簡介
CloudCanal 實作的 基于 Kafka 構建安全的跨互聯網資料同步 方案被客戶用于生產后,又出現了新的需求,主要集中在方案能否更加輕量化和可控性上,簡而言之,去掉 Kafka 中轉,直接在 CloudCanal 中實作跨網路安全互通,
本篇文章即介紹 CloudCanal 實作的更加輕量化方案,特點包括
- 無訊息等獨立軟體依賴
- 兩端資料庫完全不開放公網埠
- 兩端資料庫元資料可映射
- 基于 HTTPS 傳輸
- 具備用戶名密碼鑒權機制
- 支持多種資料庫異構互通
技術點
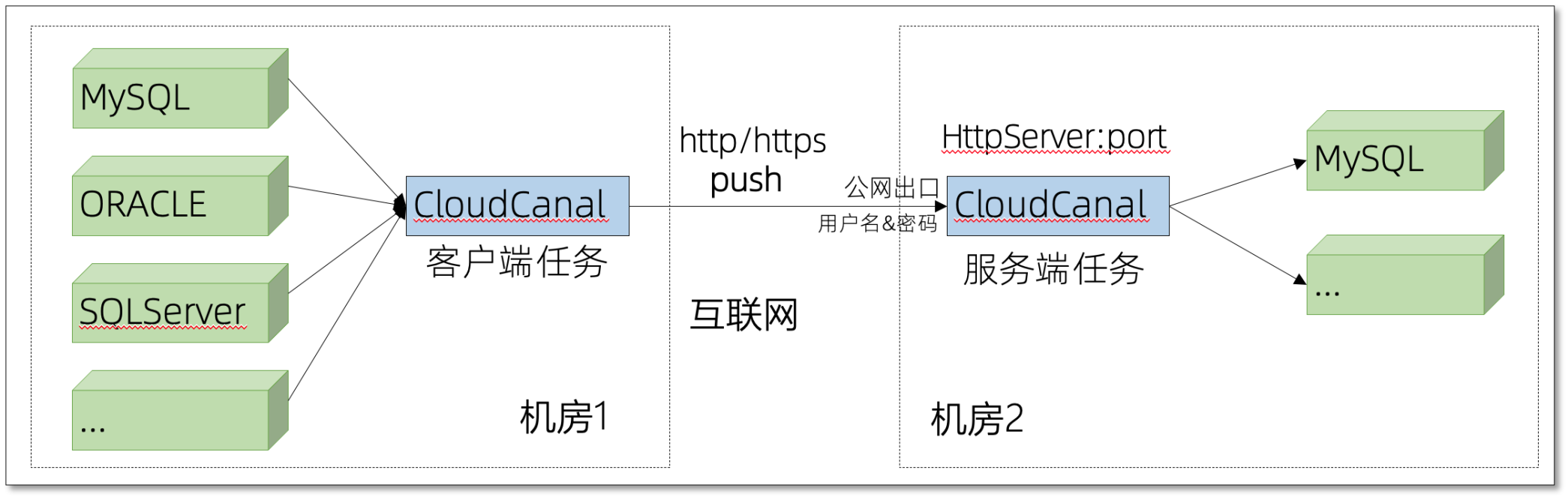
Tunnel資料源
去掉訊息依賴的跨互聯網資料庫互通,我們是通過一個虛擬的資料源 Tunnel 實作,
Tunnel 資料源本身并不是物體資料庫,而是一組邏輯資訊,包括
- ip(或域名)
- port
- 用戶名
- 密碼
- TLS 證書檔案和密碼
- 元資料
通過這個虛擬資料源,我們可以使用 HTTP(S) 或 TCP 實作資料拉取或者接收資料的目的,同時完全匹配 CloudCanal 業務模型,達到功能的完整性,
PUSH模型
對于資料傳輸模式 PUSH 或 PULL,我們選擇了 PUSH 模式,即客戶端將資料推送到服務端,本質原因在于
- 主要解決互通問題,而非訂閱問題
- 目標端同步寫入資料更加匹配 CloudCanal 其他目標端風格
- 資料通道無資料持久化,無需維護 store 來暫存資料
當然,PUSH 模式也帶來一些問題,包括
- 如何確保最終資料寫入再提交位點
- 位點回溯復雜(全量和增量、不同資料源位點格式不一致)
對于上述兩個問題,我們采用 延遲提交位點技術 解決
延遲提交位點技術
采用 PUSH 模式后,位點管理是比較復雜且危險的作業,如果提早提交位點,可能丟資料,
為此,我們實作了 延遲提交位點技術,即客戶端每一次寫入 server 端,只回傳已經提交的位點,并且將所有資料源、所有任務型別的位點序列化成 json 字串,
通過這項技術,我們能夠確保位點之前的資料肯定已經寫到對端,并且在某些業務場景下,通過客戶端任務的位點回溯,達到重復消費某一段時間資料的目的,
元資料映射
因為使用了虛擬的 Tunnel 資料源,并且其帶有 schema(存盤于CloudCanal kv配置表中), 所以針對這個資料源,我們模擬了表結構獲取和遷移的程序,讓其在任務創建和運維程序中如同一個真實存在的資料庫,
一個真實的 Tunnel 資料源的元資料如下:
[
{
"db": "cc_virtual_db",
"schemas": [
{
"schema": "cc_virtual_schema",
"tables": [
{
"table": "WORKER_STATS",
"columns": [
{
"name": "ID",
"jdbcType": -5,
"typeName": "LONG",
"key": true
},
{
"name": "GMT_CREATE",
"jdbcType": 93,
"typeName": "TIMESTAMP",
"key": false
},
{
"name": "AUCRDT",
"jdbcType": 93,
"typeName": "TIMESTAMP",
"key": false
}
]
},
{
"table": "KBS_QUESTION",
"columns": [
{
"name": "ID",
"jdbcType": -5,
"typeName": "LONG",
"key": true
},
{
"name": "CATEGORY",
"jdbcType": 12,
"typeName": "STRING",
"key": false
}
]
}
]
}
]
}
]
我們可以通過結構遷移 (MySQL/SQLServer/Oracle -> Tunnel) 擴充它,或者直接通過 資料源管理->更多->查看配置->_**dbsJson **_進行修改,
操作示例
本示例使用阿里云資源模擬杭州 RDS for MySQL 到深圳 RDS for MySQL , 兩端資料庫均不開公網埠,資料走互聯網, 采用 HTTPS 傳輸和用戶名密碼認證,
環境準備
- 杭州環境部署 CloudCanal ,并購買 RDS for MySQL 作為源端


- 深圳環境部署 CloudCanal , 并購買 RDS for MySQL 作為目標端


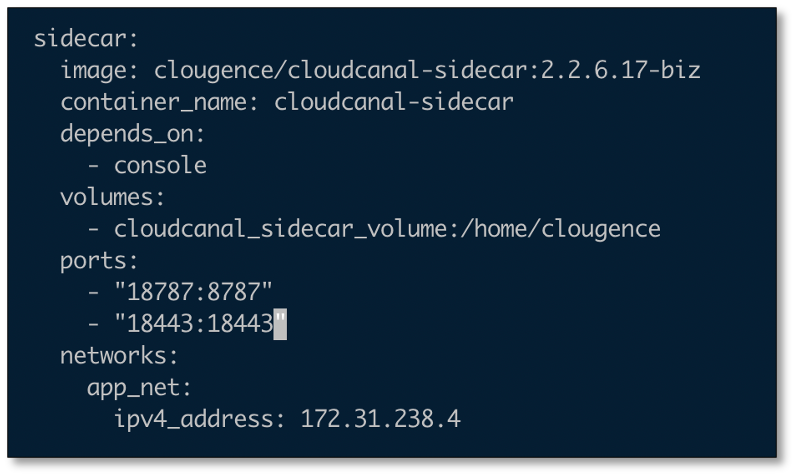
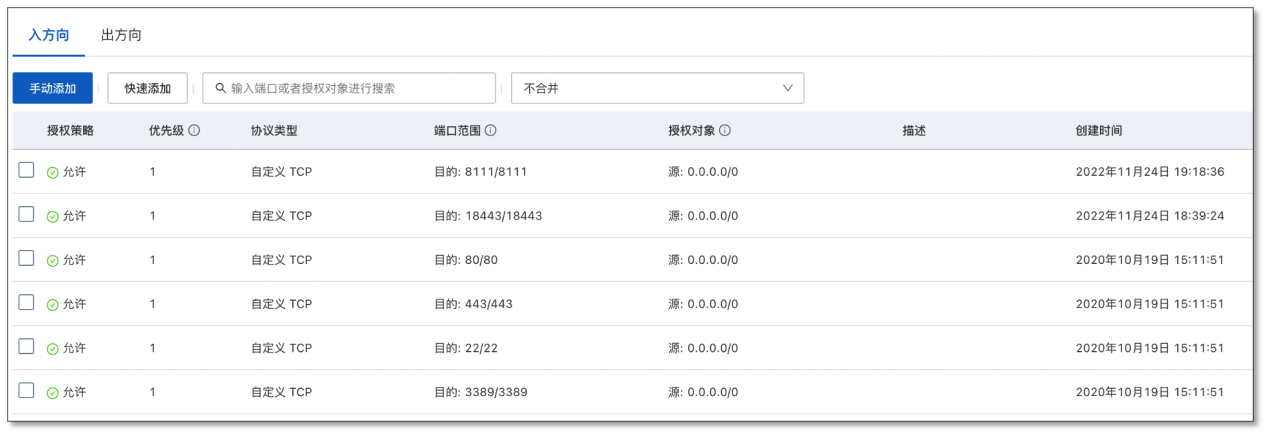
- 因 CloudCanal 為 docker 版本 , 深圳環境 CloudCanal 安裝包解壓后 ,需要修改 docker-compose.yml 埠映射再安裝/升級,并開放 ECS 安全組相關埠,以便遠程連接,
- 此例以 18443 埠作為 Tunnel 資料源監聽埠
為目標端資料庫初始化元資料
- 因無法通過 Tunnel 到對端資料庫做結構遷移,所以需要事先使用 mysqldump 等工具初始化對端資料庫結構
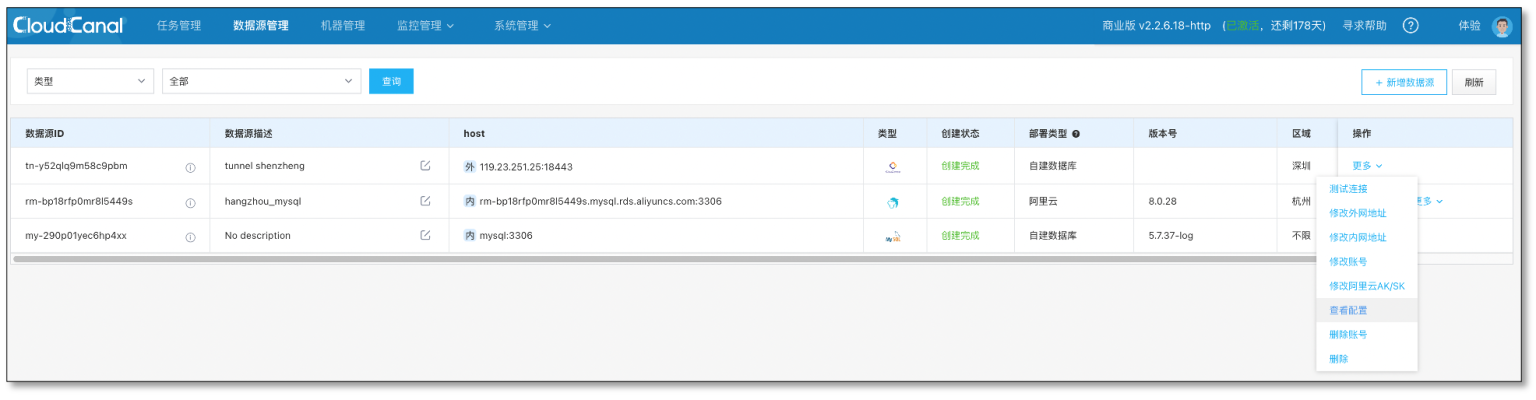
添加 Tunnel 資料源
- 分別在源端和目標端 CloudCanal 配置 Tunnel 資料源
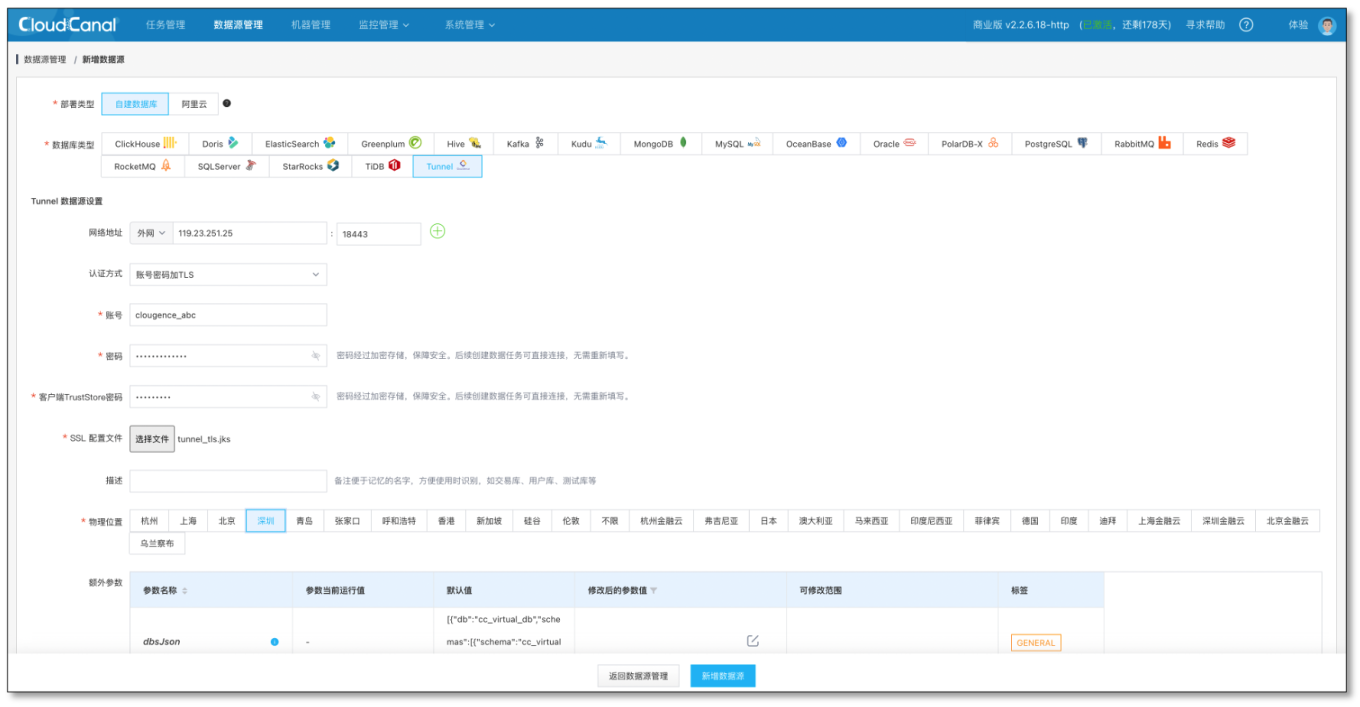
- 源端資料源串列

- 目標端資料源串列

為 Tunnel 初始化元資料
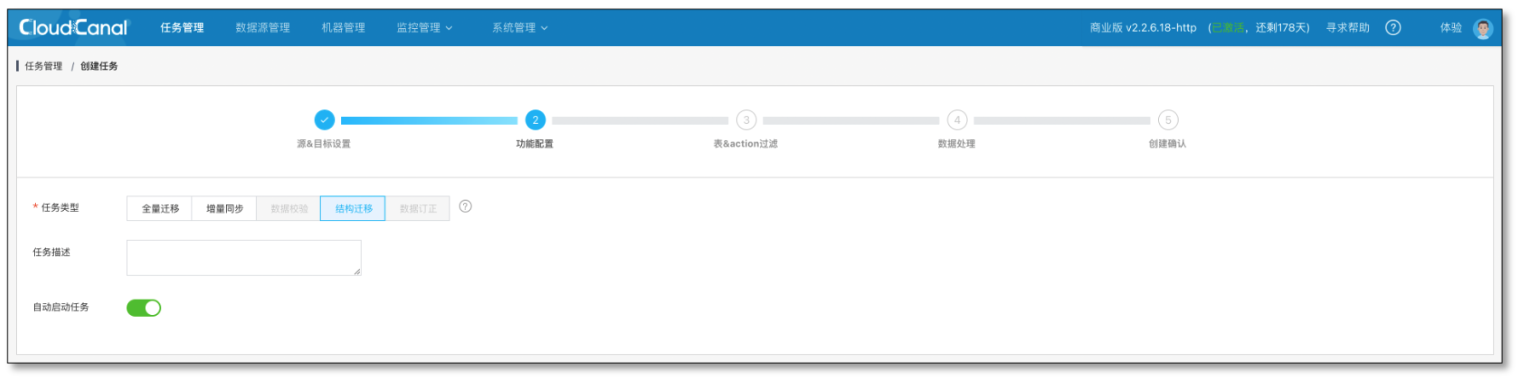
- 源端創建一個 MySQL -> Tunnel 結構遷移,并完成
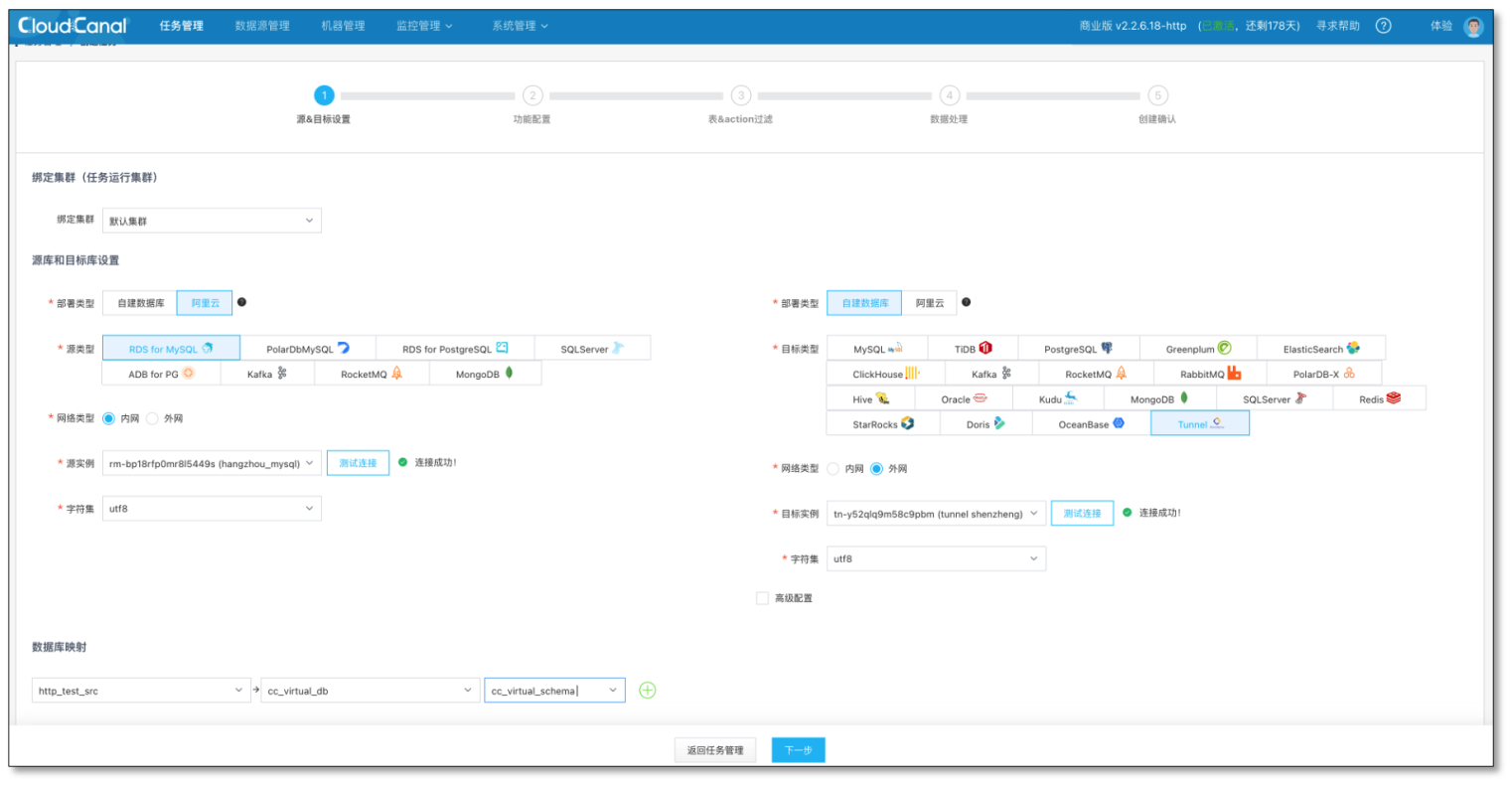
- 目標端
- 從源端 Tunnel 資料源拷貝結構并復制到對端
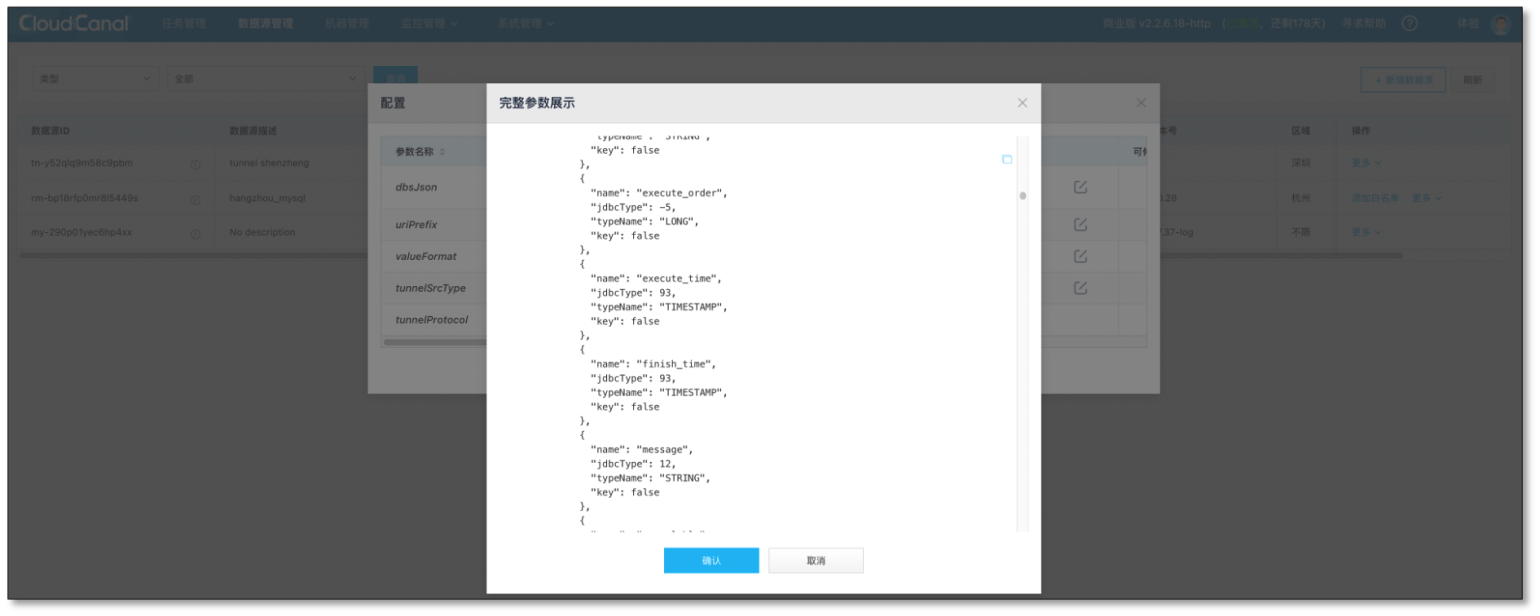
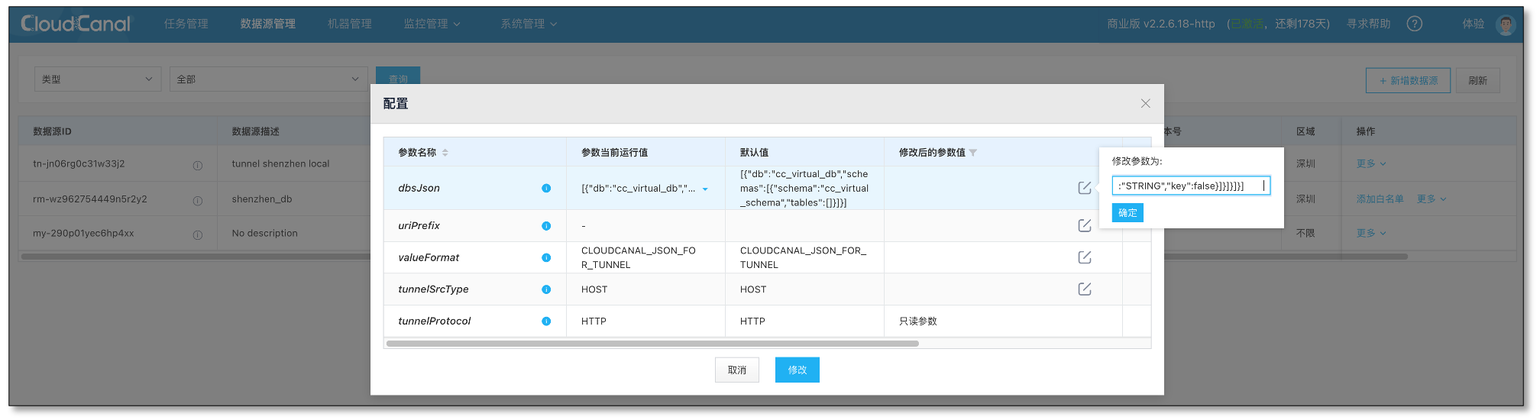
目標端任務創建
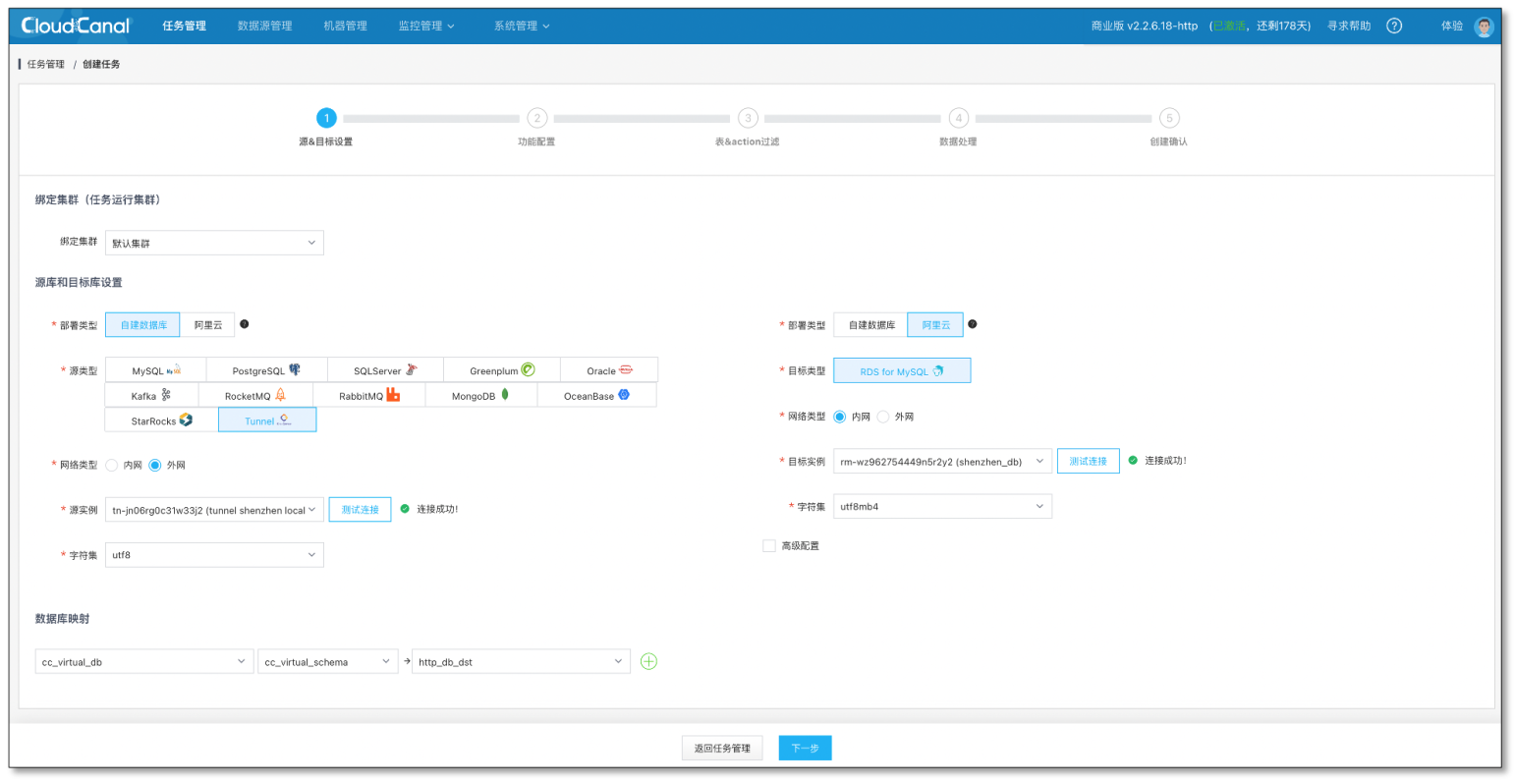
- 選擇 Tunnel 和 目標資料庫
- 選擇資料同步
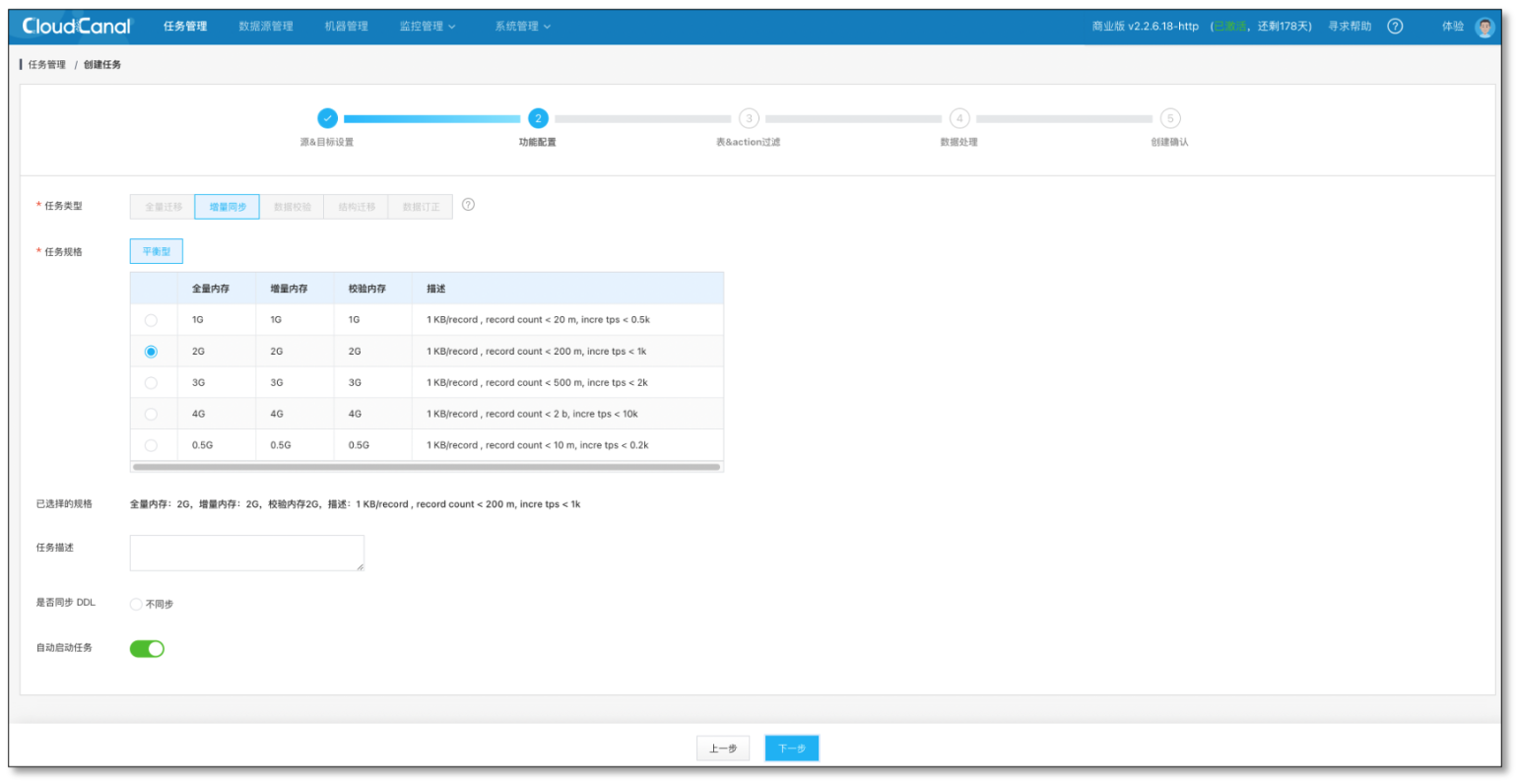
- 選擇表、列、映射略
- 任務正常運行,監聽埠并準備接收資料

源端任務創建
- 選擇源端資料庫 和 Tunnel 資料源
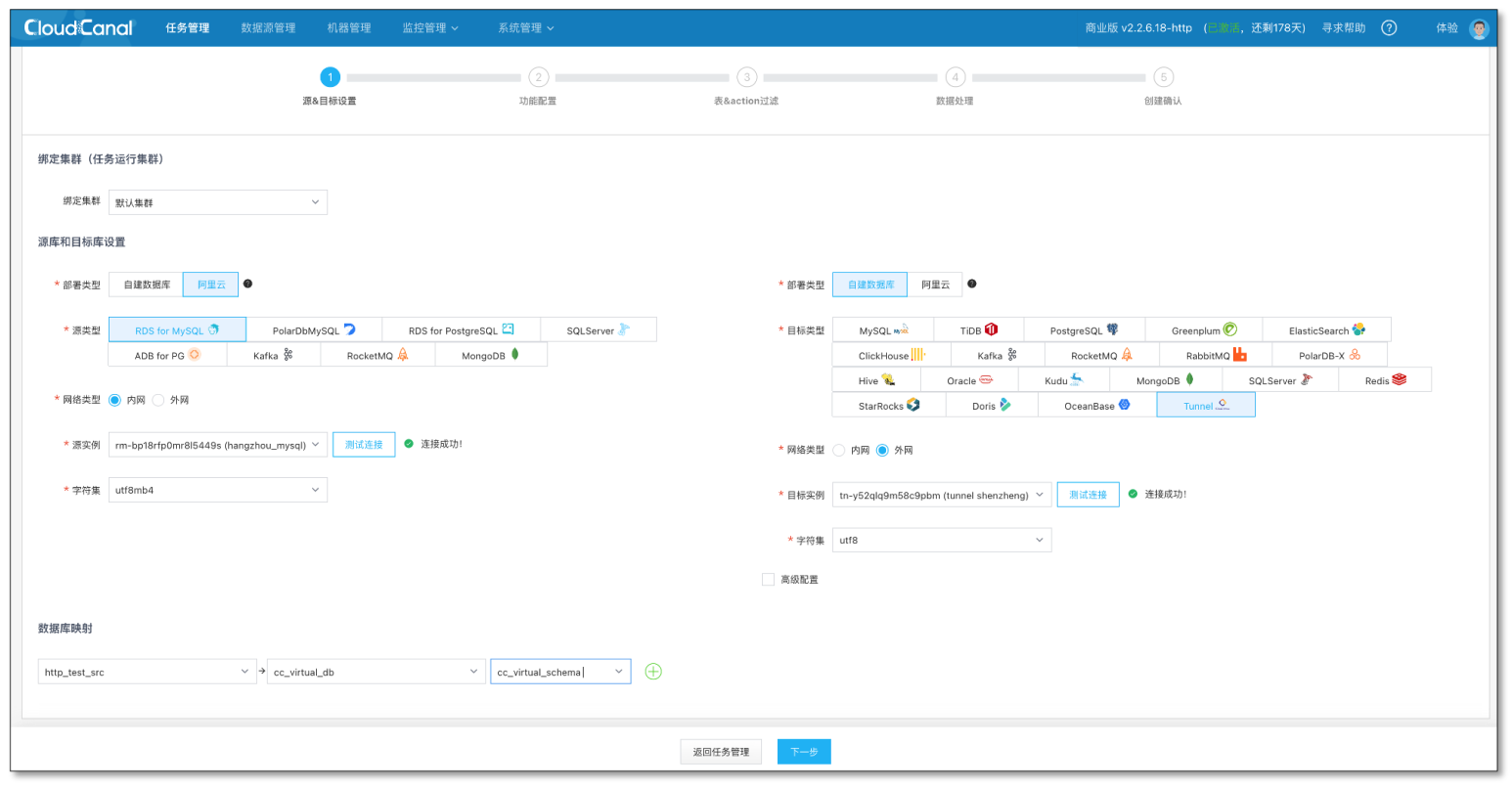
- 選擇資料同步,并初始化資料
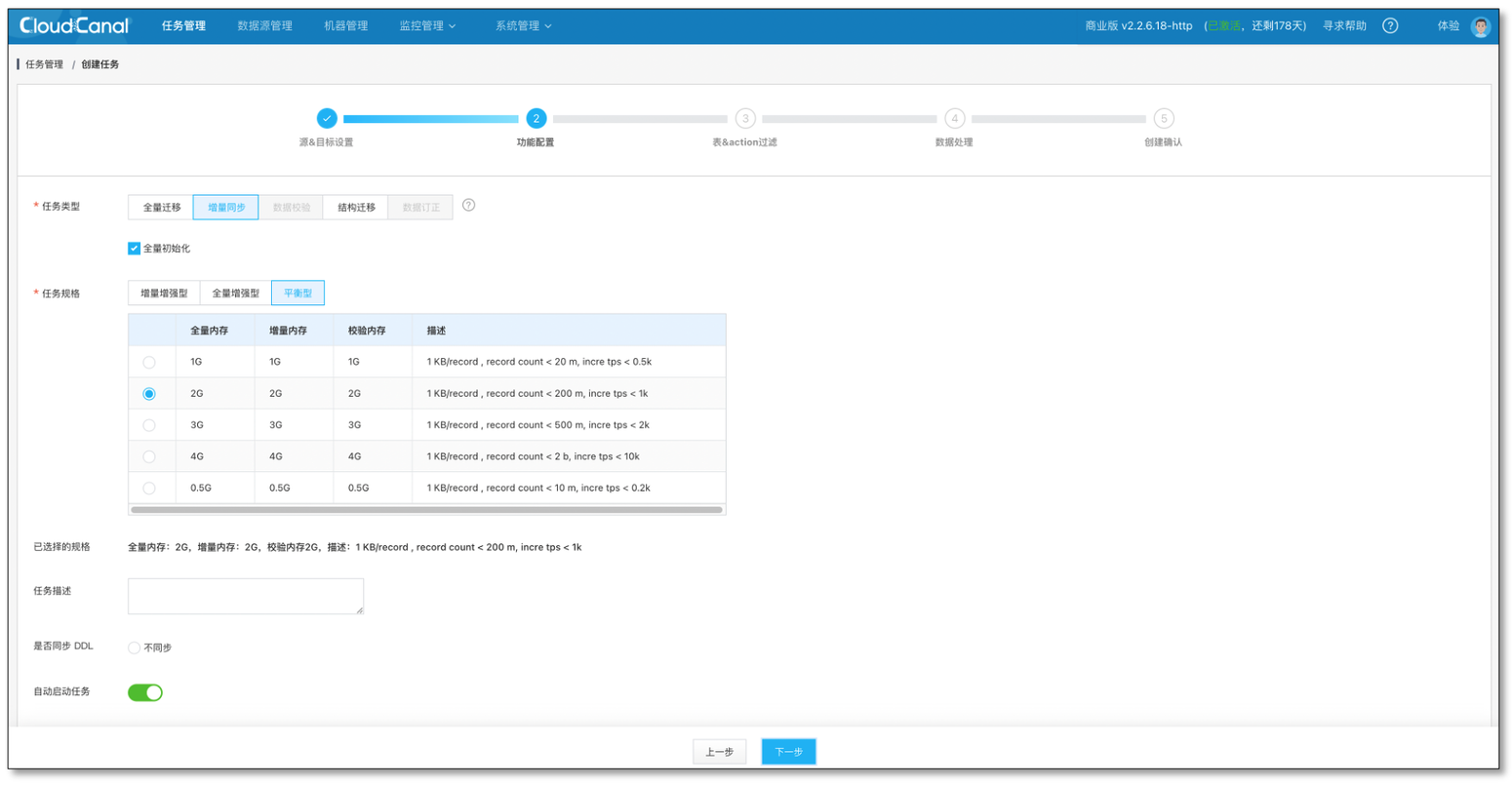
- 資料初始化中(如有效率問題,可忽略)

- 資料持續同步中

資料驗證
造增量資料
- 為了造資料簡便,開下源端資料庫公網地址
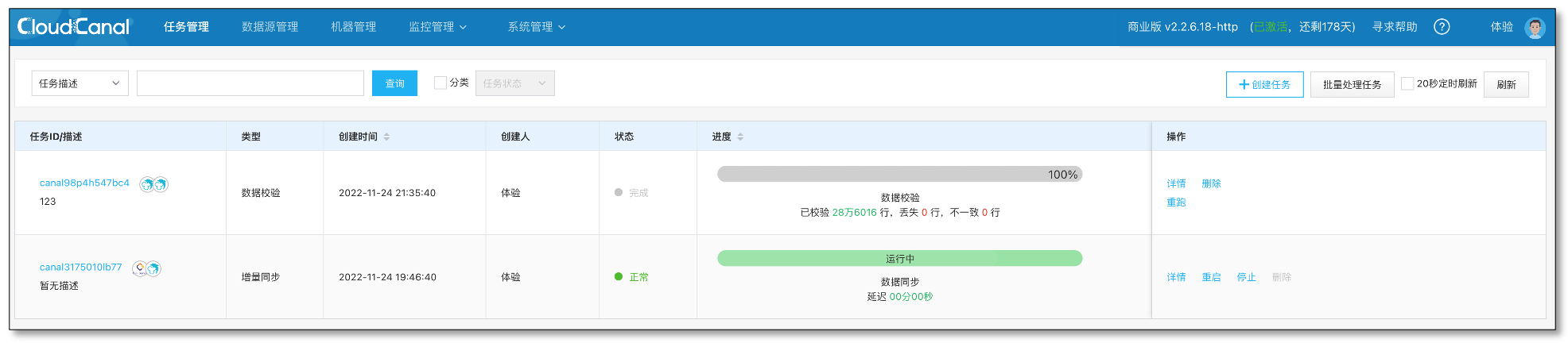
資料校驗
- 在深圳環境添加源端資料源,并做資料校驗,結果顯示資料一致,
常見問題
-
目前支持哪些鏈路的互通?
- MySQL/SQLServer/ORACLE -> MySQL , 其他互通按需添加,
-
Tunnel 到對端資料庫能做結構遷移么?準備表結構比較麻煩
- 因為資料庫結構對元資料精度要求很高,Tunnel中間結構主要為同步服務,所以元資料級別上還無法構成精確的結構遷移源端,建議構建臨時實體(只dump表結構)并開公網,再使用CloudCanal結構遷移解決問題,
-
Tunnel 資料源有結構,能動態編輯么?
- Tunnel 資料源模擬了一個資料庫,編輯任務能力天然具備,加表先編輯目標端任務,再編輯源端任務,否則反之,我們后續計劃用一篇專門的文章介紹這個運維操作,
-
目前資料互通還存在什么問題?
- 對于 blob 等欄位型別還需要進一步支持和驗證
- 跨互聯網,性能層面需要經過特別的優化
- 安全層面,目前僅用到 HTTPS 證書加密,配合自定義的賬號密碼
總結
本文主要介紹純粹通過 CloudCanal 進行資料互通實踐,通過引入虛擬資料源,達成資料互通和元資料映射等能力,具備不錯的可落地性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/539689.html
標籤:其他