一、前言
ChunJun(原FlinkX)是一個基于 Flink 提供易用、穩定、高效的批流統一的資料集成工具,既可以采集靜態的資料,比如 MySQL,HDFS 等,也可以采集實時變化的資料,比如 binlog,Kafka等,同時 ChunJun 也是一個支持原生 FlinkSql所有語法和特性的計算框架,
ChunJun 具有豐富的插件種類,多達40種,如常見的 mysql、binlog、logminer 等,大部分插件都支持 source/reader、sink/writer 及維表功能,目前很多用戶在思考能否在 Dinky 上使用 ChunJun 的插件以提供更全面的能力,那本文將帶來如何在 Dinky 上集成 ChunJun 豐富的插件,其實簡單,那我們開始吧,
二、部署 Flink+ChunJun
編譯
注意,如果需要集成 Dinky,需要將 ChunJun專案下的 chunjun-core 的pom 檔案中的 logback-classic 和 logback-core 注釋掉,否則容易在 Dinky 執行 sql 任務的時候報錯,

然后執行:

部署
使用 ChunJun 需要先部署 Flink 集群,其部署本文不再做指導,
值得注意的是,如果你需要呼叫 Flinkx 的 connect jar 的話,則需要將 classloader.resolve-order 改成 parent-first,修改完成配置以后,把 Flinkx 的 jar 包復制過來,主要是 chunjun-clients-master.jar(Flinkx 現在改名 ChunJun )以及 chunjun 的其它 connector 放到 flink/lib 目錄下,如圖所示,

例外處理
如果啟動集群時出現例外,即 Flink standalone 集群加載 flinkx-dist 里 jar 包之后,集群無法啟動,日志報錯:Exception in thread "main" java.lang.NoSuchFieldError: EMPTY_BYTE_ARRAY.
Exception in thread"main"java.lang.NoSuchFieldError:EMPTY_BYTE_ARRAY
at org.apache.logging.log4j.core.config.ConfigurationSource.
at org.apache.logging.log4j.core.config.NullConfiguration.< init>(NullConfiguration.java:32)
at org.apache.logging.log4j.core.LoggerContext.< clinit>(LoggerContext.java:85)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at org.apache.log4j.LogManager.< clinit>(LogManager.java:72)
at org.slf4j.impl.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:73)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:285)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:305)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.< clinit>(ClusterEntrypoint.java:107)
原因:這個報錯是因為 log4j 版本不統一導致的,因為 flinkx-dist 中部分插件參考的還是舊版本的 log4j 依賴,導致集群啟動程序中,出現了類沖突問題;
方案:臨時方案是將 flink lib 中 log4j 相關的jar包名字前加上字符 ‘a‘,使得flink standalone jvm 優先加載,
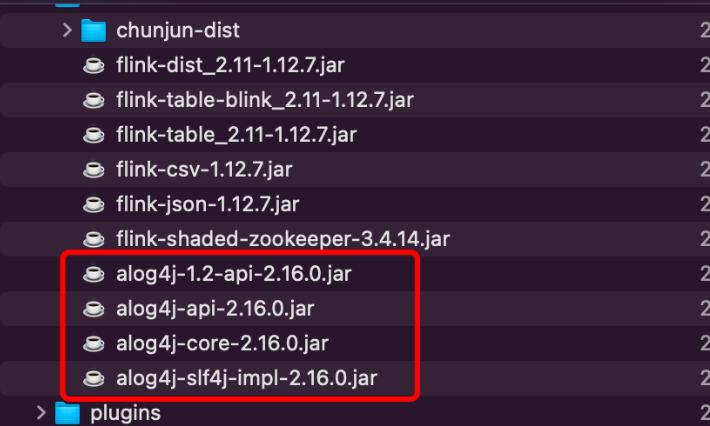
三、部署 Dinky
編譯

編譯完成后的壓縮包在 Dinky 根目錄下的 build 檔案夾下,
部署
1、上傳dlink壓縮包到部署服務器
2、解壓

3、資料庫初始化
4、把 flink 的 jar 放到 dlink 目錄下

切換 Dinky 的 Flink 版本
因為目前 flinkx 的穩定版本是 1.12.7,所以我們把 dlink 默認的 client 版本修改為 1.12

lib下的目錄如圖:
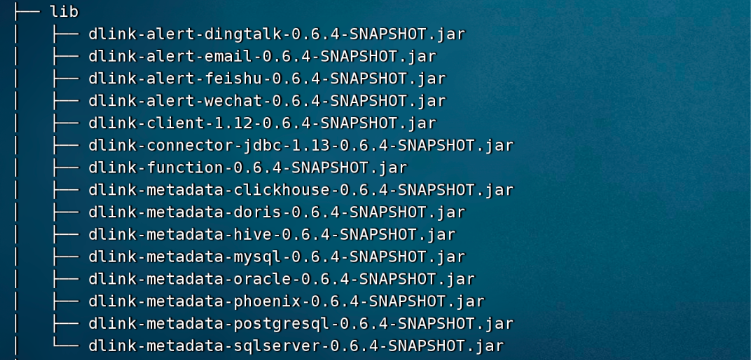
注意:因為我沒有用上 dlink-connector-jdbc 的 jar 包,所以圖中的 dlink-connector-jdbc-1.13-0.6.4-SNAPSHOT.jar 沒有換成1.12版本的,可以去掉,
啟動
啟動命令

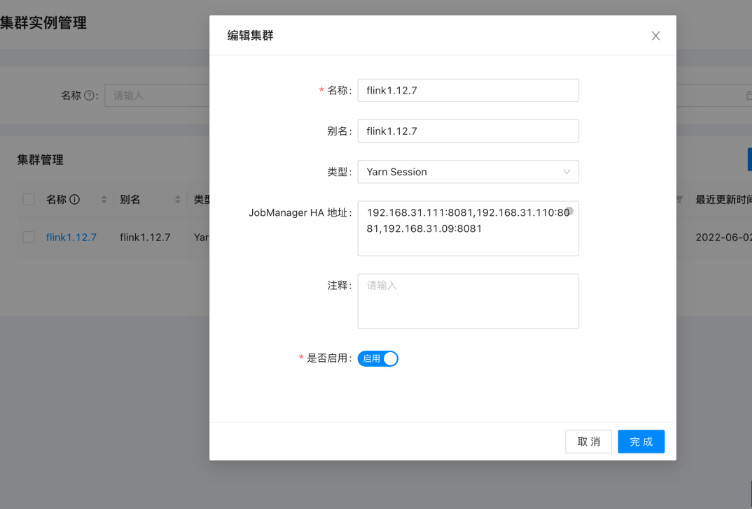
注冊集群實體
在集群實體中注冊已經啟動的 Flink 集群,
四、示例分享
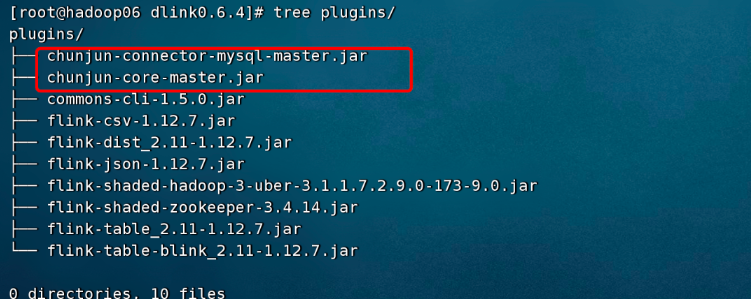
添加依賴
這里演示 mysql->mysql 的同步作業,所以需要 Flinkx 的 mysql-connector.jar 以及核心 jar,
撰寫作業
Mysql DDL:
CREATE TABLE datasource_classify (
id int unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
classify_code varchar(64) NOT NULL COMMENT '型別欄唯一編碼',
sorted int NOT NULL DEFAULT '0' COMMENT '型別欄排序欄位 默認從0開始',
classify_name varchar(64) NOT NULL COMMENT '型別名稱 包含全部和常用欄',
is_deleted tinyint NOT NULL DEFAULT '0' COMMENT '是否洗掉,1洗掉,0未洗掉',
gmt_create datetime DEFAULT CURRENT_TIMESTAMP,
gmt_modified datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY classify_code (classify_code)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='資料源分類表';
Flink Sql:
CREATE TABLE source
(
id bigint,
classify_code STRING,
sorted int,
classify_name STRING,
is_deleted int,
gmt_create timestamp(9),
gmt_modified timestamp(9),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://192.168.31.101:3306/datasource?useSSL=false',
'table-name' = 'datasource_classify',
'username' = 'root',
'password' = 'root'
,'scan.fetch-size' = '2'
,'scan.query-timeout' = '10'
);
CREATE TABLE sink
(
id bigint,
classify_code STRING,
sorted int,
classify_name STRING,
is_deleted int,
gmt_create timestamp(9),
gmt_modified timestamp(9),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://192.168.31.106:3306/test?useSSL=false',
'table-name' = 'datasource_classify',
'username' = 'root',
'password' = 'root'
,'scan.fetch-size' = '2'
,'scan.query-timeout' = '10'
);
insert into sink
select *
from source u;
執行任務
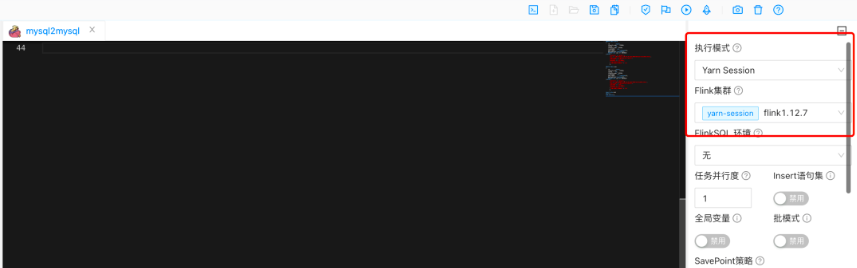
選中 Yarn Session 模式提交作業,

提交后可從執行歷史查看作業提交狀況,

行程中可以看的 Flink 集群上批作業執行完成,
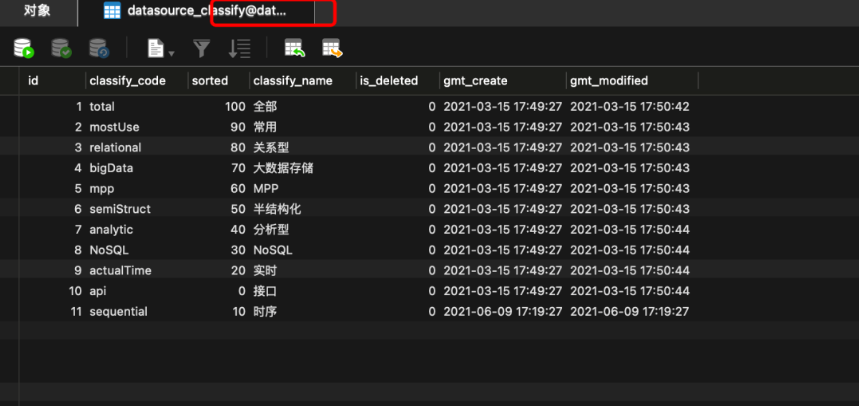
對比資料
源庫:
目標庫:
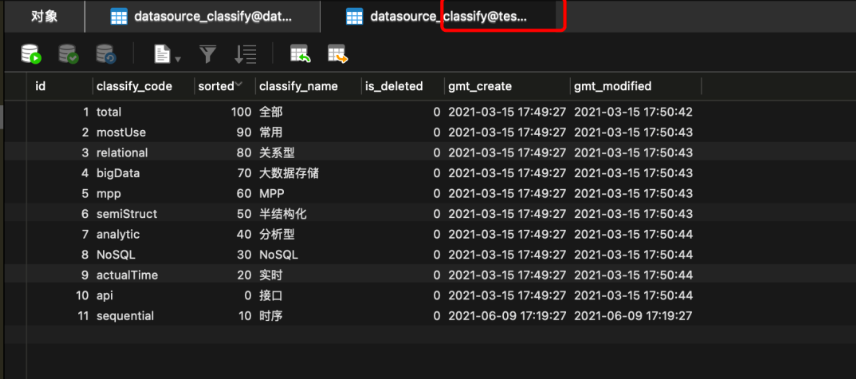
同步成功,很絲滑,
五、總結
在集成 ChunJun 的時候遇到的問題大部分都是缺包以及包沖突,所以只需要注意一下這個問題就能比較好的進行集成,
在集成服務的時候建議是,先把 Flink 和 ChunJun 進行集成,確保服務能夠正常啟用以后再進行 Dinky 的集成,這樣有利于快速定位查找問題,如果遇到文章之外的問題,也可以查看 Dinky 官網FAQ | Dinky (dlink.top) chunjun的官網QuickStart | ChunJun 純鈞 (dtstack.github.io/chunjun/),看看是否有類似問題的解決辦法作為參考,
六、用戶體驗
因為本人目前還是處于學習使用的程序中,所以很多功能沒有好好使用,待自己研究更加透徹后希望寫一篇文章,優化官網的用戶手冊,以下的優缺點以及建議都是目前我在使用學習的程序中遇到的問題,
優點
Dinky 最吸引我的地方應該就是 sql 編輯模版了,直接快捷鍵生成 sql 模版,在開發測驗中屢試不爽,在集成了 ChunJun(Flinkx) 以后,能夠做到多源資料的離線跑批任務及日常小批量實時任務的同步,支持各種型別的任務執行方式,
缺點
ui 上適配還有點小問題,例如:打開 F12 調整寬度后,再關閉,頁面 ui 不會自適應,需要重繪,
期待改進點
1、更多的自定義例外、業務例外
2、增加新的向導模式,結合資料源,通過 webUI 可以一鍵引入欄位或者勾選需要的欄位,生成 Flink Sql 的一大部分配置
CREATE TABLE 表名
(
-- 頁面勾選欄位,欄位從元資料直接拉取
id bigint,
classify_code STRING,
sorted int,
classify_name STRING,
is_deleted int,
gmt_create timestamp(9),
gmt_modified timestamp(9),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
-- 從選擇的資料中獲取
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://192.168.31.106:3306/test?useSSL=false',
'table-name' = 'datasource_classify',
'username' = 'root',
'password' = 'root'
,
-- 其它非主要配置有用戶自己填寫
);
3、sql 歷史版本管理,目前我已經提交 Feature 并被合并到 0.6.5 版本中,
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/archive/2022/11/18/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack/Taier
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/536153.html
標籤:其他
上一篇:MongoDB - 索引知識