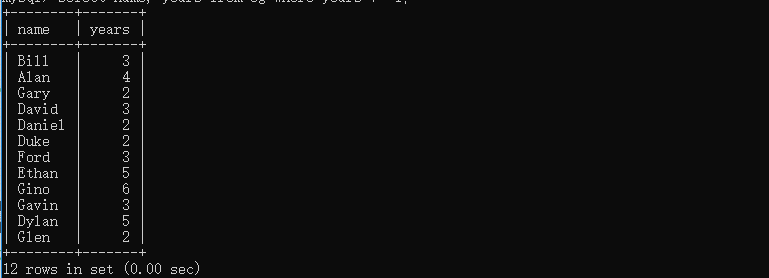
select name from eg where bon is null; # 空值查詢
-
多條件匹配
select name, post, sal from eg where post='clerk' and sal>10000;

select name, years from eg where sal between 10000 and 20000; # 范圍值查詢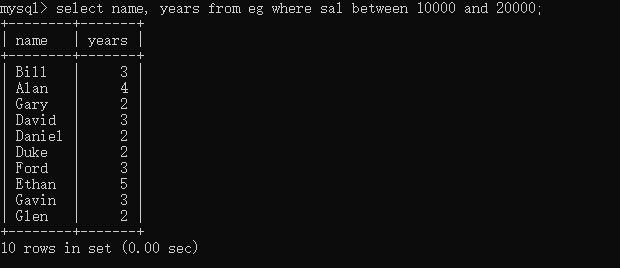
select name, years from eg where years not in (1, 3, 5); # 指定條件范圍,并進行非范圍篩選

-
搜索模式
前面提到的匹配方式都是針對已知值,但是實際情況中并不總是這樣,有時候我們需要匹配一些字面值,但是我們可能并不清楚她們的全貌,這里就需要用到搜索模式,先認識下簡單的通配符:%(任何字符出現任意次數),_(匹配單個字符),這里我們會用到like和regexp兩種運算子,一起來看下,
select name from eg where name like 'a%'; # 查詢姓名以a開頭的員工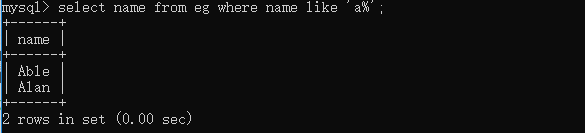 select name from eg where name like '_a%'; # 查詢姓名第二個字母為a的員工 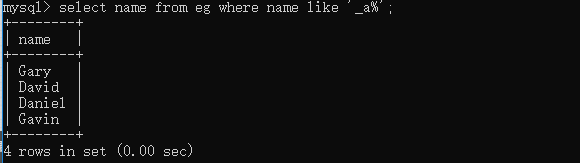 select name from eg where name like 'an'; select name from eg where name regexp 'an'; 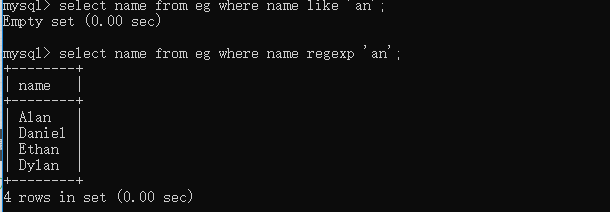 關于regexp的用法這里會涉及到正則運算式,因為正則的內容還比較多,這篇文章里我們只先做一個簡單了解,后面會在另一個專題來說明,這里我們注意一下regexp和like的一些使用區別就好,通過上面的例子我們可以看到like匹配的是整個列值,所以當'an'只在列值中出現時,like是不會回傳對應值的,而regexp操作時只要被匹配的文本在列值里出現了,那么相應值就會被回傳, -
-
5.分組
通過group by子句可以對資料進行分組,經常會和統計函式一起使用,接下來我們看下它們的具體用法,
-
基本分組
select dep, count(*) as num
from eg
group by dep; # 創建分組并按照部門統計人數
-
分組排序
select years,avg(sal) as avg_sal from eg group by years order by avg_sal desc; # 按工齡分組并分別計算平均薪資
-
多欄位分組
select dep, years, avg(sal) as dep_year_avg
from eg
group by dep, years; # 先按照部門,再按照工齡進行分組
-
-
6.分組過濾
如果我們要針對分組進行過濾,按照之前的邏輯就應該在分組后面再加上一個過濾條件,這里需要記住,group by子句后面是不可以再使用where的,這里就引出了having子句,可以用having來篩選成組后的資料,
-
分組過濾
select dep, count(*) as num
from eg
group by dep
having num > 5; # 查詢人數大于5的部門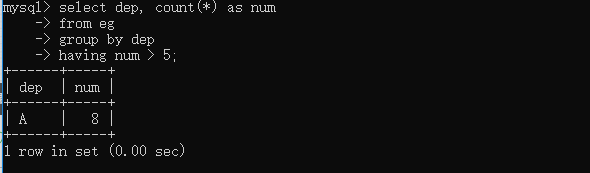
-
where和having的一些使用區別
1.where是在資料分組前進行過濾,having是在資料分組后進行過濾;
2.having可以使用欄位別名,where不可以;
3.where是直接從資料表中篩選欄位,having是從select查詢的欄位中再進行篩選,所以having后面跟的欄位一定要在前面已經出現過;
4.having可以使用統計函式,where不可以;
5.group by 子句后面只能用having,不能用where;
-
-
7.去重
有時候,我們只想知道想要的資料都有些什么不同類別,而不是全部取出它們,這個時候就需要使用關鍵字distinct對查詢到的資料進行去重處理
select distinct dep from eg; # 查詢共有多少部門
這里需要注意的是,進行去重操作時,distinct必須在所有欄位的最前面,并且它應用于所有欄位而不僅是前置它的欄位,也就是說如果distinct后面有多個欄位,只有它們組合起來的值是相等的才會被去重,看下面例子
select distinct dep, post from eg;
不過,當統計函式作為計算欄位出現時,distinct可以和統計函陣列合使用,就不一定要放在列的最前面了,舉個之前練習中遇到的例子,下面陳述句中distinct的用法也是OK的
select activity_date as day, count(distinct user_id) as active_users -
8.限制
通過條件查詢有時候符合需求的資料記錄會太多,這時可以通過limit來限制數量
select name, post
from eg
where post = 'clerk'
limit 3; # 這里指回傳不超過3行的資料
我們也可以自己定義偏移量,也就是讓它從我們想要的行數開始回傳
select name, post
from eg
where post = 'clerk'
limit 3, 3;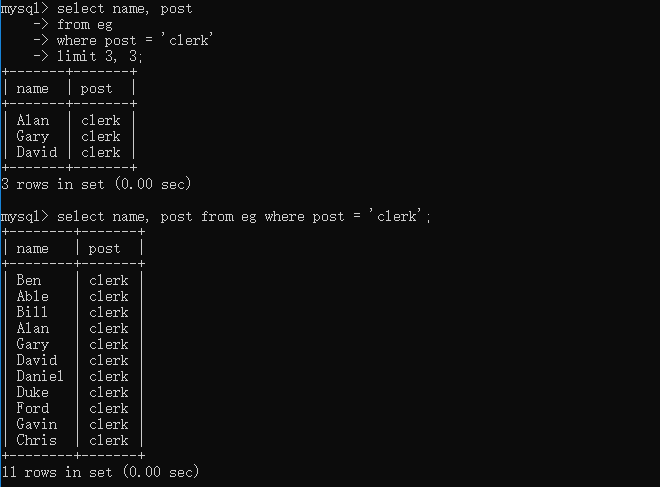
不過這里需要注意,在查詢時行數是從0算起的,所以 limit3, 3 指的是從第四行開始回傳3行資料,為了更加清晰,MySQL5還支持另一種替代語法,如下所示
select name, post
from eg
where post = 'clerk'
limit 3 offset 3;

(不過,我個人覺得前面第一種還是挺順眼的,后面這個反倒看著懵,哈哈哈哈哈~)
如果limit限制的數量大于全部數量的話,也不會報錯,會回傳全部結果,如下
select name, years
from eg
where years > 5
limit 3;
公眾號【DT派】-- 一直在路上,成為更好的人~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/52405.html
標籤:MySQL