MySQL資料模型
關系型資料庫是建立在關系模型基礎上的資料庫,簡單說,關系型資料庫是由多張能互相連接的 二維表 組成的資料庫
關系型資料庫的優點:
- 都是使用表結構,格式一致,易于維護,
- 使用通用的 SQL 語言操作,使用方便,可用于復雜查詢,
- 關系型資料庫都可以通過SQL進行操作,所以使用方便,
- 復雜查詢,現在需要查詢001號訂單資料,我們可以看到該訂單是1號客戶的訂單,而1號訂單是李聰這個客戶,以
- 后也可以在一張表中進行統計分析等操作,
- 資料存盤在磁盤中,安全,
SQL分類
- DDL(Data Definition Language) : 資料定義語言,用來定義資料庫物件:資料庫,表,列等
????DDL簡單理解就是用來操作資料庫,表等
- DML(Data Manipulation Language) 資料操作語言,用來對資料庫中表的資料進行增刪改
????DML簡單理解就對表中資料進行增刪改
- DQL(Data Query Language) 資料查詢語言,用來查詢資料庫中表的記錄(資料)
????DQL簡單理解就是對資料進行查詢操作,從資料庫表中查詢到我們想要的資料,
- DCL(Data Control Language) 資料控制語言,用來定義資料庫的訪問權限和安全級別,及創建用戶
????DML簡單理解就是對資料庫進行權限控制,比如我讓某一個資料庫表只能讓某一個用戶進行操作等,
| 注意: 以后我們最常操作的是 DML 和 DQL ,因為我們開發中最常操作的就是資料, |
DDL:操作資料庫
查詢所有的資料庫
- 運行上面陳述句效果如下:
SHOW DATABASES;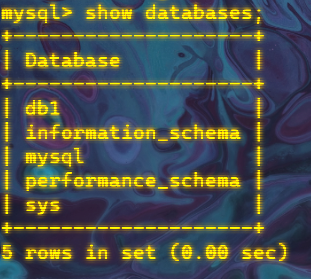
創建資料庫
-
創建資料庫:
CREATE DATABASE 資料庫名稱;
而在創建資料庫的時候,我并不知道datastu資料庫有沒有創建,直接再次創建名為db1的資料庫就會出現錯誤,
-
創建資料庫(判斷,如果不存在則創建)
CREATE DATABASE IF NOT EXISTS 資料庫名稱;洗掉資料庫
-
洗掉資料庫
DROP DATABASE 資料庫名稱;-
洗掉資料庫(判斷,如果存在則洗掉)
DROP DATABASE IF EXISTS 資料庫名稱;使用資料庫
資料庫創建好了,要在資料庫中創建表,得先明確在哪兒個資料庫中操作,此時就需要使用資料庫,
-
使用資料庫
USE 資料庫名稱;-
查看當前使用的資料庫
SELECT DATABASE();DDL:操作表
查詢表
-
查詢當前資料庫下所有表名稱
SHOW TABLES;-
查詢表結構
DESC 表名稱;表的增刪改查
-
創建表
CREATE TABLE 表名 (
欄位名1 資料型別1,
欄位名2 資料型別2,
…
欄位名n 資料型別n
);
?注意:最后一行末尾,不能加逗號
create table tb_user (
id int,
username varchar(20),
password varchar(32)
);資料型別
MySQL 支持多種型別,可以分為三類:
-
數值
tinyint : 小整數型,占一個位元組 int : 大整數型別,占四個位元組 eg : age int double : 浮點型別 使用格式: 欄位名 double(總長度,小數點后保留的位數) eg : score double(5,2) -
日期
date : 日期值,只包含年月日 eg : birthday date : datetime : 混合日期和時間值,包含年月日時分秒 -
字串
案例:
需求:設計一張學生表,請注重資料型別、長度的合理性
1. 編號
2. 姓名,姓名最長不超過10個漢字
3. 性別,因為取值只有兩種可能,因此最多一個漢字
4. 生日,取值為年月日
5. 入學成績,小數點后保留兩位
6. 郵件地址,最大長度不超過 64
7. 家庭聯系電話,不一定是手機號碼,可能會出現 - 等字符
8. 學生狀態(用數字表示,正常、休學、畢業...)陳述句設計如下:
??
create table student (
id int,
name varchar(10),
gender char(1),
birthday date,
score double(5,2),
email varchar(15),
tel varchar(15),
status tinyint
);洗掉表
-
洗掉表
DROP TABLE 表名;-
洗掉表時判斷表是否存在
DROP TABLE IF EXISTS 表名;修改表
-
修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
?
-- 將表名student修改為stu
alter table student rename to stu;-
添加一列
ALTER TABLE 表名 ADD 列名 資料型別;
?
-- 給stu表添加一列address,該欄位型別是varchar(50)
alter table stu add address varchar(50);-
修改資料型別
ALTER TABLE 表名 MODIFY 列名 新資料型別;
?
-- 將stu表中的address欄位的型別改為 char(50)
alter table stu modify address char(50);-
修改列名和資料型別
ALTER TABLE 表名 CHANGE 列名 新列名 新資料型別;
?
-- 將stu表中的address欄位名改為 addr,型別改為varchar(50)
alter table stu change address addr varchar(50);-
洗掉列
ALTER TABLE 表名 DROP 列名;
?
-- 將stu表中的addr欄位 洗掉
alter table stu drop addr;DML
DML主要是對資料進行增(insert)刪(delete)改(update)操作,
添加資料
-
給指定列添加資料
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…);-
給全部列添加資料
INSERT INTO 表名 VALUES(值1,值2,…);-
批量添加資料
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
INSERT INTO 表名 VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
-
練習
為了演示以下的增刪改操作是否操作成功,故先將查詢所有資料的陳述句介紹給大家:
select * from stu;
-- 給指定列添加資料
INSERT INTO stu (id, NAME) VALUES (1, '張三');
-- 給所有列添加資料,列名的串列可以省略的
INSERT INTO stu (id,NAME,sex,birthday,score,email,tel,STATUS) VALUES (2,'李四','男','1999-11-11',88.88,'[email protected]','13888888888',1);
?
INSERT INTO stu VALUES (2,'李四','男','1999-11-11',88.88,'[email protected]','13888888888',1);
?
-- 批量添加資料
INSERT INTO stu VALUES
(2,'李四','男','1999-11-11',88.88,'[email protected]','13888888888',1),
(2,'李四','男','1999-11-11',88.88,'[email protected]','13888888888',1),
(2,'李四','男','1999-11-11',88.88,'[email protected]','13888888888',1);修改資料
-
修改表資料
UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 條件] ;注意:
修改陳述句中如果不加條件,則將所有資料都修改!
像上面的陳述句中的中括號,表示在寫 sql 陳述句中可以省略這部分
-
練習
-
將張三的性別改為女
update stu set sex = '女' where name = '張三'; -
將張三的生日改為 1999-12-12 分數改為99.99
update stu set birthday = '1999-12-12', score = 99.99 where name = '張三'; -
注意:如果update陳述句沒有加where條件,則會將表中所有資料全部修改!
update stu set sex = '女';
-
洗掉資料
-
洗掉資料
DELETE FROM 表名 [WHERE 條件] ;-
練習
-- 洗掉張三記錄
delete from stu where name = '張三';
?
-- 洗掉stu表中所有的資料
delete from stu;基礎查詢
語法
-
查詢多個欄位
SELECT 欄位串列 FROM 表名;
SELECT * FROM 表名; -- 查詢所有資料-
去除重復記錄
SELECT DISTINCT 欄位串列 FROM 表名;-
起別名
AS: AS 也可以省略
練習
-
查詢name、age兩列
select name,age from stu; -
查詢所有列的資料,列名的串列可以使用 * 替代
select * from stu; -
查詢地址資訊
select address from stu;從上面的結果我們可以看到有重復的資料,我們也可以使用
distinct關鍵字去重重復資料, -
去除重復記錄
select distinct address from stu; -
查詢姓名、數學成績、英語成績,并通過as給math和english起別名(as關鍵字可以省略)
select name,math as 數學成績,english as 英文成績 from stu; select name,math 數學成績,english 英文成績 from stu;
條件查詢
語法
SELECT 欄位串列 FROM 表名 WHERE 條件串列;-
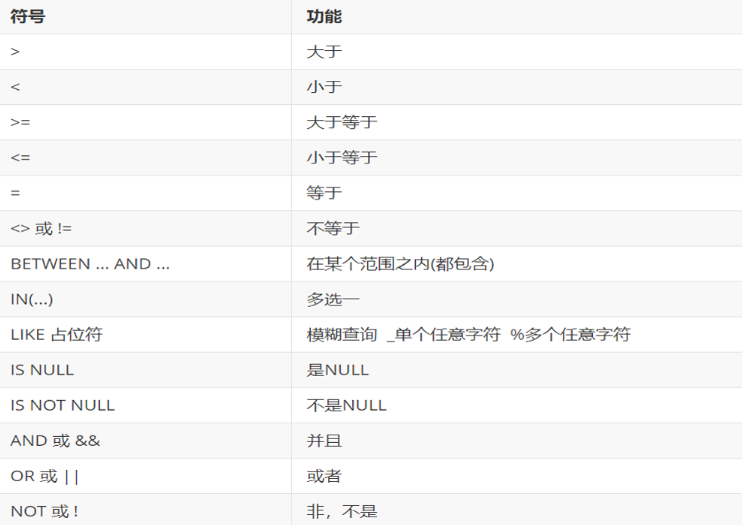
條件
????
條件查詢練習
-
查詢年齡大于20歲的學員資訊
select * from stu where age > 20; -
查詢年齡大于等于20歲的學員資訊
select * from stu where age >= 20; -
查詢年齡大于等于20歲 并且 年齡 小于等于 30歲 的學員資訊
select * from stu where age >= 20 && age <= 30; select * from stu where age >= 20 and age <= 30;上面陳述句中 && 和 and 都表示并且的意思,建議使用 and ,
也可以使用 between ... and 來實作上面需求
select * from stu where age BETWEEN 20 and 30; -
查詢入學日期在'1998-09-01' 到 '1999-09-01' 之間的學員資訊
select * from stu where hire_date BETWEEN '1998-09-01' and '1999-09-01'; -
查詢年齡等于18歲的學員資訊
select * from stu where age = 18; -
查詢年齡不等于18歲的學員資訊
select * from stu where age != 18; select * from stu where age <> 18; -
查詢年齡等于18歲 或者 年齡等于20歲 或者 年齡等于22歲的學員資訊
select * from stu where age = 18 or age = 20 or age = 22; select * from stu where age in (18,20 ,22); -
查詢英語成績為 null的學員資訊
null值的比較不能使用 = 或者 != ,需要使用 is 或者 is not
select * from stu where english = null; -- 這個陳述句是不行的 select * from stu where english is null; select * from stu where english is not null;
模糊查詢練習
模糊查詢使用like關鍵字,可以使用通配符進行占位:
(1)_ : 代表單個任意字符
(2)% : 代表任意個數字符
-
查詢姓'馬'的學員資訊
select * from stu where name like '馬%'; -
查詢第二個字是'花'的學員資訊
select * from stu where name like '_花%'; -
查詢名字中包含 '德' 的學員資訊
select * from stu where name like '%德%';
排序查詢
語法
SELECT 欄位串列 FROM 表名 ORDER BY 排序欄位名1 [排序方式1],排序欄位名2 [排序方式2] …;上述陳述句中的排序方式有兩種,分別是:
-
ASC : 升序排列 (默認值)
-
DESC : 降序排列
注意:如果有多個排序條件,當前邊的條件值一樣時,才會根據第二條件進行排序
8.3.2 練習
-
查詢學生資訊,按照年齡升序排列
select * from stu order by age ; -
查詢學生資訊,按照數學成績降序排列
select * from stu order by math desc ; -
查詢學生資訊,按照數學成績降序排列,如果數學成績一樣,再按照英語成績升序排列
select * from stu order by math desc , english asc ;
聚合函式
將一列資料作為一個整體,進行縱向計算,
聚合函式分類
| 函式名 | 功能 |
|---|---|
| count(列名) | 統計數量(一般選用不為null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
聚合函式語法
SELECT 聚合函式名(列名) FROM 表;注意:null 值不參與所有聚合函式運算
練習
-
統計班級一共有多少個學生
select count(id) from stu; select count(english) from stu;上面陳述句根據某個欄位進行統計,如果該欄位某一行的值為null的話,將不會被統計,所以可以在count(*) 來實作,* 表示所有欄位資料,一行中也不可能所有的資料都為null,所以建議使用 count(*)
select count(*) from stu; -
查詢數學成績的最高分
select max(math) from stu; -
查詢數學成績的最低分
select min(math) from stu; -
查詢數學成績的總分
select sum(math) from stu; -
查詢數學成績的平均分
select avg(math) from stu; -
查詢英語成績的最低分
select min(english) from stu;
分組查詢
語法
SELECT 欄位串列 FROM 表名 [WHERE 分組前條件限定] GROUP BY 分組欄位名 [HAVING 分組后條件過濾];注意:分組之后,查詢的欄位為聚合函式和分組欄位,查詢其他欄位無任何意義
練習
-
查詢男同學和女同學各自的數學平均分
select sex, avg(math) from stu group by sex;注意:分組之后,查詢的欄位為聚合函式和分組欄位,查詢其他欄位無任何意義
select name, sex, avg(math) from stu group by sex; -- 這里查詢name欄位就沒有任何意義 -
查詢男同學和女同學各自的數學平均分,以及各自人數
select sex, avg(math),count(*) from stu group by sex; -
查詢男同學和女同學各自的數學平均分,以及各自人數,要求:分數低于70分的不參與分組
select sex, avg(math),count(*) from stu where math > 70 group by sex; -
查詢男同學和女同學各自的數學平均分,以及各自人數,要求:分數低于70分的不參與分組,分組之后人數大于2個的
select sex, avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2;
where 和 having 區別:
-
執行時機不一樣:where 是分組之前進行限定,不滿足where條件,則不參與分組,而having是分組之后對結果進行過濾,
-
可判斷的條件不一樣:where 不能對聚合函式進行判斷,having 可以,
分頁查詢
語法
SELECT 欄位串列 FROM 表名 LIMIT 起始索引 , 查詢條目數;注意: 上述陳述句中的起始索引是從0開始
練習
-
從0開始查詢,查詢3條資料
select * from stu limit 0 , 3; -
每頁顯示3條資料,查詢第1頁資料
select * from stu limit 0 , 3; -
每頁顯示3條資料,查詢第2頁資料
select * from stu limit 3 , 3; -
每頁顯示3條資料,查詢第3頁資料
select * from stu limit 6 , 3;
從上面的練習推匯出起始索引計算公式:
起始索引 = (當前頁碼 - 1) * 每頁顯示的條數本文來自博客園,作者:link-零,轉載請注明原文鏈接:https://www.cnblogs.com/e-link/p/16964762.html???
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/539746.html
標籤:其他