1. openGauss AI框架的特點
DB4AI這個方向中,資料庫通過集成AI能力,在用戶進行AI計算時就可以避免資料搬運的問題,不同于其他的DB4AI框架,本次openGauss開源的原生框架是通過添加AI算子的方式完成資料庫中的AI計算,
那么除了避免了資料搬運所帶來的問題這個普遍優勢,openGauss的AI框架還具有以下的優勢和特點:
1)極低的學習門檻
當前最主流的計算框架:Tensorflow、pytorch、keras等大多依托于python語言作為構建的腳本語言,雖然python已經足夠的簡單易學但還是需要一定的學習成本,而當前的框架,設計提供了CREATE MODEL和PREDICT BY兩種語法用于完成AI的訓練和推斷任務,該語法相比較python更加趨近于自然語言,符合人們的用語直覺,
CREATE MODEL point_kmeans USING kmeans FEATURES position FROM kmeans_2d WITH num_centroids=3;SELECT id, PREDICT BY point_kmeans (FEATURES position) as pos FROM (select * from kmeans_2d_test limit 10)
2)極簡的資料版本管理
本次DB4AI特性中還添加了snapshot功能,資料庫通過快照的形式將資料集中的資料固定在某個時刻,同樣也支持保存經過處理過濾的資料,功能分為全量保存和增量保存,其中因為增量保存每次僅存盤資料變化,快照的空間占用大大的降低了,用戶可以直接通過不同版本名稱的快照直接獲取相對應的資料,
3)極優的性能體驗
相比于目前很多的AIinDB專案,openGauss的特性通過添加AI算子的方式將模型計算內置到資料庫中,以演算法訓練為例,其中的資料的讀取、模型的計算更新和最終的模型保存將在資料庫的執行器中完成,這種方式將更加充分地利用和釋放資料庫的計算能力,深入內核的技術路線使得我們的特性在計算速度上優于其他更高層級呼叫的方法,
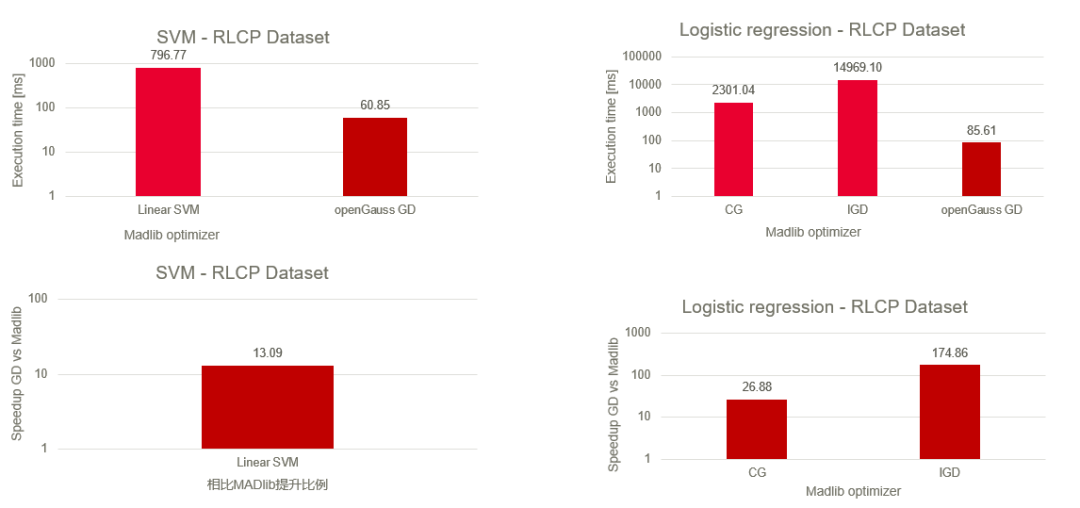
圖1.與MADlib性能對比
2. 技術原理與優勢
1)DB4AI-Snapshot
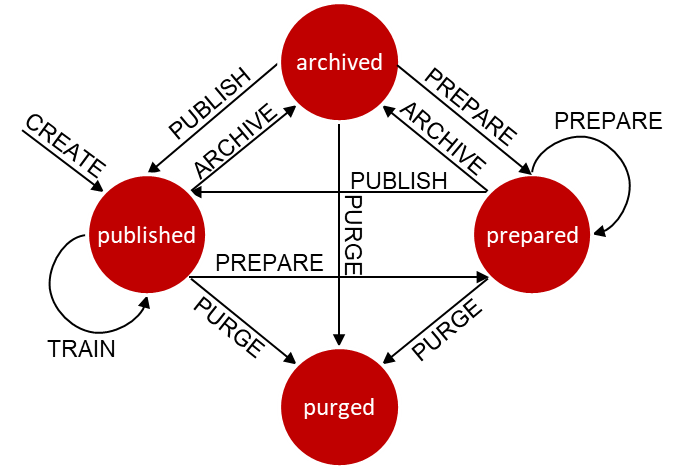
首先DB4AI.snapshot特性需要用戶通過對操作資料存盤的SQL查詢指定哪些資料將填充新快照來創建快照,初始快照始終創建為操作資料的真實和可重用副本,使資料的特定狀態不可變,因此,初始快照作為后續資料整理的起點,但它始終允許回溯到創建初始快照時原始資料的確切狀態,
由于已創建的快照無法更改,因此在開始資料整理之前,必須“準備”快照,準備好的快照的資料可以進行協作修改,為模型訓練做準備,特別是為資料管理做準備,此外,快照通過將每個操作作為元資料記錄在DB4AI系統目錄中,自動跟蹤所有的更改,為資料提供完整的集成歷史,
快照準備完成后,可以發布快照,發布的快照是不可變的,DB4AI系統強制只有發布的快照才能用于模型訓練,保證訓練任務
存檔過時的快照以用于檔案目的,在這種狀態下,資料保持不變但不能用于訓練新的模型,最后,清除快照,洗掉模式中的資料表以及視圖、恢復存盤空間,需要注意的是,快照管理為了實施嚴格的模型來源無法清除具有依賴的快照,
利用GUC引數,snapshot使用物化存盤模式或者增量存盤,在增量存盤模式中,新快照對應的視圖和資料表只保存相對父快照修改的內容,從而大大降低存盤空間,
2)DB4AI-Query
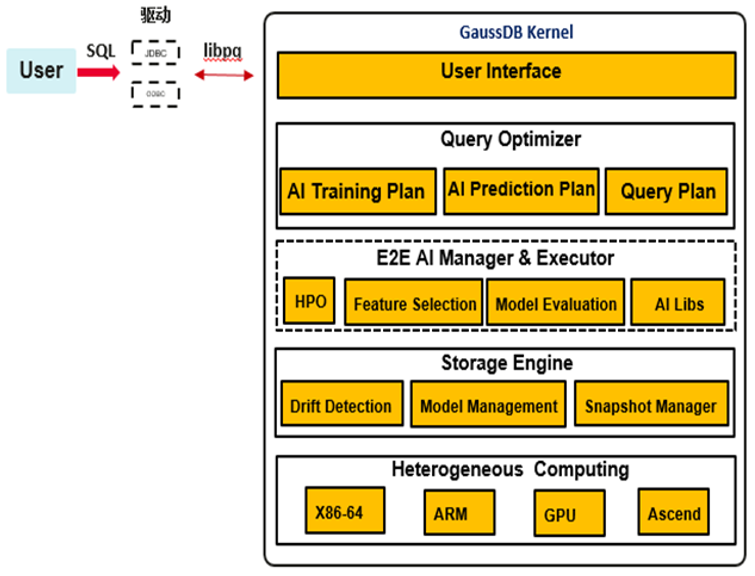
原生AI框架深度內嵌于資料庫內核中,通過查詢優化和查詢執行,構建包含AI算子的執行計劃,計算完成后,框架的存盤模塊將負責保存模型相關資訊,整個AI框架主題分成3部分,分別是:查詢優化模塊、計算執行模塊和模型存盤模塊,
查詢優化:
框架新增詞法、語法規則CREATE MODEL、PREDICT BY作為AI計算入口,在查詢優化中,模塊負責簡單的輸入校驗,包括:屬性名合法性、演算法當前是否支持、模型名稱是否沖突等,校驗完成后,該模塊根據訓練和推測任務生成對應的查詢計劃,
計算執行:
查詢執行模塊負責根據需求演算法型別的不同添加相對應的AI算子到執行計劃中,并執行運算其中包括資料讀取和模型計算更新,各個演算法之間高內聚低耦合,具有非常好的演算法擴展性,對開發者之后添加演算法友好,
模型存盤:
當模型完成訓練,執行器會把模型資料以tuple的形式傳遞給存盤模塊,最終將模型保存到系統表gs_model_warehouse中,
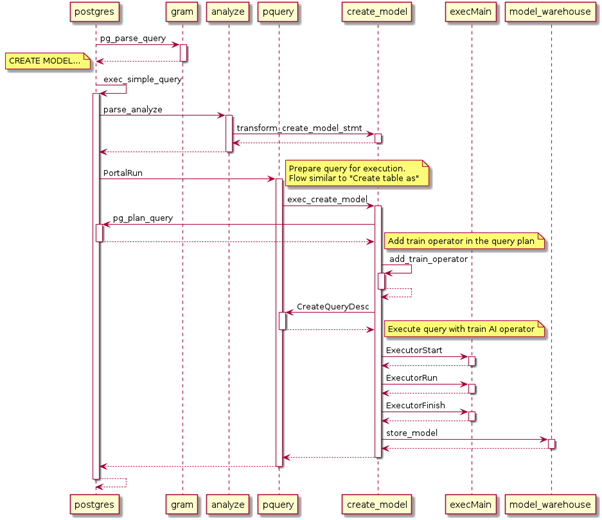
接下來我們以CREATE MODEL為例介紹用于訓練模型的查詢陳述句是如何實作的:
-
第一步 對Query進行詞法分析、語法分析(Lex、Yacc),通過識別模式類別和模式組合校對陳述句是否存在語法錯誤,生成分析樹,
-
第二步 通過詞法分析、語法分析(Lex、Yacc)后,資料庫會對得到的每一個分析樹進行語意分析和重寫,在語意分析生成查詢樹的程序中,針對命令型別為createmodelStmt的情況,資料庫首先會對演算法型別進行檢查判斷演算法屬于監督學習還是非監督學習,根據這個判斷結果繼而進一步校驗查詢陳述句所輸入的屬性、超參、模型名稱是否非法等,校驗完成后,語意分析生成查詢樹,傳遞給資料庫執行器,
-
第三步 在執行階段根據演算法型別的不同,執行器會添加不同的演算法算子到執行計劃中,將AI算子添加到掃描算子的上層,在算子執行計算的程序中,把掃描得到的資料輸入到演算法模型中進行計算和更新,最后根據超參設定的迭代條件結束算子執行,
-
第四步 計算完成后,執行器會將已訓練完成的模型以元組的形式傳遞給存盤引擎,接收到的元組轉寫模型結構體,經校驗保存到系統表gs_model_warehouse中,用戶可以通過查看系統表的方式查看模型的相關資訊,
DB4AI作為openGauss原創的高級特性,凝結了openGauss在AI上的全新實踐,通過DB4AI進一步拓展了openGauss資料庫的應用領域,
利用openGauss提供的開箱即用的DB4AI功能,既有效解決資料倉庫、資料湖場景中資料搬遷的問題,又提升了資料遷移程序中涉及的資訊安全問題,未來,結合openGauss的多模、并行計算等領先優勢,必將進一步地形成統一的資料管理平臺,減少資料異構、碎片化存盤帶來的運維、使用困難,DB4AI特性的發布,是將openGauss進一步打造成一把鋒利的瑞士軍刀的關鍵一步!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538221.html
標籤:其它
上一篇:Oracle中ALTER TABLE的五種用法(二)
下一篇:SQL Server(解決問題)已成功與服務器建立連接,但是在登錄程序中發生錯誤。provider: Shared Memory Provider, error:0 - 管道的另一端上無任何行程。