大資料時代,無人不知Google的“三駕馬車”,“三駕馬車”指的是Google發布的三篇論文,介紹了Google在大規模資料存盤與計算方向的工程實踐,奠定了業界大規模分布式存盤系統的理論基礎,如今市場上流行的幾款國產資料庫都有參考這三篇論文,
- 《The Google File System》,2003年
- 《MapReduce: Simplified Data Processing on Large Clusters》,2004年
- 《Bigtable: A Distributed Storage System for Structured Data》,2006年
其中,Bigtable是資料存盤領域的經典論文,這篇論文首次對外完整、系統的敘述了Google是如何將LSM-Tree架構應用在工業級資料存盤產品中的,熟悉資料庫的朋友,一定對LSM-Tree不陌生,LSM-Tree起源于上世紀70年代,1996年被正式提出,之后Google成功實作商業化應用,
LSM-Tree的核心思想是“Out-of-Place Update”,可以將離散隨機寫轉化為批量順序寫,這對機械硬碟作為主流存盤介質的時代而言,能大幅度提升系統吞吐,現如今,已經有一大批成熟的KV存盤產品采用了LSM-Tree架構,例如DynamoDB, HBase, Cassandra和AsterixDB等,然而,工程實踐往往存在一種取舍,幾乎很難找到一個完美契合所有應用場景的設計,LSM-Tree在帶來優秀的寫入性能的同時,也帶來了讀寫放大和空間放大問題,
隨著硬體技術的發展,固態硬碟逐漸替代機械硬碟成為存盤的主流,曾經的核心因素(隨機寫和順序寫的性能差異)現在也不再那么核心,那么現在存盤系統設計的核心是什么呢?KeeWiDB倒是可以給你答案圖片
高性能、低成本!如何減小固態硬碟擦除次數?如何延長使用壽命?這些都是KeeWiDB研發團隊重點突破的地方,基于此,本文將重點闡述KeeWiDB中存盤引擎的設計概覽,詳細介紹資料如何存盤、如何索引,給讀者提供一些KeeWiDB的思考和實踐,
一、存盤層
圖1 展示的是存盤在磁盤上的資料檔案格式,資料檔案由若干個固定大小的Page組成,檔案頭部使用了一些Page用于存盤元資訊,包括和實體與存盤相關的元資訊,元資訊后面的Page主要用于存盤用戶的資料以及資料的索引,尾部的Chunk Page則是為了滿足索引對連續存盤空間的需求,Page至頂向下分配,Chunk Page則至底向上,這種動態分配方式,空間利用率更高,
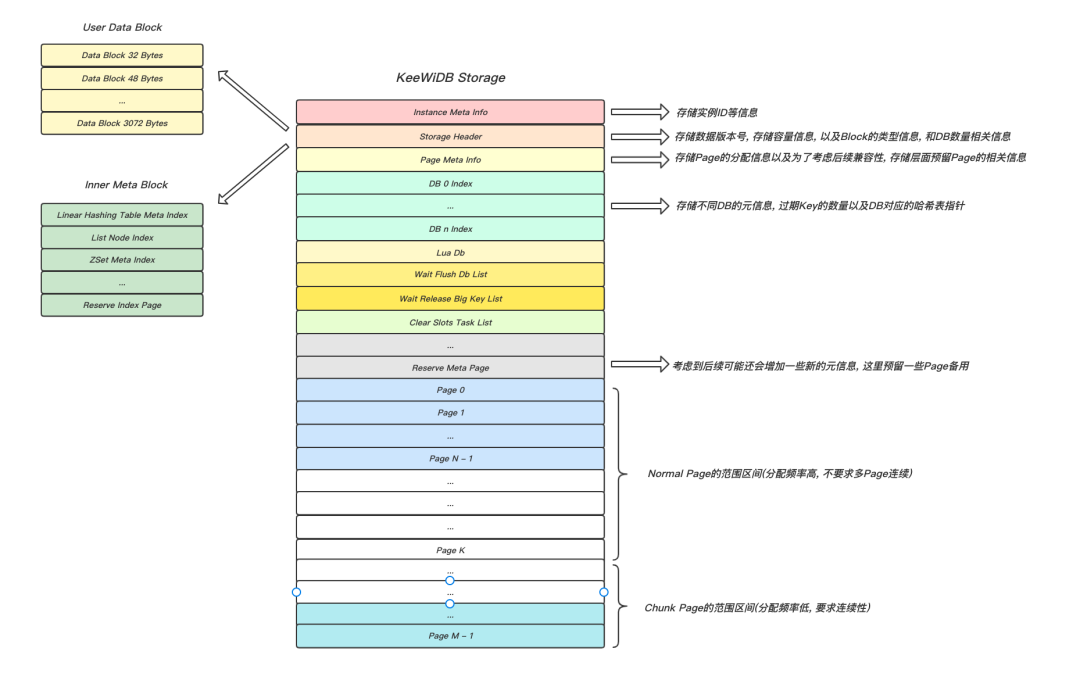
圖1 KeeWiDB的存盤層架構
和主流涉盤型資料庫相似,我們使用Page管理物理存盤資源,那么Page大小定為多少合適呢?
我們知道OS宕機可能產生Partial Write,而KeeWiDB作為一個嚴格的事務型資料庫,資料操作的持久性是必須滿足的核心性質之一,所以宕機不應該對資料的可用性造成影響,
針對Partial Write問題,業界主流的事務型資料庫都有自己的解決方案,比如MySQL采用了Double Write策略,PostgreSQL采用了Full Image策略,這些方案雖然可以解決該問題,但或多或少都犧牲了一定的性能,得益于SSD的寫盤機制,其天然就對物理頁寫入的原子性提供了很好的實作基礎,所以利用這類硬體4K物理頁寫入的原子特性,便能夠在保證資料持久性的同時,而不損失性能,此外,由于我們采用的索引相對穩定,其IO次數不會隨著Page頁大小改變而顯著不同,故權衡之下,我們選擇4K作為基本的IO單元,
至此,我們知道KeeWiDB是按照4K Page管理磁盤的出發點了,那么是否資料就能直接存盤到Page里面呢?
如你所想,不能,針對海量的小值資料,直接存盤會產生很多內部碎片,導致大量的空間浪費,同時也會導致性能大幅下降,解決辦法也很直觀,那就是將Page頁拆分為更小粒度的Block,
圖2 展示了Page內部的組織結構,主要包括兩部分:PageHeaderData和BlockTable,PageHeaderData部分存盤了Page頁的元資訊,BlockTable則是實際存盤資料的地方,包含一組連續的Block,而為了管理方便和檢索高效,同一個BlockTable中的Block大小是相等的,通過PageHeaderData的BitTable索引BlockTable,結合平臺特性,我們只需要使用一條CPU指令,便能夠定位到頁內空閑的Block塊,
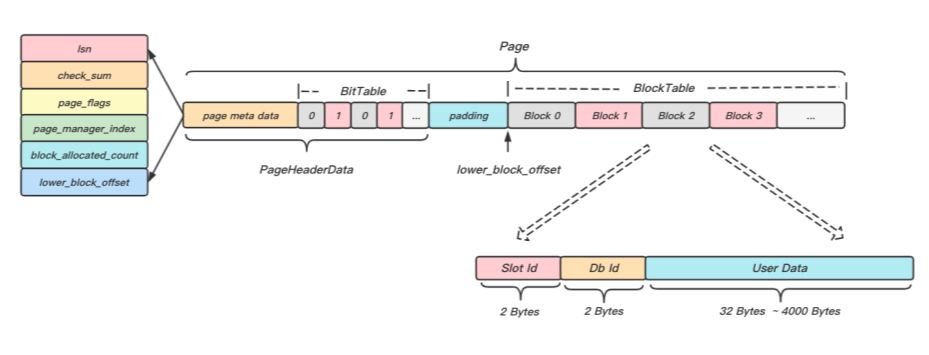
圖2 Page組成結構
而為了滿足不同用戶場景的資料存盤,存盤層內部劃分了多個梯度的Block大小,即多種型別的Page頁,每種型別的Page頁則通過特定的PageManager管理,
圖3 展示了PageManager的主要內容,通過noempty_page_list可以找到一個包含指定Block大小的Page頁,用于資料寫入;如果當前noempty_page_list為空,則從全域Free Page List中彈出一個頁,初始化后掛在該鏈表上,以便后續用戶的寫入,當Page頁變為空閑時,則從該鏈表中摘除,重新掛載到全域Free Page List上,以便其它PageManager使用,
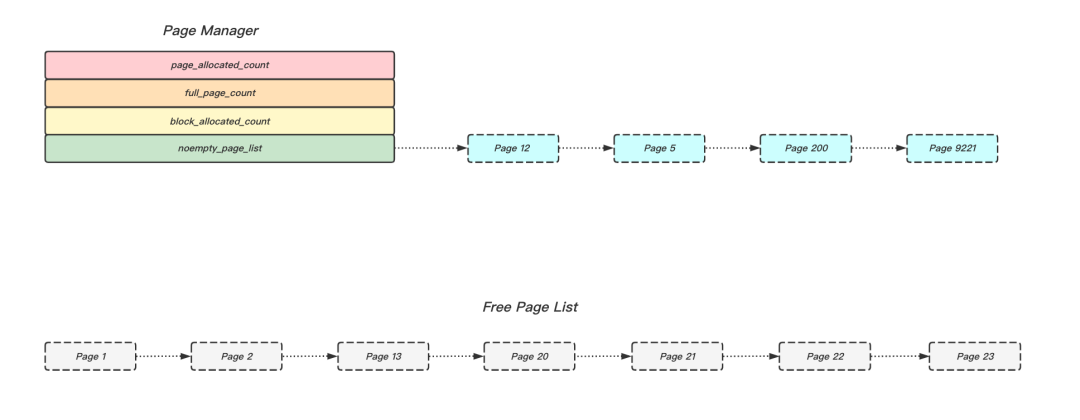
圖3 PageManager組成結構
想必大家已經發現上面的資料塊分配方式,和tcmalloc,jemalloc等記憶體分配器有相似之處,不同的是,作為磁盤型空間分配器,針對大塊空間的分配,KeeWiDB通過鏈表的方式將不同的型別的Block鏈接起來,并采用類似Best-Fit的策略選擇Block,如圖4所示,當用戶資料為5K大小時,存盤層會分配兩個Block,并通過Block頭部的Pos Info指標鏈接起來,這種大塊空間的分配方式,能夠較好的減小內部碎片,同時使資料占用的Page數更少,進而減少資料讀取時的IO次數,
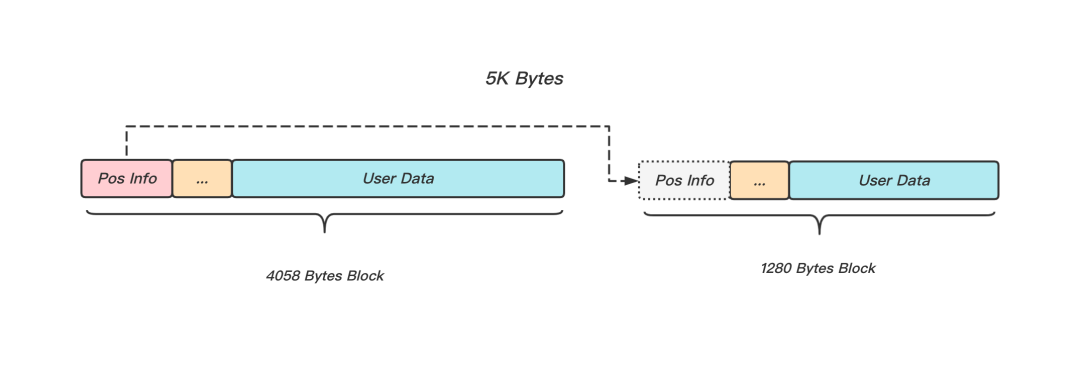
圖4 Block鏈式結構
以上便是用戶資料在KeeWiDB中存放的主要形式,可以看出,用戶資料是分散存盤在整個資料庫檔案中不同Page上的,那么如何快速定位用戶資料,便是索引的主要職責,
二、索引層
2.1 選型
KeeWiDB定位是一個KV資料庫,所以不需要像關系型資料庫那樣,為了滿足各種高性能的SQL操作而針對性的建立不同型別的索引,通常在主索引上,對范圍查詢需求不高,而對快速點查則需求強烈,所以我們沒有選擇在關系型資料庫中,發揮重要作用的B-Tree索引,而選擇了具有常數級等值查詢時間復雜度的hash索引,
hash索引大體上存在兩類技術方案Static Hashing和Dynamic Hashing,前者以Redis的主索引為代表,后者以BerkeleyDB為代表,如圖5所示,Static Hashing的主要問題是:擴容時Bucket的數量翻倍,會導致搬遷的資料量大,可能阻塞后續的讀寫訪問,基于此,Redis引入了漸進式Rehash演算法,其可以將擴容時的元素搬遷平攤到后續的每次讀寫操作上,這在一定程度上避免了阻塞問題,但由于其擴容時仍然需要Bucket空間翻倍,當資料集很大時,可能導致剩余空間無法滿足需求,進而無法實作擴容,最終使得Overflow Chain過長,導致讀寫性能下降,
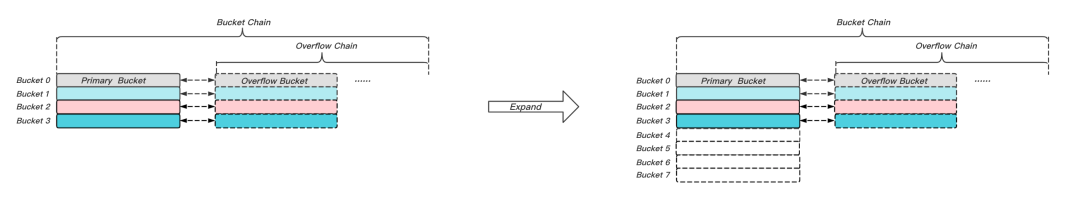
圖5 Static Hashing擴容示意圖
Dynamic Hashing技術旨在解決Overflow Chain過長的問題,核心思想是在Bucket容量達到閾值時,進行單個Bucket的分裂,實作動態擴容,而不是當整個hash table填充率達到閾值時才擴容,這樣可以避免資料傾斜時,導致某個桶Overflow Chain過長,影響處理延遲,同時動態擴容每次只需一個Bucket參與分裂,擴容時搬遷資料量小,Dynamic Hashing通常有兩種選型:Extendible Hashing和Linear Hashing,這兩種演算法都實作了上述動態擴容的特性,但實作方式有所不同,
如圖6所示,Extendible Hashing使用Depth來表達參與運算的hashcode的最低有效位的長度,Local Depth和Bucket系結,表示其中元素指定的最低有效位相等,等價于hash取模,Global Depth則表示全域參與運算的最低有效位長度的最大值,即代表當前邏輯Bucket的個數,Directory是指標陣列,用于指代邏輯Bucket的物理位置資訊,和物理Bucket存在多對一的映射關系,當Bucket的Local Depth等于Global Depth時,映射關系為一對一,
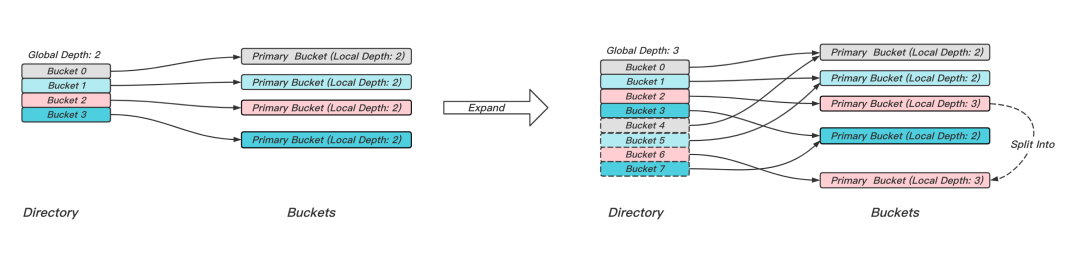
圖6 Extendible Hashing擴容示意圖
我們看看Extendible Hashing是怎么處理擴容的,若插入元素后,Bucket容量達到閾值,首先將該Bucket的Local Depth加1,然后分情況觸發擴容:
- 若當前Bucket的Local Depth < Global Depth,則只需要將該Bucket分裂,重設Directory指標即可,
- 若當前Bucket的Local Depth == Global Depth,則不僅需要分裂該Bucket,同時還需要將Directory翻倍,并重設指標,
以圖6為例,Bucket 2中的元素在擴容前,參與運算的最低有效位為10(Local Depth等于2);在擴容時,首先將Local Depth加1,然后最低有效位為010的元素保持不動,而其余有效位為110的元素,便被搬遷到物理Bucket 6中,由于Global Depth小于Local Depth,所以需要對Directory陣列翻倍擴容,然后將邏輯Bucket 6的位置資訊,指向物理Bucket 6,其余邏輯Bucket 4,5和7,則分別指向現存的物理Bucket 0,1,和3,
Extendible Hashing可以完全避免Overflow Chain的產生,使元素的讀取效率很高,但也存在弊端:Directory需要翻倍擴容,同時重設指標代價高,雖然Directory存盤的只是位置資訊,和Static Hashing相比空間利用率更高,但仍然無法避免當Bucket數量很大時,擴容對大塊空間的需求,同時擴容需要重設的Directory指標資料量,可能會隨著資料集的增大而增大,這對涉盤型資料庫來說,需要大量的磁盤IO,這會極大增加處理的長尾延遲,
Linear Hashing和Extendible Hashing相似,若插入操作導致Bucket容量達到閾值,便會觸發分裂,不同的是,分裂的Bucket是next_split_index指向的Bucket,而不是當前觸發分裂的Bucket,這種按順序分裂的機制,彌補了Extendible Hashing需要重設指標的缺點,如圖7所示,當Bucket 1插入元素17后達到了容量限制,便觸發分裂,分裂next_split_index指代的Bucket 0,最低有效位為000的元素保持不動,把最低有效位為100的元素搬遷到新建的Bucket 4中,并將next_split_index向前遞進1,
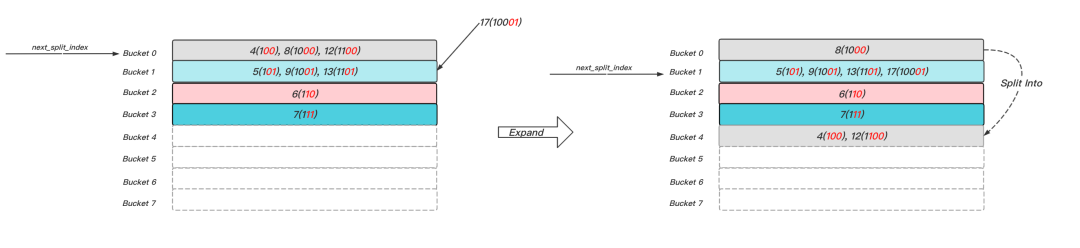
圖7 Linear Hashing擴容示意圖
Extendible Hashing通過Directory指標陣列索引Bucket位置資訊,而Linear Hashing則通過兩個hash表來解決定位問題,如圖8所示,和采用漸進式Rehash的Redis相似,可以將hash table看作同時存在一小一大兩個表,分別以low_mask和high_mask表征,當定位元素所屬Bucket時,主要分為以下幾步:
- 通過散列函式計算得到元素的hashcode;
- 通過low_mask計算元素的候選bucket_index,bucket_index = hashcode & low_mask;
- 若bucket_index >= next_split_index,則其為目標Bucket;
- 若bucket_index < next_split_index,說明其對應的Bucket已經被分裂,那么參與運算的最低有效位數應該增加1位,即需要通過high_mask計算元素的目標bucket_index,bucket_index = hashcode & high_mask,
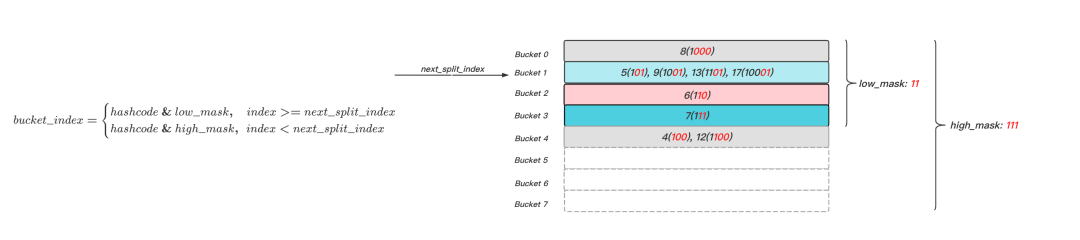
圖8 Linear Hashing訪問示意圖
當然Linear Hashing也存在一個缺點:如果資料不均勻,則可能導致某個Bucket無法及時分裂,進而產生Overflow Chain,但相比Static Hashing而言,其長度要短很多,同時工程實踐中,可以通過預分配一定數量的Bucket,緩解資料傾斜的問題,如果再適當調小觸發Bucket分裂的容量閾值,幾乎可以做到沒有Overflow Chain,結合Extendible Hashing存在擴容時磁盤IO不穩定的問題,我們最終選擇了Linear Hashing作為KeeWiDB的主索引,
2.2 詳細設計
2.2.1 基礎架構
接下來我們將走近KeeWiDB,看看Linear Hashing的工程實踐,如圖9所示,整個索引可以概括為三層:HashMetaLayer,BucketIndexLayer和BucketLayer,下面我們將分別對每個層次的內容和作用作一個概述,
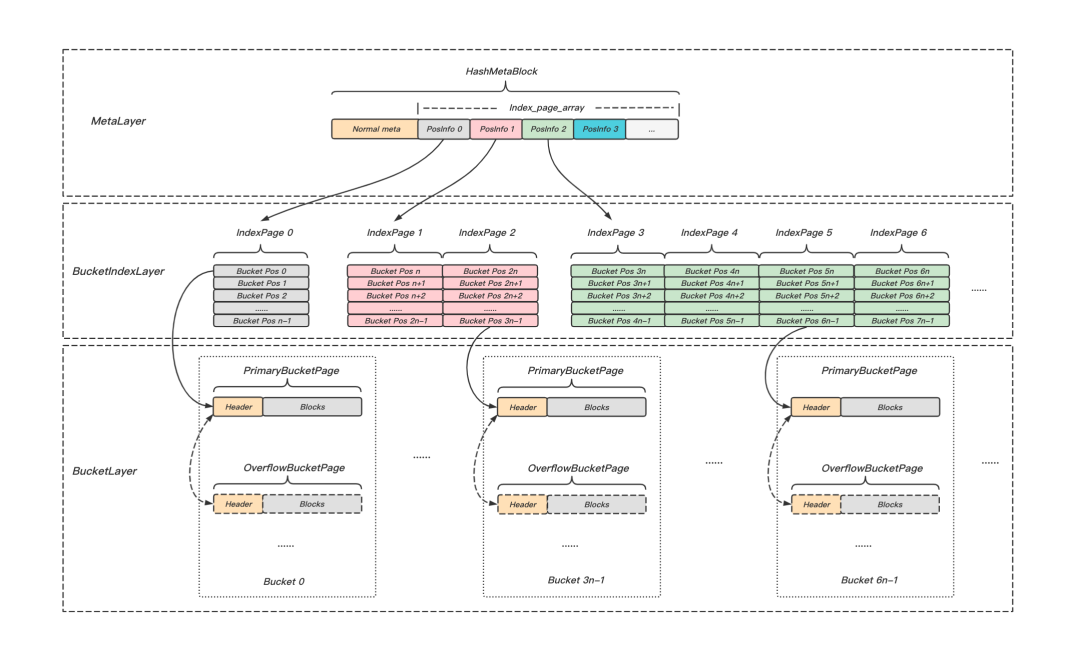
圖9 Linear Hashing實作架構圖
HashMetaLayer
HashMetaLayer主要用于描述hash table的元資訊,如圖10所示,主要包括以下內容:
- current_size: 當前hash table存盤的元素個數;
- split_bucket_index: 下次需要分裂的Bucket邏輯編號;
- current_bucket_count: 當前使用的Bucket數量;
- low_mask: 用于映射hash table的小表,high_mask =(low_mask << 1) | 1;
- index_page_array: 用于存盤分段連續的IndexPage的起始頁的位置資訊;
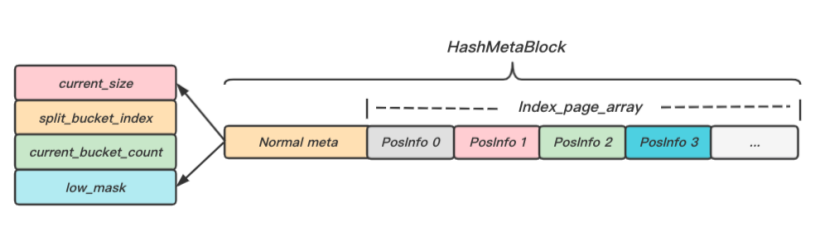
圖10 hash meta組成結構
BucketIndexLayer
BucketIndexLayer表示一組分段連續的IndexPage頁面,IndexPage主要用于存盤物理Bucket的位置資訊,其作用類似于Extendible Hashing的Directory陣列,通過引入BucketIndexLayer,可以使物理Bucket離散分布于資料庫檔案中,避免對連續大塊存盤空間的需求,引入額外的層次,不可避免的會導致IO和CPU的消耗,我們通過兩個方面來減小消耗,
首先,通過hash meta存盤的index_page_array,將定位目標Bucket的時間復雜度做到常數級,減小CPU消耗,由于每個IndexPage所能容納的Bucket位置資訊數量是固定的,所以如果將IndexPage看作邏輯連續的Page陣列時,就可以在O(1)時間復雜度下計算出Bucket所屬的IndexPage邏輯編號,以及其在IndexPage內部的偏移,再把分段連續的IndexPage的第一個頁的物理位置資訊記錄在index_page_array陣列中,定位到IndexPage的物理位置便也為常數級,如圖11所示,連續的IndexPage的頁面個數與index_page_array的陣列索引的關系為分段函式,采用分段函式主要基于以下考慮:
- 減小空間浪費,使每次分配的IndexPage數量,隨著資料量的增大而增大,而不是維持固定值,避免小資料量時造成空間浪費,特別是在多DB場景下(索引相互獨立),用戶資料傾斜時,這種空間浪費會被放大;
- 增加空間使用的靈活性,每次分配IndexPage的數量也不能無限增大,避免無法分配大塊的連續空間,
再者,我們通過記憶體快取避免IndexPage的額外IO消耗,KeeWiDB通過10MB的常駐記憶體,便可以索引數十億個元素,
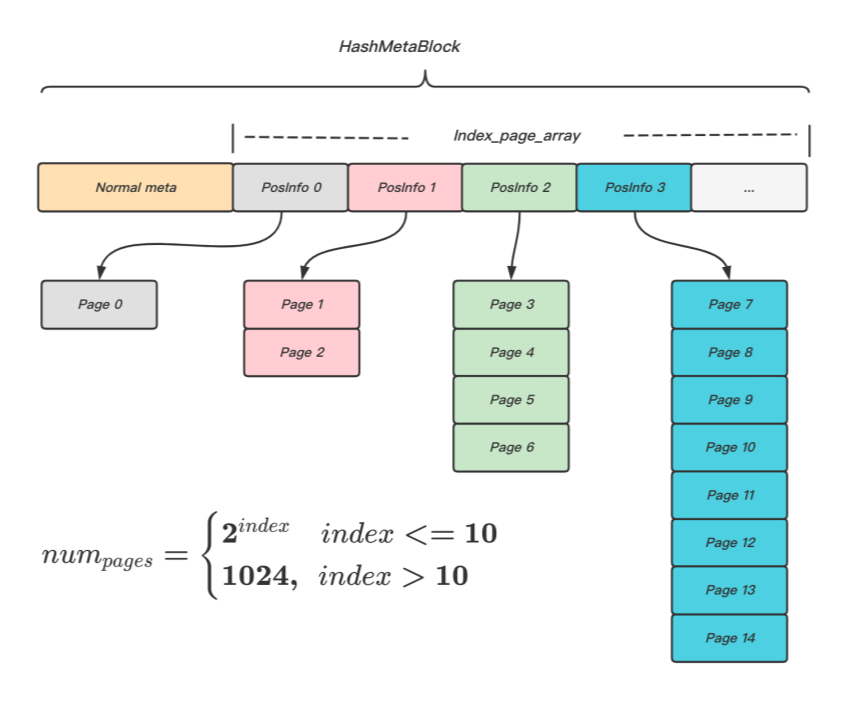
圖11 indexpagearray 結構示意圖
讀者可能有疑問,既然IndexPage可以做到分段連續,那為何不直接將BucketPage做到分段連續,這樣可以避免引入IndexPage,似憾訓能減少IO次數,不這么做,是因為相同大小的連續空間,前者能索引的元素個數是后者的數百倍,所以在多DB場景下,前者更具有優勢,與此同時,如果采用相似的索引策略,后者也并不能減小IO次數,因為bucket_page_array是index_page_array的數百倍大,這會導致hash meta無法存放在一個Page中,導致IO次數增加,所以,最終我們選擇犧牲少量記憶體空間,以提高磁盤空間使用的靈活性,
BucketLayer
BucketLayer則是最終存盤hash元素,即用戶資料索引的地方,每一個邏輯Bucket由一組物理BucketPage鏈接而成,即采用開鏈法解決hash沖突,只是鏈接的單位是Page頁而不是單個元素,BucketPage鏈表頭稱為PrimaryBucketPage,其余則為OverflowBucketPage,
如圖12所示,BucketPage主要包括兩方面內容:代表元資訊的Header和存盤資料的Blocks,Header存盤的內容又可以分為兩部分:表征Bucket結構和狀態的Normal Meta,以及表征BucketPage內部Blocks存盤狀態的blocks map,Blocks陣列是實際存盤元素的地方,其和元素一一對應,
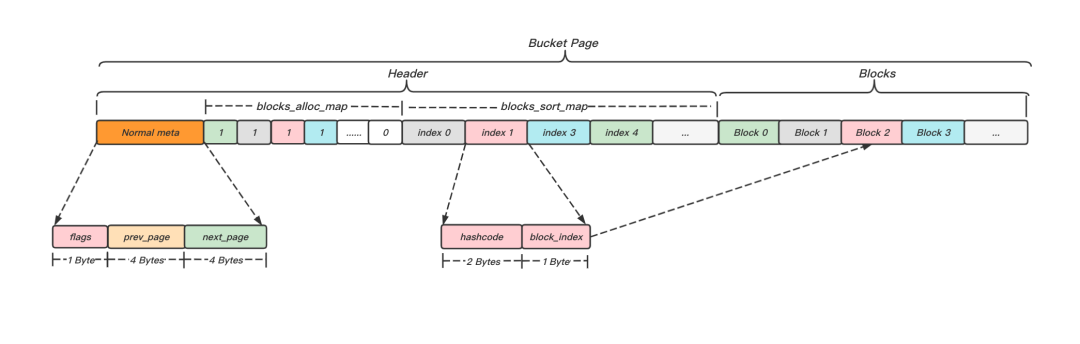
圖12 Bucket Page組成結構
BucketPage可以看作是一個按照元素hashcode排序的有序陣列,元素查找主要分為三步:
- 首先通過blocks_sort_map,二分查找與待查鍵hashcode相等的index;
- 通過index內記錄的block_index,找到其對應的Blocks陣列中的元素,即為候選索引;
- 通過該候選索引讀取存盤的用戶資料,若存盤的資料健與待查健二進制相等,則該索引即是目標索引,
更新操作只需要將查找到的Blocks陣列中對應的Block替換為新的元素,而元素插入操作在查找無果的基礎上,還需要以下幾步:
- 通過blocks_alloc_map找到Blocks陣列的空位,并將對應的bit位置1;
- 將元素插入到該Blocks陣列指定的空位中;
- 構建index,更新blocks_sort_map,
同樣,元素洗掉操作在查找成功后,也需要額外幾步:
- 通過blocks_alloc_map找到指定的bit位,將其置為0;
- 洗掉index,更新blocks_sort_map,
除了用戶觸發的讀寫操作,hash table自身還存在分裂和合并操作,如圖13所示,展示了Bucket分裂和合并時的狀態轉化圖,Bucket主要存在五種狀態:
- Normal:常規狀態;
- BeingSplitted:分裂狀態,觸發分裂時,源端Bucket的狀態;
- BeingMerged: 合并狀態,觸發合并時,源端Bucket的狀態;
- BeingFilled:填充狀態,觸發分裂(合并)時,目的端Bucket的狀態;
- BeingCleanup:清理狀態,分裂(合并)完成時,源端Bucket的狀態,
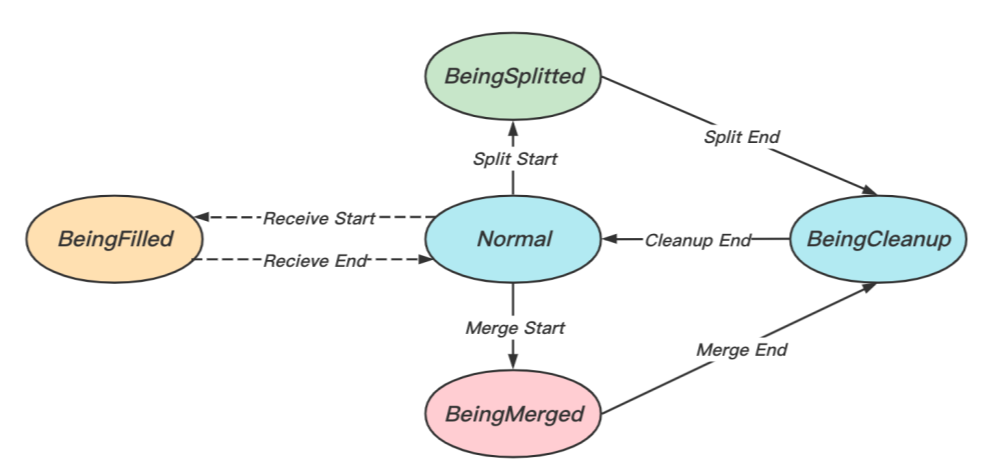
圖13 Bucket狀態轉換圖
如圖14所示,Bucket分裂操作主要分為三個階段:
- Prepare階段:創建目的Bucket物理頁,更新hash table結構,分別設定源端和目的端Bucket狀態為BeingSplitted和BeingFilled;
- Split階段:將源端Bucket的資料,按照high_mask重新rehash,將不再屬于該Bucket的資料拷貝至目的Bucket;
- Cleanup階段:將不再屬于源端Bucket的資料清理掉,
和分裂操作相似,Bucket的合并操作也分為三個階段:
- Prepare階段:分別設定源端和目的端Bucket狀態為BeingMerged和BeingFilled,
- Merge階段:將源端Bucket資料,拷貝至目的端Bucket,
- Cleanup階段:清理源端Bucket,更新hash table結構,
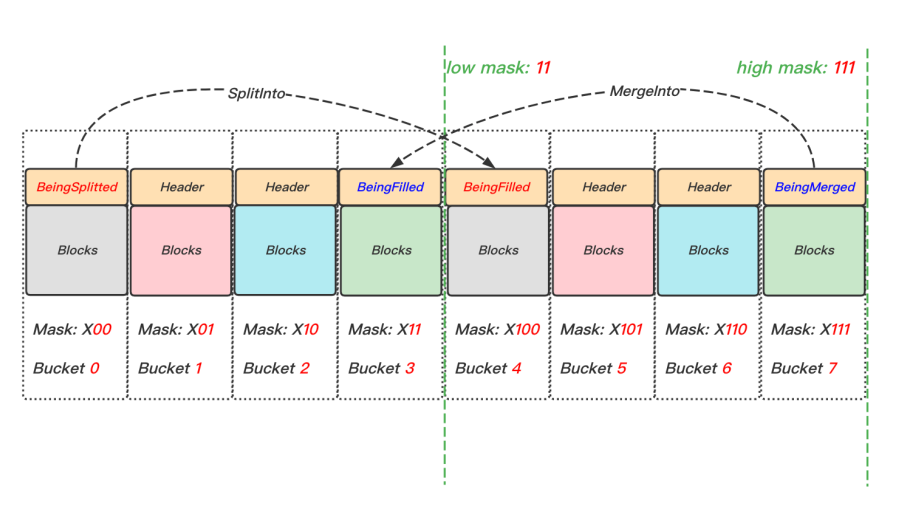
圖14 Bucket分裂和合并示意圖
那么,正常讀寫場景下,用戶訪問延遲有多大呢?現在我們梳理下,用戶寫入資料時典型的IO路徑:
- 存盤層分配資料Block,用于存放用戶資料,并構建用戶資料索引資訊;
- 查找主索引的元資料HashMetaBlock;
- 通過用戶資料鍵的hashcode值,計算得到目標Bucket邏輯編號,并定位IndexPage;
- 通過IndexPage找到對應的BucketPage,插入用戶資料索引,
由于HashMetaBlock和IndexPage資料量很小(億級資料集只需幾兆空間),可以直接快取在記憶體中,那么一次典型的小值寫入,平均只需要兩次IO:一次資料寫入,一次索引寫入,這樣平均處理延遲就能維持在較低的水平,隨著資料集的增大,寫入可能觸發分裂式擴容,而大多數場景下,擴容只會涉及2個BucketPage,即只需要額外兩次IO,且IO次數不會隨著資料量的增大而增大,這樣處理的長尾延遲就相對穩定可控,
2.2.2 并發控制
讀者通過架構篇可以了解到,KeeWiDB采用了Shared-Nothing的架構設計,宏觀上將資料集按Slot進行了拆分,每個執行緒獨立負責部分Slot資料的讀寫,即發揮了多核并發的優勢,而對于執行緒內部的讀寫訪問,則引入了協程機制,來提高單核處理能力,協程級并發意味著可能存在多個協程同時訪問系統資源,與主流關系型資料庫相似,KeeWiDB通過兩階段鎖實作事務serializable級別的隔離性要求,關于事務的相關內容,后續我們會有專題進行詳細介紹,這里我們主要討論的是,存盤引擎層是如何保障資料訪問的并發安全,
hash索引的并發控制,其核心是需要滿足以下要求:
- 讀取保障:不會讀取到中間狀態的值,記作R-1;
- 讀取保障:不會因為分裂(合并),導致讀取不到原本應該存在的值,記作R-2;
- 寫入保障:并發寫入不會互相干擾,即寫入滿足原子性,記作W-1;
- 寫入保障:不會因為分裂(合并),導致丟失更新,記作W-2;
- 自恢復保障:不會因為中途宕機,導致hash table結構被破壞,無法恢復服務,記作SR,
總體上,hash索引主要采用了三種鎖確保并發安全:
- Page鎖:讀寫物理鎖,確保物理頁訪問的原子性;
- Bucket鎖:Bucket級別讀寫邏輯鎖,確保分裂(合并)時,寫入的并發正確性;
- Exclusive鎖:特殊的Page寫鎖,該Page無他人參考,
什么是參考計數呢?如圖15所示,Page從磁盤加載上來之后,存盤在Cache模塊的Buffer陣列中,并通過PageDesc索引,每當用戶請求相關Page,便使其參考計數加1,釋放Page則參考計數減1,后臺協程會通過演算法周期性的選擇參考計數為0的頁淘汰,Exclusive鎖的含義就是除了請求者之外,無他人參考,即參考計數為1,
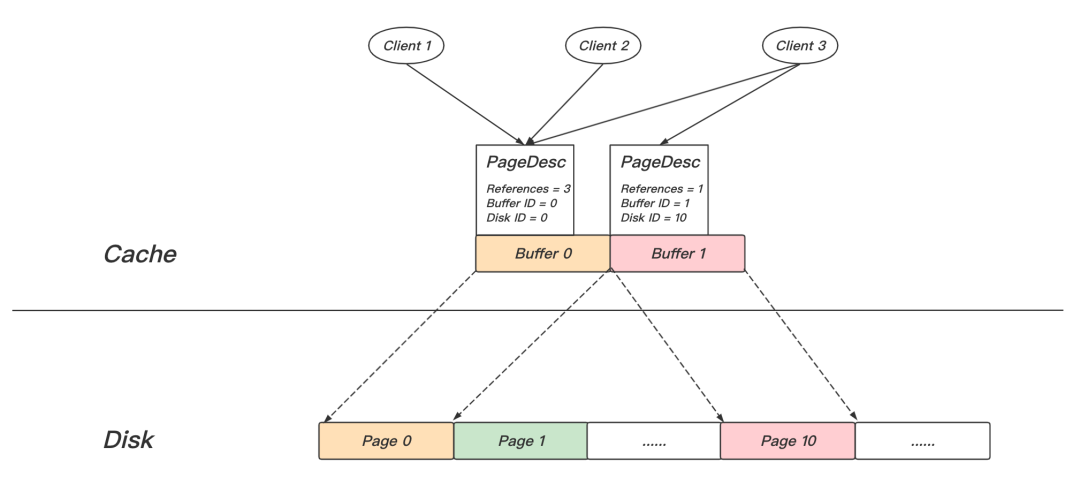
圖15 Page Cache模塊示意圖
下面將分別從內部hash table resize和外部用戶讀寫兩個典型場景,簡要描述我們是如何做到并發安全的,為了后續行文方便,現在對部分簡寫的含義作如下說明:
- PageWriteLock(X),PageReadLock(X):持有X資源的Page寫鎖或讀鎖,
- PageWriteUnlock(X),PageReadUnlock(X):釋放持有的X資源的Page寫鎖或讀鎖,
- ExclusiveLock(X),ExclusiveUnlock(X):持有或釋放X資源的Exclusive鎖,
- BucketWriteLock(X),BucketReadLock(X):持有編號為X的Bucket的寫鎖或讀鎖,
- BucketWriteUnlock(X),BucketReadUnlock(X):釋放持有的編號為X的Bucket的寫鎖或讀鎖,
- LoadFromDisk(X):從磁盤加載X表征的物理頁,存放在Cache模塊中,若已經成功加載,則只將參考計數加1,
- HMB:代表HashMetaBlock,
- IP-X:代表邏輯編號為X的IndexPage,
- B-X: 代表邏輯編號為X的Bucket,
- PBP-X:代表B-X對應的PrimaryBucketPage,
- OBP-X:代表B-X對應的OverflowBucketPage,
hash table resize
由于合并操作和分裂操作,幾憾訓為相反操作,所以下面將主要以分裂為例,分析加入并發控制之后的分裂操作是如何處理的,
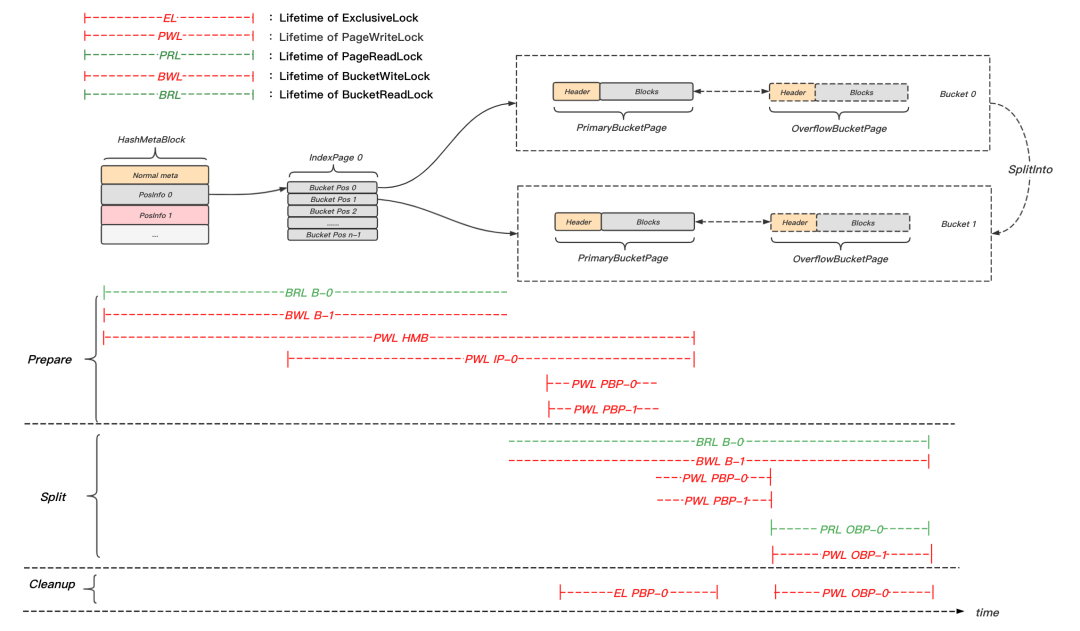
圖16 hash分裂并發控制示意圖
如圖16所示,Prepare階段的主要操作步驟如下:
- LoadFromDisk(HMB),PageReadLock(HMB);
- 根據meta資訊,定位目標Bucket及其所屬IndexPage(此例為B-0和IP-0);
- 嘗試按序獲取B-0的Bucket讀鎖和B-1的Bucket寫鎖,PageReadUnlock(HMB);
- 若B-0或B-1的Bucket鎖未成功鎖定,則釋放已持有的鎖,直接回傳;
- LoadFromDisk(IP-0),PageReadLock(IP-0),獲取PBP-0位置資訊,PageReadUnlock(IP-0);
- LoadFromDisk(PBP-0),LoadFromDisk(PBP-1);
- WriteLock(HMB),WriteLock(IP-0),PageWr iteLock(PBP-0),PageWriteLock(PBP-1);
- 更新PBP-0的狀態為BeingSplitted,更新PBP-1的狀態為BeingFilled;
- 將PBP-1的位置資訊記錄在IP-0中;
- 更新HMB元資訊欄位:next_split_index,current_Bucket_count;
- 寫入表示資料修改的WAL日志;
- WriteUnlock(IP-0),WriteUnlock(HMB),
同時持有所有待修改頁面Page鎖的目的是:確保多頁修改的原子性,極小部分場景下,WAL日志寫入可能引起協程切換,而后臺Page刷臟協程可能獲得執行權,如果此時不對所有頁加鎖,則可能導致部分頁的修改持久化,而索引通常無法記錄回滾日志,所以最終可能導致hash table結構的錯亂,
Split階段的主要操作步驟如下:
- 遍歷PBP-0中元素,按照high_mask進行rehash,將不再屬于PBP-0的元素拷貝至B-1鏈中;
- 若B-0還存在Overflow Page,則PageWriteUnlock(PBP-0);
- LoadFromDisk(OBP-0),PageReadLock(OBP-0),遍歷OBP-0中元素,按照high_mask進行rehash,將不再屬于PBP-0的元素拷貝至B-1鏈中;
- 若B-0還存在Overflow Page,則PageReadUnlock(OBP-0),從步驟3開始重復執行,直到遍歷完B-0整個鏈表;
- WriteLock(PBP-0),WriteLock(PBP-1);
- 更新PBP-0的狀態為BeingCleanup,更新PBP-1的狀態為Normal;
- WriteUnlock(PBP-0),WriteUnlock(PBP-1);
- BucketReadUnlock(0),BucketWriteUnlock(1),
在Split階段資料拷貝程序中,若B-1當前BucketPage寫滿,則需要增加Overflow Page用于后續寫入,而此操作涉及頁面分配,可能讓出執行權,所以為了避免影響B-1的并發讀取操作,會首先將當前BucketPage的寫鎖釋放,
Cleanup階段的主要操作步驟如下:
- LoadFromDisk(PBP-0);
- 嘗試獲取PBP-0的Exclusive鎖,若獲取失敗,直接退出;
- 遍歷PBP-0中元素,按照high_mask進行rehash,將不再屬于PBP-0的元素清理掉;
- 若B-0還存在Overflow Page,則PageWriteUnlock(PBP-0);
- LoadFromDisk(OBP-0),PageWriteLock(OBP-0),遍歷OBP-0中元素,按照high_mask進行rehash,將不再屬于OBP-0的元素清理掉;
- 若B-0還存在Overflow Page,則PageWriteUnlock(OBP-0),從步驟5開始重復執行,直到遍歷完B-0整個鏈表;
- WriteLock(PBP-0),更新PBP-0的狀態為Normal,WriteUnLock(PBP-0),
通過將分裂操作拆分為三個階段,主要是為了提高等待磁盤IO時的并發度,當Prepare階段完成時,新的hash table結構便對后續讀寫可見,不論是用戶讀寫還是hash table resize操作都可以基于新的結構繼續執行,即可能同時存在多個Bucket的并發分裂操作,這樣就能有效避免某次Bucket分裂耗時過長(等待磁盤IO),導致其余Bucket無法及時分裂,進而影響訪問延遲的問題,同時,將Split操作和Cleanup操作分開,也是為了能在等待新頁分配的時候,可以釋放Page鎖,避免影響并發讀寫,
read && write
如圖17所示,加入并發控制后,典型的寫入流程主要分為以下幾步:
- LoadFromDisk(HMB),PageReadLock(HMB),根據meta資訊,定位目標Bucket及其所屬IndexPage(此例為B-0和IP-0),PageReadUnlock(HMB);
- LoadFromDisk(IP-0),PageReadLock(IP-0),讀取PBP-0的位置資訊,PageReadUnlock(IP-0);
- 獲取B-0的Bucket讀鎖;
- 遍歷B-0的鏈表,直到結束或找到待查元素,然后寫入或更新相關元素,遍歷程序中,在訪問BucketPage前,先加寫鎖,訪問完后立即解鎖;
- 釋放B-0的Bucket讀鎖,
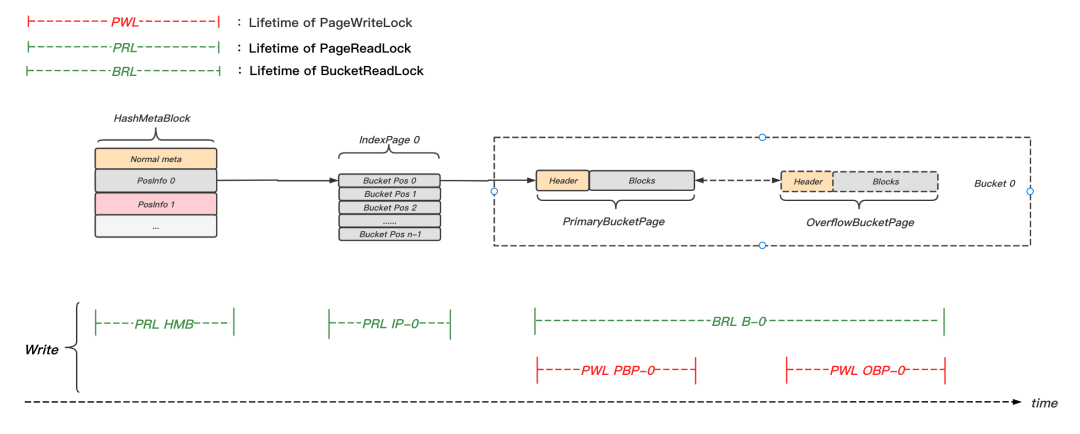
圖17 hash寫入并發控制示意圖
如圖18所示,典型的讀取流程主要分為以下幾步:
- LoadFromDisk(HMB),PageReadLock(HMB),根據meta資訊,定位目標Bucket及其所屬IndexPage(此例為B-1和IP-0),PageReadUnlock(HMB);
- LoadFromDisk(IP-0),PageReadLock(IP-0),讀取PBP-1的位置資訊,PageReadUnlock(IP-0);
- LoadFromDisk(PBP-1),PageReadLock(PBP-1);
- 若PBP-1當前狀態為BeingFilled,則PageReadUnlock(PBP-1),同時LoadFromDisk(PBP-0),持有PBP-0參考;
- 遍歷B-1的鏈表,直到結束或找到待查元素,遍歷程序中,在訪問BucketPage前,先加讀鎖,訪問完后立即解鎖;
- 若B-1鏈表無法找到對應元素,且已經持有PBP-0的參考,則以遍歷B-1鏈表相同的方式,遍歷B-0鏈表;
- B若持有PBP-0的參考,則釋放它,
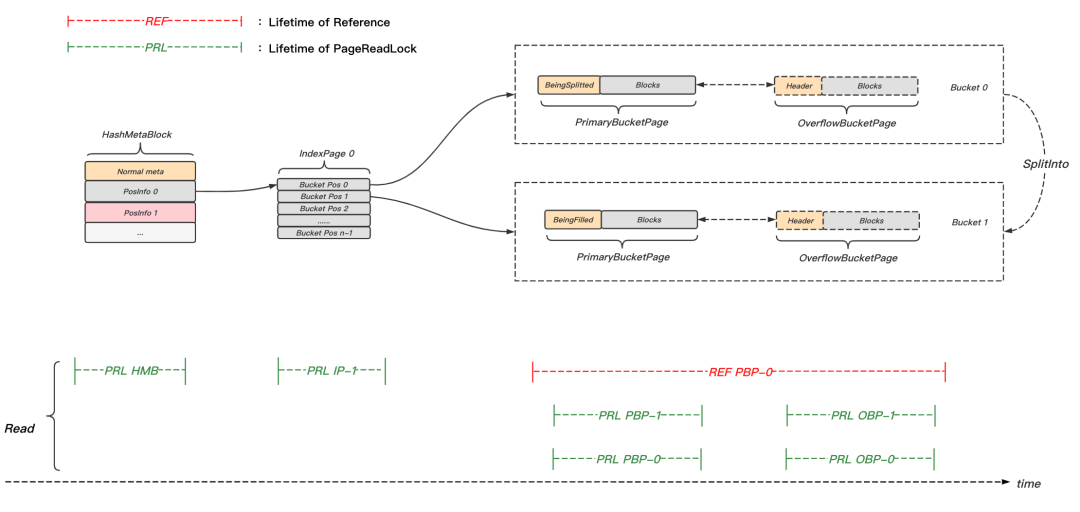
圖18 hash讀取并發控制示意圖
以上便是加入并發控制之后,hash讀寫的主要流程,限于篇幅上述流程簡化了部分故障恢復和沖突檢測邏輯,現在我們來回顧下,前文提到的并發安全保障是否得到了滿足,由于我們在讀取Page前,都獲取了該Page的讀或寫鎖,所以保證了讀寫的原子性,即R-1和W-1得到保障,讀取操作則通過事先持有待分裂Bucket的參考,避免了分裂程序中,無法讀取到已存在的元素,即R-2也得到保障,寫入操作通過事先獲取Bucket邏輯讀鎖,保證了不會因為分裂操作,導致丟失更新的問題,即滿足了W-2要求,最后通過保證hash結構變化的原子性,滿足了故障重啟后的自恢復性,即SR得到保障,
在保障了并發安全的前提下,hash索引的并發度究竟如何呢?
在回答這個問題之前,我們先來回顧下這里使用的鎖,由于我們探討的是執行緒內多協程的并發,所以使用的并不是系統鎖,而是簡單的計數器,也就是說產生鎖沖突之后,開銷主要在于用戶空間的協程背景關系切換,那么鎖沖突概率高嗎?由于我們采用了非搶占式調度,所以除非當前協程主動讓出執行權限,其他協程不會投入運行,也就不會產生沖突,
那什么時候讓出執行權呢?絕大多數情況下,是在等待IO的時候,也就是說,在持有鎖而讓出執行權的情況下,可能會產生鎖沖突,不管是讀寫操作還是分裂合并操作,對Page鎖的應用都是:先加載頁,再鎖定資源,故一般不會出現Page鎖沖突的情況,極少數情況下可能需要等待重做日志就緒,從而產生Page鎖沖突,對處于BeingFilled狀態Bucket的寫入操作,會導致Bucket鎖沖突,沖突概率隨著hash表的增大而減小,且沖突時間和相關Page鎖的沖突時間幾乎相等,Exclusive鎖的沖突概率和Bucket鎖類似,所以,工程實踐中,我們會預分配一定數量的桶,以分散并發操作的Page頁,進而減小鎖沖突的概率,最終達到減小協程切換消耗的目的,
總結
本文主要介紹了KeeWiDB存盤引擎的設計細節,首先,通過介紹存盤層的基本組織結構,知道了我們使用4K Page作為管理整個存盤檔案的基本單元,而用戶資料則是存盤于Page內的Block中,接著,通過對比分析各類索引的特點,簡述了我們選擇Linear Hashing作為用戶資料索引的主要原因,最后,深入分析了Linear Hashing在KeeWiDB中的工程實踐,包括具體的組織架構,增刪查改的大致流程,以及在協程架構下,如何做到并發安全的,
目前,KeeWiDB 正在公測階段,現已在內外部已經接下了不少業務,其中不乏有一些超大規模以及百萬 QPS 級的業務,線上服務均穩定運行中,
后臺回復“KeeWiDB”,試試看,有驚喜,
關于作者
章俊,騰訊云資料庫高級工程師,擁有多年的分布式存盤、資料庫從業經驗,現從事于騰訊云資料庫KeeWiDB的研發作業,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538578.html
標籤:其他