一、什么是資料湖?
在探討資料湖技識訓如何構建資料湖之前,我們需要先明確,什么是資料湖?
資料湖的起源,應該追溯到2010年10月,基于對半結構化、非結構化存盤的需求,同時為了推廣自家的Pentaho產品以及Hadoop,2010年Pentaho的創始人兼CTO James Dixon首次提出了資料湖的概念,
資料湖概念一經提出,便受到了廣泛關注,人們發現此概念代表了一種新的資料存盤理念,海量異構資料統一存盤可以很好地解決企業資料孤島問題,方便企業資料管理與應用,
「技術概念的提出,本質都是為了業務場景服務的,是為解決某類特定場景的問題,」
隨著新一代資訊技術的發展,以及數字化轉型的深入推進,資料作為一種“無形資產”的重要性變得比以往更為凸顯,物聯網、直播、醫療等各種業務場景每天都會生成幾GB、幾百GB,甚至TB級的原始資料,面對海量資料的存盤以及結構化資料、文本、二進制(圖片、音頻、視頻)等資料的存盤應用,傳統架構的離線資料倉庫越來越“力不從心”,
與此同時,隨著大資料技術的融合發展,資料湖不斷演變,當前我們所討論的資料湖,已經遠遠超過了當初 James Dixon 所定義的資料湖,
根據維基的定義,資料湖是一個以原始格式(通常是物件塊或檔案)存盤數的系統或存盤庫,資料湖通常是所有企業資料的單一存盤,用于報告、可視化、高級分析和機器學習等任務,資料湖可以包括來自關系資料庫的結構化資料(行和列)、半結構化資料(CSV、日志、XML、JSON)、非結構化資料(電子郵件、檔案、pdf)和二進制資料(影像、音頻、視頻),

二、袋鼠云資料湖平臺
數字經濟時代,如何有效利用不同來源、規模巨大的資料,從而加快資料價值化的呈現,把資料用活,成為很多企業的難題,
秉承「讓資料創造價值」的使命,袋鼠云進一步夯實企業數字化轉型的資料基座,今年7月的2022年產品發布會上,袋鼠云首發資料湖平臺——DataLake,
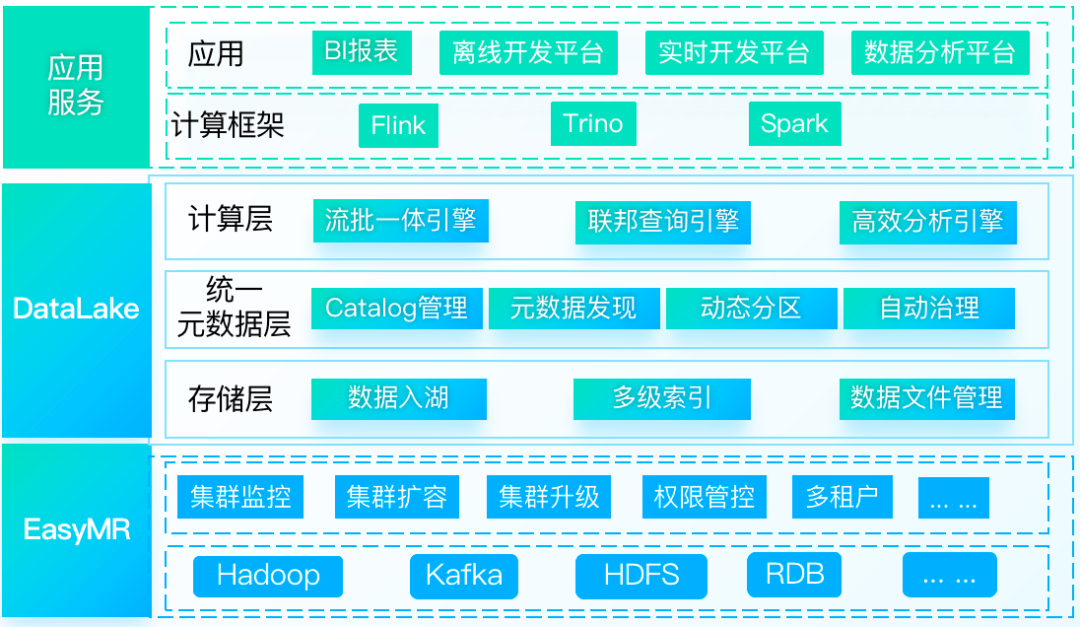
DataLake, 提供面向湖倉一體的資料湖管理分析服務,基于統一的元資料抽象構建一致性的資料訪問,提供海量資料的存盤管理和實時分析處理能力,可以幫助企業快速構建湖倉一體化平臺,完成數字化基礎建設,
DataLake讓業務回應更加及時,讓企業運轉更加高效,
三、DataLake的核心特性
下文為大家著重介紹DataLake的核心特性:
1.高效資料入湖
通過?研批流?體資料集成框架ChunJun,可視化的任務配置,將外部資料高效入湖,讓資料具備更高的新鮮度,同時也可對已有表hive結構進行快速掃描,一鍵生成湖表資訊,節省10x倍資料的傳輸時間和50%磁盤空間,
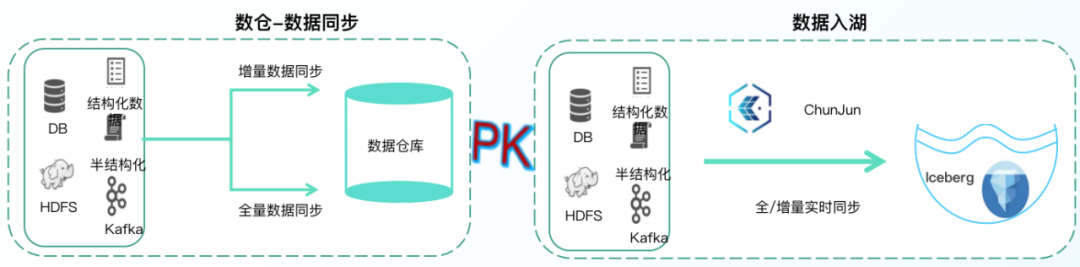
? 引入ChunJun,提供資料同步效率實作秒級快速入湖
? 全資料同步量/增量一體化,鏈路短組件少開發維護成本低
? 不影響在線業務的穩定
2.統一元資料管理
支持物理表、虛擬元資料的統一管理,支持表結構變更、時間旅行、資料檔案自動治理能力,
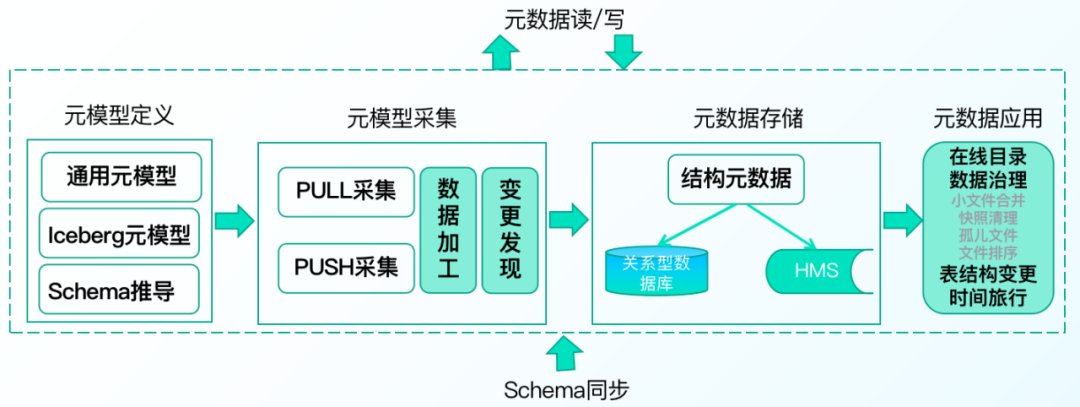
袋鼠云資料湖DataLake提供統一的在線資料目錄和離線資料治理能力,主要由以下四個部分構成:
? 元模型定義:是對元資料的抽象描述,定義了通用元模型和Iceberg元模型
? 元資料采集:支持基于PULL定時拉取和PUSH主動上報的兩種方式采集元資料,保證元資料的實時同步
? 元資料存盤:根據不同元資料的資料結構和用途,形成以Hive Metastore為主,關系型資料庫為輔的存盤架構
? 元資料應用:提供線資料目錄和離線資料治理能力,在線資料目錄可為資料湖的計算引擎提供Schema管理功能;離線資料治理包括,小檔案合并、快照清理、孤兒檔案清理能治理能力,可以有效降低資料存盤提高資料查詢效率,同時還支持表結構變更、時間旅行的能力,可以快速對湖表進行加列改列刪列,而資料無需重寫,支持對資料和Schema進行版本管理一鍵回滾
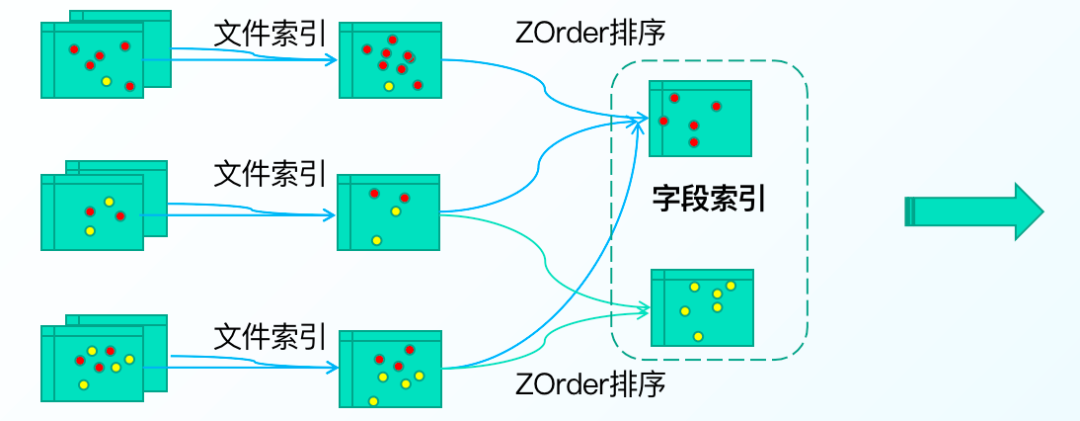
3.多級索引加速
高效Data Skipping方案,支持多種索引模式,如bloom index,data skipping index ……
4.高性能聯邦查詢
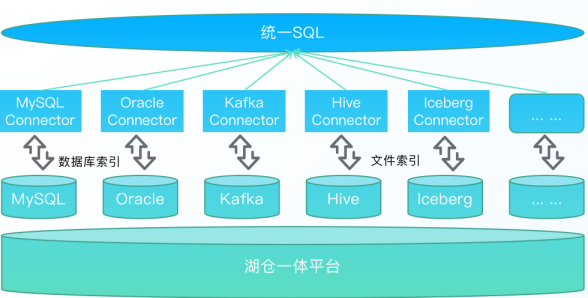
內置多種資料連接器,并在開源基礎上提供更高效的索引結構,極大提高了資料的跨源聯合分析查詢能力,可快速完成各類分析需求,帶來極致的互動式資料分析體驗,
支持MySQL、Oracle、Hive、Iceberg、ClickHouse、MongoDB等30+異構資料源連接器,滿足市場95%客戶需求,進行Connector整合統一SQL,對外提供標準資料API服務,極大簡化用戶多資料源資料查詢的復雜度,一個標準介面可以同時查詢30+資料庫,
5.事務支持
支持所有ACID語意,T+0資料更新,
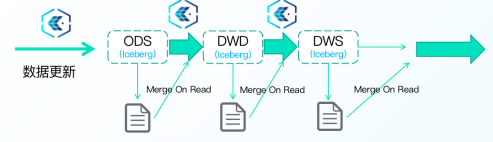
? 基于Iceberg架構資料湖支持Merge On Read模式,資料實際應用時進行Merge操作,可以支持近實時的資料匯入和實時資料讀取
? 支持ACID,保證了多任務資料同步的寫入和查詢的隔離性,不會產生臟資料
? 支持行級別快速資料更新,極大提高資料更新效率
6.流批一體
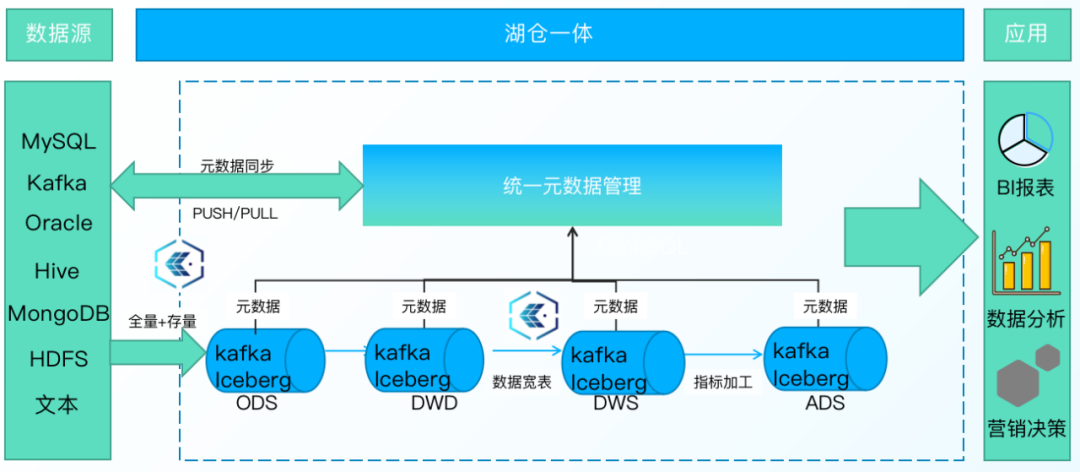
基于資料存盤層的統一邏輯,支持流和批的一體化分析,一套架構同時滿足流批業務操作,降低學習、使用、維護成本,
異構資料源資料通過ChunJun同步到資料湖平臺,歷史資料存盤Iceberg湖內,可以提供更高效的查詢同時具備廉價存盤,增量資料運用訊息佇列提供低延時的寫入和消費能力,存盤于kafka,同時kafka內資料自動同步到Iceberg內,并記錄kafka偏移,以保證資料一致性,
資料進行流式消費時,湖內會自動根據資料讀取情況判斷讀取Kafka 還是 Iceberg 內資料,系統進行自動切換,以實作秒級毫秒級的資料實時查詢,
7.多種底層存盤
湖倉平臺支持HDFS、S3、OSS、MInio等多種底層存盤,靈活滿足客戶不同資料存盤需求,
四、一起體驗DataLake
結合這些核心特性,接下來一起玩轉袋鼠云資料湖平臺DataLake吧~
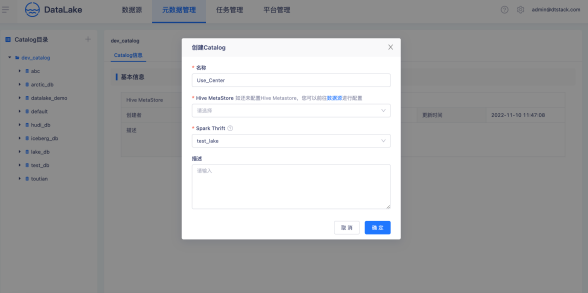
創建CalaLog
首先創建一個Calalog,一個Calalog只允許系結一個Hive MetaStore,Calalog與Hive MetaStore是一一對應,用戶可以使用Calalog進行業務部門資料隔離,
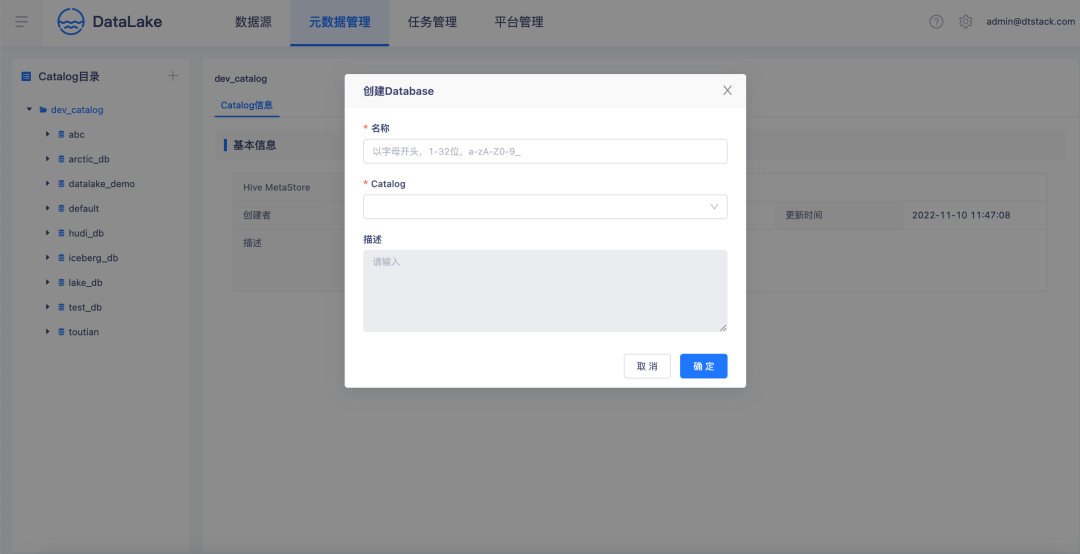
創建Database
創建一個Database系結到Calalog上,
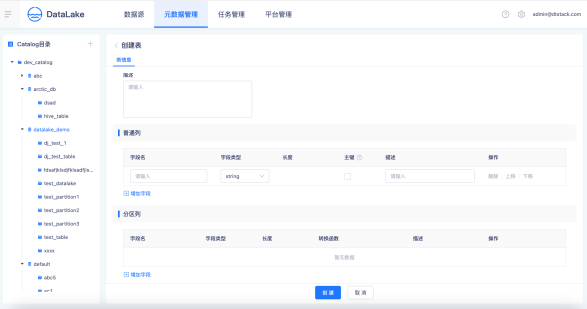
創建一張Table
選擇Table所在的Catalog、Database,創建一張Iceberg湖表,設定表普通列,支持對普通列欄位設定主鍵,可以用作表的唯一標識,
選擇普通列欄位作為磁區欄位,設定磁區欄位的轉換函式,袋鼠云資料湖平臺支持時間欄位按照年、月、日和小時粒度劃磁區,支持行組級索引設定和自定義高級引數設定,
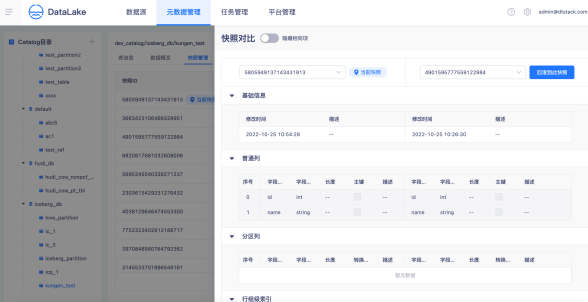
快照管理
袋鼠云資料湖平臺支持快照歷史管理,支持多版本間快照變更對比,支持湖表時間旅行,一鍵回滾到指定資料版本,
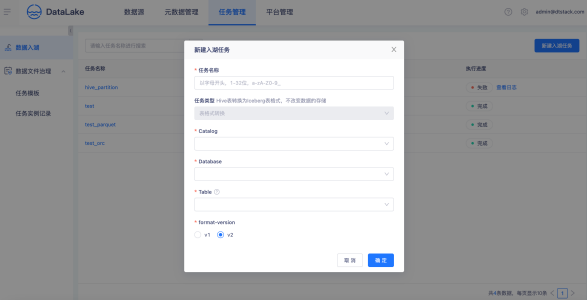
資料入湖
創建入湖任務,選擇一張Hive進行轉表入湖,一鍵生成湖表資訊,對比資料同步入湖,可以節省10x倍資料的傳輸時間,
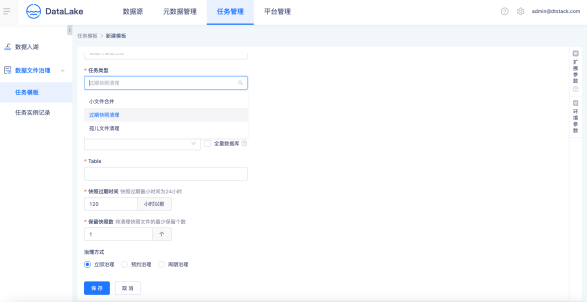
資料檔案治理
創建資料檔案治理任務模板,支持小檔案合并、快照清理、孤兒檔案清理等資料檔案治理任務,支持立即支持、預約治理、周期治理多種資料治理方式,
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/p/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack/Taier
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538410.html
標籤:大數據