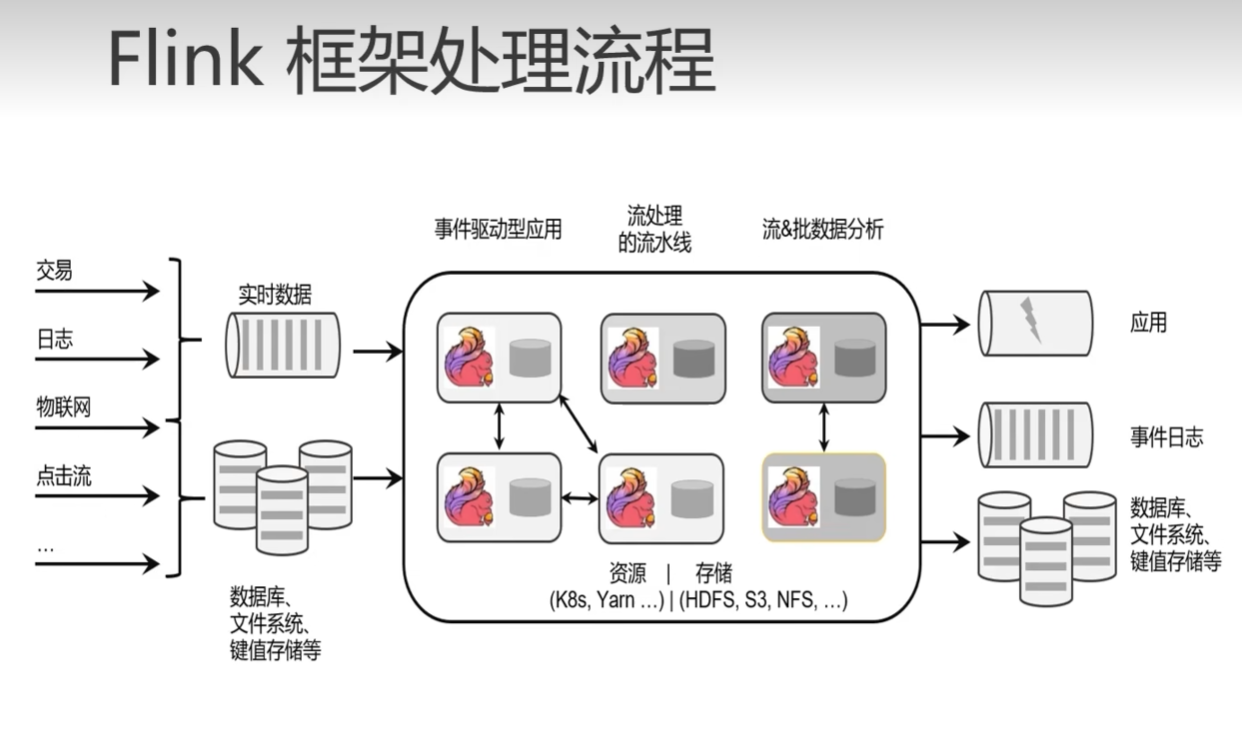
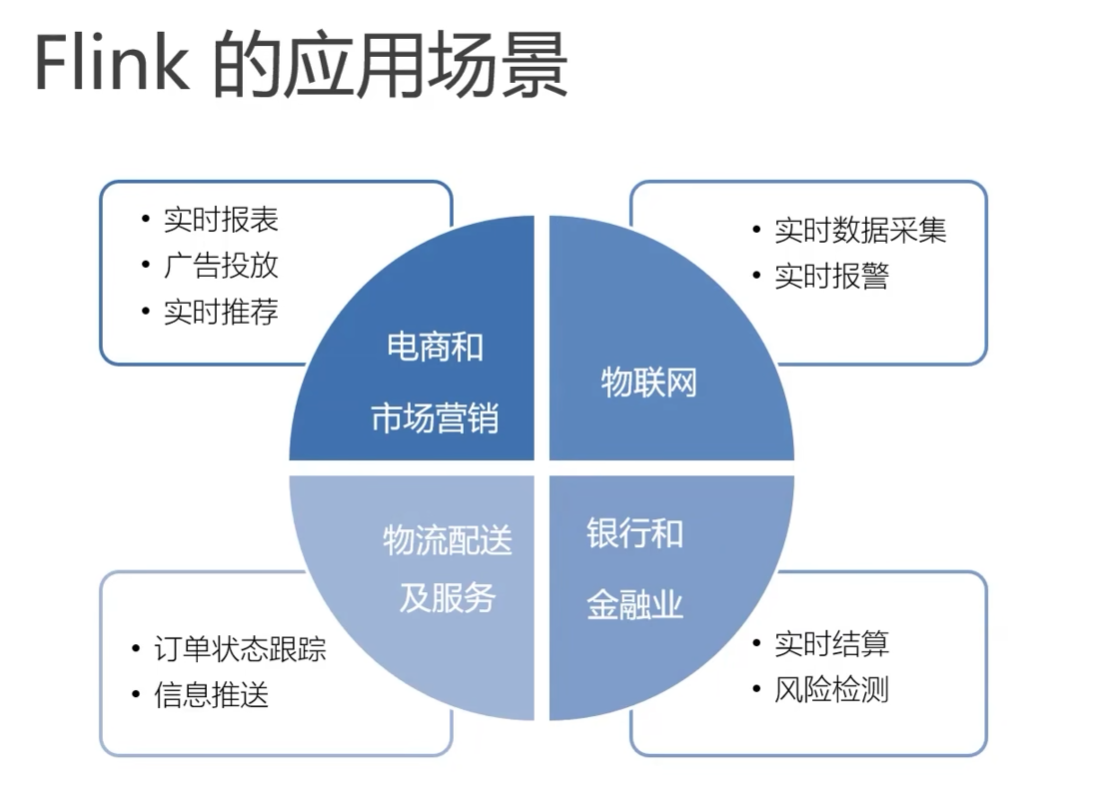
數倉分層
| 分層 | 全稱 | 譯名 | 說明 | 壓縮 | 列式存盤 | 磁區 |
|---|---|---|---|---|---|---|
| ODS | Operation Data Store | 原始層 | 原始資料 | ? | ? | ? |
| DIM | Dimension | 維度層 | 合并維度表 | ? | ? | ? |
| DWD | Data Warehouse Detail | 明細層 | 資料處理、維度建模 | ? | ? | ? |
| DWS | Data Warehouse Service | 服務層 | 去主鍵聚合,得到原子指標 | ? | ? | ? |
| DWT | Data Warehouse Topic | 主題層 | 存放主題物件的累積行為 | ? | ? | ? |
| ADS | Application Data Store | 應用層 | 具體業務指標 | ? | ? | ? |
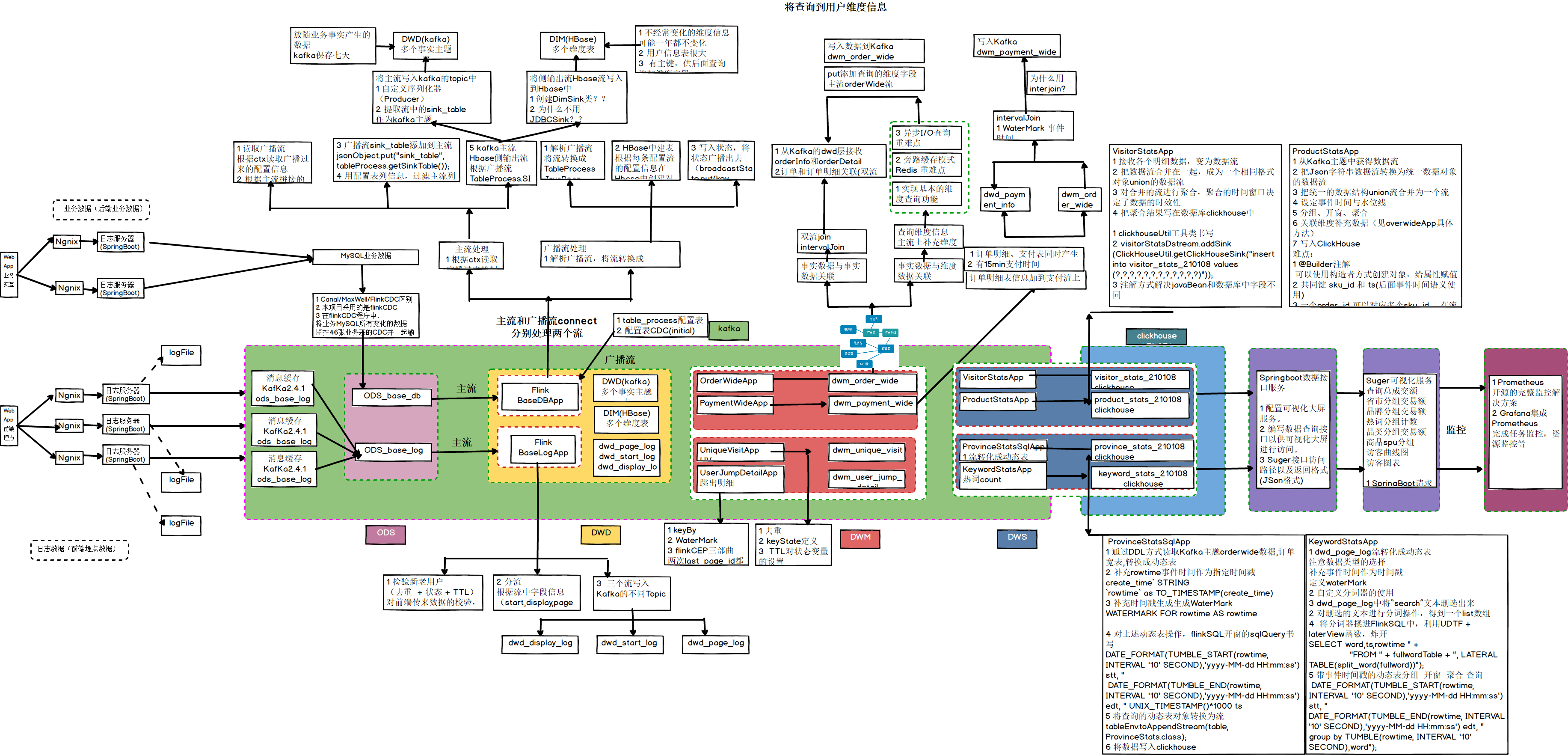
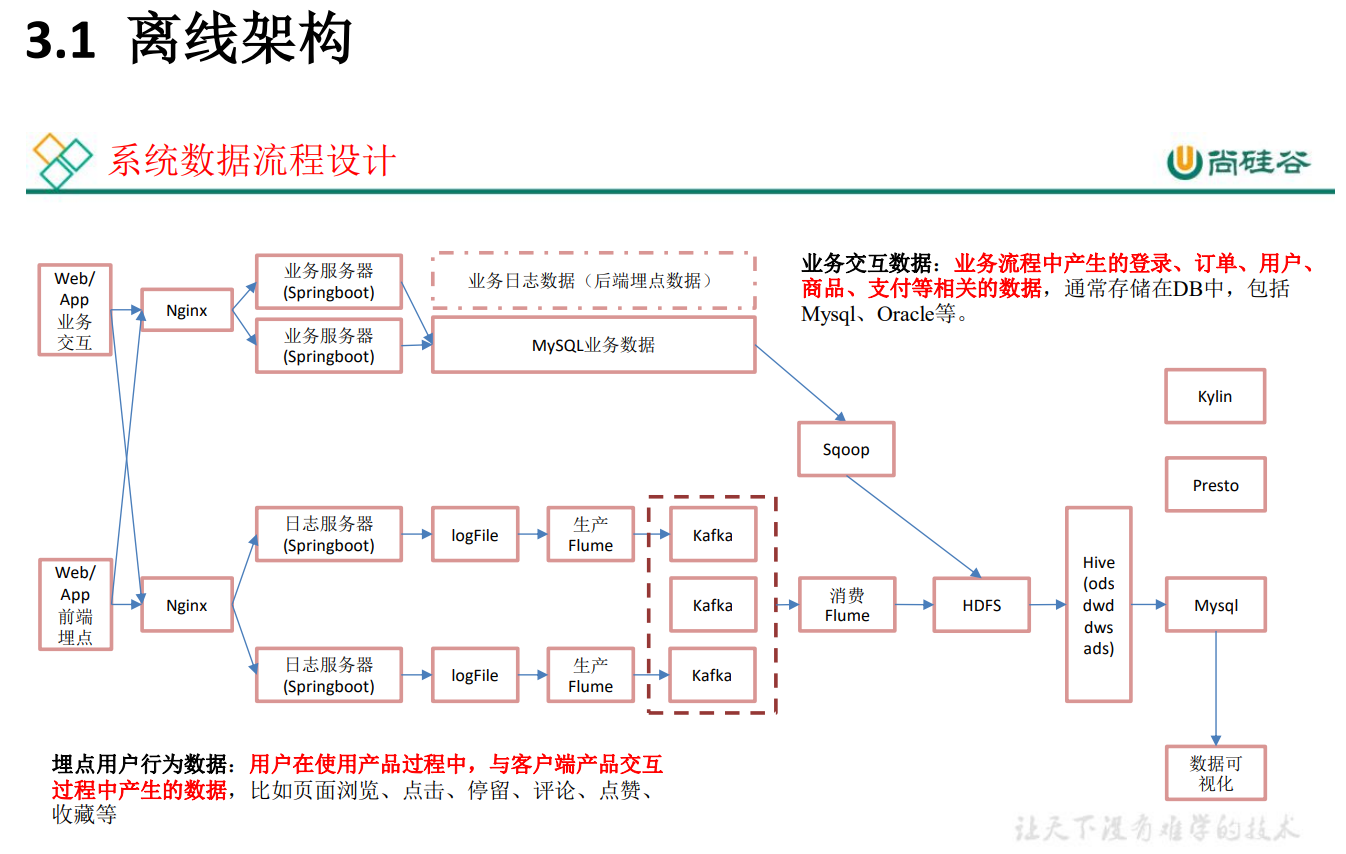
- ODS:原始資料,日志和業務資料 放到 Kafka
- DWD:根據資料物件為單位進行分流,比如訂單、頁面訪問等等
- DIM:維度資料
- DWM:對于部分資料物件進行進一步加工,比如獨立訪問、跳出行為,也可以和維度進行關聯,形成寬表,依舊是明細資料,
- DWS:根據某個主題將多個事實資料輕度聚合,形成主題寬表,
- ADS:把ClickHouse中的資料根據可視化需進行篩選聚合
命名規范
庫名:業務大類
表名:分層名_業務細類
臨時表:temp_表名
備份表:bak_表名
視圖:view_表名(場景:不共享的維度表、即席查詢)
| 分層 | 命名規范 | 說明 | 例 |
|---|---|---|---|
| ODS | ods+源型別+源表名+full/i | full:全量同步 i:增量同步 |
ods_postgresql_sku_full ods_mysql_order_detail_i ods_frontend_log |
| DIM | dim+維度+full/zip | full:全量表 zip:拉鏈表 日期維度表沒有后綴 |
dim_sku_full dim_user_zip dim_date |
| DWD | dwd+事實+full/i | full:全量事實 i:增量事實 |
|
| DWS | dws+原子指標 | 時間粒度有1d、1h… 1d:按1天 1h:按1小時 |
dws_page_visitor_1d |
| DWT | dwt_消費者畫像 | ||
| ADS | ads+衍生指標/派生指標 |
離線數倉:事實表,維度表,都放Hive
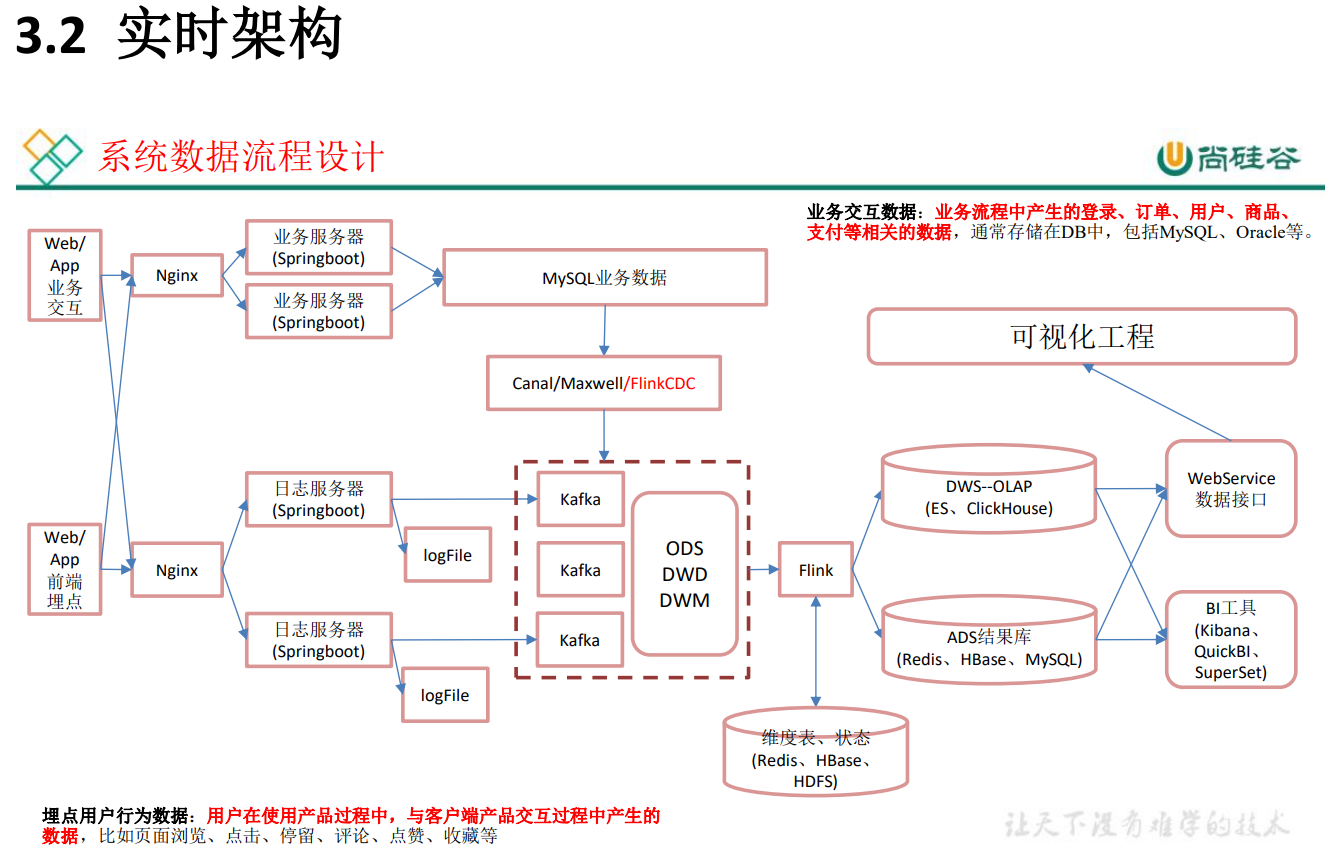
實時數倉:原始資料放 Kafka,維度資料 放 HBase,Phoenix
-
離線計算:就是在計算開始前已知所有輸入資料,輸入資料不會產生變化,一般計算量級較大,計算時間也較長,例如今天早上一點,把昨天累積的日志,計算出所需結果,最經典的就是 Hadoop 的 MapReduce 方式;
一般是根據前一日的資料生成報表,雖然統計指標、報表繁多,但是對時效性不敏感,從技術操作的角度,這部分屬于批處理的操作,即根據確定范圍的資料一次性計算, -
實時計算:輸入資料是可以以序列化的方式一個個輸入并進行處理的,也就是說在開始的時候并不需要知道所有的輸入資料,與離線計算相比,運行時間短,計算量級相對較小,強調計算程序的時間要短,即所查當下給出結果,
主要側重于對當日資料的實時監控,通常業務邏輯相對離線需求簡單一下,統計指標也少一些,但是更注重資料的時效性,以及用戶的互動性,從技術操作的角度,這部分屬于流處理的操作,根據資料源源不斷地到達進行實時的運算, -
即席查詢: 需求的臨時性,小李,把兩星期的資料拉給我看下(只在這個時刻需要)
Presto: 當場計算(基于記憶體速度快)
Kylin:預計算(提前算好),多維分析(Hive With Cube)
Sqoop 匯入資料方式:
-
增量: where 1=1、
-
全量: where 創建時間=當天、
-
新增及變化:where 創建時間=當天 or 操作時間=當天、
-
特殊(只匯入一次)
Flume: -
tailDirSource
優點:斷點續傳,監控多目錄多檔案
缺點:當檔案更名之后,重新讀取該檔案造成資料重復
注意:1. 要使用不更名的列印日志框架(logback)--一般logback 也會設定成更名的,每天一個日志檔案,檔案名帶上日期,如果寫死檔案名,更名后可能會丟資料
2.修改原始碼,讓TailDirSource判斷檔案時,只看 iNode 值 -
KafkaChannel
優點:將資料匯入Kafka,省了一層Sink
Kafka:生產者、消費者
用法:1. Source-KafkaChannel-Sink
2. Source-KafkaChannel
3. KafkaChannel-Sink
邏輯線: 資料流、監控、優化、配置,
Kafka
- Producer:ACK、攔截器、序列化器、磁區器、發送流程、事務、冪等性,磁區規則-->有指定磁區發到指定磁區,沒有根據Key進行hash,都沒有進行輪詢(粘性)
- Broker: Topic 副本-> 高可用 ISR LEO、HW ;磁區:高并發、負載均衡(防止熱點)
- Consumer:磁區分配規則 offset 保存(默認:_consumer_offsets 主題、其它:手動維護Offerset(MySQL)帶事務,精準一次消費
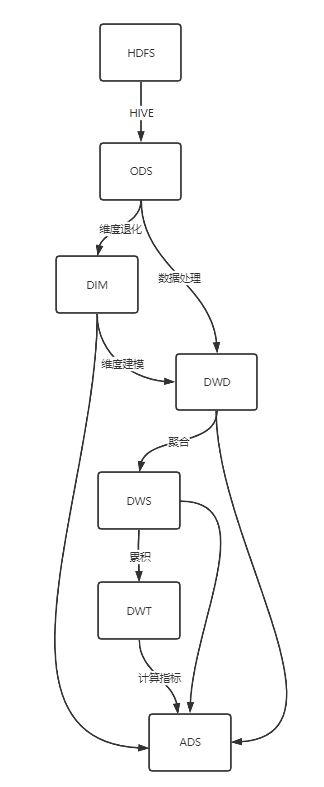
分層的好處
- 復雜問題拆解為多層
- 減少重復開發(可以去中間層取數,不用每次都去原始層)
- 隔離原始資料,例如:例外資料、敏感資料(用戶電話…)
資料存盤策略
- 原始層保持資料原貌,不進行脫敏和清洗
- 創建磁區表(例如:日期磁區),防止全表掃描
- 資料壓縮,減少磁盤占用(如:LZO、gzip、snappy)
- 列式存盤提高查詢效率(如:Parquet、ORC)
離線架構:追求系統的穩定性、考慮到公司未來的發展,資料量一定會變得很大、早期的時間實時業務使用 SparkStreaming(微批次)
- 優點:耦合性低、穩定性高
- 缺點:時效性差
實時架構:Kafka集群高可用,資料量小,所有機器存在同一個機房,傳輸沒有問題,
- 優點:時效性好 Flink
- 缺點:耦合性高,穩定性低
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/539426.html
標籤:大數據
上一篇:1.5.4 HDFS 客戶端操作-hadoop-最全最完整的保姆級的java大資料學習資料
下一篇:事務相關知識集錦