Redis雖然是一個記憶體級別的快取程式,也就是redis是使用記憶體進行資料的快取的,但是其可以將記憶體的資料按照一定的策略保存到硬碟中,這樣的話就可以實作持久保存的目的;目前的話redis支持的兩種不同方式的資料持久化保存機制,分別是RDB和AOF,這兩種方式的話很類似于MySQL資料庫的dump和二進制日志的方式,
1、RBD模式
1.1、RDB模式的作業原理
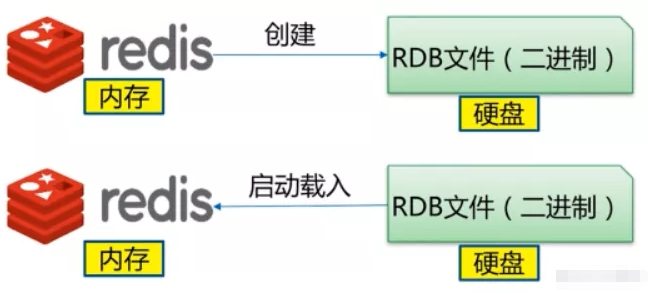
RDB(Redis DataBase):基于時間的快照,其默認只保留當前最新的一次快照,特點是執行速度比較快,缺點是可能會丟失從上次快照到當前的時間點未做快照的資料,
1.2、RDB bgsave實作快照的具體程序
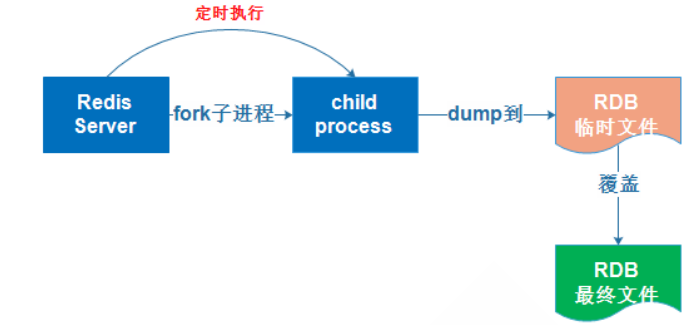
Redis從master主行程先fork出一個子行程,使用寫時復制機制,子行程將記憶體的資料保存為一個臨時檔案,比如dump.rdb,當資料保存完后在將上一次保存的RDB檔案替換掉,然后就會關掉子行程,這樣可以保證每一次做RDB快照保存的資料都是完整的;因為直接替換RDB檔案的時候,可能會出現突然斷電等問題,從而導致RDB檔案還沒有保存完整就因為突然關機停止保存,并會出現導致資料丟失的情況,后續的話是可以手動將每次生成的RDB檔案進行備份,這樣的話就可以最大化的來保存歷史資料,
1.3、RDB的相關配置
#在組態檔中的 save 選項設定多個保存條件,只有任何一個條件滿足,服務器都會自動執行 BGSAVE 命令 save 900 1 #900s內修改了1個key即觸發保存RDB save 300 10 #300s內修改了10個key即觸發保存RDB save 60 10000 #60s內修改了10000個key即觸發保存RDB dbfilename dump.rdb dir ./ #編澤編譯安裝時默認RDB檔案存放在Redis的作業目錄,此配置可指定保存的資料目錄 stop-writes-on-bgsave-error yes #當快照失敗是否仍允許寫入,yes為出錯后禁止寫入,建議為no rdbcompression yes rdbchecksum yes
1.4實作RBD的方法
- save: 同步,不推薦使用,使用主行程完成快照,因此會阻賽其它命令執行
- bgsave: 異步后臺執行,不影響其它命令的執行,會開啟獨立的子行程,因此不會阻賽其它命令執行
- 組態檔實作自動保存: 在組態檔中制定規則,自動執行bgsave
1.4、自動備份的方式
- 使用自動備份方式的話是需要在redis組態檔中指定規則,當在redis配置中規則后,觸發了規則后就會自動執行,
[root@node1 ~]#grep '^save' /apps/redis/etc/redis.conf save 900 1 #900秒內更改一條及以上資訊即自動備份 save 300 10 #300秒內更改十條及以上資訊即自動備份 save 60 10000 #60秒內更改一萬條及以上資訊即自動備份
1.5、RDB模式的優缺點
RDB模式優點:
- RDB快照保存了某個時間點的資料,可以通過腳本執行redis指令bgsave(非阻塞,后臺執行)或者save(會阻塞寫操作,不推薦)命令自定義時間點備份,可以保留多個備份,當出現問題可以恢復到不同時間點的版本,很適合備份,并且此檔案格式也支持有不少第三方工具可以進行后續的資料分析;比如: 可以在最近的24小時內,每小時備份一次RDB檔案,并且在每個月的每一天,也備份一個RDB檔案,這樣的話,即使遇上問題,也可以隨時將資料集還原到不同的版本,
- RDB可以最大化Redis的性能,父行程在保存 RDB檔案時唯一要做的就是fork出一個子行程,然后這個子行程就會處理接下來的所有保存作業,父行程無須執行任何磁盤 I/O 操作,
- RDB在大量資料,比如幾個G的資料,恢復的速度要比AOF的快,
RDB模式缺點:
- 不能實時保存資料,可能會丟失上次執行RDB備份到當前的記憶體資料,當你需要實時保存資料時,那么你就要盡量避免在服務器故障時丟失資料,這樣的話RDB就不適合使用了,雖然Redis允許設定不同的保存點(save point)來控制保存RDB檔案的頻率,但是,因為RDB檔案需要保存整個資料集的狀態,所以它并不是一個輕松快速的操作,因此一般會超過5分鐘以上才保存一次RDB檔案,在這種情況下,一旦發生故障停機,你就可能會丟失好幾分鐘的資料,
- 當資料量非常大時,從父行程fork子行程進行保存至RDB檔案是需要一點時間的,可能是毫秒或者是秒,這個是取決于磁盤的IO性能,在資料集比較龐大時,fork()可能會非常耗時,造成服務器在一定時間內停止處理客戶端﹔如果資料集非常巨大,并且CPU時間非常緊張的話,那么這種停止時間甚至可能會長達整整一秒或更久,雖然AOF重寫也需要進行fork(),但無論AOF重寫的執行間隔有多長,資料的持久性都不會有任何損失,
2、AOF模式
2.1、AOF模式作業原理

- AOF:AppendOnylFile,按照操作順序依次將操作追加到指定的日志檔案末尾
- AOF和RDB一樣使用了寫時復制機制,AOF默認為每秒鐘 fsync一次,即將執行的命令保存到AOF檔案當中,這樣即使redis服務器發生故障最多只丟失1秒鐘之內的資料,也可以設定不同的fsync策略always,即設定每次執行命令的時候執行fsync,fsync會在后臺執行執行緒,所以主執行緒可以繼續處理用戶的正常請求而不受到寫入AOF檔案的I/O影響
- 同時啟用RDB和AOF,進行恢復時,默認AOF檔案優先級高于RDB檔案,即會使用AOF檔案進行恢復
注意事項:AOF模式默認是關閉的,第一次開啟AOF后,并重啟服務生效后,會因為AOF的優先級高于RDB,而AOF默認沒有資料檔案存在,從而導致所有資料丟失,因此所以要使用正確的方法來開啟AOF,以防資料丟失,
2.2、AOF相關配置
appendonly no #是否開啟AOF日志記錄,默認redis使用的是rdb方式持久化,這種方式在許多應用中已經足夠用了,但是redis如果中途宕機,會導致可能有幾分鐘的資料丟失(取決于dump資料的間隔時間),根據save來策略進行持久化,Append Only File是另一種持久化方式,可以提供更好的持久化特性,Redis會把每次寫入的資料在接收后都寫入 appendonly.aof 檔案,每次啟動時Redis都會先把這個檔案的資料讀入記憶體里,先忽略RDB檔案,默認不啟用此功能 appendfilename "appendonly.aof" #文本檔案AOF的檔案名,存放在dir指令指定的目錄中 appendfsync everysec #aof持久化策略的配置 #no表示由作業系統保證資料同步到磁盤,Linux的默認fsync策略是30秒,最多會丟失30s的資料 #always表示每次寫入都執行fsync,以保證資料同步到磁盤,安全性高,性能較差 #everysec表示每秒執行一次fsync,可能會導致丟失這1s資料,此為默認值,也生產建議值 dir /path #rewrite相關 no-appendfsync-on-rewrite yes auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes
2.2.1動態設定(建議使用的方式)
#這時aof是沒有開啟的 [root@node1 ~]#grep '^append' /apps/redis/etc/redis6379.conf appendonly no appendfilename "appendonly.aof" appendfsync everysec #把data檔案夾所有者所有組設為redis [root@node1 ~]#ll /apps/redis/data total 1452 drwxr-xr-x 2 redis redis 4096 Nov 2 13:13 ./ drwxr-xr-x 7 redis redis 4096 Oct 31 15:41 ../ -rw-r--r-- 1 redis redis 1477882 Nov 2 13:13 dump6379.rdb [root@node1 ~]#systemctl restart redis6379.service #進入客戶端設定 [root@node1 ~]#redis-cli -a 123456 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 127.0.0.1:6379> dbsize (integer) 100000 127.0.0.1:6379> config get appendonly 1) "appendonly" 2) "no" 127.0.0.1:6379> config set appendonly yes OK 127.0.0.1:6379> config get appendonly 1) "appendonly" 2) "yes"
2.3、AOF rewrite重寫
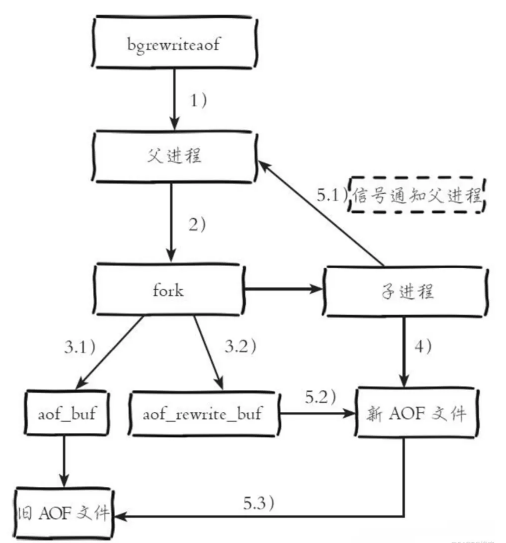
?將一些重復的、可以合并的、過期的資料重新寫入一個新的AOF檔案,這樣的話可以節約AOF備份占用的硬碟空間,也是可以加速恢復程序,可以手動執行bgrewriteaof觸發AOF,第一次開啟AOF功能,或定義自動rewrite策略,
2.4、AOF模式的優缺點
AOF模式的優點:
- 資料安全性相對較高,根據所使用的fsync策略(fsync是同步記憶體中redis所有已經修改的檔案到存盤設備),默認是appendfsync everysec,即每秒執行一次fsync,在這種配置下,Redis仍然可以保持良好的性能,并且就算發生故障停機,也最多只會丟失一秒鐘的資料(fsync會在后臺執行緒執行,所以主執行緒可以繼續努力地處理命令請求)
- 由于該機制對日志檔案的寫入操作采用的是append模式,因此在寫入程序中不需要seek, 即使出現宕機現象,也不會破壞日志檔案中已經存在的內容,然而如果本次操作只是寫入了一半資料就出現了系統崩潰問題,不用擔心,在Redis下一次啟動之前,可以通過redis-check-aof工具來解決資料一致性的問題,
-
Redis可以在AOF檔案體積變得過大時,自動地在后臺對AOF進行重寫,重寫后的新AOF檔案包含了恢復當前資料集所需的最小命令集合,整個重寫操作是絕對安全的,因為Redis在創建新AOF檔案的程序中,append模式不斷的將修改資料追加到現有的 AOF檔案里面,即使重寫程序中發生停機,現有的 AOF檔案也不會丟失,而一旦新AOF檔案創建完畢,Redis就會從舊AOF檔案切換到新AOF檔案,并開始對新AOF檔案進行追加操作,
-
AOF包含一個格式清晰、易于理解的日志檔案用于記錄所有的修改操作,事實上,也可以通過該檔案完成資料的重建;
AOF檔案有序地保存了對資料庫執行的所有寫入操作,這些寫入操作以Redis協議的格式保存,因此 AOF檔案的內容非常容易被人讀懂,對檔案進行分析(parse)也很輕松,匯出(export)AOF檔案也非常簡單:舉個例子,如果不小心執行了FLUSHALL.命令,但只要AOF檔案未被重寫,那么只要停止服務器,移除 AOF檔案末尾的FLUSHAL命令,并重啟Redis,就可以將資料集恢復到FLUSHALL執行之前的狀態,
AOF模式缺點:
- 即使有些操作是重復的也會全部記錄,AOF的檔案大小要大于RDB格式的檔案;
- AOF在恢復大資料集時的速度比RDB的恢復速度要慢;
- 根據fsync策略不同,AOF速度可能會慢于RDB;
- bug出現的可能性會更多
3、RDB模式和AOF模式的選擇
- 如果注意是來充當快取功能,或者可以承受短暫時間的資料丟失,通常生產環境一般只需要開啟RDB就可以了,啟用RDB也是默認值,
- 如果資料需要持久化保存,有點也不可以丟失的話,就可以選擇開啟RDB和AOF,
- 一般不會只開啟AOF的,這樣操作也是不建議的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/526057.html
標籤:其他
上一篇:Windows 環境搭建 PostgreSQL 物理復制高可用架構資料庫服務
下一篇:mysql資料庫常用命令