目錄
- 1.5.4 HDFS 客戶端操作
- 1.5.4.1 Shell 命令列操作HDFS
- 1.5.4.2 JAVA客戶端
- 1.5.4.2.1 客戶端環境準備
- 1.5.4.2.2 HDFS的API操作
- 1.5.4.2.2.1 上傳檔案
- 1.5.4.2.2.2 下載檔案
- 1.5.4.2.2.3 洗掉檔案/檔案夾
- 1.5.4.2.2.4 查看檔案名稱、權限、長度、塊資訊
- 1.5.4.2.2.5 檔案夾判斷
- 1.5.4.2.2.6 I/O流操作HDFS
1.5.4 HDFS 客戶端操作
1.5.4.1 Shell 命令列操作HDFS
- 基本語法
? bin/hadoop fs 具體命令 OR bin/hdfs dfs 具體命令
- 命令大全
[root@linux121 hadoop-2.9.2]# bin/hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec>
<path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
-
HDFS命令演示
-
啟動Hadoop集群(方便后續的測驗)
[root@linux121 hadoop-2.9.2]$ sbin/start-dfs.sh [root@linux122 hadoop-2.9.2]$ sbin/start-yarn.sh -
-help:輸出這個命令引數
[root@linux121 hadoop-2.9.2]$ hadoop fs -help rm -
-ls: 顯示目錄資訊
[root@linux121 hadoop-2.9.2]$ hadoop fs -ls / -
-mkdir:在HDFS上創建目錄
[root@linux121 hadoop-2.9.2]$ hadoop fs -mkdir -p /lagou/bigdata -
-moveFromLocal:從本地剪切粘貼到HDFS
[root@linux121 hadoop-2.9.2]$ touch hadoop.txt [root@linux121 hadoop-2.9.2]$ hadoop fs -moveFromLocal ./hadoop.txt /lagou/bigdata -
-appendToFile:追加一個檔案到已經存在的檔案末尾
[root@linux121 hadoop-2.9.2]$ touch hdfs.txt [root@linux121 hadoop-2.9.2]$ vi hdfs.txt輸入
namenode datanode block replication [root@linux121 hadoop-2.9.2]$ hadoop fs -appendToFile ./hdfs.txt /lagou/bigdata/hadoop.txt -
-cat:顯示檔案內容
[root@linux121 hadoop-2.9.2]$ hadoop fs -cat /lagou/bigdata/hadoop.txt -
-chgrp 、-chmod、-chown:Linux檔案系統中的用法一樣,修改檔案所屬權限
[root@linux121 hadoop-2.9.2]$ hadoop fs -chmod 666 /lagou/bigdata/hadoop.txt [root@linux121 hadoop-2.9.2]$ hadoop fs -chown root:root /lagou/bigdata/hadoop.txt -
-copyFromLocal:從本地檔案系統中拷貝檔案到HDFS路徑去
[root@linux121 hadoop-2.9.2]$ hadoop fs -copyFromLocal README.txt / -
-copyToLocal:從HDFS拷貝到本地
[root@linux121 hadoop-2.9.2]$ hadoop fs -copyToLocal /lagou/bigdata/hadoop.txt ./ -
-cp :從HDFS的一個路徑拷貝到HDFS的另一個路徑
[root@linux121 hadoop-2.9.2]$ hadoop fs -cp /lagou/bigdata/hadoop.txt /hdfs.txt -
-mv:在HDFS目錄中移動檔案
[root@linux121 hadoop-2.9.2]$ hadoop fs -mv /hdfs.txt /lagou/bigdata/ -
-get:等同于copyToLocal,就是從HDFS下載檔案到本地
[root@linux121 hadoop-2.9.2]$ hadoop fs -get /lagou/bigdata/hadoop.txt ./ -
-put:等同于copyFromLocal
[root@linux121 hadoop-2.9.2]$ hadoop fs -mkdir -p /user/root/test/ #本地檔案系統創建yarn.txt [root@linux121 hadoop-2.9.2]$ vim yarn.txt resourcemanager nodemanager [root@linux121 hadoop-2.9.2]$ hadoop fs -put ./yarn.txt /user/root/test/ -
-tail:顯示一個檔案的末尾
[root@linux121 hadoop-2.9.2]$ hadoop fs -tail /user/root/test/yarn.txt -
-rm:洗掉檔案或檔案夾
[root@linux121 hadoop-2.9.2]$ hadoop fs -rm /user/root/test/yarn.txt -
-rmdir:洗掉空目錄
[root@linux121 hadoop-2.9.2]$ hadoop fs -mkdir /test [root@linux121 hadoop-2.9.2]$ hadoop fs -rmdir /test -
-du統計檔案夾的大小資訊
[root@linux121 hadoop-2.9.2]$ hadoop fs -du -s -h /user/root/test [root@linux121 hadoop-2.9.2]$ hadoop fs -du -h /user/root/test -
-setrep:設定HDFS中檔案的副本數量
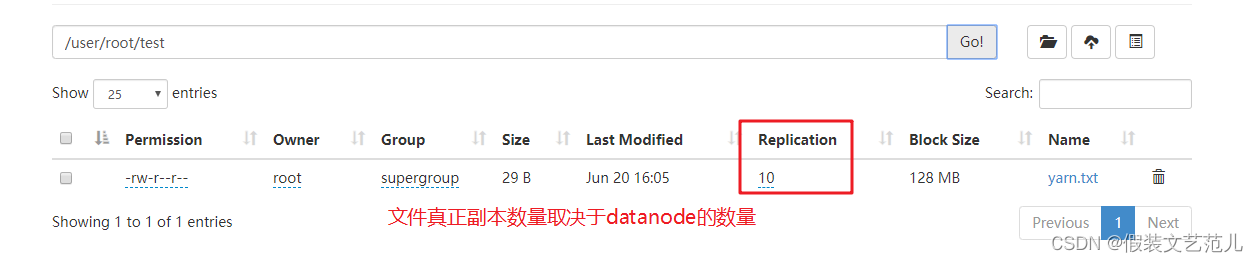
[root@linux121 hadoop-2.9.2]$ hadoop fs -setrep 10 /lagou/bigdata/hadoop.txt
圖3-3 HDFS副本數量
這里設定的副本數只是記錄在NameNode的元資料中,是否真的會有這么多副本,還得看DataNode的數量,因為目前只有3臺設備,最多也就3個副本,只有節點數的增加到10臺時,副本數才能達到10, -
1.5.4.2 JAVA客戶端
1.5.4.2.1 客戶端環境準備
- 將Hadoop-2.9.2安裝包解壓到非中文路徑(例如:E:\hadoop-2.9.2),
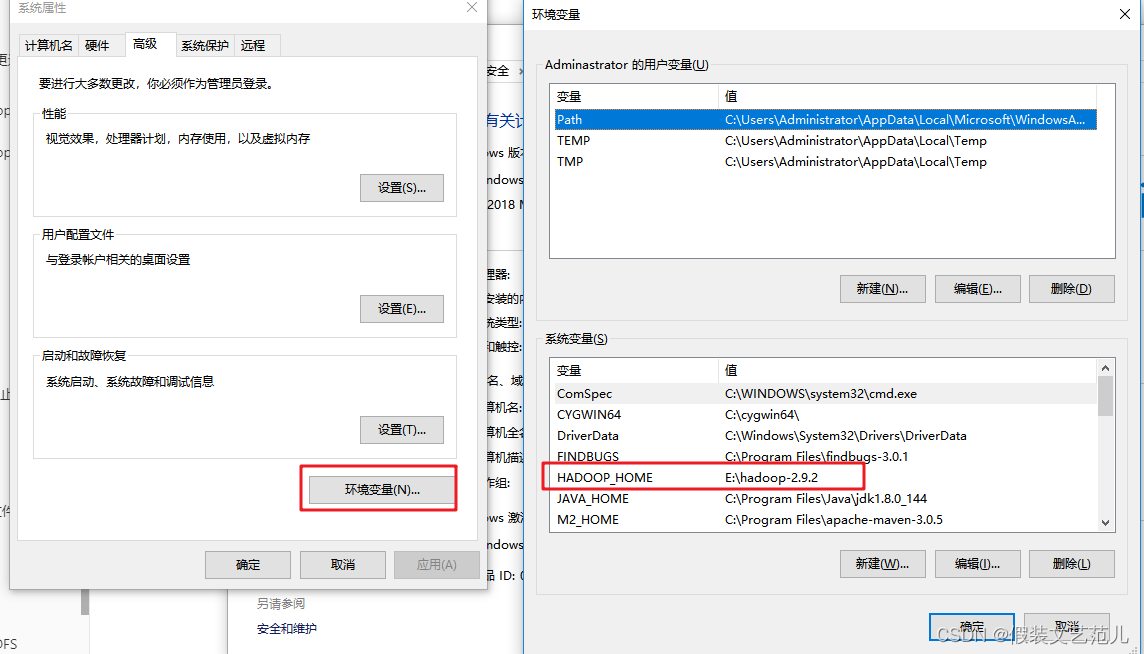
- 配置HADOOP_HOME環境變數
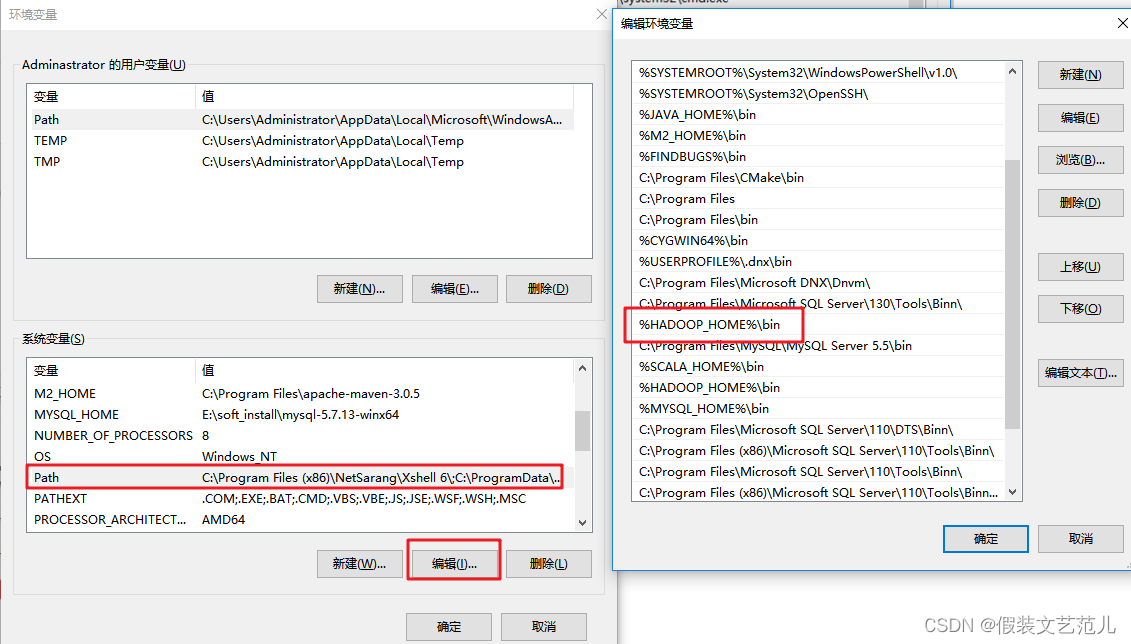
- 配置Path環境變數,
-
創建一個Maven工程ClientDemo
-
匯入相應的依賴坐標+日志組態檔
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.9.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.9.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.9.2</version> </dependency> </dependencies>為了便于控制程式運行列印的日志數量,需要在專案的src/main/resources目錄下,新建一個檔案,命名為“log4j.properties”,檔案內容:
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n -
創建包名:com.lagou.hdfs
-
創建HdfsClient類
public class HdfsClient{ @Test public void testMkdirs() throws IOException, InterruptedException, URISyntaxException { // 1 獲取檔案系統 Configuration configuration = new Configuration(); // 配置在集群上運行 // configuration.set("fs.defaultFS", "hdfs://linux121:9000"); // FileSystem fs = FileSystem.get(configuration); FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root"); // 2 創建目錄 fs.mkdirs(new Path("/test")); // 3 關閉資源 fs.close(); } }
遇到問題:
如果不指定操作HDFS集群的用戶資訊,默認是獲取當前作業系統的用戶資訊,出現權限被拒絕的問 題,報錯如下:

1.5.4.2.2 HDFS的API操作
1.5.4.2.2.1 上傳檔案
-
撰寫源代碼
@Test public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException { // 1 獲取檔案系統 Configuration configuration = new Configuration(); configuration.set("dfs.replication", "2"); FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root"); // 2 上傳檔案 fs.copyFromLocalFile(new Path("e:/lagou.txt"), new Path("/lagou.txt")); // 3 關閉資源 fs.close(); System.out.println("end"); } -
將hdfs-site.xml拷貝到專案的根目錄下
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="https://www.cnblogs.com/gitBook/p/configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> -
引數優先級
引數優先級排序:(1)代碼中設定的值 >(2)用戶自定義組態檔 >(3)服務器的默認配置
1.5.4.2.2.2 下載檔案
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"),
configuration, "root");
// 2 執行下載操作
// boolean delSrc 指是否將原檔案洗掉
// Path src 指要下載的檔案路徑
// Path dst 指將檔案下載到的路徑
// boolean useRawLocalFileSystem 是否開啟檔案校驗
fs.copyToLocalFile(false, new Path("/lagou.txt"), new
Path("e:/lagou_copy.txt"), true);
// 3 關閉資源
fs.close();
}
1.5.4.2.2.3 洗掉檔案/檔案夾
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root");
// 2 執行洗掉
fs.delete(new Path("/api_test/"), true);
// 3 關閉資源
fs.close();
}
1.5.4.2.2.4 查看檔案名稱、權限、長度、塊資訊
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException{
// 1獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root");
// 2 獲取檔案詳情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
// 輸出詳情
// 檔案名稱
System.out.println(status.getPath().getName());
// 長度
System.out.println(status.getLen());
// 權限
System.out.println(status.getPermission());
// 分組
System.out.println(status.getGroup());
// 獲取存盤的塊資訊
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 獲取塊存盤的主機節點
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("-----------華麗的分割線----------");
}
// 3 關閉資源
fs.close();
}
1.5.4.2.2.5 檔案夾判斷
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案配置資訊
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root");
// 2 判斷是檔案還是檔案夾
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// 如果是檔案
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName()); }else {
System.out.println("d:"+fileStatus.getPath().getName()); }
}
// 3 關閉資源
fs.close();
1.5.4.2.2.6 I/O流操作HDFS
以上我們使用的API操作都是HDFS系統框架封裝好的,我們自己也可以采用IO流的方式實作檔案的上傳 和下載,
-
檔案上傳
-
需求:把本地e盤上的lagou.txt檔案上傳到HDFS根目錄
-
撰寫代碼
@Test public void putFileToHDFS() throws IOException, InterruptedException, URISyntaxException { // 1 獲取檔案系統 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root"); // 2 創建輸入流 FileInputStream fis = new FileInputStream(new File("e:/lagou.txt")); // 3 獲取輸出流 FSDataOutputStream fos = fs.create(new Path("/lagou_io.txt")); // 4 流對拷 IOUtils.copyBytes(fis, fos, configuration); // 5 關閉資源 IOUtils.closeStream(fos); IOUtils.closeStream(fis); fs.close(); }
-
-
檔案下載
-
需求:從HDFS上下載lagou.txt檔案到本地e盤上
-
撰寫代碼
// 檔案下載 @Test public void getFileFromHDFS() throws IOException, InterruptedException, URISyntaxException{ // 1 獲取檔案系統 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root"); // 2 獲取輸入流 FSDataInputStream fis = fs.open(new Path("/lagou_io.txt")); // 3 獲取輸出流 FileOutputStream fos = new FileOutputStream(new File("e:/lagou_io_copy.txt")); // 4 流的對拷 IOUtils.copyBytes(fis, fos, configuration); // 5 關閉資源 IOUtils.closeStream(fos); IOUtils.closeStream(fis); fs.close(); }
-
-
seek 定位讀取
-
需求:將HDFS上的lagou.txt的內容在控制臺輸出兩次
-
撰寫代碼
@Test public void readFileSeek2() throws IOException, InterruptedException, URISyntaxException{ // 1 獲取檔案系統 Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root"); // 2 打開輸入流,讀取資料輸出到控制臺 FSDataInputStream in = null; try{ in= fs.open(new Path("/lagou.txt")); IOUtils.copyBytes(in, System.out, 4096, false); in.seek(0); //從頭再次讀取 IOUtils.copyBytes(in, System.out, 4096, false); }finally { IOUtils.closeStream(in); } }
注意
- windows解壓安裝Hadoop后,在呼叫相關API操作HDFS集群時可能會報錯,這是由于Hadoop安 裝缺少windows作業系統相關檔案所致,如下圖:
-

解決方案:
從資料檔案夾中找到winutils.exe拷貝放到windows系統Hadoop安裝目錄的bin目錄下即可!! HDFS檔案系統權限問題
- hdfs的檔案權限機制與linux系統的檔案權限機制類似!!
r:read w:write x:execute 權限x對于檔案表示忽略,對于檔案夾表示是否有權限訪問其內容
如果linux系統用戶zhangsan使用hadoop命令創建一個檔案,那么這個檔案在HDFS當中的owner 就是zhangsan
HDFS檔案權限的目的,防止好人做錯事,而不是阻止壞人做壞事,HDFS相信你告訴我你是誰, 你就是誰!!
解決方案
- 指定用戶資訊獲取FileSystem物件
- 關閉HDFS集群權限校驗
```properties
vim hdfs-site.xml
#添加如下屬性
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
```
修改完成之后要分發到其它節點,同時要重啟HDFS集群
- 基于HDFS權限本身比較雞肋的特點,我們可以徹底放棄HDFS的權限校驗,如果生產環境中我們可以考慮借助kerberos以及sentry等安全框架來管理大資料集群安全,所以我們直接修改HDFS的根目錄權限為777
```shell
hadoop fs -chmod -R 777 /
```
參考代碼
```java
package com.lagou.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.permission.FsPermission;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
import org.apache.hadoop.yarn.webapp.hamlet.Hamlet;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClientDemo {
FileSystem fs = null;
Configuration configuration = null;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//1 獲取Hadoop 集群的configuration物件
configuration = new Configuration();
//configuration.set("fs.defaultFS", "hdfs://linux121:9000");
//configuration.set("dfs.replication", "2");
//2 根據configuration獲取Filesystem物件
fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root");
}
@After
public void destory() throws IOException {
//4 釋放FileSystem物件(類似資料庫連接)
fs.close();
}
@Test
public void testMkdirs() throws URISyntaxException, IOException, InterruptedException {
//FileSystem fs = FileSystem.get(configuration);
//3 使用FileSystem物件創建一個測驗目錄
fs.mkdirs(new Path("/api_test2"));
}
// 上傳檔案
@Test
public void copyFromLocalToHdfs() throws URISyntaxException, IOException, InterruptedException {
//上傳檔案
//src:源檔案目錄:本地路徑
//dst:目標檔案目錄,hdfs路徑
fs.copyFromLocalFile(new Path("e:/lagou.txt"), new Path("/lagou.txt"));
// 上傳檔案到hdfs默認是3個副本,
//如何改變上傳檔案的副本數量?
//1 configuration物件中指定新的副本數量
}
// 下載檔案
@Test
public void copyFromHdfsToLocal() throws URISyntaxException, IOException, InterruptedException {
// boolean:是否洗掉源檔案
//src:hdfs路徑
//dst:目標路徑,本地路徑
fs.copyToLocalFile(true, new Path("/lagou.txt"), new Path("e:/lagou_copy.txt"));
}
// 洗掉檔案或者檔案夾
@Test
public void deleteFile() throws URISyntaxException, IOException, InterruptedException {
fs.delete(new Path("/api_test2"), true);
}
// 遍歷hdfs的根目錄得到檔案以及檔案夾的資訊:名稱,權限,長度等
@Test
public void listFiles() throws URISyntaxException, IOException, InterruptedException {
//得到一個迭代器:裝有指定目錄下所有檔案資訊
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(new Path("/"), true);
//遍歷迭代器
while (remoteIterator.hasNext()) {
LocatedFileStatus fileStatus = remoteIterator.next();
//檔案名稱
final String fileName = fileStatus.getPath().getName();
//長度
final long len = fileStatus.getLen();
//權限
final FsPermission permission = fileStatus.getPermission();
//分組
final String group = fileStatus.getGroup();
//用戶
final String owner = fileStatus.getOwner();
System.out.println(fileName + "\t" + len + "\t" + permission + "\t" + group + "\t" + owner);
//塊資訊
final BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
final String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println("主機名稱" + host);
}
}
System.out.println("---------------------------------");
}
}
// 檔案以及檔案夾判斷
@Test
public void isFile() throws URISyntaxException, IOException, InterruptedException {
final FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
final boolean flag = fileStatus.isFile();
if (flag) {
System.out.println("檔案:" + fileStatus.getPath().getName());
} else {
System.out.println("檔案夾:" + fileStatus.getPath().getName());
}
}
}
// 使用IO流操作HDFS
//上傳檔案:準備輸入流讀取本地檔案,使用hdfs的輸出流寫資料到hdfs
@Test
public void uploadFileIO() throws IOException {
//1. 讀取本地檔案的輸入流
final FileInputStream inputStream = new FileInputStream(new File("e:/lagou.txt"));
//2. 準備寫資料到hdfs的輸出流
final FSDataOutputStream outputStream = fs.create(new Path("/lagou.txt"));
// 3.輸入流資料拷貝到輸出流 :陣列的大小,以及是否關閉流底層有默認值
IOUtils.copyBytes(inputStream, outputStream, configuration);
// 4.可以再次關閉流
IOUtils.closeStream(outputStream);
IOUtils.closeStream(inputStream);
}
// 下載檔案
@Test
public void downLoadFileIO() throws IOException {
//1. 讀取hdfs檔案的輸入流
final FSDataInputStream in = fs.open(new Path("/lagou.txt")); // 2. 本地檔案的輸出流
final FileOutputStream out = new FileOutputStream(new File("e:/lagou_io_copy.txt"));
//3. 流的拷貝
IOUtils.copyBytes(in, out, configuration);
//4.可以再次關閉流
IOUtils.closeStream(out);
IOUtils.closeStream(in);
}
// seek定位讀取hdfs指定檔案 :使用io流讀取/lagou.txt檔案并把內容輸出兩次,本質就是讀取文 件內容兩次并輸出
@Test
public void seekReadFile() throws IOException {
//1 創建一個讀取hdfs檔案的輸入流
final FSDataInputStream in = fs.open(new Path("/lagou.txt"));
//2.控制臺資料:System.out
//3 實作流拷貝,輸入流--》控制臺輸出
// IOUtils.copyBytes(in, System.out, configuration);
IOUtils.copyBytes(in, System.out, 4096, false);
// 4. 再次讀取檔案
in.seek(0); // 定位從0偏移量(檔案頭部)再次讀取
IOUtils.copyBytes(in, System.out, 4096, false);
//5.關閉輸入流
IOUtils.closeStream(in);
}
}
```轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/539386.html
標籤:大數據