聚合管道
聚合框架是 MongoDB 中的一組分析工具,可以對一個或多個集合中的檔案進行分析,
MongoDB 的聚合框架基于管道的概念:首先從集合中獲取到輸入,然后將輸入的檔案傳遞到一個或多個階段,每個階段都將之前階段輸出的內容作為輸入,最終得到一個聚合結果作為輸出,
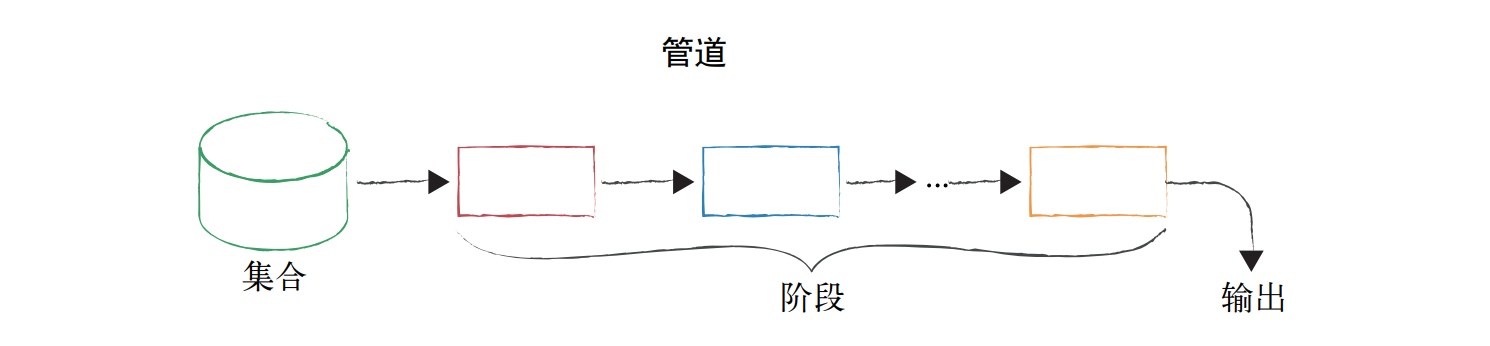
上面的圖是一個比較寬泛的管道流程圖,這里展示一個 MongoDB 聚合陳述句映射到管道之后的情況:
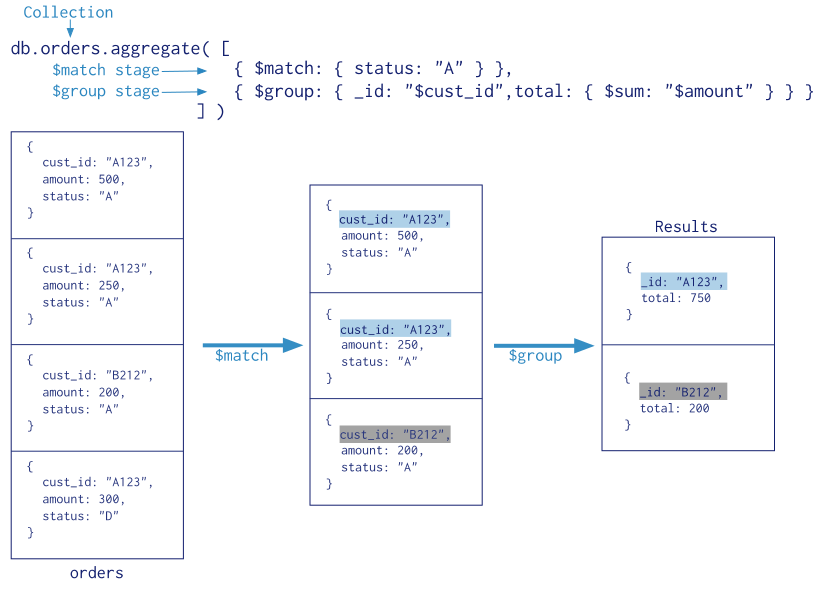
在這里可以看得出,aggregate([{}, {}]) 是一個聚合陳述句,在函式的陣列中,每一個物件都是一個階段,$match 應該就是一個篩選檔案的階段,$group 應該就是一個分組匯總的階段,
管道階段
使用聚合框架最重要的就是熟悉操作的語法,以及將這些語法構建成管道當中的階段,
在 MongoDB 聚合框架中,每一個階段都必須要規定一個特定的階段運算子,這些階段運算子表明了階段的執行規則,可以到 官方檔案 上查看更多、更詳細的內容,
常見操作
最常見的操作應該是能與普通查詢陳述句對應上的操作,如查詢、投影、排序、跳過、限制等等,雖然這些在一個 find() 陳述句中就能實作,
最常使用的操作就是查詢,也可以說是篩選、過濾,在聚合框架中使用 $match 來表明這是一個篩選檔案的階段,如下是其使用語法:
{ $match: { <query> } }
第二個則是投影,這個階段可以修改輸入檔案的結構,通常是重命名、增加、洗掉屬性,也可以通過運算式創建計算結果以及嵌套檔案,如下是其使用語法:
// <field>: <1 or true>
// <field>: <0 or false>
// <field>: <expression>
{ $project: { <specification(s)> } }
排序、跳過、限制都比較容易理解,實際上可以與 find() 結果的游標支持的函式做聯系,如下是其使用語法:
// 排序
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
// 跳過
{ $skip: <positive 64-bit integer> }
// 限制
{ $limit: <positive 64-bit integer> }
上述 5 個階段是最常用的階段,在使用時需要注重它們的效率,一般會使用這樣的順序去構建管道:
- 通過篩選陳述句過濾指定集合,得到符合要求的檔案串列;
- 如果排序非常重要,這一個階段需要在過濾檔案之后;
- 如果需要做分頁功能,應該是先執行跳過的階段,然后再到限制的階段;
- 最后,執行投影階段(進入投影階段的檔案應該盡量少),
更多操作 - 投影
投影階段一個比較大的作用就是,限制下一步的檔案欄位數量,也就是洗掉屬性,如下是使用方式:
// 不回傳 _id 欄位
{ $project: { _id: 0 } }
// 不回傳指定的 field 欄位
{ $project: { <field>: 0 } }
洗掉屬性是黑名單的功能,投影階段也支持白名單的功能,即回傳串列內的欄位,如下是使用方式:
// 回傳指定的 field 欄位
{ $project: { <field>: 1 } }
前兩個功能是比較好理解的,但投影階段所能做的遠不止如此,還有很多其他的功能(投影階段支持大部分條件組),這里做個簡單舉例:
// 將 author 嵌套檔案下 last 屬性賦值給 lastName 屬性
{ $project: { lastName: "$author.last" } }
// 上述的功能里,對于嵌套檔案和內嵌陣列回傳的結果是不一樣的,陣列會繼承下來
// 投影支持類似于三元運算的運算式
{ $project: { lastName: {
$cond: {
if: { $eq: [ "", "$author.last" ] },
then: "$$REMOVE",
else: "$author.last",
}
} } }
更多操作 - 展開
在處理陣列時,一個比較常見的操作是為陣列中的每一個元素形成一個輸出檔案,
一個實際的例子就是,一件衣服在庫存中有 S、M、L 三個尺寸,而這三個尺寸會存盤在同一個陣列欄位當中,當我們聚合時想要將這一條檔案展開成三個檔案,一個尺寸對應一個檔案,
// 原始檔案
{
"clothesId": "123456",
"sizeList": ["S", "M", "L"]
}
// 展開后的檔案
{
"clothesId": "123456",
"sizeList": "S"
}
{
"clothesId": "123456",
"sizeList": "M"
}
{
"clothesId": "123456",
"sizeList": "L"
}
聚合程序中,展開階段的語法是:
{ $unwind: <field path> }
// 上述衣服的例子中,可以用以下陳述句來展開
{ $unwind: "$sizeList" }
更多操作 - 分組
分組是聚合管道中舉足輕重的一個階段,這里的分組可以看作是 SQL 的 GOURP BY 陳述句,其能為聚合功能帶來非常大的可能性,
分組階段使用了 $group 運算子,支持使用一個鍵或多個鍵將輸入的檔案進行分組,其語法如下:
{
$group: {
// 分組的標識
_id: <expression>,
<field1>: { <accumulator1> : <expression1> },
...
}
}
其中 _id 是必須的,可以簡單指定分組的鍵,也可以使用條件組做處理后生成自定義鍵,
可選的 <field> 是分組后需要展示的鍵,并且可以指定條件組來決定它們的值是什么,
尤其是,MongoDB 提供了累加器可以實作復雜的功能,如求和、平均值、最大值、最小值等等,
這里有個對集合求和的例子,也是最簡單的使用:
{
$group: {
// 對型別進行分組
_id: "type",
// 這里是求和,一個檔案記作 1 個,即對同型別的檔案進行計數
count: { $sum: 1 },
}
}
更多操作 - 入庫
顧名思義,入庫需要作為管道中最后的階段,將管道生成的檔案寫入集合中,
聚合框架提供了 $out 和 $merge 兩個運算子標識入庫階段,其中 $merge 是在 4.2 版本中引入的,這兩個運算子的語法如下:
// 指定資料庫和集合,會直接覆寫
{ $out: { db: "<output-db>", coll: "<output-collection>" } }
// 配置更加豐富
{ $merge: {
// 指定資料庫和集合
into: <collection> -or- { db: <db>, coll: <collection> },
// 確定唯一標識與集合中做匹配
on: <identifier field> -or- [ <identifier field1>, ...], // Optional
// 設定變數
let: <variables>, // Optional
// 如果標識存在時處理檔案的方式
whenMatched: <replace|keepExisting|merge|fail|pipeline>, // Optional
// 如果標識不存在時處理檔案的方式
whenNotMatched: <insert|discard|fail> // Optional
} }
如果可以的話,建議使用 $merge 作為寫入集合的首選方式,其功能更多,
當然,其真正的優勢是,可以按照按需生成的物化視圖(materialized view),在管道運行的階段,輸出到集合的內容會進行增量更新,
條件組累加器
在一些階段操作中,MongoDB 支持使用累加器來增強聚合功能,這里說的累加器泛指求和、平均值、最大值、最小值等功能的運算子,
算術運算
這里的算術運算不是統稱的四則運算,指的是與數學相關的運算,如平均值、求和等,
$avg 累加器用于計算平均值,通過是直接指定一個鍵名即可,使用 { $avg: "$keyName" } 這樣的語法,
$sum 累加器用于計算指定鍵的和,也是直接指定一個鍵名即可,使用 { $sum: "$keyName" } 這樣的語法,
最值運算
累加器支持的最值包括這些:最小值、最大值、最大的 n 個值,
最小值和最大值的理解都比較容易,使用也比較容易,最小值使用了 { $min: "$keyName" } 這樣的語法,最大值使用了 { $max: "$keyName" } 這樣的語法,
最大的 n 個值是在 5.2 版本新增的累加器,其作用是通過指定輸入的鍵,得到這些鍵值中排序后最大的 n 個值,其語法如下:
{
$maxN: {
// 指定鍵名 input: "$score"
input: <expression>,
// 指定數量 n: 3
n: <expression>
}
}
陣列提取
這里的陣列提取指的是提取陣列中的某個元素,現在能支持到的就是提取出陣列中的前 n 個元素、后 n 個元素,
在這里可以使用 $first、$firstN、$last、$lastN 這樣的運算子,它們的語法分別如下:
{ $first: <expression> }
{
$firstN: {
input: <expression>,
n: <expression>
}
}
{ $last: <expression> }
{
$lastN: {
input: <expression>,
n: <expression>
}
}
其他運算
除了上述的累加器,聚合框架還有非常多其他的累加器,這里簡單列一下:
$accumulator: 回傳自定義累加器函式的結果$addToSet: 回傳一個無重復值的陣列$bottom: 回傳指定排序規則后最后 1 個元素$bottomN: 回傳指定排序規則后最后 n 個元素$count: 回傳檔案的計數$mergeObjects: 回傳合并多個物件之后的結果$push: 回傳一個可以有重復值的陣列$stdDevPop: 回傳輸入值的總體標準差$stdDevSamp: 回傳輸入值的樣本標準差
這些累加器都有各自的用法,使用得當可實作非常強大的資料分析功能,完整的內容可以到 官方檔案 上查看,
首發于「程式員翔仔」,點擊查看更多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538261.html
標籤:NoSQL
下一篇:MongoDB - 聚合查詢