前段時間簡單整理了一下 oracle 中使用頻率較高的幾個正則運算式,雖然是以10g為例子的,但是在其他版本中也同樣適用。
Oracle中的正則運算式離不開這4個函式:
1. regexp_like
2. regexp_substr
3. regexp_instr
4. regexp_replace
看函式名稱大概就能猜到有什么用了。
regexp_like 只能用于條件運算式,和 like 類似,但是使用的正則運算式進行匹配,語法很簡單:

regexp_substr 函式,和 substr 類似,用于拾取符合正則運算式描述的字符子串,語法如下:
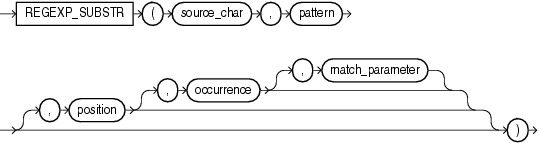
regexp_instr 函式,和 instr 類似,用于標定符合正則運算式的字符子串的開始位置,語法如下:
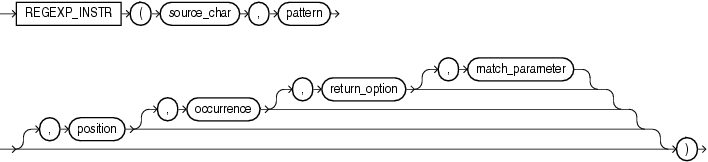
regexp_replace 函式,和 replace 類似,用于替換符合正則運算式的字串,語法如下:
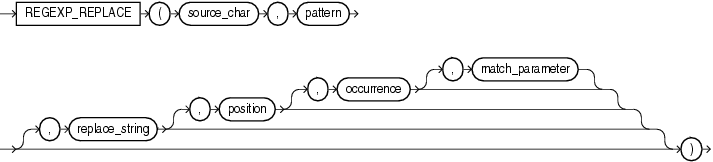
這里決議一下幾個引數的含義:
1。source_char,輸入的字串,可以是列名或者字串常量、變數。
2。pattern,正則運算式。
3。match_parameter,匹配選項。
取值范圍: i:大小寫不敏感; c:大小寫敏感;n:點號 . 不匹配換行符號;m:多行模式;x:擴展模式,忽略正則運算式中的空白字符。
4。position,標識從第幾個字符開始正則運算式匹配。
5。occurrence,標識第幾個匹配組。
6。replace_string,替換的字串。
Sql代碼
oracle 10g正則運算式 REGEXP_LIKE 用法
/*
ORACLE中的支持正則運算式的函式主要有下面四個:
1,REGEXP_LIKE :與LIKE的功能相似
2,REGEXP_INSTR :與INSTR的功能相似
3,REGEXP_SUBSTR :與SUBSTR的功能相似
4,REGEXP_REPLACE :與REPLACE的功能相似
它們在用法上與Oracle SQL 函式LIKE、INSTR、SUBSTR 和REPLACE 用法相同,
但是它們使用POSIX 正則運算式代替了老的百分號(%)和通配符(_)字符。
POSIX 正則運算式由標準的元字符(metacharacters)所構成:
'^' 匹配輸入字串的開始位置,在方括號運算式中使用,此時它表示不接受該字符集合。
'$' 匹配輸入字串的結尾位置。如果設定了 RegExp 物件的 Multiline 屬性,則 $ 也匹
配 '\n' 或 '\r'。
'.' 匹配除換行符之外的任何單字符。
'?' 匹配前面的子運算式零次或一次。
'+' 匹配前面的子運算式一次或多次。
'*' 匹配前面的子運算式零次或多次。
'|' 指明兩項之間的一個選擇。例子'^([a-z]+|[0-9]+)$'表示所有小寫字母或數字組合成的
字串。
'( )' 標記一個子運算式的開始和結束位置。
'[]' 標記一個中括號運算式。
'{m,n}' 一個精確地出現次數范圍,m=<出現次數<=n,'{m}'表示出現m次,'{m,}'表示至少
出現m次。
\num 匹配 num,其中 num 是一個正整數。對所獲取的匹配的參考。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何數字。
[[:alnum:]] 任何字母和數字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大寫字母。
[[:lower:]] 任何小寫字母。
[[:punct:]] 任何標點符號。
[[:xdigit:]] 任何16進制的數字,相當于[0-9a-fA-F]。
各種運算子的運算優先級
\轉義符
(), (?:), (?=), [] 圓括號和方括號
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和順序
|
*/
示例:
創建表并初始化資料
--創建表
create table fzq (
id varchar(4),
value varchar(10)
);
--插入資料
insert into fzq values ('1','1234560');
insert into fzq values ('2','1234560');
insert into fzq values ('3','1b3b560');
insert into fzq values ('4','abc');
insert into fzq values ('5','abcde');
insert into fzq values ('6','ADREasx');
insert into fzq values ('7','123 45');
insert into fzq values ('8','adc de');
insert into fzq values ('9','adc,.de');
insert into fzq values ('10','1B');
insert into fzq values ('10','abcbvbnb');
insert into fzq values ('11','11114560');
insert into fzq values ('11','11124560');
--提交
commit;
關于 regexp_like 和like 的驗證比較:
tbs@TICKET> select * from fzq where value like '1____60';
ID VALUE
---- ----------
1 1234560
2 1234560
3 1b3b560
tbs@TICKET> select * from fzq where regexp_like(value,'1....60');
ID VALUE
---- ----------
1 1234560
2 1234560
3 1b3b560
11 11114560
11 11124560
tbs@TICKET> select * from fzq where regexp_like(value,'1[0-9]{4}60');
ID VALUE
---- ----------
1 1234560
2 1234560
11 11114560
11 11124560
tbs@TICKET> select * from fzq where regexp_like(value,'1[[:digit:]]{4}60');
ID VALUE
---- ----------
1 1234560
2 1234560
11 11114560
11 11124560
tbs@TICKET> select * from fzq where not regexp_like(value,'^[[:digit:]]+$');
ID VALUE
---- ----------
3 1b3b560
4 abc
5 abcde
6 ADREasx
7 123 45
8 adc de
9 adc,.de
10 1B
10 abcbvbnb
已選擇9行。
tbs@TICKET> -- 查詢value中不是純數字的記錄
tbs@TICKET> select * from fzq where not regexp_like(value,'^[[:digit:]]+$');
ID VALUE
---- ----------
3 1b3b560
4 abc
5 abcde
6 ADREasx
7 123 45
8 adc de
9 adc,.de
10 1B
10 abcbvbnb
已選擇9行。
tbs@TICKET> -- 查詢value中不包含任何數字的記錄。
tbs@TICKET> select * from fzq where regexp_like(value,'^[^[:digit:]]+$');
ID VALUE
---- ----------
4 abc
5 abcde
6 ADREasx
8 adc de
9 adc,.de
10 abcbvbnb
已選擇6行。
www.2cto.com
tbs@TICKET> --查詢以12或者1b開頭的記錄.不區分大小寫。
tbs@TICKET> select * from fzq where regexp_like(value,'^1[2b]','i');
ID VALUE
---- ----------
1 1234560
2 1234560
3 1b3b560
7 123 45
10 1B
tbs@TICKET> --查詢以12或者1b開頭的記錄.區分大小寫。
tbs@TICKET> select * from fzq where regexp_like(value,'^1[2B]');
ID VALUE
---- ----------
1 1234560
2 1234560
7 123 45
10 1B
tbs@TICKET> -- 查詢資料中包含空白的記錄。
tbs@TICKET> select * from fzq where regexp_like(value,'[[:space:]]');
ID VALUE
---- ----------
7 123 45
8 adc de
tbs@TICKET> --查詢所有包含小寫字母或者數字的記錄。
tbs@TICKET> select * from fzq where regexp_like(value,'^([a-z]+|[0-9]+)$');
ID VALUE
---- ----------
1 1234560
2 1234560
4 abc
5 abcde
10 abcbvbnb
11 11114560
11 11124560
已選擇7行。
tbs@TICKET> --查詢任何包含標點符號的記錄。
tbs@TICKET> select * from fzq where regexp_like(value,'[[:punct:]]');
ID VALUE
---- ----------
9 adc,.de
tbs@TICKET>
tbs@TICKET> select * from dual where regexp_like('b', '^[abc]$');
www.2cto.com
D
-
X
tbs@TICKET>
tbs@TICKET> select * from dual where regexp_like('abc', '^[abc]$');
未選定行
tbs@TICKET>
tbs@TICKET> select * from dual where regexp_like('abc', '^a[abc]c$');
D
-
X
歡迎大家繼續補充~
uj5u.com熱心網友回復:
已推薦!
uj5u.com熱心網友回復:
學習學習
uj5u.com熱心網友回復:
這里有之前從論壇里整理的幾個例子,答案不唯一,僅供參考:1.輸入一個字串,回傳原字串每個字符間加1個空格的新串
例如:傳入 "abcde" 回傳"a b c d e"
傳入 "王小明" 回傳"王 小 明"
select regexp_replace('asdlfj','(.)','\1 ') from dual2.有一張表table1,里面兩個欄位itemid和itemname,當itemid的尾數是000000結尾時,itemname原有名稱不變;當itemid尾數為0000,且不為000000時,itemname前加兩個全角空格;其他情況下itemname前加四個全角空格。
select decode(regexp_instr(itemid,'000000$'),0,decode(regexp_instr(itemid,'0000$'),0,to_multi_byte(' ')||itemname,to_multi_byte(' ')||itemname),itemname)
from table13. 現在有一個欄位是一個大欄位,格式類似于{{{111,222,333,444,555,666},{777,888,999,aaa,bbb,ccc},{ddd,eee,fff,ggg,hhh,iii}}} 現在想要得到444,666和aaa,ccc和ggg,iii這種資料
with t as(select '{{{111,222,333,444,555,666},{777,888,999,aaa,bbb,ccc},{ddd,eee,fff,ggg,hhh,iii}}}' str from dual)
select regexp_replace(str,'{+([^,]+,){3}([^,]+,)[^,]+,([^,}]+)}+','\2\3')
from t4. select 'aaa,bbb,ccc,ddd,eee,fff' from dual
union all
select 'ddd,qqq,12,3333,42687,opqe' from dual
怎么得到倒數第二段和倒數第三段呢?
with t3 as (
select 'aaa,bbb,ccc,ddd,eee,fff' str from dual
union all
select 'ddd,qqq,12,3333,42687,opqe' str from dual)
第一種:
select rtrim(regexp_replace(str,'([^,]+,){3}(([^,]+,){2})([^,]+)','\2'),',')
from t3第二種:
select regexp_replace(str,'([^,]+,){3}([^,]+,)([^,]+),([^,]+)','\2\3')
from t3
uj5u.com熱心網友回復:
uj5u.com熱心網友回復:
select regexp_replace('asdlfj','(.)','\1 ') from dual

可以用這個就少了后面的一個空格 了
select regexp_replace('asdlfj','(.)',' \1',2) from dual
uj5u.com熱心網友回復:
ASDASASDASDuj5u.com熱心網友回復:
棒棒達,感謝樓主分享。uj5u.com熱心網友回復:
收藏,學習
uj5u.com熱心網友回復:
整理很詳細
uj5u.com熱心網友回復:
仔細看了一下,聽仔細的,我也是別人推薦看到的,我會繼續推薦的uj5u.com熱心網友回復:
oracle 11g中新增正則函式:regexp_count()regexp_count() 作為 regexp_instr() 函式的一個補充,用于計算模式字串在源串中出現的次數
函式語法如下:

對于引數 source_char,pattern,position,match_param 的含義參照上面解釋。
示例如下:
The following example shows that subexpressions parentheses in pattern are ignored:
SELECT REGEXP_COUNT('123123123123123', '(12)3', 1, 'i') REGEXP_COUNT
FROM DUAL;
REGEXP_COUNT
------------
5
In the following example, the function begins to evaluate the source string at the third character, so skips over the first occurrence of pattern:
SELECT REGEXP_COUNT('123123123123', '123', 3, 'i') COUNT FROM DUAL;
COUNT
----------
3
uj5u.com熱心網友回復:
看到使用頻率較高~~ 學習了uj5u.com熱心網友回復:

uj5u.com熱心網友回復:
增長見識了 謝謝樓主。技術就是要大家討論幾分享uj5u.com熱心網友回復:
uj5u.com熱心網友回復:
表示,呵呵,收藏了學習下uj5u.com熱心網友回復:
關注一下
uj5u.com熱心網友回復:
感謝分享!辛苦大大!uj5u.com熱心網友回復:
很好的分享,學習了!uj5u.com熱心網友回復:
學習了。56uj5u.com熱心網友回復:
很好的分享,學習學習uj5u.com熱心網友回復:
這幾個函式我記得在051中由類似的題,remark 學習下。uj5u.com熱心網友回復:
收到收到收到收到uj5u.com熱心網友回復:
很好很強大~uj5u.com熱心網友回復:
感謝分享 謝謝 學習了uj5u.com熱心網友回復:
學習,學習。uj5u.com熱心網友回復:
感 謝分享!uj5u.com熱心網友回復:
太深奧了 只能果斷收藏!!!!uj5u.com熱心網友回復:
uj5u.com熱心網友回復:
謝謝分享,很有用轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/52494.html
標籤:高級技術
上一篇:批量插入 觸發器如何實作
下一篇:oracle 分析函式手冊