什么是集群
能夠對外提供相同服務的多臺服務器組成的集合,
為什么要建立集群
1.從可用性角度考慮,如果只有一臺機器提供服務,一旦出現故障,那么整個服務不可用,
2.從容量角度考慮,當服務訪問量上升,單臺機器無法支撐訪問量時,必然要擴容,
如何建立集群
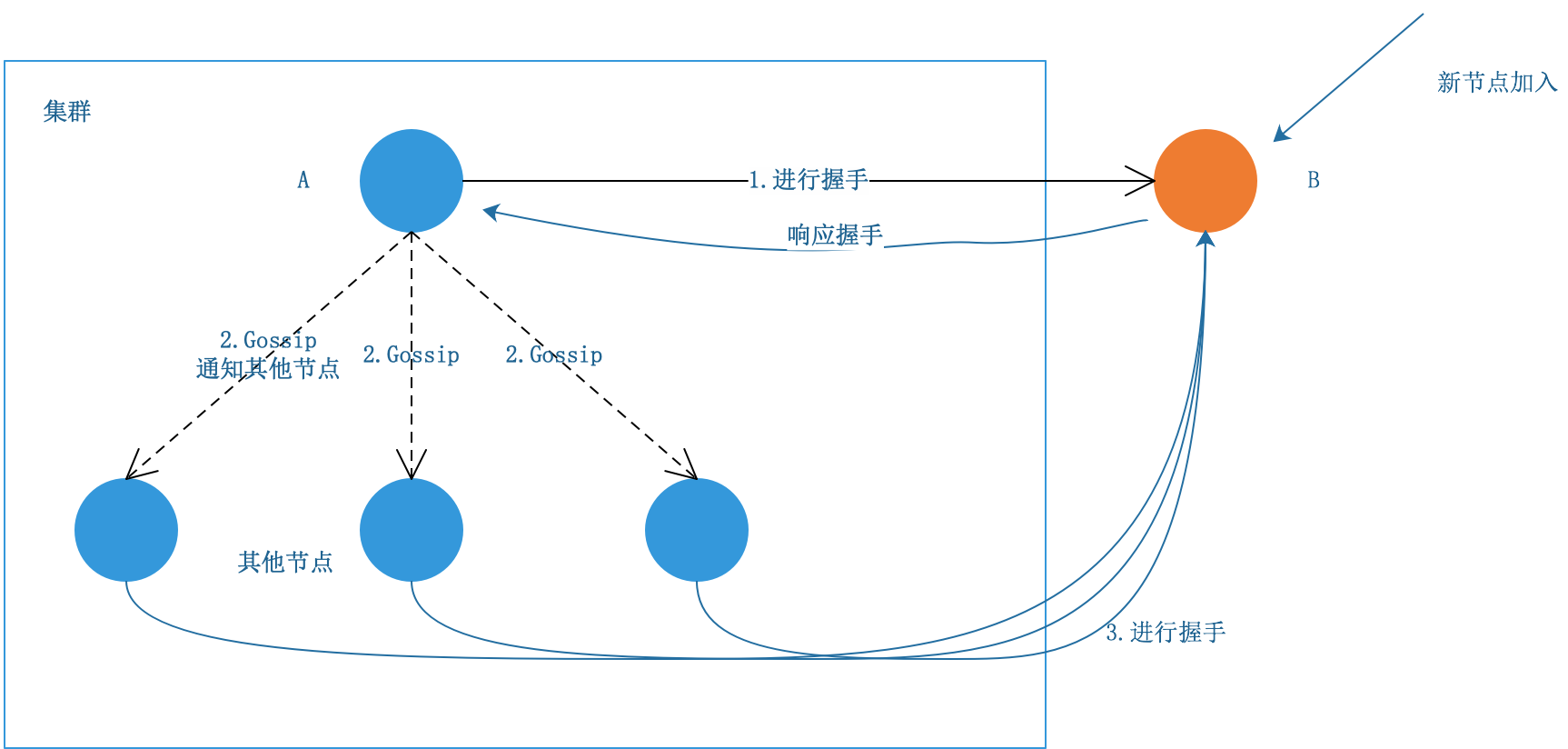
當有新的節點要加入集群時,客戶端可以任選集群中的一個節點,比如A,跟新節點B通過握手建立連接,然后A會將B加入的資訊通過Gossip訊息通知給集群中的其他節點,其他節點也通過握手跟新節點建立連接,
這里面有幾個問題需要回答:
如何進行握手?
如何進行集群狀態同步?
如何保存/尋址鍵值對?
如何進行擴容?
如何進行故障轉移?
集群資料結構
在介紹具體功能之前,我們先介紹一下集群的資料結構,
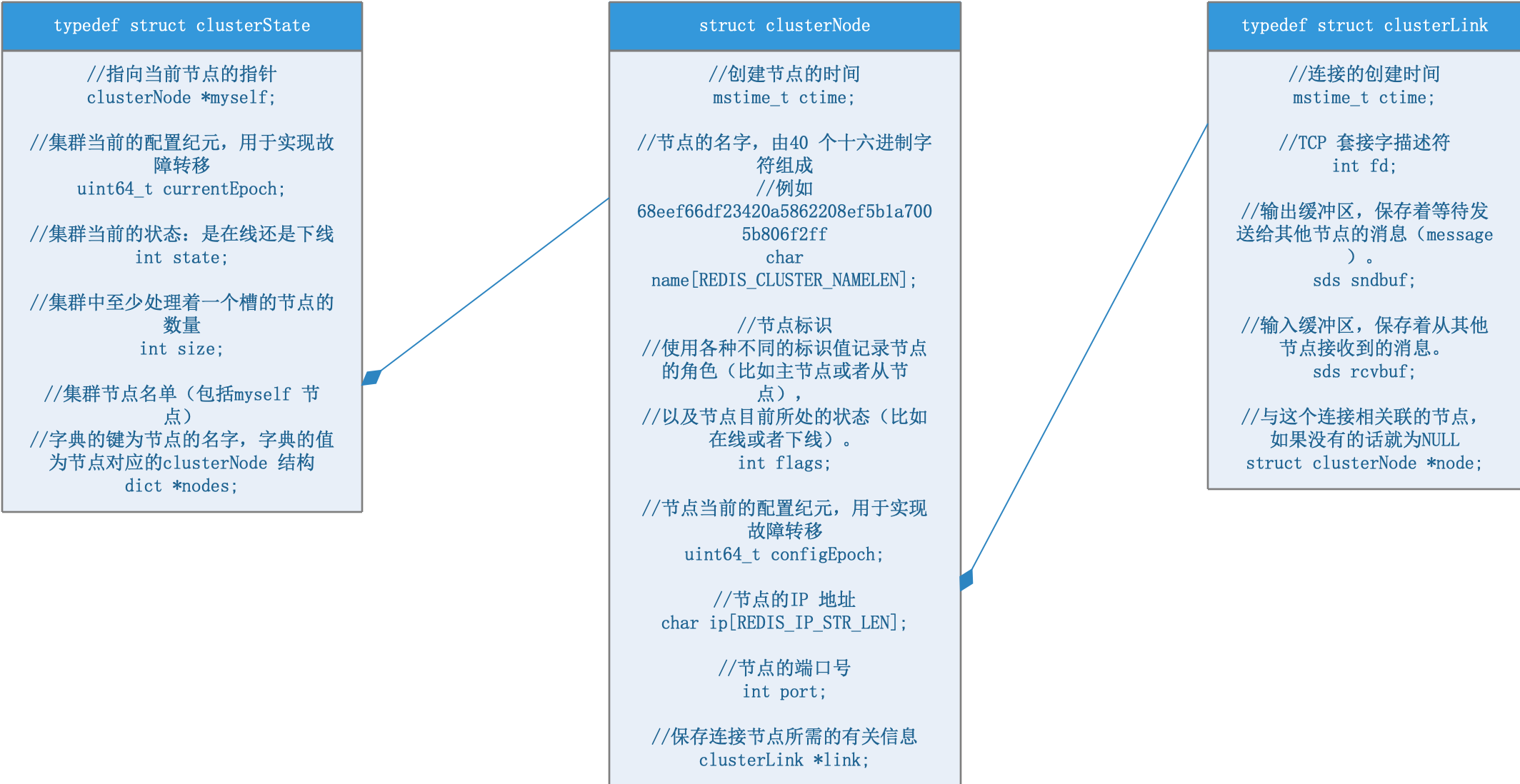
typedef struct clusterState {
// 指向當前節點的指標
clusterNode *myself;
// 集群當前的配置紀元,用于實作故障轉移
unit64_t currentEpoch;
// 集群當前的狀態:是在線還是下線
int state;
// 集群中至少處理著一個槽的節點的數量
int size;
// 集群節點名單(包括myself節點),字典的鍵為節點的名字,字典的值為節點對應的clusterNode結構
dict *nodes;
// 記錄了集群中所有16384個槽的指派資訊
clusterNode *slots[16384];
// 使用跳躍表保存槽和鍵之間的關系
zskiplist *slots_to_keys;
// 記錄當前節點正在從其他節點倒入的槽
clusterNode *importing_slots_from[16384];
// 記錄當前節點正在遷移至其他節點的槽
clusterNode *migrating_slots_to[16384];
} clusterState;
struct clusterNode {
// 創建節點的時間
mstime_t ctime;
// 節點的名字,由40個字十六進制字串組成
char name[REDIS_CLUSTER_NAMELEN];
// 節點的標識,使用各種不同的標識值記錄節點的角色(比如主節點或者從節點),以及節點目前所處的狀態(比如在線或者下線)
int flags;
// 節點當前的配置紀元,用于實作故障轉移
uint64_t configEpoch;
// 節點IP地址
char ip[REDIS_IP_STR_LEN];
// 節點的埠號
int port;
// 保存連接節點所需的有關資訊
clusterLink *link;
// 二進制位陣列,記錄節點負責處理哪些槽
unsigned char slots[16384/8];
// 記錄節點負責處理的槽的數量,即是slots陣列中值為1的二進制位的數量
int numslots;
// 如果這是個從節點,指向要復制的主節點的clusterNode結構
struct clusterNode *slaveof;
// 正在復制這個主節點的從節點數量
int numslaves;
// 一個資料組,每個陣列項指向一個正在復制這個主節點的從節點的clusterNode結構
struct clusterNode **slaves;
// 一個鏈表,記錄了所有其他節點對該節點的下線報告, 每個下線報告由一個clusterNodeFailReport結構表示
list *fail_reports;
};
typedef struct clusterLink {
// 連接的創建時間
mstime_t ctime;
// TCP 套接字描述符
int fd;
// 輸出緩沖區,保存著待發送給其他節點的訊息(message)
sds sndbuf;
// 輸入緩沖區,保存著從其他節點接收到的訊息
sds rcvbuf;
// 與這個連接相關聯的節點,如果沒有的話就為NULL
struct clusterNode *node;
} clusterLink;
struct clusterNodeFailReport {
// 報告目標節點已經下線的節點
struct clusterNode *node;
// 最后一次從node節點收到下線報告的時間
// 程式使用這個時間戳來檢查下線報告是否過期
// (與當前時間戳相差太久的下線報告會被洗掉)
mstime_t time;
}
每個Redis服務器上都維護一個集群狀態物件clusterState,記錄了集群狀態、集群版本號、當前節點、集群中所有的節點名單、槽指派資訊、槽和鍵的關系、槽遷移資訊,這些資訊會在相應的場景中用到,
如何進行握手
通過MEET命令實作節點之間握手建聯,
命令格式:
CLUSTER MEET <ip> <port>
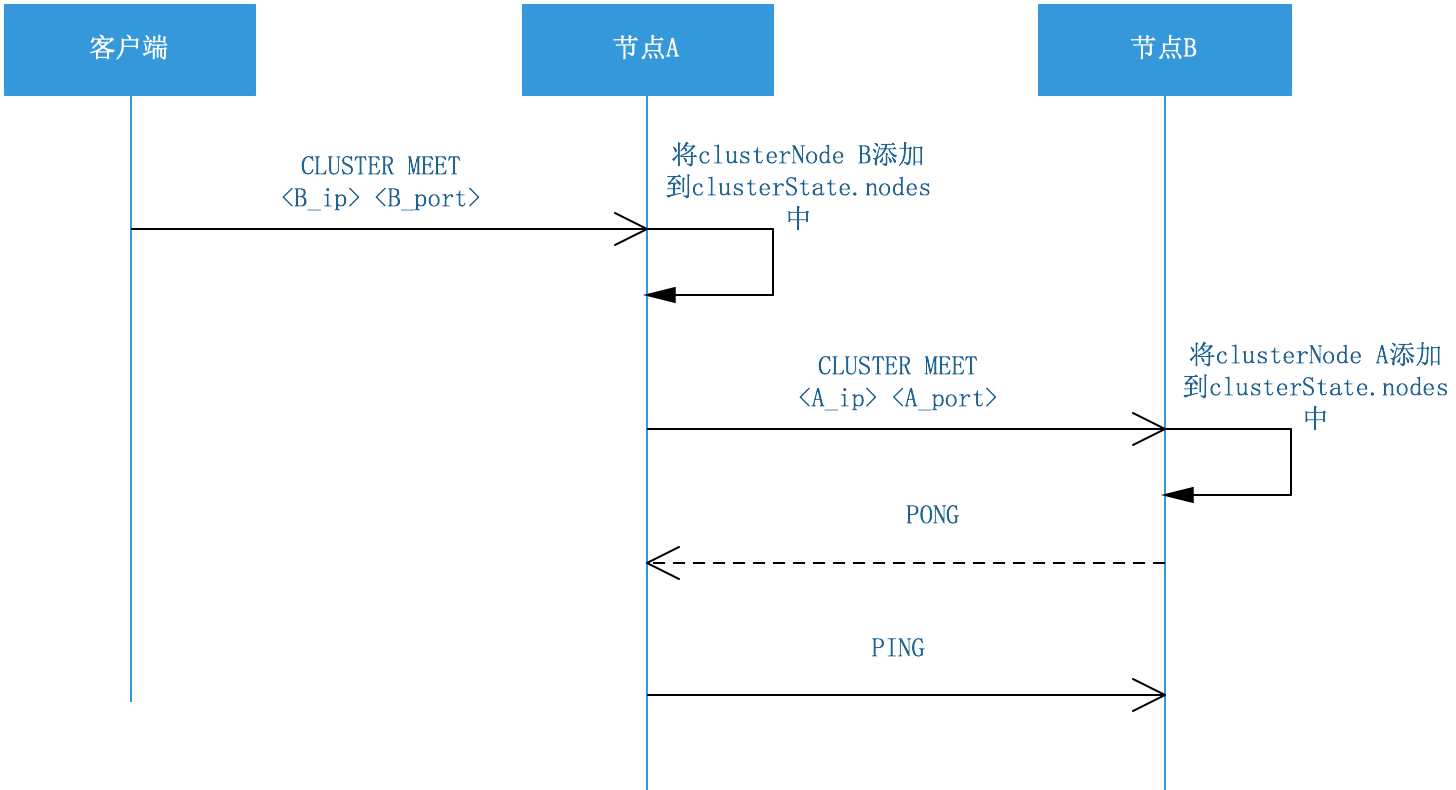
首先客戶端向節點A發送MEET命令,將節點B加入到A的集群狀態物件中,然后A再向B發送MEET命令,將節點A加入到B的集群狀態物件中,然后B向A發送一個PONG訊息作為回應,A收到B的PONG訊息再回復一個PING訊息作為回應,這樣通過3次握手,A跟B建立了連接,然后A通過Gossip訊息廣播給集群中的其他節點,其他節點以同樣的方式跟B建立連接,
握手的程序:
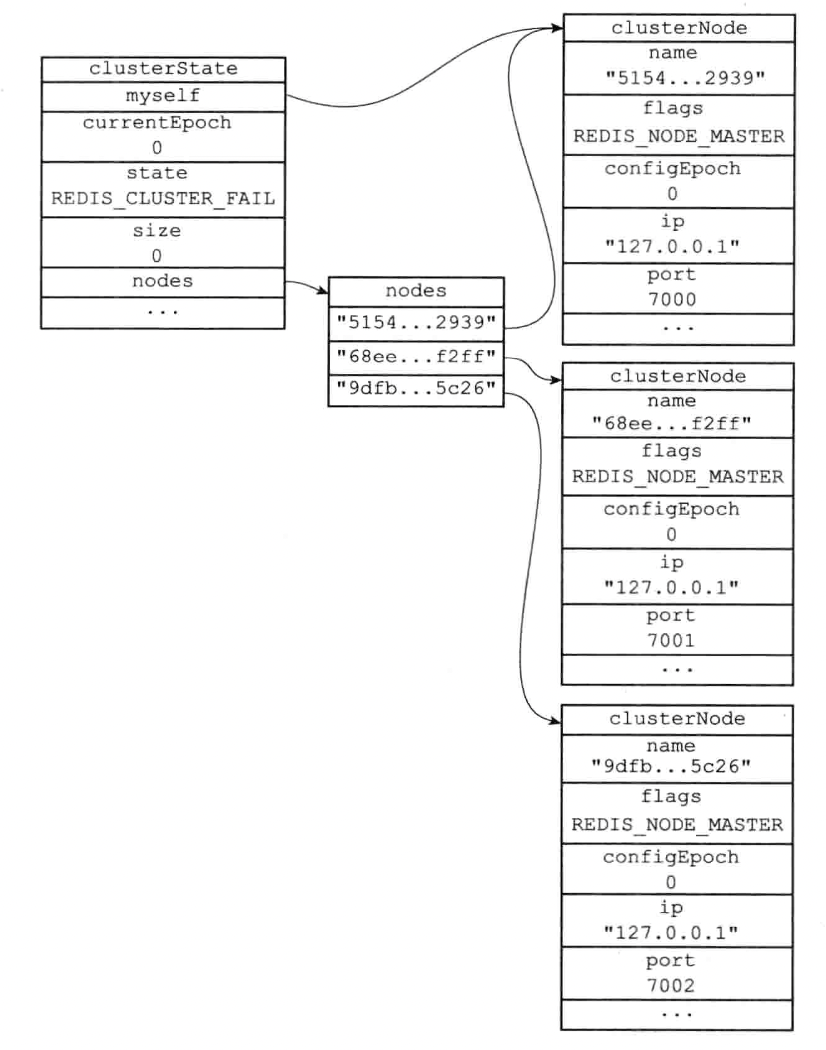
假設節點A的IP、埠分別為127.0.0.1:7000,節點B的IP、埠分別為127.0.0.1:7001,節點C的IP、埠分別為127.0.0.1:7002,以下展示的是節點A的集群狀態物件clusterState,
如何進行狀態同步
剛剛講到節點之間通過Gossip訊息進行狀態同步,感興趣的可以了解一下Gossip協議介紹,
https://blog.csdn.net/qq_43590614/article/details/115131473
https://zhuanlan.zhihu.com/p/162970961
集群如何保存鍵值對
槽指派
集群的整個資料庫被分為16384個槽,每個鍵值對都屬于這16384個槽中的一個,每個節點可以處理0個或最多16384個槽,
當資料庫中16384個槽都有節點在處理時,集群處于上線狀態;相反地,如果有任何一個槽沒有節點處理,那么集群處于下線狀態,
通過CLUSTER ADDSLOTS <slot> [slot ...]命令將槽指派給節點負責,
舉例:
將槽0-5000指派給節點7000負責:
127.0.0.1:7000> CLUSTER ADDSLOTS 0 1 2 ... 5000
將槽5001-10000指派給節點7001負責:
127.0.0.1:7001> CLUSTER ADDSLOTS 5001 5002 5003 ... 10000
將槽10001-16383指派給節點7002負責:
127.0.0.1:7002> CLUSTER ADDSLOTS 10001 10002 10003 ... 16383
進行槽指派前執行CLUSTER INFO:
127.0.0.1:7000> CLUSTER INFO
cluster_state:fail
進行槽指派后執行CLUSTER INFO:
127.0.0.1:7000> CLUSTER INFO
cluster_state:ok
說明槽指派完成后,集群進入上線狀態,
接下來介紹節點保存槽指派資訊的方法,以及節點之間傳播槽指派資訊的方法,
所謂槽,其實就是二進制位,節點用二進制陣列來保存槽資訊,
struct clusterNode {
// ...
// 二進制位陣列,記錄節點負責處理哪些槽
unsigned char slots[16384/8];
// 記錄節點負責處理的槽的數量,即是slots陣列中值為1的二進制位的數量
int numslots;
// ...
};
如果slots陣列在索引i上的二進制位的值為1,那么表示節點負責處理槽i,
如果slots陣列在索引i上的二進制位的值為0,那么表示節點不負責處理槽i,

傳播節點的槽指派資訊
節點除了會將自己負責處理的槽資訊記錄在clusterNode結構的slots屬性和numslots屬性之外,還會將自己的slots陣列通過訊息發送給集群中的其他節點,來告訴其他節點自己目前負責處理哪些槽,
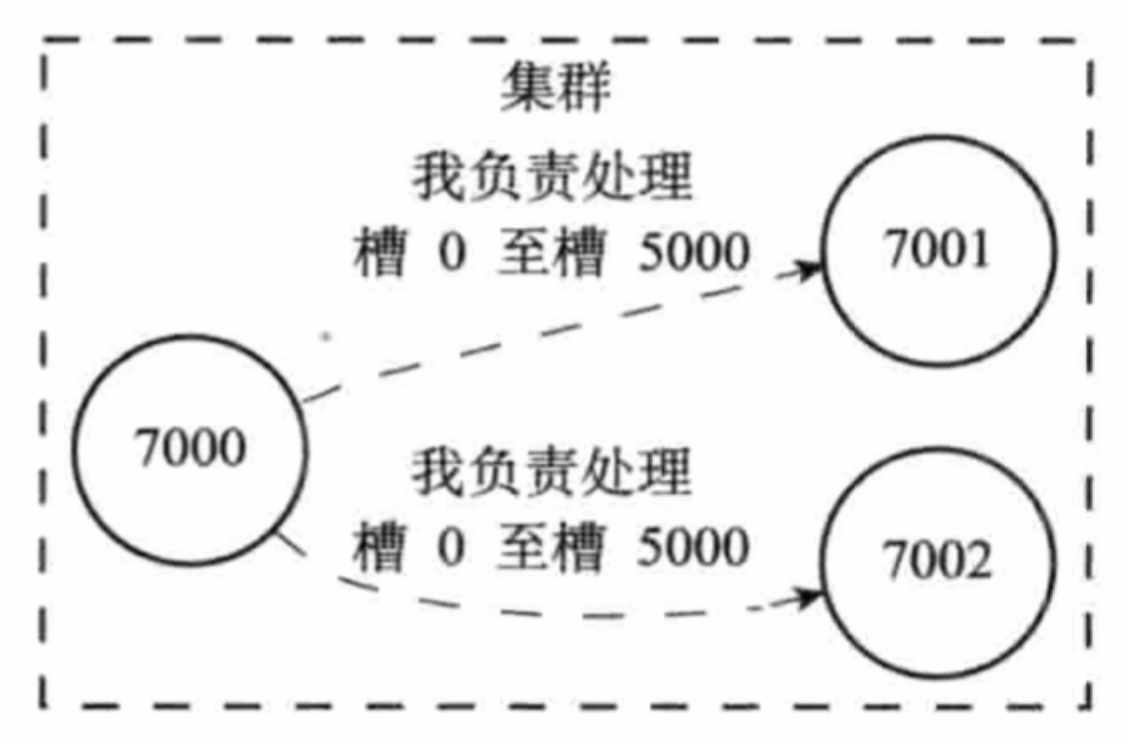
當節點A通過訊息從節點B那里接收到節點B的slots陣列時,節點A會在自己的clusterState.nodes字典中查找節點B對應的clusterNode結構,并對結構中的slots陣列進行保存或者更新,
這樣集群中的每個節點都會知道資料庫中的16384個槽分別被指派給了哪些節點,
記錄集群所有槽的指派資訊:
typedef struct clusterState {
// ...
// 記錄了集群中所有16384個槽的指派資訊
clusterNode *slots[16384];
// ...
} clusterState;
slots陣列包含16384個項,每個陣列項都是一個指向clusterNode結構的指標:
如果slots[i]指標指向NULL,那么表示槽i尚未指派給任何節點,
如果slots[i]指標指向一個clusterNode結構,那么表示槽i已經指派給了clusterNode結構所代表的節點,
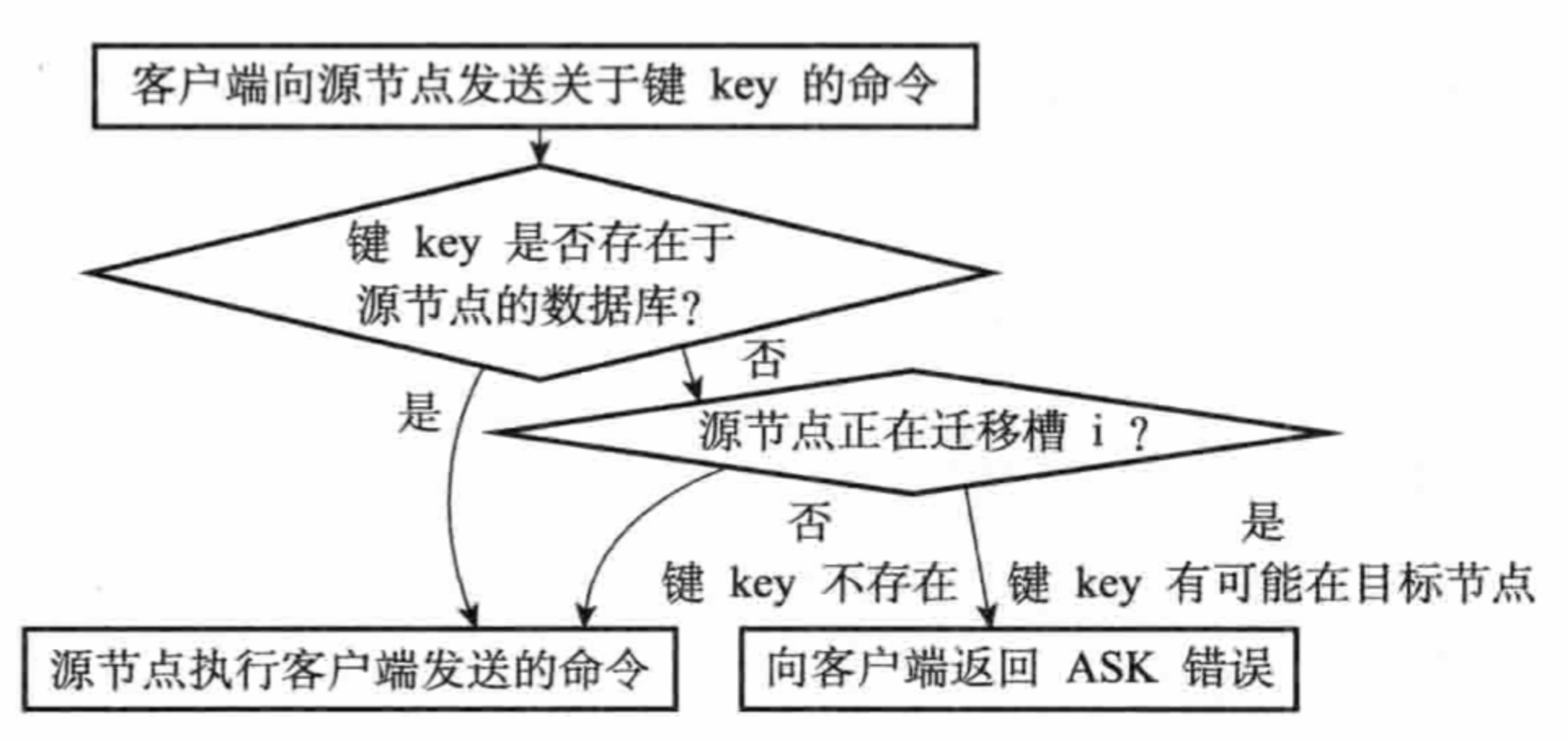
集群如何尋址鍵值對
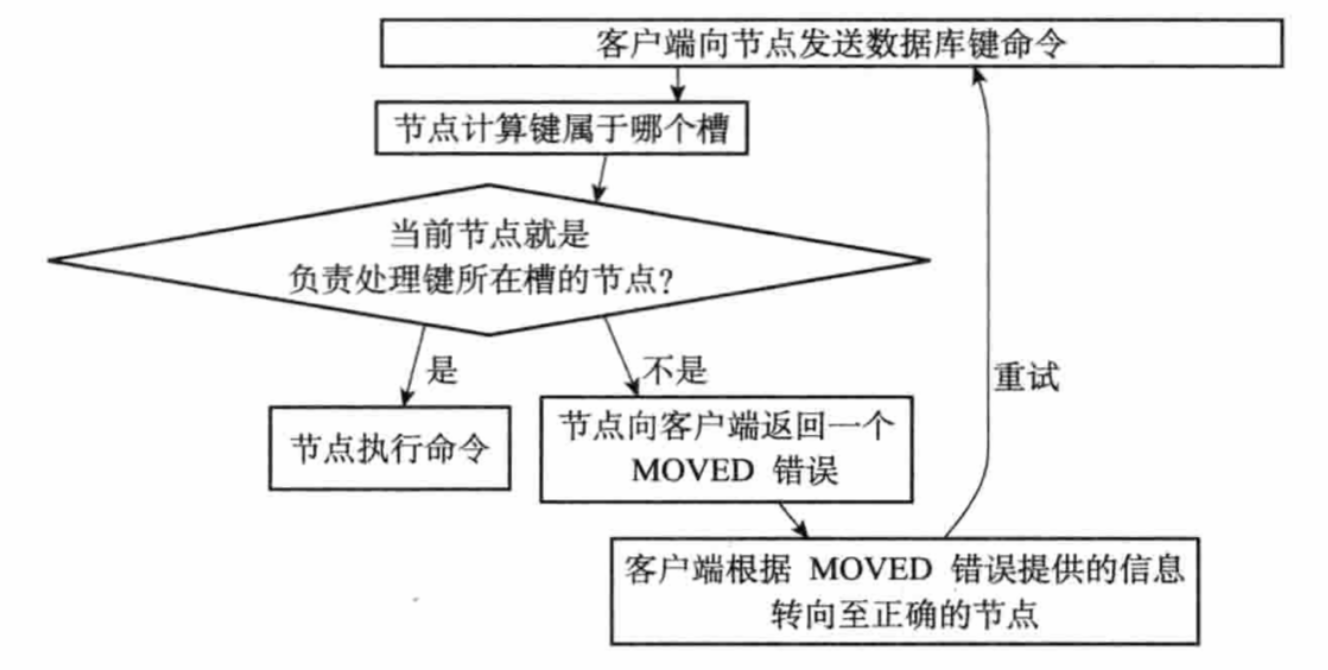
當客戶端向節點發送資料庫鍵命令,節點會計算出鍵屬于哪個槽,再判斷這個槽是否指派給了自己:
- 如果鍵所在槽指派給了當前節點,那么節點直接執行這個命令;
- 如果鍵所在槽沒有指派給當前節點,那么節點會向客戶端回傳一個MOVED錯誤,將客戶端重定向到正確的節點,并再次發送之前要執行的命令,
判斷流程如下:
計算鍵屬于哪個槽
def slot_number(key):
return CRC16(key) & 16383
先計算key的CRC16校驗碼,再對16383取余,計算出一個介于0-16383之間的整數作為鍵的槽號,
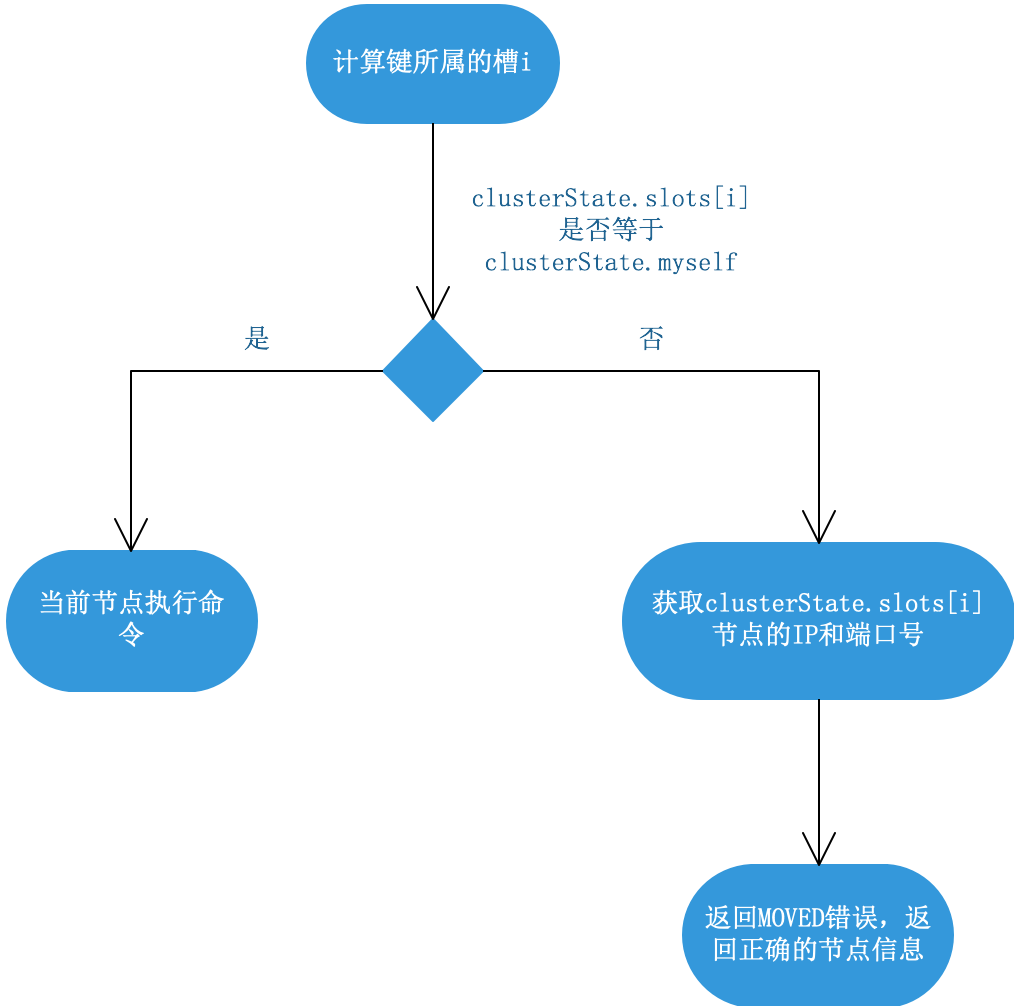
判斷槽是否由當前節點負責處理
判斷clusterState.slots[i]對應的節點是否等于clusterState.myself,如果等于,由當前節點處理;不等于,回傳MOVED錯誤,指向clusterState.slots[i]對應的節點,
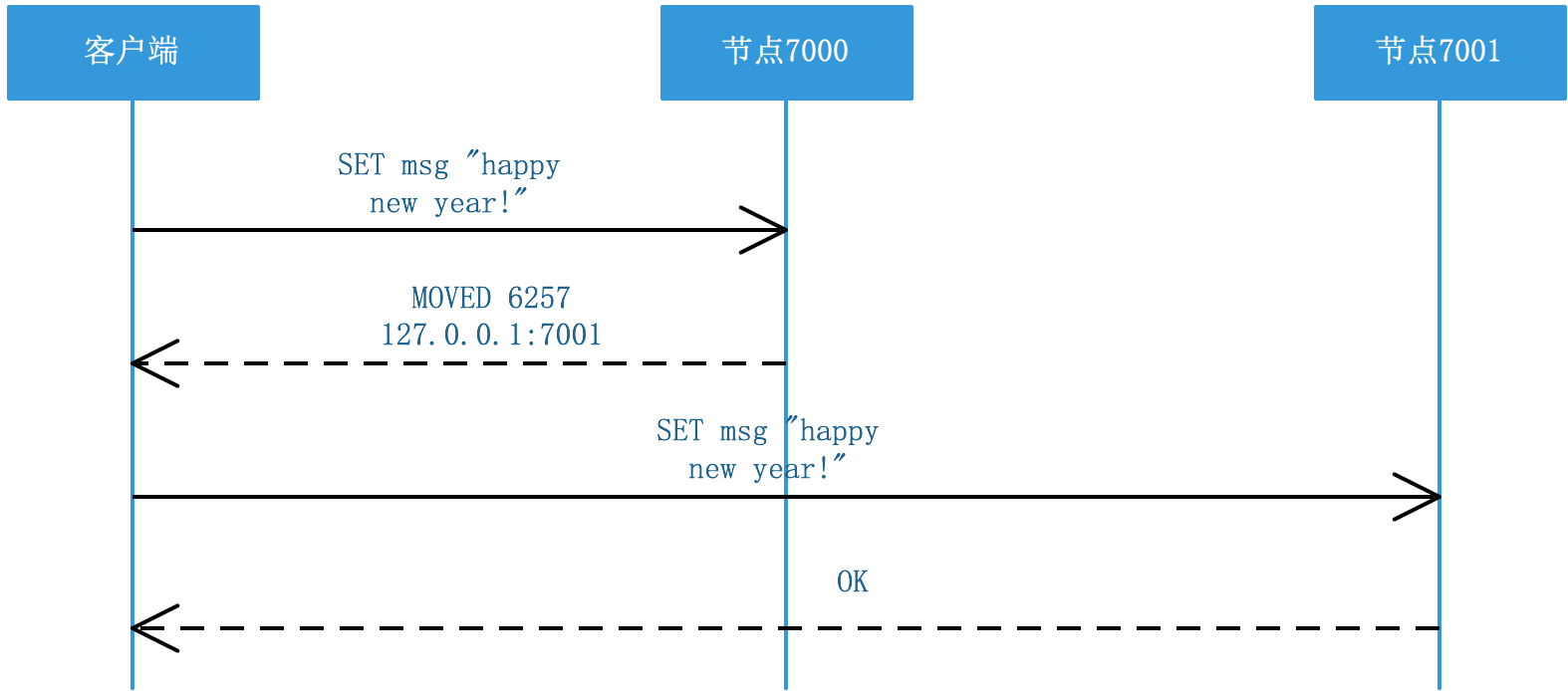
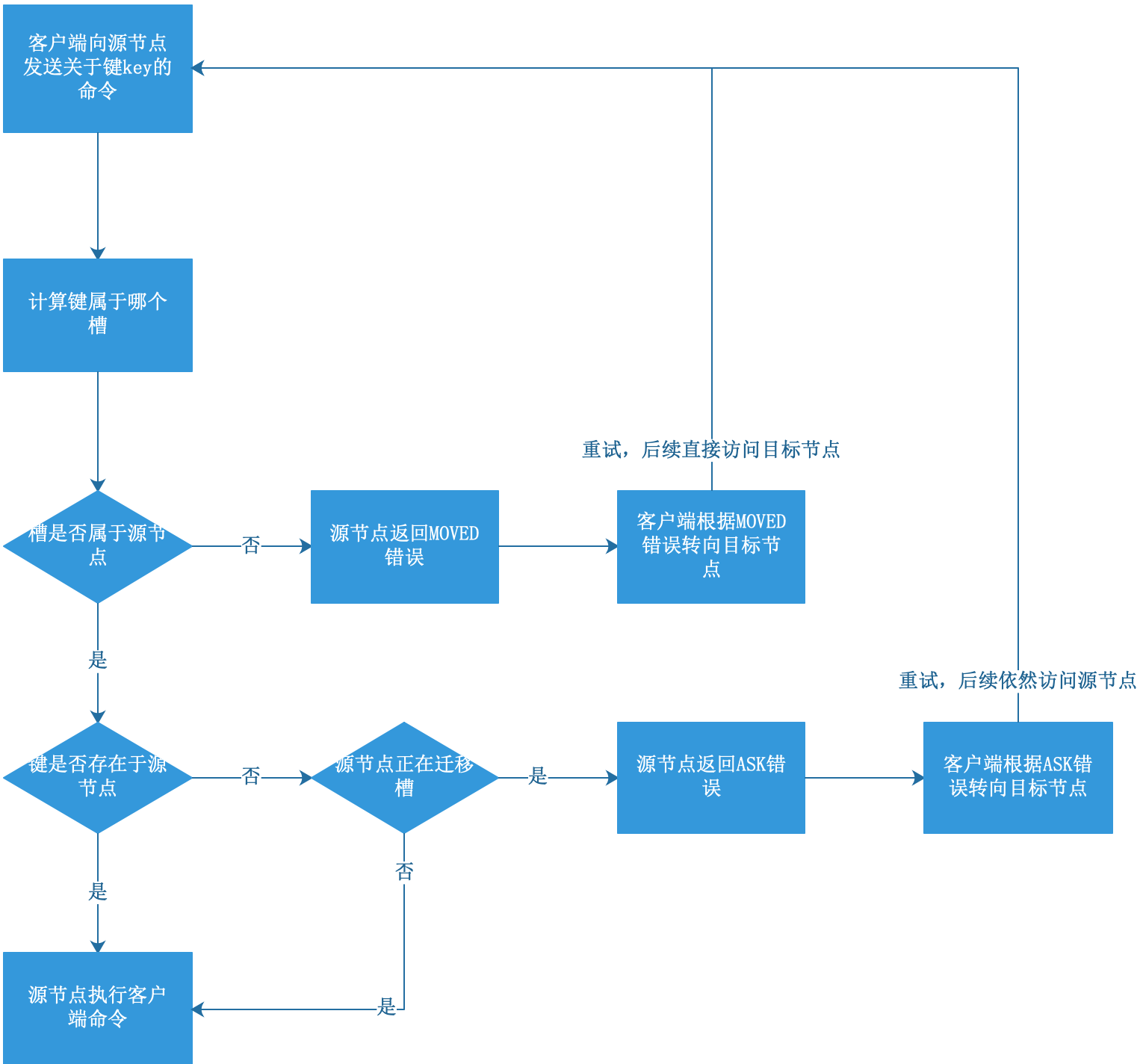
MOVED錯誤
當節點發現鍵所在的槽不是由自己處理時,會向客戶端回傳一個MOVED錯誤,并將客戶端重定向到正確的節點,
MOVED錯誤的格式:
MOVED <slot> <ip>:<port>
其中slot為鍵所在的槽,ip和port為負責處理槽的節點IP和埠號,
例如:
MOVED 10086 127.0.0.1:7002
表示槽10086由IP為127.0.0.1,埠號為7002的節點處理,
集群擴容/縮容如何重新分片
當集群需要擴容或縮容時,機器數變了,為了保證槽分布均勻,需要對槽重新指派,并且屬于槽的鍵值對也要做相應的遷移,
重新分片操作可以在線進行,在重新分片的程序中,集群不需要下線,并且源節點和目標節點都可以繼續處理命令請求,
重新分片的實作原理
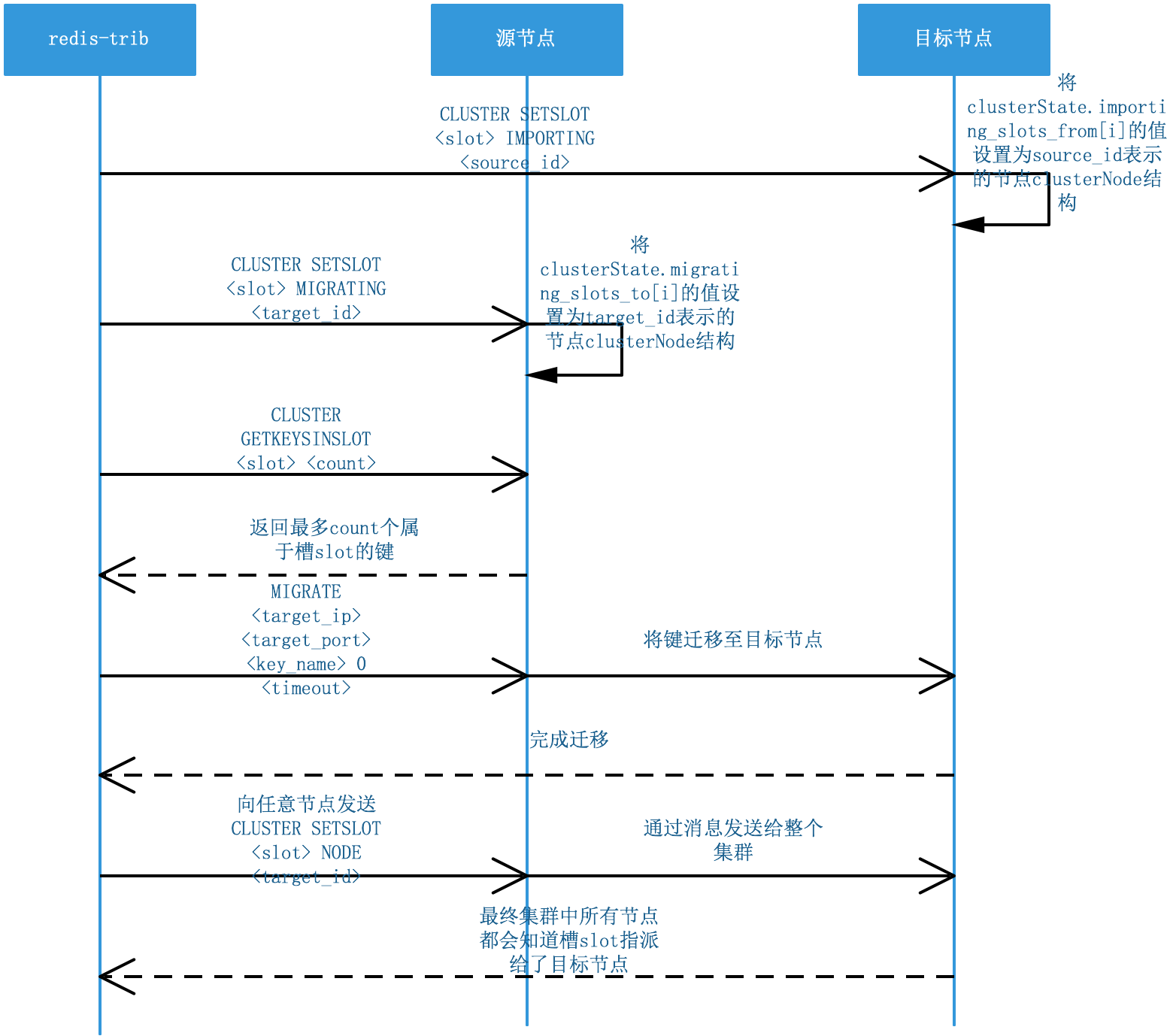
ASK錯誤
在進行重新分片程序中,源節點的某個槽正在進行遷移,屬于被遷移槽的一部分鍵值對保存在源節點里面,另一部分鍵值對保存在目標節點里面,這時候如果節點收到一個關于鍵的命令,需要判斷鍵所屬的槽是否發生遷移,
集群執行命令的完整程序(考慮MOVED錯誤和ASK錯誤):
集群如何進行故障轉移
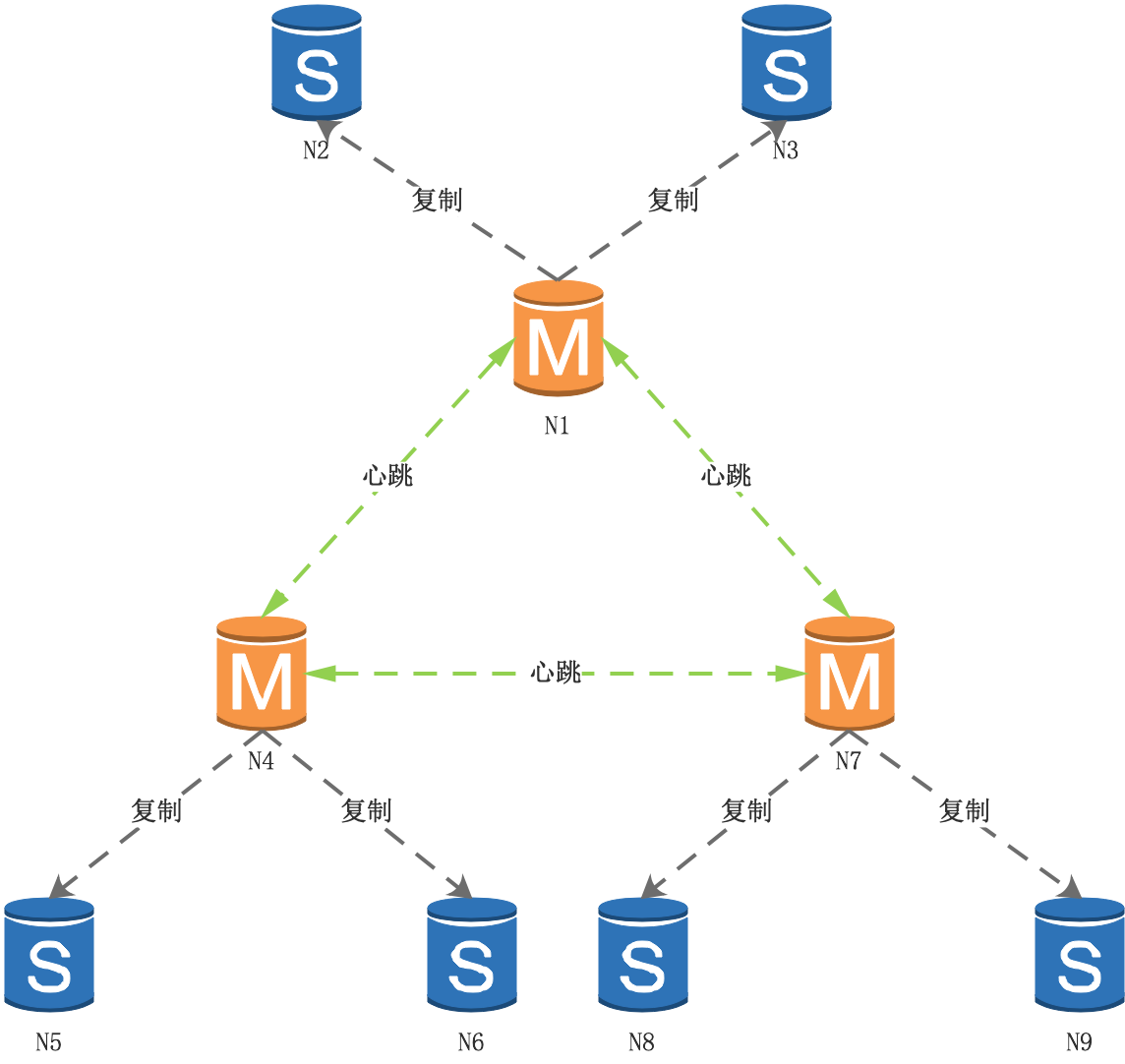
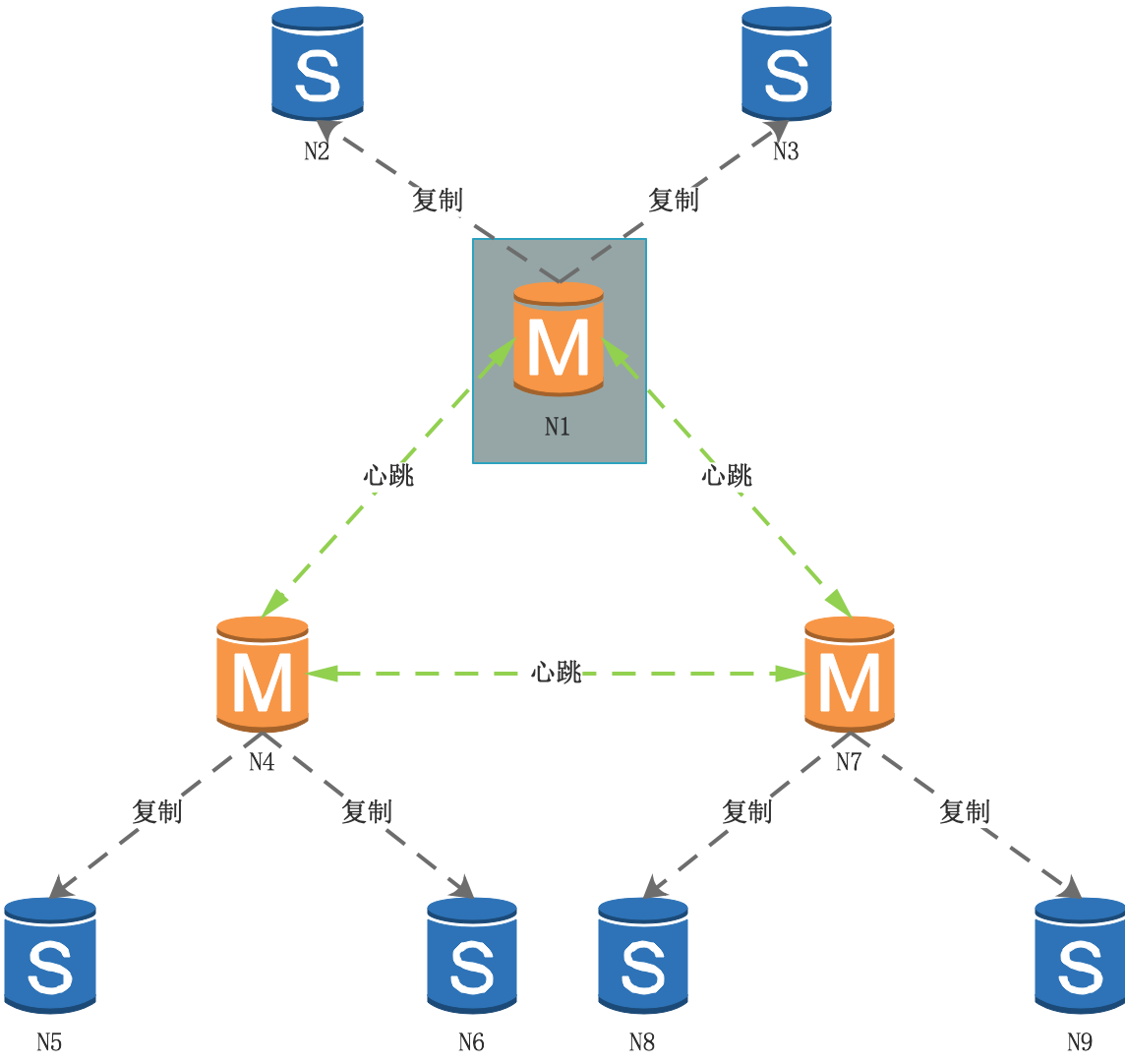
節點N1、N4、N7是主節點,節點N2、N3、N5、N6、N8、N9為從節點,
集群進行故障檢測到N1進入下線狀態:
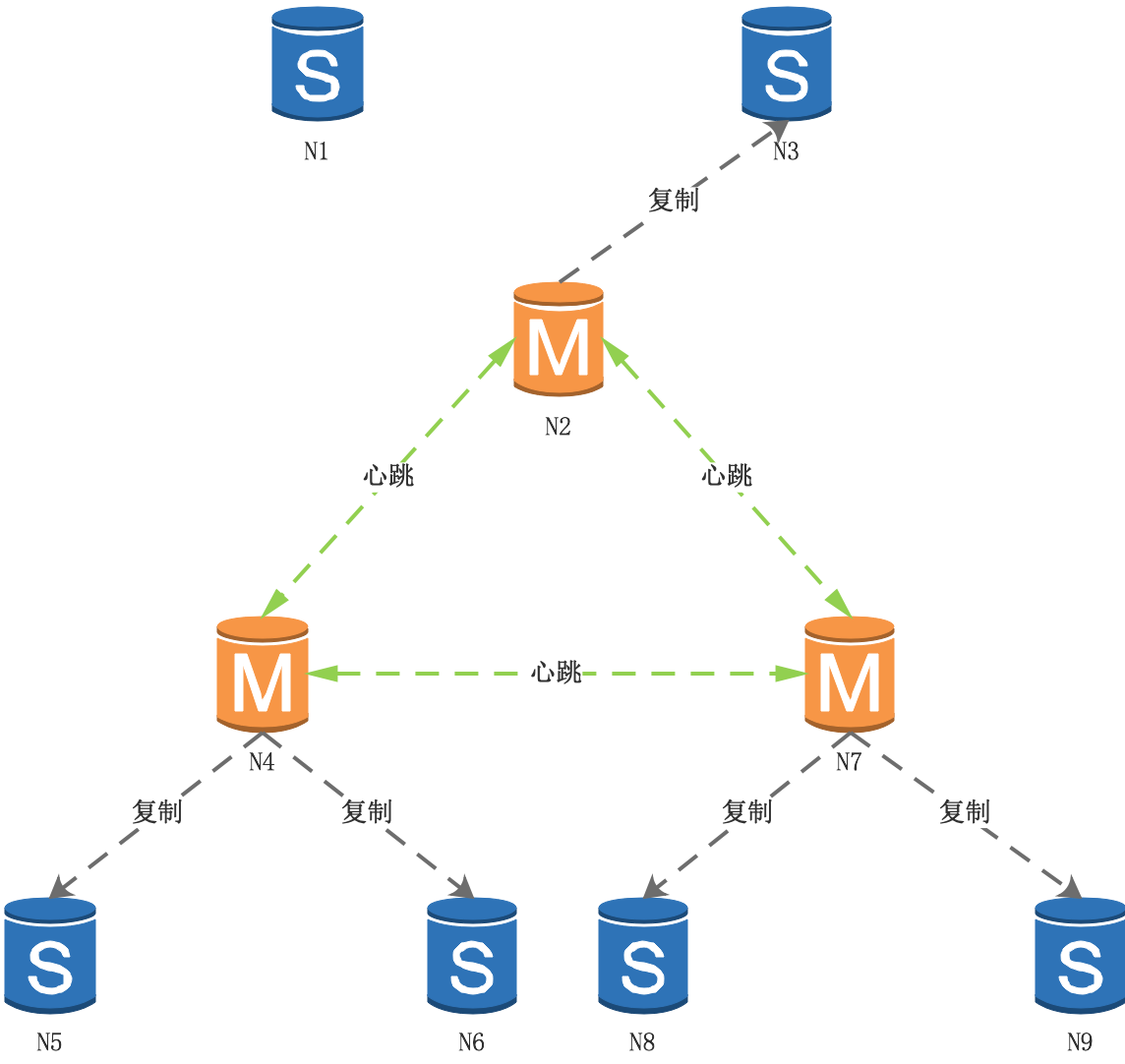
集群通過選舉演算法,從N1的從節點中選出新的主節點,比如N2被選為新的主節點:
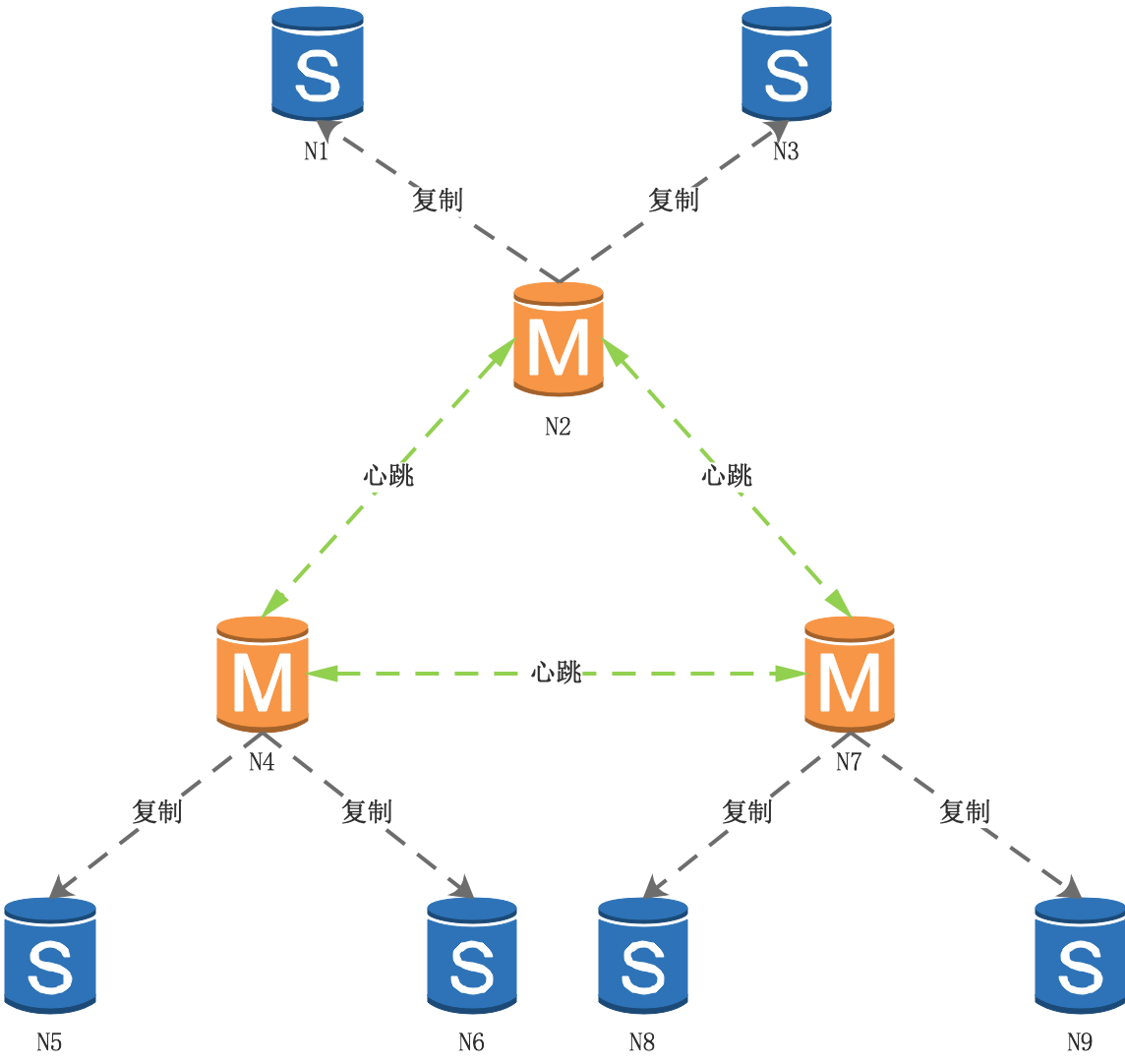
當節點N1重新上線,成為N2的從節點:
這里涉及到幾個重要的程序,故障檢測、故障轉移、選舉主節點、設定從節點,下面詳細說明,
故障檢測
集群中每個節點都會定期向其他節點發送PING訊息,來檢測對方是否在線,如果接收PING訊息的節點沒有在規定時間內回傳PONG訊息,那么發送PING訊息的節點就會將接收PING訊息的節點標記為疑似下線(probable fail,PFAIL),
集群中各個節點會通過互相發送訊息的方式來交換集群中各個節點的狀態,例如某個節點是處于在線狀態、疑似下線狀態(PFAIL),還是已下線狀態(FAIL),
當一個節點A收到B的訊息,B認為C疑似下線,A會在clusterState.nodes中找到C對應的clusterNode結構,將B的下線報告添加到clusterNode中的fail_reports鏈表里面,
如果A發現C的fail_reports中有超過半數的節點的下線報告,那么A會將C標記為已下線(FAIL),并將C已下線的訊息廣播給集群中的其他節點,所有收到FAIL訊息的節點都會將C標記為已下線,
(1)N4檢測N1心跳失敗,生成N1的心跳失敗記錄,
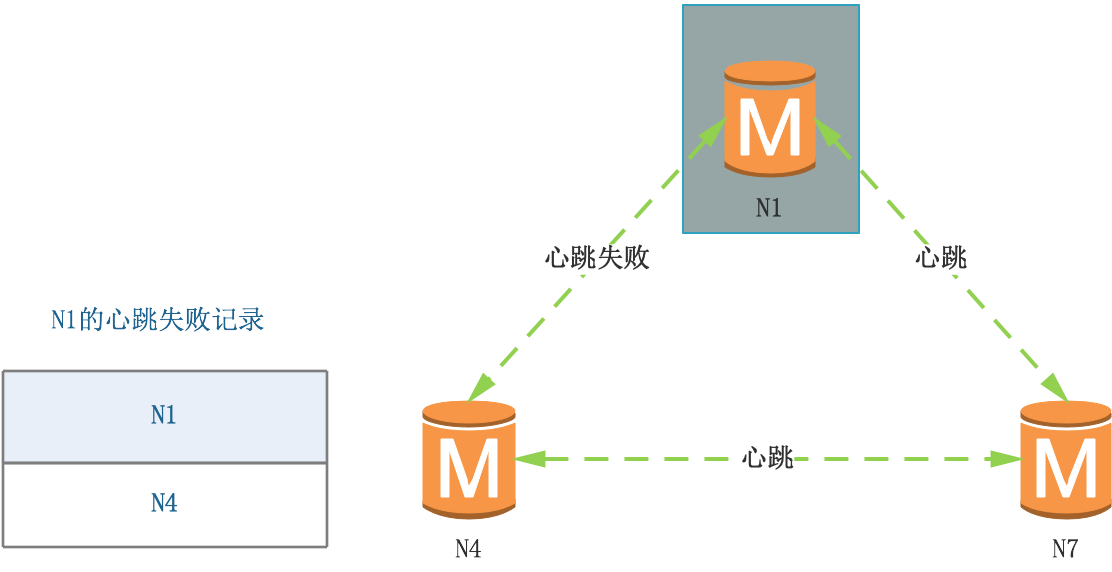
(2)N7檢測N1心跳失敗,生成N1的心跳失敗記錄,
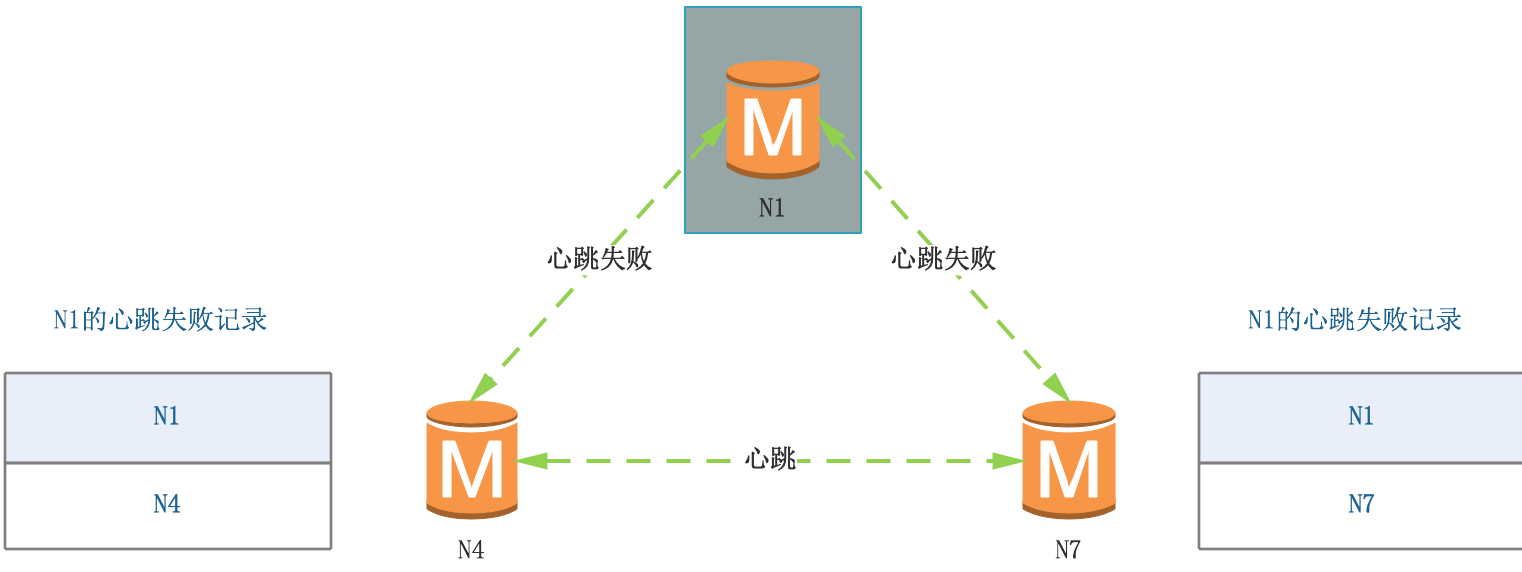
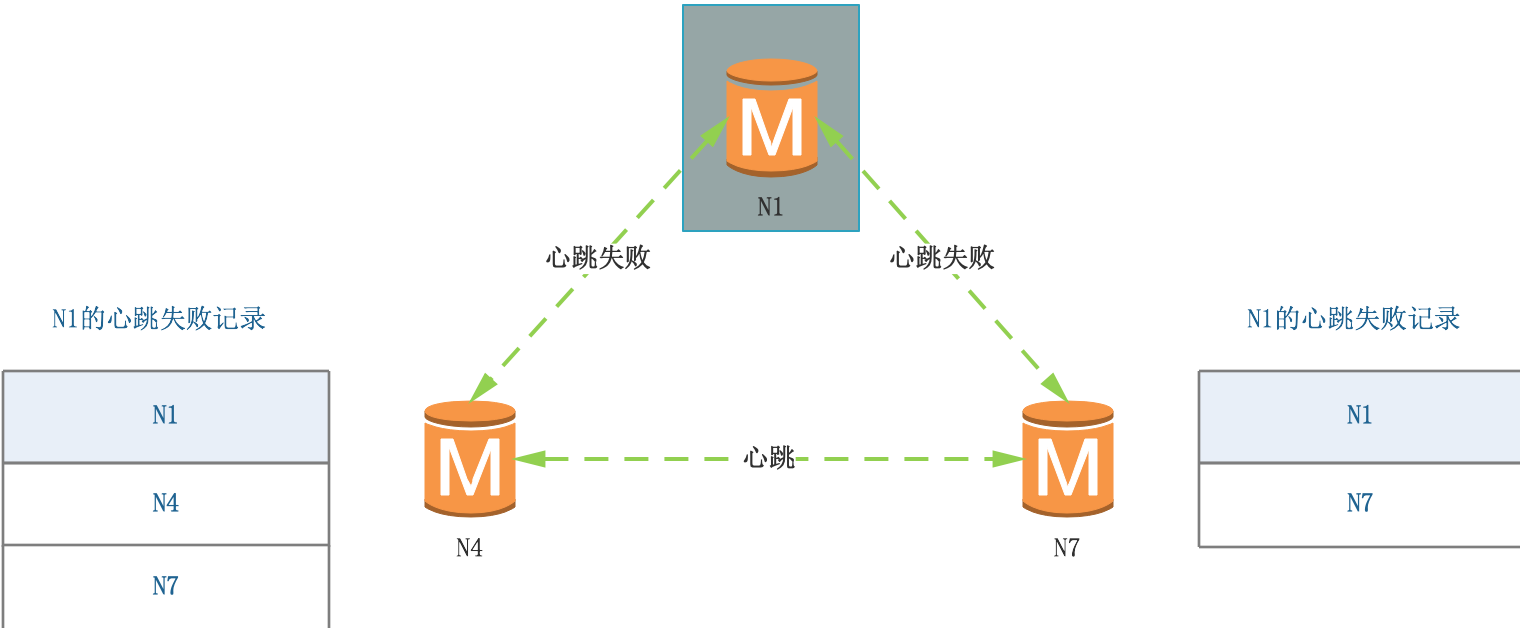
(3)N4、N7之間互相交換訊息,N4收到N7的訊息,合并心跳失敗記錄,
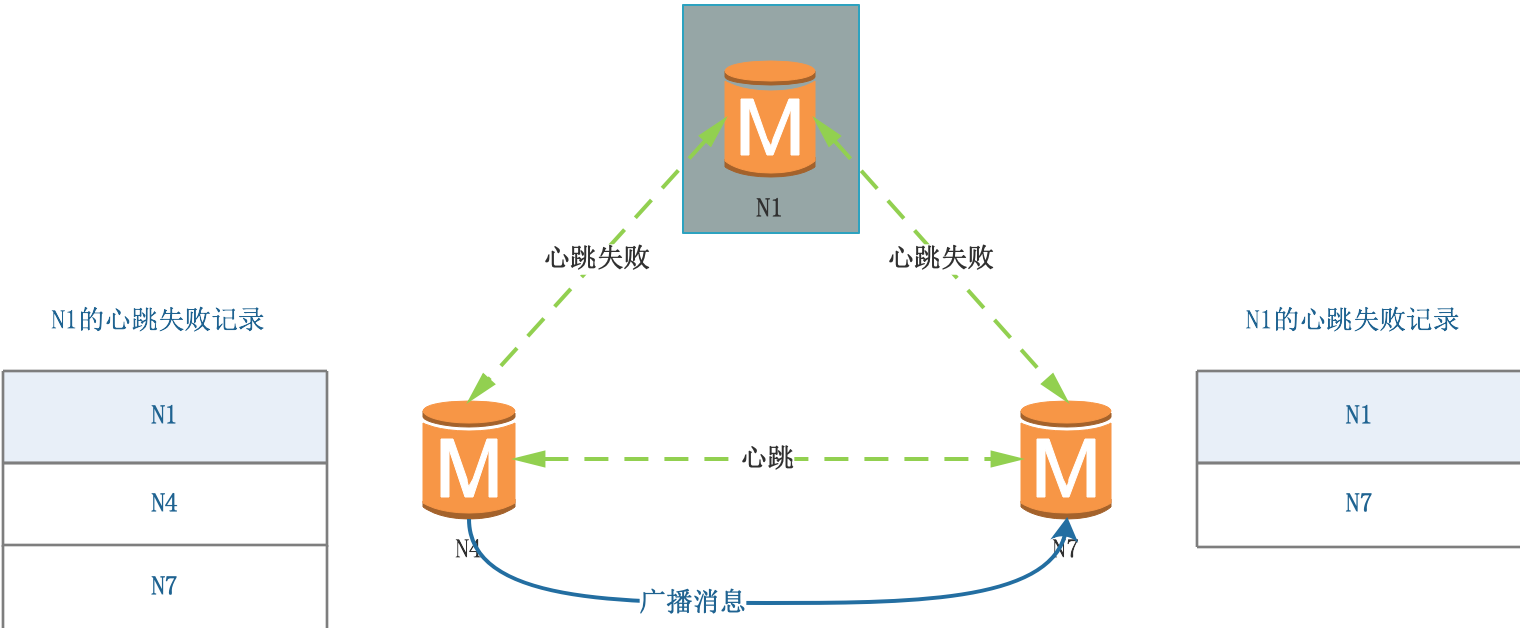
(4)N4檢測到超過半數節點的下線報告,標記N1為已下線,并廣播給其他節點,
故障轉移
當一個從節點發現自己正在復制的主節點進入了已下線狀態時,從節點將開始對下線主節點進行故障轉移,以下是故障轉移的執行步驟:
(1)復制下線主節點的所有從節點里面,會有一個從節點被選中,
(2)被選中的從節點會執行SLAVEOF no one命令,成為新的主節點,
(3)新的主節點會撤銷所有對已下線主節點的槽指派,并將這些槽全部指派給自己,
(4)新的主節點向集群廣播一條PONG訊息,這條PONG訊息可以讓集群中的其他節點立即知道這個節點已經由從節點變成了主節點,并且這個主節點已經接管了原本由已下線節點負責處理的槽,
(5)新的主節點開始接收和自己負責處理的槽有關的命令請求,故障轉移完成,
選舉新的主節點
以下是集群選舉新的主節點的方法:
(1)集群的配置紀元是一個自增計數器,它的初始值為0,
(2)當集群里的某個節點開始一次故障轉移操作時,集群配置紀元的值會被增一,
(3)對于每個配置紀元,集群里每個負責處理槽的主節點都有一次投票的機會,而第一個向主節點要求投票的從節點將獲得主節點的投票,
(4)當從節點發現自己正在復制的主節點進入已下線狀態時,從節點會向集群廣播一條CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST訊息,要求所有收到這條訊息、并且具有投票權的主節點向這個從節點投票,
(5)如果一個主節點具有投票權(它正在負責處理槽),并且這個主節點尚未投票給其他從節點,那么主節點將向要求投票的從節點回傳一條CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息,表示這個主節點支持從節點成為新的主節點,
(6)每個參與選舉的從節點都會接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息,并根據自己收到了多少條這種訊息來統計自己獲得了多少主節點的支持,
(7)如果集群里有N個具有投票權的主節點,那么當一個從節點收集到大于等于N/2+1張支持票時,這個從節點就會當選為新的主節點,
(8)因為在每一個配置紀元里面,每個具有投票權的主節點只能投一次票,所以如果有N個主節點進行投票,那么具有大于等于N/2+1張支持票的從節點只會有一個,這確保了新的主節點只會有一個,
(9)如果在一個配置紀元里面沒有從節點能收集到足夠多的支持票,那么集群進入一個新的配置紀元,并再次進行選舉,直到選出新的主節點為止,
這個選舉方法是基于Raft演算法實作的,
設定從節點
向一個節點發送命令:
CLUSTER REPLICATE <node_id>
可以讓接收命令的節點成為node_id所指定節點的從節點,并開始對主節點進行復制,
一個節點成為從節點,并開始復制某個主節點這一資訊會通過訊息發送給集群中的其他節點,最終集群中的所有節點都會知道某個從節點正在復制某個主節點,
集群中使用的訊息
訊息型別


訊息體
MEET、PING、PONG訊息的實作
Redis集群中的各個節點通過Gossip協議來交換各自關于不同節點的狀態資訊,其中Gossip協議由MEET、PING、PONG三種資訊來實作,這三種訊息的正文都由clusterMsgDataGossip結構組成的,
每次發送MEET、PONG、PING訊息時,發送者都從自己的已知節點串列中隨機選出兩個節點(可以是主節點也可以是從節點),并將這兩個被選中節點的資訊分別保存到兩個clusterMsgDataGossip結構里面,
clusterMsgDataGossip結構記錄了被選中節點的名字,發送者與被選中節點最后一次發送和接收PING訊息和PONG訊息的時間戳,被選中節點的IP地址和埠號,以及被選中節點的標識值,
當接收者收到MEET、PING、PONG訊息時,接收者會訪問訊息正文中的兩個clusterMsgDataGossip結構,并根據自己是否認識clusterMsgDataGossip結構中記錄的被選中節點來選擇進行哪種操作:
如果被選中節點不存在于接收者的已知節點串列,那么說明接收者是第一次接觸到被選中節點,接收者將根據結構中記錄的IP地址和埠號等資訊,與被選中節點進行握手,
如果被選中節點已經存在于接收者的已知節點串列,那么說明接收者之前已經與被選中的節點進行過接觸,接收者將根據clusterMsgDataGossip結構記錄的資訊,對被選中節點所對應的clusterNode結構進行更新,
舉個發送PING訊息和回傳PONG訊息的例子,假設在一個包含A、B、C、D、E、F六個節點的集群里:
節點A向節點D發送PING訊息,并且訊息里面包含了節點B和節點C的資訊,當節點D收到這條PING訊息時,它將更新自己對節點B和節點C的認識,
之后,節點D將向節點A回傳一條PONG訊息,并且訊息里面包含了節點E和節點F的訊息,當節點A收到這條PONG訊息時,它將更新自己對節點E和節點F的認識,
整個通信程序如下圖所示

FAIL訊息的實作


轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/528111.html
標籤:其他
上一篇:第六章-關系資料理論