目錄
- 視圖 create view ... as
- 觸發器
- 簡介
- 創建觸發器的語法 create trigger
- 觸發器命名有一定的規律
- 臨時修改SQL陳述句的結束符 delimiter
- 觸發器的實際運用
- 觸發器補充方法 show triggers\drop trigger
- 事務
- 事務的四大特性 ACID
- 事務實際運用 start transaction
- 事務相關關鍵字 savepoint
- 事務的隔離級別(重要)
- 1.read uncommitted(未提交讀)
- 2.read committed(提交讀)
- 3.repeatable read(可重復讀)
- 4.serializable(可串行讀)
- 多版本并發控制 MVCC
- 存盤程序 procedure
- 有參函式和無參函式
- 存盤程序相關關鍵字 show procedure status
- 在mysql和python中使用
- 函式
- 常用函式 soundex
- 流程控制
- 分支結構 IF THEN
- 回圈結構 WHILE DO
- 索引
- 索引的概念
- MySQL中的索引 index key
- 索引加快查詢的本質
- 聚焦索引 輔助索引 覆寫索引 非覆寫索引
- 索引的資料結構
- 二叉樹
- B樹
- B+\B*樹
- B+樹等值查詢
- B+樹范圍查詢
- 索引失效
- 慢查詢優化
- explain命令使用方法
- 查詢資料的方式
- 全表掃描
- 索引掃描
- 資料庫設計三范式
視圖 create view ... as
ps:SQL檔案在上一篇博客末尾
視圖就是通過查詢得到一張虛擬表,然后保存下來,下次直接使用
create view teacher_course as
select * from teacher inner join course on teacher.tid = course.teacher_id;
1.視圖的表只能用來查詢不能做其他增刪改操作 視圖的資料來源于原表
2.視圖盡量少用 會跟真正的表產生混淆 從而干擾操作者 終端里視圖和原表放在一起,Navicat會把視圖單獨存放在views,
將課程表與教師表拼接產生視圖:
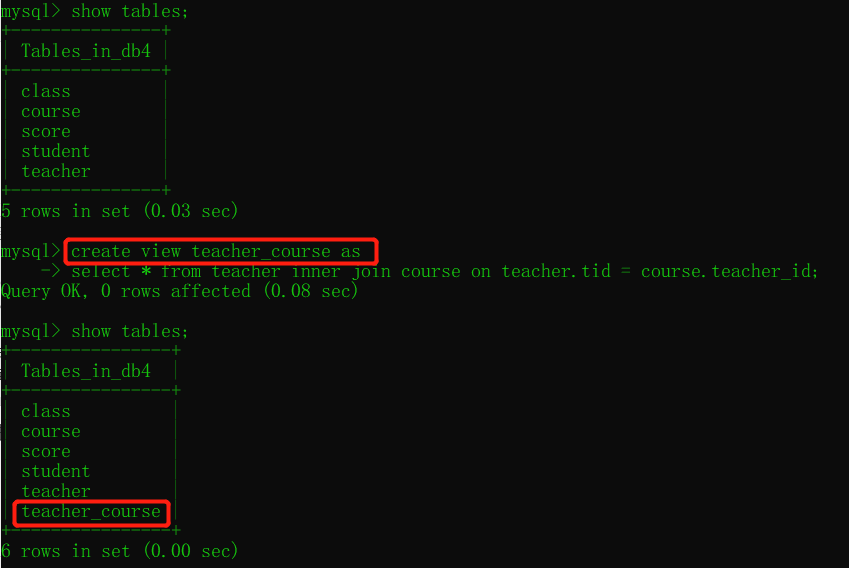
視圖表無法洗掉:

觸發器
簡介
達到某個條件之后自動觸發執行
在MySQL中更加詳細的說明是觸發器:針對表繼續增、刪、改操作能夠自動觸發
主要有六種情況:增前、增后、刪前、刪后、改前、改后
創建觸發器的語法 create trigger
create trigger 觸發器的名字 before/after insert/update/delete on 表名 for each row
begin
sql陳述句
end
觸發器命名有一定的規律
觸發器的命名不是硬性規范,想自定義名字也可以,
tri_before_insert_t1
tri_after_delete_t2
tri_after_update_t2
臨時修改SQL陳述句的結束符 delimiter
因為有些操作中需要使用分號 使用關鍵字更換SQL陳述句的結束符
delimiter $$ /* 臨時將結束符更改為$$ */
delimiter ; /* 用完記得改回來 */
觸發器的實際運用
/* 創建cmd表 */
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, #提交時間
success enum ('yes', 'no') #0代表執行失敗
);
/* 創建錯誤日志表 */
CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
);
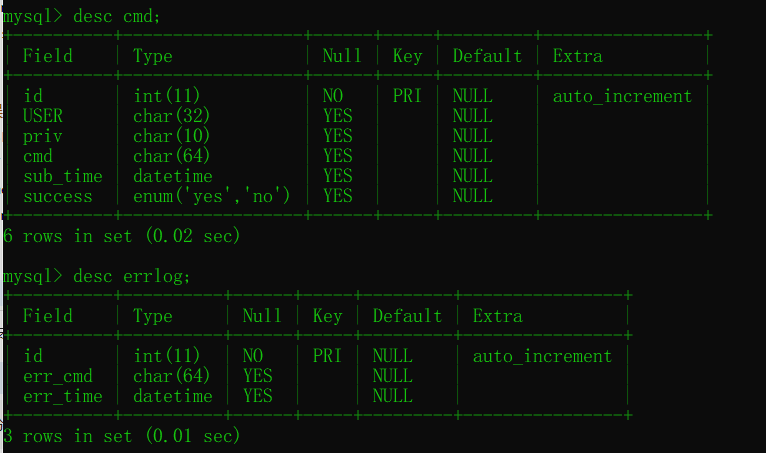
/* 創建觸發器
1.tri_after_insert_cmd 表示cmd表增加資料后觸發 名字可以修改 這樣寫比較規范
2.新增的資料的success欄位如果為no,則會向errlog表插入一條資料,這條資料包含cmd表新增資料的資訊,
3.NEW指代的當前cmd表的每一條資料物件,相當于每次往cmd表插入的資料,
*/
delimiter $$ # 將mysql默認的結束符由;換成$$
create trigger tri_after_insert_cmd after insert on cmd for each row
begin # 表示SQL陳述句開始
if NEW.success = 'no' then # 新記錄都會被MySQL封裝成NEW物件
insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time);
end if; # 表示if陳述句結束,加上就行了,
end $$ # SQL陳述句結束 再加上結束符$$
delimiter ; # 結束之后記得再改回來,不然后面結束符就都是$$了
無注釋版:
delimiter $$
create trigger helloworld after insert on cmd for each row
begin
if NEW.success = 'no' then
insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time);
end if;
end $$
delimiter ;
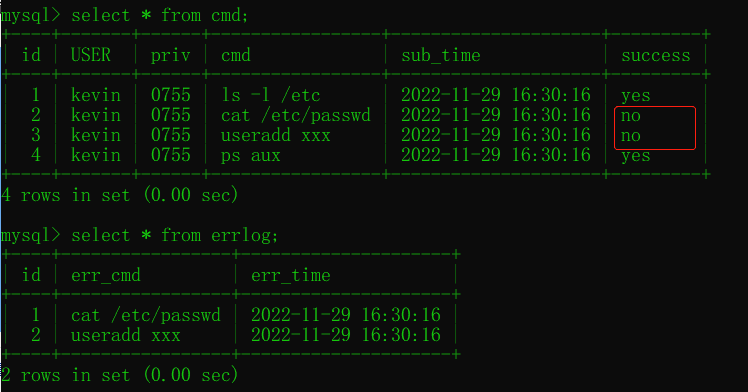
#往表cmd中插入記錄,觸發觸發器,根據IF的條件決定是否插入錯誤日志
#NOW()函式可以獲取當前的時間
INSERT INTO cmd (
USER,
priv,
cmd,
sub_time,
success
)
VALUES
('kevin','0755','ls -l /etc',NOW(),'yes'),
('kevin','0755','cat /etc/passwd',NOW(),'no'),
('kevin','0755','useradd xxx',NOW(),'no'),
('kevin','0755','ps aux',NOW(),'yes');
# 查詢errlog表記錄
select * from errlog;
給cmd表插入資料之后,查看errlog表:
觸發器補充方法 show triggers\drop trigger
- 查看所有的觸發器:
show triggers;
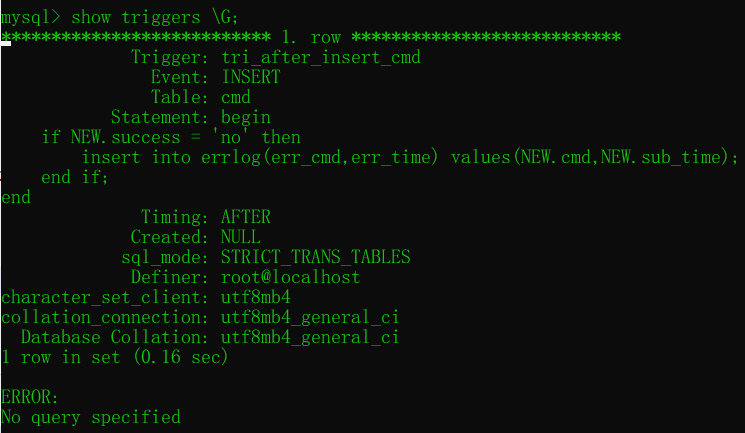
trigger --> 觸發器的名字
event:INSERT --> 在發生插入的時候觸發
table --> 發動觸發器的表
statement --> sql陳述句
timming --> 觸發的時機(這里是在插入之后) - 洗掉觸發器:
drop trigger tri_after_insert_cmd;
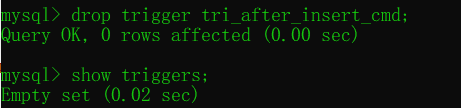
- 新增多個觸發器時報錯:

這個版本的MySQL還不支持“同一個表中具有相同操作時間和事件的多個觸發器”,
事務
事務的四大特性 ACID
事務的四大特性(ACID)
A:原子性
事務中的各項操作是不可分割的整體 要么同時成功要么同時失敗
比如銀行轉賬 你的賬戶增加錢 別人賬戶扣錢 要么同時成功要么同時失敗
C:一致性
使資料庫從一個一致性狀態變到另一個一致性狀態
I:隔離性
多個事務之間彼此不干擾
他給你轉錢,你給他轉錢,互不干擾(操作資料時互不干擾)
D:持久性
也稱永久性,指一個事務一旦提交,它對資料庫中資料的改變就應該是永久性的
轉賬成功之后,賬戶的錢就永久性的減少了,不可能回退到轉賬之前的狀態,
事務實際運用 start transaction
/* 創建用戶表 */
create table user(
id int primary key auto_increment,
name char(32),
balance int
);
/* 添加基礎資料 */
insert into user(name,balance)
values
('jason',1000),
('kevin',1000),
('tank',1000);
/* 修改資料之前先開啟事務操作 */
start transaction;
/* 修改操作 */
update user set balance=900 where name='jason'; #買支付100元
update user set balance=1010 where name='kevin'; #中介拿走10元
update user set balance=1090 where name='tank'; #賣家拿到90元
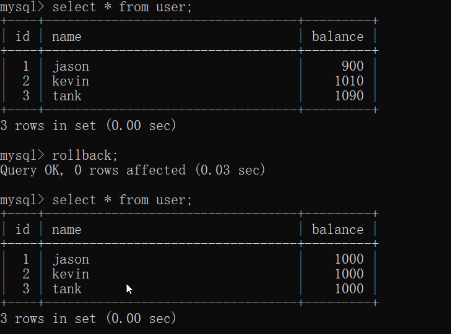
/* 回滾到上一個狀態 */
rollback;
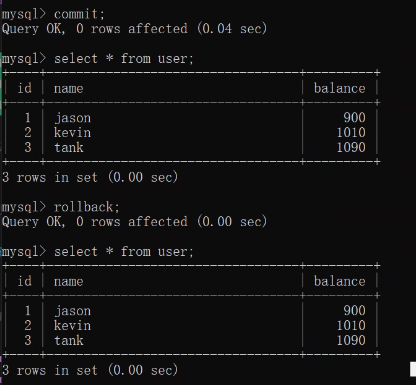
/* 開啟事務之后,只要沒有執行commit操作,資料其實都沒有真正重繪到硬碟*/
commit;
/*
回滾怎么實作?
沒確認時,改的是記憶體中的資料,不影響硬碟中的真實資料,
當進行確認,才會將記憶體的資料 保存到硬碟 永久修改
執行rollback commit意味著事務結束,
*/
rollback:
commit確認之后無法rollback:
事務相關關鍵字 savepoint
"""
事務相關關鍵字
start transaction;
rollback
commit
savepoint 保留點
部分事務 和 完整事務
"""
為了支持回退部分事務處理,必須能在事務處理塊中合適的位置放置占位符,
這樣如果需要回退可以回退到某個占位符(保留點)
# ps:但這也打破了事務的原子性,所以使用的少
創建占位符:savepoint sp01;
回退到占位符地址: rollback to sp01;
事務的隔離級別(重要)
事務需要對資料進行操作,所以事務與事務之間需要隔離操作,防止產生錯誤,
在SQL標準中定義了四種隔離級別,每一種級別都規定了一個事務中所做的修改
InnoDB支持所有隔離級別
set transaction isolation level 級別
1.read uncommitted(未提交讀)
事務中的修改即使沒有提交,對其他事務也都是可見的,事務可以讀取未提交的資料,這一現象也稱之為"臟讀"
2.read committed(提交讀)
大多數資料庫系統默認的隔離級別
一個事務從開始直到提交之前所作的任何修改對其他事務都是不可見的,這種級別也叫做"不可重復讀"
3.repeatable read(可重復讀)
- 可重復讀是MySQL默認隔離級別,
- 能夠解決"臟讀"問題,但是無法解決"幻讀"
所謂幻讀指的是當某個事務在讀取某個范圍內的記錄時另外一個事務又在該范圍內插入了新的記錄,當之前的事務再次讀取該范圍的記錄會產生幻行,InnoDB和XtraDB通過多版本并發控制(MVCC)及間隙鎖策略解決該問題 - 幻讀的例子
某事務讀取資料庫發現有3條資料 結果另一個事物刪了一條資料 此時先前的事務讀取的資訊就錯了,故成為幻讀, - 如何解決幻讀?
在資料上做特殊標記,資料被修改,這個唯一標識會變,事務修改時檢查標識,一旦發現標識和之前讀取的時候不同,就重新讀資料庫,
4.serializable(可串行讀)
強制事務串行執行,很少使用該級別
一次性只有一個事務操作資料,慢的離譜,
多版本并發控制 MVCC
MVCC只能在read committed(提交讀)、repeatable read(可重復讀)兩種隔離級別下作業,其他兩個不兼容(read uncommitted:總是讀取最新 serializable:所有的行都加鎖)
InnoDB的MVCC通過在每行記錄后面保存兩個隱藏的列來實作MVCC
一個列保存了行的創建時間
一個列保存了行的過期時間(或洗掉時間) # 本質是系統版本號
每開始一個新的事務版本號都會自動遞增,事務開始時刻的系統版本號會作為事務的版本號用來和查詢到的每行記錄版本號進行比較
例如
剛插入第一條資料的時候,我們默認事務id為1,實際是這樣存盤的
username create_version delete_version
jason 1
可以看到,我們在content列插入了kobe這條資料,在create_version這列存盤了1,1是這次插入操作的事務id,
然后我們將jason修改為jason01,實際存盤是這樣的
username create_version delete_version
jason 1 2
jason01 2
可以看到,update的時候,會先將之前的資料delete_version標記為當前新的事務id,也就是2,然后將新資料寫入,將新資料的create_version標記為新的事務id
當我們洗掉資料的時候,實際存盤是這樣的
username create_version delete_version
jason01 2 3
"""
由此當我們查詢一條記錄的時候,只有滿足以下兩個條件的記錄才會被顯示出來:
1.當前事務id要大于或者等于當前行的create_version值,這表示在事務開始前這行資料已經存在了,
2.當前事務id要小于delete_version值,這表示在事務開始之后這行記錄才被洗掉,
"""
存盤程序 procedure
有參函式和無參函式
/* 可以看成是python中的自定義函式 */
# 無參函式
delimiter $$
create procedure p1()
begin
select * from cmd;
end $$
delimiter ;
# 呼叫
call p1()
# 有參函式
delimiter $$
create procedure p2(
in m int, # in表示這個引數必須只能是傳入不能被回傳出去
in n int,
out res int # out表示這個引數可以被回傳出去,還有一個inout表示即可以傳入也可以被回傳出去
)
begin
select * from cmd where id > m and id < n;
set res=0; # 用來標志存盤程序是否執行
end $$
delimiter ;
# 針對res需要先提前定義
set @res=10; 定義
select @res; 查看
call p1(1,5,@res) 呼叫
select @res 查看
/*
1. 注意 in out inout
2. 為什么要使用set定義? 需要一個變數接受回傳值
3. 為什么要@? @指向函式里的回傳值res
*/
存盤程序相關關鍵字 show procedure status
查看存盤程序具體資訊
show create procedure pro1;
查看所有存盤程序
show procedure status;
洗掉存盤程序
drop procedure pro1;
在mysql和python中使用
# 大前提:存盤程序在哪個庫下面創建的只能在對應的庫下面才能使用!!!
# 1、直接在mysql中呼叫
set @res=10 # res的值是用來判斷存盤程序是否被執行成功的依據,所以需要先定義一個變數@res存盤10
call p1(2,4,10); # 報錯
call p1(2,4,@res);
# 查看結果
select @res; # 執行成功,@res變數值發生了變化
# 2、在python程式中呼叫
pymysql鏈接mysql
產生的游表cursor.callproc('p1',(2,4,10)) # 內部原理:@_p1_0=2,@_p1_1=4,@_p1_2=10;
cursor.excute('select @_p1_2;')
函式
可以看成是python中的內置函式
mysql的內置函式只能在SQL陳述句中使用
常用函式 soundex
/* 可以通過help 函式名 查看幫助信息!" */
# 1.移除指定字符
Trim、LTrim、RTrim
# 2.大小寫轉換
Lower、Upper
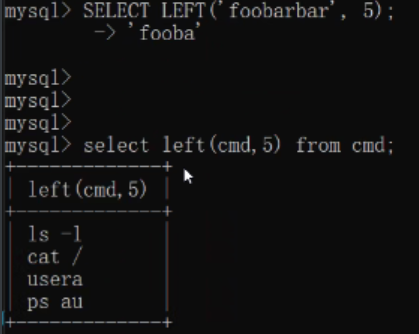
# 3.獲取左右起始指定個數字符
Left、Right
# 4.回傳讀音相似值(對英文效果)
Soundex
/*
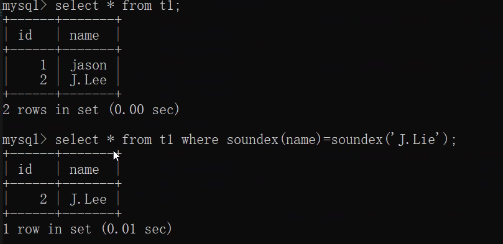
eg:客戶表中有一個顧客登記的用戶名為J.Lee
但如果這是輸入錯誤真名其實叫J.Lie,可以使用soundex匹配發音類似的
where Soundex(name)=Soundex('J.Lie')
*/
# 5.日期格式:date_format
'''在MySQL中表示時間格式盡量采用2022-11-11形式'''
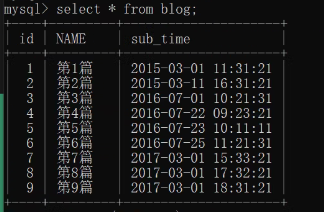
CREATE TABLE blog (
id INT PRIMARY KEY auto_increment,
NAME CHAR (32),
sub_time datetime
);
INSERT INTO blog (NAME, sub_time)
VALUES
('第1篇','2015-03-01 11:31:21'),
('第2篇','2015-03-11 16:31:21'),
('第3篇','2016-07-01 10:21:31'),
('第4篇','2016-07-22 09:23:21'),
('第5篇','2016-07-23 10:11:11'),
('第6篇','2016-07-25 11:21:31'),
('第7篇','2017-03-01 15:33:21'),
('第8篇','2017-03-01 17:32:21'),
('第9篇','2017-03-01 18:31:21');
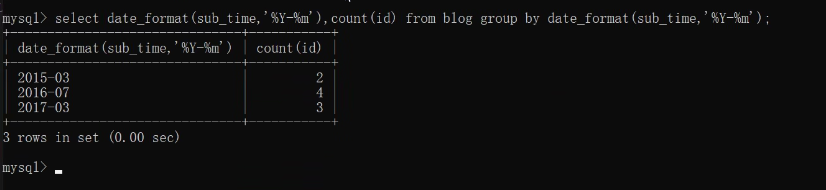
select date_format(sub_time,'%Y-%m'),count(id) from blog group by date_format(sub_time,'%Y-%m');
1.where Date(sub_time) = '2015-03-01'
2.where Year(sub_time)=2016 AND Month(sub_time)=07;
# 更多日期處理相關函式
adddate 增加一個日期
addtime 增加一個時間
datediff計算兩個日期差值
Left函式只要資料的指定個數的字符:
回傳讀音相似的值soundex(只對英文有效):
date_format實作真實業務邏輯(將博客按照年月分組):
- blog表展示
- 按照年月分組
流程控制
分支結構 IF THEN
declare i int default 0;
IF i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF;
回圈結構 WHILE DO
DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT num ;
SET num = num + 1 ;
END WHILE ;
索引
索引的概念
1)索引就好比一本書的目錄,它能讓你更快的找到自己想要的內容
2)讓獲取的資料更有目的性,從而提高資料庫檢索資料的性能
MySQL中的索引 index key
MySQL索引主要有兩種結構:B+Tree索引和Hash索引,
索引在MySQL中也叫做“鍵”,是存盤引擎用于快速找到記錄的一種資料結構,mysql有以下幾種鍵:
* primary key
* unique key
* index key
'''
1.上述的三個key都可以加快資料查詢
2.primary key和unique key除了可以加快查詢本身還自帶限制條件而index key很單一就是用來加快資料查詢
3.外鍵不屬于索引鍵的范圍 是用來建立關系的 與加快查詢無關
'''
索引加快查詢的本質
id int primary key auto_increment,
name varchar(32) unique,
province varchar(32)
age int
phone bigint
select name from userinfo where phone=18818888888; # 一頁頁的翻
select name from userinfo where id=99999; # 按照目錄確定頁數找
/*
1. 索引可以加快資料查詢 但是會降低增刪的速度 (發生增刪改操作時,會重新建立索引)
2. 通常情況下我們頻繁使用某些欄位查詢資料,為了提升查詢的速度可以將該欄位建立索引
*/
聚焦索引 輔助索引 覆寫索引 非覆寫索引
聚集索引(primary key)
主鍵、主鍵索引
輔助索引(unique,index)
除主鍵意外的都是輔助索引
輔助索引在查詢資料的時候還是要借助于聚集索引
/*查詢順序: 輔助索引樹 --> 主鍵索引 --> 主鍵索引樹 -->真實資料 */
覆寫索引
select name from user where name='jason';
非覆寫索引
select age from user where name='jason';
索引的資料結構
索引底層其實是樹結構>>>:樹是計算機底層的資料結構
'''注意:樹結構每一個節點存放的資料大小是固定的'''
樹有很多中型別
二叉樹、b樹、b+樹、B*樹......
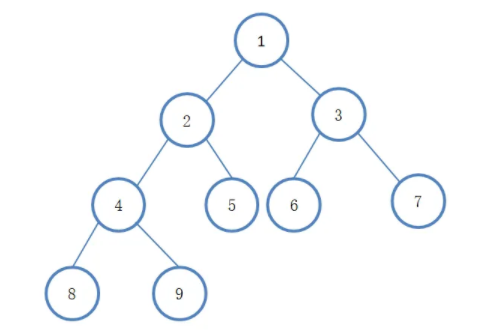
二叉樹
# 二叉樹
二叉樹里面還可以細分成很多領域 我們簡單的了解即可
二叉意味著每個節點最大只能分兩個子節點
二叉樹的特點:每個節點最多有2個分叉,左子樹和右子樹資料順序左小右大,
根節點:樹的最頂端的節點,(根節點只有一個)
枝節點:除根節點之外,并且本身下面還連接有節點的節點,
葉結點:自己下面不再連接有節點的節點(即末端),稱為葉子節點(又稱為終端結點),
B樹
所有的節點都可以存放完整的資料
MySQL的資料是存盤在磁盤檔案中的,查詢資料時需要先把磁盤中的資料加載到記憶體中,磁盤IO操作非常耗時,所以我們優化的重點就是盡量減少磁盤IO操作,所以,我們應當盡量減少從磁盤中讀取資料的次數,另外,從磁盤中讀取資料時,都是按照磁盤塊來讀取的,并不是一條一條的讀,如果我們能把盡量多的資料放進磁盤塊中,那一次磁盤讀取操作就會讀取更多資料,那我們查找資料的時間也會大幅度降低,
如果我們用樹這種資料結構作為索引的資料結構,那我們每查找一次資料就需要從磁盤中讀取一個節點,也就是我們說的一個磁盤塊,我們都知道平衡二叉樹可是每個節點只存盤一個鍵值和資料的,那說明什么?說明每個磁盤塊僅僅存盤一個鍵值和資料!那如果我們要存盤海量的資料呢?
可以想象到二叉樹的節點將會非常多,高度也會極其高,我們查找資料時也會進行很多次磁盤IO,我們查找資料的效率將會極低!
為了解決平衡二叉樹的這個弊端,B樹應運而生, B樹是一種多叉平衡查找樹,主要的特點是:
1、葉子節點都在同一層,葉子節點沒有指標連接
2、B樹的節點中存盤著多個元素,每個內節點有多個分叉
3、節點中的元素包含鍵值和資料,節點中的鍵值從大到小排列
4、所有的節點都可以存放完整的資料
下面模擬下查找key為27的data的程序:
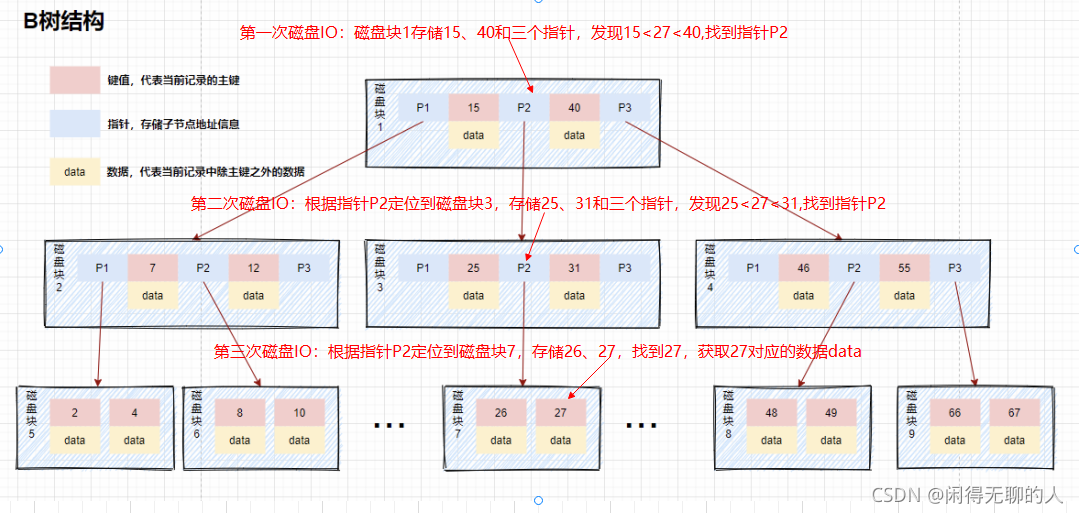
存在的一些問題:
B樹中每個節點中包含key值以及data值,而每一個節點的存盤空間是有限的(MySQL默認16K),如果data中存放的資料較大時,將會導致每個節點能存盤的key的數量很小,所以當資料量很多,且每行資料量很大的時候,同樣會導致樹的高度變得很高,增大查詢時的磁盤IO次數,進而影響查詢效率,
不支持范圍查詢的快速查找,而在實際的應用中,資料庫范圍查詢的頻率非常高,以下的一種情況是我查找10和35之間的資料,查找到15之后,需要回到根節點重新遍歷查找,需要從根節點進行多次遍歷,查詢效率有待提高,
B+\B*樹
只有葉子節點才會存放真正的資料 其他節點只存放索引資料
B+葉子節點增加了指向其他葉子節點的指標
B*葉子節點和枝節點都有指向其他節點的指標
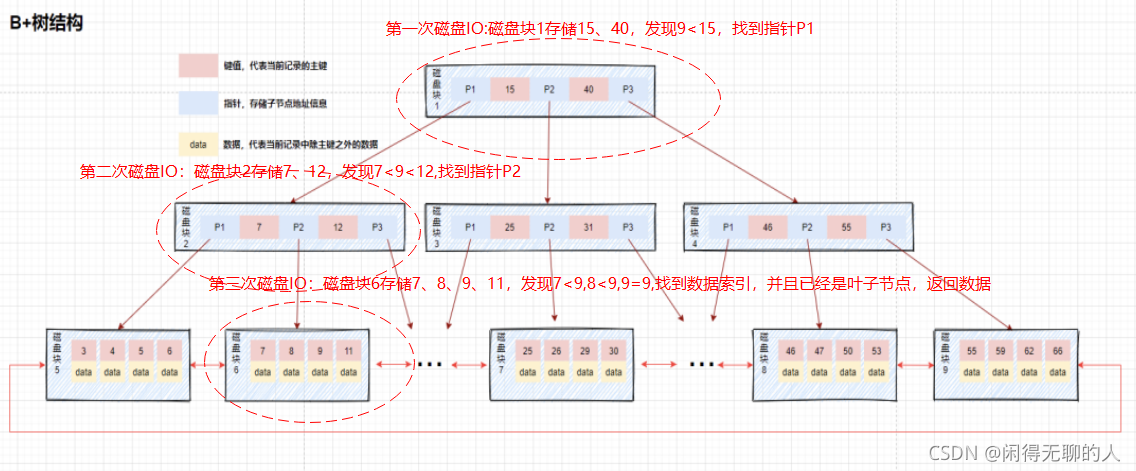
對比B樹和B+樹,我們發現二者主要存在以下幾點不同的地方:
- 資料都存放在葉子節點中
- 非葉子節點只存盤鍵值資訊,不再存盤資料
- 所有葉子節點之間都有一個指標,指向下一個葉子節點,而且葉子節點之間使用雙向指標連接,最底層的葉子節點形成了一個雙向有序鏈表
B+樹等值查詢
下面模擬下查找key為9的data的程序:
B+樹范圍查詢
下面模擬下查找key的范圍為9到26這個范圍的data的程序:
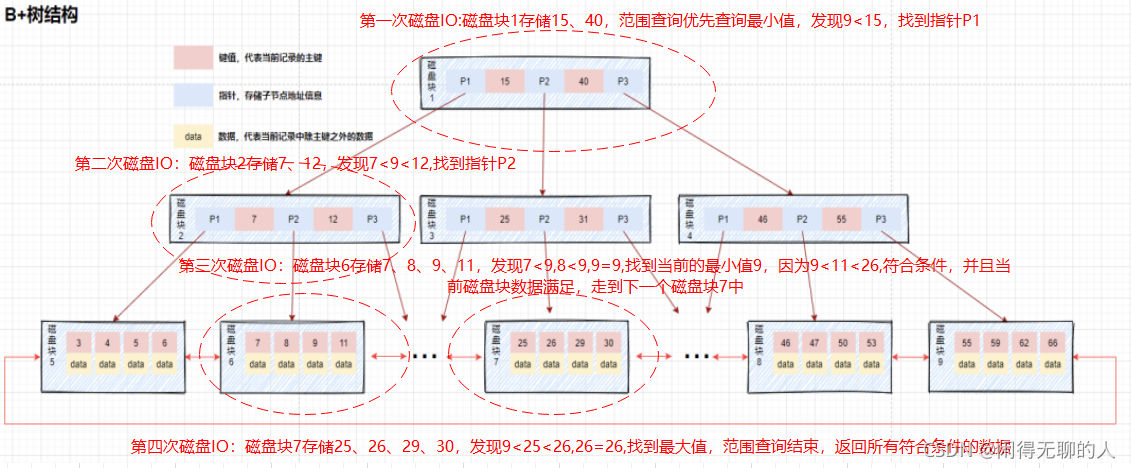
從上面的結果,我們可以知道B+樹作為索引結構帶來的好處:
- 磁盤IO次數更少
- 資料遍歷更為方便
- 查詢性能更穩定
由于B+樹優秀的結構特性,在MySQL中,存盤引擎MyISAM和InnoDB的索引就采用了B+樹的資料結構,
索引失效
有時候就算采用索引欄位查詢資料 也可能不會走索引!!!
1.前導模糊查詢不能利用索引(like '%XX'或者like '%XX%')
2.如果mysql估計使用全表掃描要比使用索引快,則不使用索引
3.OR前后存在非索引的列,索引失效
如果條件中有or,即使其中有條件帶索引也不會使用(這也是為什么盡量少用or的原因)
要想使用or,又想讓索引生效,只能將or條件中的每個列都加上索引
4.普通索引的不等于不會走索引;如果是主鍵,則還是會走索引;如果是主鍵或索引是整數型別,則還是會走索引
5.計算導致索引失效
更多:
https://zhuanlan.zhihu.com/p/461253119
https://m.php.cn/article/487049.html
慢查詢優化
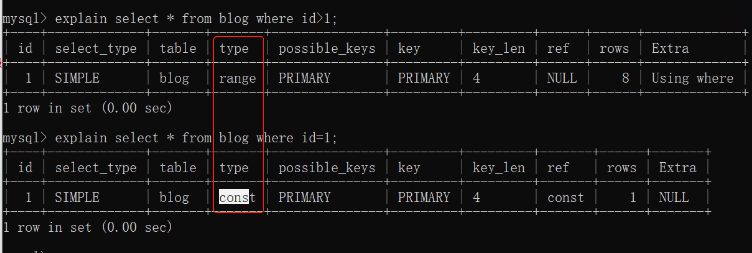
explain命令使用方法
mysql> explain select name,countrycode from city where id=1;
查詢資料的方式
全表掃描
1)在explain陳述句結果中type為ALL
2)什么時候出現全表掃描?
2.1 業務確實要獲取所有資料
2.2 不走索引導致的全表掃描
2.2.1 沒索引
2.2.2 索引創建有問題
2.2.3 陳述句有問題
生產中,mysql在使用全表掃描時的性能是極其差的,所以MySQL盡量避免出現全表掃描
索引掃描
2.1 常見的索引掃描型別:
1)index
2)range
3)ref
4)eq_ref
5)const
6)system
7)null
從上到下,性能從最差到最好,我們認為至少要達到range級別
index:Full Index Scan,index與ALL區別為index型別只遍歷索引樹,
range:索引范圍掃描,對索引的掃描開始于某一點,回傳匹配值域的行,顯而易見的索引范圍掃描是帶有between或者where子句里帶有<,>查詢,
mysql> alter table city add index idx_city(population);
mysql> explain select * from city where population>30000000;
ref:使用非唯一索引掃描或者唯一索引的前綴掃描,回傳匹配某個單獨值的記錄行,
mysql> alter table city drop key idx_code;
mysql> explain select * from city where countrycode='chn';
mysql> explain select * from city where countrycode in ('CHN','USA');
mysql> explain select * from city where countrycode='CHN' union all select * from city where countrycode='USA';
eq_ref:類似ref,區別就在使用的索引是唯一索引,對于每個索引鍵值,表中只有一條記錄匹配,簡單來說,就是多表連接中使用primary key或者 unique key 作為關聯條件A join B on A.sid=B.sid
const、system:當MySQL對查詢某部分進行優化,并轉換為一個常量時,使用這些型別訪問,
如將主鍵置于where串列中,MySQL就能將該查詢轉換為一個常量
mysql> explain select * from city where id=1000;
NULL:MySQL在優化程序中分解陳述句,執行時甚至不用訪問表或索引,例如從一個索引列里選取最小值可以通過單獨索引查找完成,
mysql> explain select * from city where id=1000000000000000000000000000;
參考:
https://www.cnblogs.com/Dominic-Ji/articles/15429493.html
https://www.cnblogs.com/Dominic-Ji/articles/15426531.html
資料庫設計三范式
第一范式:任何一張表都應該有自己的主鍵,并且每一個欄位的原子性都是不可再分的,
第二范式:在第一范式的基礎上,要求所有的非主鍵欄位完全依賴主鍵,不能產生部分依賴,
第三范式:在第二范式的基礎上,所有非主鍵只能依賴于主鍵,不能產生傳遞依賴,
'''
提醒:完美符合三范式的資料庫也比較少,為了滿足客戶的實際需求,
常常會用資料冗余去換執行速度,就是魚和熊掌的關系,
'''轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538778.html
標籤:其他
上一篇:第十章-資料庫恢復技術