目錄
- 多表查詢的兩種方法
- 方式1:連表操作
- 方式2:子查詢
- SQL補充知識點
- 1.分組之前欄位拼接 concat concat_ws
- 2.SQL執行判斷條件 exists
- 3.表相關SQL補充
- 修改表名 alter table ... rename ...
- 添加欄位 alter table ... add ... after/first
- 修改欄位名 alter table ... change/modify
- 洗掉欄位名 alter table ... drop
- 給表添加注釋 commit
- 可視化軟體navicat
- 建立連接
- 轉儲和運行SQL檔案
- 添加外鍵的注意事項
- 多表查詢練習題
- pymysql模塊
- 基本使用 cursor=pymysql.cursors.DictCursor
- 獲取資料 fetchall
- 移動游標 scroll
- 增刪改二次確認 commit autocommit=True
- 補充方法 rowcount rollback
- 確保資料的一致性
- 引入動態字典生成SQL陳述句
- 更新資料時的主鍵配置 ON DUPLICATE KEY UPDATA
- while回圈 + fetchone
- 練習
- SQL練習題
- 基于pymysql用戶注冊登錄
多表查詢的兩種方法
方式1:連表操作
語法:
select * from (表1) inner\right\left\union join (表2) on (拼接條件)
inner join 內連接
select * from emp inner join dep on emp.dep_id=dep.id;
只連接兩張表中公有的資料部分
left join 左連接
select * from emp left join dep on emp.dep_id=dep.id;
以左表為基準 展示左表所有的資料 如果沒有對應項則用NULL填充
right join 右連接
select * from emp right join dep on emp.dep_id=dep.id;
以右表為基準 展示右表所有的資料 如果沒有對應項則用NULL填充
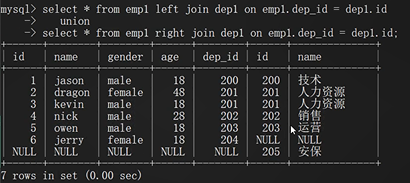
union 全連接
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
以左右表為基準 展示所有的資料 各自沒有的全部NULL填充
'''
學會了連表操作之后也就可以連接N多張表
思路:將拼接之后的表起別名當成一張表再去與其他表拼接 再起別名當一張表 再去與其他表拼接 其次往復即可
'''
準備拼接的表:
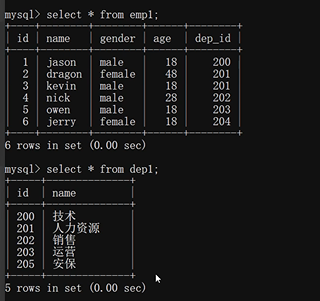
內連接:
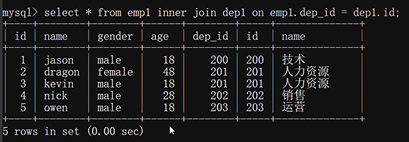
只有進行鏈接的兩個標準,都存在與連接標準相匹配的資料才會被保留下來,emp1.dep_id和dep1.id這兩列,有資料是重復的,保留這些重復資料(200,201,201,202,203)所在的那一整行,
丟棄每個表獨有的:如(emp的dep_id=204這一行,dep1的id=205這一行),
左連接:
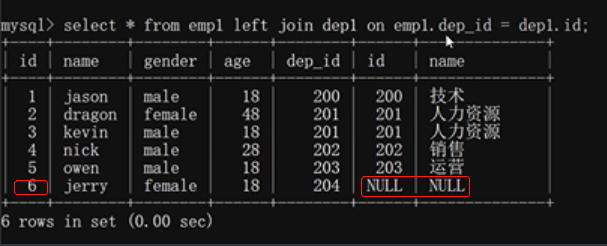
關鍵字left join左邊的emp1為左表,以左表為基準 展示左表所有的資料 右表有資料對應就對應 沒有資料對應就寫NULL
右連接:
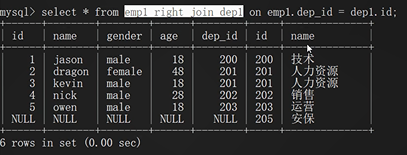
union 全連接:全部展示
方式2:子查詢
子查詢:將一條SQL陳述句用括號括起來當成另外一條SQL陳述句的查詢條件
題目:求姓名是jason的員工部門名稱
子查詢類似于我們日常生活中解決問題的方式>>>:分步操作
步驟1:先根據jason獲取部門編號
select dep_id from emp where name='jason';
步驟2:再根據部門編號獲取部門名稱
select name from dep where id=200;
總結
select name from dep where id=(select dep_id from emp where name='jason');
'''
很多時候多表查詢需要結合實際情況判斷用哪種 更多時候甚至是相互配合使用
'''
通過第一條查詢獲取到dep_id=200:
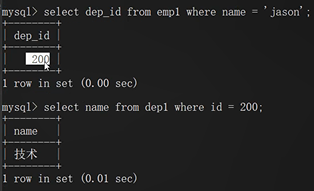
將第一條陳述句作為第二條陳述句的查詢條件:

SQL補充知識點
1.分組之前欄位拼接 concat concat_ws
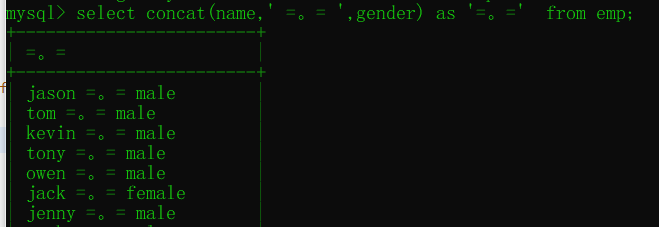
concat用于分組之前的欄位拼接操作
select concat(name,'$',gender) from emp;
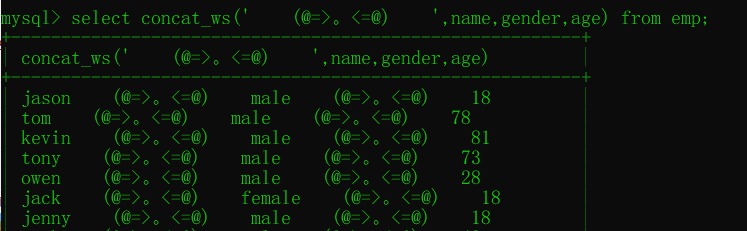
concat_ws拼接多個欄位并且中間的連接符一致 concat偷懶版本
select concat_ws('|',name,gender,age,dep_id) from emp;
concat使用:
concat_ws使用:
2.SQL執行判斷條件 exists
語法:sql1 exists sql2
sql2有結果的情況下才會執行sql1 否則不執行sql1 回傳空資料
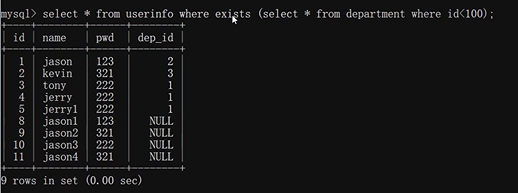
exists前面的陳述句是否執行 取決于后面的sql陳述句是否有結果
如果有結果就執行 前面這個sql陳述句 沒有結果就不執行前面這個sql陳述句
相當于exist括號里面裝的是一個判斷條件 根據這個來決定前面的sql是否執行
3.表相關SQL補充
原表:
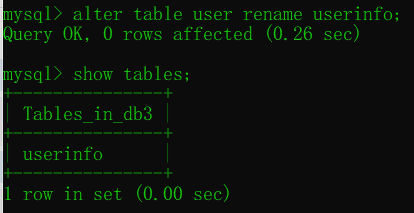
修改表名 alter table ... rename ...
alter table 表名 rename 新表名; # 修改表名
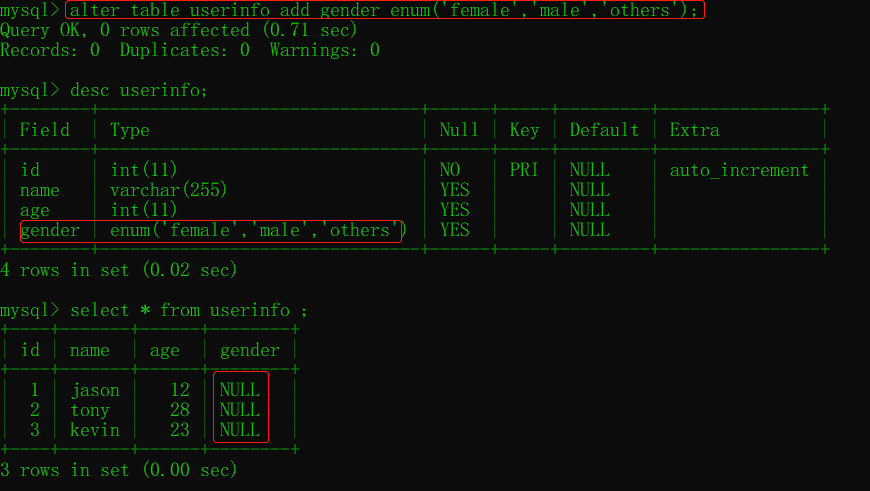
添加欄位 alter table ... add ... after/first
alter table 表名 add 欄位名 欄位型別(數字) 約束條件; # 添加欄位
alter table 表名 add 欄位名 欄位型別(數字) 約束條件 after 已有欄位;
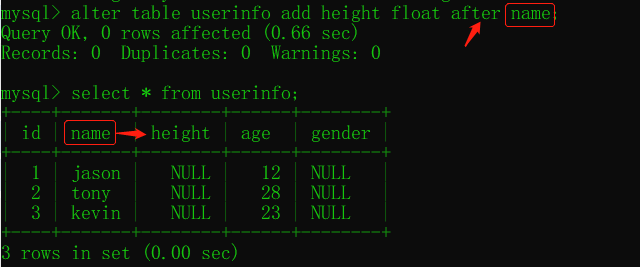
alter table 表名 add 欄位名 欄位型別(數字) 約束條件 first;
修改欄位名 alter table ... change/modify
alter table 表名 change 舊欄位名 新欄位名 欄位型別(數字) 約束條件;
alter table 表名 modify 欄位名 新欄位型別(數字) 約束條件;
洗掉欄位名 alter table ... drop
alter table 表名 drop 欄位名; # 洗掉欄位
給表添加注釋 commit
可以給表添加注釋:
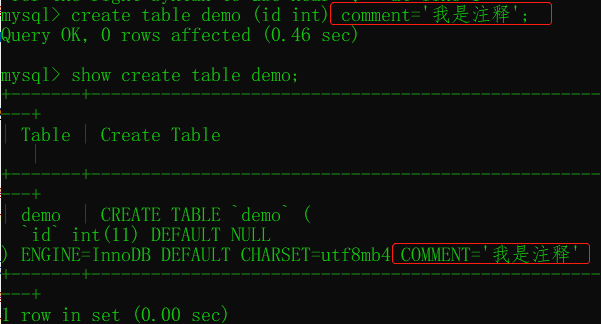
注釋有兩個查看位置:
- 使用代碼
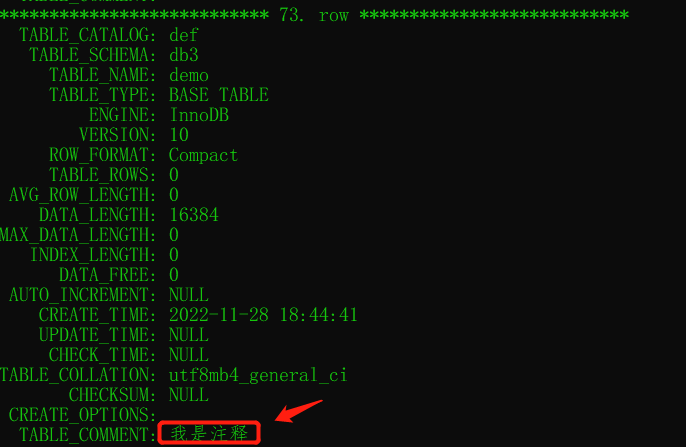
show create table 表名 - 去資料庫information_schema里面查看,
information_schema這是個臨時庫,存盤資料在記憶體,use一下這個庫,然后查詢:
select * from tables \G可以在眾多結果找到我們剛剛創建的表:
可視化軟體navicat
第三方開發的用來充當資料庫客戶端的簡單快捷的操作界面
無論第三方軟體有多么的花里胡哨 底層的本質還是SQL
能夠操作資料庫的第三方可視化軟體有很多 其中針對MySQL最出名的就是Navicat
1.瀏覽器搜索Navicat直接下載
版本很多、能夠充當的資料庫客戶端也很多
2.破解方式
先試用在破解、直接下載破解版(老版本)、修改試用日期
3.常用操作
有些功能可能需要自己修改SQL預覽
創建庫、表、記錄、外鍵
逆向資料庫到模型、模型創建(通過畫圖的形式創表)
新建查詢可以撰寫SQL陳述句并自帶提示功能
SQL陳述句注釋語法
--、#、\**\
運行、轉儲SQL檔案
美化SQL 相當于pycharm格式化代碼
建立連接
- 鏈接服務端
- 填寫資訊
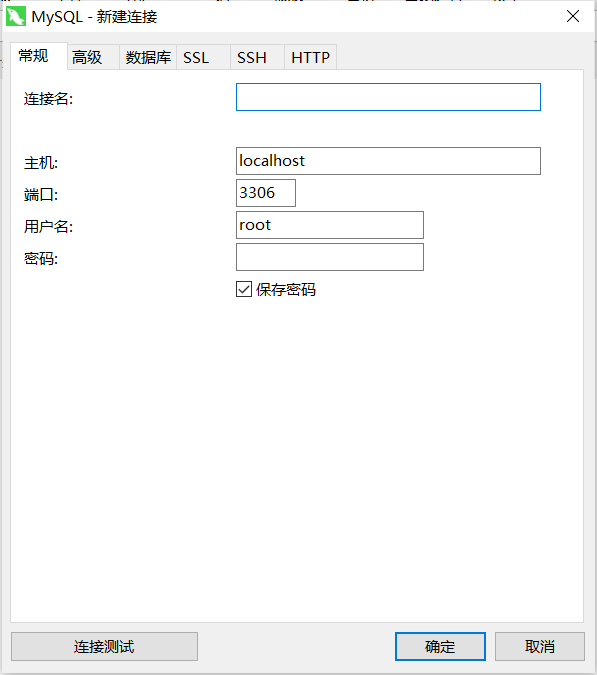
這里的主機指的是mysql服務端,mysql運行在本地就填localhost,在公網就填公網ip,
先點擊測驗連接,再點擊確定,
轉儲和運行SQL檔案
Navicat可以將自己的資料庫打包成SQL檔案,給別人使用,也可以運行別人打包的SQL檔案,獲取別人的資料庫全部資訊,
轉儲生成sql檔案:
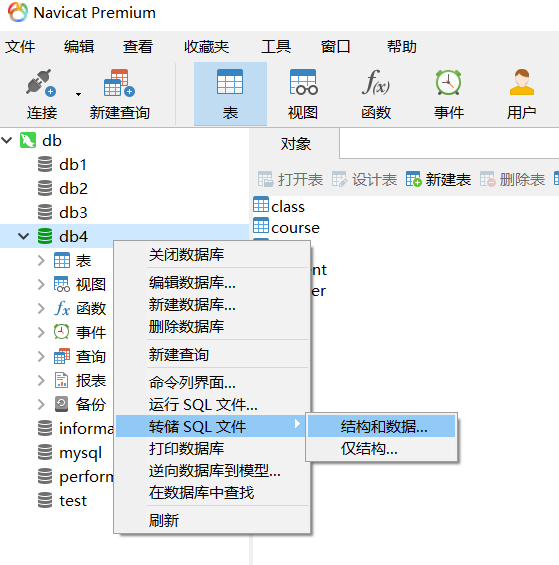
運行sql檔案:
- 首先需要先新建一個資料庫或者打開一個資料庫(重要)
- 右鍵資料庫,點擊運行SQL檔案:
選擇要運行的SQL檔案即可
添加外鍵的注意事項
-
先創建被外鍵關聯的表,給被關聯的表錄入資料,
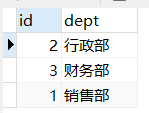
-
再創建有外鍵的表,先創建外鍵欄位,保存表:
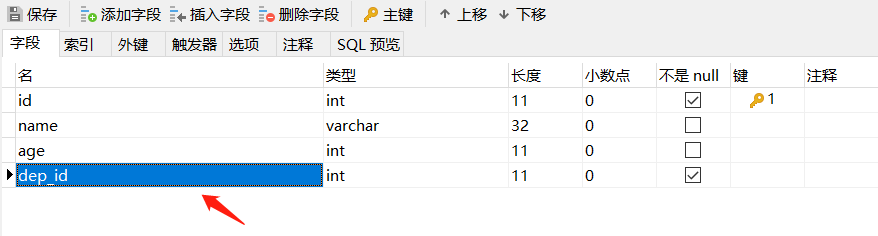
-
再將創建的外鍵進行系結
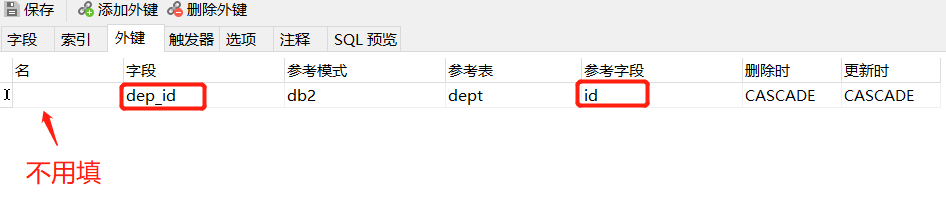
這里有個坑就是:
添加外鍵的時候 要注意 自己表外鍵的資料型別 和參考的目標表的欄位資料型別要相同
不然會報錯error: cannot add foreign key constraint
創建好了就保存可以按快捷鍵ctrl+s -
創建好的外鍵

補充: 創鍵一對一外鍵時 可以修改SQL陳述句
1.比如給userinfo添加對于user_msg的外鍵

2.還是先創建欄位
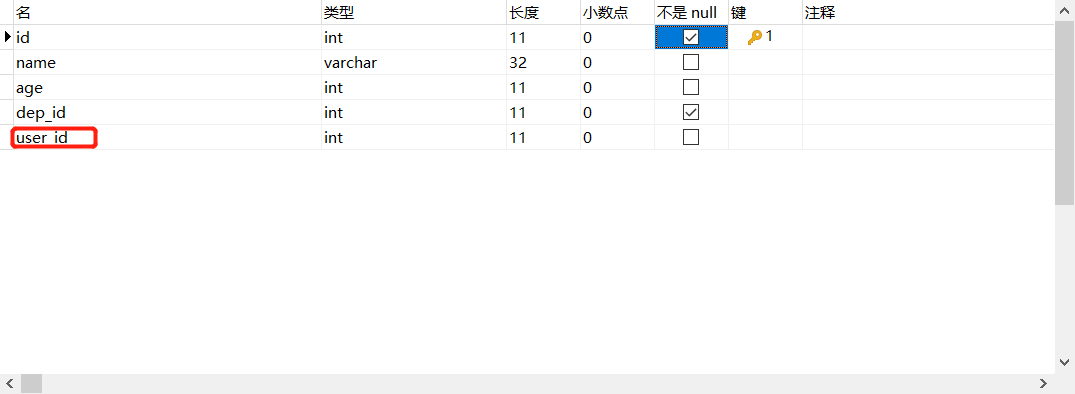
3.添加外鍵
無法修改SQL 如何添加一對一外鍵?
多表查詢練習題
"""
撰寫復雜的SQL不要想著一口氣寫完
一定要先明確思路 然后一步步寫一步步查一步步補
"""
1、查詢所有的課程的名稱以及對應的任課老師姓名
4、查詢平均成績大于八十分的同學的姓名和平均成績
7、查詢沒有報李平老師課的學生姓名
8、查詢沒有同時選修物理課程和體育課程的學生姓名
9、查詢掛科超過兩門(包括兩門)的學生姓名和班級
-- 1、查詢所有的課程的名稱以及對應的任課老師姓名
# 1.先確定需要用到幾張表 課程表 分數表
# 2.預覽表中的資料 做到心中有數
-- select * from course;
-- select * from teacher;
# 3.確定多表查詢的思路 連表 子查詢 混合操作
-- SELECT
-- teacher.tname,
-- course.cname
-- FROM
-- course
-- INNER JOIN teacher ON course.teacher_id = teacher.tid;
-- 4、查詢平均成績大于八十分的同學的姓名和平均成績
# 1.先確定需要用到幾張表 學生表 分數表
# 2.預覽表中的資料
-- select * from student;
-- select * from score;
# 3.根據已知條件80分 選擇切入點 分數表
# 求每個學生的平均成績 按照student_id分組 然后avg求num即可
-- select student_id,avg(num) as avg_num from score group by student_id having avg_num>80;
# 4.確定最終的結果需要幾張表 需要兩張表 采用連表更加合適
-- SELECT
-- student.sname,
-- t1.avg_num
-- FROM
-- student
-- INNER JOIN (
-- SELECT
-- student_id,
-- avg(num) AS avg_num
-- FROM
-- score
-- GROUP BY
-- student_id
-- HAVING
-- avg_num > 80
-- ) AS t1 ON student.sid = t1.student_id;
-- 7、查詢沒有報李平老師課的學生姓名
# 1.先確定需要用到幾張表 老師表 課程表 分數表 學生表
# 2.預覽每張表的資料
# 3.確定思路 思路1:正向篩選 思路2:篩選所有報了李平老師課程的學生id 然后取反即可
# 步驟1 先獲取李平老師教授的課程id
-- select tid from teacher where tname = '李平老師';
-- select cid from course where teacher_id = (select tid from teacher where tname = '李平老師');
# 步驟2 根據課程id篩選出所有報了李平老師的學生id
-- select distinct student_id from score where course_id in (select cid from course where teacher_id = (select tid from teacher where tname = '李平老師'))
# 步驟3 根據學生id去學生表中取反獲取學生姓名
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid NOT IN (
-- SELECT DISTINCT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- teacher_id = (
-- SELECT
-- tid
-- FROM
-- teacher
-- WHERE
-- tname = '李平老師'
-- )
-- )
-- )
-- 8、查詢沒有同時選修物理課程和體育課程的學生姓名(報了兩門或者一門不報的都不算)
# 1.先確定需要的表 學生表 分數表 課程表
# 2.預覽表資料
# 3.根據給出的條件確定起手的表
# 4.根據物理和體育篩選課程id
-- select cid from course where cname in ('物理','體育');
# 5.根據課程id篩選出所有跟物理 體育相關的學生id
-- select * from score where course_id in (select cid from course where cname in ('物理','體育'))
# 6.統計每個學生報了的課程數 篩選出等于1的
-- select student_id from score where course_id in (select cid from course where cname in ('物理','體育'))
-- group by student_id
-- having count(course_id) = 1;
# 7.子查詢獲取學生姓名即可
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid IN (
-- SELECT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- cname IN ('物理', '體育')
-- )
-- GROUP BY
-- student_id
-- HAVING
-- count(course_id) = 1
-- )
-- 9、查詢掛科超過兩門(包括兩門)的學生姓名和班級
# 1.先確定涉及到的表 分數表 學生表 班級表
# 2.預覽表資料
-- select * from class
# 3.根據條件確定以分數表作為起手條件
# 步驟1 先篩選掉大于60的資料
-- select * from score where num < 60;
# 步驟2 統計每個學生掛科的次數
-- select student_id,count(course_id) from score where num < 60 group by student_id;
# 步驟3 篩選次數大于等于2的資料
-- select student_id from score where num < 60 group by student_id having count(course_id) >= 2;
# 步驟4 連接班級表與學生表 然后基于學生id篩選即可
SELECT
student.sname,
class.caption
FROM
student
INNER JOIN class ON student.class_id = class.cid
WHERE
student.sid IN (
SELECT
student_id
FROM
score
WHERE
num < 60
GROUP BY
student_id
HAVING
count(course_id) >= 2
);
SQL檔案:
鏈接:https://pan.baidu.com/s/1LUu3U8VHc4oxT58zhJyfRg
提取碼:pur1
pymysql模塊
基本使用 cursor=pymysql.cursors.DictCursor
pymysql模塊
pip3 install pymysql
import pymysql
# 1.連接MySQL服務端
db = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
db='db4_03',
charset='utf8mb4'
)
# 2.產生游標物件
# cursor = db.cursor() # 括號內不填寫額外引數 資料是元組 指定性不強 [(),()]
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) # [{},{}]
# 3.撰寫SQL陳述句
# sql = 'select * from teacher;'
sql = 'select * from score;'
# 4.發送SQL陳述句
affect_rows = cursor.execute(sql) # execute也有回傳值 接收的是SQL陳述句影響的行數
print(affect_rows)
# 5.獲取SQL陳述句執行之后的結果
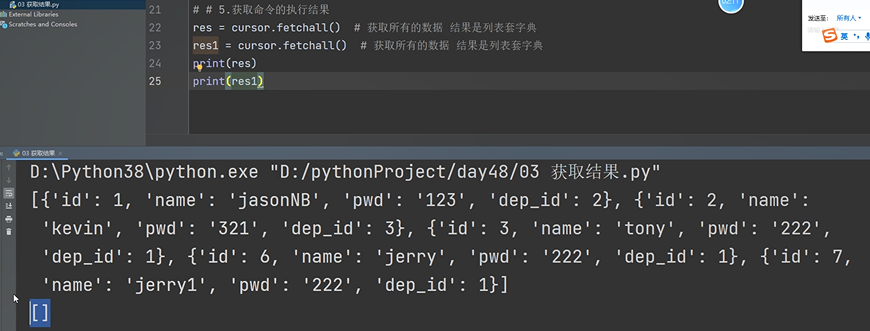
res = cursor.fetchall()
print(res)
獲取資料 fetchall
fetchall() 獲取所有的結果
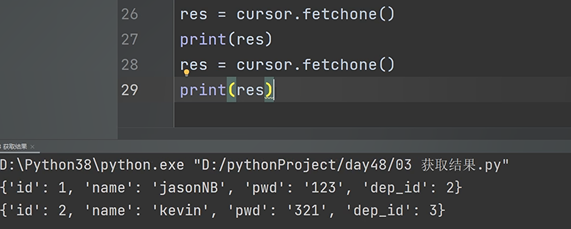
fetchone() 一次讀一個資料,每次都基于上次的位置往后面讀,
fetchmany() 獲取指定數量的結果集資料
ps:注意三者都有類似于檔案游標移動的特性
讀取結果集可以類比讀取檔案 游標讀取到末尾了 再繼續讀就沒有內容了 所以多次使用fetchall 第二次及以后都獲取的是空,
fetchall:
fetchone:
移動游標 scroll
cursor.scroll(1,'relative') # 基于當前位置往后移動1位
cursor.scroll(1,'absolute') # 基于資料的開頭往后移動一位
注意這個輸入的數字 是要≥0的,
≥0的
增刪改二次確認 commit autocommit=True
在pymysql.connect里添加autocommit=True
# 可以針對增 刪 改的操作 進行自動確認(無需寫代碼二次確認)
db.commit() # 針對 增 刪 改 需要二次確認(代碼確認)
補充方法 rowcount rollback
對于游標物件:
cursor.rowcount # 用于獲取查詢結果的條數
對于connect方法產生的db物件:
rollback # 資料回滾 用于增刪改出錯的情況 將資料庫狀態回復到commit之前 相當于什么事都沒發生
確保資料的一致性
插入一條資料,要么全部插入要么都不插入,不會出現插入一半的情況,這稱之為事務的原子性,
增刪改都是對資料庫進行更改的操作,而更改操作都必須是一個事務,所以這些操作的標注寫法是:
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
引入動態字典生成SQL陳述句
添加欄位的時候需要修改我們構建的SQL陳述句,這不是我們想要的,所以引入字典動態生成SQL:
import pymysql
db = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='123',
db='db1', # can be changed
charset='utf8mb4', # default
autocommit=True, # set to True
)
cursor = db.cursor(cursor=pymysql.cursors.DictCursor)
# dict
data = https://www.cnblogs.com/passion2021/archive/2022/11/28/{'id': '2200320',
'name': 'John Doe',
'age': '12',
}
table = 'students'
keys = ','.join(data.keys()) # create a str like 'id,name,age'
values = ','.join(['%s'] * len(data)) # make format symbols like '%s,%s,%s'
sql = 'INSERT INTO {table} ({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
print(sql) # INSERT INTO students (id,name,age) VALUES (%s,%s,%s)
try:
if cursor.execute(sql,tuples=(data.values())):
print('Success')
db.commit()
except Exception:
print('Error')
db.rollback()
db.close()
更新資料時的主鍵配置 ON DUPLICATE KEY UPDATA
在某些應用情境下,我們關心表中會不會出現重復資料,如果出現了,我們希望更新資料而不是重復保存一次,我們需要實作:如果資料存在,就更新資料;如果資料不存在,則插入資料,
可以給插入陳述句添加約束條件:ON DUPLICATE KEY UPDATA 意思是如果主鍵已經存在,就執行更新操作,
完整的SQL寫法:INSERT INTO stundent(id,name,age) VALUES(%s,%s,%s) ON DUPLICATE KEY UPDATA id = %s,name = %s, age = %s 注意這里%s是占位符,可以通過execute第二個引數給他傳進去,這樣寫即可實作主鍵不存在便插入資料,主鍵存在則更新資料,
while回圈 + fetchone
fetchall方法全部獲取資料,如果資料量很大,那么占用的開銷也會非常高
所以可以使用:
sql = 'SELECT * FROM students WHERE age >= 20'
try:
cursor.execute(sql)
print('count:',cursor.rowcount)
row = cursor.fetchone()
while row:
print('row:',row)
row = cursor.fetchone()
excpet:
print('error')
練習
SQL練習題
1、查詢所有的課程的名稱以及對應的任課老師姓名
SELECT
cname,
tname
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid;
2、查詢學生表中男女生各有多少人
SELECT gender,count(gender) FROM student GROUP BY gender
3、查詢物理成績等于100的學生的姓名
SELECT
sname,
num
FROM
( SELECT student_id, num FROM score INNER JOIN course ON course.cid = score.course_id WHERE cname = '物理' AND num = 100 ) AS std_id
INNER JOIN student ON std_id.student_id = student.sid
4、查詢平均成績大于八十分的同學的姓名和平均成績
-- SELECT * FROM score WHERE num>=80
-- 拼學生名字
-- SELECT * FROM student INNER JOIN score ON score.student_id=student.sid WHERE num>=80
-- 按學生分組
SELECT
sname,
avg( num )
FROM
student
INNER JOIN score ON score.student_id = student.sid
WHERE
num >= 80
GROUP BY
student_id
5、查詢所有學生的學號,姓名,選課數,總成績
SELECT
student_id,
sname,
count( course_id ),
avg( num )
FROM
student
INNER JOIN score ON student.sid = score.student_id
GROUP BY
sname
6、 查詢姓李老師的個數
SELECT * FROM teacher WHERE tname like '%李%'
7、 查詢沒有報李平老師課的學生姓名
8、 查詢物理課程比生物課程高的學生的學號
SELECT
wl.student_id
FROM
( SELECT * FROM score WHERE course_id = 1 ) AS sw
INNER JOIN ( SELECT * FROM score WHERE course_id = 2 ) AS wl ON sw.student_id = wl.student_id
WHERE
wl.num > sw.num
9、 查詢沒有同時選修物理課程和體育課程的學生姓名
SELECT
student_id
FROM
score
INNER JOIN course ON score.course_id = course.cid
WHERE
cname = '物理'
OR cname = '體育'
GROUP BY
student_id
HAVING
count( course_id ) = 1
10、查詢掛科超過兩門(包括兩門)的學生姓名和班級
、查詢選修了所有課程的學生姓名
12、查詢李平老師教的課程的所有成績記錄
SELECT num FROM score WHERE course_id in (2,4) #坑
13、查詢全部學生都選修了的課程號和課程名
SELECT GROUP_CONCAT(student_id) FROM score GROUP BY course_id
14、查詢每門課程被選修的次數
SELECT course_id,count(student_id) FROM score GROUP BY course_id
15、查詢之選修了一門課程的學生姓名和學號
SELECT student_id,count(course_id) as one FROM score GROUP BY student_id HAVING one = 1
16、查詢所有學生考出的成績并按從高到低排序(成績去重)
SELECT * FROM score ORDER BY num desc
17、查詢平均成績大于85的學生姓名和平均成績
18、查詢生物成績不及格的學生姓名和對應生物分數
19、查詢在所有選修了李平老師課程的學生中,這些課程(李平老師的課程,不是所有課程)平均成績最高的學生姓名
20、查詢每門課程成績最好的前兩名學生姓名
21、查詢不同課程但成績相同的學號,課程號,成績
22、查詢沒學過“葉平”老師課程的學生姓名以及選修的課程名稱;
23、查詢所有選修了學號為1的同學選修過的一門或者多門課程的同學學號和姓名;
24、任課最多的老師中學生單科成績最高的學生姓名
基于pymysql用戶注冊登錄
# user rigister and login application use pymysql instead
import pymysql
db = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='123',
db='db1', # can be changed
charset='utf8mb4', # default
autocommit=True, # set to True
)
# 1.create cursor object
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) # add cursor configuration
# 2. get user data
user_name = input('Enter user name>>>').strip()
pass_word = input('Enter password>>>').strip()
# 3.write SQL statement
sql = "select * from userinfo where name='%s' and pwd='%s'" # action to '%s' don't forget --> ''
# solved problem: pymysql.err.OperationalError: (1054, "Unknown column 'jason' in 'where clause'")
print(sql)
# 4.execute SQL statemen
cursor.execute(sql,(user_name, pass_word)) # execute function can solved SQL injection
# 5.get result
result = cursor.fetchall()
# 6.rigister result
if result:
print('welcome!')
print(result)
else:
print('username or password is incorrect')
# 7.sql injection problem
# real sql = select * from userinfo where name='jason' -- kdwokodwdkoa' and pwd='123'
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538680.html
標籤:其他