資料也有冷熱之分,你知道嗎?
根據訪問的頻率的高低可將資料分為熱資料和冷資料,訪問頻率高的則為熱資料,低為冷資料,如果熱、冷資料不區分,一并存盤,顯然不科學,將冷資料也存盤在昂貴的記憶體中,那么你想,成本得多高呢?
有趣的是,根據我們實際的觀察,目前很多使用 Redis 的業務就是這樣操作的,
得益于高性能以及豐富的資料結構命令,Redis 成為目前最受歡迎的 KV 記憶體資料庫,但隨著業務資料量的爆炸增長,Redis 的記憶體消耗也會隨之爆炸,無論客戶是自建服務器還是云服務器,記憶體都是一個必須考慮的成本問題,它不僅貴還要持續購買,
此外 Redis 雖然提供了 AOF 和 RDB 兩種方案來實作資料的持久化,但是使用不當可能會對性能造成影響甚至引發丟資料的問題,
好在,隨著科技的發展,持久化硬體的發展速度也在提升,持久記憶體的出現進一步縮小了與記憶體的性能差距,或許,合理利用新型持久化技識訓成為一個好的成本解決方案,
基于這一思路,為解決 Redis 可能帶來的記憶體成本、容量限制以及持久化等一系列問題,騰訊云資料庫團隊推出了新一代分布式KV存盤資料庫 KeeWiDB,本文將詳細介紹KeeWiDB 的架構設計思路、實作路徑及成效,先簡單總結一下 KeeWiDB 的特性:
- 友好:完全兼容 Redis 協議,原先使用 Redis 的業務無需修改任何代碼便可以遷移到 KeeWiDB 上;
- 高性能低延遲:通過創新性的分級存盤架構設計,單節點讀寫能力超過 18 萬 QPS,訪問延遲達到毫秒級;
- 更低的成本:內核自動區分冷熱資料,冷資料存盤在相對低價的 SSD 上;
- 更大的容量:節點支持 TB 級別的資料存盤,集群支持 PB 級別的資料存盤;
- 保證了事務的 ACID (原子性 Atomicity、一致性 Consitency、隔離性 Isolation、持久性 Durability)四大特性;
一、整體架構
KeeWiDB 的架構由代理層和服務層兩個部分構成:
代理層:由多個無狀態的Proxy節點組成,主要功能是負責與客戶端進行互動;
服務層:由多個Server節點組成的集群,負責資料的存盤以及在機器發生故障時可以自動進行故障切換,
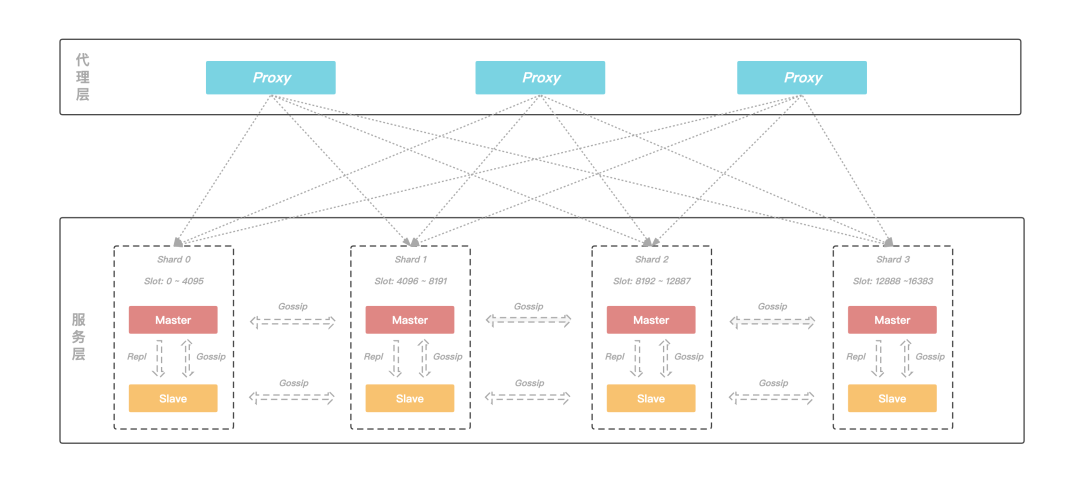
圖:KeeWiDB整體架構圖
代理層
客戶端通過 Proxy 連接來進行訪問,由于 Proxy 內部維護了后端集群的路由資訊,所以 Proxy 可以將客戶端的請求轉發到正確的節點進行處理,從而客戶端無需關心集群的路由變化,用戶可以像使用 Redis 單機版一樣來使用 KeeWiDB,
Proxy 的引入,還帶來了諸多優勢:
- 客戶端直接和 Proxy 進行互動,后端集群在擴縮容場景不會影響客戶端請求;
- Proxy 內部有自己的連接池和后端 KeeWiDB 進行互動,可大大減少 KeeWiDB 上的連接數量,同時有效避免業務短連接場景下反復建連斷連對內核造成性能的影響;
- 支持讀寫分離,針對讀多寫少的場景,通過添加副本數量可以有效分攤 KeeWiDB 的訪問壓力;
- 支持命令攔截和審計功能,針對高危命令進行攔截和日志審計,大幅度提高系統的安全性;
- 由于 Proxy 是無狀態的,負載較高場景下可以通過增加 Proxy 數量來緩解壓力,此外我們的 Proxy 支持熱升級功能,后續 Proxy 添加了新功能或者性能優化,存量 KeeWiDB 實體的 Proxy 都可以進行對客戶端無感知的平滑升級;
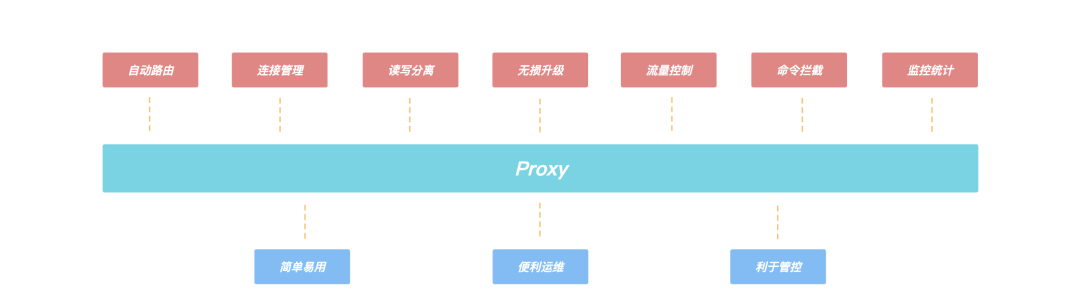
圖:Proxy上的功能
服務層
KeeWiDB 的后端采用了集群的架構,這是因為集群具有高可用、可擴展性、分布式、容錯等優質特性;同時,在具體的實作上參考了 Redis 的集群模式,KeeWiDB 集群同樣由若干個分片構成,而每個分片上又存在若干個節點,由這些節點共同組成一主多從的高可用架構;此外每個分片的主節點負責集群中部分 Slot 的資料,并且可以通過動態修改主節點負責 Slot 區間的形式來實作橫向的擴縮容,為客戶提供了容量可彈性伸縮的能力,
二、Server內部模型
在 Server 內部存在一個集群管理模塊,該模塊通過 Gossip 協議與集群中的其他節點進行通信,獲取集群的最新狀態資訊;另外 Server 內部存在多個作業執行緒,KeeWiDB 會將當前 Server 負責的 Slot 區間按一定的規則劃分給各個作業執行緒進行處理, 并且每個作業執行緒都有自己獨立的連接管理器,事務模塊以及存盤引擎等重要組件,執行緒之間不存在資源共享,做到了行程內部的 Shared-Nothing,正是這種 Shared-Nothing 的體系結構,減少了 KeeWiDB 行程內部執行緒之間由于競爭資源的等待時間,獲得了良好并行處理能力以及可擴展的性能,
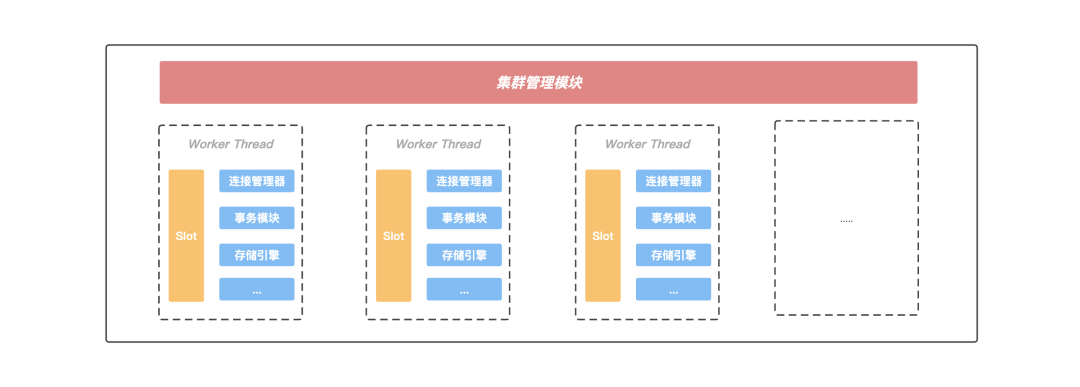
圖:Server內部模塊
執行緒模型
KeeWiDB 的設計目的,就是為了解決 Redis 的痛點問題,所以大容量,高性能以及低延遲是 KeeWiDB 追求的目標,
和資料都存放在記憶體中的 Redis 不同,KeeWiDB 的資料是存盤在 PMem(Persistent Memory)和相對低價的 SSD 上,在用戶執行讀寫訪問請求期間 KeeWiDB 都有可能會涉及到跟硬碟的互動,所以如果還像 Redis 一樣采用單行程單執行緒方案的話,單節點的性能肯定會大打折扣,因此,KeeWiDB 采取了單行程多執行緒的方案,一方面可以更好的利用整機資源來提升單節點的性能,另一方面也能降低運維門檻,
多執行緒方案引入的核心思想是通過提高并行度來提升單節點的吞吐量,但是在處理用戶寫請求期間可能會涉及到不同執行緒操作同一份共享資源的情況,比如存盤引擎內部為了保證事務的原子性和持久性需要寫 WAL,主從之間進行同步需要寫 Binlog,這些日志檔案在寫入的程序中通常會涉及到持久化操作,相對較慢,雖然我們也采取了一系列的優化措施,例如使用組提交策略來降低持久化的頻率,但是優化效果有限,
同時為了保證執行緒安全,在這類日志的寫入期間通常都要進行加鎖,這樣一來,一方面雖然上層可以多執行緒并行的處理用戶請求,但是到了寫日志期間卻退化成了串行執行;另一方面,申請和釋放鎖通常會涉及到用戶態和內核態的切換,頻繁的申請釋放操作會給 CPU 帶來額外的開銷,顯然會導致性能問題,

圖:執行緒模型
正是由于行程內不同執行緒訪問同一份共享資源需要加鎖,而大量的鎖沖突無法將多執行緒的性能發揮到極致,所以我們將節點內部負責的 Slot 區間進行進一步的拆分,每個作業執行緒負責特定一組 Slot 子區間的讀寫請求,互不沖突;此外每個作業執行緒都擁有自己獨立的事務模塊以及存盤引擎等重要組件,不再跨執行緒共享,
通過對共享資源進行執行緒級別的拆分,各個執行緒在處理用戶請求時都可以快速的獲得所需要的資源,不發生等待事件,這無論是對單個請求延遲的降低還是多個請求并發的提升,都有巨大的好處;此外由于處理用戶請求所需的資源都在執行緒內部,KeeWiDB 無需再為了執行緒安全而上鎖,有效規避了由于頻繁上鎖帶來的額外性能開銷,
引入協程
通過上面的章節介紹,KeeWiDB 通過行程內部 Shared-Nothing 的體系結構減少了執行緒之間由于競爭共享資源花費的等待時間,提升了行程內部的并發度,此時我們再將視角轉移到執行緒內部,在業務高峰時期作業執行緒也需要負責處理大量的客戶端請求,由于每次請求操作都有可能會涉及到和磁盤的互動,此時如果再采用同步 IO 的形式和磁盤進行互動的話,由于一個客戶端請求執行的 I/O 操作就會阻塞當前執行緒,此時后面所有的客戶端請求需要排隊等待處理, 顯然并發度會大打折扣,
這時候也許有讀者會提出按照 KeeWiDB 目前這套行程內部 Shared-Nothing 的體系結構,執行緒之間不存在共享資源競爭了,是不是可以通過增加執行緒數來緩解這個問題?想法不錯,但是大量的執行緒引入可能會帶來另外一些問題:
- 開啟過多的執行緒會耗費大量的系統資源, 包括記憶體;
- 執行緒的背景關系切換涉及到用戶空間和內核空間的切換, 大量執行緒的背景關系切換同樣會給 CPU 帶來額外的開銷;
為了讓單個執行緒的性能能夠發揮到極致,不把時間浪費在等待磁盤 I/O 上,KeeWiDB 首先考慮的是采取異步 I/O 的方案(應用層觸發 I/O 操作后立即回傳,執行緒可以繼續處理其他事件,而當 I/O 操作已經完成的時候會得到 I/O 完成的通知),
很明顯,使用異步 I/O 來撰寫程式性能會遠遠高于同步 I/O,但是異步 I/O 的缺點是編程模型復雜,我們常規的編碼方式是自上而下的,但是異步 I/O 編程模型大多采用異步回呼的方式,
隨著專案工程的復雜度增加,由于采用異步回呼撰寫的代碼和常規編碼思維相悖,尤其是回呼嵌套多層的時候,不僅開發維護成本指數級上升,出錯的幾率以及排查問題的難度也大幅度增加,
正是由于異步 I/O 編程模型有上面提到的種種缺點, 我們經過一系列調研作業之后,決定引入協程來解決我們的痛點, 下面先來看一下cppreference中對協程的描述:
A coroutine is a function that can suspend execution to be resumed later. Coroutines are stackless: they suspend execution by returning to the caller and the data that is required to resume execution is stored separately from the stack. This allows for sequential code that executes asynchronously (e.g. to handle non-blocking I/O without explicit callbacks).
from:https://en.cppreference.com/w/cpp/language/coroutines
協程實際上就是一個可以掛起(suspend)和恢復(resume)的函式,我們可以暫停協程的執行,去做其他事情,然后在適當的時候恢復到之前暫停的位置繼續執行接下來的邏輯,總而言之,協程可以讓我們使用同步方式撰寫異步代碼,
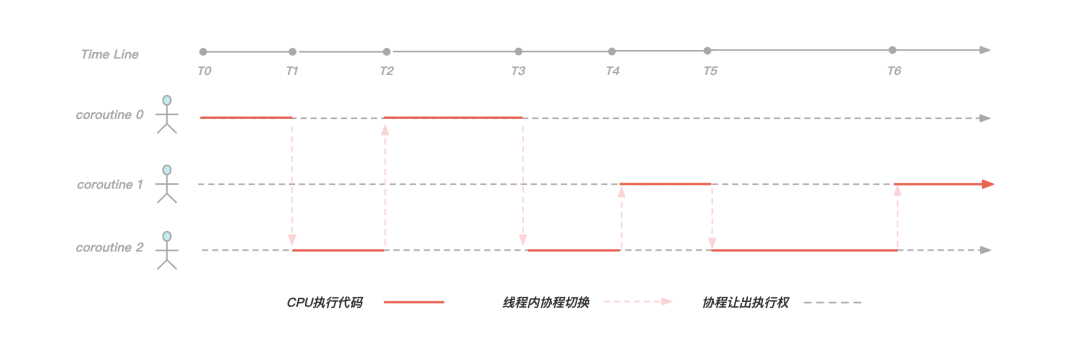
圖:協程切換示意圖
KeeWiDB 為每一個客戶端連接都創建了一個協程,以上圖為例,在作業執行緒內服務三個客戶端連接,就創建三個協程,在[T0,T1)階段協程0正在執行邏輯代碼,但是到了T1時刻協程0發現需要執行磁盤 I/O 操作獲取資料,于是讓出執行權并且等待 I/O 操作完成,此時協程2獲取到執行權,并且在[T1,T2)時間段內執行邏輯代碼,到了T2時刻協程2讓出執行權,并且此時協程0的 I/O 事件正好完成了,于是執行權又回到協程0手中繼續執行,
可以看得出來,通過引入協程,我們有效解決了由于同步 I/O 操作導致執行緒阻塞的問題,使執行緒盡可能的繁忙起來,提高了執行緒內的并發;另外由于協程切換只涉及基本的 CPU 背景關系切換,并且完全在用戶空間進行,而執行緒切換涉及特權模式切換,需要在內核空間完成,所以協程切換比執行緒切換開銷更小,性能更優,
三、資料存盤
在文章開頭有提到在持久記憶體出現后,進一步縮小了與記憶體的性能差距,持久記憶體是一種新的存盤技術,它結合了 DRAM 的性能和位元組尋址能力以及像 SSD 等傳統存盤設備的可持久化特性,正是這些特性使得持久記憶體非常有前景,并且也非常適合用于資料庫系統,

圖:Dram和PMem以及SSD的性能比較
通過上圖可以看到,PMem(Persistent Memory)相對于 DRAM 有著更大的容量,但是相對于 SSD 有著更大的帶寬和更低的讀寫延遲,正是因為如此,它非常適合存盤引擎中的大容量Cache和高性能 WAL 日志,
前面有提到過日志檔案在寫入的程序中涉及到的持久化操作有可能會成為整個系統的瓶頸,我們通過將 WAL 存放在 PMem 上,日志持久化操作耗時大幅降低,提升了服務整體的性能;此外由于 PMem 的讀寫速度比 SSD 要快1~2個數量級,在故障恢復期間,回放 WAL 的時間也大幅度的縮短,整個系統的可用性得到了大幅度的提升,
考慮到 KeeWiDB 作為高性能低延遲的資料庫,我們不僅需要做到平均延遲低,更要做到長尾延遲可控,
雖然在涉及到檔案操作的場景下,利用 Page Cache 技術能夠大幅提升檔案的讀寫速度,但是由于 Page Cache 默認由作業系統調度分配,存在一定的不確定性(內核總是積極地將所有空閑記憶體都用作 Page Cache 和 Buffer Cache,當記憶體不夠用時就會使用 LRU 等演算法淘汰快取頁, 此時有可能造成檔案讀寫操作有時延抖動),在一些極端場景下可能會直接影響客戶實體的P99,P100,所以** KeeWiDB 采用了 Direct I/O的方式來繞過作業系統的 Page Cache 并自行維護一份應用層資料的 Cache,讓磁盤的 IO 更加可控**,
使用 Page cache 能夠大大加速檔案的讀寫速度,那什么是頁面快取(Page Cache)呢?
In computing, a page cache, sometimes also called disk cache, is a transparent cache for the pages originating from a secondary storage device such as a hard disk drive (HDD) or a solid-state drive (SSD). The operating system keeps a page cache in otherwise unused portions of the main memory (RAM), resulting in quicker access to the contents of cached pages and overall performance improvements. A page cache is implemented in kernels with the paging memory management, and is mostly transparent to applications.
from:https://en.wikipedia.org/wiki/Page_cache#cite_note-1
和大多數磁盤資料庫一樣,KeeWiDB 將 Page 作為存盤引擎磁盤管理的最小單位,將資料檔案內部劃分成若干個 Page,每個 Page 的大小為 4K,用于存盤用戶資料和一些我們存盤引擎內部的元資訊,從大容量低成本的角度出發,KeeWiDB 將資料檔案存放在 SSD 上,
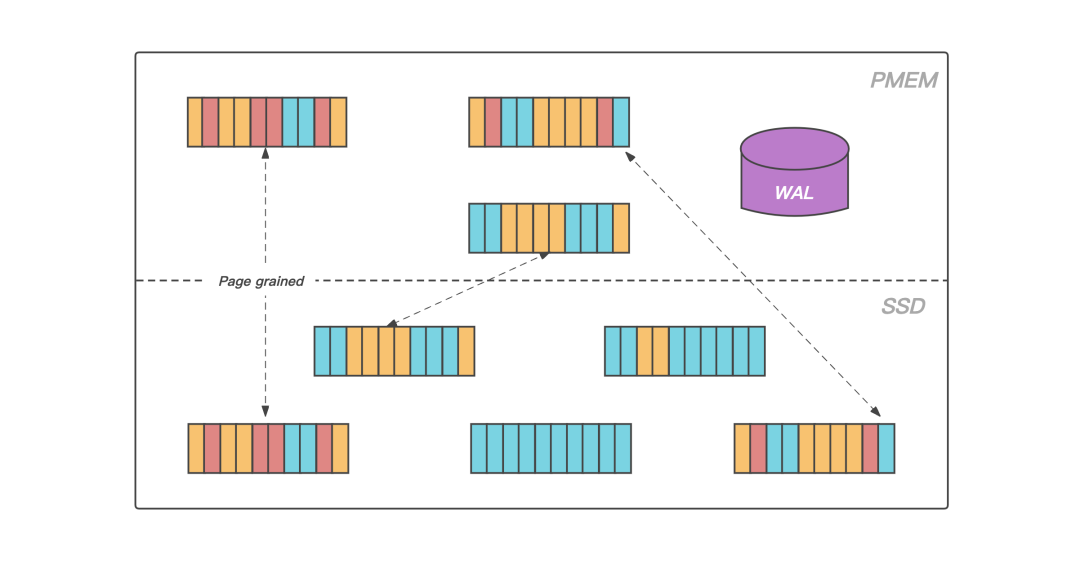
圖:資料頁的升溫和落冷
此外,得益于 PMem 接近于 DRAM 的讀寫速度以及支持位元組尋址的能力,KeeWiDB在 PMem 上實作了存盤引擎的 Cache 模塊,在服務運行期間存放業務熱資料的資料頁會被加載到 PMem 上,KeeWiDB 在處理用戶請求期間不再直接操作 SSD 上的資料頁,而是操作讀寫延遲更低的 PMem,使得 KeeWiDB 的性能以及吞吐量得到了進一步的提升;
同時為了能夠合理高效的利用 PMem 上的空間,KeeWiDB 內部實作了高效的 LRU 淘汰演算法,并且通過異步刷臟的方式,將 PMem 中長時間沒有訪問的資料頁寫回到 SSD 上的資料檔案中,
四、主從同步
文章開頭的架構圖有提到 KeeWiDB 集群由多個分片構成,每個分片內部有多個節點,這些節點共同組成一主多從的高可用架構,和 Redis 類似,用戶的請求會根據 Key 被路由到對應分片的主節點,主節點執行完后再將請求轉化為 Binlog Record 寫入本地的日志檔案并轉發給從節點,從節點通過應用日志檔案完成資料的復制,
在 Redis 的 Replication 實作中,從節點每接收一個請求都立即執行,然后再繼續處理下一個請求,如此往復,依賴其全記憶體的實作,單個請求的執行耗時非常短,從節點的回放相當于是單連接的 pipeline 寫入,其回放速度足以跟上主節點的執行速度,但這種方式卻不適合 KeeWiDB 這樣的存盤型資料庫,主要原因如下:
- 存盤型資料庫的請求執行程序中涉及到磁盤 IO,單個請求的執行耗時本身就比較長;
- 主節點同時服務多個客戶端連接,不同連接的請求并發執行,發揮了協程異步 IO 的優勢,節點整體 QPS 有保障;
- 主從同步只有一個連接,由于從庫順序回放請求,無法并發,回放的 QPS 遠遠跟不上主節點處理用戶請求的 QPS;
為了提升從節點回放的速度,避免在主庫高負載寫入場景下,出現從庫追不上主庫的問題,KeeWiDB 的 Replication 機制做了以下兩點改進:
- 在從節點增加 RelayLog 作為中繼,將從節點的命令接收和回放兩個程序拆開,避免回放程序拖慢命令的接收速度;
- 在主節點記錄 Binlog 的時候增加邏輯時鐘資訊,回放的時候根據邏輯時鐘確定依賴關系,將互相之間沒有依賴的命令一起放進回放的協程池,并發完成這批命令的回放,提升從節點整體的回放 QPS;
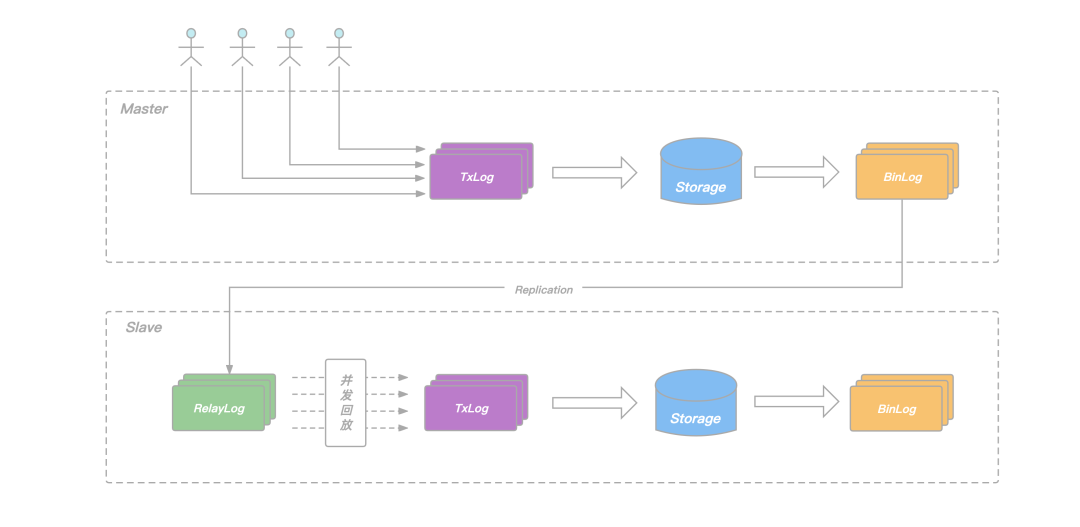
圖:從庫并發回放
所謂的邏輯時鐘,對應到 KeeWiDB 的具體實作里,就是我們在每一條 BinLog record 中添加了 seqnum 和 parent 兩個欄位:
- seqnum 是主節點事務 commit 的序列號,每次有新的事務 commit,當前 seqnum 賦給當前事務,全域 seqnum 自增1;
- parent 由主節點在每個事務開始執行前的 prepare 階段獲取,記錄此時已經 commit 的最大 seqnum,記為 max,說明當前事務是在 max 對應事務 commit 之后才開始執行,二者在主節點端有邏輯上的先后關系;
從節點回放 RelayLog 中的 Binlog Record 時,我們只需要簡單地將它的 parent 和 seqnum 看作一個區間,簡記為(P,S),如果它的(P,S)區間和當前正在回放的其它Record 的(P,S)區間有交集,說明他們在主節點端 Prepare 階段沒有沖突,可以把這條 Record 放進去一塊并發地回放,反之,則這條 Record 需要阻塞等待,等待當前正在回放的這批 Binlog Record 全部結束后再繼續,
通過在 Binlog 中添加 seqnum 和 parent 兩個欄位,我們在保證資料正確性的前提下實作了從庫的并發回放,確保了主庫在高負載寫入場景下,從庫依舊可以輕松的追上主庫,為我們整個系統的高可用提供了保障,
五、總結
本篇文章先從整體架構介紹了 KeeWiDB 的各個組件,然后深入 Server 內部分析了在執行緒模型選擇時的一些思考以及面臨的挑戰,最后介紹了存盤引擎層面的資料檔案以及相關日志在不同存盤介質上的分布情況,以及 KeeWiDB 是如何解決從庫回放 Binlog 低效的問題,通過本文,相信不少讀者對 KeeWiDB 又有了進一步的了解,那么,在接下來的文章中我們還會深入到 KeeWiDB 自研存盤引擎內部,向讀者介紹 KeeWiDB 在存盤引擎層面如何實作高效的資料存盤和索引,敬請期待,
目前,KeeWiDB 正在公測階段(鏈接:https://cloud.tencent.com/product/keewidb ),現已在內外部已經接下了不少業務,其中不乏有一些超大規模以及百萬 QPS 級的業務,線上服務均穩定運行中,
后臺回復“KeeWiDB”,試試看,有驚喜,
關于作者
吳顯堅,騰訊云資料庫高級工程師,負責過開源專案Pika的核心研發作業,對資料庫、分布式存盤有一定了解,現從事騰訊云Redis內核以及KeeWiDB的研發作業,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/530593.html
標籤:其他