
分庫分表,是企業里面比較常見的針對高并發、資料量大的場景下的一種技術優化方案,也是一個非常高頻的面試題,但是,因為很多人其實并沒有非常豐富的分庫分表的經驗,所以能把這個問題回答得比較好的人其實還挺少的,
那么,本文就來試圖把關于分庫分表的事情,一次性講個清楚,
一、分庫,分表,分庫分表
首先,我們需要知道所謂"分庫分表",根本就不是一件事兒,而是三件事兒,他們要解決的問題也都不一樣,
這三個事兒分別是"只分庫不分表"、"只分表不分庫"、以及"既分庫又分表",
1、什么時候分庫?
其實,分庫主要解決的是并發量大的問題,因為并發量一旦上來了,那么資料庫就可能會成為瓶頸,因為資料庫的連接數是有限的,雖然可以調整,但是也不是無限調整的,
所以,當當你的資料庫的讀或者寫的QPS過高,導致你的資料庫連接數不足了的時候,就需要考慮分庫了,通過增加資料庫實體的方式來提供更多的可用資料庫鏈接,從而提升系統的并發度,
比較典型的分庫的場景就是我們在做微服務拆分的時候,就會按照業務邊界,把各個業務的資料從一個單一的資料庫中拆分開,分表把訂單、物流、商品、會員等單獨放到單獨的資料庫中,
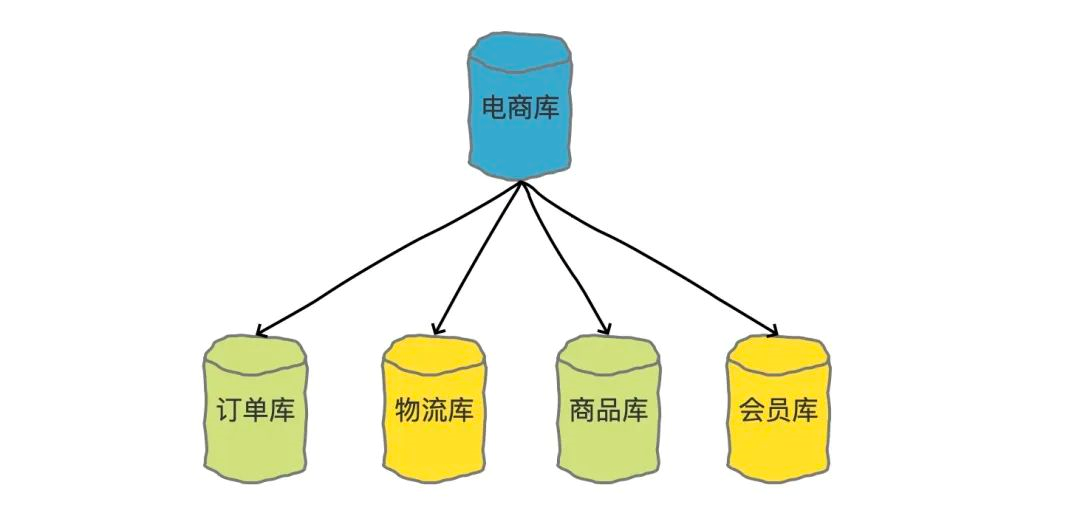
還有就是有的時候可能會需要把歷史訂單挪到歷史庫里面去,這也是分庫的一種具體做法,
2、什么時候分表?
分庫主要解決的是并發量大的問題,那分表其實主要解決的是資料量大的問題,
假如你的單表資料量非常大,因為并發不高,資料量連接可能還夠,但是存盤和查詢的性能遇到了瓶頸了,你做了很多優化之后還是無法提升效率的時候,就需要考慮做分表了,
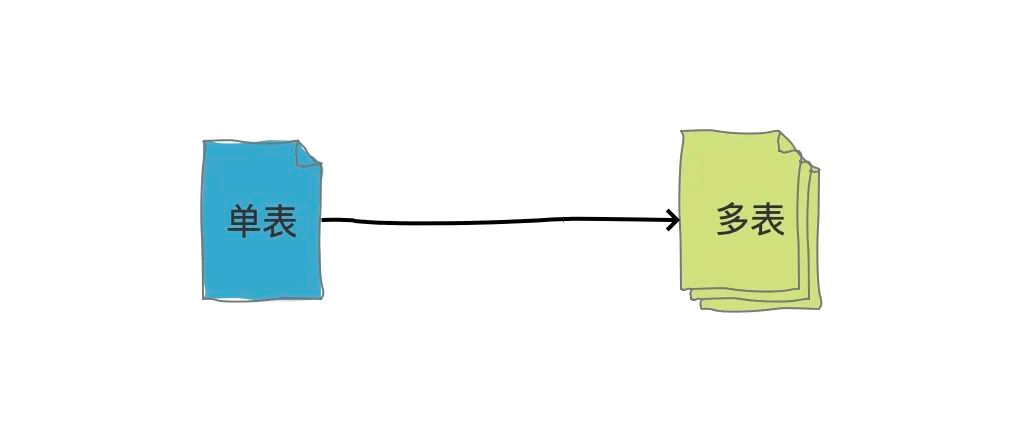
通過將資料拆分到多張表中,來減少單表的資料量,從而提升查詢速度,
一般我們認為,單表行數超過 500 萬行或者單表容量超過 2GB之后,才需要考慮做分庫分表了,小于這個資料量,遇到性能問題先建議大家通過其他優化來解決,
3、什么時候既分庫又分表?
那么什么時候分庫又分表呢,那就是既需要解決并發量大的問題,又需要解決資料量大的問題時候,通常情況下,高并發和資料量大的問題都是同時發生的,所以,我們會經常遇到分庫分表需要同時進行的情況,
所以,當你的資料庫鏈接也不夠了,并且單表資料量也很大導致查詢比較慢的時候,就需要做既分庫又分表了,
二、橫向拆分和縱向拆分
談及到分庫分表,那就要涉及到該如何做拆分的問題,
通常在做拆分的時候有兩種分法,分別是橫向拆分(水平拆分)和縱向拆分(垂直拆分),假如我們有一張表,如果把這張表中某一條記錄的多個欄位,拆分到多張表中,這種就是縱向拆分,那如果把一張表中的不同的記錄分別放到不同的表中,這種就是橫向拆分,
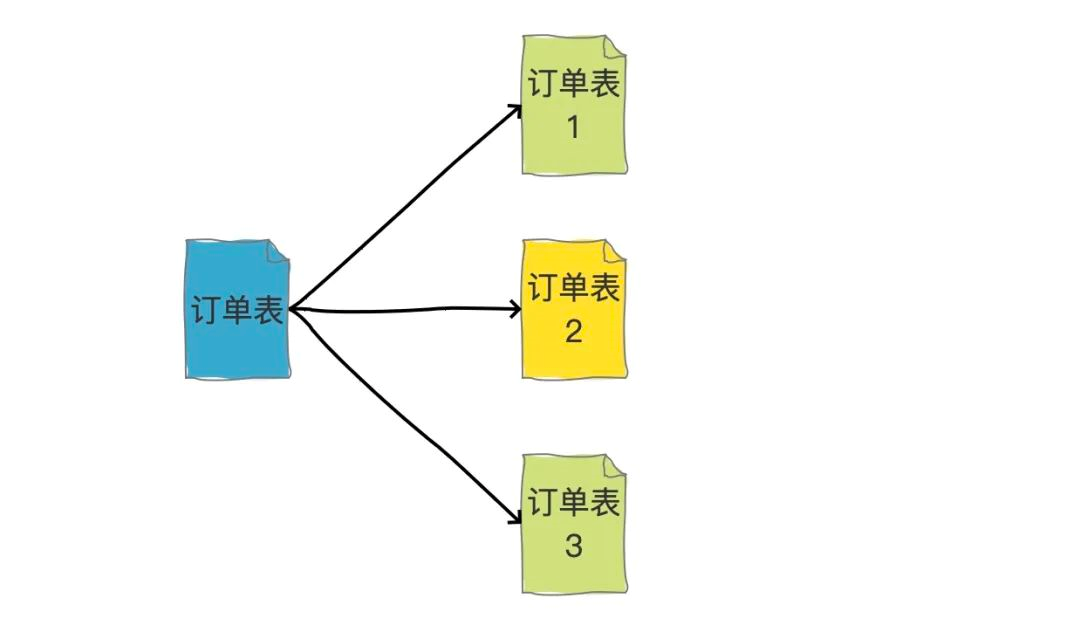
橫向拆分的結果是資料庫表中的資料會分散到多張分表中,使得每一個單表中的資料的條數都有所下降,比如我們可以把不同的用戶的訂單分表拆分放到不同的表中,
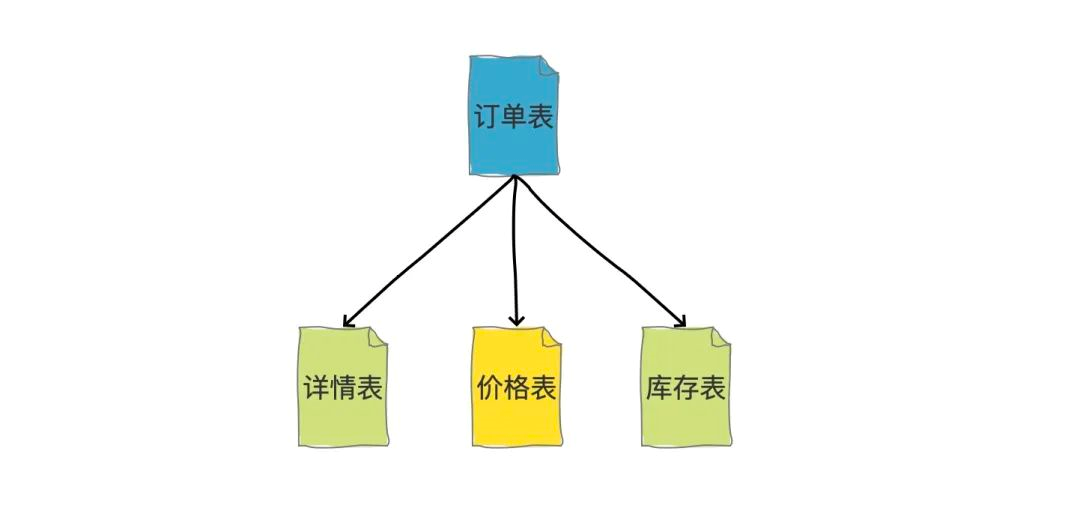
縱向拆分的結果是資料庫表中的資料的欄位數會變少,使得每一個單表中的資料的存盤有所下降,比如我可以把商品詳情資訊、價格資訊、庫存資訊等等分別拆分到不同的表中,
還有我們談到的針對不同的業務做拆分成多個資料庫的這種情況,其實也是縱向拆分的一種,
三、分表欄位的選擇
在分庫分表的程序中,我們需要有一個欄位用來進行分表,比如按照用戶分表、按照時間分表、按照地區分表,這里面的用戶、時間、地區就是所謂的分表欄位,
那么,在選擇這個分表欄位的時候,一定要注意,要根據實際的業務情況來做慎重的選擇,
比如說我們要對交易訂單進行分表的時候,我們可以選擇的資訊有很多,比如買家Id、賣家Id、訂單號、時間、地區等等,具體應該如何選擇呢?
通常,如果有特殊的訴求,比如按照月度匯總、地區匯總等以外,我們通常建議大家按照買家Id進行分表,因為這樣可以避免一個關鍵的問題那就是——資料傾斜(熱點資料),
1、買家還是賣家?
首先,我們先說為什么不按照賣家分表?
因為我們知道,電商網站上面是有很多買家和賣家的,但是,一個大的賣家可能會產生很多訂單,比如像蘇寧易購、當當等這種店鋪,他每天在天貓產生的訂單量就非常的大,如果按照賣家Id分表的話,那同一個賣家的很多訂單都會分到同一張表,
那就會使得有一些表的資料量非常的大,但是有些表的資料量又很小,這就是發生了資料傾斜,這個賣家的資料就變成了熱點資料,隨著時間的增長,就會使得這個賣家的所有操作都變得例外緩慢,
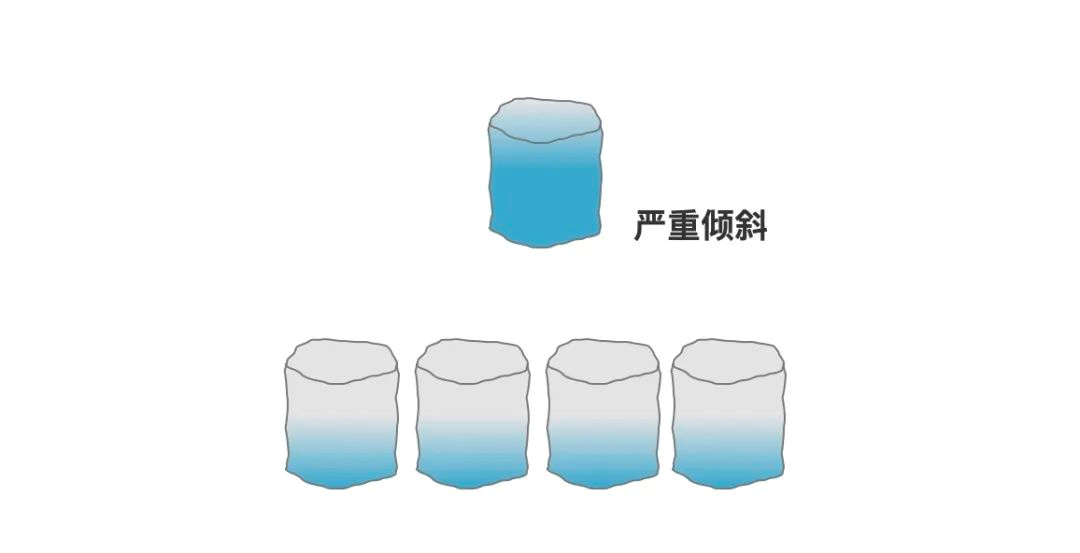
但是,買家ID做分表欄位就不會出現這類問題,因為一個不太容易出現一個買家能把資料買傾斜了,
但是需要注意的是,我們說按照買家Id做分表,保證的是同一個買家的所有訂單都在同一張表 ,并不是要給每個買家都單獨分配一張表,
我們在做分表路由的時候,是可以設定一定的規則的,比如我們想要分1024張表,那么我們可以用買家ID或者買家ID的hashcode對1024取模,結果是0000-1023,那么就存盤到對應的編號的分表中就行了,
2、賣家查詢怎么辦?
如果按照買家Id進行了分表,那賣家的查詢怎么辦,這不就意味著要跨表查詢了嗎?
首先,業務問題我們要建立在業務背景下討論,電商網站訂單查詢有幾種場景?
-
買家查自己的訂單
-
賣家查自己的訂單
-
平臺的小二查用戶的訂單
首先,我們用買家ID做了分表,那么買家來查詢的時候,是一定可以把買家ID帶過來的,我們直接去對應的表里面查詢就行了,
那如果是賣家查呢?賣家查詢的話,同樣可以帶賣家id過來,那么,我們可以有一個基于binlog、flink等準實時的同步一張賣家維度的分表,這張表只用來查詢,來解決賣家查詢的問題,
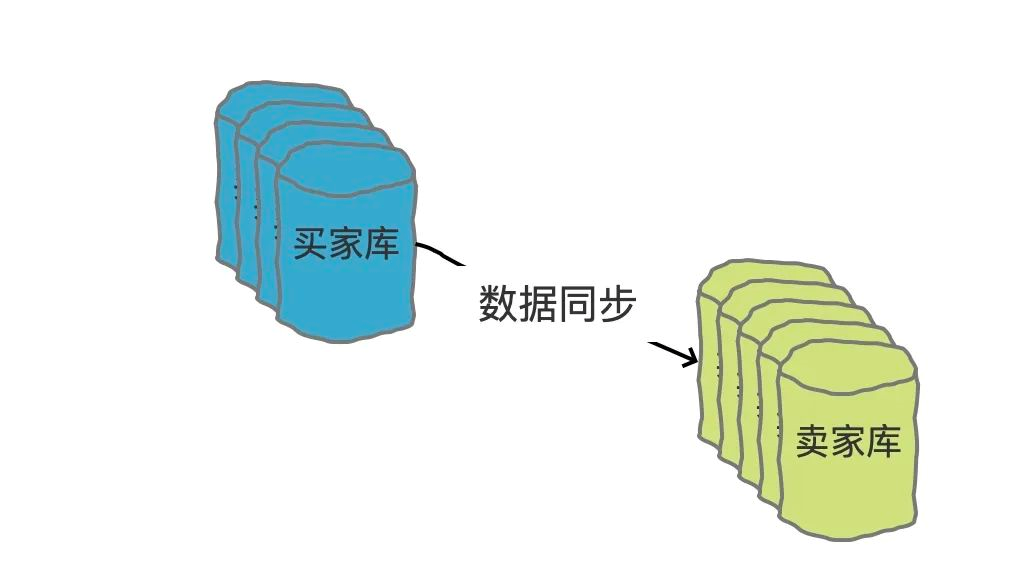
本質上就是用空間換時間的做法,
不知道大家看到這里會不會有這樣的疑問:同步一張賣家表,這不又帶來了大賣家的熱點問題了嗎?
首先,我們說同步一張賣家維度的表來,但是其實所有的寫操作還是要寫到買家表的,只不過需要準實時同步的方案同步到賣家表中,也就是說,我們的這個賣家表理論上是沒有業務的寫操作,只有讀操作的,
所以,這個賣家庫只需要有高性能的讀就行了,那這樣的話就可以有很多選擇了,比如可以部署到一些配置不用那么高的機器、或者其實可以干脆就不用MYSQL,而是采用HBASE、PolarDB、Lindorm等資料庫就可以了,這些資料庫都是可以海量資料,并提供高性能查詢的,
還有呢就是,大賣家一般都是可以識別的,提前針對大賣家,把他的訂單,再按照一定的規則拆分到多張表中,因為只有讀,沒有寫操作,所以拆分多張表也不用考慮事務的問題,
3、按照訂單查詢怎么辦?
上面說的都是有買賣家ID的情況,那沒有買賣家ID呢?用訂單號直接查怎么辦呢?
這種問題的解決方案是,在生成訂單號的時候,我們一般會把分表解決編碼到訂單號中去,因為訂單生成的時候是一定可以知道買家ID的,那么我們就把買家ID的路由結果比如1023,作為一段固定的值放到訂單號中就行了,這就是所謂的"基因法",
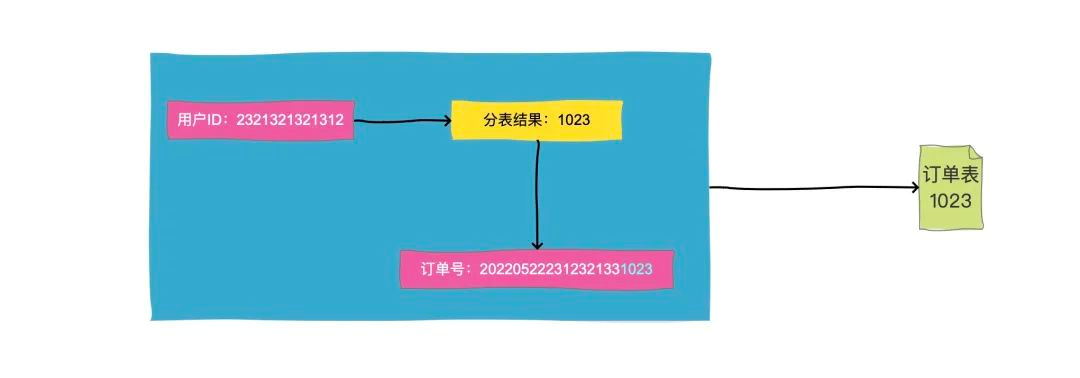
這樣按照訂單號查詢的時候,決議出這段數字,直接去對應分表查詢就好了,
至于還有人問其他的查詢,沒有買賣家ID,也沒訂單號的,那其實就屬于是低頻查詢或者非核心功能查詢了,那就可以用ES等搜索引擎的方案來解決了,就不贅述了,
四、分表演算法
選定了分表欄位之后,如何基于這個分表欄位來準確的把資料分表到某一張表中呢?
這就是分表演算法要做的事情了,但是不管什么演算法,我們都需要確保一個前提,那就是同一個分表欄位,經過這個演算法處理后,得到的結果一定是一致的,不可變的,
通常情況下,當我們對order表進行分表的時候,比如我們要分成128張表的話,那么得到的128表應該是:order_0000、order_0001、order_0002.....order_0126、order_0127,
通常的分表演算法有以下幾種:
1、直接取模
在分庫分表時,我們是事先可以知道要分成多少個庫和多少張表的,所以,比較簡單的就是取模的方式,
比如我們要分成128張表的話,就用一個整數來對128取模就行了,得到的結果如果是0002,那么就把資料放到order_0002這張表中,
2、Hash取模
那如果分表欄位不是數字型別,而是字串型別怎么辦呢?有一個辦法就是哈希取模,就是先對這個分表欄位取Hash,然后在再取模,
但是需要注意的是,Java中的hash方法得到的結果有可能是負數,需要考慮這種負數的情況,
3、一致性Hash
前面兩種取模方式都比較不錯,可以使我們的資料比較均勻的分布到多張分表中,但是還是存在一個缺點,
那就是如果需要擴容二次分表,表的總數量發生變化時,就需要重新計算hash值,就需要涉及到資料遷移了,
為了解決擴容的問題,我們可以采用一致性哈希的方式來做分表,
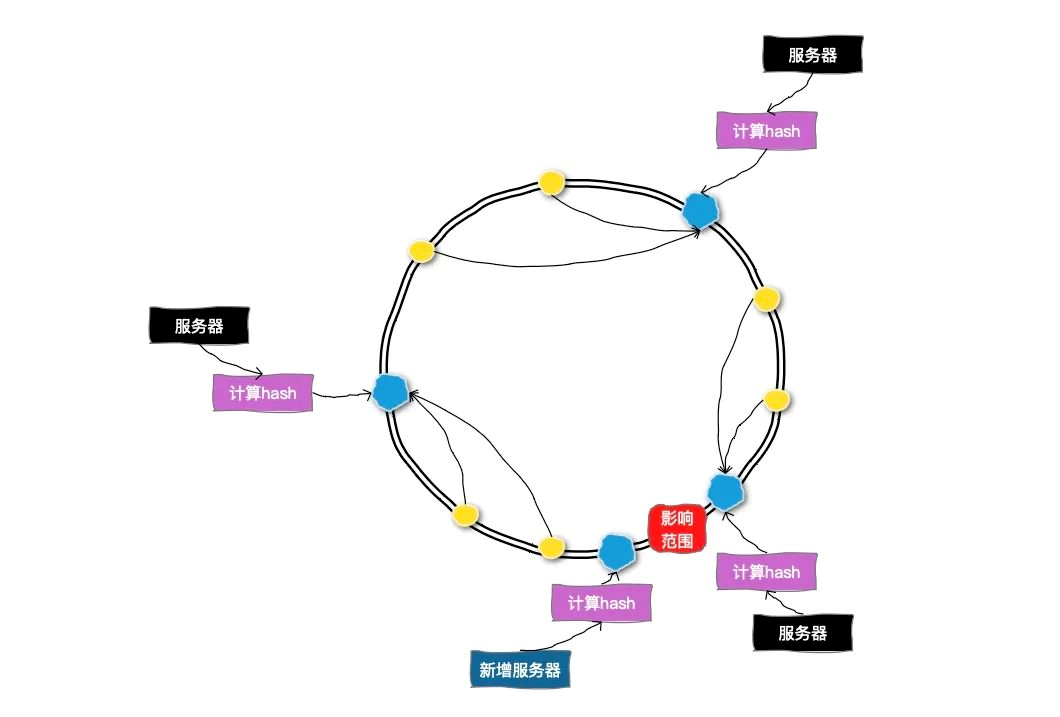
一致性哈希可以按照常用的hash演算法來將對應的key哈希到一個具有2^32次方個節點的空間中,形成成一個順時針首尾相接的閉合的環形,所以當添加一臺新的資料庫服務器時,只有增加服務器的位置和逆時針方向第一臺服務器之間的鍵會受影響,
五、全域ID的生成
涉及到分庫分表,就會引申出分布式系統中唯一主鍵ID的生成問題,因為在單表中我們可以用資料庫主鍵來做唯一ID,但是如果做了分庫分表,多張單表中的自增主鍵就一定會發生沖突,那就不具備全域唯一性了,
那么,如何生成一個全域唯一的ID呢?有以下幾種方式,
1、UUID
很多人對UUID都不陌生,它是可以做到全域唯一的,而且生成方式也簡單,但是我們通常不推薦使用他做唯一ID,首先UUID太長了,其次字串的查詢效率也比較慢,而且沒有業務含義,根本看不懂,
2、基于某個單表做自增主鍵
多張單表生成的自增主鍵會沖突,但是如果所有的表中的主鍵都從同一張表生成是不是就可以了,
所有的表在需要主鍵的時候,都到這張表中獲取一個自增的ID,
這樣做是可以做到唯一,也能實作自增,但是問題是這個單表就變成整個系統的瓶頸,而且也存在單點問題,一旦他掛了,那整個資料庫就都無法寫入了,
3、基于多個單表+步長做自增主鍵
為了解決單個資料庫做自曾主鍵的瓶頸及單點故障問題,我們可以引入多個表來一起生成就行了,
但是如何保證多張表里面生成的Id不重復呢?如果我們能實作以下的生成方式就行了:
實體1生成的ID從1000開始,到1999結束,
實體2生成的ID從2000開始,到2999結束,
實體3生成的ID從3000開始,到3999結束,
實體4生成的ID從4000開始,到4999結束,
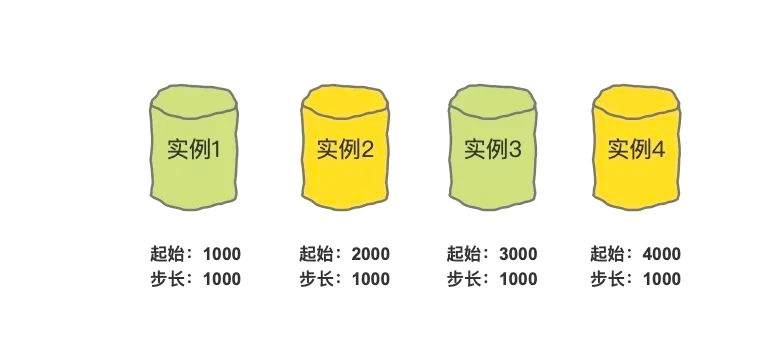
這樣就能避免ID重復了,那如果第一個實體的ID已經用到1999了怎么辦?那就生成一個新的起始值:
實體1生成的ID從5000開始,到5999結束,
實體2生成的ID從6000開始,到6999結束,
實體3生成的ID從7000開始,到7999結束,
實體4生成的ID從8000開始,到8999結束,
我們把步長設定為1000,確保每一個單表中的主鍵起始值都不一樣,并且比當前的最大值相差1000就行了,
4、雪花演算法
雪花演算法也是比較常用的一種分布式ID的生成方式,它具有全域唯一、遞增、高可用的特點,
雪花演算法生成的主鍵主要由 4 部分組成,1bit符號位、41bit時間戳位、10bit作業行程位以及 12bit 序列號位,
時間戳占用41bit,精確到毫秒,總共可以容納約69年的時間,
作業行程位占用10bit,其中高位5bit是資料中心ID,低位5bit是作業節點ID,做多可以容納1024個節點,
序列號占用12bit,每個節點每毫秒0開始不斷累加,最多可以累加到4095,一共可以產生4096個ID,
所以,一個雪花演算法可以在同一毫秒內最多可以生成1024 X 4096 = 4194304個唯一的ID,
六、分庫分表的工具
在選定了分表欄位和分表演算法之后,那么,如何把這些功能給實作出來,需要怎么做呢?
我們如何可以做到像處理單表一樣處理分庫分表的資料呢?這就需要用到一個分庫分表的工具了,
目前市面上比較不錯的分庫分表的開源框架主要有三個,分別是sharding-jdbc、TDDL和Mycat,
1、Sharding-JDBC
現在叫ShardingSphere(Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar這3款相互獨立的產品組成),它定位為輕量級Java框架,在Java的JDBC層提供的額外服務,它使用客戶端直連資料庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強版的JDBC驅動,完全兼容JDBC和各種ORM框架,
開源地址:https://shardingsphere.apache.org
2、TDDL
TDDL 是淘寶開源的一個用于訪問資料庫的中間件, 它集成了分庫分表, 讀寫分離,權重調配,動態資料源配置等功能,封裝 jdbc 的 DataSource給用戶提供統一的基于客戶端的使用,
開源地址:https://github.com/alibaba/tb_tddl
3、Mycat
Mycat是一款分布式關系型資料庫中間件,它支持分布式SQL查詢,兼容MySQL通信協議,以Java生態支持多種后端資料庫,通過資料分片提高資料查詢處理能力,
開源地址:https://github.com/MyCATApache/Mycat2
七、分庫分表帶來的問題
分庫分表之后,會帶來很多問題,
首先,做了分庫分表之后,所有的讀和寫操作,都需要帶著分表欄位,這樣才能知道具體去哪個庫、哪張表中去查詢資料,如果不帶的話,就得支持全表掃描,
但是,單表的時候全表掃描比較容易,但是做了分庫分表之后,就沒辦法做掃表的操作了,如果要掃表的話就要把所有的物理表都要掃一遍,
還有,一旦我們要從多個資料庫中查詢或者寫入資料,就有很多事情都不能做了,比如跨庫事務就是不支持的,
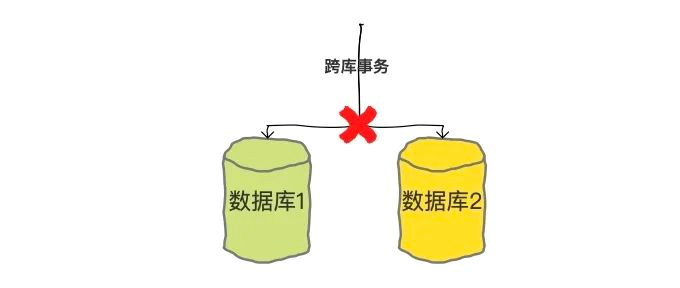
所以,分庫分表之后就會帶來因為不支持事務而導致的資料一致性的問題,
其次,做了分庫分表之后,以前單表中很方便的分頁查詢、排序等等操作就都失效了,因為我們不能跨多表進行分頁、排序,
總之,分庫分表雖然能解決一些大資料量、高并發的問題,但是同時也會帶來一些新的問題,所以,在做資料庫優化的時候,還是建議大家優先選擇其他的優化方式,最后再考慮分庫分表,
八、總結
以上,本文介紹了分庫分表的一些原因,以及如何做分庫分表,并且討論了其中比較關鍵的分表欄位和分表演算法的問題,還介紹了幾款比較不錯的分庫分表的相關框架,
最后,還有一些需要大家注意的就是分庫分表會引入一些新的問題,這些問題的解決成本也都不低,所以在做技術選型的時候也要做好這方面的評估,
作者丨Hollis
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/How-to-Sub-Database-and-Sub-Table.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538077.html
標籤:SQL Server