1.mysql登陸
完整登陸命令:
mysql -u root -p xxxxx -h 127.0.0.1 -P 23306
語法:mysql -u 用戶名 -p 密碼 -h mysql服務器的IP地址 -P 使用的埠號
非完整登陸命令:
mysql -u root -p 回車(回車后再輸入密碼)
mysql -u root -p xxxxx -h 127.0.0.1 回車(回車后再輸入密碼)
2.SQL陳述句:
SQL語言共分為四大類:資料查詢語言DQL,資料操縱語言DML,資料定義語言DDL,資料控制語言DCL,
1. 資料查詢語言DQL
資料查詢語言DQL基本結構是由SELECT子句,FROM子句,WHERE
子句組成的查詢塊:
SELECT <欄位名表>
FROM <表或視圖名>
WHERE <查詢條件>
2 .資料操縱語言DML
資料操縱語言DML主要有三種形式:
1) 插入:INSERT
2) 更新:UPDATE
3) 洗掉:DELETE
3. 資料定義語言DDL
資料定義語言DDL用來創建資料庫中的各種物件-----表、視圖、
索引、同義詞、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER
| | | | |
表 視圖 索引 同義詞 簇
DDL操作是隱性提交的!不能rollback
4. 資料控制語言DCL
資料控制語言DCL用來授予或回收訪問資料庫的某種特權,并控制
資料庫操縱事務發生的時間及效果,對資料庫實行監視等,如:
1) GRANT:授權,
2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一點,
回滾---ROLLBACK
回滾命令使資料庫狀態回到上次最后提交的狀態,其格式為:
SQL>ROLLBACK;
3) COMMIT [WORK]:提交,
在資料庫的插入、洗掉和修改操作時,只有當事務在提交到資料
庫時才算完成,在事務提交前,只有操作資料庫的這個人才能有權看
到所做的事情,別人只有在最后提交完成后才可以看到,
提交資料有三種型別:顯式提交、隱式提交及自動提交,下面分
別說明這三種型別,
(1) 顯式提交
用COMMIT命令直接完成的提交為顯式提交,其格式為:
SQL>COMMIT;
(2) 隱式提交
用SQL命令間接完成的提交為隱式提交,這些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,
EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME,
(3) 自動提交
若把AUTOCOMMIT設定為ON,則在插入、修改、洗掉陳述句執行后,
系統將自動進行提交,這就是自動提交,其格式為:
SQL>SET AUTOCOMMIT ON;
注意:
①進入mysql后所有命令必須以分號(;)結尾
②如果你要查一些資料時顯示亂,螢屏寬度不夠展不開,你就在命令結尾加\G最后不要加分號,這樣顯示就會清晰了.
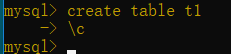
③如果輸錯命令想退出來不執行,就輸入\c回車即可,如下圖
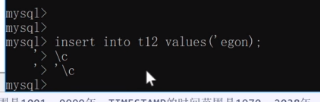
④如果少寫一個引號,直接\c是退不出來的,需要先寫'再寫\c就行了如下圖
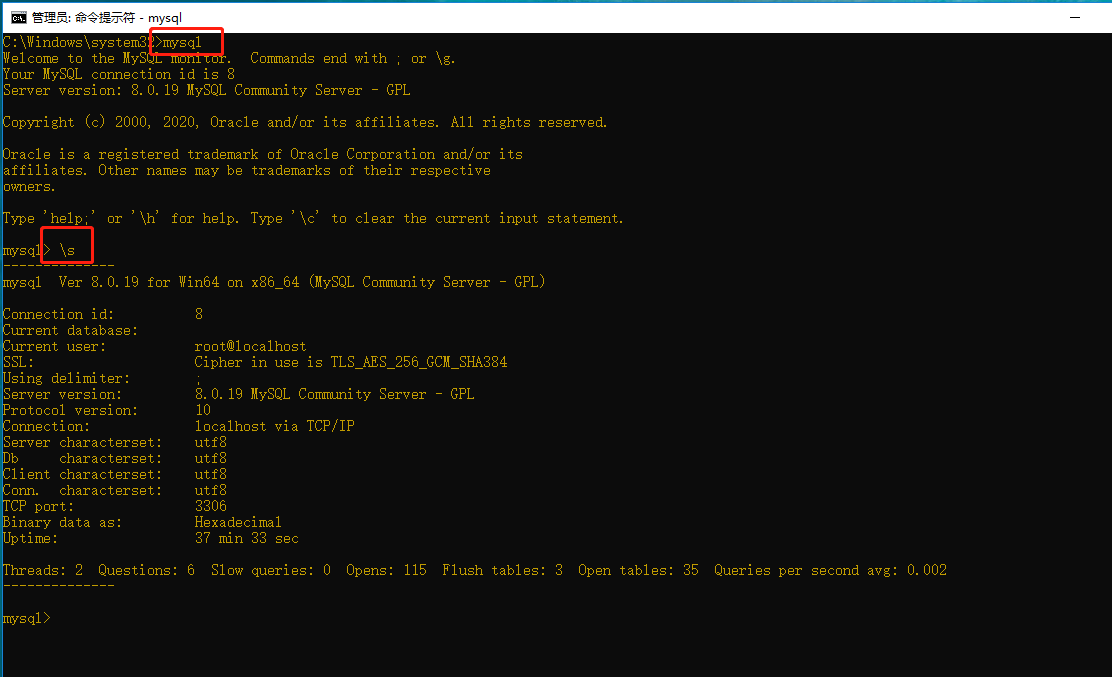
3.查看本資料庫版本與編碼集
進入資料庫后輸入\s
4.資料庫的增刪改查
資料庫的增刪改查說白了其實就是檔案夾的增刪改查
增
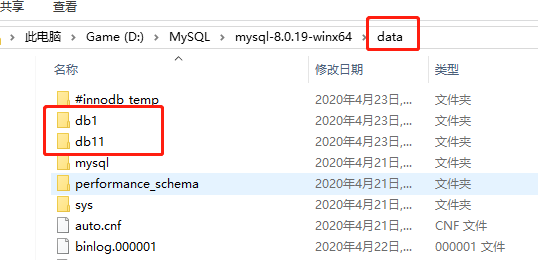
create database db1 charset utf8;(這里在創建庫時指定了編碼集)
create database db11; (不指定編碼集也可)
此時就在你安裝資料庫的檔案夾下的data檔案中新增了兩個檔案夾(db1和db11)
查看所有資料庫時,有資料庫安裝時自帶的資料庫也一并顯示出來了
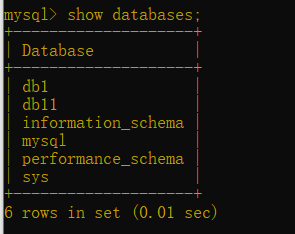
查
show create database db1;(查看剛建的資料庫的配置)
show databases;(查看所有資料庫--庫名)
查看當前所在的資料庫:select database();
由于你my.ini檔案中配置制定了編碼集,所以不指定編碼集的資料庫db11也是utf8.
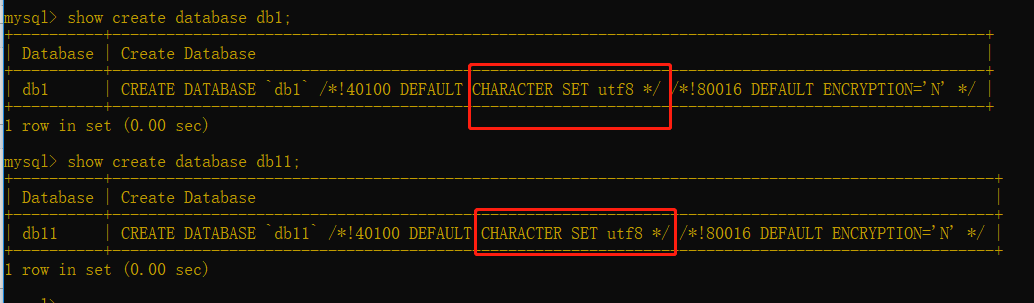
改
alter database db1 charset gbk;(將資料庫db1的編碼集改為gbk了)
切換資料庫
use +資料庫名+;
刪
drop database db1;(洗掉資料庫db1)
5.資料庫中表的增刪改查
表的增刪改查可以看做是對檔案的增刪改查
增加表時你需要先進入一個資料庫(use +資料庫名+;),增加表時就在你進入的資料庫中新增表
增
create table t1(id int,name char); 新增表t1,表中有兩個欄位id和name,id是整形,name是字串
查
show create table t1;(查看該表具體資訊)
如果沒進入資料庫你想直接查就在對應的表名前加資料庫名.
show create table db1.t1;
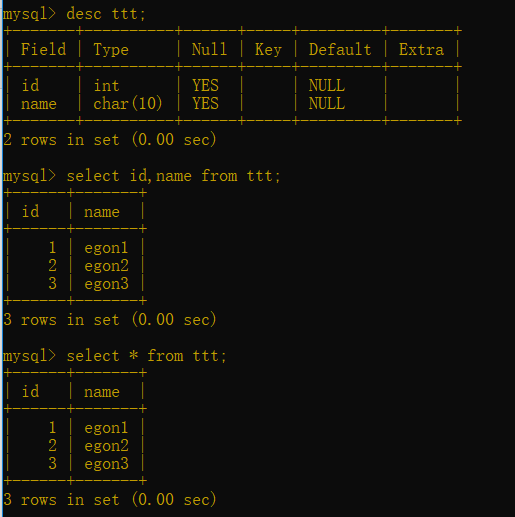
show tables;查看當前資料庫下所有表名
desc t1;查看某表中所有欄位以及欄位的屬性(desc是describe的縮寫)
select id from n; 查詢表n中id欄位的所有內容
select * from n;查詢表n中所有內容
改
alter table t1 modify name char(6);(將name欄位屬性改為字串,寬度改為6,默認寬度是1)modify是固定寫法
alter table t1 change name NAME char(7);(修改欄位名name改為NAME,并且寬度改為7)change是固定寫法新的名字NAME后面必須接新欄位的屬性,否則報錯,你可以是新的屬性也可以是原來的屬性.
修改表名:
alter table ttt rename xxx;將ttt表名改為xxx
增加欄位:
alter table xxx add n char(10) ; 在xxx表中增加一個n欄位,資料型別為char長度為10
alter table xxx add n char(10) first; 將n欄位添加到第一個欄位位置
alter table xxx add n char(10) after id; 將n欄位添加到id欄位位置的后面
刪
drop table t1;洗掉表t1
洗掉欄位:
alter table xxx drop n ;洗掉xxx表中n欄位
復制表格(可以在同資料庫但是不要重名,也可以在不同資料庫可以重名,)
①既復制表結構,又要資料:
create table t1 select host,user from mysql.user; (就是把你查到的某個表的資料select...,直接在創建表格時直接寫在后面就行了,寫在了表名后面)
create table t1 select * from db1.ttt;
②只要表結構,不要資料:
法一:就是在后面加個不成立的條件,讓他查不到對應的資料就行了,查到的內容為空就只剩表結構了
create table t1 select host,user from mysql.user where 1>2;
法二:like
create table t5 like t2;這樣就把t2的表結構復制過來創建了t5
6.行記錄(表中內容)的增刪改查
增
insert into t1(id,name) values(1,'egon1'),(2,'egon2'),(3,'egon3');(新增了3條行記錄,id為1,name為egon1...)into可以省略
insert into t1 values(1,'egon1'),(2,'egon2'),(3,'egon3');不寫欄位,默認就按照所有欄位來插入
查
select id,name from db1.ttt;(查看ti表中id和name兩個欄位)這里吧資料庫db1也加上了,其實你在db1資料庫下就不用了寫db1,直接寫表名字即可
select * from db1.ttt;查詢t1表下所有欄位
查詢某個欄位中資料的長度
select char_length(name) from t4; 查詢t4表中name欄位的內容的長度.
改
update db1.t1 set name='wwe';將t1表中所有name欄位全部寫成wwe
update db1.t1 set name='ALEX' where id=2;將id等于2的name欄位改成ALEX
刪
delete from t1;(將所有記錄全部刪,表變成空表)這個不會清空自增長的計數,delete一般都會與where連用,來固定洗掉某行記錄.
truncate t1 ;會清空自增長的計數,再插入行記錄時id會從1開始
delete from t1 where id=2;(只洗掉id=2的記錄)
7.存盤引擎
存盤引擎就是表的型別
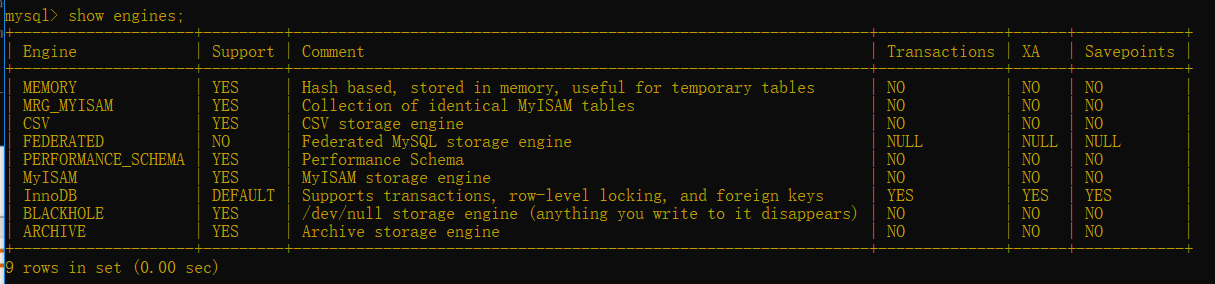
查看支持的所有存盤引擎
show engines;
或show engines\G 查的比較詳細(有\G時不加分號結尾)
創建表時指定存盤引擎:
create table t1(id int)engine=innodb;不指定默認就是innodb
8.單表查詢:
單表查詢條件順序:
書寫順序如下:
select distinct 欄位1,欄位2,欄位3 from 庫.表
①where 條件
②group by 分組條件
③having 過濾
④order by 排序欄位
⑤limit n;
distinct是去重
運行順序:
①from 庫.表(找不到表的話就不運行了)
②where
③group by
④having
⑤distinct 欄位1,欄位2,欄位3 (如果寫了distinct就先去重,再order by),這里運行的是select后面的內容,就是你要顯示的欄位內容
⑥order by
⑦limit in
執行順序寫成函式形式:
def from(db,table): f=open(r'%s\%s' %(db,table)) return f def where(condition,f): for line in f: if condition: yield line def group(lines): pass def having(group_res): pass def distinct(having_res): pass def order(distinct_res): pass def limit(order_res) pass #開始執行 def select(): f=from('db1','t1') lines=where('id>3',f) group_res=group(lines) having_res=having(group_res) distinct_res=distinct(having_res) order_res=order(distinct_res) res=limit(order_res) print(res) return res
①where(條件):會把整個表格全部查一遍
注:where用不了聚合函式,因為他是在分組(group by)之前運行
這兩句是一個意思:(between,in)
①
select name,salary from employee where salary >= 20000 and salary <= 30000;
select name,salary from employee where salary between 20000 and 30000;
②
select name,salary from employee where salary < 20000 or salary > 30000;
select name,salary from employee where salary not between 20000 and 30000;
③
select * from employee where age = 73 or age = 81 or age = 28;
select * from employee where age in (73,81,28);
select * from employee where post_comment is Null; 某欄位為空,不能寫成=' '
select * from employee where post_comment is not Null; 某欄位不為空
like模糊匹配:
select * from employee where name like "jin%"; 以jin開頭的都算上
select * from employee where name like "jin___";一個下劃線代表一個字符,不管你寫的是啥,他只匹配字符數量夠了就行,例如:jinxxx可以,但是jinqwer就不行,多了一個字符.
②group by(分組):
在group by之后都可用聚合函式
先設定:set global sql_mode="ONLY_FULL_GROUP_BY"; 設定嚴格模式,然后exit退出再進
注意:
①分組之后,只能取分組的欄位,以及每個組聚合結果,就是設定之前你分組時候可以用*獲取內容,設定后,只能取你分組的欄位或者聚合的欄位,別的欄位拿不到,寫了就報錯.
②分組之后,你可以取其他欄位,但是這個欄位一定是分組后該組最上面的一行資料,如果你要取,最好用聚合函式來取,max,min,avg等
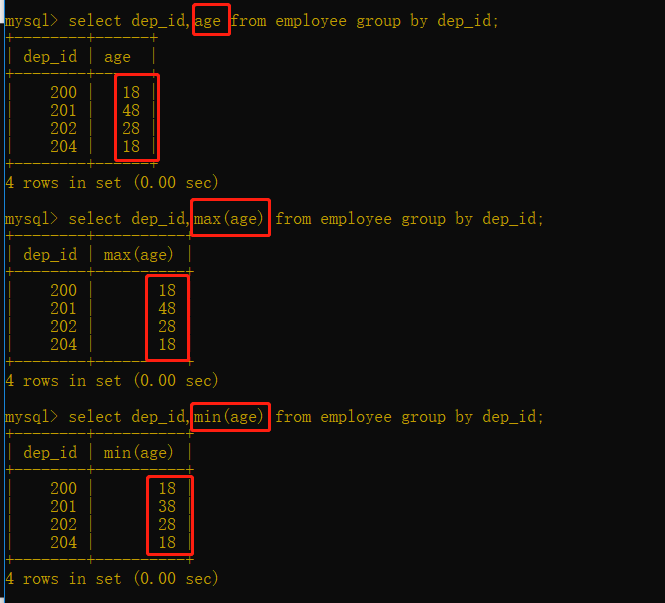
③不要用unique的欄位來分組,因為全是不一樣的,分不分沒區別
設定之前:

設定之后
聚合函式:
max 最大值
min 最小值
avg 求平均數
sum 求總和
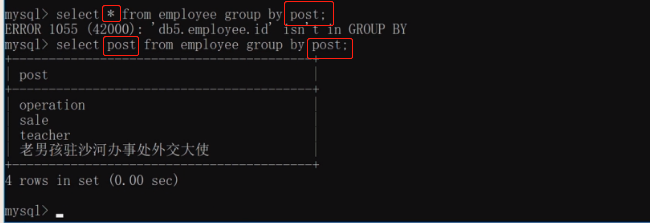
count 求數量(多少行記錄)
select post,count(id) as emp_count from employee group by post;
select post,max(salary) as emp_count from employee group by post;
select post,min(salary) as emp_count from employee group by post;
select post,avg(salary) as emp_count from employee group by post;
select post,sum(age) as emp_count from employee group by post;
沒有group by則默認整體算作一組
select max(salary) from employee;
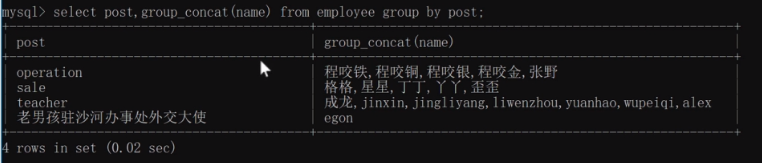
拼接group_concat:
#group_concat
select post,group_concat(name) from employee group by post;將name欄位內容按照post欄位進行分類,并寫在post分類之后
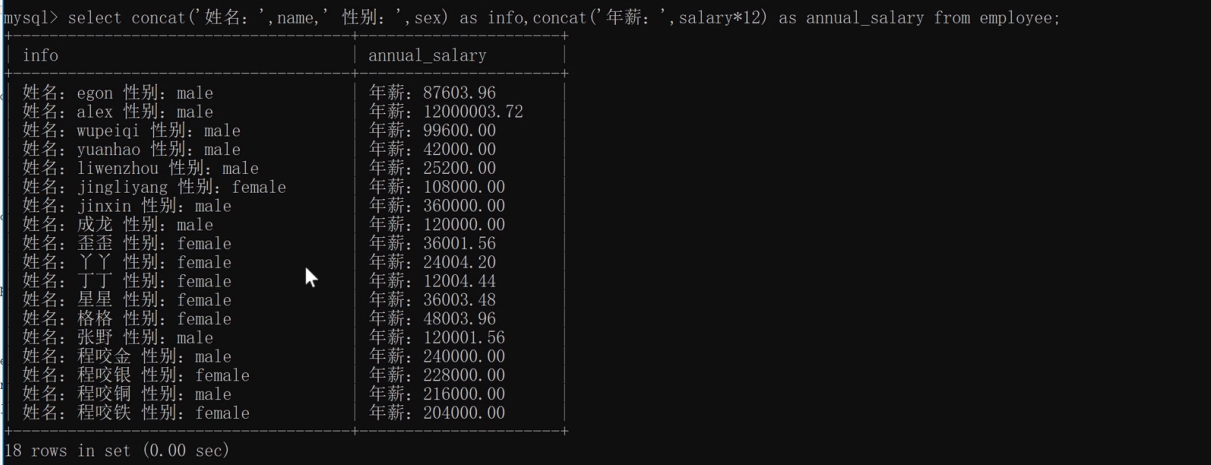
定義顯示格式:(拼接字串)用concat
select concat ('姓名:' ,name, ' 性別:',sex) as info ,concat('年薪:',salary*12) as annual_salary from employee;
顯示如下:
另一種:
select concat(name,':',sex,':'age) from employee;
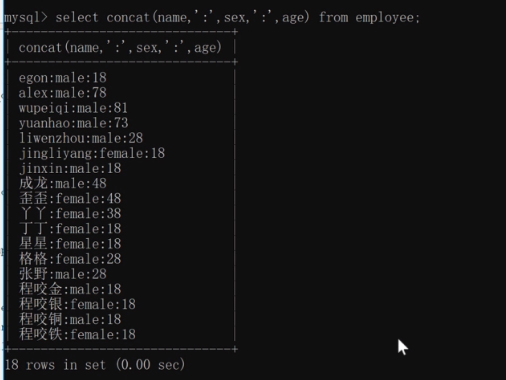
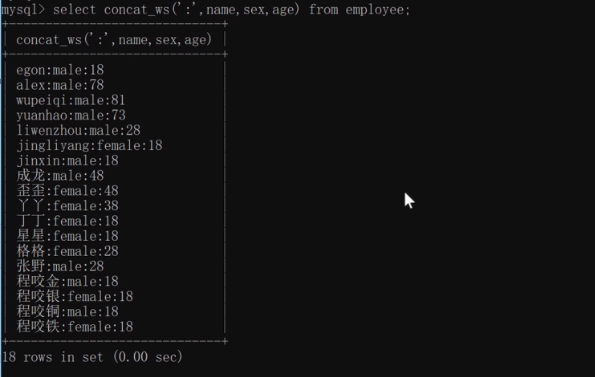
換一種寫法:用concat_ws他會在兩個欄位中間都加入相同的內容
select concat_ws(':',name,sex,age) from employee;
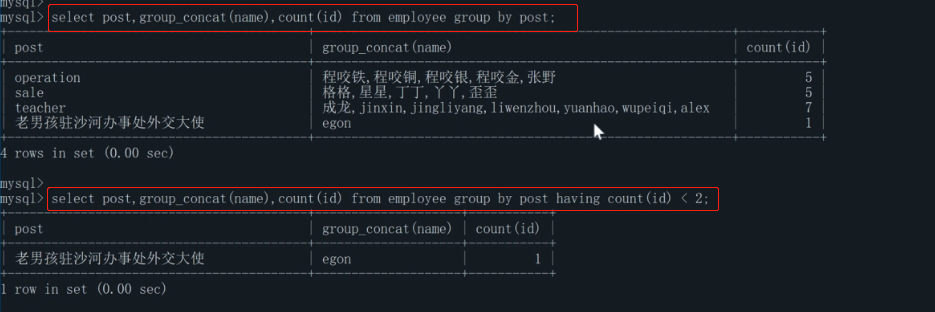
③having(過濾):
查詢各崗位包含員工個數小于2的崗位名、崗位內包含用功名字、個數
過濾后:
select post,group_concat(name),count(id) from employee group by post having count(id) < 2;
過濾前:
select post,group_concat(name),count(id) from employee group by post;
④order by(排序):
默認是升序(asc)
降序:desc
select * from employee order by age asc; #升序
select * from employee order by age desc; #降序
select * from employee order by age asc,id desc; #先按照age升序排,如果age相同則按照id降序排
⑤limit(限制顯示條數):
用法一(顯示條數):
select * from employee limit 3;只看前三條
select * from employee order by salary desc limit 1;我要看薪資最高的那個人,先倒序按照薪資排序,然后只取第一條

用法二(分頁,分段取):
但是實際作業不會僅僅用limit來做分頁,這樣取每次還都是從第一條開始數,只是取的時候按照對應的數字去取,很麻煩.
select * from employee limit 0,5;第一行開始取,一共取5行記錄,取得id是從1-5,你如果寫1,5,那取的id就是2-6
select * from employee limit 5,5;
select * from employee limit 10,5;
select * from employee limit 15,5;
注意:
limit后如果有兩個數字并且用逗號隔開,第一個數字表示從第幾行資料開始,但是不取這一行,從他下一行開始取,第二個數字表示向下取幾行.
9.簡單查詢:
select name,salary*12 from employee; 在查詢時可以進行運算,一個月工資,乘12就變成了年薪
select name,salary*12 as nianxin from employee; 在顯示時就會將salary的欄位名改為nianxin
10.正則匹配:
select * from employee where name like 'jin%'; (like是模糊匹配)
select * from employee where name regexp '^jin'; (regexp啟用正則,^表示以xxx為開頭的)
select * from employee where name regexp '^jin.*(g|n)$'; (以jin開頭,并且以g或者是n結尾的,中間字符不限制的)
11.連表查詢:
from后直接寫倆表名用逗號隔開,會出現很多重復欄位,笛卡爾積,第一張表所有行記錄都會跟第二張表每一條行記錄做對應關系
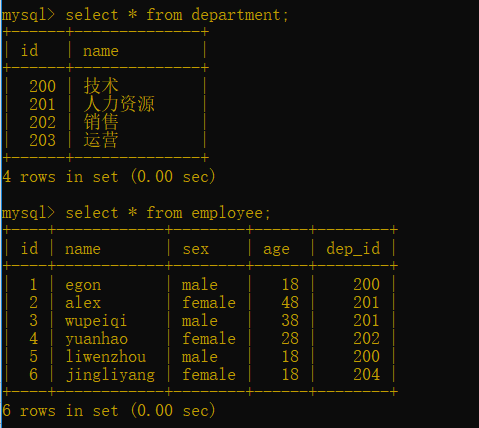
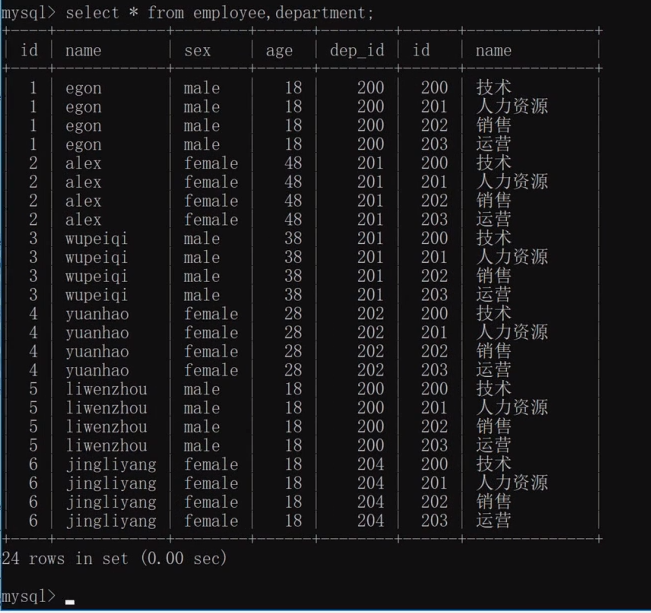
1.內連接:只取兩張表的共同部分
語法: select * from 表一 inner join 表二 on 表一.欄位 = 表二.欄位;
select * from employee inner join department on employee.dep_id = department.id ;
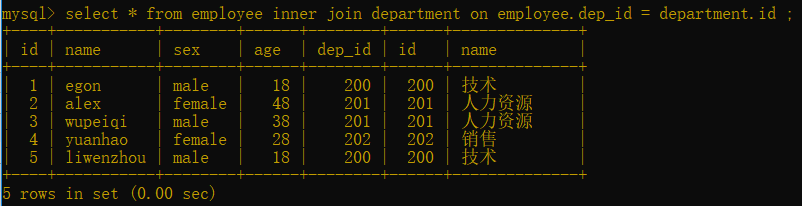
2.左連接:在內連接的基礎上保留左表的記錄
語法: select * from 表一 left join 表二 on 表一.欄位 = 表二.欄位;
select * from employee left join department on employee.dep_id = department.id ;
以左表為主,如果右表中沒有與之對應的內容就寫NULL
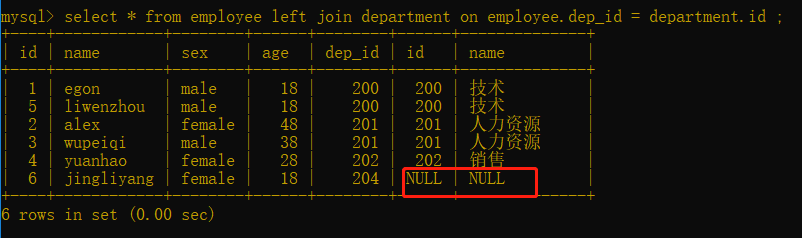
3.右連接:在內連接的基礎上保留右表的記錄(與左連接差不多)
語法: select * from 表一 right join 表二 on 表一.欄位 = 表二.欄位;
select * from employee right join department on employee.dep_id = department.id ;
以右表為主,如果左表中沒有與之對應的內容就寫NULL
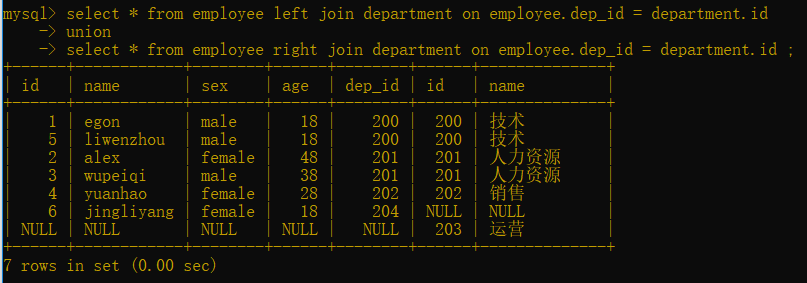
4.全外連接:在內連接的基礎上保留左右兩表沒有對應關系的記錄
錯誤寫法:mysql中沒有full
select * from employee full join department on employee.dep_id = department.id ;
正確寫法:用union連接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id ;
查一下:
平均年齡大于30歲的部門名和平均年齡
select department.name as bumen ,avg(age) as pingjunnianling from employee inner join department on employee.dep_id = department.id
group by department.name
having avg(age)>30;

注:select陳述句關鍵字定義順序
SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>
select陳述句關鍵字執行順序:
(7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_condition> (10) LIMIT <limit_number>
12.子查詢:
1:子查詢是將一個查詢陳述句嵌套在另一個查詢陳述句中, 2:內層查詢陳述句的查詢結果,可以為外層查詢陳述句提供查詢條件, 3:子查詢中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等關鍵字 4:還可以包含比較運算子:= 、 !=、> 、<等
①帶IN關鍵字的子查詢
#查詢平均年齡在25歲以上的部門名 select id,name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25); #查看技術部員工姓名 select name from employee where dep_id in (select id from department where name='技術'); #查看不足1人的部門名(子查詢得到的是有人的部門id) select name from department where id not in (select distinct dep_id from employee);
②帶比較運算子的子查詢
#比較運算子:=、!=、>、>=、<、<=、<> #查詢大于所有人平均年齡的員工名與年齡 mysql> select name,age from emp where age > (select avg(age) from emp); +---------+------+ | name | age | +---------+------+ | alex | 48 | | wupeiqi | 38 | +---------+------+ rows in set (0.00 sec) #查詢大于部門內平均年齡的員工名、年齡 select t1.name,t1.age from emp t1 inner join (select dep_id,avg(age) avg_age from emp group by dep_id) t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age;
③帶EXISTS關鍵字的子查詢
EXISTS關字鍵字表示存在,在使用EXISTS關鍵字時,內層查詢陳述句不回傳查詢的記錄,
而是回傳一個真偽值,True或False
當回傳True時,外層查詢陳述句將進行查詢;當回傳值為False時,外層查詢陳述句不進行查詢
#department表中存在dept_id=203,Ture mysql> select * from employee -> where exists -> (select id from department where id=200); +----+------------+--------+------+--------+ | id | name | sex | age | dep_id | +----+------------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | liwenzhou | male | 18 | 200 | | 6 | jingliyang | female | 18 | 204 | +----+------------+--------+------+--------+ #department表中存在dept_id=205,False mysql> select * from employee -> where exists -> (select id from department where id=204); Empty set (0.00 sec)
特殊用法(as):
select * from
(select id,name from employee) as t1;
這里是將查詢到的內容賦值給t1當做一個表格,再從這張表查詢相關內容
新建個遠程賬號,并且賦予權限:
13.存盤程序
利用存盤程序插入多條記錄.
存盤程序(類似函式) 1.準備表 create table s1( id int, name varchar(20), gender char(6), email varchar(50) ); 2.創建存盤程序,插入多條記錄 delimiter $$ #宣告存盤程序結束符號為$$ create procedure auto_insert1() #創建存盤程序,procedure為關鍵字不能變,auto_insert1為自定義的存盤程序的名字 BEGIN #開始,關鍵字 declare i int default 1; #宣告一個數字變數i默認值為1 while(i<=1000)do insert into s1 values(i,'egon','male',concat('egon',i,'@163.com')); set i=i+1; end while; END$$ #結束關鍵字加自己定義的結束符號來結束存盤程序 delimiter ; #重新宣告 ; 為結束符號,將自己定義的$$取消 3.查看存盤程序 show create procedure auto_insert1\G 4.呼叫存盤程序 call auto_insert1(); #在mysql中呼叫 cursor.callproc('auto_insert1') #在python的pymysql模塊中使用 5.查看串列的內容 select * from s1;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/52440.html
標籤:MySQL