目錄Python基礎之MySQL資料庫
- Python基礎之MySQL資料庫
- 一、SQL陳述句常用查詢方法
- 前期資料準備
- 1、基本查詢
- 2、撰寫SQL陳述句的小技巧
- 3、查詢之where篩選
- 3、1.功能介紹
- 3、2.實際應用
- 4、查詢之group by分組
- 4、1.功能介紹
- 4、2.實際應用
- 5、關查詢之having過濾
- 5、1.功能介紹
- 5、2.實際應用
- 6、查詢之distinct去重
- 6、1.功能介紹
- 6、2.實際應用
- 7、查詢之order by排序
- 7、1.功能介紹
- 7、2.實際應用
- 8、查詢之Limit分頁
- 8、1.功能介紹
- 8、2.實際應用
- 9、查詢之regexp正則
- 9、1.功能介紹
- 9、2.實際應用
- 二、多表查詢思路
- 資料準備
- 1、實際應用
一、SQL陳述句常用查詢方法
前期資料準備
? 為了更加直觀的展示、演示SQL陳述句查詢關鍵字,需匯入下串列格與記錄(資料)
? 模擬公司,匯入創建公司員工表,表內包含:ID、姓名、年齡、作業時間、崗位
創建人員表格:
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
gender enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一個部門一個屋子
depart_id int
);
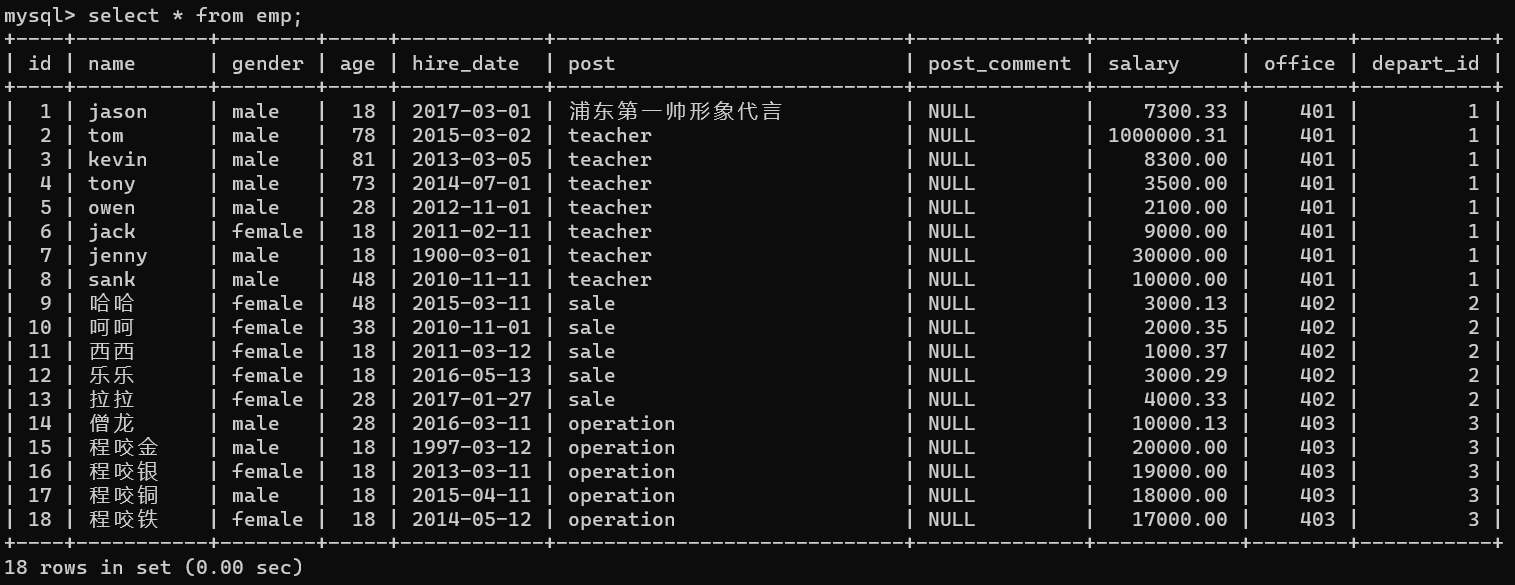
生成人員資訊:
#插入記錄
#三個部門:教學,銷售,運營
insert into emp(name,gender,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','浦東第一帥形象代言',7300.33,401,1), #以下是教學部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是銷售部門
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('樂樂','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龍','male',28,'20160311','operation',10000.13,403,3), #以下是運營部門
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬銀','female',18,'20130311','operation',19000,403,3),
('程咬銅','male',18,'20150411','operation',18000,403,3),
('程咬鐵','female',18,'20140512','operation',17000,403,3);:``
1、基本查詢
-
關鍵字:select
-
功能:基本、最常用的查詢方法,可以通過關鍵字查詢表內所有或指定的資料
select : 指定需要查詢的欄位資訊
select * 查詢所有欄位
select 欄位名 查詢指定欄位記錄
select 方法(指定的欄位) 查詢處理后的欄位記錄
from
指定需要查詢的表資訊
from 庫名.表名
from 表名
'''
注意事項:
1、SQL陳述句中關鍵字的執行順序和撰寫順序并不是一致的
eg:
select * from t1;
我們先寫的是select,執行的順序卻是from t1 ——> select *
2、對于執行的順序我們不用過多在意,只需要注意功能,熟練之后會撰寫的很自然
'''
2、撰寫SQL陳述句的小技巧
-
對于查詢用法,針對‘select’后面的欄位我們可以先使用‘*’占位,然后往后面寫,寫到需要查詢的欄位時回來補全
-
在實際應用中‘select’后面很少直接寫‘*’ , 因為星號表示所有,在當前表中資料量非常龐大時會非常浪費資料庫資源
-
SQL陳述句的撰寫類似于代碼的撰寫,不是一蹴而就的,也需要縫縫補補
-
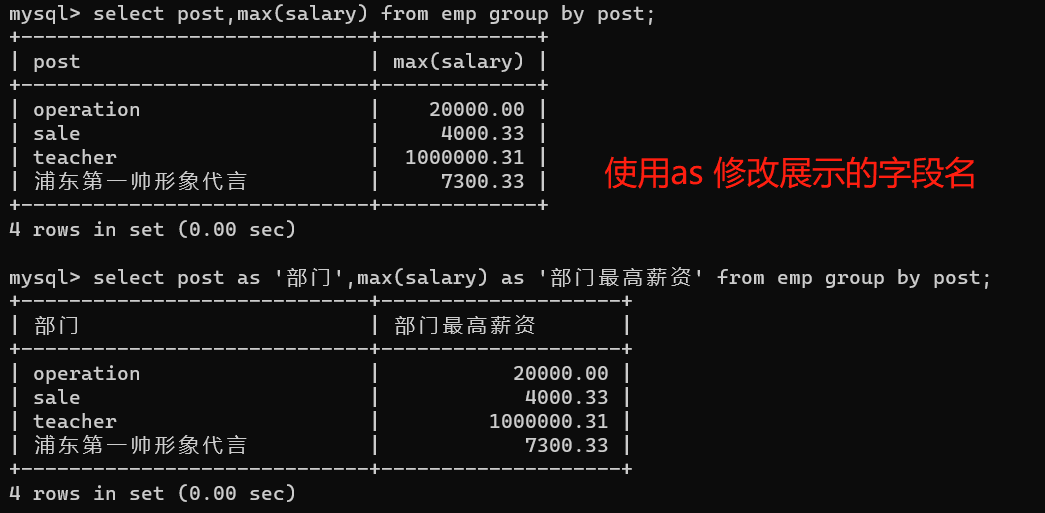
在查詢的欄位后使用‘as’的方式可以用來修改展示的欄位名,不會影響表的結構,只用來當前列印下的展示
3、查詢之where篩選
3、1.功能介紹
- 關鍵字:where
- 功能:SQL陳述句中最常用的關鍵字,用于篩選資料,支持成員運算子,邏輯運算子號、身份運算子、模糊查詢
- 模糊查詢:
- 功能:當條件不足時可使用模糊查詢,特征搭配模糊查詢字符
- 關鍵詞:like
| 字符 | 方法 | 功能 |
|---|---|---|
| % | 模糊查詢 | 搭配字符前后,匹配任意字符 |
| _ | 模糊查詢 | 搭配字符前后,匹配單個字符 |
3、2.實際應用
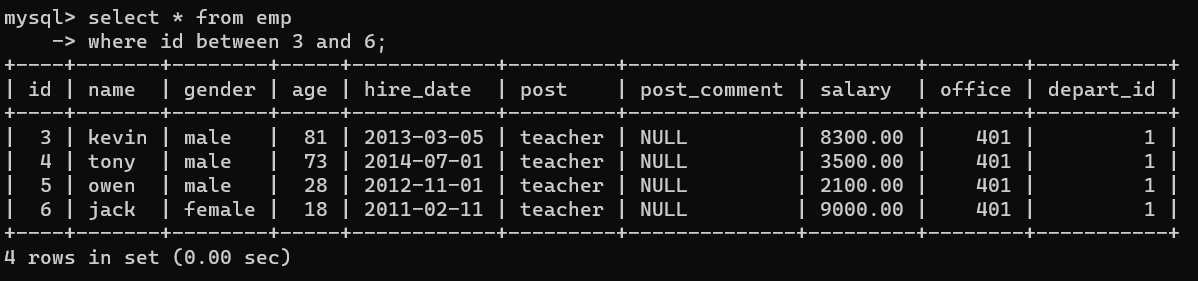
- 1.查詢id大于等于3,小于等于6的資料
1、方式一:
select * from emp where id>3 and id<=6;
2、方式二: 搭配關鍵詞:between
select * from emp where id between 3 and 6;

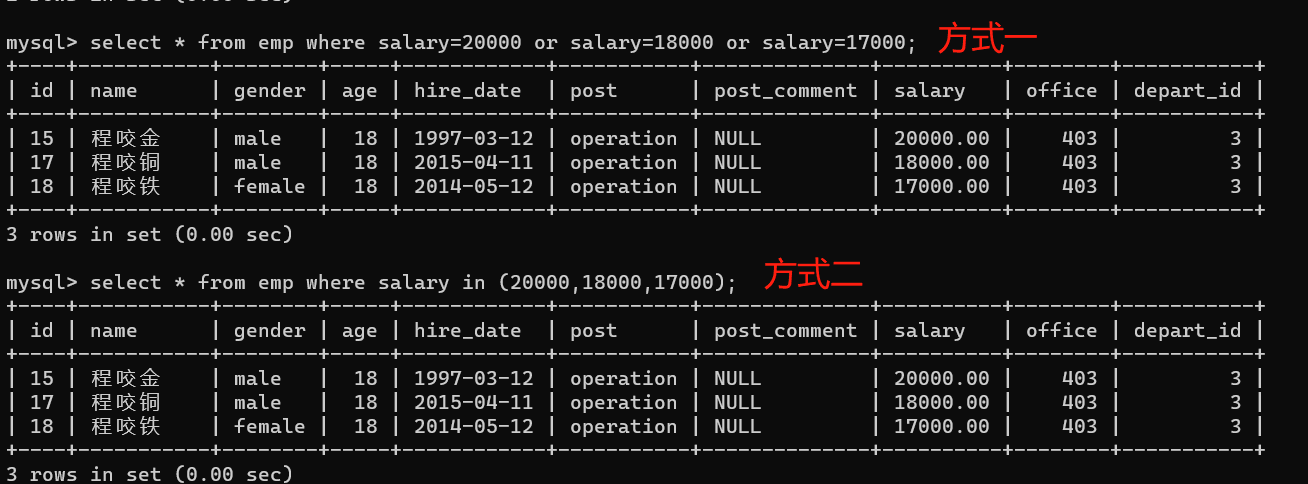
- 2.查詢薪資是20000或者18000或者是17000的資料
1、方式一:
select * from emp where salary=20000 or salary=18000 or salary=17000;
2、方式二:
select * from emp where salary in (20000,18000,17000);
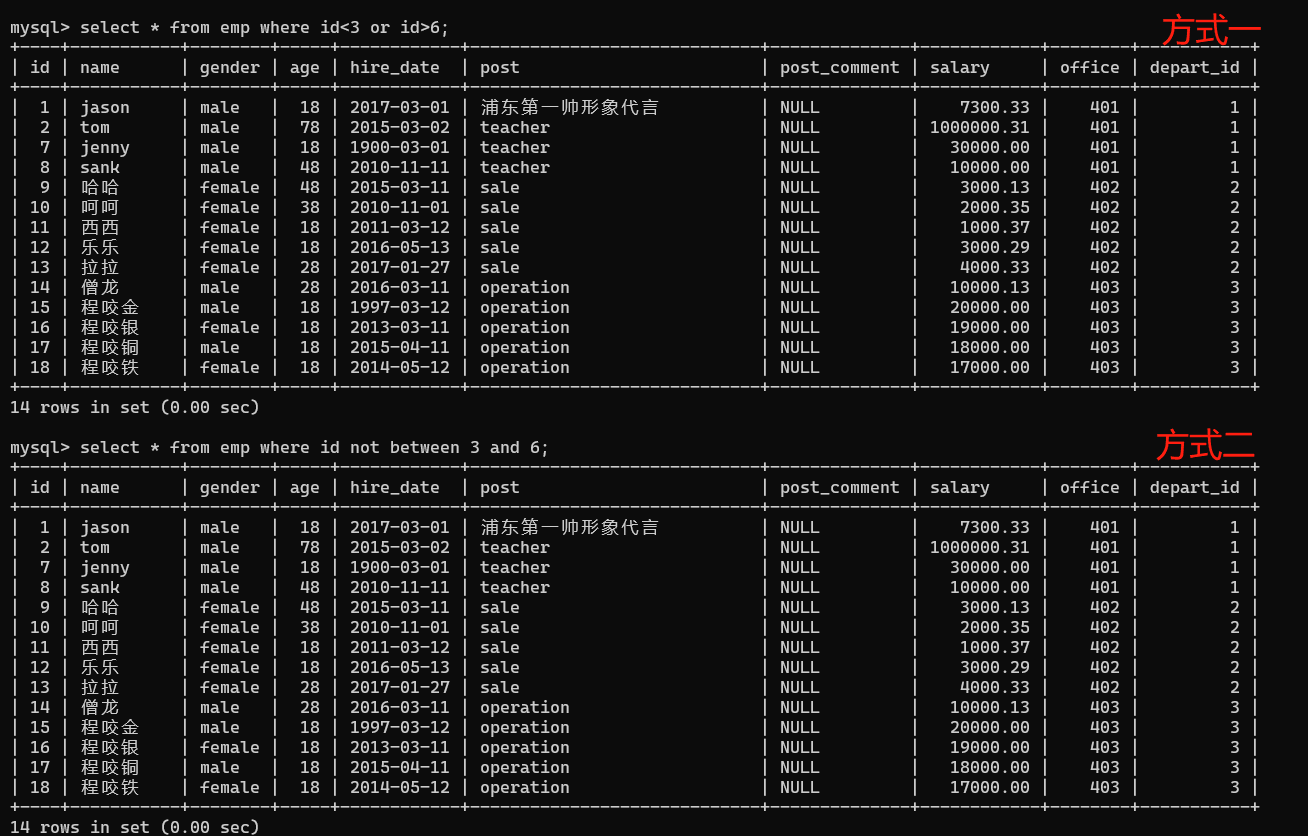
- 3.查詢id小于三和大于6的資料
1、方式一:
select * from emp where id<3 or id>6;
2、方式二:
select * from emp where id not between 3 and 6;
- 4.查詢姓名中包含o的員工姓名和薪資
? 條件不夠時通常使用模糊查詢,搭配查詢字符
select * from emp where name like %o%;

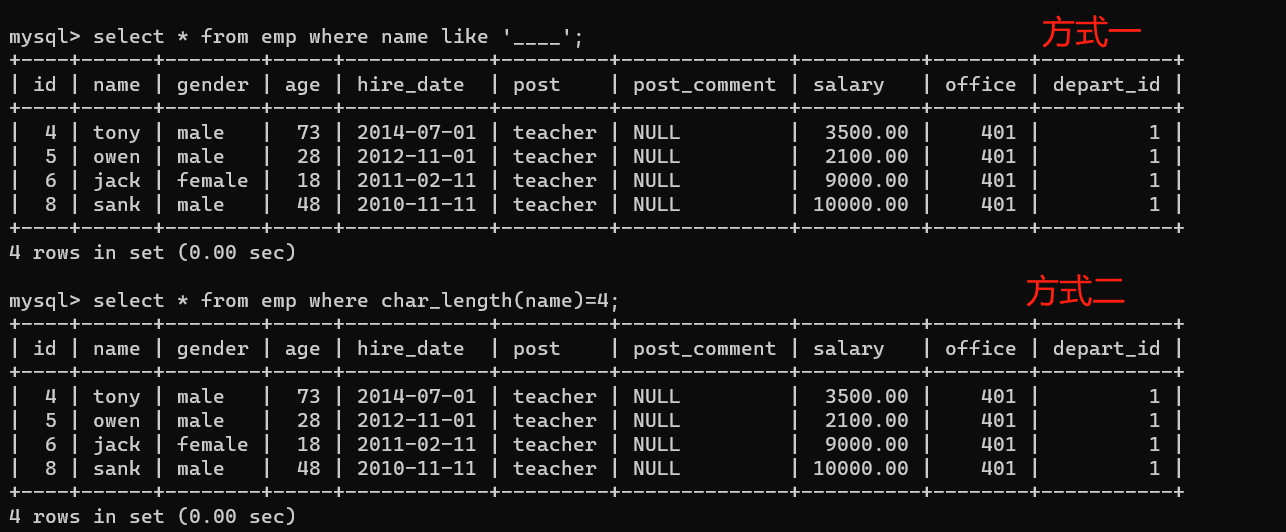
- 5.查詢員工姓名是由四個字符組成的員工姓名與其薪資
1、方式一:
selsect * from emp where name like '____';
2、方式二:
select * from emp where char_length(name)=4;
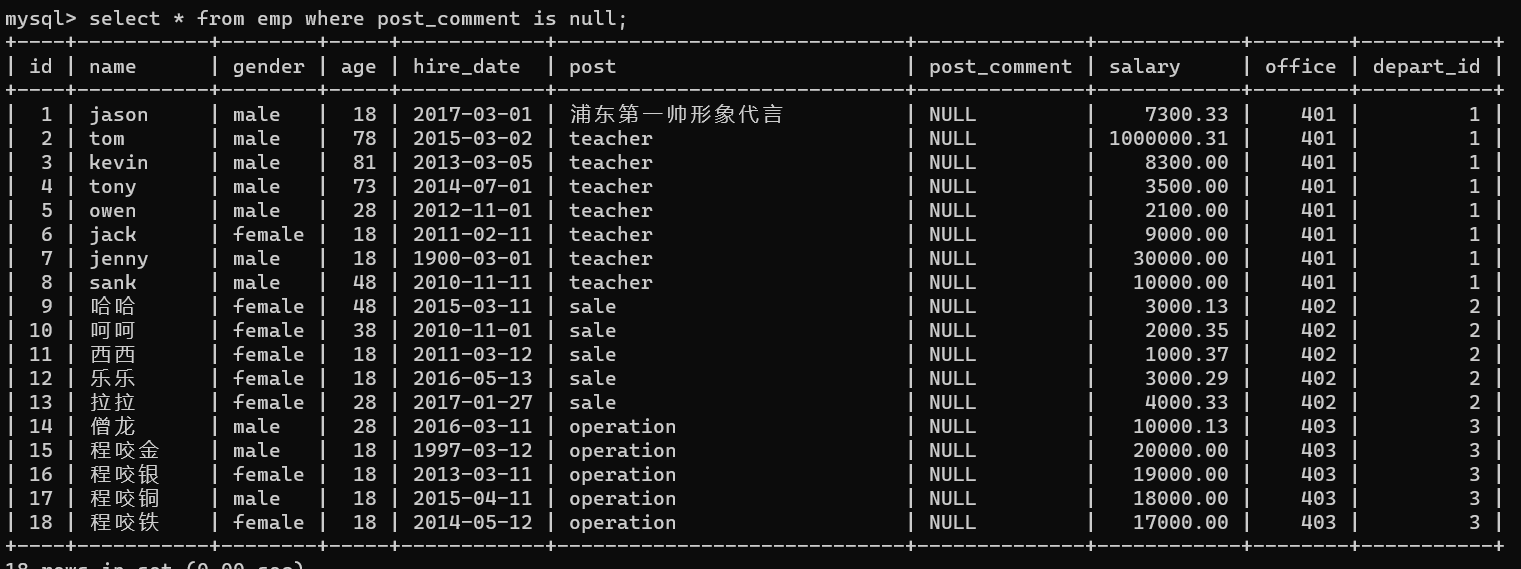
- 6.查詢崗位描述為空的員工名與崗位名---針對null不能用等號,只能用is
select * from emp where post_comment is null;
4、查詢之group by分組
4、1.功能介紹
- 關鍵詞:group by
- 功能:可以將指定的條件進行分組,例如將多個相同部門的員工按部門分組
- 可搭配聚合函式:
- max():取最大值
- min():取最小值
- sum():求和
- avg():平均值
- count():計數
4、2.實際應用
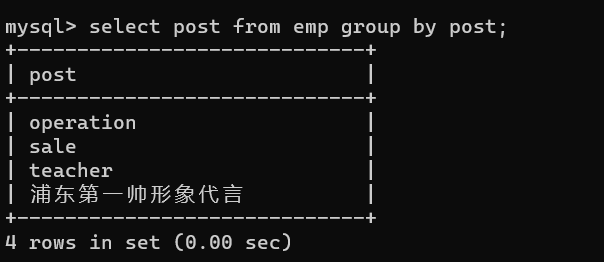
- 1.統計表內公司的總類
? 在使用,group by 的時候,可能會出現以下這種用法

? 這種方法在MySQL5.5之前,并不會報錯,但是列印的資料并不利于觀看,因為它直接將部門的某一行列印出來,我們應該將需要列印的字符名放在selsct后:
? select post from group by post;
? 在MySQL5.5之后,使用這種方法將會報錯,可以通過在配置內添加嚴格模式來改正這種方法
# 將下列代碼拷貝至my.ini檔案的MySQLd下,重啟系統環境中的MySQL服務端
sql_mode='strict_trans_tables,only_full_group_by'
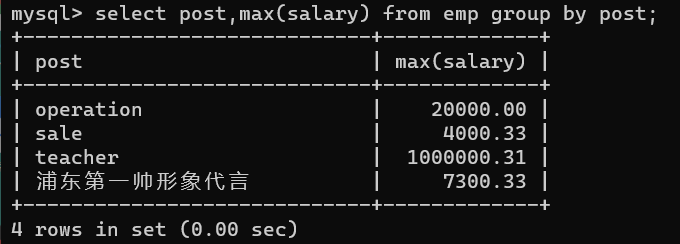
- 2.獲取每個部門的最高工資
推導流程:
# 1、先獲取部門資訊
select post from emp group by post;
# 2、獲取部門下人員工資
select post,max(salary) from emp group by post;
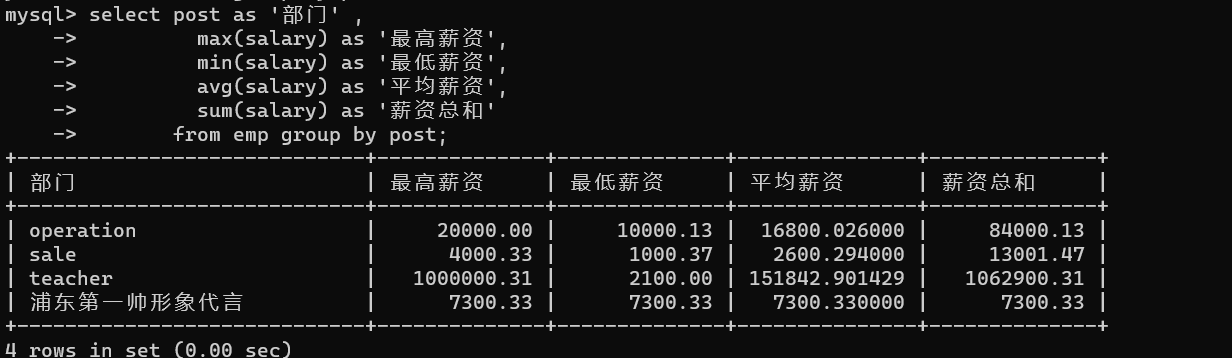
- 3.一次性獲取部門薪資的所有資料,最高、最低、平均、薪資總和
推導流程:
# 1、先獲取部門資訊
select post from emp group by post;
# 2、獲取部門下人員工資的綜合資訊
select post as '部門' ,
max(salary) as '最高薪資',
min(salary) as '最低薪資',
avg(salary) as '平均薪資',
sum(salary) as '薪資總和'
from emp group by post;
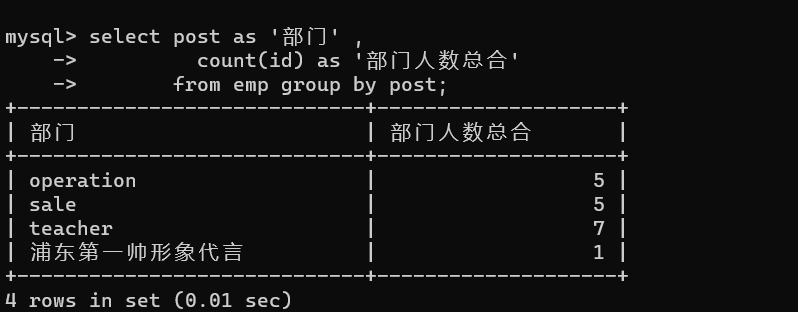
- 4.統計每個部門的人數
推導流程:
# 1、先獲取部門資訊
select post from emp group by post;
# 2、獲取部門下人員工資的綜合資訊
select post as '部門' ,
count(id) as '部門人數總合'
from emp group by post;
- 5.統計每個部門的部門名稱及員工姓名
- 使用group by后,不可直接展示多條欄位名,想要展示多條欄位名只能使用方法的方式來展示
- 關鍵詞:group_concat()
- 支持在后方闊內填入多條欄位名,需要用逗號隔開,同時也支持資料展示自定義
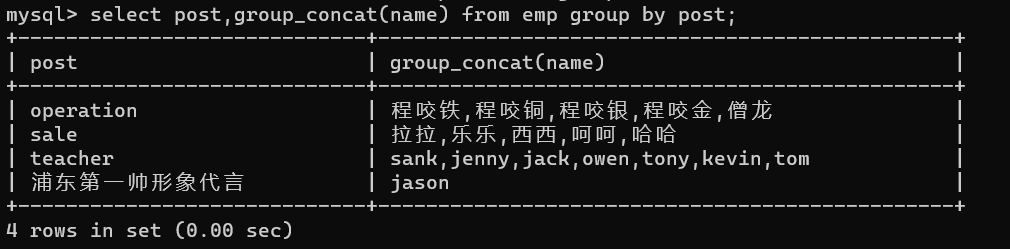
1、列印部門名稱及部門下人員姓名
select post,group_concat(name) from emp group by post;
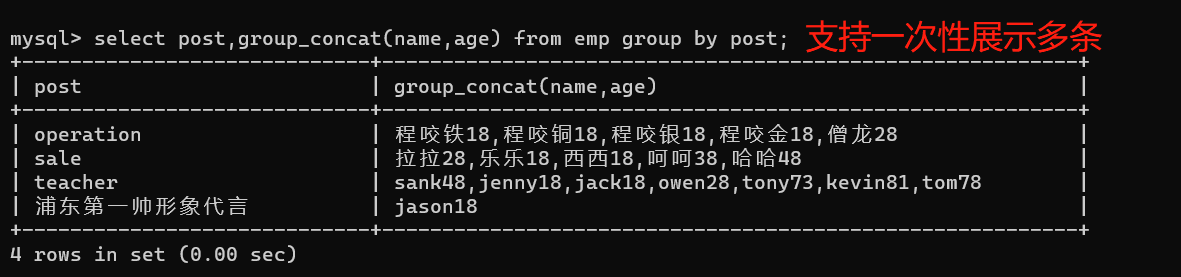
2、列印部門名稱,部門下人員姓名、年齡
select post,group_concat(name,age) from emp group by post;
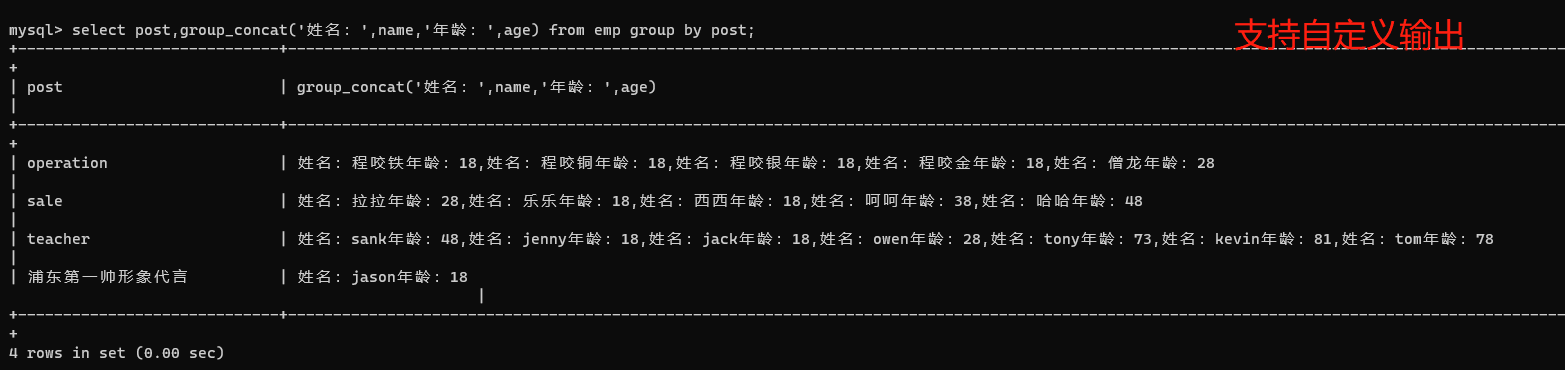
3、自定義輸出內容
select post,group_concat('姓名:',name,'年齡:',age) from emp group by post;
5、關查詢之having過濾
5、1.功能介紹
- 關鍵詞:having
- 功能:having的功能和where功能的本質是一樣的,都是用來對資料進行篩選
- 區別是having用來對資料進行二次篩選
- 功能:having的功能和where功能的本質是一樣的,都是用來對資料進行篩選
5、2.實際應用
- 1.統計各部門年齡在30歲以上的員工平均工資 并且保留大于10000的資料
推導流程:
# 1、篩選大于30的員工
select * from emp where age > 30;
# 2、對獲取的資訊進行部門分類
select post from where age > 30 group by;
# 3、對獲取的資訊取工資的平均值
select post.vag(salary) from emp where age > 30 group bay;
# 4、對平均工資進行過濾,保留大于10000的資料
select post,vag(salary) from emp where age > 30 group by having vag(salary)>10000;

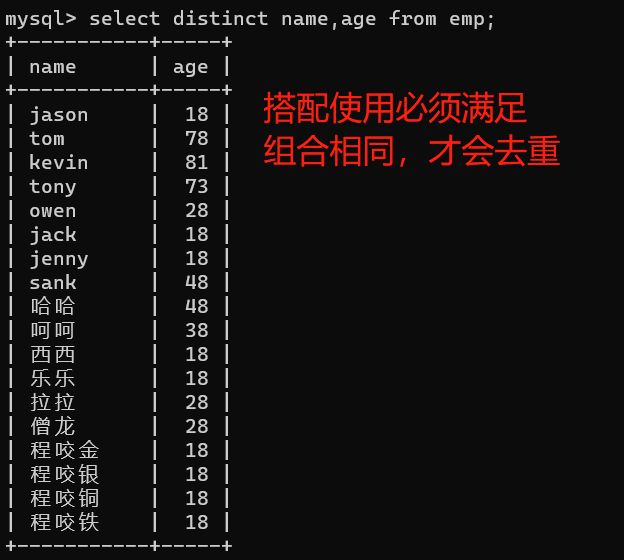
6、查詢之distinct去重
6、1.功能介紹
-
關鍵詞:distinct
-
功能:可以去除表中重復的資料,但是資料必須要一樣才可以,也可以多列使用
- 多列使用時,滿足的條件是多個欄位的組合發生重復才會去重
6、2.實際應用
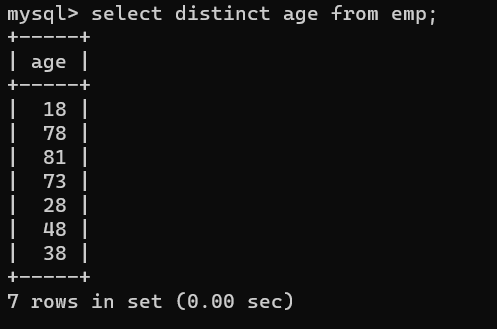
- 去除重復的年齡
1、單列使用
select distinct age from emp;
2、多列使用
select distinct name,age from emp;
7、查詢之order by排序
7、1.功能介紹
- 關鍵詞:order by
- 功能:在查看表時,可將指定的欄位下的資料排序,支持多列排序(例如先按照年齡排序,再將相同年齡段的用戶按照收入排序),默認為升序,可修改為降序
- 升降序
- 升序:
- select * from 表名 order by 欄位名;
- select * from 表名 order by 欄位名 asc;
- 降序:
- select * from 表名 order by 欄位名 desc;
- 升序:
7、2.實際應用
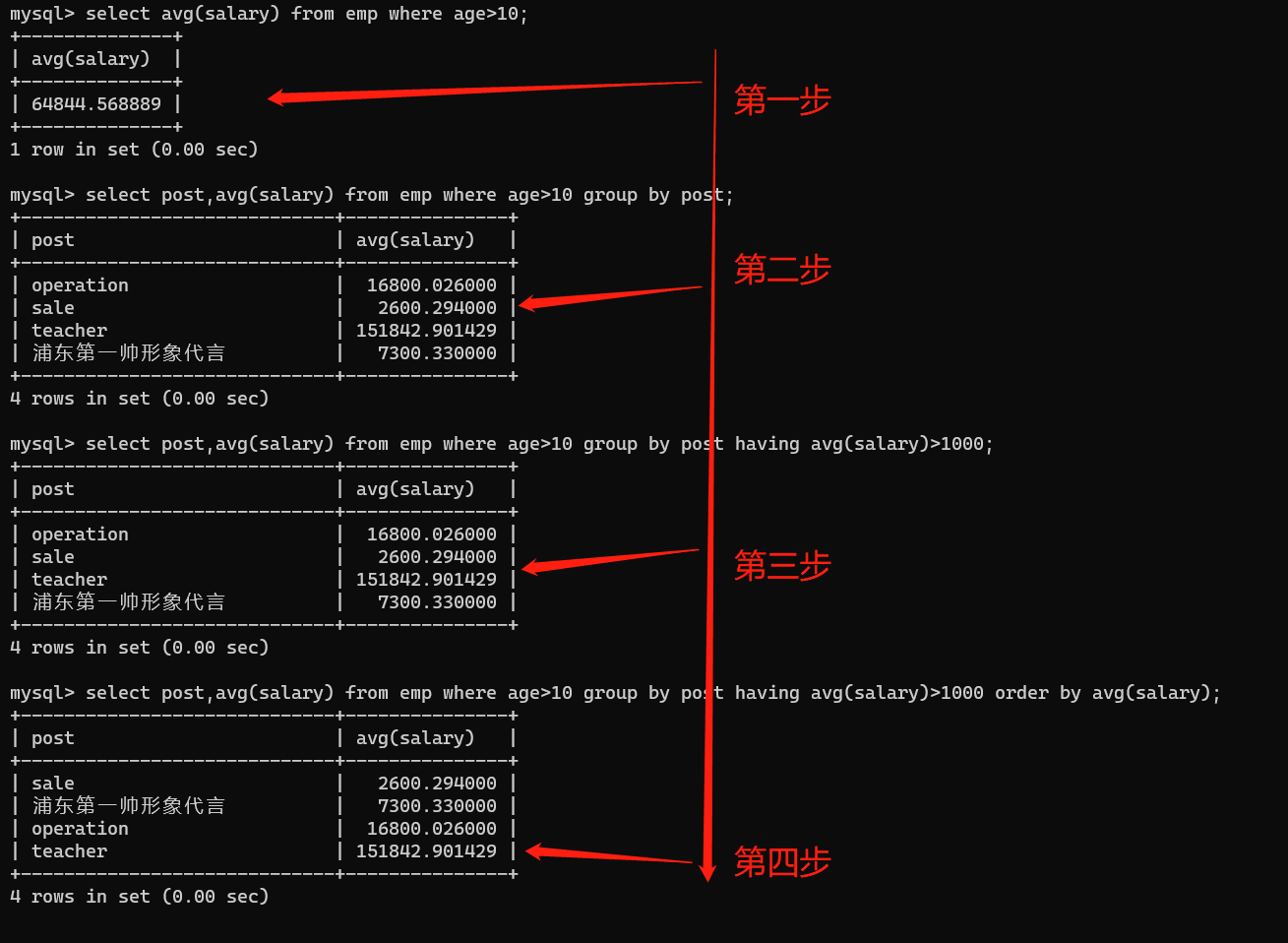
- 統計各部門年齡在10歲以上的員工平均工資,并且保留平均工資大于1000的部門,然后對平均工資進行排序
推導流程:
# 1、先篩選出年齡大于10的人員平均工資
select avg(salary) from emp where age>10;
# 2、將各部門人員資訊分開
select post,avg(salary) from emp where age>10 group by post;
# 3、進行二次篩選,保留平均工資大于1000的部門
select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000;
# 4、對工資進行排序
select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000 order by avg(salary);
8、查詢之Limit分頁
8、1.功能介紹
- 關鍵詞:limit
- 功能:當我們再打開一個資料量較為龐大的表時,會占用很多記憶體,limit可以幫助我們將表分頁,再后方闊內輸入引數可控制表打開條數,也可支持打開的范圍
8、2.實際應用
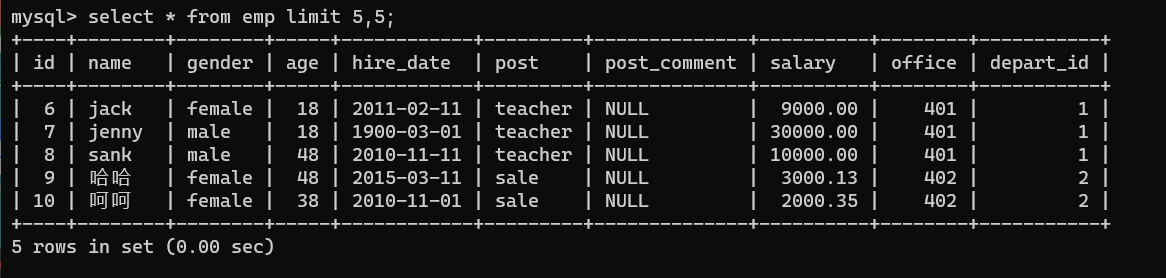
- 常規用法
1、限制表打開的條數
select * from emp limit 5;
2、控制表打開的范圍
select * from emp limit 5,5;

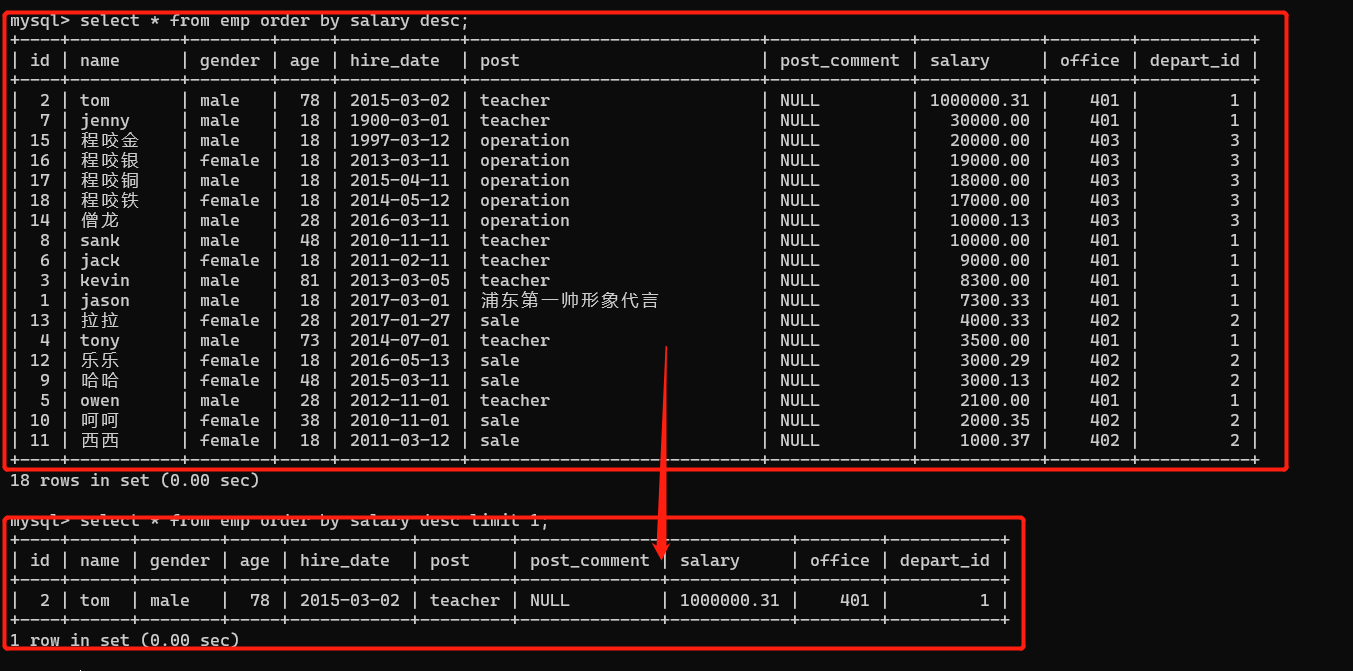
- 查詢工資最高的人的資訊
推導流程:
# 1、將表內所有人員的工資進行排序 設定為降序
select * from empor order by salary desc limit 1;
9、查詢之regexp正則
9、1.功能介紹
- 關鍵詞:regexp
- 功能:可以按照指定正則條件,對表內的資料進行搜索,是模糊搜索的一種
9、2.實際應用
- 搜索j開頭n或y結尾的用戶資訊
select * from emp where name regexp '^j.*(y|n)$';

二、多表查詢思路
資料準備
創建部門表:
create table dep(
id int primary key auto_increment,
name varchar(20)
);
創建員工資訊表:
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
插入資料:
insert into dep values
(200,'技術'),
(201,'人力資源'),
(202,'銷售'),
(203,'運營'),
(205,'財務');
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('dragon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
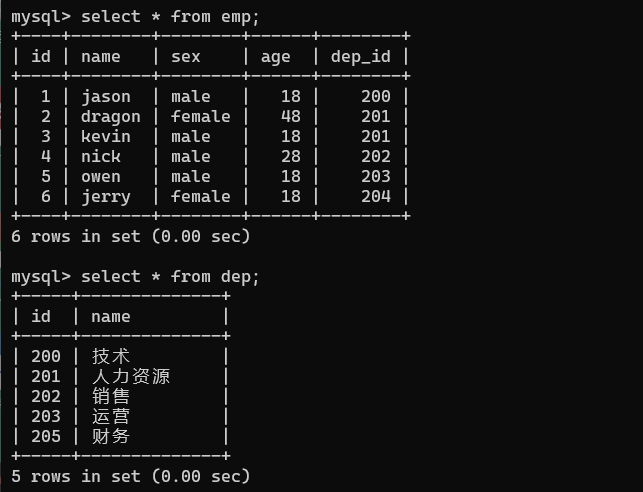
1、實際應用
? 以上兩個表,類似于公司的員工資訊,和公司部門表,兩張表為關系型表,通過之前的學習,我們了解到想要查詢資料可以通過‘select * from 表名’的方式進行查詢,其實這個方法也可以一次性查詢多張表,方法如下
select * from emp,dep;
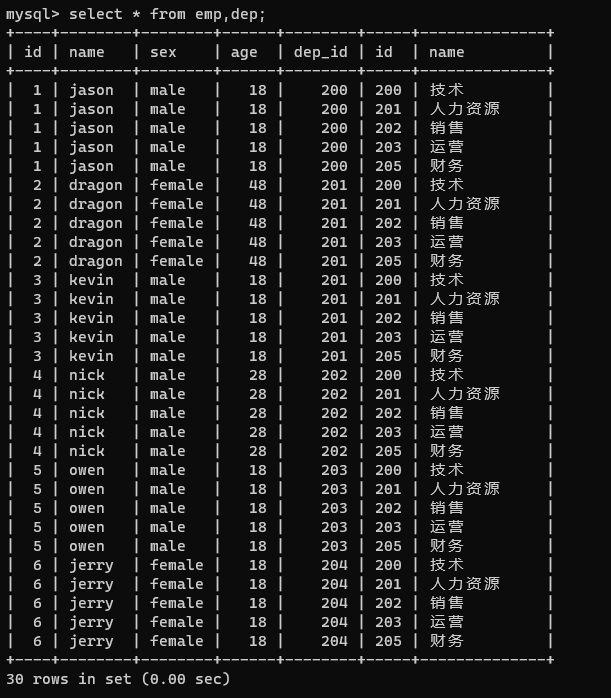
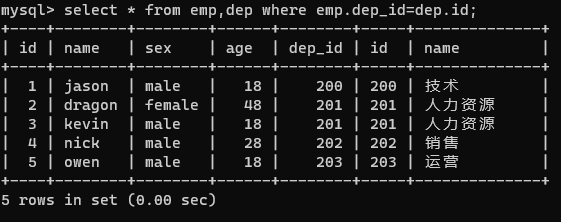
? 由上圖可以看出,select 方法一次性讀出了兩張表,但是表的資料發生了錯亂,欄位發生了沖突由此我們可以通過指定表名的方式進行查詢,避免發生錯亂
select * from emp,dep where emp.dep_id=dep.id;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538412.html
標籤:MySQL
下一篇:Linux安裝MySQL