簡介
官方文章的地址是 Building with Patterns: A Summary,其中匯總了 12 種設計模式及使用場景,
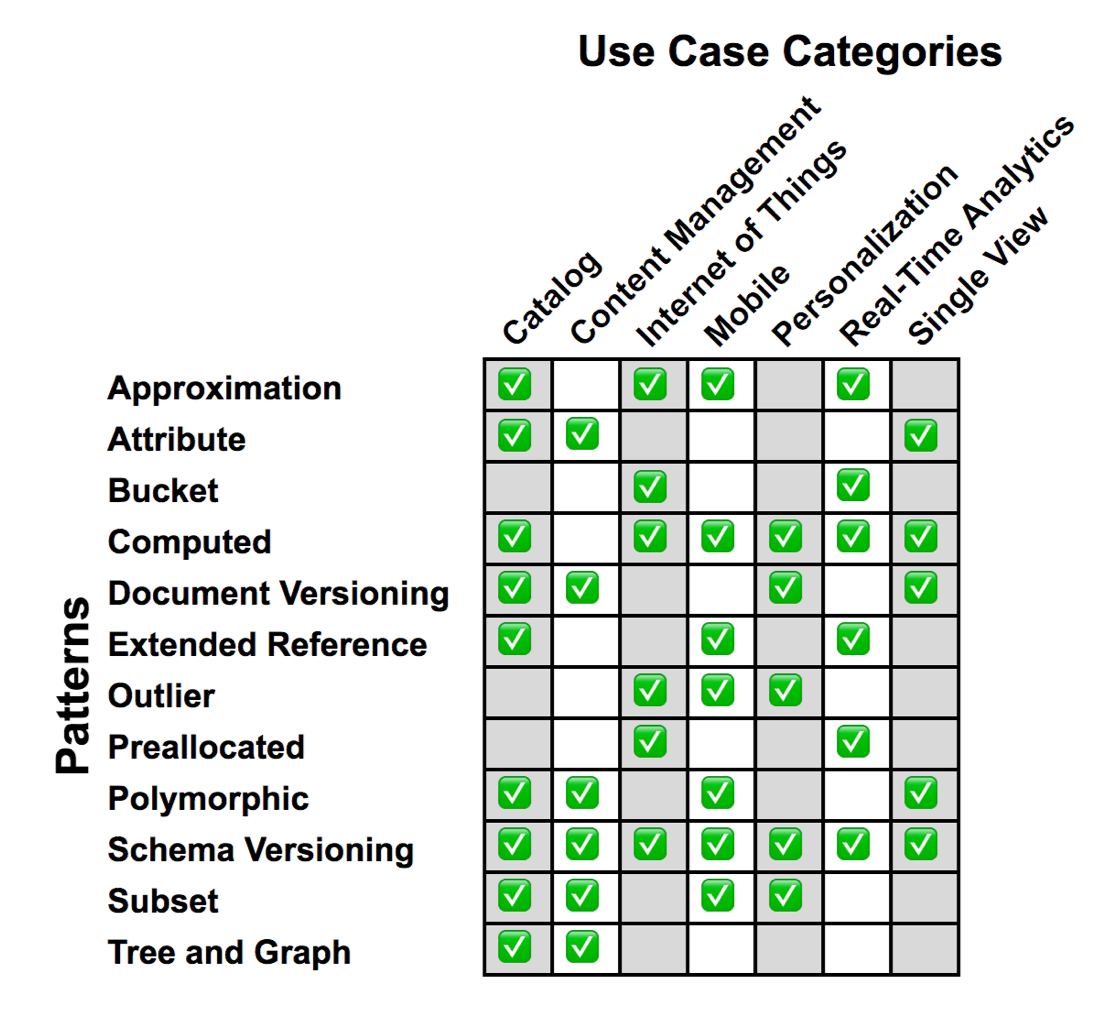
上述的圖表列舉了 12 種設計模式及應用場景,主要是以下這些:
- 近似值模式(Approximation Pattern)
- 屬性模式(Attribute Pattern)
- 桶模式(Bucket Pattern)
- 計算模式(Computed Pattern)
- 檔案版本控制模式(Document Versioning Pattern)
- 擴展參考模式(Extended Peference Pattern)
- 例外值模式(Outlier Pattern)
- 預分配模式(Preallocated Pattern)
- 多型模式(Polymorphic Pattern)
- 模式版本控制模式(Schema Versioning Pattern)
- 子集模式(Subset Pattern)
- 樹型模式(Tree and Graph Pattern)
近似值模式
示例描述
淘寶在往年“雙十一”都會有一個銷售額大屏展示,當銷售額小于 1 億時,可能展示的是實際的數量,當銷售額超過 1 億時,單位立即變成以“億”為單位,對于展示的大屏而言,”億“以下的單位這個時候并不是很重要了,
對于上述的場景,如果每次幾十、幾百都直接去更新資料庫中的實際值,則更新資料庫會變得非常頻繁,對于資料庫的壓力是非常大的,
實際上,并不需要每次都去更新資料庫,我們只需要將這個實際的精確值存盤在記憶體中,使用 1 億作為一個閾值,一旦超過這個閾值就精確值更新進資料庫中,
對于精度不是首要考慮因素時,那么就可以使用近似值模式,尤其是消耗資源(時間、記憶體、CPU 周期)非常昂貴時效果會更佳,
近似值模式就是通過減少資料的寫入頻率,從而降低了架構的復雜度和資源開銷,進而提升了整體的性能與效率,
優缺點
近似值模式的優點如下:
- 由于是近似的資料,不必時時刻刻寫入,資料庫的寫操作量級更小
近似值模式的缺點如下:
- 存盤的是近似的資料,無法應對需要展示精確資料的場景
- 此模式需要在應用層實作
屬性模式
示例描述
屬性模式運用到了 MongoDB 多鍵索引的概念,支持對陣列中的嵌套子檔案中的某個屬性進行索引,
假設現在有一個關于電影的集合,其中檔案中會包含標題、導演、制片人、演員、上映時間等等資訊,對于跨地區上映的電影,有可能不同地區的上映時間是不一樣的,
如下展示是一條電影的檔案資料:
{
"title": "Star Wars",
"director": "George Lucas",
// 不同地區有不同的上映時間
"release_US": ISODate("1977-05-20T01:00:00+01:00"),
"release_France": ISODate("1977-10-19T01:00:00+01:00"),
"release_Italy": ISODate("1977-10-20T01:00:00+01:00"),
"release_UK": ISODate("1977-12-27T01:00:00+01:00"),
}
為了支持對所有上映時間做一個快速搜索,也許我們需要將所有的上映時間設定為單一索引,這個時候,索引的數量就會變得顯而易見的多,
使用屬性模式,我們通過將這些上映時間資訊移動到一個陣列中,然后再對這個陣列建立一個多鍵索引索引,以實作使用一個索引替代多個類似索引的功能,
如下是修改結構后的檔案資料:
{
"title": "Star Wars",
"director": "George Lucas",
// 所有的地區的上映時間都放在同一個屬性內部
"releaseList": [
{
"region": "US",
"date": ISODate("1977-05-20T01:00:00+01:00")
},
{
"region": "France",
"date": ISODate("1977-10-19T01:00:00+01:00")
},
{
"region": "Italy",
"date": ISODate("1977-10-20T01:00:00+01:00")
},
{
"region": "UK",
"date": ISODate("1977-12-27T01:00:00+01:00")
}
]
}
優缺點
屬性模式的優點如下:
- 需要更少的索引
- 查詢變得更容易撰寫,而且通常更快
桶模式
示例描述
桶模式有點類似于水平分庫,常見的水平分庫是將一個集合按照某一個規則分布到不同的資料庫上,桶模式是將一個集合中的檔案按照某一個規則合并起來,
假設現在有一個需要記錄用戶日志的需求,對于用戶的每一個動作,都需要將其更新到 MongoDB 當中,并且是記錄其動作、時間,
對于這樣的日志資料來說,如果將每一個動作都存盤成一個檔案,則將會占用極大的存盤空間和記憶體,
使用桶模式的解決辦法就是,將一段時間的日志資料存盤成一個檔案,再將每一個動作日志的資料存盤到子檔案資料中,
當需要管理流式資料的時候,如時間序列、實時分析或物聯網應用程式,桶模式就是一個很好的解決方案,
優缺點
桶模式的優點如下:
- 減少了集合中的檔案總數
- 提高了索引性能
- 可以通過預聚合簡化資料的訪問
計算模式
示例描述
對于大型資料集,每一次計算都可能會占用極大的 CPU、磁盤、記憶體等相關資源,甚至是影響到服務器上的其他計算,
而對于需要重復計算、讀取比寫入多的場景,計算模式提供了一種優化的思路,以便降低服務器資源的占用,
拿一個電影觀看總人數的例子來說明:假設現在頁面上需要展示觀看電影的實際總人數,而且這個頁面會有成千上萬的人訪問,
雖然,我們可以對電影的每一次放映都記錄起觀看人數,但是要獲取總人數,則需要拿出所有的放映場次的觀看人數之后計算其總和,這個計算就非常耗費資源和時間,
對于只有放映場次變化之后,總人數才會更新的情況,實際資料庫讀取的次數遠遠大于寫入的次數,
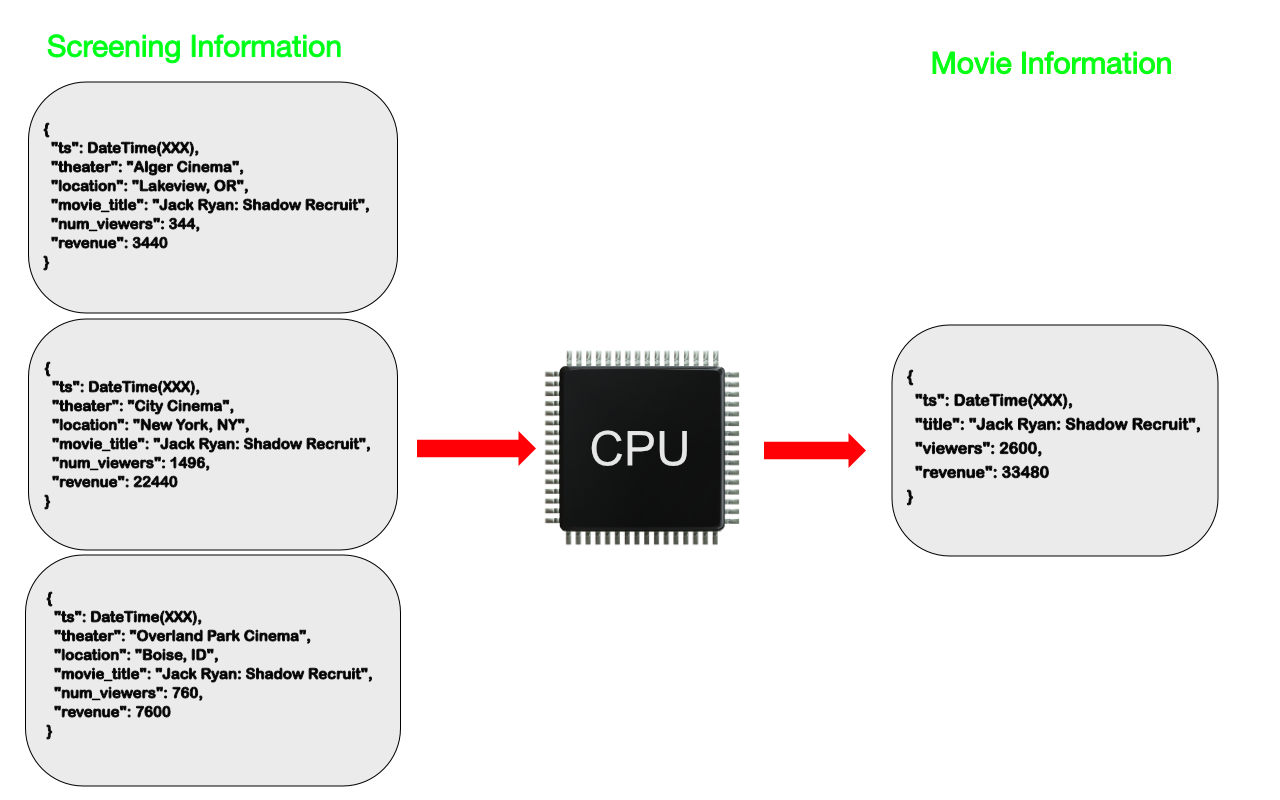
在這個場景中,計算模式的思路是:每一次更新放映場次資料的時候,將這個放映場次的人數匯總到一個檔案當中,這個檔案直接面向用戶的查詢,
優缺點
計算模式的優點如下:
- 對于頻繁的計算可以減少 CPU 的負載
- 查詢變得更容易撰寫,而且通常更快
計算模式的缺點如下:
- 識別出需要使用此模式的的場景可能比較困難
- 除非必要,請勿過度使用此模式
檔案版本控制模式
示例描述
檔案版本控制模式在高度規范化的行業中非常有用,這些行業會要求資料的特定時間點版本,
假設現在有一個博客系統,其中有一個記錄每次編輯博客文章歷史的功能,這樣的功能就能應用檔案版本控制模式,
假設我們將所有的文章歷史都存盤在同一個集合當中,則需要考慮大部分與文章相關的功能都要過濾掉歷史版本、版本越多則集合檔案數量越多等等問題,
檔案版本控制模式的想法是:檔案中需要記錄一個檔案的版本,將最新的檔案保存在一個 current 集合中,而那些舊版本的檔案保存在 history 集合中,
為了最大化利用檔案版本控制模式的優勢,通常會假設資料訪問模式盡量符合以下要求:
- 每個檔案不會有太多的修訂版本
- 需要做版本控制的檔案不會太多
- 大多數的查詢都是基于檔案的最新版本
優缺點
檔案版本控制模式的優點如下:
- 容易實作,對現有系統的影響小
- 在最新版本上進行請求時,沒有性能上的影響
檔案版本控制模式的缺點如下:
- 寫操作的數量會翻倍
- 請求需要被定位到正確的集合
擴展參考模式
示例描述
MongoDB 是一個不需要提前建模的 NoSQL,當不同檔案、不同集合之間存在關系的時候,通常會有嵌入和參考兩種方式,
嵌入就是將檔案資料嵌入到參考此資料的檔案中,訪問時直接訪問這一次檔案即可;參考就是只在檔案中參考另一個檔案的標識,訪問時需要訪問兩次資料庫才能拿到完整的資料,
擴展參考模式是指僅復制經常訪問并且不經常更改的欄位,而不是復制所有的資料,減少資訊的連接以提高性能,

這張圖的場景是:客戶和訂單是 1 對 N 的關系,通常查詢訂單串列的時候需要展示客戶的一些資訊,我們就需要考慮是否將客戶的資訊冗余進訂單資訊中,
擴展參考模式認為,客戶的名稱和地址是不常做更新的,可以直接將這些資訊冗余進訂單表中,以達到減少兩個集合連接查詢的要求,
優缺點
擴展參考模式的優點如下:
- 當有大量的 JOIN 操作時可以提升性能
- 讀操作會更快,并且可以減少 JOIN 操作的數量
擴展參考模式的缺點如下:
- 修改冗余的這部分資料會比較復雜
例外值模式
示例描述
顧名思義,例外值模式主要用以解決超出應用程式正常模式的少數例外查詢情況,
假設你正在搭建一個出售圖書的電子商務網站,現在需要記錄一本書都有哪些用戶購買過,一個常見的做法的是將購買的用戶標識存盤在圖書檔案中,如下展示:
{
"_id": ObjectId('6392cecd4dd9624424ad025d'),
"title": "三國演義",
"author": "羅貫中",
"purchase_customers": [
"user0",
"user1",
"user3",
// ...
]
}
對于上述的檔案結構,大部分情況下是適用的,但是,對于銷量特別高的圖書,極可能導致圖書檔案的大小超過 16MB 的限制,
使用例外值模式的方式是:在圖書檔案中添加一個欄位來將其標記為例外值,超過一定大小的內容可以存盤在另一個檔案當中,在應用程式中對例外檔案做擴展查詢處理,減少例外檔案對正常檔案的影響,
優缺點
例外值模式的優點如下:
- 防止整個應用被某些例外的檔案或請求所影響
- 請求會針對那些典型的用例進行優化,而例外值仍將得到處理
例外值模式的缺點如下:
- 通常會為特定的查詢而進行定制,因此一些臨時產生的查詢可能性能不太理想
- 此模式的大部分作業是在應用程式代碼中完成的
預分配模式
示例描述
在使用 MMAPv1 存盤引擎時,MongoDB 的一個常見優化是提前分配所需的記憶體,以滿足不斷增長的檔案未來會達到的大小,
MMAPv1 中不斷增長的檔案需要由服務端以相當昂貴的成本進行位置的遷移,而 WiredTiger 的無鎖機制(lock-free)和重寫(rewrite)更新演算法不需要這種處理,
一個相對應的例子就是,直接存盤一個二維資料可以做到預分配記憶體,而存盤二維陣列轉換后的稀疏陣列則無法做到預分配記憶體,
因此,在 MMAPv1 中,更推薦使用預分配模式直接存盤原始的二維陣列,
優缺點
預分配模式的優點如下:
- 當預先知道檔案結構時,可以簡化設計
預分配模式的缺點如下:
- 簡單和性能之間的權衡
多型模式
示例描述
在面向物件中,多型指的是為不同資料型別的物體提供統一的介面,或使用一個單一的符號來表示多個不同的型別,
而 MongoDB 不強制要求集合的檔案擁有特定的結構,這里的多型模式指的是,集合中的檔案具有更多的相似性而不是差異性,檔案結構都類似但又不完全相同,
其一種實作方案是將檔案分組在一起做查詢,而不是將其分散到多個集合中;另一種實作方案是使用嵌入式子檔案的模式匯總,
多型模式的一個典型用例是單一視圖應用程式:假設現在一家較大的公司收購了其他公司,這些公司的業務都是類似的,資料庫都以類似的方式存盤了資料,
這個時候就可以利用 MongoDB 和多型模式在短時間內構建好單一視圖應用程式,
除了單一視圖應用程式外,多型模式的其他典型用例還有以下幾種:
- 內容管理
- 移動應用程式
- 產品目錄
優缺點
多型模式的優點如下:
- 實作簡單
- 查詢可以在單個集合中運行
模式版本控制模式
示例描述
幾乎每個資料庫在其生命周期中的某個時刻都會產生變更,一旦資料庫中的資料模型發生變化,通常需要停止應用程式,遷移資料庫以支持新模式,然后重新啟動,
這種停機更新會導致糟糕的用戶體驗,而模式版本控制模式允許歷史版本和當前版本的檔案在集合中同時存在,以此保障用戶體驗,
通過使用 schema_version 欄位定義模式的版本,并將其保存到資料庫中,每個新的模式版本都會增加 schema_version 欄位的值,
在應用程式內部,為每個模式版本創建相應的處理函式,這樣即可適應不同版本的資料,
優缺點
模式版本控制模式的優點如下:
- 不需要停機時間
- 模式遷移可控
- 減少未來的技術債務
模式版本控制模式的缺點如下:
- 在遷移程序中,對相同的欄位可能需要兩個索引
子集模式
示例描述
MongoDB 將頻繁訪問的資料保存在 RAM 中,當資料和索引的作業集超過分配的物理 RAM 時,隨著磁盤訪問的發生以及資料從 RAM 中轉出,性能會開始下降,
為解決這個問題,一個方案是向服務器添加更多的 RAM,不過擴展會有上限,而且非常昂貴;或者考慮對集合進行分片,但這會帶來額外的成本和復雜性,
子集模式就解決了有大量資料的大檔案沒有被應用程式使用而導致的作業集超過 RAM 容量的問題,比如說一個電商產品的評論可能有成千上萬條,但大部分情況下都只會訪問最近 10 個評論,
其實作方法就是,將一個存盤大檔案的集合拆分成多個子集,每一個子集都能為單獨的功能提供資源,減少了作業集的總體大小,
優缺點
子集模式的優點如下:
- 在總體上減小了作業集的大小
- 縮短了最常用資料的磁盤訪問時間
子集模式的缺點如下:
- 必須管理子集
- 請求附加的資料需要額外的資料庫訪問
樹形模式
示例描述
對于 SQL 來說,可以通過外鏈子結點或父結點的方式表示樹形結構,
對于 MongoDB 而言,比較方便的就是通過存盤子結點陣列的方式實作,但是其缺點就是每次更新時都需要操作整個結構,不合適做頻繁更新,比如說家譜,
因此,當資料是分層結構并且經常被查詢時,樹形模式是比較優的一個選擇,并且可以通過給陣列中的屬性創建多鍵索引提高查詢效率,
優缺點
樹形模式的優點如下:
- 通過避免多次 JOIN 操作提高了性能
樹形模式的缺點如下:
- 需要在應用程式中管理樹結構的更新
首發于「程式員翔仔」,點擊查看更多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/539889.html
標籤:NoSQL
上一篇:SQL審核平臺Yearning