導讀
BitSail 是位元組跳動開源資料集成引擎,支持多種異構資料源間的資料同步,并提供離線、實時、全量、增量場景下全域資料集成解決方案,目前支撐了位元組內部和火山引擎多個客戶的資料集成需求,經過位元組跳動各大業務線海量資料的考驗,在性能、穩定性上得到較好驗證,
10 月 26 日,位元組跳動宣布 BitSail 專案正式在 GitHub 開源,為更多的企業和開發者帶來便利,降低資料建設的成本,讓資料高效地創造價值,本篇內容將圍繞 BitSail 演講歷程及重點能力決議展開,主要包括以下四個部分:
-
位元組跳動內部資料集成背景
-
BitSail 技術演進歷程
-
BitSail 能力決議
-
未來展望
位元組跳動內部資料集成背景
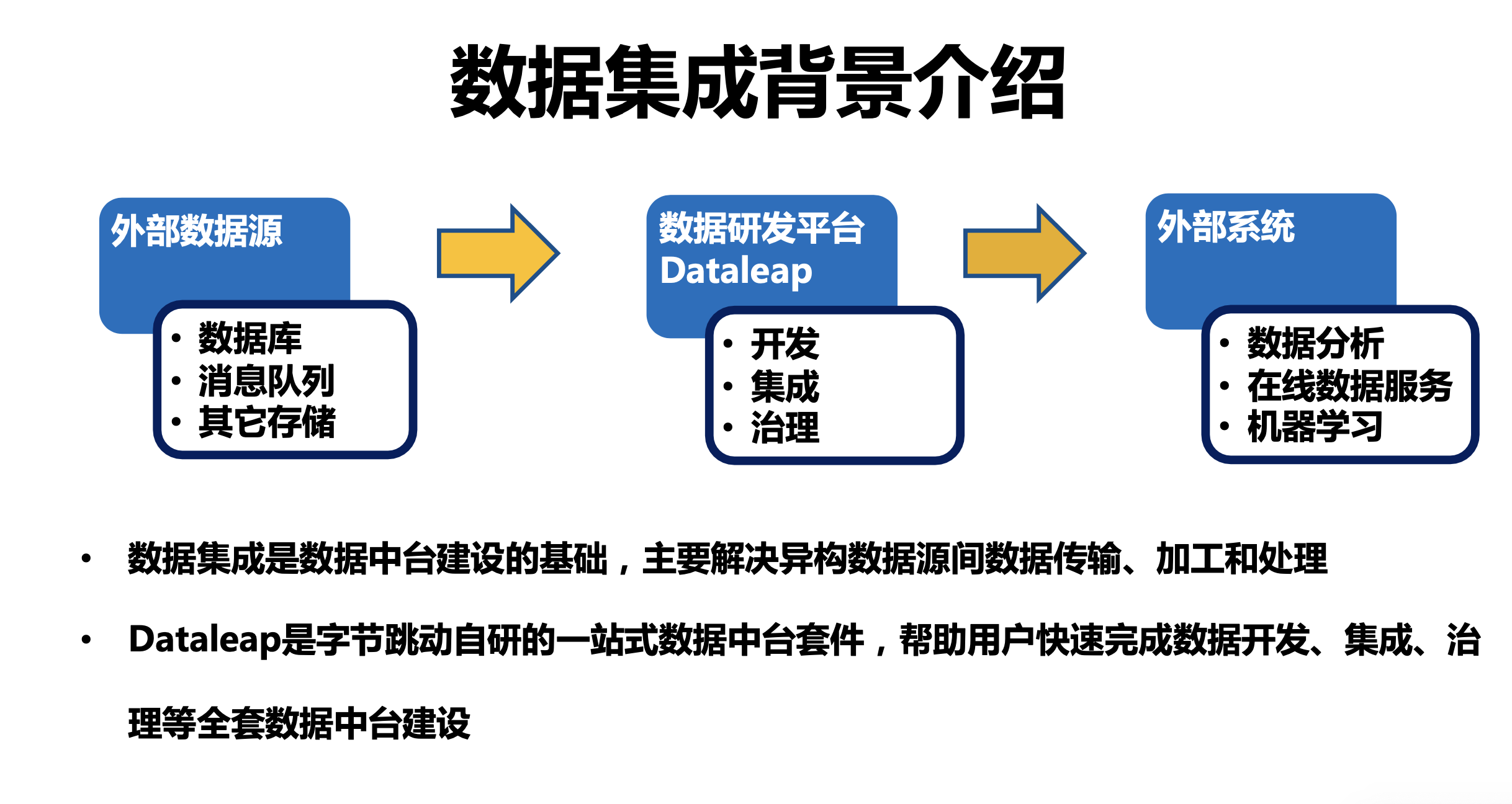
一直以來,位元組跳動都非常重視并貫徹“資料驅動”這一理念,作為資料驅動的一環,資料中臺能力的建設至關重要,而這其中,資料集成作為資料中臺建設的基礎,主要解決了異構資料源的資料傳輸、加工和處理的問題,
BitSail 源自位元組跳動資料平臺團隊自研的資料集成引擎 DTS(全稱 Data Transmission Service,即資料傳輸服務),最扯訓于 Apache Flink 實作,至今已經服務于位元組內部業務接近五年,現已具備批式集成、流式集成和增量集成三類同步模式,并支持分布式水平擴展和流批一體架構,在各種資料量和各種場景下,一個框架即可解決資料集成需求,此外,BitSail 采用插件式架構,支持運行時解耦,從而具備極強的靈活性,企業可以很方便地接入新的資料源,
BitSail 演進歷程
1. 全域資料集成引擎演進三階段
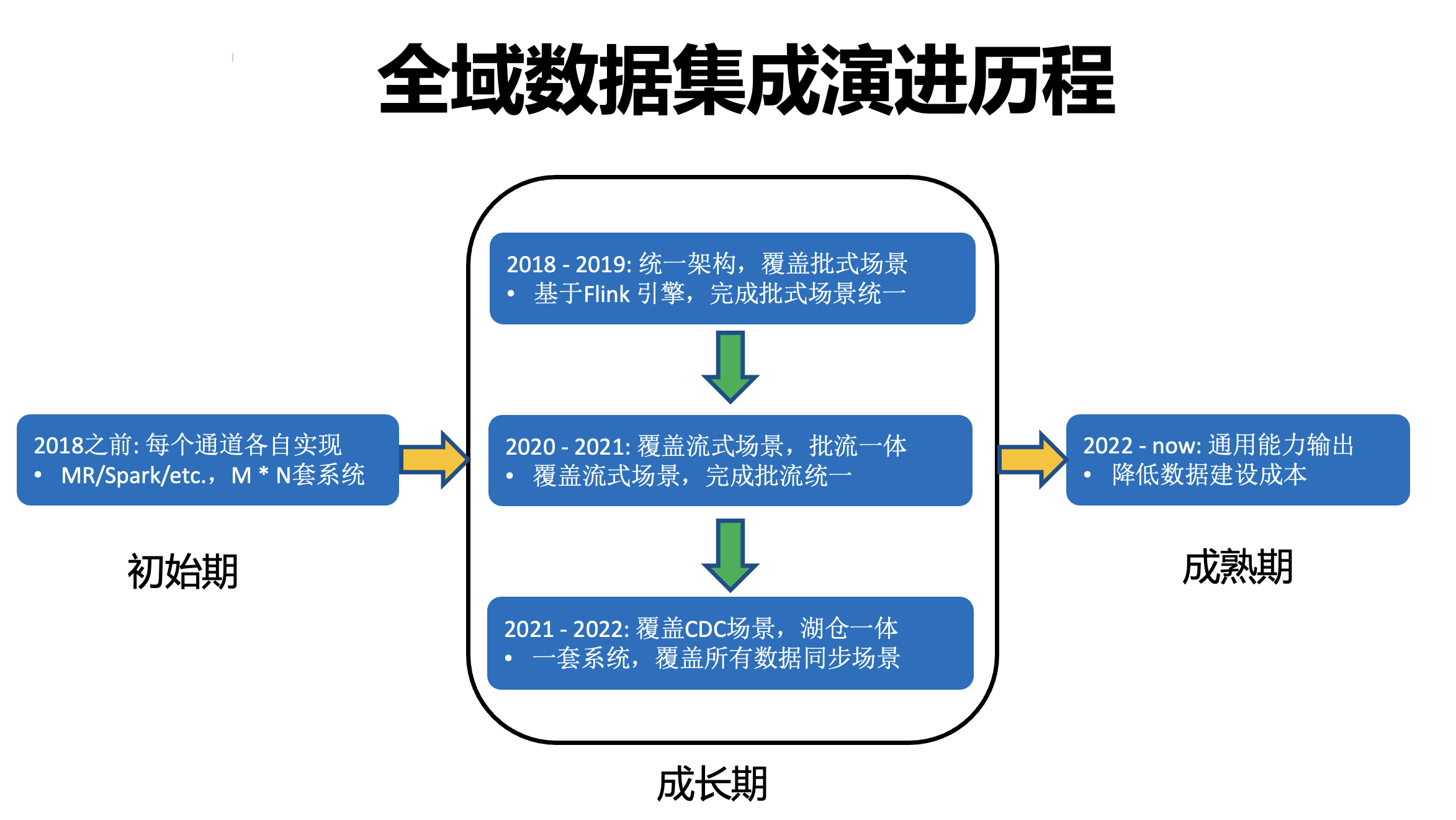
位元組跳動資料集成引擎 BitSail 演進的歷程可以分為三個階段:
① 初始期: 2018 年以前公司沒有統一的資料集成框架,對每個通道都是各自實作,因此依賴的大資料引擎也比較零散,如 MapReduce、Spark,資料源之間的連接也是網狀連接,整體的開發和運維成本都比較高,
② 成長期:可以分為三個小階段,
-
2018-2019:隨著 Flink 生態不斷完善,越來越多的公司將 Flink 作為大資料計算引擎的首選,位元組跳動也不例外,并在 Flink 上持續探索,并于 2019 年提出基于 Flink 的異構資料源間傳輸,完成批式場景的統一,
-
2020-2021:隨著 Flink 批流一體的完善,位元組跳動對原有架構進行較大升級,并覆寫了流式場景,完成批流場景的統一,
-
2021-2022:接入了 Hudi 資料湖引擎,解決 CDC 資料實時同步問題,并提供湖倉一體解決方案,
③ 成熟期:2022 年開始全域資料集成引擎的整體架構已經穩定,并經過位元組跳動內部各業務線生產環境的考驗,在性能和穩定性上也得到充分的保障,于是團隊希望能夠將能力對外輸出,為更多的企業和開發者帶來便利,降低資料建設的成本,讓資料高效地創造價值,
2. BitSail 資料集成引擎技術架構演進
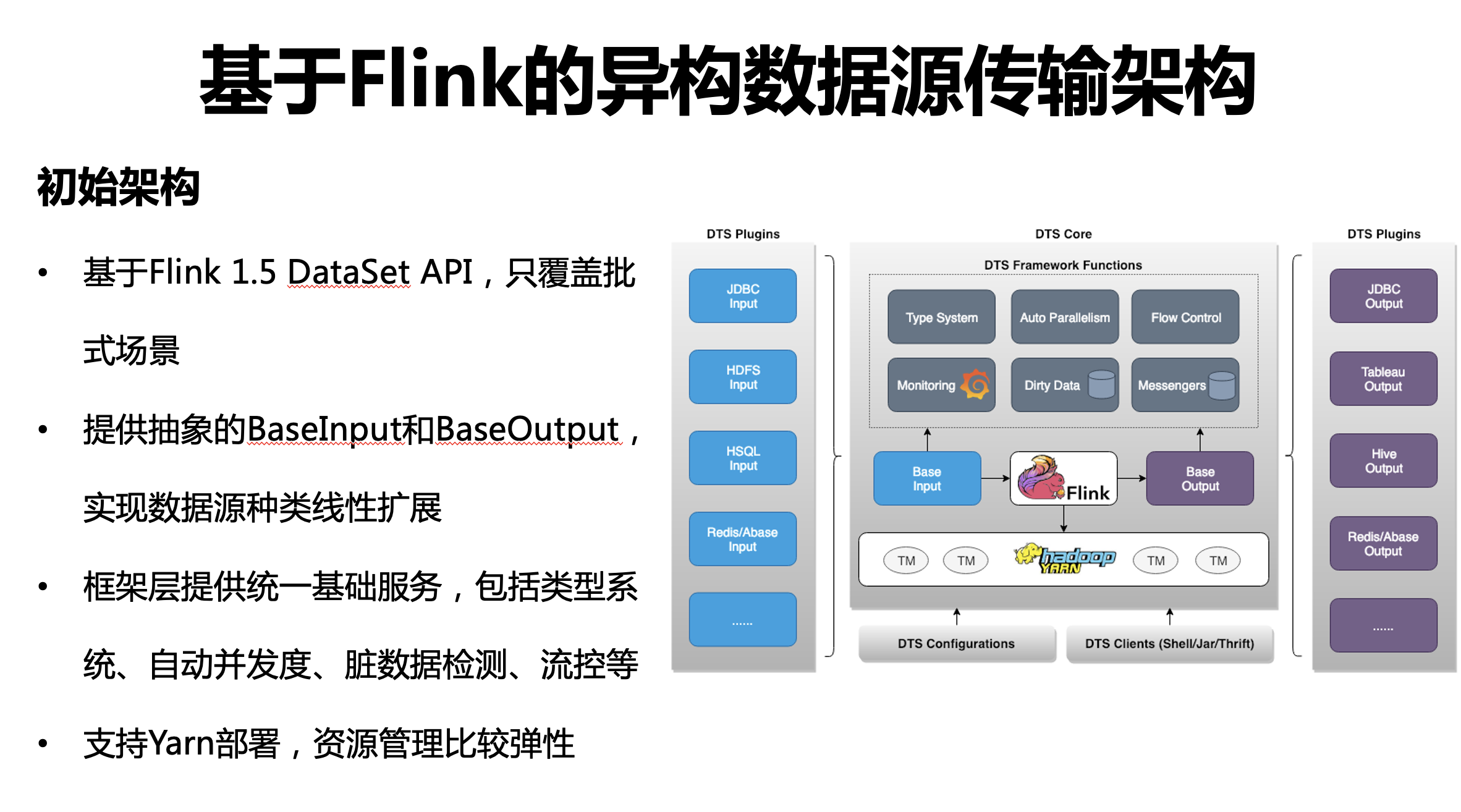
① 基于 Flink 的異構資料源傳輸架構
基于 Flink 1.5 DataSet API 實作的異構資料源傳輸架構,只支持批式場景,框架核心思想是,對原始輸入層資料抽象為 BaseInput,主要用于拉取源端的資料;對輸出層抽象為 BaseOutput,負責將資料寫到外部系統,同時,框架層提供了基礎服務,包括型別系統(Type System)、自動并發度(Auto Parallelism)、流控(Flow Control)、臟資料檢測(Dirty Data)等等,并對所有的資料源通道生效,
以下介紹一個批次場景上比較有意思的功能,也是實際業務中面臨的一些痛點,
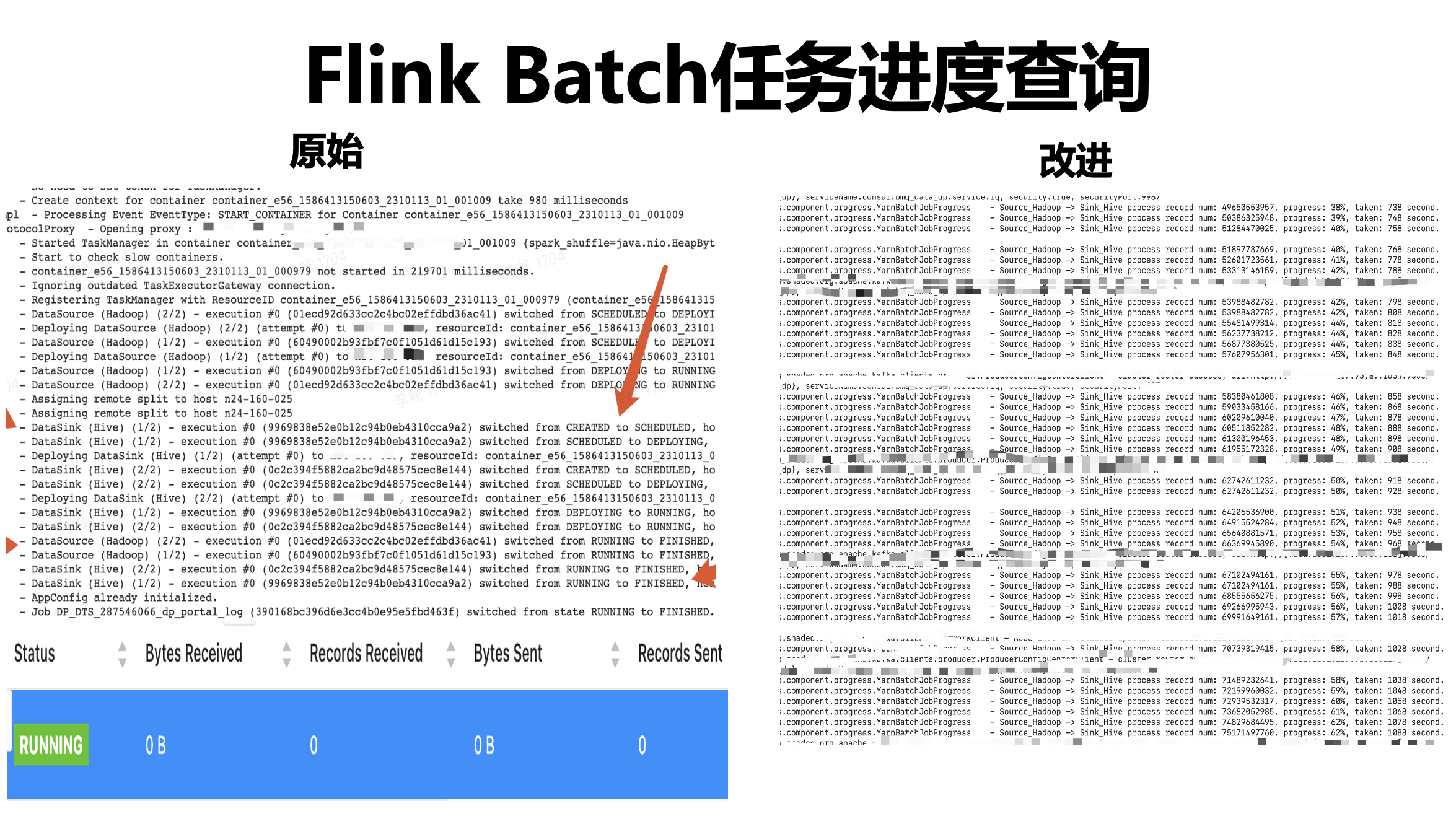
上圖左上部分是原始的 Flink 運行日志,從這個日志里看不到任務進度資料和預測資料,如當前任務運行的百分比、運行完成所需時間,
左下部分則是 Flink UI 界面提供的任務運行的元資訊,可以看到讀寫條數都是 0,從 Flink 引擎角度,由于所有算子作為一個整體是沒有輸入和輸出的,這是合理的,但從用戶角度就無法看到任務整體進度資訊和當前處理記錄條數,從而導致用戶懷疑這個任務是否已經卡住,圖中右邊是改造之后的效果,日志中明確輸出當前處理了多少條數、實時進度展示、消耗時間等等,該功能在位元組內部上線后,得到了很多業務的好評,
下面介紹一下具體的實作,
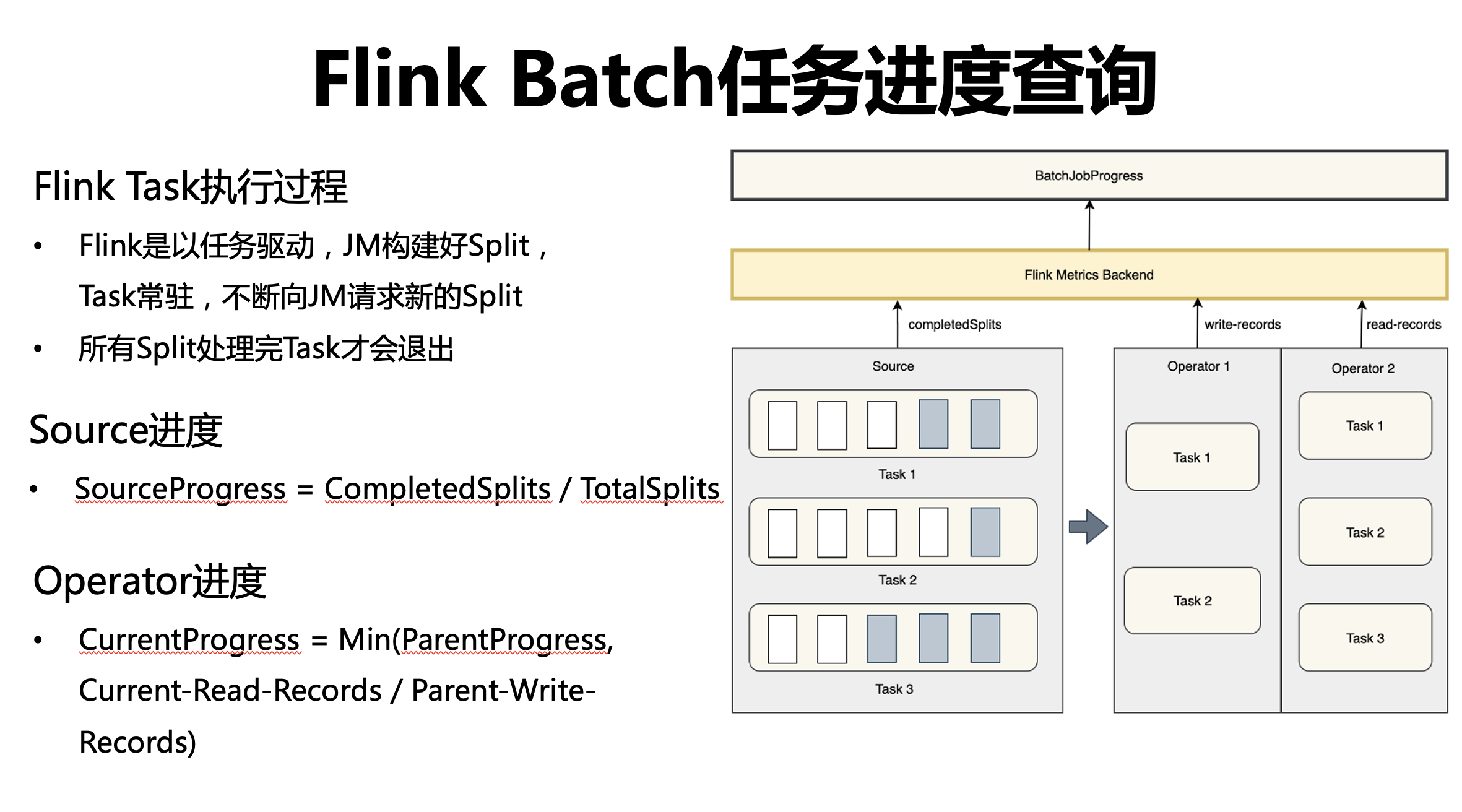
首先回顧 Flink Task 的執行程序,與傳統的 MapReduce、Spark 的驅動模型不一樣,Flink 是以任務驅動,JM 創建好 Split 之后,Task 是常駐運行,不斷向 JM 請求新的 Split,只有所有的 Split 處理完之后,Task 才會退出,此時,如果用總的完成的 Task 個數除以總的 Task 個數,進度將出現一定程度的失真,最開始,所有的 Task 都在運行,不斷地去拉取 Split,我們看到的進度會是 0,等到 JM 的 Split 處理完之后,所有的 Task 會集中退出,可以看到進度會突然跳動到 100%,中間是缺少進度資訊的,
為了解決這個問題,我們還是要回到資料驅動本身,以 Split 的維度來衡量整個 Job 的運行程序,圖中右邊所展示的是,通過 Flink UI 提供的 API,可以拿到整個任務的拓撲資訊,將其分為兩層算子并進行改造,分別是 Source 層和 Operator 層,
-
Source 層
我們修改了原生的 Source API,具體的話包括兩個部分,第一個是創建 Split 之后,我們會去拿到 Total Split 的個數,將它上載到 Metric 里;其次是 Source 里的每個 Task 每處理完一個 Split 之后,我們會上報一個 CompletedSplit,最終我們通過 Flink UI 是可以拿到當前已經完成的 Split 個數以及總共的 Split 個數,并用完成的 Split 個數來除以總共的 Split 個數來衡量 Source 節點的進度,
-
Operator 層
首先我們會看當前 Operator 上游節點的輸出多少條,以及當前節點它讀取了多少條,并用當前節點讀取的條數除以它的上游節點的輸出條數作為當前 Operator 的進度,同時,這里我們做了一個梯度限制,就是當前節點的進度只能小于等于它的上游節點進度,
② 基于 Flink 批流一體的架構
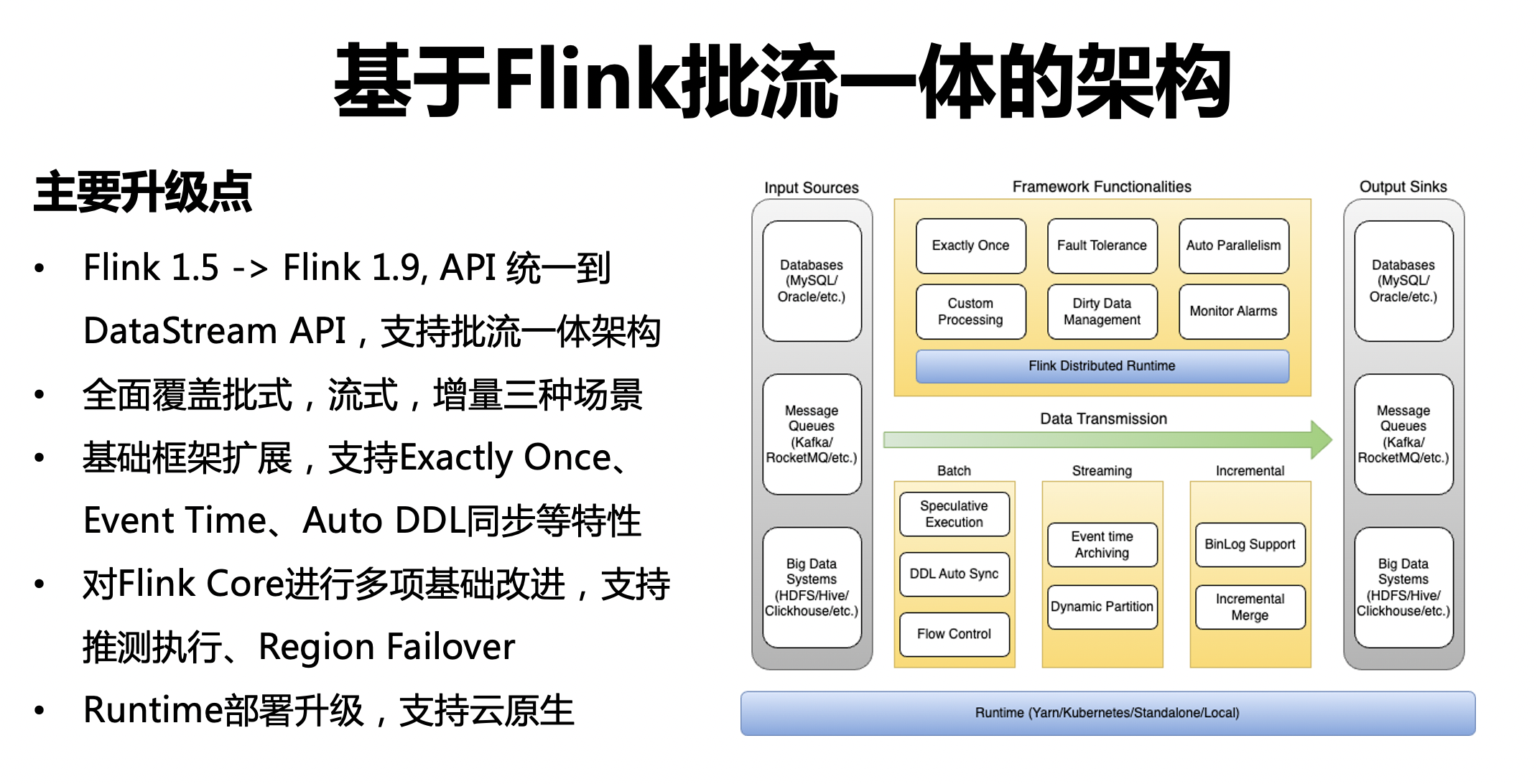
以下是批流一體的架構,相對于原有架構,位元組跳動資料平臺團隊完成如下升級:
-
將 Flink 版本從 1.5 升級到 1.9,同時我們分析了 DataSet API,統一升級到 DataStream API,以支持批流一體架構,
-
對資料源支持進行擴充,除了原有的離線資料源之外,增加了實時資料源,如訊息佇列,
-
對框架層完成拓展,支持 Exactly Once、支持 Event Time 寫入、Auto DDL 等功能,
-
對引擎層進行改進,增加推測執行、Region Failover 等功能,
-
在 Runtime 層也做了進一步的擴充,支持云原生架構,
我們分析一個實時場景中比較典型的鏈路,MQ 到 Hive 這個鏈路,
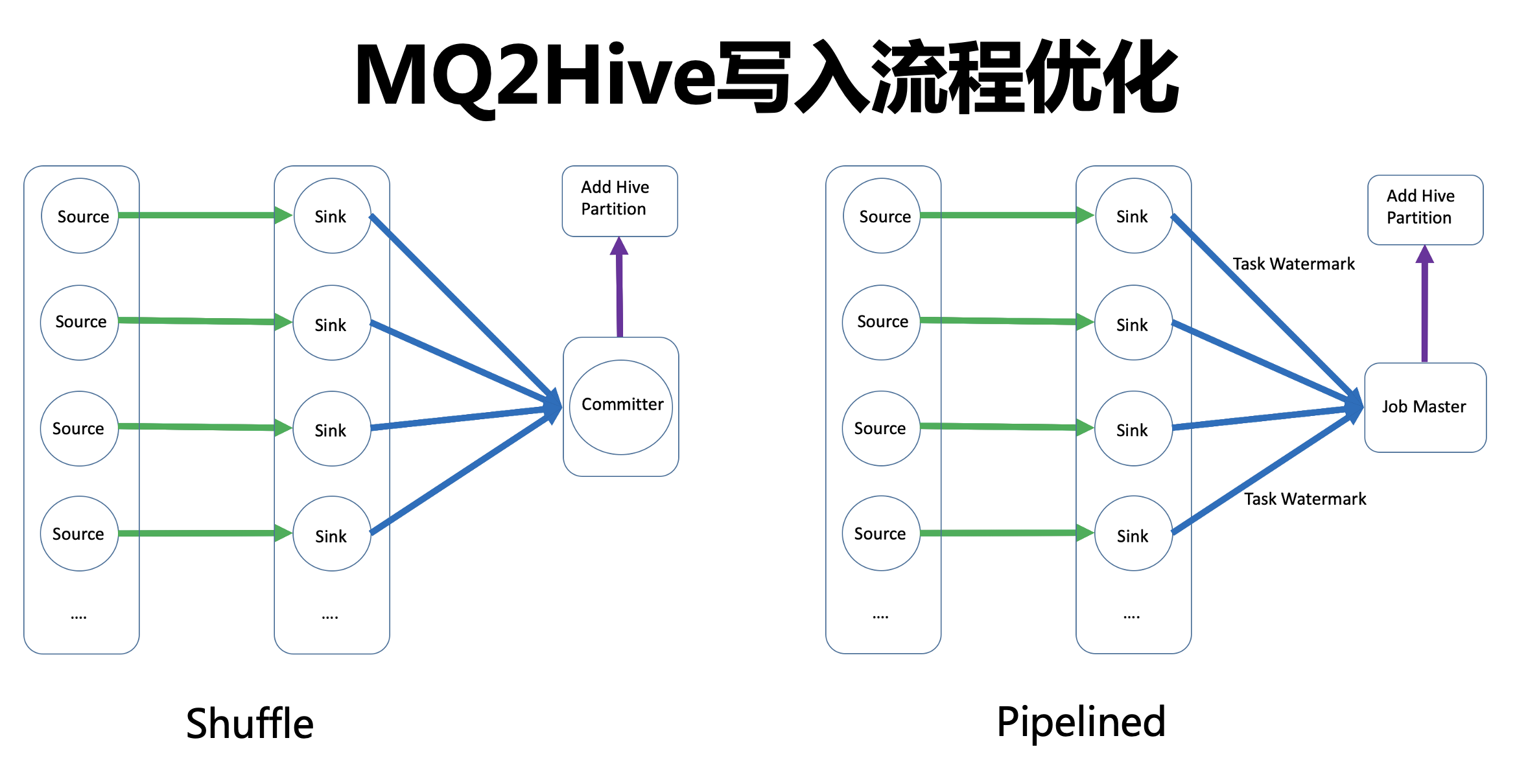
左圖(Shuffle)是目前社區的實作方式,很多資料湖的寫入,比如 Hudi、Iceberg 基本上也是這個結構,這套結構分為兩層算子,第一層是我們的資料處理層,負責資料的讀取和寫入;第二層算子是一個單節點的提交層,它是一個單并發,主要負責元資訊的提交,比如去生成 Hive 的磁區或者做一些其他的元資訊動作,
這個架構的優勢是其整體拓撲(資料處理流程)比較清晰,算子功能定位也比較清楚,但是它有一個明顯的缺陷,加入一個單并發節點后,導致整個任務變成 Shuffle 連接,而 Shuffle 連接天然的弱勢是,當遇到 Task Failover 的時候,它會直接進行全域重啟,
右圖(Pipelined)是改造之后的資料處理流程,資料寫入部分沒有變化,變化的是后面的提交部分,這樣的設計考慮是是保持原有 Pipeline 架構,以實作 Task 容錯時不會進行全域重啟,廢棄了原有的單并發提交節點,把所有元資訊的提交拿到 JM 端處理,同時 Task 和 JM 的通訊是通過 Aggregate Manager 來實作,改為這套架構之后,在大資料量場景下,其穩定性得到了顯著的提升,
③ 基于 Flink 湖倉一體的架構
引入湖倉一體架構的目的是解決 CDC 資料的近實時同步,
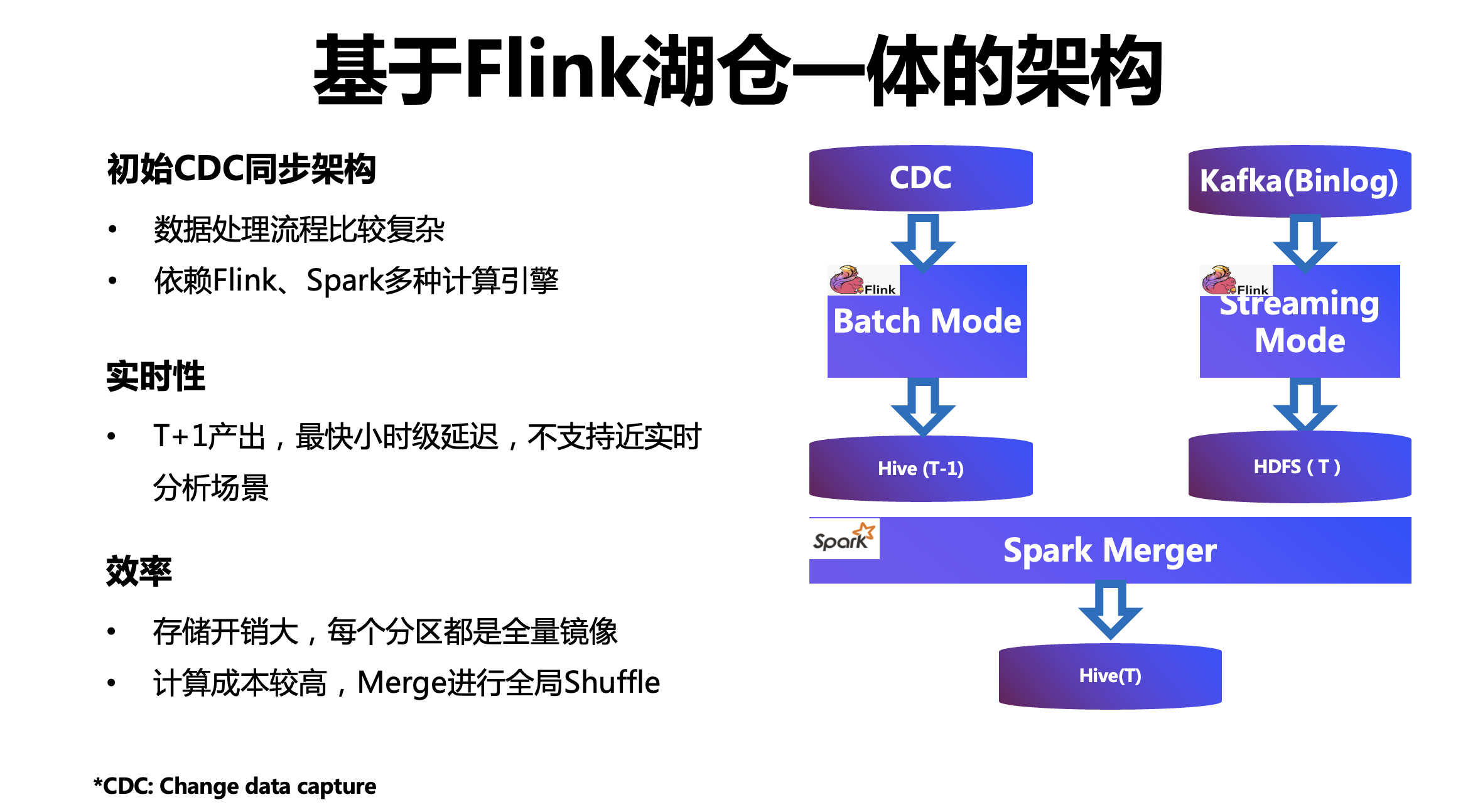
右圖是原有架構,處理流程包括三個模塊:
-
拉取批次任務:用來拉取 CDC 全量的資料,寫到 Hive 里作為一個基礎的鏡像,
-
實時任務:拉取 CDC 的 Changelog,并實時寫入 HDFS,作為一個增量資料,
-
離線調度任務:周期性地進行 Merge,將全量資料和增量資料進行合并,形成新的全量資料,
上述架構比較復雜,并依賴 Flink、Spark 等多種計算引擎,在實時性方面,只能做到 T+1,最快也只能做到小時級延遲,無法有效支撐近實時分析場景,從效率來說,存盤開銷比較大,每個磁區都是一個全量鏡像,而且計算成本較高,每次 Merge 都需要進行全域 Shuffle,
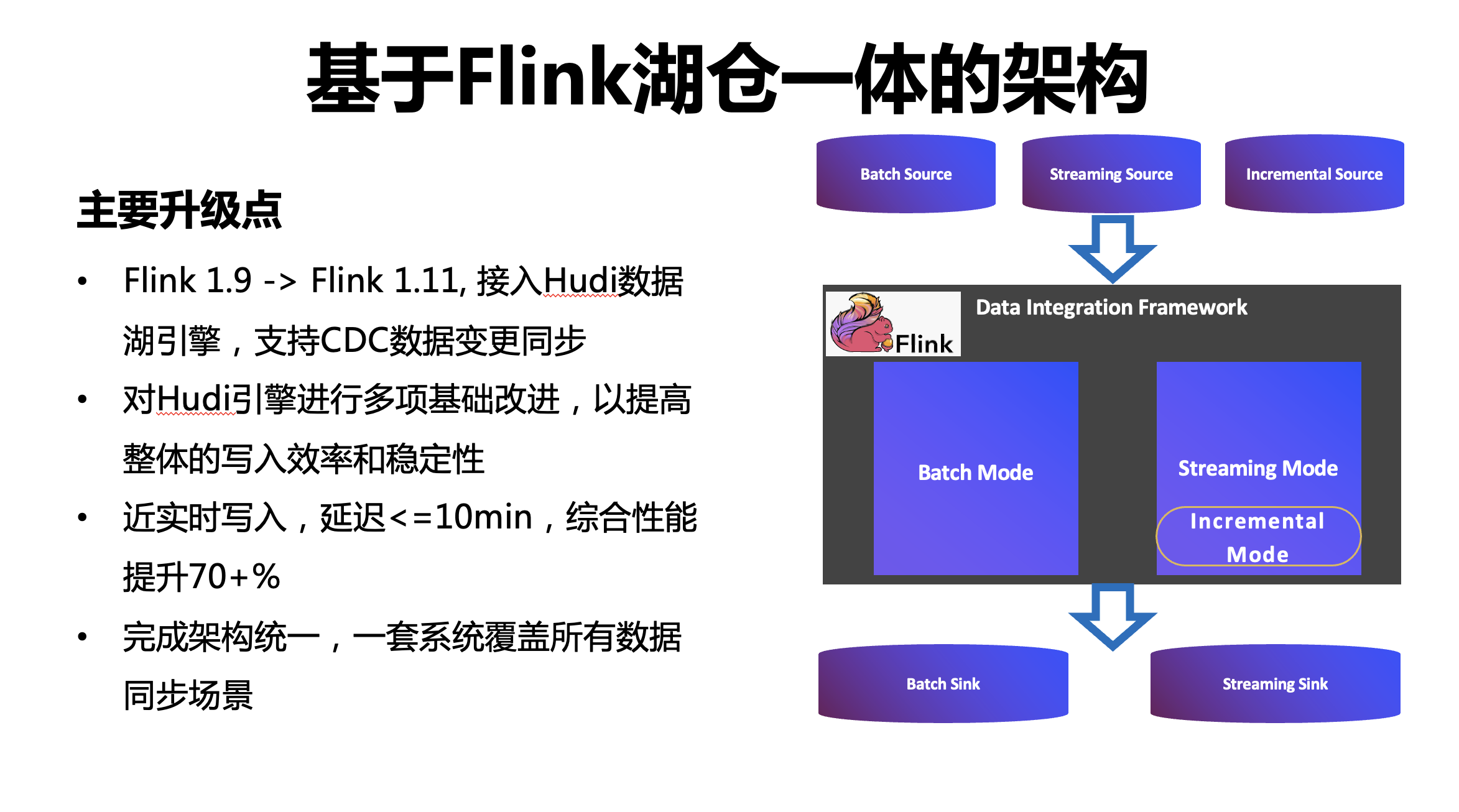
右圖是升級后的架構,主要的升級點包括:
-
將 Flink 1.9 升級到 Flink 1.11,接入了 Hudi 資料湖引擎,以支持 CDC 資料近實時同步,這是因為 Hudi 引擎有完備的索引機制以及高效的 Upsert 性能,
-
對 Hudi 引擎也進行了多項基礎改進,以提高整體的寫入效率和穩定性,
最終實施的效果,近實時寫入,整體的延遲在 10 分鐘以內,綜合性能比原有架構提升 70%以上,至此,完成了全域資料集成架構統一,實作一套系統覆寫所有同步場景,
3. 架構演程序序實踐經驗分享
下面介紹實際演程序序中的一些思考、問題和改進方案,
-
表型別選擇
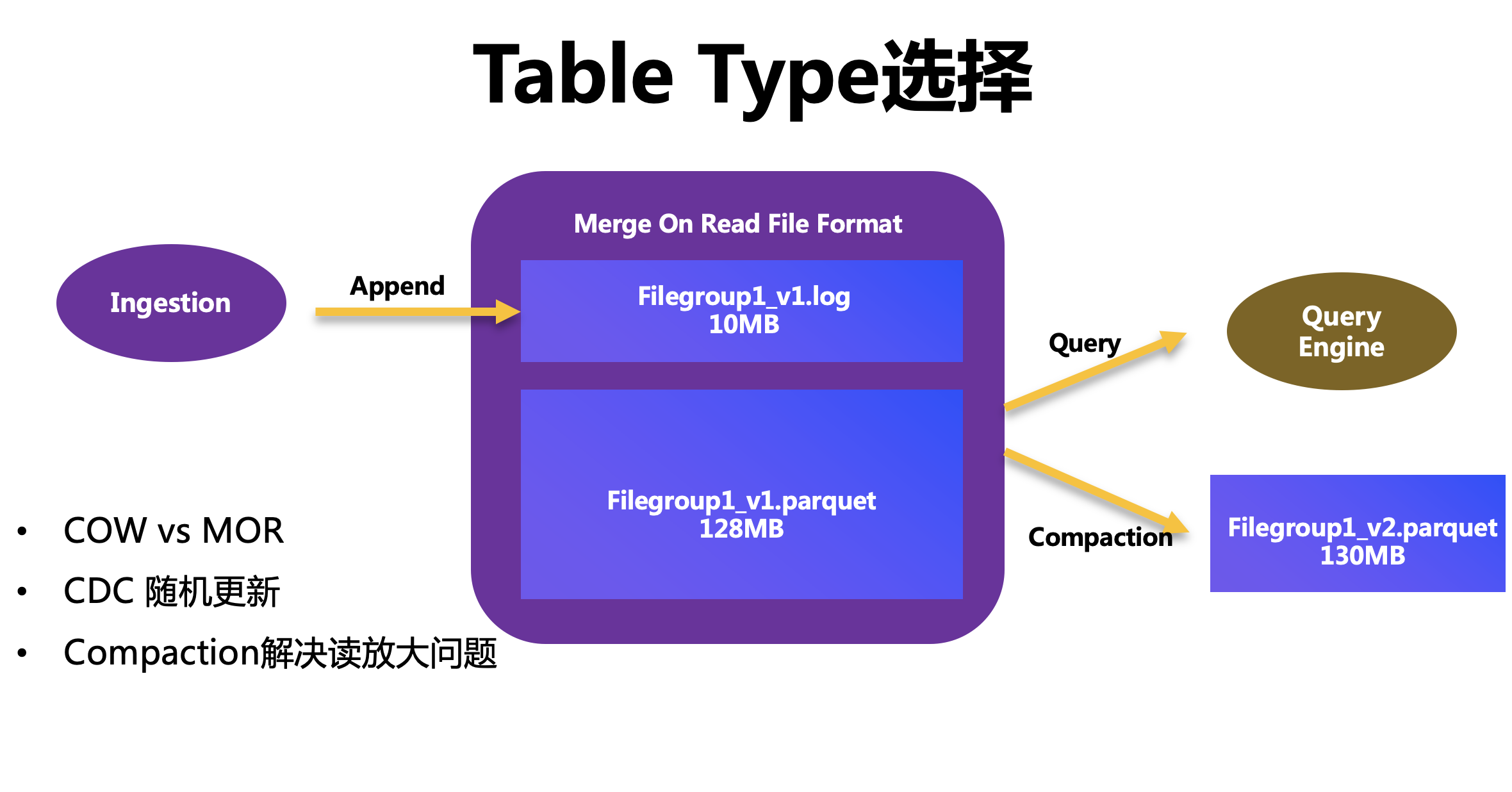
資料湖是支持多種表格式的,比如 CopyOnWrite(簡稱 COW)表、MergeOnRead(簡稱 MOR)表,COW 表的優勢在于讀性能比較好,但是會導致寫放大,MOR 表正好相反,寫的性能比較好的,會導致讀放大,具體選擇哪種表格式,更多要根據大家的業務場景來決定,
我們的業務場景是為了解決 CDC 資料的近實時同步,CDC 資料有個明顯的特點,是存在大量的隨機更新,這個場景下選擇 COW,會導致寫放大的問題比較嚴重,所以我們選擇了 MOR 表,上圖就是一個 MOR 表查詢和寫入的流程,第一個是列存盤的基礎鏡像檔案,我們稱之為 Base 檔案,第二個是行存盤的增量日志,我們稱之為 Log 檔案,
每次查詢時,需要將 Log 檔案和 Base 檔案合并,為了解決 MOR 表讀放大的問題,通常我們會建一個 Compaction 的服務,通過周期性的調度,將 Log 檔案和 Base 檔案合并,生成一個新的 Base 檔案,
-
Hudi 實時寫入痛點
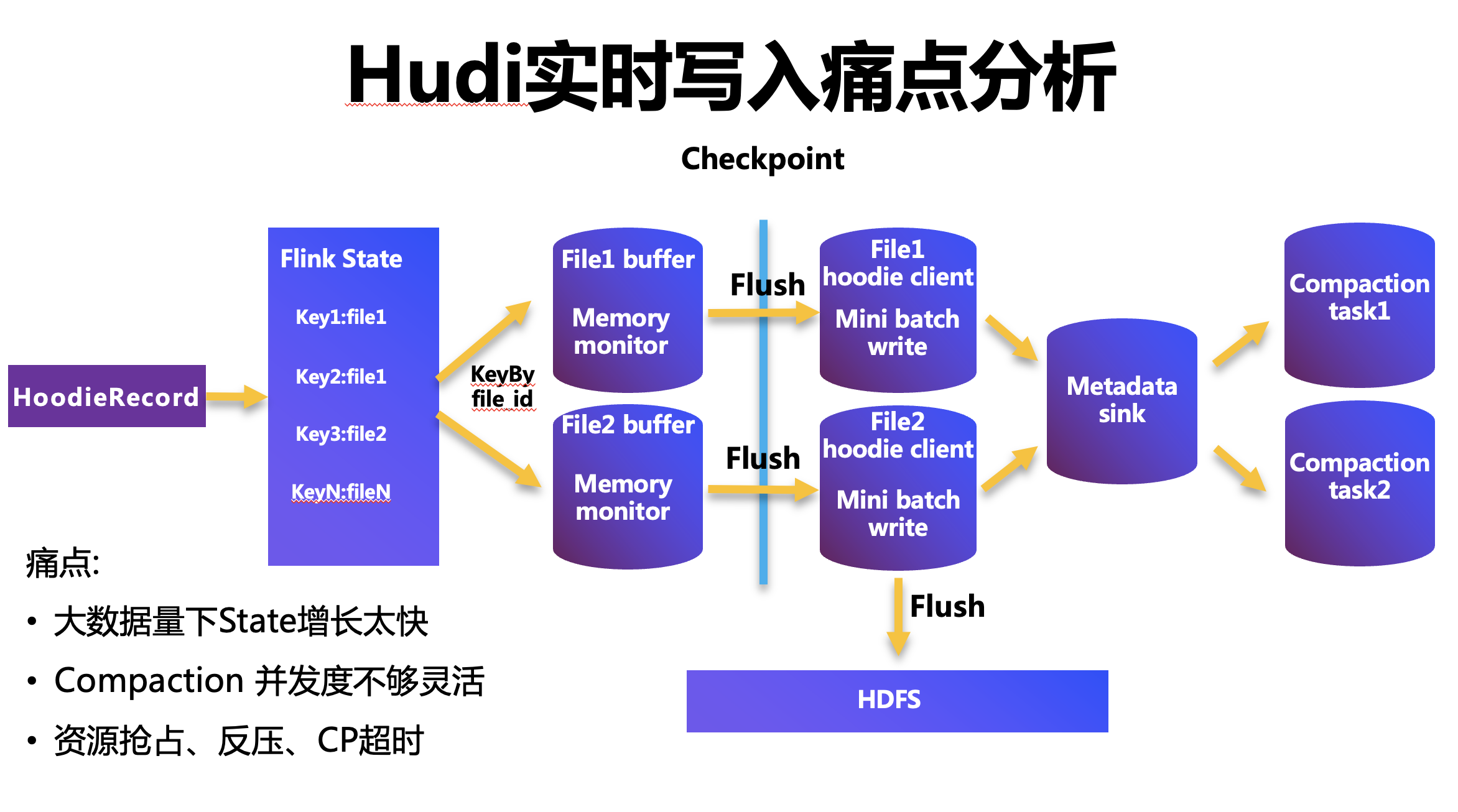
如圖所示,這是原生的 Hudi 實時寫入的流程圖,
首先,我們接入 Hudi 資料,會進入 Flink State,它的作用是索引,Hudi 提供了很多索引機制,比如 BloomIndex,但是 BloomIndex 有個缺陷,它會出現假陽性,降級去遍歷整個檔案,在效率上有一定的影響,Flink State 的優勢是支持增量更新,同時它讀取的性能會比較高,經過 Flink State 之后,我們就可以確認這條記錄是 Upsert,還是 Insert 記錄,同時會分配一個 File Id,
緊接著,我們通過這個 File Id 會做一層 KeyBy,將相同 File 的資料分配到同一個 Task,Task 會為每一個 File Id 在本地做一次快取,當快取達到上限后,會將這批資料 Flush 出去到 hoodie client 端,Hoodie client 主要是負責以塊的方式來寫增量的 Log 資料,以 Mini Batch 的方式將資料重繪到 HDFS,
再之后,我們會接一個單并發的提交節點,最新的版本是基于 Coordinator 來做的,當所有的算子 Checkpoint 完成之后,會提交元資訊做一次 Commit,認為這次寫入成功,同時 Checkpoint 時,我們會重繪 Task 的快取和 hoodie client 的快取,同時寫到 HDFS,通常,我們還會接一個 Compaction 的算子,主要用來解決 MOR 表讀放大的問題,
這個架構在實際的生產環境會遇到如下問題:
(1)當資料量比較大的時候,Flink State 的膨脹會比較厲害,相應地會影響 Task 的速度以及 Checkpoint 的成功率,
(2)關于 Compaction 算子,Flink 的流式任務資源是常駐的,Compaction 本身是一個周期性的調度,如果并發度設定比較高,往往就意味著資源的浪費比較多,
(3)Flink 提供了很多資源優化的策略,比如 Slot Sharing,來提高整體的資源利用率,這就會導致資源搶占的問題,Compaction 會和真正的資料讀寫算子來進行資源的搶占,Compaction 本身也是一個重 I/O、CPU 密集型操作,需要不斷地讀取增量日志、全量日志,同時再輸出一個全量資料,
針對上述問題,我們優化了 Hudi 的寫入流程,
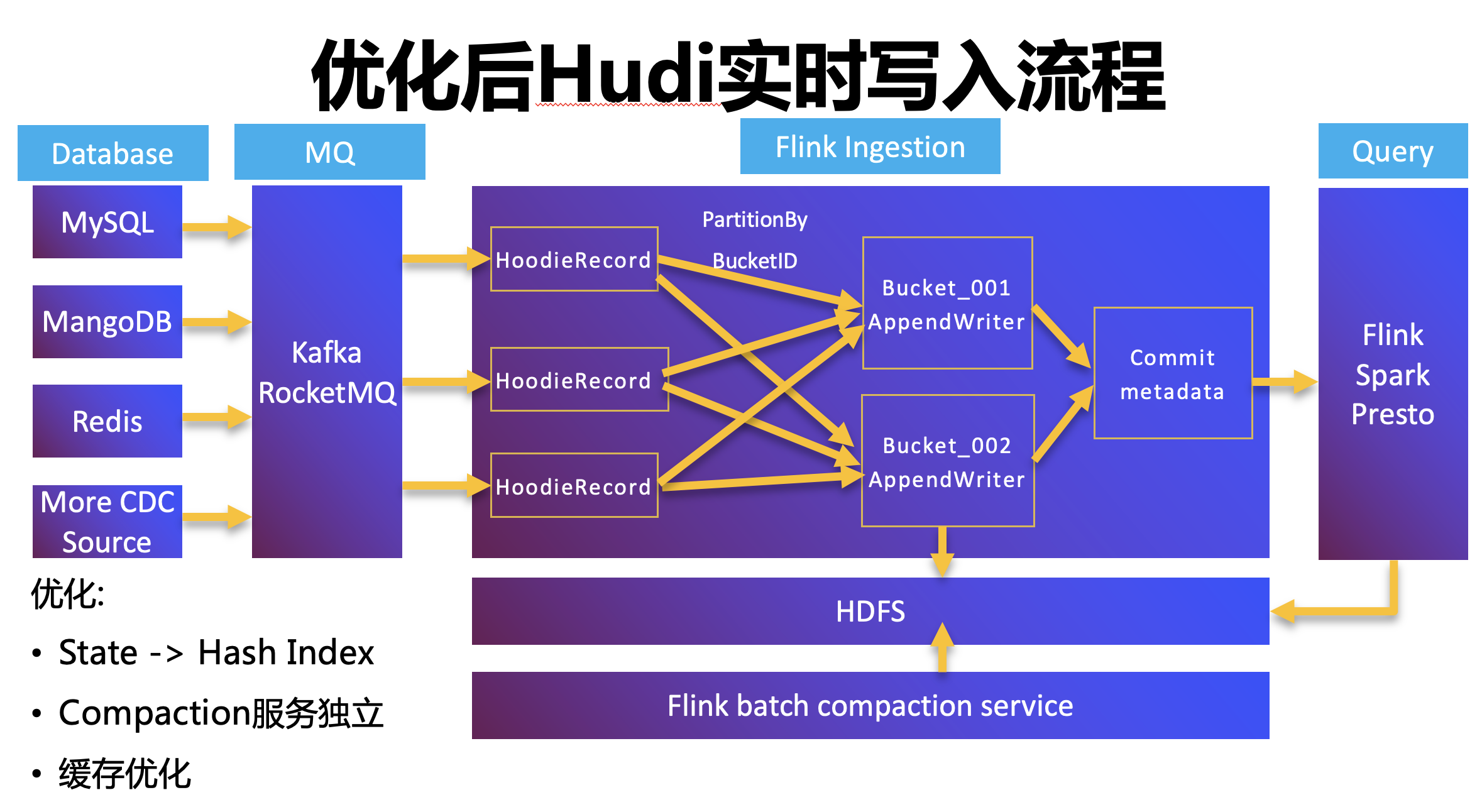
首先我們會采集 CDC 的 Change Log,并發送到訊息佇列,然后消費訊息佇列中的 Change Log,然后我們進行如下三個優化:
(1)廢棄了原先的 Flink State,替換為 Hash Index,Hash Index 的優勢是不依賴外部存盤,來了一個 HoodieRecord 之后,只需要一個簡單的哈希處理,就知道它對應的 Bucket,
(2)將 Compaction 服務獨立成一個離線的任務,并且是周期性的調度,用來解決資源浪費和資源搶占的問題,
(3)將 Task 快取和 Hudi 快取做了合并,因為每次 Checkpoint 都需要重繪 Task 快取,Hudi 快取需要寫入 HDFS,如果快取的資料量比較多,會導致整個 Checkpoint 時間比較長,
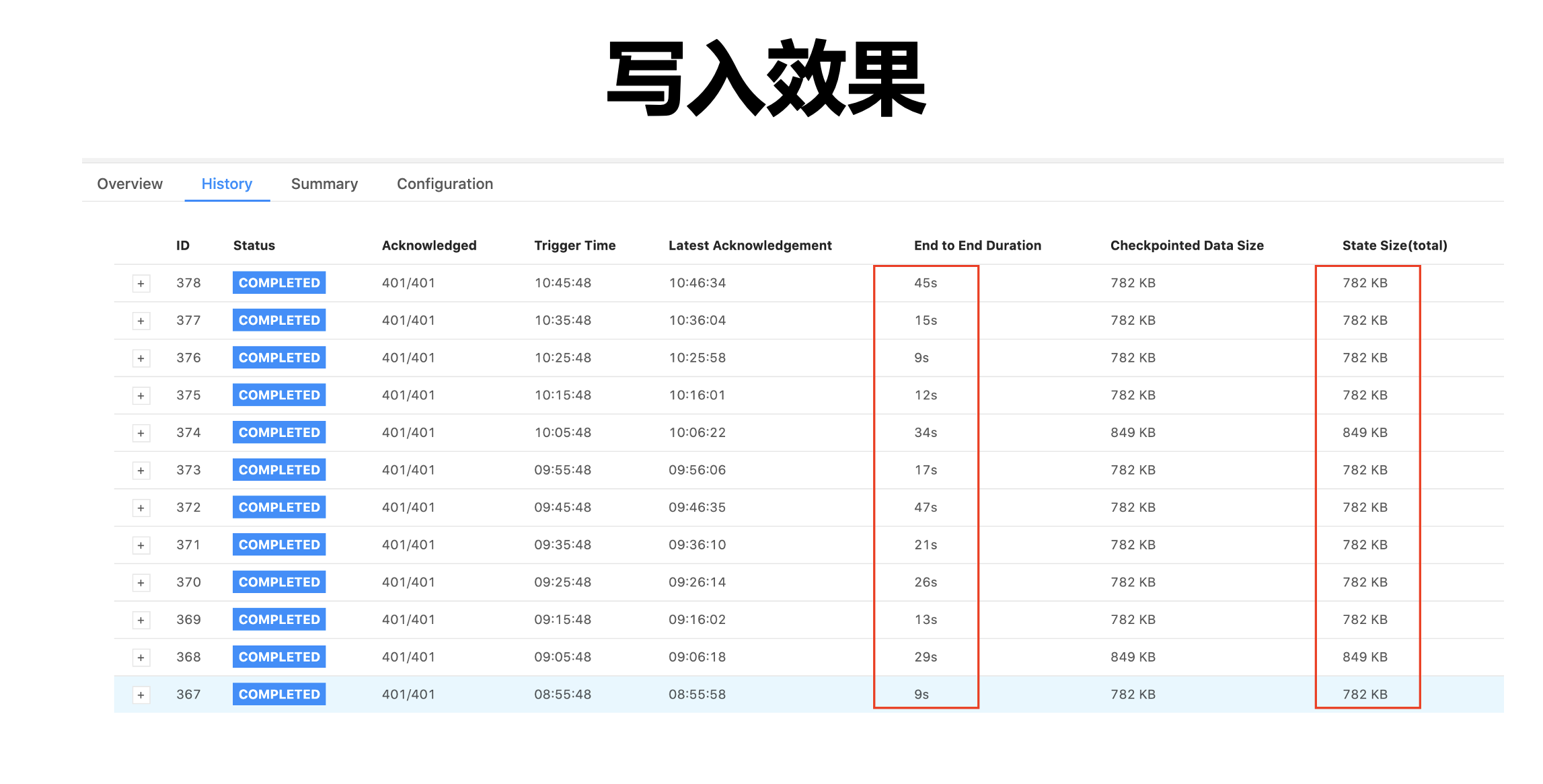
優化之后,穩定性方面,可以支持百萬級的 QPS;端到端的 Checkpoint 延時控制在 1 分鐘以內,Checkpoint 成功率可以做到 99%,
BitSail 能力決議
目前技術架構比較成熟,并經過位元組跳動各業務線的驗證,在資料的穩定性和效率上都能得到一定的保障,因此,我們希望能把自己沉淀的經驗對外輸出,給更多企業和開發者帶來便利,降低大家資料建設的成本,讓資料創造高效的價值,為了達到這個目標,我們要解決兩個能力的構建,
1. 低成本共建能力
資料集成有一個明顯的網路效應,每個用戶所面臨的資料集成的場景也是不一樣的,因此需要大家的共同參與,完善資料集成的功能和生態,這就需要解決共建成本的問題,讓大家都能低成本地參與整個專案的共建和迭代,
在 BitSail 中,我們通過兩個思路推進這個能力建設,
① 模塊拆分
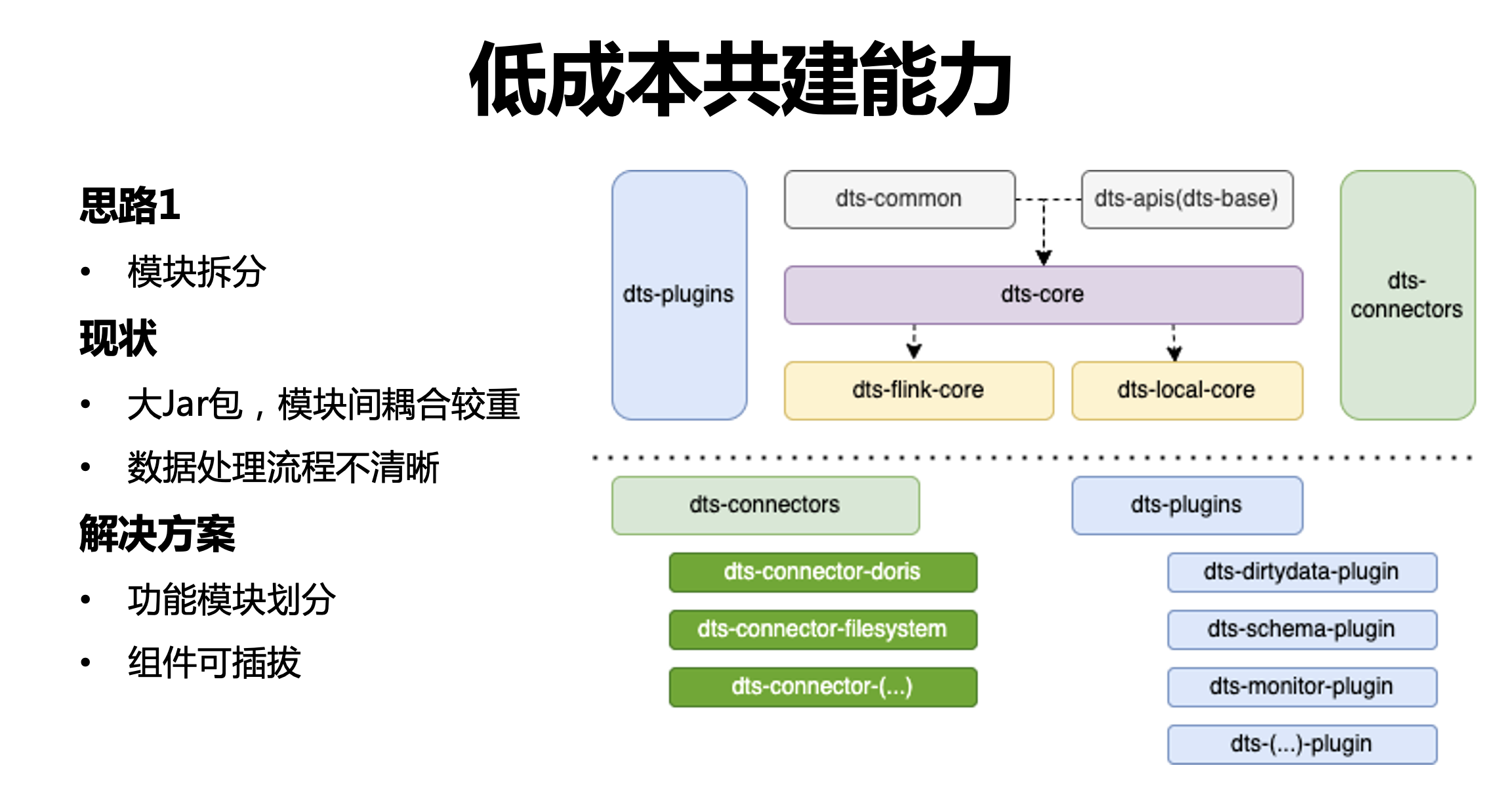
所有的模塊糅合在一個大的 jar 包中,包括引擎層、資料源層、基礎框架層,模塊耦合比較嚴重,資料處理流程也不清晰,針對這個問題,我們按照功能模塊進行劃分,將基礎框架和資料源從引擎中獨立出來,同時我們的技術組件采取可插拔的設計,以應對不同的用戶環境,比如臟資料檢測、Schema 同步、監控等等,在不同的環境中會有不同的實作方式,
② 介面抽象
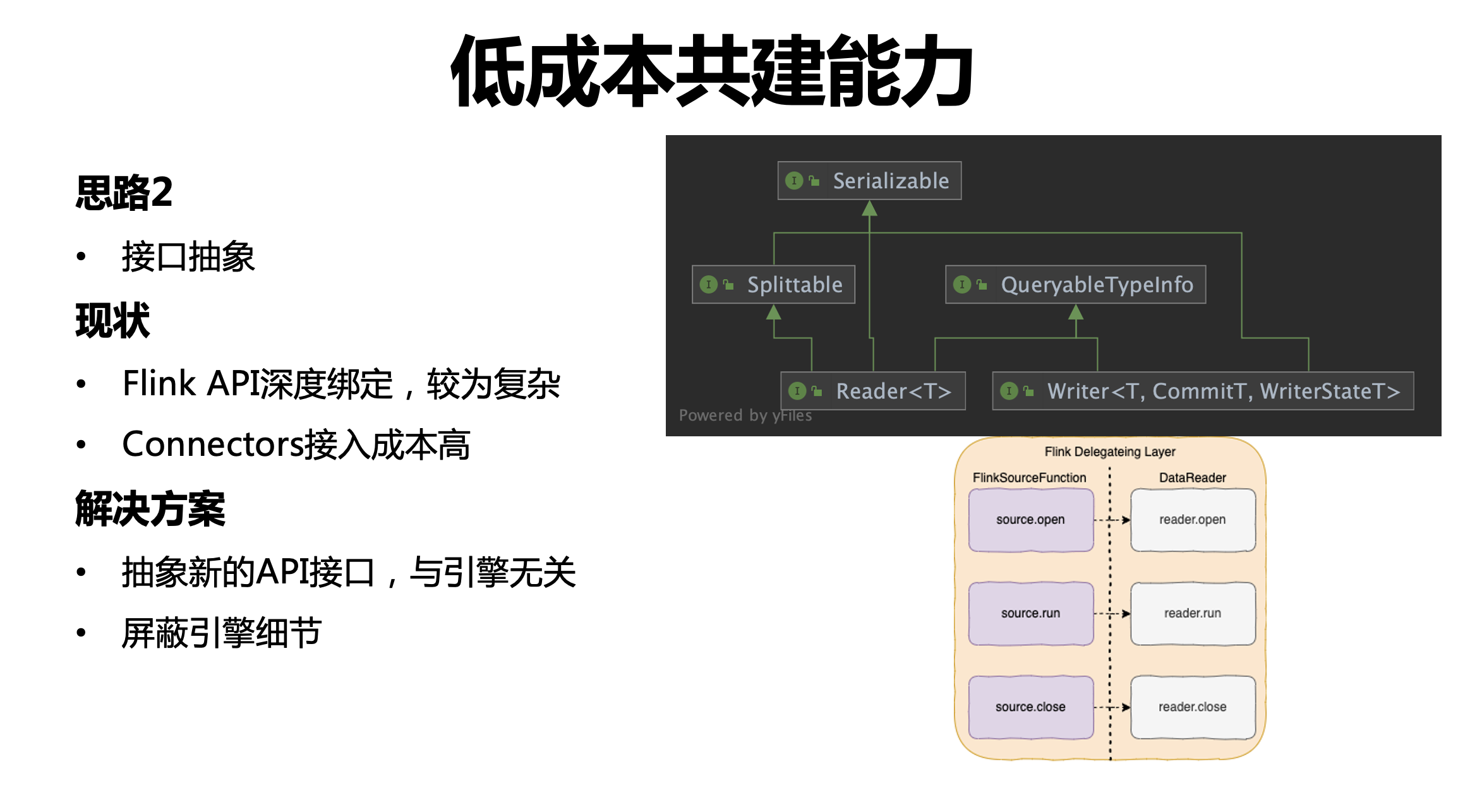
框架對 Flink API 是深度系結,用戶需要深入到 Flink 引擎內部,這會導致整體 Connector 接入成本比較高,為了解決這個問題,我們抽象了新的讀寫介面,該介面與引擎無關,用戶只要開發新的介面即可,同時在內部會做一層新的抽象介面與引擎介面的轉換,這個轉換對用戶是屏蔽的,用戶不需要了解底層引擎細節,
2. 架構的兼容能力
不同公司依賴的大資料組件和資料源的版本不一樣,同時還會遇到版本前后不兼容問題,因此需要完善架構的兼容能力,以解決不同環境下的快速安裝、部署和驗證,我們同樣有兩個思路來建設這個能力,
① 多引擎架構
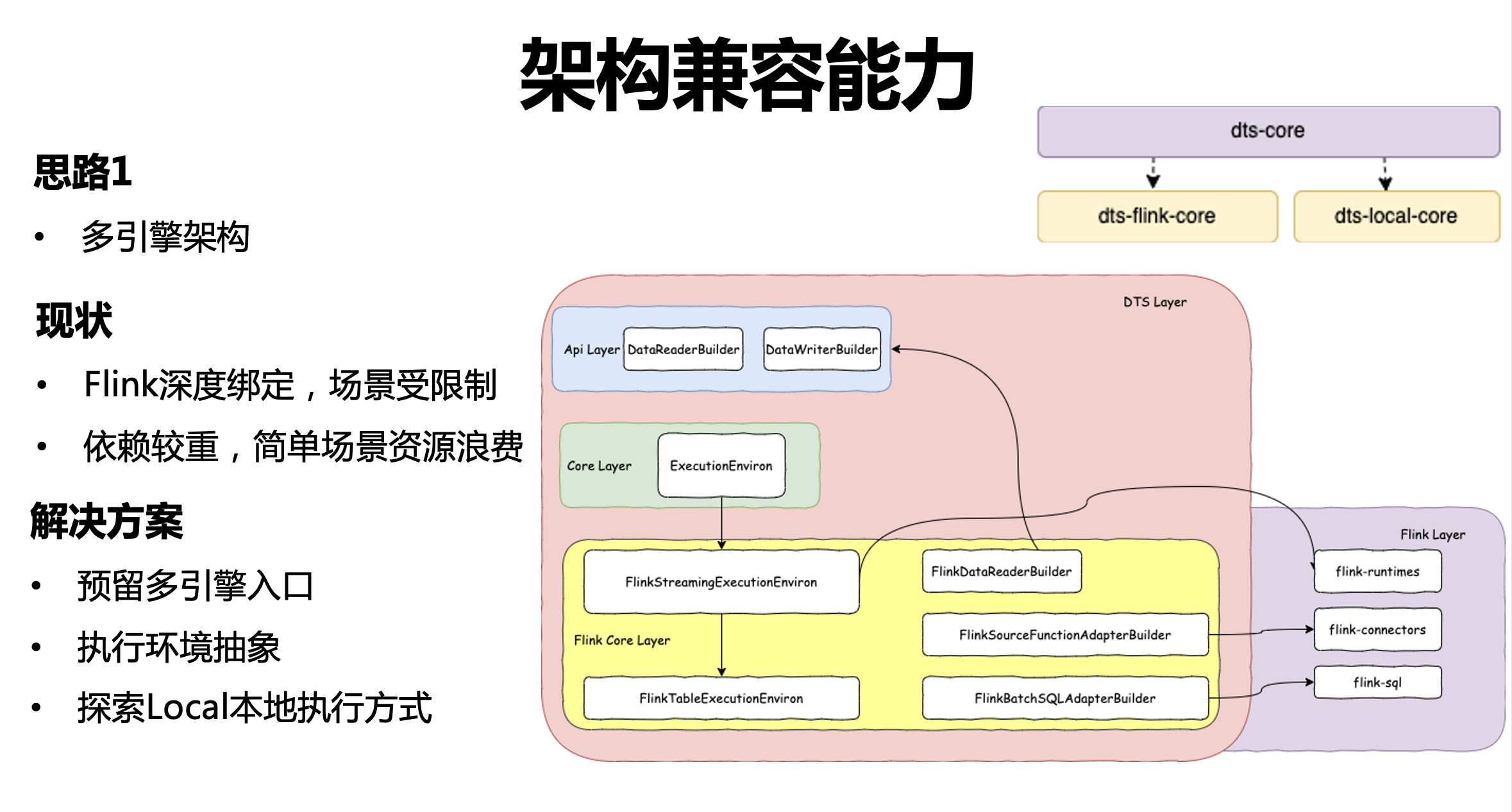
當前架構和 Flink 引擎深度系結,在使用場景方面受到一定的限制,比如有些客戶用了 Spark 引擎或者其他引擎,Flink 引擎依賴比較重的情況下,對于簡單場景和小資料量場景,整體的資源浪費比較嚴重,
為解決此問題,我們在引擎層預留了多引擎入口,在已經預留的 Flink 引擎基礎之上,接下來會擴展到 Spark 引擎或者 Local Engine,具體實作方面,我們對執行的環境進行了一層抽象,不同的引擎會去實作我們的抽象類,同時,我們探索 Local 執行方式,對小資料量在本地通過執行緒的方式來解決,不用去啟動 Flink Job 或類似的處理,提高整體資源的使用效率,
② 依賴隔離

目前系統存在一些外部環境中沒有的內部依賴,大資料底座也是系結的公司內部版本,我們進行了三個方面的優化:
-
剔除公司內部依賴,采取開源的通用解決方案,以應對不同的業務場景,
-
大資料底座方面,采用 Provided 依賴,不系結固定底座,運行時由外部指定,針對不兼容的場景,通過 Maven Profile 和 Maven Shade 隔離,
-
針對資料源多版本和版本不兼容的問題,采取動態加載的策略,將資料源做成獨立的組件,每次只會加載需要的資料源,以達到隔離的目標,
未來展望
BitSail 希望資料暢通無阻地航行到有價值的地方,期待和大家共同合作,完善資料集成的功能和生態,同時未來我們將在三個方面繼續深化:
① 多引擎架構:探索 Local Engine 落地,支持本地執行,對簡單場景和小資料量場景提高資源利用率;實作引擎智能選擇策略,針對簡單場景使用 Local Engine;針對復雜場景復用大資料引擎的能力,
② 通用能力建設:推廣新介面,對用戶屏蔽引擎細節,降低 Connector 開發成本
探索 Connector 多語言方案,
③ 流式資料湖:統一 CDC 資料入湖解決方案,在性能上穩定支撐千萬級 QPS
在資料湖平臺能力構建方面,全面覆寫批式、流式、增量使用場景,
進入 BitSail 代碼倉庫:https://github.com/bytedance/bitsail
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/526935.html
標籤:其他